
Strumenti di riferimento
Gli strumenti di benchmark TensorFlow Lite attualmente misurano e calcolano statistiche per i seguenti importanti parametri di prestazione:
- Tempo di inizializzazione
- Tempo di inferenza dello stato di riscaldamento
- Tempo di inferenza di stato stazionario
- Utilizzo della memoria durante il tempo di inizializzazione
- Utilizzo complessivo della memoria
Gli strumenti di benchmark sono disponibili come app di benchmark per Android e iOS e come file binari nativi da riga di comando e condividono tutti la stessa logica di misurazione delle prestazioni di base. Tieni presente che le opzioni disponibili e i formati di output sono leggermente diversi a causa delle differenze nell'ambiente di runtime.
Applicazione di riferimento per Android
Esistono due opzioni per utilizzare lo strumento di benchmark con Android. Uno è un binario di benchmark nativo e un altro è un'app di benchmark Android, un indicatore migliore del funzionamento del modello nell'app. In ogni caso, i numeri dello strumento di benchmark saranno comunque leggermente diversi rispetto a quando si esegue l'inferenza con il modello nell'app reale.
Questa app benchmark Android non ha interfaccia utente. Installalo ed eseguilo utilizzando il comando adb e recupera i risultati utilizzando il comando adb logcat .
Scarica o crea l'app
Scarica le app benchmark Android predefinite notturne utilizzando i collegamenti seguenti:
Per quanto riguarda le app benchmark Android che supportano le operazioni TF tramite Flex delegate , utilizza i collegamenti seguenti:
Puoi anche creare l'app dal codice sorgente seguendo queste istruzioni .
Preparare un punto di riferimento
Prima di eseguire l'app benchmark, installa l'app e invia il file del modello al dispositivo come segue:
adb install -r -d -g android_aarch64_benchmark_model.apk
adb push your_model.tflite /data/local/tmp
Esegui il benchmark
adb shell am start -S \
-n org.tensorflow.lite.benchmark/.BenchmarkModelActivity \
--es args '"--graph=/data/local/tmp/your_model.tflite \
--num_threads=4"'
graph è un parametro obbligatorio.
-
graph:string
Il percorso del file del modello TFLite.
È possibile specificare più parametri facoltativi per l'esecuzione del benchmark.
-
num_threads:int(predefinito=1)
Il numero di thread da utilizzare per eseguire l'interprete TFLite. -
use_gpu:bool(default=false)
Utilizza il delegato GPU . -
use_nnapi:bool(predefinito=falso)
Utilizza il delegato NNAPI . -
use_xnnpack:bool(default=false)
Utilizza il delegato XNNPACK . -
use_hexagon:bool(default=false)
Utilizza il delegato Hexagon .
A seconda del dispositivo in uso, alcune di queste opzioni potrebbero non essere disponibili o non avere alcun effetto. Fai riferimento ai parametri per ulteriori parametri prestazionali che potresti eseguire con l'app benchmark.
Visualizza i risultati utilizzando il comando logcat :
adb logcat | grep "Inference timings"
I risultati del benchmark sono riportati come:
... tflite : Inference timings in us: Init: 5685, First inference: 18535, Warmup (avg): 14462.3, Inference (avg): 14575.2
Binario benchmark nativo
Lo strumento di benchmark viene fornito anche come benchmark_model binario nativo. Puoi eseguire questo strumento da una riga di comando della shell su Linux, Mac, dispositivi incorporati e dispositivi Android.
Scarica o crea il binario
Scarica i file binari nativi precostruiti della riga di comando notturna seguendo i collegamenti seguenti:
Per quanto riguarda i file binari precostruiti notturni che supportano le operazioni TF tramite Flex delegate , utilizzare i collegamenti seguenti:
Per eseguire il benchmark con il delegato TensorFlow Lite Hexagon , abbiamo anche precostruito i file libhexagon_interface.so richiesti (vedi qui per i dettagli su questo file). Dopo aver scaricato il file della piattaforma corrispondente dai collegamenti seguenti, rinominare il file in libhexagon_interface.so .
