
ابرداده TensorFlow Lite استانداردی برای توصیف مدل ارائه می دهد. فراداده منبع مهمی از دانش در مورد آنچه مدل انجام می دهد و اطلاعات ورودی/خروجی آن است. ابرداده از هر دو تشکیل شده است
- بخش های قابل خواندن توسط انسان که بهترین عملکرد را هنگام استفاده از مدل ارائه می دهند و
- قطعات قابل خواندن توسط ماشین که می توانند توسط تولید کننده های کد مورد استفاده قرار گیرند، مانند مولد کد TensorFlow Lite Android و ویژگی Android Studio ML Binding .
همه مدلهای تصویر منتشر شده در TensorFlow Hub با ابردادهها پر شدهاند.
مدل با فرمت ابرداده
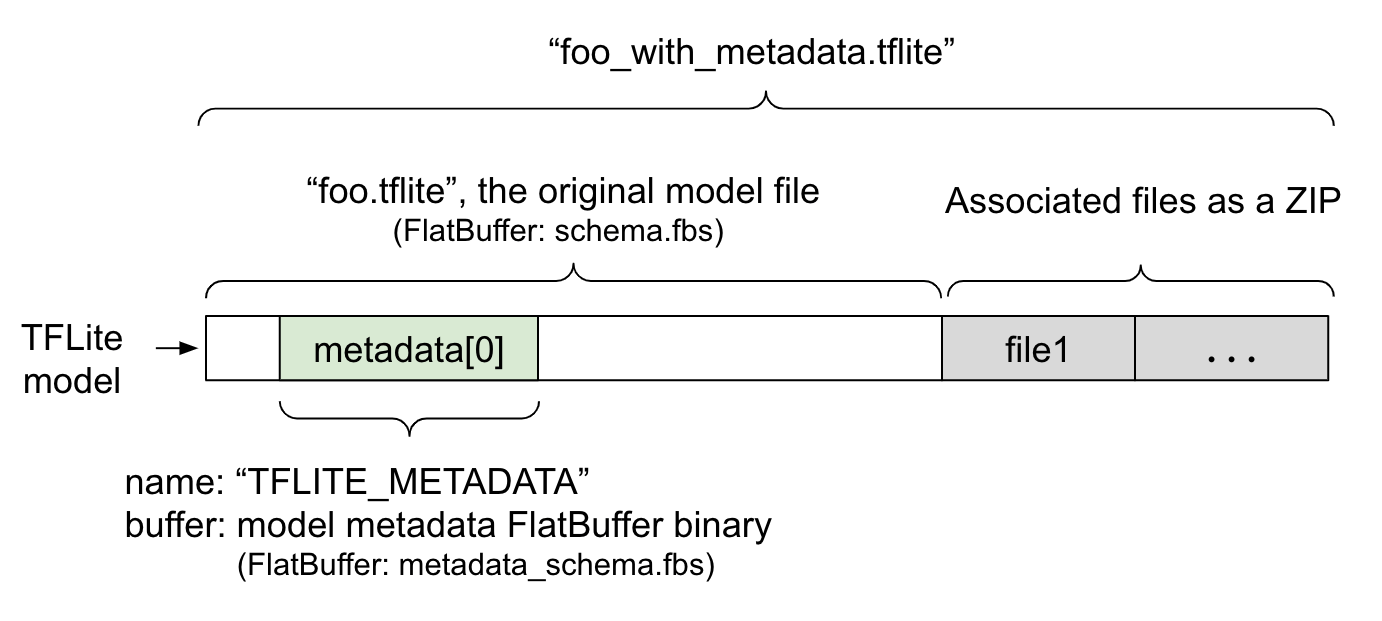
ابرداده مدل در metadata_schema.fbs ، یک فایل FlatBuffer تعریف شده است. همانطور که در شکل 1 نشان داده شده است، در قسمت فوق داده طرحواره مدل TFLite ، تحت نام "TFLITE_METADATA" ذخیره می شود. برخی از مدلها ممکن است با فایلهای مرتبط همراه باشند، مانند فایلهای برچسب طبقهبندی . این فایل ها با استفاده از حالت "Apend" ZipFile (حالت 'a' ) به انتهای فایل مدل اصلی به عنوان یک ZIP الحاق می شوند. TFLite Interpreter می تواند فرمت فایل جدید را به همان روش قبلی مصرف کند. برای اطلاعات بیشتر به بسته بندی فایل های مرتبط مراجعه کنید.
