
Периферийные устройства часто имеют ограниченную память или вычислительную мощность. К моделям можно применять различные оптимизации, чтобы их можно было запускать в рамках этих ограничений. Кроме того, некоторые оптимизации позволяют использовать специализированное оборудование для ускорения вывода.
TensorFlow Lite и набор инструментов для оптимизации модели TensorFlow предоставляют инструменты, позволяющие минимизировать сложность оптимизирующего вывода.
Рекомендуется рассмотреть возможность оптимизации модели в процессе разработки приложения. В этом документе излагаются некоторые рекомендации по оптимизации моделей TensorFlow для развертывания на периферийном оборудовании.
Почему модели должны быть оптимизированы
Существует несколько основных способов оптимизации модели, которые могут помочь в разработке приложений.
Уменьшение размера
Некоторые формы оптимизации можно использовать для уменьшения размера модели. Меньшие модели имеют следующие преимущества:
- Меньший размер хранилища: модели меньшего размера занимают меньше места на устройствах ваших пользователей. Например, приложение Android, использующее меньшую модель, будет занимать меньше места на мобильном устройстве пользователя.
- Меньший размер загрузки: модели меньшего размера требуют меньше времени и пропускной способности для загрузки на устройства пользователей.
- Меньше использования памяти. Меньшие модели используют меньше оперативной памяти при запуске, что освобождает память для использования другими частями вашего приложения и может привести к повышению производительности и стабильности.
Во всех этих случаях квантование может уменьшить размер модели, возможно, за счет некоторой точности. Сокращение и кластеризация могут уменьшить размер модели для загрузки, упрощая ее сжимаемость.
Уменьшение задержки
Задержка — это количество времени, необходимое для выполнения одного вывода с использованием данной модели. Некоторые формы оптимизации могут уменьшить объем вычислений, необходимых для выполнения вывода с использованием модели, что приводит к снижению задержки. Задержка также может влиять на энергопотребление.
В настоящее время квантование можно использовать для уменьшения задержки за счет упрощения вычислений, происходящих во время вывода, возможно, за счет некоторой точности.
Совместимость с ускорителем
Некоторые аппаратные ускорители, такие как Edge TPU , могут выполнять логический вывод очень быстро с правильно оптимизированными моделями.
Как правило, эти типы устройств требуют, чтобы модели были квантованы определенным образом. См. документацию каждого аппаратного ускорителя, чтобы узнать больше об их требованиях.
Компромиссы
Оптимизация потенциально может привести к изменению точности модели, что необходимо учитывать в процессе разработки приложения.
Изменения точности зависят от конкретной оптимизируемой модели, и их трудно предсказать заранее. Как правило, модели, оптимизированные по размеру или задержке, теряют небольшую точность. В зависимости от вашего приложения это может повлиять или не повлиять на работу ваших пользователей. В редких случаях некоторые модели могут получить некоторую точность в результате процесса оптимизации.
Виды оптимизации
TensorFlow Lite в настоящее время поддерживает оптимизацию посредством квантования, сокращения и кластеризации.
Они являются частью набора инструментов TensorFlow Model Optimization Toolkit , который предоставляет ресурсы для методов оптимизации моделей, совместимых с TensorFlow Lite.
Квантование
Квантование работает за счет уменьшения точности чисел, используемых для представления параметров модели, которые по умолчанию представляют собой 32-битные числа с плавающей запятой. Это приводит к меньшему размеру модели и более быстрым вычислениям.
В TensorFlow Lite доступны следующие типы квантования:
| Техника | Требования к данным | Уменьшение размера | Точность | Поддерживаемое оборудование |
|---|---|---|---|---|
| Квантование float16 после обучения | Нет данных | До 50% | Незначительная потеря точности | ЦП, графический процессор |
| Квантование динамического диапазона после обучения | Нет данных | До 75% | Наименьшая потеря точности | Процессор, графический процессор (Android) |
| Целочисленное квантование после обучения | Немаркированный репрезентативный образец | До 75% | Небольшая потеря точности | ЦП, графический процессор (Android), EdgeTPU, Hexagon DSP |
| Обучение с учетом квантования | Маркированные данные обучения | До 75% | Наименьшая потеря точности | ЦП, графический процессор (Android), EdgeTPU, Hexagon DSP |
Следующее дерево решений поможет вам выбрать схемы квантования, которые вы, возможно, захотите использовать для своей модели, просто на основе ожидаемого размера и точности модели.
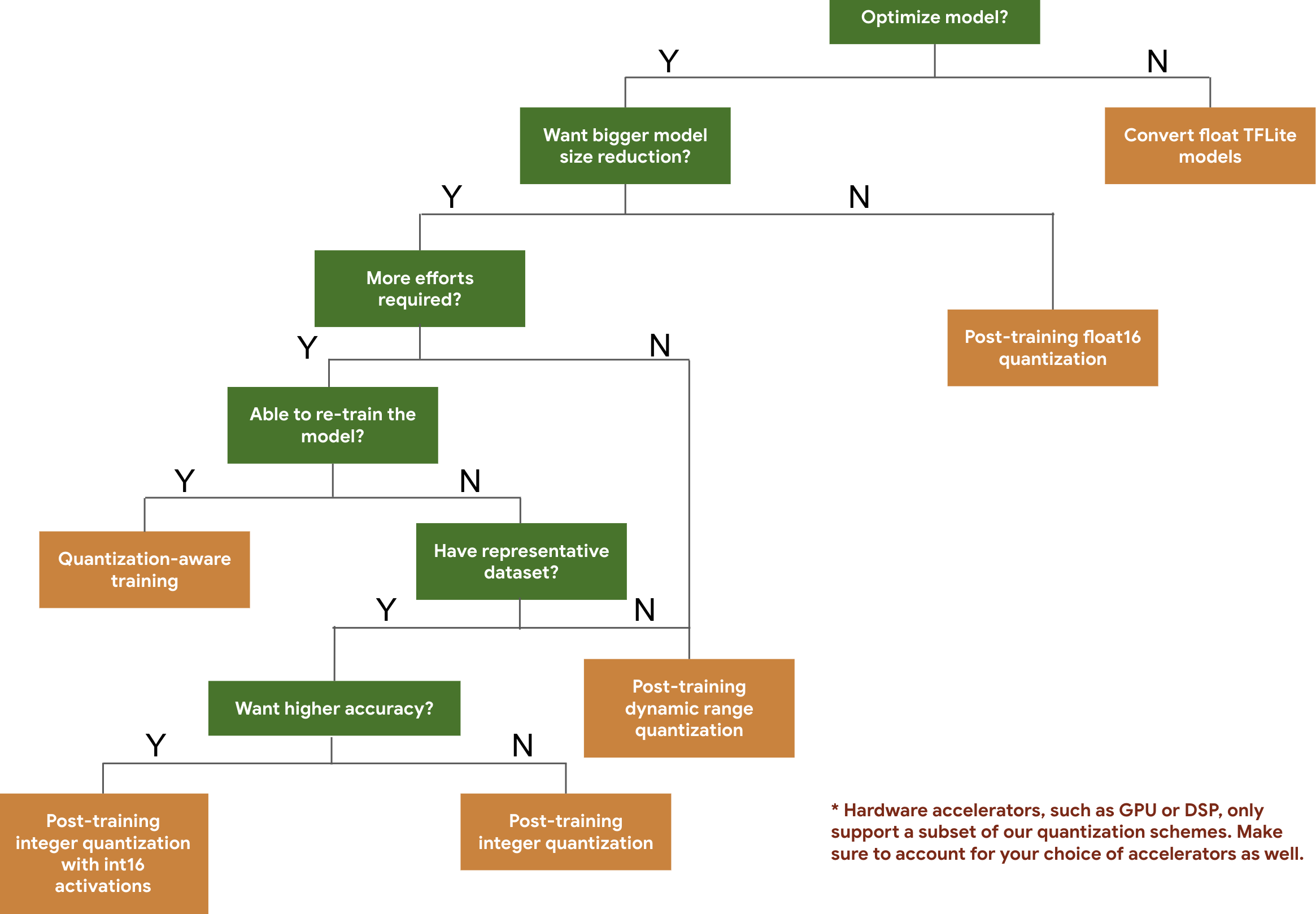
Ниже приведены результаты задержки и точности для квантования после обучения и обучения с учетом квантования на нескольких моделях. Все значения задержки измерены на устройствах Pixel 2 с использованием одного большого ядра процессора. По мере совершенствования набора инструментов будут меняться и цифры:
| Модель | Топ-1 Точность (Оригинал) | Первоклассная точность (оцифрованная после обучения) | Высшая точность (обучение с учетом квантования) | Задержка (исходная) (мс) | Задержка (квантованная после обучения) (мс) | Задержка (обучение с учетом квантования) (мс) | Размер (исходный) (МБ) | Размер (оптимизированный) (МБ) |
|---|---|---|---|---|---|---|---|---|
| Мобилнет-v1-1-224 | 0,709 | 0,657 | 0,70 | 124 | 112 | 64 | 16,9 | 4.3 |
| Мобилнет-v2-1-224 | 0,719 | 0,637 | 0,709 | 89 | 98 | 54 | 14 | 3.6 |
| Начало_v3 | 0,78 | 0,772 | 0,775 | 1130 | 845 | 543 | 95,7 | 23,9 |
| Resnet_v2_101 | 0,770 | 0,768 | Н/Д | 3973 | 2868 | Н/Д | 178,3 | 44,9 |
Полное целочисленное квантование с активациями int16 и весами int8
Квантование с активациями int16 — это схема квантования полного целого числа с активациями в int16 и весами в int8. Этот режим может повысить точность квантованной модели по сравнению со схемой целочисленного квантования, при этом как активации, так и веса в int8 сохраняют аналогичный размер модели. Рекомендуется, когда активации чувствительны к квантованию.
ПРИМЕЧАНИЕ. В настоящее время в TFLite доступны только неоптимизированные реализации эталонного ядра для этой схемы квантования, поэтому по умолчанию производительность будет ниже по сравнению с ядрами int8. Доступ ко всем преимуществам этого режима в настоящее время можно получить с помощью специализированного оборудования или специального программного обеспечения.
Ниже приведены результаты точности для некоторых моделей, в которых используется этот режим. Модель Тип показателя точности Точность (активации float32) Точность (активации int8) Точность (активации int16) Wav2letter ВЭР 6,7% 7,7% 7,2% DeepSpeech 0.5.1 (развернут) ССВ 6,13% 43,67% 6,52% ЙолоV3 карта(IOU=0,5) 0,577 0,563 0,574 МобилНетВ1 Топ-1 Точность 0,7062 0,694 0,6936 МобилНетВ2 Топ-1 Точность 0,718 0,7126 0,7137 МобильныйБерт F1 (точное совпадение) 88,81(81,23) 2.08(0) 88,73(81,15)
Обрезка
Сокращение работает путем удаления параметров из модели, которые оказывают лишь незначительное влияние на ее прогнозы. Урезанные модели имеют одинаковый размер на диске и имеют одинаковую задержку во время выполнения, но их можно сжимать более эффективно. Это делает обрезку полезным методом уменьшения размера загружаемой модели.
В будущем TensorFlow Lite обеспечит снижение задержки для обрезанных моделей.
Кластеризация
Кластеризация работает путем группировки весов каждого слоя модели в заранее определенное количество кластеров, а затем совместного использования значений центроидов для весов, принадлежащих каждому отдельному кластеру. Это уменьшает количество уникальных весовых значений в модели, тем самым снижая ее сложность.
В результате кластерные модели можно сжимать более эффективно, предоставляя преимущества при развертывании, аналогичные сокращению.
Рабочий процесс разработки
Для начала проверьте, могут ли модели в размещенных моделях работать для вашего приложения. Если нет, мы рекомендуем пользователям начать с инструмента квантования после обучения , поскольку он широко применим и не требует данных обучения.
В случаях, когда целевые показатели точности и задержки не достигаются или важна поддержка аппаратного ускорителя, обучение с учетом квантования является лучшим вариантом. Дополнительные методы оптимизации см. в наборе инструментов оптимизации модели TensorFlow .
Если вы хотите еще больше уменьшить размер модели, вы можете попробовать выполнить обрезку и/или кластеризацию перед квантованием моделей.