Puoi anche creare il file binario del benchmark nativo dal sorgente sul tuo computer.
bazel build -c opt //tensorflow/lite/tools/benchmark:benchmark_model
Per creare con la toolchain NDK di Android, devi prima configurare l'ambiente di compilazione seguendo questa guida oppure utilizzare l'immagine docker come descritto in questa guida .
bazel build -c opt --config=android_arm64 \
//tensorflow/lite/tools/benchmark:benchmark_model
Esegui il benchmark
Per eseguire i benchmark sul tuo computer, esegui il file binario dalla shell.
path/to/downloaded_or_built/benchmark_model \
--graph=your_model.tflite \
--num_threads=4
È possibile utilizzare lo stesso set di parametri menzionato sopra con il file binario nativo della riga di comando.
Ops modello di profilazione
Il binario del modello benchmark consente inoltre di profilare le operazioni del modello e ottenere i tempi di esecuzione di ciascun operatore. Per fare ciò, passa il flag --enable_op_profiling=true a benchmark_model durante l'invocazione. I dettagli sono spiegati qui .
Binario benchmark nativo per più opzioni di prestazioni in un'unica esecuzione
Viene inoltre fornito un pratico e semplice codice binario C++ per confrontare più opzioni di prestazioni in un'unica esecuzione. Questo binario è costruito sulla base dello strumento di benchmark sopra menzionato che può confrontare solo una singola opzione di prestazione alla volta. Condividono lo stesso processo di creazione/installazione/esecuzione, ma il nome di destinazione BUILD di questo binario è benchmark_model_performance_options e richiede alcuni parametri aggiuntivi. Un parametro importante per questo binario è:
perf_options_list : string (default='all')
Un elenco separato da virgole di opzioni di prestazioni TFLite da confrontare.
Puoi ottenere file binari precompilati notturni per questo strumento come elencato di seguito:
Applicazione di riferimento per iOS
Per eseguire benchmark su un dispositivo iOS, è necessario creare l'app dal codice sorgente . Inserisci il file del modello TensorFlow Lite nella directory benchmark_data dell'albero dei sorgenti e modifica il file benchmark_params.json . Questi file vengono inseriti nell'app e l'app legge i dati dalla directory. Visita l' app benchmark iOS per istruzioni dettagliate.
Benchmark delle prestazioni per modelli noti
Questa sezione elenca i benchmark delle prestazioni di TensorFlow Lite durante l'esecuzione di modelli noti su alcuni dispositivi Android e iOS.
Benchmark delle prestazioni di Android
Questi numeri di benchmark delle prestazioni sono stati generati con il file binario di benchmark nativo .
Per i benchmark Android, l'affinità della CPU è impostata per utilizzare big core sul dispositivo per ridurre la varianza (vedi dettagli ).
Si presuppone che i modelli siano stati scaricati e decompressi nella directory /data/local/tmp/tflite_models . Il binario del benchmark viene creato utilizzando queste istruzioni e si presuppone che si trovi nella directory /data/local/tmp .
Per eseguire il benchmark:
adb shell /data/local/tmp/benchmark_model \
--num_threads=4 \
--graph=/data/local/tmp/tflite_models/${GRAPH} \
--warmup_runs=1 \
--num_runs=50
Per eseguire con il delegato nnapi, impostare --use_nnapi=true . Per eseguire con il delegato GPU, impostare --use_gpu=true .
I valori prestazionali riportati di seguito sono misurati su Android 10.
| Nome del modello | Dispositivo | CPU, 4 thread | GPU | NNAPI |
|---|---|---|---|---|
| Mobilenet_1.0_224(flottante) | Pixel 3 | 23,9 ms | 6,45 ms | 13,8 ms |
| Pixel 4 | 14,0 ms | 9,0 ms | 14,8 ms | |
| Mobilenet_1.0_224 (quantità) | Pixel 3 | 13,4 ms | --- | 6,0 ms |
| Pixel 4 | 5,0 ms | --- | 3,2 ms | |
| NASNet mobile | Pixel 3 | 56 ms | --- | 102 ms |
| Pixel 4 | 34,5 ms | --- | 99,0 ms | |
| SqueezeNet | Pixel 3 | 35,8 ms | 9,5 ms | 18,5 ms |
| Pixel 4 | 23,9 ms | 11,1 ms | 19,0 ms | |
| Inception_ResNet_V2 | Pixel 3 | 422 ms | 99,8 ms | 201 ms |
| Pixel 4 | 272,6 ms | 87,2 ms | 171,1 ms | |
| Inception_V4 | Pixel 3 | 486 ms | 93 ms | 292 ms |
| Pixel 4 | 324,1 ms | 97,6 ms | 186,9 ms |
Benchmark delle prestazioni di iOS
Questi numeri di benchmark delle prestazioni sono stati generati con l' app benchmark iOS .
Per eseguire i benchmark iOS, l'app benchmark è stata modificata per includere il modello appropriato e benchmark_params.json è stato modificato per impostare num_threads su 2. Per utilizzare il delegato GPU, le opzioni "use_gpu" : "1" e "gpu_wait_type" : "aggressive" sono state aggiunto anche a benchmark_params.json .
| Nome del modello | Dispositivo | CPU, 2 thread | GPU |
|---|---|---|---|
| Mobilenet_1.0_224(flottante) | iPhoneXS | 14,8 ms | 3,4 ms |
| Mobilenet_1.0_224 (quantità) | iPhoneXS | 11 ms | --- |
| NASNet mobile | iPhoneXS | 30,4 ms | --- |
| SqueezeNet | iPhoneXS | 21,1 ms | 15,5 ms |
| Inception_ResNet_V2 | iPhoneXS | 261,1 ms | 45,7 ms |
| Inception_V4 | iPhoneXS | 309 ms | 54,4 ms |
Traccia interni di TensorFlow Lite
Traccia gli interni di TensorFlow Lite in Android
Gli eventi interni dell'interprete TensorFlow Lite di un'app Android possono essere acquisiti dagli strumenti di tracciamento Android . Sono gli stessi eventi dell'API Android Trace , quindi gli eventi acquisiti dal codice Java/Kotlin vengono visualizzati insieme agli eventi interni di TensorFlow Lite.
Alcuni esempi di eventi sono:
- Invocazione dell'operatore
- Modifica del grafico da parte del delegato
- Allocazione del tensore
Tra le diverse opzioni per acquisire tracce, questa guida copre Android Studio CPU Profiler e l'app System Tracing. Fare riferimento allo strumento da riga di comando Perfetto o allo strumento da riga di comando Systrace per altre opzioni.
Aggiunta di eventi di traccia nel codice Java
Questo è uno snippet di codice dall'app di esempio Image Classification . L'interprete TensorFlow Lite viene eseguito nella sezione recognizeImage/runInference . Questo passaggio è facoltativo ma è utile per aiutare a notare dove viene effettuata la chiamata di inferenza.
Trace.beginSection("recognizeImage");
...
// Runs the inference call.
Trace.beginSection("runInference");
tflite.run(inputImageBuffer.getBuffer(), outputProbabilityBuffer.getBuffer().rewind());
Trace.endSection();
...
Trace.endSection();
Abilita la traccia TensorFlow Lite
Per abilitare la traccia TensorFlow Lite, imposta la proprietà del sistema Android debug.tflite.trace su 1 prima di avviare l'app Android.
adb shell setprop debug.tflite.trace 1
Se questa proprietà è stata impostata quando viene inizializzato l'interprete TensorFlow Lite, verranno tracciati gli eventi chiave (ad esempio, l'invocazione dell'operatore) dall'interprete.
Dopo aver acquisito tutte le tracce, disabilita la traccia impostando il valore della proprietà su 0.
adb shell setprop debug.tflite.trace 0
Profilo CPU di Android Studio
Acquisisci tracce con Android Studio CPU Profiler seguendo i passaggi seguenti:
Seleziona Esegui > App profilo dai menu in alto.
Fai clic in un punto qualsiasi della sequenza temporale della CPU quando viene visualizzata la finestra Profiler.
Seleziona "Traccia chiamate di sistema" tra le modalità di profilazione della CPU.
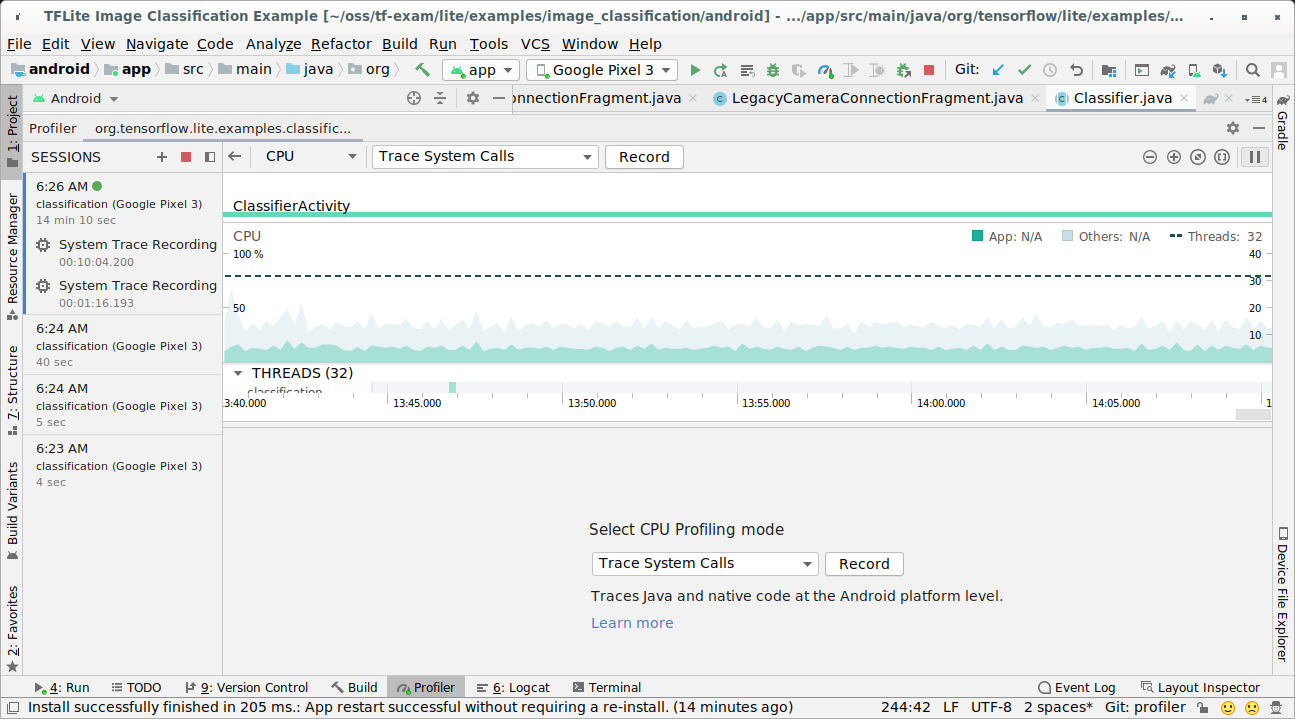
Premere il pulsante "Registra".
Premere il pulsante "Stop".
Esaminare il risultato della traccia.
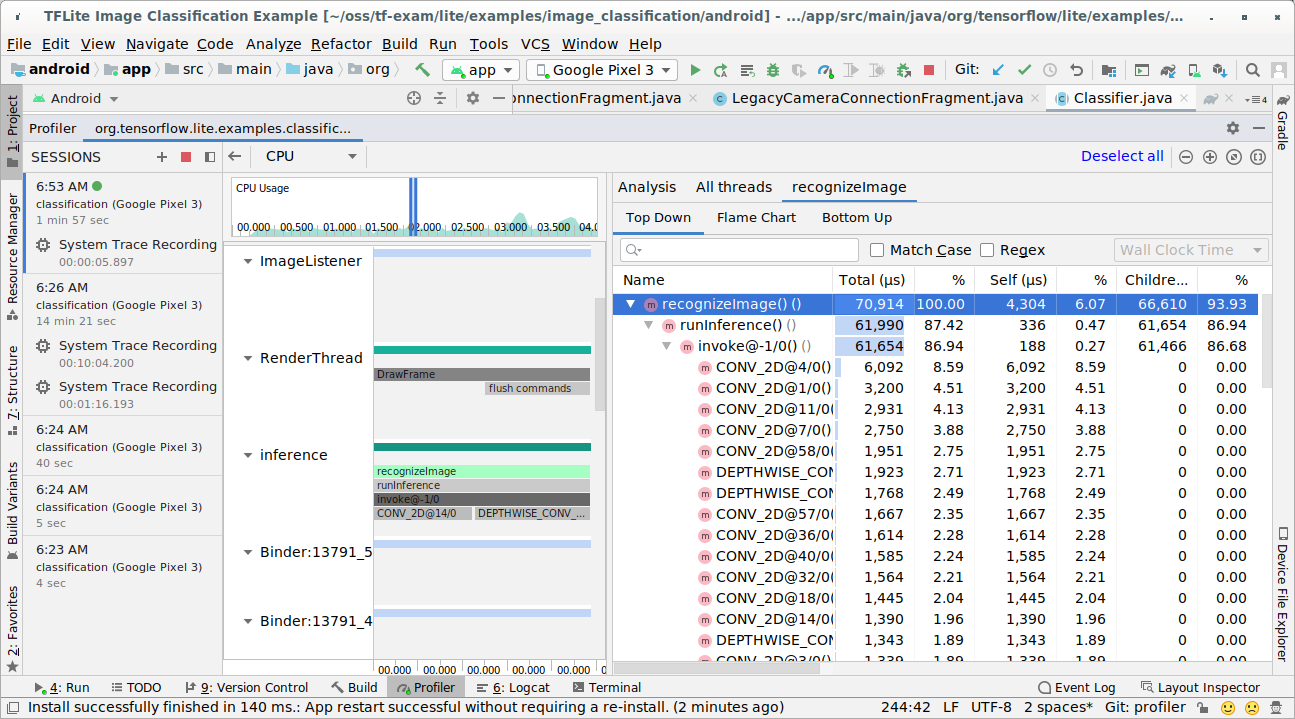
In questo esempio puoi vedere la gerarchia degli eventi in un thread e le statistiche per ogni tempo dell'operatore e anche vedere il flusso di dati dell'intera app tra i thread.
Applicazione di tracciamento del sistema
Acquisisci tracce senza Android Studio seguendo i passaggi dettagliati nell'app System Tracing .
In questo esempio, gli stessi eventi TFLite sono stati acquisiti e salvati nel formato Perfetto o Systrace a seconda della versione del dispositivo Android. I file di traccia acquisiti possono essere aperti nell'interfaccia utente di Perfetto .
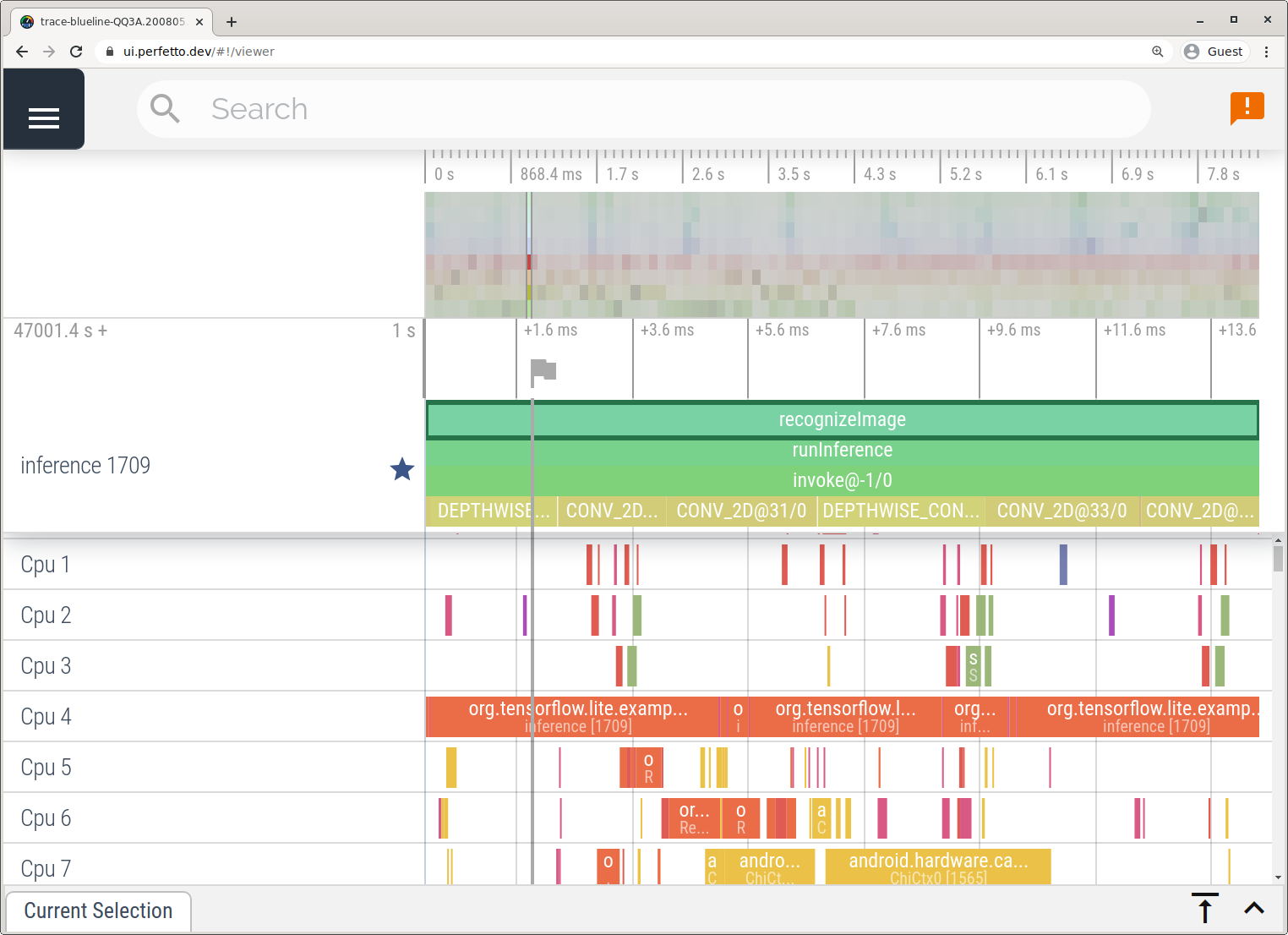
Traccia gli interni di TensorFlow Lite in iOS
Gli eventi interni dell'interprete TensorFlow Lite di un'app iOS possono essere acquisiti dallo strumento Instruments incluso con Xcode. Sono gli eventi di segnalazione iOS, quindi gli eventi catturati dal codice Swift/Objective-C vengono visualizzati insieme agli eventi interni di TensorFlow Lite.
Alcuni esempi di eventi sono:
- Invocazione dell'operatore
- Modifica del grafico da parte del delegato
- Allocazione del tensore
Abilita la traccia TensorFlow Lite
Imposta la variabile di ambiente debug.tflite.trace seguendo i passaggi seguenti:
Seleziona Prodotto > Schema > Modifica schema... dai menu in alto di Xcode.
Fai clic su "Profilo" nel riquadro di sinistra.
Deseleziona la casella di controllo "Utilizza gli argomenti dell'azione Esegui e le variabili di ambiente".
Aggiungi
debug.tflite.tracenella sezione "Variabili d'ambiente".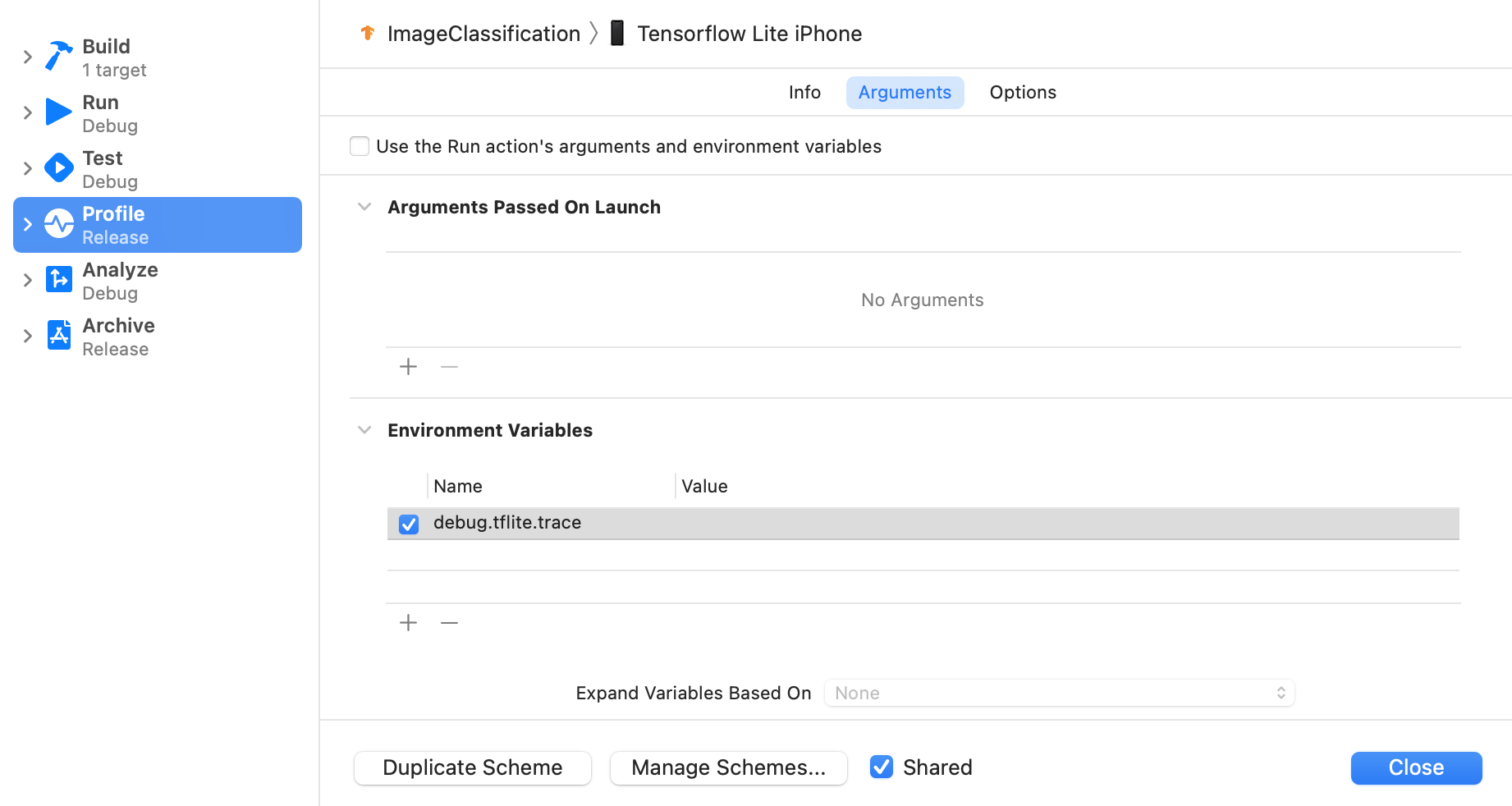
Se desideri escludere gli eventi TensorFlow Lite durante la profilazione dell'app iOS, disabilita la traccia rimuovendo la variabile di ambiente.
Strumenti XCode
Acquisisci le tracce seguendo i passaggi seguenti:
Seleziona Prodotto > Profilo dai menu principali di Xcode.
Fare clic su Registrazione tra modelli di profilazione all'avvio dello strumento Strumenti.
Premere il pulsante "Avvia".
Premere il pulsante "Stop".
Fare clic su "os_signpost" per espandere gli elementi del sottosistema di registrazione del sistema operativo.
Fare clic sul sottosistema di registrazione del sistema operativo "org.tensorflow.lite".
Esaminare il risultato della traccia.
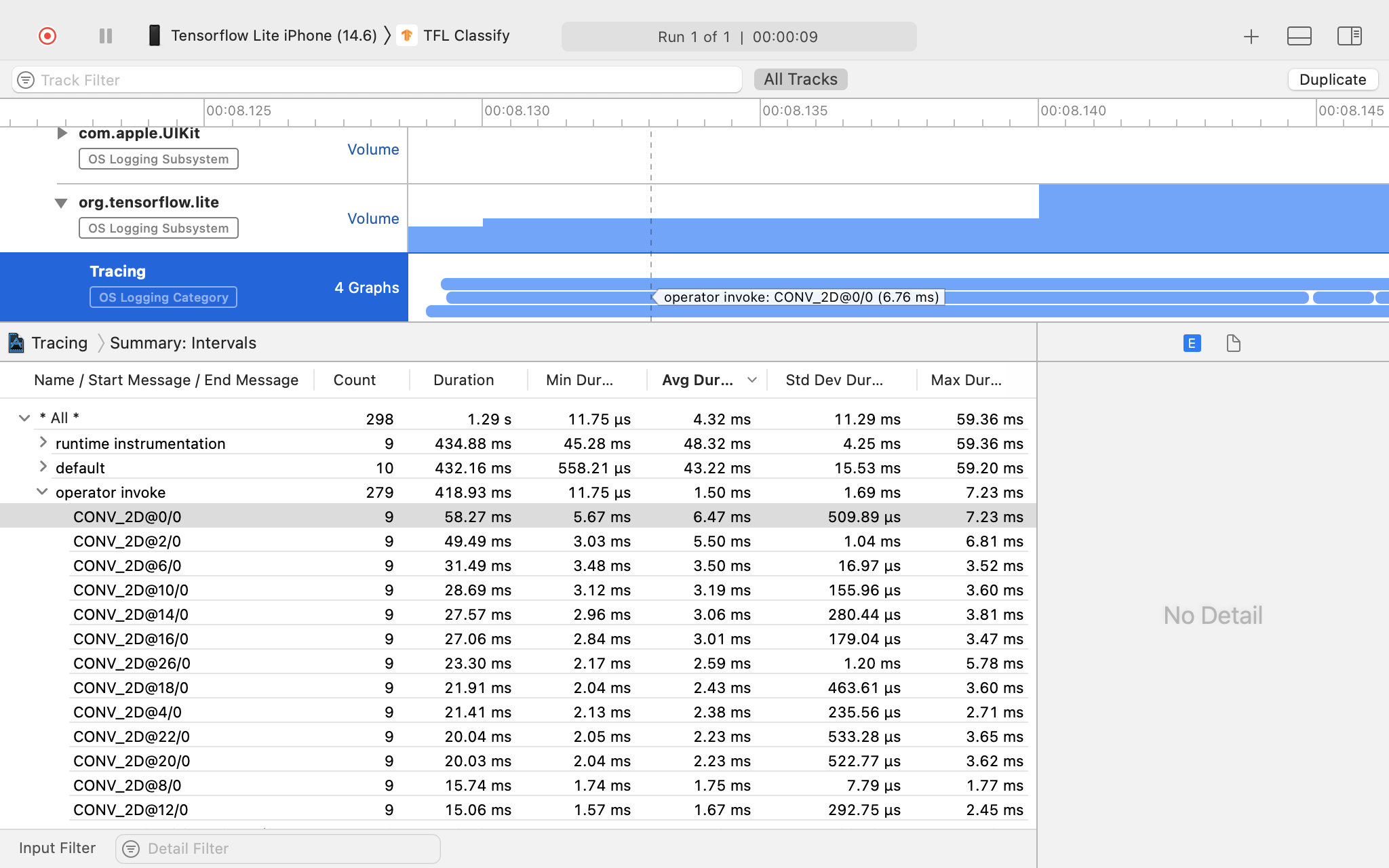
In questo esempio puoi vedere la gerarchia degli eventi e delle statistiche per ogni orario dell'operatore.
Utilizzando i dati di tracciamento
I dati di tracciamento consentono di identificare i colli di bottiglia delle prestazioni.
Ecco alcuni esempi di approfondimenti che puoi ottenere dal profiler e potenziali soluzioni per migliorare le prestazioni:
- Se il numero di core della CPU disponibili è inferiore al numero di thread di inferenza, il sovraccarico di pianificazione della CPU può portare a prestazioni inferiori alla media. Puoi riprogrammare altre attività ad uso intensivo della CPU nella tua applicazione per evitare sovrapposizioni con l'inferenza del modello o modificare il numero di thread dell'interprete.
- Se gli operatori non sono completamente delegati, alcune parti del grafico del modello vengono eseguite sulla CPU anziché sull'acceleratore hardware previsto. Puoi sostituire gli operatori non supportati con operatori supportati simili.