دستورالعمل زیر را در مورد نحوه پر کردن، تجسم و خواندن فراداده مشاهده کنید.
ابزارهای ابرداده را راه اندازی کنید
قبل از افزودن متادیتا به مدل خود، برای اجرای TensorFlow به یک محیط برنامه نویسی پایتون نیاز دارید. یک راهنمای دقیق در مورد نحوه تنظیم این در اینجا وجود دارد.
پس از راه اندازی محیط برنامه نویسی پایتون، باید ابزارهای اضافی را نصب کنید:
pip install tflite-support
ابزار ابرداده TensorFlow Lite از پایتون 3 پشتیبانی می کند.
افزودن ابرداده با استفاده از Flatbuffers Python API
سه بخش برای ابرداده مدل در طرحواره وجود دارد:
- اطلاعات مدل - توضیحات کلی مدل و همچنین مواردی مانند شرایط مجوز. ModelMetadata را ببینید.
- اطلاعات ورودی - شرح ورودی ها و پیش پردازش های مورد نیاز مانند عادی سازی. SubGraphMetadata.input_tensor_metadata را ببینید.
- اطلاعات خروجی - شرح خروجی و پس پردازش مورد نیاز مانند نگاشت به برچسب ها. SubGraphMetadata.output_tensor_metadata را ببینید.
از آنجایی که TensorFlow Lite در این مرحله فقط از یک زیرگراف پشتیبانی می کند، مولد کد TensorFlow Lite و ویژگی Android Studio ML Binding از ModelMetadata.name و ModelMetadata.description به جای SubGraphMetadata.name و SubGraphMetadata.description ، هنگام نمایش ابرداده و ژنر استفاده می کنند.
انواع ورودی/خروجی پشتیبانی شده
ابرداده های TensorFlow Lite برای ورودی و خروجی با در نظر گرفتن انواع مدل خاصی طراحی نشده اند، بلکه انواع ورودی و خروجی را در نظر می گیرند. مهم نیست که مدل از نظر عملکردی چه کاری انجام می دهد، تا زمانی که انواع ورودی و خروجی از موارد زیر یا ترکیبی از موارد زیر تشکیل شده باشد، توسط ابرداده TensorFlow Lite پشتیبانی می شود:
- ویژگی - اعدادی که اعداد صحیح بدون علامت یا float32 هستند.
- تصویر - ابرداده در حال حاضر از تصاویر RGB و مقیاس خاکستری پشتیبانی می کند.
- جعبه مرزی - جعبه های مرزبندی مستطیلی شکل. این طرح از انواع طرح های شماره گذاری پشتیبانی می کند.
فایل های مرتبط را بسته بندی کنید
مدلهای TensorFlow Lite ممکن است با فایلهای مرتبط مختلف همراه باشند. برای مثال، مدلهای زبان طبیعی معمولاً فایلهای vocab دارند که قطعات کلمه را به شناسههای کلمه نگاشت میکنند. مدل های طبقه بندی ممکن است فایل های برچسبی داشته باشند که دسته بندی اشیا را نشان می دهد. بدون فایل های مرتبط (در صورت وجود)، یک مدل به خوبی کار نخواهد کرد.
فایل های مرتبط را می توان از طریق کتابخانه فراداده پایتون با مدل همراه کرد. مدل جدید TensorFlow Lite به یک فایل فشرده تبدیل می شود که شامل مدل و فایل های مرتبط می شود. می توان آن را با ابزارهای زیپ معمولی باز کرد. این قالب مدل جدید همچنان از همان پسوند فایل، .tflite استفاده می کند. با چارچوب TFLite و مترجم موجود سازگار است. برای جزئیات بیشتر به بسته بندی فراداده و فایل های مرتبط در مدل مراجعه کنید.
اطلاعات فایل مرتبط را می توان در ابرداده ثبت کرد. بسته به نوع فایل و جایی که فایل به آن پیوست شده است (به عنوان مثال ModelMetadata ، SubGraphMetadata ، و TensorMetadata )، مولد کد TensorFlow Lite Android ممکن است پردازش قبل/پست مربوطه را به طور خودکار روی شی اعمال کند. برای جزئیات بیشتر به بخش <استفاده از کدگن> هر نوع فایل مرتبط در طرح مراجعه کنید.
پارامترهای نرمال سازی و کوانتیزاسیون
عادی سازی یک تکنیک رایج پیش پردازش داده در یادگیری ماشینی است. هدف نرمال سازی تغییر مقادیر به یک مقیاس مشترک، بدون تحریف تفاوت در محدوده مقادیر است.
کوانتیزاسیون مدل تکنیکی است که امکان نمایش دقیق وزنها و به صورت اختیاری فعالسازی برای ذخیرهسازی و محاسبات را فراهم میکند.
از نظر پیش پردازش و پس پردازش، عادی سازی و کوانتیزه شدن دو مرحله مستقل هستند. در اینجا جزئیات است.
| عادی سازی | کوانتیزاسیون | |
|---|---|---|
نمونه ای از مقادیر پارامتر تصویر ورودی در MobileNet به ترتیب برای مدل های float و quant. | مدل شناور : - میانگین: 127.5 - std: 127.5 مدل کوانت : - میانگین: 127.5 - std: 127.5 | مدل شناور : - نقطه صفر: 0 - مقیاس: 1.0 مدل کوانت : - نقطه صفر: 128.0 - مقیاس: 0.0078125f |
چه زمانی فراخوانی کنیم؟ | ورودی ها : اگر داده های ورودی در آموزش نرمال سازی شوند، داده های ورودی استنتاج باید بر این اساس نرمال سازی شوند. خروجی ها : داده های خروجی به طور کلی عادی نمی شوند. | مدل های شناور نیازی به کوانتیزاسیون ندارند. مدل کوانتیزه ممکن است در پردازش قبل و بعد نیاز به کمی سازی داشته باشد یا نداشته باشد. بستگی به نوع داده تانسورهای ورودی/خروجی دارد. - تانسورهای شناور: بدون نیاز به کوانتیزاسیون در پردازش قبل و بعد. Quant op و dequant op در نمودار مدل قرار می گیرند. - تانسورهای int8/uint8: در پردازش قبل و بعد نیاز به کمی سازی دارند. |
فرمول | normalized_input = (ورودی - میانگین) / std | کمی سازی برای ورودی ها : q = f / مقیاس + نقطه صفر Dequantize برای خروجی ها : f = (q - صفر نقطه) * مقیاس |
پارامترها کجا هستند | توسط سازنده مدل پر شده و در فراداده مدل، به عنوان NormalizationOptions ذخیره می شود | به طور خودکار توسط مبدل TFLite پر شده و در فایل مدل tflite ذخیره می شود. |
| چگونه پارامترها را بدست آوریم؟ | از طریق MetadataExtractor API [2] | از طریق TFLite Tensor API [1] یا از طریق MetadataExtractor API [2] |
| آیا مدلهای شناور و کوانت دارای ارزش یکسانی هستند؟ | بله، مدل های float و quant پارامترهای Normalization یکسانی دارند | خیر، مدل شناور نیازی به کوانتیزاسیون ندارد. |
| آیا TFLite Code Generator یا Android Studio ML binding به طور خودکار آن را در پردازش داده تولید می کند؟ | آره | آره |
[1] TensorFlow Lite Java API و TensorFlow Lite C++ API .
[2] کتابخانه استخراج کننده فراداده
هنگام پردازش دادههای تصویر برای مدلهای uint8، نرمالسازی و کوانتیزاسیون گاهی اوقات نادیده گرفته میشوند. زمانی که مقادیر پیکسل در محدوده [0، 255] هستند انجام این کار خوب است. اما به طور کلی، شما همیشه باید داده ها را بر اساس پارامترهای نرمال سازی و کوانتیزاسیون در صورت لزوم پردازش کنید.
اگر NormalizationOptions در فراداده تنظیم کنید ، TensorFlow Lite Task Library می تواند نرمال سازی را برای شما انجام دهد. پردازش کوانتیزاسیون و کوانتیزاسیون همیشه کپسوله شده است.
مثال ها
میتوانید نمونههایی در مورد نحوه پر کردن ابرداده برای انواع مختلف مدلها در اینجا بیابید:
طبقه بندی تصویر
اسکریپت را از اینجا دانلود کنید، که متادیتا را در mobilenet_v1_0.75_160_quantized.tflite پر می کند. اسکریپت را به این صورت اجرا کنید:
python ./metadata_writer_for_image_classifier.py \
--model_file=./model_without_metadata/mobilenet_v1_0.75_160_quantized.tflite \
--label_file=./model_without_metadata/labels.txt \
--export_directory=model_with_metadata
برای پر کردن ابرداده برای سایر مدلهای طبقهبندی تصویر، مشخصات مدل را مانند این به اسکریپت اضافه کنید. بقیه این راهنما برخی از بخشهای کلیدی را در مثال طبقهبندی تصویر برجسته میکند تا عناصر کلیدی را نشان دهد.
