

Klasyfikacja wideo to zadanie uczenia maszynowego polegające na identyfikowaniu tego, co reprezentuje film. Model klasyfikacji wideo jest szkolony na zestawie danych wideo, który zawiera zestaw unikalnych klas, takich jak różne akcje lub ruchy. Model odbiera klatki wideo jako dane wejściowe i podaje prawdopodobieństwo, że każda klasa będzie reprezentowana w filmie.
Zarówno modele klasyfikacji wideo, jak i modele klasyfikacji obrazów wykorzystują obrazy jako dane wejściowe do przewidywania prawdopodobieństw, że te obrazy należą do predefiniowanych klas. Jednak model klasyfikacji wideo przetwarza również relacje przestrzenno-czasowe między sąsiednimi klatkami, aby rozpoznać działania w filmie.
Na przykład model rozpoznawania działań wideo można wytrenować w celu identyfikowania ludzkich działań, takich jak bieganie, klaskanie i machanie. Poniższa ilustracja przedstawia dane wyjściowe modelu klasyfikacji wideo w systemie Android.
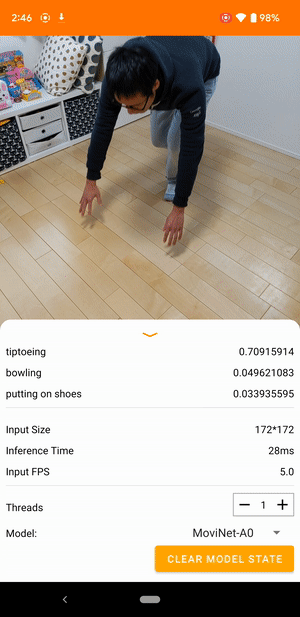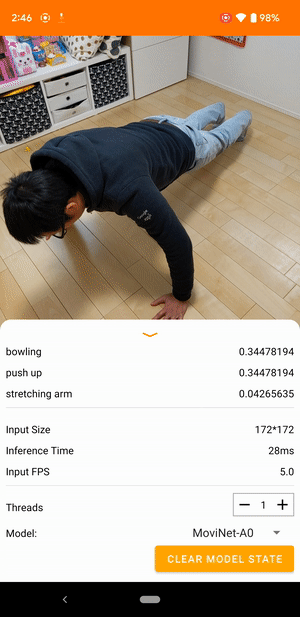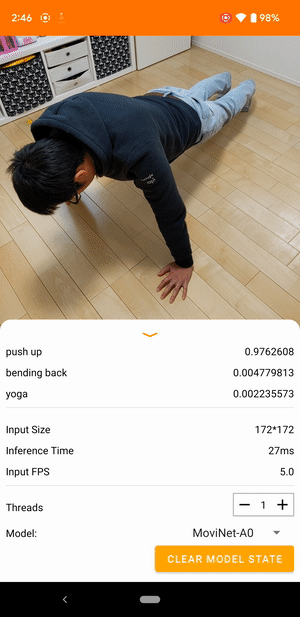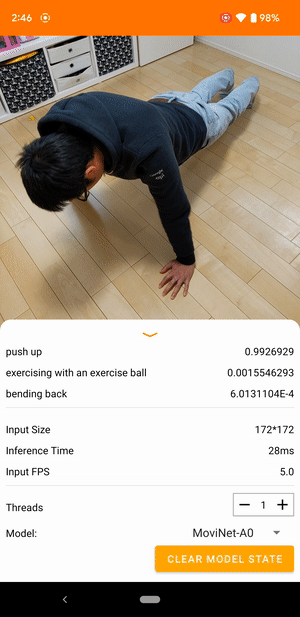
Zaczynaj
Jeśli korzystasz z platformy innej niż Android lub Raspberry Pi lub znasz już interfejsy API TensorFlow Lite , pobierz startowy model klasyfikacji wideo i pliki pomocnicze. Możesz także zbudować własny, niestandardowy potok wnioskowania, korzystając z biblioteki pomocniczej TensorFlow Lite .
Pobierz model startowy z metadanymi
Jeśli dopiero zaczynasz korzystać z TensorFlow Lite i pracujesz z systemem Android lub Raspberry Pi, zapoznaj się z poniższymi przykładowymi aplikacjami, które pomogą Ci rozpocząć.
Android
Aplikacja na Androida wykorzystuje tylną kamerę urządzenia do ciągłej klasyfikacji wideo. Wnioskowanie odbywa się przy użyciu interfejsu API języka Java TensorFlow Lite . Aplikacja demonstracyjna klasyfikuje klatki i wyświetla przewidywane klasyfikacje w czasie rzeczywistym.
Malinowe Pi
Przykład Raspberry Pi wykorzystuje TensorFlow Lite z Pythonem do ciągłej klasyfikacji wideo. Podłącz Raspberry Pi do kamery, np. Pi Camera, aby przeprowadzić klasyfikację wideo w czasie rzeczywistym. Aby wyświetlić wyniki z kamery, podłącz monitor do Raspberry Pi i użyj protokołu SSH, aby uzyskać dostęp do powłoki Pi (aby uniknąć podłączania klawiatury do Pi).
Przed rozpoczęciem skonfiguruj Raspberry Pi z systemem operacyjnym Raspberry Pi (najlepiej zaktualizowanym do wersji Buster).
Opis modelu
Mobilne sieci wideo ( MoViNets ) to rodzina wydajnych modeli klasyfikacji wideo zoptymalizowanych pod kątem urządzeń mobilnych. Sieci MoViNet charakteryzują się najnowocześniejszą dokładnością i wydajnością w przypadku kilku wielkoskalowych zbiorów danych dotyczących rozpoznawania działań wideo, dzięki czemu doskonale nadają się do zadań związanych z rozpoznawaniem działań wideo .
Istnieją trzy warianty modelu MoviNet dla TensorFlow Lite: MoviNet-A0 , MoviNet-A1 i MoviNet-A2 . Warianty te przeszkolono przy użyciu zestawu danych Kinetics-600 , aby rozpoznawały 600 różnych działań człowieka. MoviNet-A0 jest najmniejszym, najszybszym i najmniej dokładnym rozwiązaniem. MoviNet-A2 jest największym, najwolniejszym i najdokładniejszym. MoviNet-A1 jest kompromisem pomiędzy A0 i A2.
Jak to działa
Podczas szkolenia udostępniany jest model klasyfikacji wideo i powiązane z nimi etykiety . Każda etykieta to nazwa odrębnej koncepcji lub klasy, którą model nauczy się rozpoznawać. W przypadku rozpoznawania działań wideo filmy będą przedstawiać działania człowieka, a etykiety będą powiązanymi działaniami.
Model klasyfikacji wideo może nauczyć się przewidywać, czy nowe filmy należą do którejkolwiek z klas udostępnianych podczas szkolenia. Proces ten nazywany jest wnioskowaniem . Możesz także skorzystać z uczenia transferowego , aby zidentyfikować nowe klasy filmów, korzystając z istniejącego modelu.
Model jest modelem strumieniowym, który odbiera ciągłe wideo i reaguje w czasie rzeczywistym. Gdy model odbiera strumień wideo, identyfikuje, czy którakolwiek z klas ze zbioru danych szkoleniowych jest reprezentowana w wideo. Dla każdej klatki model zwraca te klasy wraz z prawdopodobieństwem, że wideo reprezentuje tę klasę. Przykładowe wyjście w danym momencie może wyglądać następująco:
| Działanie | Prawdopodobieństwo |
|---|---|
| taniec kwadratowy | 0,02 |
| igła do nawlekania | 0,08 |
| kręcąc palcami | 0,23 |
| Macha ręką | 0,67 |
Każde działanie w danych wyjściowych odpowiada etykiecie w danych szkoleniowych. Prawdopodobieństwo oznacza prawdopodobieństwo, że akcja zostanie wyświetlona w filmie.
Wejścia modelu
Model przyjmuje jako sygnał wejściowy strumień klatek wideo RGB. Rozmiar wejściowego wideo jest elastyczny, ale idealnie pasuje do rozdzielczości uczenia modelu i liczby klatek na sekundę:
- MoviNet-A0 : 172 x 172 przy 5 kl./s
- MoviNet-A1 : 172 x 172 przy 5 kl./s
- MoviNet-A1 : 224 x 224 przy 5 kl./s
Oczekuje się, że wejściowe filmy wideo będą miały wartości kolorów w zakresie od 0 do 1, zgodnie z powszechnymi konwencjami wejściowymi obrazu .
Wewnętrznie model analizuje także kontekst każdej klatki, wykorzystując informacje zebrane w poprzednich klatkach. Osiąga się to poprzez pobieranie stanów wewnętrznych z danych wyjściowych modelu i wprowadzanie ich z powrotem do modelu w nadchodzących klatkach.
Wyjścia modelu
Model zwraca serię etykiet i odpowiadających im wyników. Wyniki są wartościami logitowymi, które reprezentują przewidywania dla każdej klasy. Wyniki te można przekonwertować na prawdopodobieństwa za pomocą funkcji softmax ( tf.nn.softmax ).
exp_logits = np.exp(np.squeeze(logits, axis=0))
probabilities = exp_logits / np.sum(exp_logits)
Wewnętrznie dane wyjściowe modelu obejmują również stany wewnętrzne z modelu i przekazują je z powrotem do modelu w nadchodzących klatkach.
Benchmarki wydajności
Wartości porównawcze wydajności są generowane za pomocą narzędzia do porównywania . Sieci MoviNet obsługują tylko procesor.
Wydajność modelu mierzy się ilością czasu potrzebnego modelowi na wykonanie wnioskowania na danym sprzęcie. Niższy czas oznacza szybszy model. Dokładność mierzy się częstotliwością, w której model poprawnie klasyfikuje zajęcia w filmie.
| Nazwa modelu | Rozmiar | Dokładność * | Urządzenie | PROCESOR ** |
|---|---|---|---|---|
| MoviNet-A0 (kwantyzacja całkowita) | 3,1 MB | 65% | Piksel 4 | 5 ms |
| Piksel 3 | 11 ms | |||
| MoviNet-A1 (kwantyzacja całkowita) | 4,5 MB | 70% | Piksel 4 | 8 ms |
| Piksel 3 | 19 ms | |||
| MoviNet-A2 (kwantyzacja całkowita) | 5,1 MB | 72% | Piksel 4 | 15 ms |
| Piksel 3 | 36 ms |
* Najlepsza dokładność zmierzona w zestawie danych Kinetics-600 .
** Opóźnienie mierzone podczas pracy na procesorze z 1 wątkiem.
Personalizacja modelu
Wstępnie wytrenowane modele są szkolone w zakresie rozpoznawania 600 ludzkich działań ze zbioru danych Kinetics-600 . Możesz także użyć uczenia transferowego, aby ponownie wytrenować model w celu rozpoznawania ludzkich działań, które nie znajdują się w oryginalnym zestawie. Aby to zrobić, potrzebujesz zestawu filmów szkoleniowych dla każdego z nowych działań, które chcesz uwzględnić w modelu.
Więcej informacji na temat dostrajania modeli na niestandardowych danych można znaleźć w repozytorium MoViNets i samouczku MoViNets .
Dalsza lektura i zasoby
Aby dowiedzieć się więcej o koncepcjach omawianych na tej stronie, skorzystaj z następujących zasobów: