
The machine learning (ML) operators you use in your model can impact the process of converting a TensorFlow model to TensorFlow Lite format. The TensorFlow Lite converter supports a limited number of TensorFlow operations used in common inference models, which means that not every model is directly convertible. The converter tool allows you to include additional operators, but converting a model this way also requires you to modify the TensorFlow Lite runtime environment you use to execute your model, which can limit your ability use standard runtime deployment options, such as Google Play services.
The TensorFlow Lite Converter is designed to analyze model structure and apply optimizations in order to make it compatible with the directly supported operators. For example, depending on the ML operators in your model, the converter may elide or fuse those operators in order to map them to their TensorFlow Lite counterparts.
Even for supported operations, specific usage patterns are sometimes expected, for performance reasons. The best way to understand how to build a TensorFlow model that can be used with TensorFlow Lite is to carefully consider how operations are converted and optimized, along with the limitations imposed by this process.
Supported operators
TensorFlow Lite built-in operators are a subset of the operators that are part of the TensorFlow core library. Your TensorFlow model may also include custom operators in the form of composite operators or new operators defined by you. The diagram below shows the relationships between these operators.
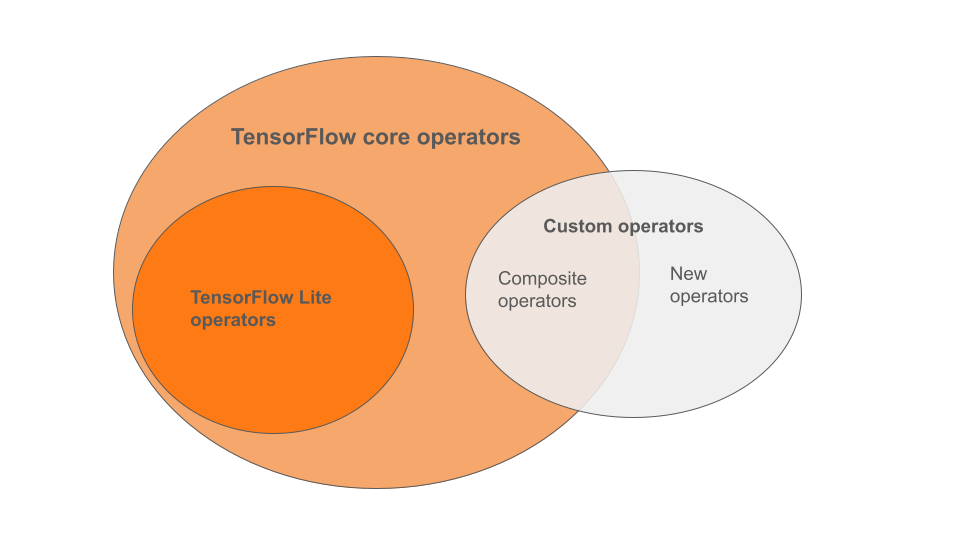
From this range of ML model operators, there are 3 types of models supported by the conversion process:
- Models with only TensorFlow Lite built-in operator. (Recommended)
- Models with the built-in operators and select TensorFlow core operators.
- Models with the built-in operators, TensorFlow core operators and/or custom operators.
If your model only contains operations that are natively supported by TensorFlow Lite, you do not need any additional flags to convert it. This is the recommended path because this type of model will convert smoothly and is simpler to optimize and run using the default TensorFlow Lite runtime. You also have more deployment options for your model such as Google Play services. You can get started with the TensorFlow Lite converter guide. See the TensorFlow Lite Ops page for a list of built-in operators.
If you need to include select TensorFlow operations from the core library, you must specify that at conversion and ensure your runtime includes those operations. See the Select TensorFlow operators topic for detailed steps.
Whenever possible, avoid the last option of including custom operators in your converted model. Custom operators are either operators created by combining multiple primitive TensorFlow core operators or defining a completely new one. When custom operators are converted, they can increase the size of the overall model by incurring dependencies outside of the built-in TensorFlow Lite library. Custom ops, if not specifically created for mobile or device deployment, can result in worse performance when deployed to resource constrained devices compared to a server environment. Finally, just like including select TensorFlow core operators, custom operators requires you to modify the model runtime environment which limits you from taking advantage of standard runtime services such as the Google Play services.
Supported types
Most TensorFlow Lite operations target both floating-point (float32) and
quantized (uint8, int8) inference, but many ops do not yet for other types
like tf.float16 and strings.
Apart from using different version of the operations, the other difference between floating-point and quantized models is the way they are converted. Quantized conversion requires dynamic range information for tensors. This requires "fake-quantization" during model training, getting range information via a calibration data set, or doing "on-the-fly" range estimation. See quantization for more details.
Straight-forward conversions, constant-folding and fusing
A number of TensorFlow operations can be processed by TensorFlow Lite even
though they have no direct equivalent. This is the case for operations that can
be simply removed from the graph (tf.identity), replaced by tensors
(tf.placeholder), or fused into more complex operations (tf.nn.bias_add).
Even some supported operations may sometimes be removed through one of these
processes.
Here is a non-exhaustive list of TensorFlow operations that are usually removed from the graph:
tf.addtf.debugging.check_numericstf.constanttf.divtf.dividetf.fake_quant_with_min_max_argstf.fake_quant_with_min_max_varstf.identitytf.maximumtf.minimumtf.multiplytf.no_optf.placeholdertf.placeholder_with_defaulttf.realdivtf.reduce_maxtf.reduce_mintf.reduce_sumtf.rsqrttf.shapetf.sqrttf.squaretf.subtracttf.tiletf.nn.batch_norm_with_global_normalizationtf.nn.bias_addtf.nn.fused_batch_normtf.nn.relutf.nn.relu6
Experimental Operations
The following TensorFlow Lite operations are present, but not ready for custom models:
CALLCONCAT_EMBEDDINGSCUSTOMEMBEDDING_LOOKUP_SPARSEHASHTABLE_LOOKUPLSH_PROJECTIONSKIP_GRAMSVDF