
Квантование после обучения — это метод преобразования, который может уменьшить размер модели, а также улучшить задержку процессора и аппаратного ускорителя с небольшим ухудшением точности модели. Вы можете квантовать уже обученную модель TensorFlow с плавающей запятой при преобразовании ее в формат TensorFlow Lite с помощью конвертера TensorFlow Lite .
Методы оптимизации
На выбор имеется несколько вариантов квантования после обучения. Вот сводная таблица вариантов и преимуществ, которые они предоставляют:
| Техника | Преимущества | Аппаратное обеспечение |
|---|---|---|
| Квантование динамического диапазона | В 4 раза меньше, в 2-3 раза быстрее | Процессор |
| Полное целочисленное квантование | В 4 раза меньше, в 3 раза быстрее | ЦП, Edge TPU, Микроконтроллеры |
| Квантование с плавающей запятой16 | В 2 раза меньше, ускорение графического процессора | ЦП, графический процессор |
Следующее дерево решений может помочь определить, какой метод квантования после обучения лучше всего подходит для вашего варианта использования:
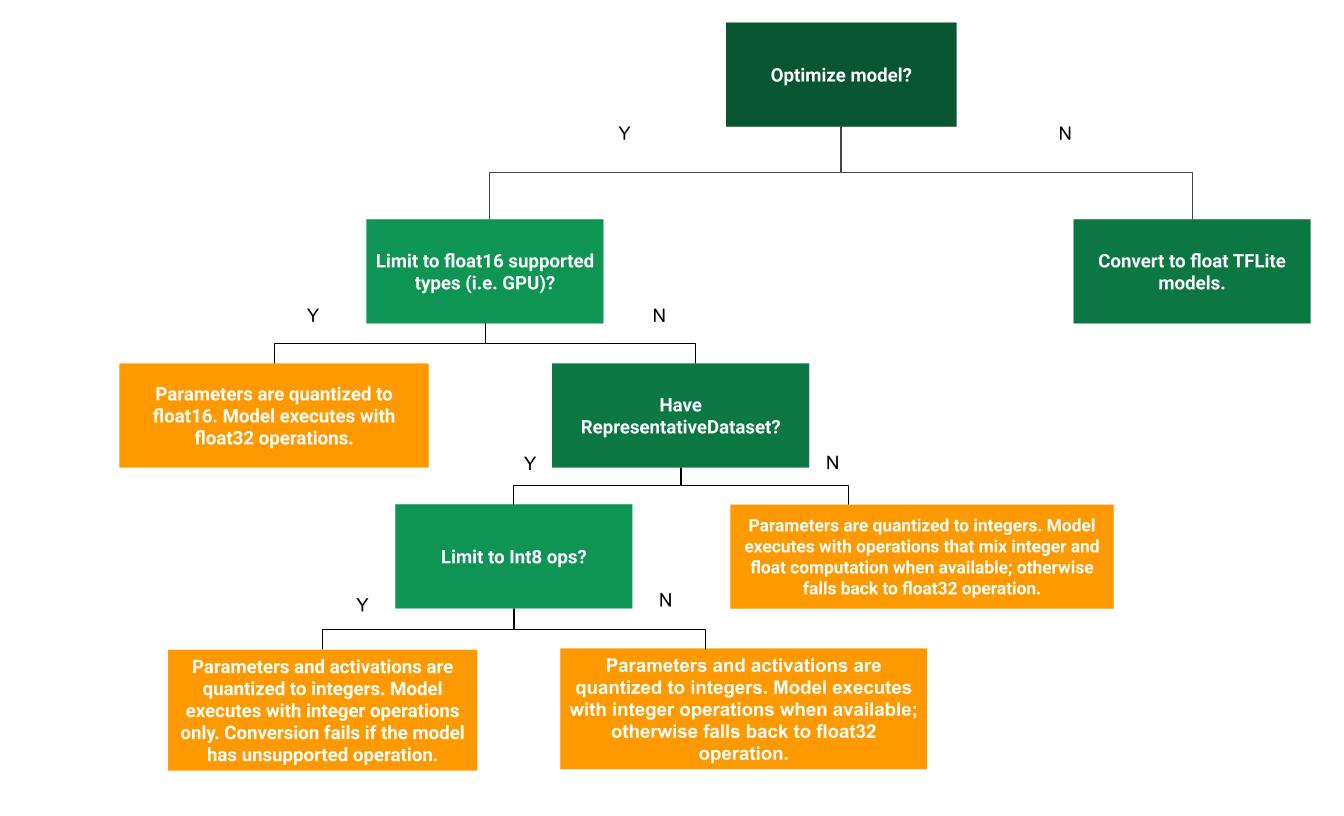
Квантование динамического диапазона
Квантование динамического диапазона является рекомендуемой отправной точкой, поскольку оно обеспечивает меньшее использование памяти и более быстрые вычисления без необходимости предоставления репрезентативного набора данных для калибровки. Этот тип квантования статически квантует только веса от плавающей запятой до целого числа во время преобразования, что обеспечивает 8-битную точность:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] tflite_quant_model = converter.convert()
Чтобы еще больше уменьшить задержку во время вывода, операторы «динамического диапазона» динамически квантуют активации на основе их диапазона до 8 бит и выполняют вычисления с 8-битными весами и активациями. Эта оптимизация обеспечивает задержки, близкие к выводам с полной фиксированной точкой. Однако выходные данные по-прежнему сохраняются с использованием плавающей запятой, поэтому увеличенная скорость операций с динамическим диапазоном меньше, чем при полных вычислениях с фиксированной запятой.
Полное целочисленное квантование
Вы можете добиться дальнейшего улучшения задержки, снижения пикового использования памяти и совместимости с аппаратными устройствами или ускорителями, работающими только с целыми числами, если убедиться, что все математические вычисления модели являются целочисленными квантованными.
Для полного целочисленного квантования необходимо откалибровать или оценить диапазон, т. е. (мин, максимум) всех тензоров с плавающей запятой в модели. В отличие от постоянных тензоров, таких как веса и смещения, переменные тензоры, такие как входные данные модели, активации (выходные данные промежуточных слоев) и выходные данные модели, не могут быть откалиброваны, если мы не проведем несколько циклов вывода. В результате конвертеру требуется репрезентативный набор данных для их калибровки. Этот набор данных может представлять собой небольшое подмножество (около 100–500 образцов) данных обучения или проверки. Обратитесь к representative_dataset() ниже.
В версии TensorFlow 2.7 вы можете указать репрезентативный набор данных с помощью подписи , как показано в следующем примере:
def representative_dataset():
for data in dataset:
yield {
"image": data.image,
"bias": data.bias,
}
Если в данной модели TensorFlow имеется более одной подписи, вы можете указать несколько наборов данных, указав ключи подписи:
def representative_dataset():
# Feed data set for the "encode" signature.
for data in encode_signature_dataset:
yield (
"encode", {
"image": data.image,
"bias": data.bias,
}
)
# Feed data set for the "decode" signature.
for data in decode_signature_dataset:
yield (
"decode", {
"image": data.image,
"hint": data.hint,
},
)
Вы можете создать репрезентативный набор данных, предоставив входной список тензоров:
def representative_dataset():
for data in tf.data.Dataset.from_tensor_slices((images)).batch(1).take(100):
yield [tf.dtypes.cast(data, tf.float32)]
Начиная с версии TensorFlow 2.7, мы рекомендуем использовать подход на основе сигнатур вместо подхода на основе списка входных тензоров, поскольку порядок входных тензоров можно легко изменить.
В целях тестирования вы можете использовать фиктивный набор данных следующим образом:
def representative_dataset():
for _ in range(100):
data = np.random.rand(1, 244, 244, 3)
yield [data.astype(np.float32)]
Целое число с резервным значением с плавающей запятой (с использованием ввода/вывода с плавающей запятой по умолчанию)
Чтобы полностью выполнить целочисленное квантование модели, но использовать операторы с плавающей запятой, когда у них нет целочисленной реализации (чтобы обеспечить плавное преобразование), выполните следующие действия:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset tflite_quant_model = converter.convert()
Только целое число
Создание только целочисленных моделей — распространенный вариант использования TensorFlow Lite для микроконтроллеров и TPU Coral Edge .
Кроме того, чтобы обеспечить совместимость с целочисленными устройствами (такими как 8-битные микроконтроллеры) и ускорителями (такими как Coral Edge TPU), вы можете обеспечить полное целочисленное квантование для всех операций, включая ввод и вывод, выполнив следующие действия:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] converter.inference_input_type = tf.int8 # or tf.uint8 converter.inference_output_type = tf.int8 # or tf.uint8 tflite_quant_model = converter.convert()
Квантование с плавающей запятой16
Вы можете уменьшить размер модели с плавающей запятой, квантовав веса до float16, стандарта IEEE для 16-битных чисел с плавающей запятой. Чтобы включить квантование весов с помощью float16, выполните следующие действия:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_types = [tf.float16] tflite_quant_model = converter.convert()
Преимущества квантования float16 заключаются в следующем:
- Это уменьшает размер модели почти вдвое (поскольку все веса становятся вдвое меньше исходного размера).
- Это вызывает минимальную потерю точности.
- Он поддерживает некоторые делегаты (например, делегат GPU), которые могут работать непосредственно с данными float16, что приводит к более быстрому выполнению, чем вычисления float32.
Недостатки квантования float16 заключаются в следующем:
- Это не уменьшает задержку так сильно, как квантование с фиксированной запятой.
- По умолчанию квантованная модель float16 «деквантует» значения весов до float32 при запуске на ЦП. (Обратите внимание, что делегат GPU не будет выполнять это деквантование, поскольку он может работать с данными float16.)
Только целое число: 16-битные активации с 8-битными весами (экспериментально)
Это экспериментальная схема квантования. Это похоже на схему «только целые числа», но активации квантуются в зависимости от их диапазона до 16 бит, веса квантуются в 8-битное целое число, а смещение квантуется в 64-битное целое число. В дальнейшем это называется квантованием 16x8.
Основное преимущество этого квантования заключается в том, что оно может значительно повысить точность, но лишь незначительно увеличить размер модели.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8] tflite_quant_model = converter.convert()
Если квантование 16x8 не поддерживается для некоторых операторов в модели, модель все равно можно квантовать, но неподдерживаемые операторы остаются в плавающем состоянии. Чтобы разрешить это, в target_spec следует добавить следующую опцию.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8, tf.lite.OpsSet.TFLITE_BUILTINS] tflite_quant_model = converter.convert()
Примеры случаев использования, в которых повышение точности, обеспечиваемое этой схемой квантования, включают:
- супер-разрешение,
- обработка аудиосигнала, такая как шумоподавление и формирование луча,
- шумоподавление изображения,
- HDR-реконструкция из одного изображения.
Недостатком такого квантования является:
- В настоящее время вывод заметно медленнее, чем 8-битное целое число, из-за отсутствия оптимизированной реализации ядра.
- В настоящее время он несовместим с существующими делегатами TFLite с аппаратным ускорением.
Учебник по этому режиму квантования можно найти здесь .
Точность модели
Поскольку веса квантуются после обучения, может произойти потеря точности, особенно для небольших сетей. Предварительно обученные полностью квантованные модели предоставляются для конкретных сетей в TensorFlow Hub . Важно проверить точность квантованной модели, чтобы убедиться, что любое ухудшение точности находится в допустимых пределах. Существуют инструменты для оценки точности модели TensorFlow Lite .
В качестве альтернативы, если падение точности слишком велико, рассмотрите возможность использования обучения с учетом квантования . Однако для этого требуются изменения во время обучения модели для добавления ложных узлов квантования, тогда как методы квантования после обучения на этой странице используют существующую предварительно обученную модель.
Представление квантованных тензоров
8-битное квантование аппроксимирует значения с плавающей запятой, используя следующую формулу.
\[real\_value = (int8\_value - zero\_point) \times scale\]
Представление состоит из двух основных частей:
Веса по осям (также известные как по каналам) или по тензорам, представленные значениями дополнения до двух int8 в диапазоне [-127, 127] с нулевой точкой, равной 0.
Тензорные активации/входы представлены значениями дополнения до двух int8 в диапазоне [-128, 127] с нулевой точкой в диапазоне [-128, 127].
Подробное описание нашей схемы квантования можно найти в нашей спецификации квантования . Поставщикам оборудования, желающим подключиться к делегатскому интерфейсу TensorFlow Lite, рекомендуется реализовать описанную там схему квантования.