
การหาปริมาณหลังการฝึกเป็นเทคนิคการแปลงที่สามารถลดขนาดโมเดลในขณะเดียวกันก็ปรับปรุงเวลาแฝงของตัวเร่ง CPU และฮาร์ดแวร์ด้วย โดยมีการลดความแม่นยำของโมเดลลงเล็กน้อย คุณสามารถวัดปริมาณโมเดล Float TensorFlow ที่ผ่านการฝึกอบรมแล้วได้เมื่อแปลงเป็นรูปแบบ TensorFlow Lite โดยใช้ TensorFlow Lite Converter
วิธีการเพิ่มประสิทธิภาพ
มีตัวเลือกการวัดปริมาณหลังการฝึกอบรมหลายตัวเลือก นี่คือตารางสรุปตัวเลือกและประโยชน์ที่ได้รับ:
| เทคนิค | ประโยชน์ | ฮาร์ดแวร์ |
|---|---|---|
| การหาปริมาณช่วงไดนามิก | เล็กลง 4 เท่า เร็วขึ้น 2x-3 เท่า | ซีพียู |
| การหาปริมาณจำนวนเต็ม | เล็กลง 4 เท่า เร็วขึ้น 3 เท่า | CPU, Edge TPU, ไมโครคอนโทรลเลอร์ |
| การหาปริมาณ Float16 | เล็กลง 2 เท่า อัตราเร่ง GPU | ซีพียู, จีพียู |
แผนผังการตัดสินใจต่อไปนี้สามารถช่วยพิจารณาว่าวิธีการวัดปริมาณหลังการฝึกอบรมแบบใดที่เหมาะกับกรณีการใช้งานของคุณมากที่สุด:
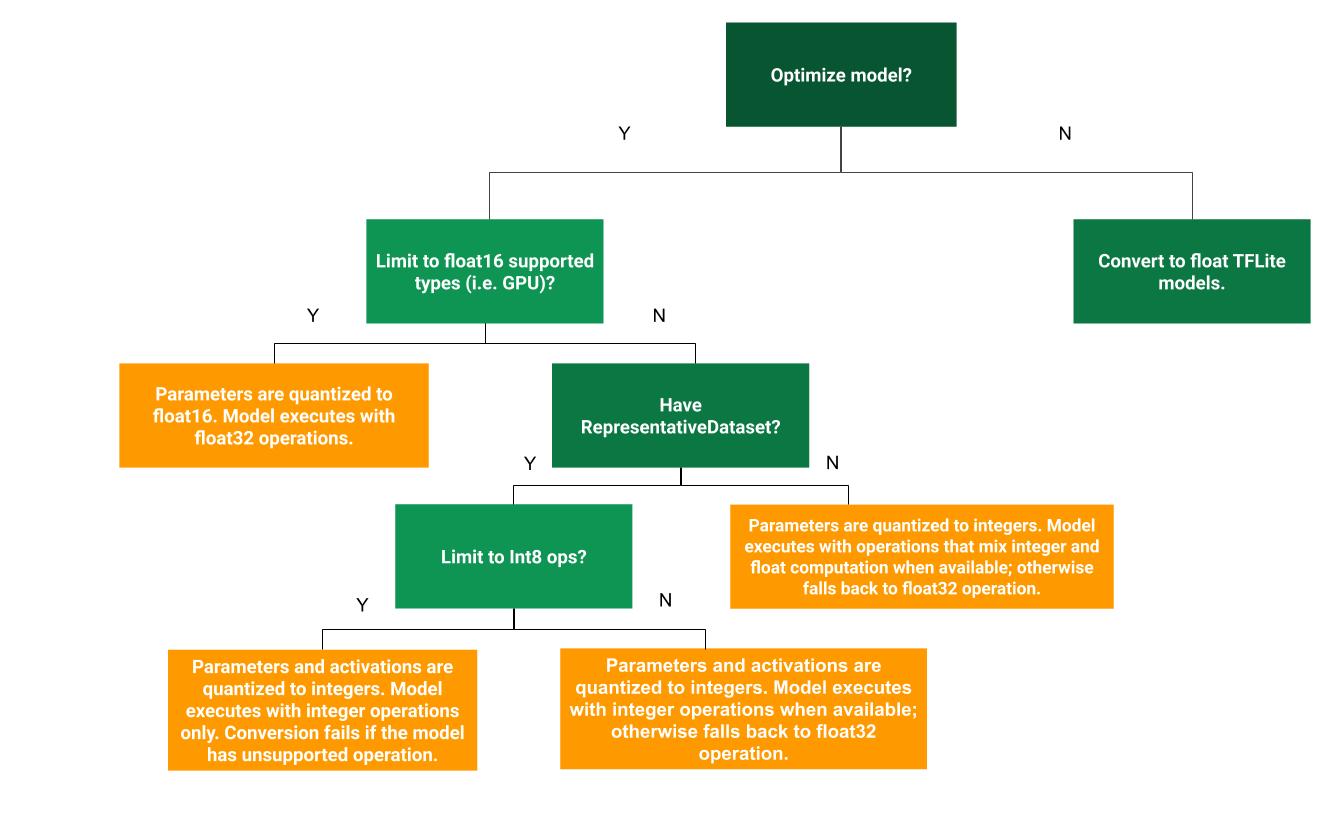
การหาปริมาณช่วงไดนามิก
การหาปริมาณช่วงไดนามิกเป็นจุดเริ่มต้นที่แนะนำ เนื่องจากช่วยลดการใช้หน่วยความจำและการคำนวณที่รวดเร็วขึ้น โดยที่คุณไม่ต้องจัดเตรียมชุดข้อมูลตัวแทนสำหรับการสอบเทียบ การหาปริมาณประเภทนี้จะวัดปริมาณแบบคงที่เฉพาะน้ำหนักจากจุดลอยตัวถึงจำนวนเต็ม ณ เวลาการแปลง ซึ่งให้ความแม่นยำ 8 บิต:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] tflite_quant_model = converter.convert()
เพื่อลดเวลาแฝงในระหว่างการอนุมาน ตัวดำเนินการ "ช่วงไดนามิก" จะจัดปริมาณการเปิดใช้งานแบบไดนามิกตามช่วงเป็น 8 บิต และดำเนินการคำนวณด้วยน้ำหนัก 8 บิตและการเปิดใช้งาน การเพิ่มประสิทธิภาพนี้ให้เวลาแฝงที่ใกล้เคียงกับการอนุมานจุดคงที่โดยสมบูรณ์ อย่างไรก็ตาม ผลลัพธ์ยังคงถูกจัดเก็บโดยใช้จุดลอยตัว ดังนั้นความเร็วที่เพิ่มขึ้นของการดำเนินการช่วงไดนามิกจึงน้อยกว่าการคำนวณจุดคงที่แบบเต็ม
การหาปริมาณจำนวนเต็ม
คุณสามารถรับการปรับปรุงเวลาแฝงเพิ่มเติม ลดการใช้หน่วยความจำสูงสุด และความเข้ากันได้กับอุปกรณ์ฮาร์ดแวร์หรือตัวเร่งความเร็วจำนวนเต็มเท่านั้น โดยตรวจสอบให้แน่ใจว่าคณิตศาสตร์ของโมเดลทั้งหมดเป็นจำนวนเต็ม
สำหรับการหาปริมาณจำนวนเต็ม คุณต้องปรับเทียบหรือประมาณช่วง เช่น (ต่ำสุด สูงสุด) ของเทนเซอร์จุดลอยตัวทั้งหมดในแบบจำลอง ซึ่งแตกต่างจากเทนเซอร์คงที่ เช่น น้ำหนักและอคติ เทนเซอร์แบบแปรผัน เช่น อินพุตโมเดล การเปิดใช้งาน (เอาต์พุตของเลเยอร์กลาง) และเอาต์พุตโมเดลไม่สามารถสอบเทียบได้ เว้นแต่เราจะรันรอบการอนุมานสองสามรอบ ด้วยเหตุนี้ ตัวแปลงจึงจำเป็นต้องมีชุดข้อมูลตัวแทนในการสอบเทียบ ชุดข้อมูลนี้อาจเป็นชุดย่อยขนาดเล็ก (ประมาณ ~100-500 ตัวอย่าง) ของข้อมูลการฝึกอบรมหรือการตรวจสอบความถูกต้อง อ้างถึงฟังก์ชัน representative_dataset() ด้านล่าง
จากเวอร์ชัน TensorFlow 2.7 คุณสามารถระบุชุดข้อมูลตัวแทนผ่าน ลายเซ็นได้ ดังตัวอย่างต่อไปนี้:
def representative_dataset():
for data in dataset:
yield {
"image": data.image,
"bias": data.bias,
}
หากมีลายเซ็นมากกว่าหนึ่งลายเซ็นในโมเดล TensorFlow ที่กำหนด คุณสามารถระบุชุดข้อมูลหลายชุดได้โดยการระบุคีย์ลายเซ็น:
def representative_dataset():
# Feed data set for the "encode" signature.
for data in encode_signature_dataset:
yield (
"encode", {
"image": data.image,
"bias": data.bias,
}
)
# Feed data set for the "decode" signature.
for data in decode_signature_dataset:
yield (
"decode", {
"image": data.image,
"hint": data.hint,
},
)
คุณสามารถสร้างชุดข้อมูลตัวแทนได้โดยระบุรายการเซ็นเซอร์อินพุต:
def representative_dataset():
for data in tf.data.Dataset.from_tensor_slices((images)).batch(1).take(100):
yield [tf.dtypes.cast(data, tf.float32)]
ตั้งแต่เวอร์ชัน TensorFlow 2.7 เราขอแนะนำให้ใช้วิธีแบบอิงลายเซ็นแทนวิธีแบบอิงรายการเทนเซอร์อินพุต เนื่องจากสามารถพลิกลำดับเทนเซอร์อินพุตได้อย่างง่ายดาย
เพื่อวัตถุประสงค์ในการทดสอบ คุณสามารถใช้ชุดข้อมูลจำลองได้ดังนี้:
def representative_dataset():
for _ in range(100):
data = np.random.rand(1, 244, 244, 3)
yield [data.astype(np.float32)]
จำนวนเต็มพร้อมทางเลือกสำรองลอย (ใช้อินพุต/เอาท์พุตลอยเริ่มต้น)
หากต้องการระบุจำนวนโมเดลจำนวนเต็มอย่างสมบูรณ์ แต่ใช้ตัวดำเนินการ float เมื่อไม่มีการใช้งานจำนวนเต็ม (เพื่อให้แน่ใจว่าการแปลงเกิดขึ้นอย่างราบรื่น) ให้ใช้ขั้นตอนต่อไปนี้:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset tflite_quant_model = converter.convert()
จำนวนเต็มเท่านั้น
การสร้างโมเดลจำนวนเต็มเท่านั้นเป็นกรณีการใช้งานทั่วไปสำหรับ TensorFlow Lite สำหรับไมโครคอนโทรลเลอร์ และ Coral Edge TPU
นอกจากนี้ เพื่อให้แน่ใจว่าเข้ากันได้กับอุปกรณ์จำนวนเต็มเท่านั้น (เช่น ไมโครคอนโทรลเลอร์ 8 บิต) และตัวเร่งความเร็ว (เช่น Coral Edge TPU) คุณสามารถบังคับใช้การหาปริมาณจำนวนเต็มสำหรับการดำเนินการทั้งหมด รวมถึงอินพุตและเอาต์พุต โดยใช้ขั้นตอนต่อไปนี้:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] converter.inference_input_type = tf.int8 # or tf.uint8 converter.inference_output_type = tf.int8 # or tf.uint8 tflite_quant_model = converter.convert()
การหาปริมาณ Float16
คุณสามารถลดขนาดของโมเดลจุดลอยตัวได้โดยการวัดปริมาณน้ำหนักเป็น float16 ซึ่งเป็นมาตรฐาน IEEE สำหรับตัวเลขจุดลอยตัว 16 บิต หากต้องการเปิดใช้งานการวัดปริมาณน้ำหนัก float16 ให้ใช้ขั้นตอนต่อไปนี้:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_types = [tf.float16] tflite_quant_model = converter.convert()
ข้อดีของการหาปริมาณ float16 มีดังนี้:
- จะลดขนาดโมเดลลงได้ถึงครึ่งหนึ่ง (เนื่องจากน้ำหนักทั้งหมดลดลงครึ่งหนึ่งของขนาดดั้งเดิม)
- ทำให้สูญเสียความแม่นยำน้อยที่สุด
- รองรับผู้ร่วมประชุมบางคน (เช่น ผู้แทน GPU) ซึ่งสามารถดำเนินการได้โดยตรงบนข้อมูล float16 ส่งผลให้ดำเนินการได้เร็วกว่าการคำนวณ float32
ข้อเสียของการหาปริมาณ float16 มีดังนี้:
- มันไม่ได้ลดเวลาแฝงมากเท่ากับการวัดปริมาณไปจนถึงคณิตศาสตร์จุดคงที่
- ตามค่าเริ่มต้น โมเดลเชิงปริมาณ float16 จะ "ลดขนาด" ค่าน้ำหนักเป็น float32 เมื่อทำงานบน CPU (โปรดทราบว่าตัวแทน GPU จะไม่ดำเนินการลดปริมาณนี้ เนื่องจากสามารถทำงานกับข้อมูล float16 ได้)
จำนวนเต็มเท่านั้น: การเปิดใช้งาน 16 บิตพร้อมน้ำหนัก 8 บิต (ทดลอง)
นี่เป็นรูปแบบเชิงปริมาณเชิงทดลอง คล้ายกับรูปแบบ "จำนวนเต็มเท่านั้น" แต่การเปิดใช้งานจะถูกวัดปริมาณตามช่วงถึง 16 บิต น้ำหนักจะถูกวัดปริมาณเป็นจำนวนเต็ม 8 บิต และอคติจะถูกวัดปริมาณเป็นจำนวนเต็ม 64 บิต สิ่งนี้เรียกอีกอย่างว่าการหาปริมาณ 16x8
ข้อได้เปรียบหลักของการหาปริมาณนี้คือสามารถปรับปรุงความแม่นยำได้อย่างมาก แต่จะเพิ่มขนาดโมเดลเพียงเล็กน้อยเท่านั้น
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8] tflite_quant_model = converter.convert()
หากตัวดำเนินการบางตัวในโมเดลไม่รองรับการหาปริมาณขนาด 16x8 โมเดลก็ยังสามารถหาปริมาณได้ แต่ตัวดำเนินการที่ไม่รองรับจะถูกเก็บไว้ในโฟลต ควรเพิ่มตัวเลือกต่อไปนี้ใน target_spec เพื่ออนุญาตสิ่งนี้
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8, tf.lite.OpsSet.TFLITE_BUILTINS] tflite_quant_model = converter.convert()
ตัวอย่างของกรณีการใช้งานที่มีการปรับปรุงความแม่นยำตามแผนการวัดปริมาณนี้ ได้แก่:
- ความละเอียดสูงสุด
- การประมวลผลสัญญาณเสียง เช่น การตัดเสียงรบกวน และการสร้างบีมฟอร์มมิ่ง
- การลดสัญญาณรบกวนของภาพ,
- การสร้าง HDR ใหม่จากภาพเดียว
ข้อเสียของการหาปริมาณนี้คือ:
- การอนุมานในปัจจุบันช้ากว่าจำนวนเต็ม 8 บิตอย่างเห็นได้ชัด เนื่องจากขาดการใช้งานเคอร์เนลที่ปรับให้เหมาะสม
- ขณะนี้เข้ากันไม่ได้กับผู้ร่วมประชุม TFLite ที่เร่งด้วยฮาร์ดแวร์ที่มีอยู่
สามารถดูบทช่วยสอนสำหรับโหมดการวัดปริมาณ ได้ที่นี่
ความแม่นยำของโมเดล
เนื่องจากการตุ้มน้ำหนักเป็นแบบวัดปริมาณหลังการฝึก จึงอาจสูญเสียความแม่นยำ โดยเฉพาะสำหรับเครือข่ายขนาดเล็ก โมเดลเชิงปริมาณเต็มรูปแบบที่ผ่านการฝึกอบรมล่วงหน้ามีไว้สำหรับเครือข่ายเฉพาะบน TensorFlow Hub สิ่งสำคัญคือต้องตรวจสอบความถูกต้องของแบบจำลองเชิงปริมาณเพื่อตรวจสอบว่าการลดลงในความถูกต้องนั้นอยู่ภายในขีดจำกัดที่ยอมรับได้ มีเครื่องมือในการประเมิน ความแม่นยำของโมเดล TensorFlow Lite
หรืออีกทางหนึ่ง หากความแม่นยำลดลงสูงเกินไป ให้พิจารณาใช้ การฝึกอบรมที่คำนึงถึงเชิงปริมาณ อย่างไรก็ตาม การดำเนินการดังกล่าวจำเป็นต้องมีการแก้ไขระหว่างการฝึกแบบจำลองเพื่อเพิ่มโหนดการวัดปริมาณปลอม ในขณะที่เทคนิคการวัดปริมาณหลังการฝึกในหน้านี้จะใช้แบบจำลองที่ได้รับการฝึกล่วงหน้าที่มีอยู่
การเป็นตัวแทนของเทนเซอร์เชิงปริมาณ
การหาปริมาณ 8 บิตประมาณค่าจุดลอยตัวโดยใช้สูตรต่อไปนี้
\[real\_value = (int8\_value - zero\_point) \times scale\]
การเป็นตัวแทนมีสองส่วนหลัก:
น้ำหนักต่อแกน (หรือต่อช่อง) หรือน้ำหนักต่อเทนเซอร์แสดงด้วยค่าเสริมของ int8 two ในช่วง [-127, 127] โดยมีจุดศูนย์เท่ากับ 0
การเปิดใช้งาน/อินพุตต่อเทนเซอร์แสดงด้วยค่าเสริมของ int8 two ในช่วง [-128, 127] โดยมีจุดศูนย์อยู่ในช่วง [-128, 127]
หากต้องการดูรายละเอียดเกี่ยวกับแผนการหาปริมาณของเรา โปรดดู ข้อมูลจำเพาะเกี่ยวกับปริมาณ ของเรา ผู้จำหน่ายฮาร์ดแวร์ที่ต้องการเชื่อมต่อกับอินเทอร์เฟซตัวแทนของ TensorFlow Lite ได้รับการสนับสนุนให้ใช้โครงร่างการวัดปริมาณตามที่อธิบายไว้ที่นั่น