

Классификация видео — это задача машинного обучения, направленная на определение того, что представляет собой видео. Модель классификации видео обучается на наборе видеоданных, который содержит набор уникальных классов, таких как различные действия или движения. Модель получает видеокадры в качестве входных данных и выводит вероятность того, что каждый класс будет представлен в видео.
Модели классификации видео и изображений используют изображения в качестве входных данных для прогнозирования вероятности принадлежности этих изображений к заранее определенным классам. Однако модель классификации видео также обрабатывает пространственно-временные отношения между соседними кадрами, чтобы распознавать действия в видео.
Например, модель распознавания видеодействий можно обучить распознавать действия человека, такие как бег, хлопки в ладоши и махание рукой. На следующем изображении показаны выходные данные модели классификации видео на Android.
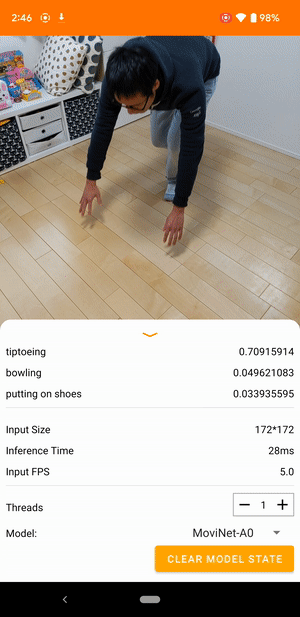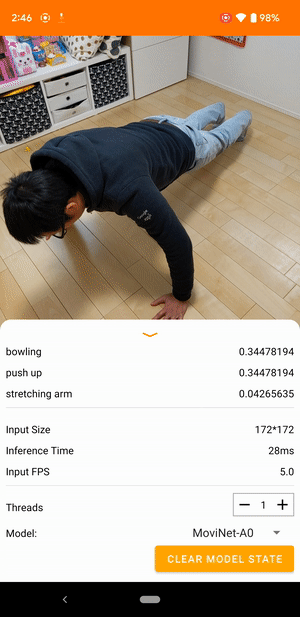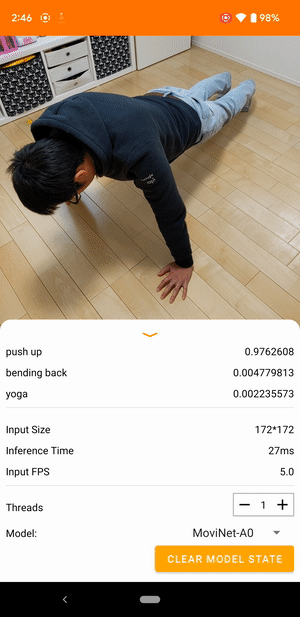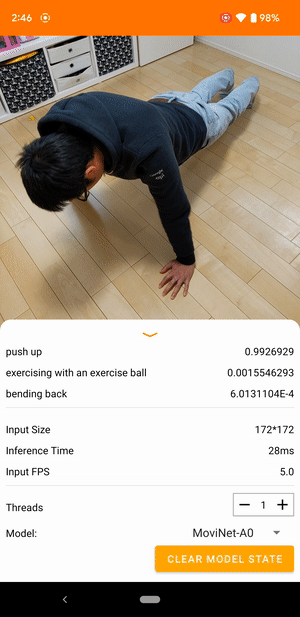
Начать
Если вы используете платформу, отличную от Android или Raspberry Pi, или если вы уже знакомы с API-интерфейсами TensorFlow Lite , загрузите начальную модель классификации видео и вспомогательные файлы. Вы также можете создать свой собственный конвейер вывода, используя библиотеку поддержки TensorFlow Lite .
Скачать стартовую модель с метаданными
Если вы новичок в TensorFlow Lite и работаете с Android или Raspberry Pi, изучите следующие примеры приложений, которые помогут вам начать работу.
Андроид
Приложение Android использует заднюю камеру устройства для непрерывной классификации видео. Вывод выполняется с помощью Java API TensorFlow Lite . Демо-приложение классифицирует кадры и отображает прогнозируемые классификации в режиме реального времени.
Raspberry Pi
В примере Raspberry Pi используется TensorFlow Lite с Python для непрерывной классификации видео. Подключите Raspberry Pi к камере, например Pi Camera, чтобы выполнять классификацию видео в реальном времени. Чтобы просмотреть результаты с камеры, подключите монитор к Raspberry Pi и используйте SSH для доступа к оболочке Pi (чтобы избежать подключения клавиатуры к Pi).
Прежде чем начать, настройте Raspberry Pi на ОС Raspberry Pi (желательно обновленную до Buster).
Описание модели
Мобильные видеосети ( MoViNets ) — это семейство эффективных моделей классификации видео, оптимизированных для мобильных устройств. MoViNets демонстрируют современную точность и эффективность на нескольких крупномасштабных наборах данных распознавания видеодействий, что делает их хорошо подходящими для задач распознавания видеодействий .