شیرجه عمیق به مثال طبقه بندی تصویر
اطلاعات مدل
فراداده با ایجاد یک اطلاعات مدل جدید شروع می شود:
from tflite_support import flatbuffers
from tflite_support import metadata as _metadata
from tflite_support import metadata_schema_py_generated as _metadata_fb
""" ... """
"""Creates the metadata for an image classifier."""
# Creates model info.
model_meta = _metadata_fb.ModelMetadataT()
model_meta.name = "MobileNetV1 image classifier"
model_meta.description = ("Identify the most prominent object in the "
"image from a set of 1,001 categories such as "
"trees, animals, food, vehicles, person etc.")
model_meta.version = "v1"
model_meta.author = "TensorFlow"
model_meta.license = ("Apache License. Version 2.0 "
"http://www.apache.org/licenses/LICENSE-2.0.")
اطلاعات ورودی/خروجی
این بخش به شما نشان می دهد که چگونه امضای ورودی و خروجی مدل خود را توصیف کنید. این ابرداده ممکن است توسط تولیدکنندگان کد خودکار برای ایجاد کدهای پیش و پس از پردازش استفاده شود. برای ایجاد اطلاعات ورودی یا خروجی در مورد یک تانسور:
# Creates input info.
input_meta = _metadata_fb.TensorMetadataT()
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
ورودی تصویر
تصویر یک نوع ورودی رایج برای یادگیری ماشین است. ابرداده TensorFlow Lite از اطلاعاتی مانند فضای رنگی و اطلاعات پیش پردازش مانند عادی سازی پشتیبانی می کند. ابعاد تصویر نیازی به مشخصات دستی ندارد زیرا قبلاً توسط شکل تانسور ورودی ارائه شده است و می توان به طور خودکار استنباط کرد.
input_meta.name = "image"
input_meta.description = (
"Input image to be classified. The expected image is {0} x {1}, with "
"three channels (red, blue, and green) per pixel. Each value in the "
"tensor is a single byte between 0 and 255.".format(160, 160))
input_meta.content = _metadata_fb.ContentT()
input_meta.content.contentProperties = _metadata_fb.ImagePropertiesT()
input_meta.content.contentProperties.colorSpace = (
_metadata_fb.ColorSpaceType.RGB)
input_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.ImageProperties)
input_normalization = _metadata_fb.ProcessUnitT()
input_normalization.optionsType = (
_metadata_fb.ProcessUnitOptions.NormalizationOptions)
input_normalization.options = _metadata_fb.NormalizationOptionsT()
input_normalization.options.mean = [127.5]
input_normalization.options.std = [127.5]
input_meta.processUnits = [input_normalization]
input_stats = _metadata_fb.StatsT()
input_stats.max = [255]
input_stats.min = [0]
input_meta.stats = input_stats
خروجی برچسب
برچسب را می توان از طریق یک فایل مرتبط با استفاده از TENSOR_AXIS_LABELS به یک تانسور خروجی نگاشت.
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
output_meta.name = "probability"
output_meta.description = "Probabilities of the 1001 labels respectively."
output_meta.content = _metadata_fb.ContentT()
output_meta.content.content_properties = _metadata_fb.FeaturePropertiesT()
output_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.FeatureProperties)
output_stats = _metadata_fb.StatsT()
output_stats.max = [1.0]
output_stats.min = [0.0]
output_meta.stats = output_stats
label_file = _metadata_fb.AssociatedFileT()
label_file.name = os.path.basename("your_path_to_label_file")
label_file.description = "Labels for objects that the model can recognize."
label_file.type = _metadata_fb.AssociatedFileType.TENSOR_AXIS_LABELS
output_meta.associatedFiles = [label_file]
فراداده های Flatbuffer را ایجاد کنید
کد زیر اطلاعات مدل را با اطلاعات ورودی و خروجی ترکیب می کند:
# Creates subgraph info.
subgraph = _metadata_fb.SubGraphMetadataT()
subgraph.inputTensorMetadata = [input_meta]
subgraph.outputTensorMetadata = [output_meta]
model_meta.subgraphMetadata = [subgraph]
b = flatbuffers.Builder(0)
b.Finish(
model_meta.Pack(b),
_metadata.MetadataPopulator.METADATA_FILE_IDENTIFIER)
metadata_buf = b.Output()
متادیتا و فایل های مرتبط را در مدل بسته بندی کنید
هنگامی که Metadata Flatbuffer ایجاد می شود، ابرداده و فایل label از طریق روش populate در فایل TFLite نوشته می شوند:
populator = _metadata.MetadataPopulator.with_model_file(model_file)
populator.load_metadata_buffer(metadata_buf)
populator.load_associated_files(["your_path_to_label_file"])
populator.populate()
می توانید هر تعداد فایل مرتبط را که می خواهید از طریق load_associated_files در مدل بسته بندی کنید. با این حال، لازم است حداقل آن دسته از فایلهای مستند شده در ابرداده را بسته بندی کنید. در این مثال، بسته بندی فایل برچسب اجباری است.
متادیتا را تجسم کنید
میتوانید از Netron برای تجسم ابردادههای خود استفاده کنید، یا میتوانید با استفاده از MetadataDisplayer ابردادهها را از یک مدل TensorFlow Lite در قالب json بخوانید:
displayer = _metadata.MetadataDisplayer.with_model_file(export_model_path)
export_json_file = os.path.join(FLAGS.export_directory,
os.path.splitext(model_basename)[0] + ".json")
json_file = displayer.get_metadata_json()
# Optional: write out the metadata as a json file
with open(export_json_file, "w") as f:
f.write(json_file)
Android Studio همچنین از نمایش ابرداده از طریق ویژگی Android Studio ML Binding پشتیبانی می کند.
نسخه سازی فراداده
طرحواره ابرداده هم با شماره نسخه سازی معنایی، که تغییرات فایل طرحواره را ردیابی می کند و هم با شناسایی فایل Flatbuffers، که سازگاری نسخه واقعی را نشان می دهد، نسخه بندی می شود.
شماره نسخه سازی معنایی
طرحواره ابرداده با شماره نسخهسازی معنایی مانند MAJOR.MINOR.PATCH نسخهبندی میشود. تغییرات طرحواره را طبق قوانین اینجا ردیابی می کند. تاریخچه فیلدهای اضافه شده پس از نسخه 1.0.0 را مشاهده کنید.
شناسایی فایل Flatbuffers
نسخهسازی معنایی در صورت پیروی از قوانین، سازگاری را تضمین میکند، اما به معنای ناسازگاری واقعی نیست. وقتی شماره MAJOR را بالا میبرید، لزوماً به این معنی نیست که سازگاری با عقبتر شکسته شده است. بنابراین، ما از شناسه فایل Flatbuffers ، file_identifier ، برای نشان دادن سازگاری واقعی طرحواره ابرداده استفاده می کنیم. شناسه فایل دقیقا 4 کاراکتر است. بر روی یک طرحواره ابرداده خاص ثابت است و توسط کاربران تغییر نمی کند. اگر به دلایلی باید سازگاری عقبافتاده طرحواره ابرداده قطع شود، file_identifier به عنوان مثال از "M001" به "M002" افزایش مییابد. انتظار می رود File_identifier بسیار کمتر از metadata_version تغییر کند.
حداقل نسخه تجزیه کننده فراداده لازم
حداقل نسخه تجزیه کننده فراداده ضروری حداقل نسخه تجزیه کننده فراداده (کد تولید شده توسط Flatbuffers) است که می تواند بافرهای مسطح فراداده را به طور کامل بخواند. این نسخه عملاً بزرگترین شماره نسخه در بین نسخههای تمام فیلدهای پر شده و کوچکترین نسخه سازگار است که با شناسه فایل نشان داده شده است. حداقل نسخه تجزیه کننده فراداده ضروری به طور خودکار توسط MetadataPopulator پر می شود زمانی که ابرداده در یک مدل TFLite پر می شود. برای اطلاعات بیشتر در مورد نحوه استفاده از حداقل نسخه تجزیه کننده فراداده ضروری، به استخراج کننده فراداده مراجعه کنید.
فراداده های مدل ها را بخوانید
کتابخانه Metadata Extractor ابزاری مناسب برای خواندن فراداده و فایل های مرتبط از یک مدل در پلتفرم های مختلف است ( نسخه جاوا و نسخه C++ را ببینید). شما می توانید ابزار استخراج ابرداده خود را به زبان های دیگر با استفاده از کتابخانه Flatbuffers بسازید.
فراداده را در جاوا بخوانید
برای استفاده از کتابخانه Metadata Extractor در برنامه Android خود، توصیه می کنیم از TensorFlow Lite Metadata AAR میزبانی شده در MavenCentral استفاده کنید. این شامل کلاس MetadataExtractor ، و همچنین اتصالات جاوا FlatBuffers برای طرحواره ابرداده و طرح مدل است.
شما می توانید این را در وابستگی های build.gradle خود به صورت زیر مشخص کنید:
dependencies {
implementation 'org.tensorflow:tensorflow-lite-metadata:0.1.0'
}
برای استفاده از عکسهای فوری شبانه، مطمئن شوید که مخزن عکس فوری Sonatype را اضافه کردهاید.
شما می توانید یک شی MetadataExtractor را با یک ByteBuffer که به مدل اشاره می کند مقداردهی اولیه کنید:
public MetadataExtractor(ByteBuffer buffer);
ByteBuffer باید در تمام طول عمر شی MetadataExtractor بدون تغییر باقی بماند. اگر شناسه فایل Flatbuffers فراداده مدل با تجزیه کننده فراداده مطابقت نداشته باشد، ممکن است مقداردهی اولیه ناموفق باشد. برای اطلاعات بیشتر به نسخه سازی ابرداده مراجعه کنید.
با استفاده از شناسههای فایل منطبق، استخراجکننده ابرداده به دلیل سازوکار سازگاری پیشرو و عقب Flatbuffers، ابردادههای تولید شده از تمام طرحوارههای گذشته و آینده را با موفقیت میخواند. با این حال، فیلدهای طرحوارههای آینده را نمیتوان توسط استخراجکنندههای ابرداده قدیمی استخراج کرد. حداقل نسخه تجزیه کننده ضروری فراداده، حداقل نسخه تجزیه کننده فراداده را نشان می دهد که می تواند Metadata Flatbuffers را به طور کامل بخواند. می توانید از روش زیر برای بررسی اینکه آیا حداقل شرط نسخه تجزیه کننده لازم برآورده شده است استفاده کنید:
public final boolean isMinimumParserVersionSatisfied();
عبور در یک مدل بدون ابرداده مجاز است. با این حال، فراخوانی روشهایی که از ابرداده خوانده میشوند باعث خطاهای زمان اجرا میشود. با فراخوانی متد hasMetadata میتوانید بررسی کنید که آیا یک مدل دارای ابرداده است:
public boolean hasMetadata();
MetadataExtractor توابع مناسبی را برای شما فراهم می کند تا متادیتای تانسورهای ورودی/خروجی را دریافت کنید. مثلا،
public int getInputTensorCount();
public TensorMetadata getInputTensorMetadata(int inputIndex);
public QuantizationParams getInputTensorQuantizationParams(int inputIndex);
public int[] getInputTensorShape(int inputIndex);
public int getoutputTensorCount();
public TensorMetadata getoutputTensorMetadata(int inputIndex);
public QuantizationParams getoutputTensorQuantizationParams(int inputIndex);
public int[] getoutputTensorShape(int inputIndex);
اگرچه طرح مدل TensorFlow Lite از چندین زیرگراف پشتیبانی می کند، مترجم TFLite در حال حاضر تنها از یک زیرگراف پشتیبانی می کند. بنابراین، MetadataExtractor شاخص زیرگراف را به عنوان آرگومان ورودی در روش های خود حذف می کند.
فایل های مرتبط را از مدل ها بخوانید
مدل TensorFlow Lite با فراداده و فایلهای مرتبط اساساً یک فایل فشرده است که میتوان آن را با ابزارهای فشرده معمولی برای دریافت فایلهای مرتبط باز کرد. به عنوان مثال، می توانید mobilenet_v1_0.75_160_quantized را از حالت فشرده خارج کرده و فایل برچسب موجود در مدل را به صورت زیر استخراج کنید:
$ unzip mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
Archive: mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
extracting: labels.txt
همچنین می توانید فایل های مرتبط را از طریق کتابخانه Metadata Extractor بخوانید.
در جاوا، نام فایل را به متد MetadataExtractor.getAssociatedFile منتقل کنید:
public InputStream getAssociatedFile(String fileName);
به طور مشابه، در C++، این کار را می توان با روش ModelMetadataExtractor::GetAssociatedFile انجام داد:
tflite::support::StatusOr<absl::string_view> GetAssociatedFile(
const std::string& filename) const;