Существует три варианта модели MoviNet для TensorFlow Lite: MoviNet-A0 , MoviNet-A1 и MoviNet-A2 . Эти варианты были обучены с помощью набора данных Kinetics-600 распознаванию 600 различных действий человека. MoviNet-A0 — самый маленький, быстрый и наименее точный. MoviNet-A2 — самый большой, медленный и точный. MoviNet-A1 представляет собой компромисс между A0 и A2.
Как это работает
Во время обучения модели классификации видео предоставляются видеоролики и связанные с ними метки . Каждая метка — это имя отдельной концепции или класса, который модель научится распознавать. Для распознавания видеодействий видеоролики будут отражать действия человека, а метки будут ассоциироваться с действиями.
Модель классификации видео может научиться предсказывать, принадлежат ли новые видео к какому-либо из классов, предоставленных во время обучения. Этот процесс называется выводом . Вы также можете использовать трансферное обучение для определения новых классов видео, используя уже существующую модель.
Модель представляет собой потоковую модель, которая получает непрерывное видео и отвечает в режиме реального времени. Когда модель получает видеопоток, она определяет, представлены ли в видео какие-либо классы из набора обучающих данных. Для каждого кадра модель возвращает эти классы вместе с вероятностью того, что видео представляет этот класс. Пример вывода в определенный момент времени может выглядеть следующим образом:
| Действие | Вероятность |
|---|---|
| кадриль | 0,02 |
| нитковая игла | 0,08 |
| вертя пальцы | 0,23 |
| Размахивая рукой | 0,67 |
Каждое действие в выходных данных соответствует метке в обучающих данных. Вероятность обозначает вероятность того, что действие отображается в видео.
Входные данные модели
Модель принимает на вход поток видеокадров RGB. Размер входного видео является гибким, но в идеале он соответствует разрешению и частоте кадров обучения модели:
- MoviNet-A0 : 172 x 172 при 5 кадрах в секунду
- MoviNet-A1 : 172 x 172 при 5 кадрах в секунду
- MoviNet-A1 : 224 x 224 при 5 кадрах в секунду
Ожидается, что входные видео будут иметь значения цвета в диапазоне от 0 до 1 в соответствии с общепринятыми соглашениями по вводу изображений .
Внутри модель также анализирует контекст каждого кадра, используя информацию, собранную в предыдущих кадрах. Это достигается путем извлечения внутренних состояний из выходных данных модели и передачи их обратно в модель для последующих кадров.
Выходные данные модели
Модель возвращает серию меток и соответствующие им оценки. Оценки представляют собой логит-значения, которые представляют прогноз для каждого класса. Эти оценки можно преобразовать в вероятности с помощью функции softmax ( tf.nn.softmax ).
exp_logits = np.exp(np.squeeze(logits, axis=0))
probabilities = exp_logits / np.sum(exp_logits)
Внутренние выходные данные модели также включают внутренние состояния модели и передают их обратно в модель для последующих кадров.
Тесты производительности
Показатели производительности генерируются с помощью инструмента сравнительного анализа . MoviNets поддерживают только ЦП.
Производительность модели измеряется количеством времени, которое требуется модели для выполнения вывода на данном аппаратном обеспечении. Меньшее время подразумевает более быструю модель. Точность измеряется тем, насколько часто модель правильно классифицирует класс в видео.
| Название модели | Размер | Точность * | Устройство | ПРОЦЕССОР ** |
|---|---|---|---|---|
| MoviNet-A0 (целочисленно-квантованный) | 3,1 МБ | 65% | Пиксель 4 | 5 мс |
| Пиксель 3 | 11 мс | |||
| MoviNet-A1 (целочисленно-квантованный) | 4,5 МБ | 70% | Пиксель 4 | 8 мс |
| Пиксель 3 | 19 мс | |||
| MoviNet-A2 (целочисленно-квантованный) | 5,1 МБ | 72% | Пиксель 4 | 15 мс |
| Пиксель 3 | 36 мс |
* Точность высшего уровня измерена на наборе данных Kinetics-600 .
** Задержка измерена при работе на однопоточном процессоре.
Настройка модели
Предварительно обученные модели обучены распознавать 600 действий человека из набора данных Kinetics-600 . Вы также можете использовать трансферное обучение, чтобы переобучить модель для распознавания действий человека, которых нет в исходном наборе. Для этого вам понадобится набор обучающих видеороликов для каждого нового действия, которое вы хотите включить в модель.
Дополнительную информацию о точной настройке моделей на основе пользовательских данных см. в репозитории MoViNets и в учебном пособии по MoViNets .
Дальнейшее чтение и ресурсы
Используйте следующие ресурсы, чтобы узнать больше о концепциях, обсуждаемых на этой странице: