
| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub | |
В этом руководстве показано, как использовать Deep & Cross Network (DCN) для эффективного изучения пересечений функций.
Задний план
Что такое кресты функций и почему они важны? Представьте, что мы создаем систему рекомендаций, чтобы продавать блендер клиентам. Затем, предыстория покупки клиента , такие как purchased_bananas и purchased_cooking_books или географические особенности, одиночные функции. Если один купил как бананы и кулинарные книги, то этот клиент будет более вероятно , нажмите на рекомендуемом блендер. Сочетание purchased_bananas и purchased_cooking_books упоминается как особенность креста, которая обеспечивает дополнительную информацию взаимодействия за пределами индивидуальных особенностей.
Какие проблемы возникают при изучении крестиков функций? В веб-приложениях данные в основном категоричны, что приводит к большому и разреженному пространству функций. Выявление эффективных пересечений функций в этой настройке часто требует ручной разработки функций или исчерпывающего поиска. Традиционные модели многослойного персептрона с прямой связью (MLP) представляют собой универсальные аппроксиматоры функций; Однако, они не могут эффективно аппроксимировать даже 2 - го или 3-го порядка функций кресты [ 1 , 2 ].
Что такое глубокая и кросс-сеть (DCN)? DCN была разработана для более эффективного изучения явных перекрестных функций и функций с ограниченной степенью. Она начинается с входным слоем ( как правило , вложением слоя), с последующим поперечной сетью , содержащей множество поперечных слоев , что модели явными функциональные взаимодействий, а затем соединяется с глубокой сетью , которая моделирует неявные взаимодействия особенности.
- Кросс-сеть. Это ядро DCN. Он явно применяет пересечение признаков на каждом слое, и максимальная степень полинома увеличивается с глубиной слоя. На приведенном ниже рисунке показаны \((i+1)\)-го поперечного слоя.
- Глубокая сеть. Это традиционный многослойный перцептрон с прямой связью (MLP).
Глубокая сеть и сеть кросс затем объединяются , чтобы сформировать DCN [ 1 ]. Обычно мы можем разместить глубокую сеть поверх кросс-сети (многослойная структура); мы также можем разместить их параллельно (параллельная структура).
Далее мы сначала покажем преимущества DCN на игрушечном примере, а затем расскажем о некоторых распространенных способах использования DCN с использованием набора данных MovieLen-1M.
Давайте сначала установим и импортируем необходимые пакеты для этого colab.
pip install -q tensorflow-recommenderspip install -q --upgrade tensorflow-datasets
import pprint
%matplotlib inline
import matplotlib.pyplot as plt
from mpl_toolkits.axes_grid1 import make_axes_locatable
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_recommenders as tfrs
Пример игрушки
Чтобы проиллюстрировать преимущества DCN, давайте рассмотрим простой пример. Предположим, у нас есть набор данных, в котором мы пытаемся смоделировать вероятность того, что клиент нажмет на объявление блендера, с его функциями и меткой, описанными ниже.
| Характеристики / этикетка | Описание | Тип значения / диапазон |
|---|---|---|
| \(x_1\) = страна | страна, в которой живет этот клиент | Int в [0, 199] |
| \(x_2\) = бананы | # банан купил клиент | Int в [0, 23] |
| \(x_3\) = кулинарные книги | # кулинарные книги, приобретенные клиентом | Int в [0, 5] |
| \(y\) | вероятность нажатия на рекламу блендера | - |
Затем мы позволяем данным следовать следующему базовому распределению:
\[y = f(x_1, x_2, x_3) = 0.1x_1 + 0.4x_2+0.7x_3 + 0.1x_1x_2+3.1x_2x_3+0.1x_3^2\]
где вероятность \(y\) линейно зависит как от особенностей \(x_i\)«с, но также и на мультипликативных взаимодействиях между \(x_i\)» ы. В нашем случае, мы можем сказать , что вероятность покупки блендер (\(y\)) зависит не только от покупки бананов (\(x_2\)) или поваренных книг (\(x_3\)), но и на покупку бананов и поваренные книги вместе (\(x_2x_3\)).
Мы можем сгенерировать данные для этого следующим образом:
Генерация синтетических данных
Сначала мы определим \(f(x_1, x_2, x_3)\) , как описано выше.
def get_mixer_data(data_size=100_000, random_seed=42):
# We need to fix the random seed
# to make colab runs repeatable.
rng = np.random.RandomState(random_seed)
country = rng.randint(200, size=[data_size, 1]) / 200.
bananas = rng.randint(24, size=[data_size, 1]) / 24.
coockbooks = rng.randint(6, size=[data_size, 1]) / 6.
x = np.concatenate([country, bananas, coockbooks], axis=1)
# # Create 1st-order terms.
y = 0.1 * country + 0.4 * bananas + 0.7 * coockbooks
# Create 2nd-order cross terms.
y += 0.1 * country * bananas + 3.1 * bananas * coockbooks + (
0.1 * coockbooks * coockbooks)
return x, y
Давайте сгенерируем данные, которые соответствуют распределению, и разделим данные на 90% для обучения и 10% для тестирования.
x, y = get_mixer_data()
num_train = 90000
train_x = x[:num_train]
train_y = y[:num_train]
eval_x = x[num_train:]
eval_y = y[num_train:]
Конструкция модели
Мы собираемся опробовать как кросс-сеть, так и глубокую сеть, чтобы проиллюстрировать преимущества кросс-сети для рекомендателей. Поскольку данные, которые мы только что создали, содержат только взаимодействия функций 2-го порядка, этого будет достаточно для иллюстрации с помощью однослойной кросс-сети. Если бы мы хотели смоделировать взаимодействия функций более высокого порядка, мы могли бы сложить несколько перекрестных слоев и использовать многослойную перекрестную сеть. Мы будем строить две модели:
- Перекрестная сеть только с одним перекрестным слоем;
- Глубокая сеть с более широкими и глубокими слоями ReLU.
Сначала мы строим унифицированный модельный класс, потеря которого представляет собой среднеквадратичную ошибку.
class Model(tfrs.Model):
def __init__(self, model):
super().__init__()
self._model = model
self._logit_layer = tf.keras.layers.Dense(1)
self.task = tfrs.tasks.Ranking(
loss=tf.keras.losses.MeanSquaredError(),
metrics=[
tf.keras.metrics.RootMeanSquaredError("RMSE")
]
)
def call(self, x):
x = self._model(x)
return self._logit_layer(x)
def compute_loss(self, features, training=False):
x, labels = features
scores = self(x)
return self.task(
labels=labels,
predictions=scores,
)
Затем мы указываем кросс-сеть (с 1 кросс-уровнем размера 3) и DNN на основе ReLU (с размерами слоев [512, 256, 128]):
crossnet = Model(tfrs.layers.dcn.Cross())
deepnet = Model(
tf.keras.Sequential([
tf.keras.layers.Dense(512, activation="relu"),
tf.keras.layers.Dense(256, activation="relu"),
tf.keras.layers.Dense(128, activation="relu")
])
)
Модельное обучение
Теперь, когда у нас есть данные и модели, мы собираемся обучить модели. Сначала мы перемешиваем и группируем данные, чтобы подготовиться к обучению модели.
train_data = tf.data.Dataset.from_tensor_slices((train_x, train_y)).batch(1000)
eval_data = tf.data.Dataset.from_tensor_slices((eval_x, eval_y)).batch(1000)
Затем мы определяем количество эпох, а также скорость обучения.
epochs = 100
learning_rate = 0.4
Хорошо, теперь все готово, давайте скомпилируем и обучим модели. Вы можете установить verbose=True , если вы хотите увидеть , как модель прогрессирует.
crossnet.compile(optimizer=tf.keras.optimizers.Adagrad(learning_rate))
crossnet.fit(train_data, epochs=epochs, verbose=False)
<keras.callbacks.History at 0x7f27d82ef390>
deepnet.compile(optimizer=tf.keras.optimizers.Adagrad(learning_rate))
deepnet.fit(train_data, epochs=epochs, verbose=False)
<keras.callbacks.History at 0x7f27d07a3dd0>
Оценка модели
Мы проверяем производительность модели на наборе оценочных данных и сообщаем среднеквадратичную ошибку (RMSE, чем ниже, тем лучше).
crossnet_result = crossnet.evaluate(eval_data, return_dict=True, verbose=False)
print(f"CrossNet(1 layer) RMSE is {crossnet_result['RMSE']:.4f} "
f"using {crossnet.count_params()} parameters.")
deepnet_result = deepnet.evaluate(eval_data, return_dict=True, verbose=False)
print(f"DeepNet(large) RMSE is {deepnet_result['RMSE']:.4f} "
f"using {deepnet.count_params()} parameters.")
CrossNet(1 layer) RMSE is 0.0011 using 16 parameters. DeepNet(large) RMSE is 0.1258 using 166401 parameters.
Мы видим , что крест сети , достигнутые величины снижения RMSE чем РЕЛУ на основе DNN, с величинами меньшим числом параметров. Это свидетельствует об эффективности кросс-сети в изучении кросс-функций.
Модель понимания
Мы уже знаем, какие пересечения признаков важны в наших данных, было бы интересно проверить, действительно ли наша модель изучила важное пересечение признаков. Это можно сделать, визуализировав заученную матрицу весов в DCN. Вес \(W_{ij}\) представляет изученную важность взаимодействия между особенностью \(x_i\) и \(x_j\).
mat = crossnet._model._dense.kernel
features = ["country", "purchased_bananas", "purchased_cookbooks"]
plt.figure(figsize=(9,9))
im = plt.matshow(np.abs(mat.numpy()), cmap=plt.cm.Blues)
ax = plt.gca()
divider = make_axes_locatable(plt.gca())
cax = divider.append_axes("right", size="5%", pad=0.05)
plt.colorbar(im, cax=cax)
cax.tick_params(labelsize=10)
_ = ax.set_xticklabels([''] + features, rotation=45, fontsize=10)
_ = ax.set_yticklabels([''] + features, fontsize=10)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:11: UserWarning: FixedFormatter should only be used together with FixedLocator # This is added back by InteractiveShellApp.init_path() /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:12: UserWarning: FixedFormatter should only be used together with FixedLocator if sys.path[0] == '': <Figure size 648x648 with 0 Axes>
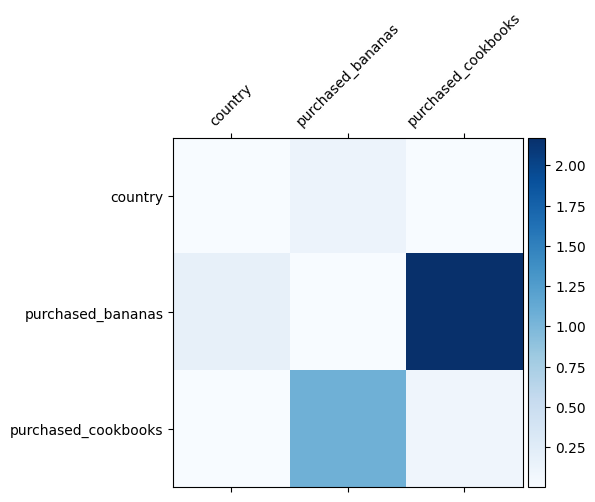
Более темные цвета представляют собой более сильные усвоенные взаимодействия - в этом случае ясно, что модель усвоила, что совместная покупка бабан и поваренных книг важна.
Если вы заинтересованы в том, пробуя более сложные синтетические данные, не стесняйтесь , чтобы проверить эту бумагу .
Пример киноленты 1М
Рассмотрим теперь эффективность DCN на реальном наборе данных: MovieLens 1M [ 3 ]. Movielens 1M - популярный набор данных для рекомендательных исследований. Он прогнозирует рейтинги фильмов пользователей с учетом пользовательских функций и функций, связанных с фильмами. Мы используем этот набор данных, чтобы продемонстрировать некоторые распространенные способы использования DCN.
Обработка данных
Процедура обработки данных следует аналогичную процедуру в качестве основного ранжирования учебника .
ratings = tfds.load("movie_lens/100k-ratings", split="train")
ratings = ratings.map(lambda x: {
"movie_id": x["movie_id"],
"user_id": x["user_id"],
"user_rating": x["user_rating"],
"user_gender": int(x["user_gender"]),
"user_zip_code": x["user_zip_code"],
"user_occupation_text": x["user_occupation_text"],
"bucketized_user_age": int(x["bucketized_user_age"]),
})
WARNING:absl:The handle "movie_lens" for the MovieLens dataset is deprecated. Prefer using "movielens" instead.
Затем мы случайным образом разделяем данные на 80% для обучения и 20% для тестирования.
tf.random.set_seed(42)
shuffled = ratings.shuffle(100_000, seed=42, reshuffle_each_iteration=False)
train = shuffled.take(80_000)
test = shuffled.skip(80_000).take(20_000)
Затем мы создаем словарь для каждой функции.
feature_names = ["movie_id", "user_id", "user_gender", "user_zip_code",
"user_occupation_text", "bucketized_user_age"]
vocabularies = {}
for feature_name in feature_names:
vocab = ratings.batch(1_000_000).map(lambda x: x[feature_name])
vocabularies[feature_name] = np.unique(np.concatenate(list(vocab)))
Конструкция модели
Архитектура модели, которую мы будем строить, начинается со слоя внедрения, который передается в кросс-сеть, за которой следует глубокая сеть. Размер внедрения установлен на 32 для всех функций. Вы также можете использовать разные размеры встраивания для разных функций.
class DCN(tfrs.Model):
def __init__(self, use_cross_layer, deep_layer_sizes, projection_dim=None):
super().__init__()
self.embedding_dimension = 32
str_features = ["movie_id", "user_id", "user_zip_code",
"user_occupation_text"]
int_features = ["user_gender", "bucketized_user_age"]
self._all_features = str_features + int_features
self._embeddings = {}
# Compute embeddings for string features.
for feature_name in str_features:
vocabulary = vocabularies[feature_name]
self._embeddings[feature_name] = tf.keras.Sequential(
[tf.keras.layers.StringLookup(
vocabulary=vocabulary, mask_token=None),
tf.keras.layers.Embedding(len(vocabulary) + 1,
self.embedding_dimension)
])
# Compute embeddings for int features.
for feature_name in int_features:
vocabulary = vocabularies[feature_name]
self._embeddings[feature_name] = tf.keras.Sequential(
[tf.keras.layers.IntegerLookup(
vocabulary=vocabulary, mask_value=None),
tf.keras.layers.Embedding(len(vocabulary) + 1,
self.embedding_dimension)
])
if use_cross_layer:
self._cross_layer = tfrs.layers.dcn.Cross(
projection_dim=projection_dim,
kernel_initializer="glorot_uniform")
else:
self._cross_layer = None
self._deep_layers = [tf.keras.layers.Dense(layer_size, activation="relu")
for layer_size in deep_layer_sizes]
self._logit_layer = tf.keras.layers.Dense(1)
self.task = tfrs.tasks.Ranking(
loss=tf.keras.losses.MeanSquaredError(),
metrics=[tf.keras.metrics.RootMeanSquaredError("RMSE")]
)
def call(self, features):
# Concatenate embeddings
embeddings = []
for feature_name in self._all_features:
embedding_fn = self._embeddings[feature_name]
embeddings.append(embedding_fn(features[feature_name]))
x = tf.concat(embeddings, axis=1)
# Build Cross Network
if self._cross_layer is not None:
x = self._cross_layer(x)
# Build Deep Network
for deep_layer in self._deep_layers:
x = deep_layer(x)
return self._logit_layer(x)
def compute_loss(self, features, training=False):
labels = features.pop("user_rating")
scores = self(features)
return self.task(
labels=labels,
predictions=scores,
)
Модельное обучение
Мы перемешиваем, группируем и кэшируем данные обучения и тестирования.
cached_train = train.shuffle(100_000).batch(8192).cache()
cached_test = test.batch(4096).cache()
Давайте определим функцию, которая запускает модель несколько раз и возвращает среднее значение RMSE и стандартное отклонение модели из нескольких запусков.
def run_models(use_cross_layer, deep_layer_sizes, projection_dim=None, num_runs=5):
models = []
rmses = []
for i in range(num_runs):
model = DCN(use_cross_layer=use_cross_layer,
deep_layer_sizes=deep_layer_sizes,
projection_dim=projection_dim)
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate))
models.append(model)
model.fit(cached_train, epochs=epochs, verbose=False)
metrics = model.evaluate(cached_test, return_dict=True)
rmses.append(metrics["RMSE"])
mean, stdv = np.average(rmses), np.std(rmses)
return {"model": models, "mean": mean, "stdv": stdv}
Мы устанавливаем некоторые гиперпараметры для моделей. Обратите внимание, что эти гиперпараметры устанавливаются глобально для всех моделей в демонстрационных целях. Если вы хотите получить максимальную производительность для каждой модели или провести честное сравнение моделей, мы предлагаем вам настроить гиперпараметры. Помните, что архитектура модели и схемы оптимизации взаимосвязаны.
epochs = 8
learning_rate = 0.01
DCN (в стопке). Сначала мы обучаем модель DCN многослойной структуре, то есть входные данные подаются в кросс-сеть, а затем в глубокую сеть.
dcn_result = run_models(use_cross_layer=True,
deep_layer_sizes=[192, 192])
WARNING:tensorflow:mask_value is deprecated, use mask_token instead. WARNING:tensorflow:mask_value is deprecated, use mask_token instead. 5/5 [==============================] - 3s 24ms/step - RMSE: 0.9312 - loss: 0.8674 - regularization_loss: 0.0000e+00 - total_loss: 0.8674 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9339 - loss: 0.8726 - regularization_loss: 0.0000e+00 - total_loss: 0.8726 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9326 - loss: 0.8703 - regularization_loss: 0.0000e+00 - total_loss: 0.8703 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9351 - loss: 0.8752 - regularization_loss: 0.0000e+00 - total_loss: 0.8752 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9339 - loss: 0.8729 - regularization_loss: 0.0000e+00 - total_loss: 0.8729
DCN низкого ранга. Чтобы снизить затраты на обучение и обслуживание, мы используем методы низкого ранга для аппроксимации весовых матриц DCN. Ранг передается через аргумент projection_dim ; Меньшая projection_dim приводит к более низкой стоимости. Обратите внимание , что projection_dim должно быть меньше , чем (размер входного) / 2 , чтобы уменьшить стоимость. На практике мы наблюдали, что использование DCN низкого ранга с рангом (размером ввода) / 4 постоянно сохраняло точность DCN полного ранга.
dcn_lr_result = run_models(use_cross_layer=True,
projection_dim=20,
deep_layer_sizes=[192, 192])
5/5 [==============================] - 0s 3ms/step - RMSE: 0.9307 - loss: 0.8669 - regularization_loss: 0.0000e+00 - total_loss: 0.8669 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9312 - loss: 0.8668 - regularization_loss: 0.0000e+00 - total_loss: 0.8668 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9303 - loss: 0.8666 - regularization_loss: 0.0000e+00 - total_loss: 0.8666 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9337 - loss: 0.8723 - regularization_loss: 0.0000e+00 - total_loss: 0.8723 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9300 - loss: 0.8657 - regularization_loss: 0.0000e+00 - total_loss: 0.8657
DNN. Мы обучаем модель DNN того же размера в качестве эталона.
dnn_result = run_models(use_cross_layer=False,
deep_layer_sizes=[192, 192, 192])
5/5 [==============================] - 0s 3ms/step - RMSE: 0.9462 - loss: 0.8989 - regularization_loss: 0.0000e+00 - total_loss: 0.8989 5/5 [==============================] - 0s 4ms/step - RMSE: 0.9352 - loss: 0.8765 - regularization_loss: 0.0000e+00 - total_loss: 0.8765 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9393 - loss: 0.8840 - regularization_loss: 0.0000e+00 - total_loss: 0.8840 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9362 - loss: 0.8772 - regularization_loss: 0.0000e+00 - total_loss: 0.8772 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9377 - loss: 0.8798 - regularization_loss: 0.0000e+00 - total_loss: 0.8798
Мы оцениваем модель на тестовых данных и сообщаем среднее значение и стандартное отклонение из 5 прогонов.
print("DCN RMSE mean: {:.4f}, stdv: {:.4f}".format(
dcn_result["mean"], dcn_result["stdv"]))
print("DCN (low-rank) RMSE mean: {:.4f}, stdv: {:.4f}".format(
dcn_lr_result["mean"], dcn_lr_result["stdv"]))
print("DNN RMSE mean: {:.4f}, stdv: {:.4f}".format(
dnn_result["mean"], dnn_result["stdv"]))
DCN RMSE mean: 0.9333, stdv: 0.0013 DCN (low-rank) RMSE mean: 0.9312, stdv: 0.0013 DNN RMSE mean: 0.9389, stdv: 0.0039
Мы видим, что DCN обеспечивает лучшую производительность, чем DNN того же размера с уровнями ReLU. Более того, DCN низкого ранга смогла снизить параметры при сохранении точности.
Подробнее о DCN. Кроме того , было показано , Что у выше, есть более творческие еще практически полезные способы использования DCN [ 1 ].
DCN с параллельной структурой. Входы подаются параллельно кросс-сети и глубокой сети.
Объединение перекрестных слоев. Входные данные подаются параллельно нескольким перекрестным слоям для захвата дополнительных пересечений признаков.
Модель понимания
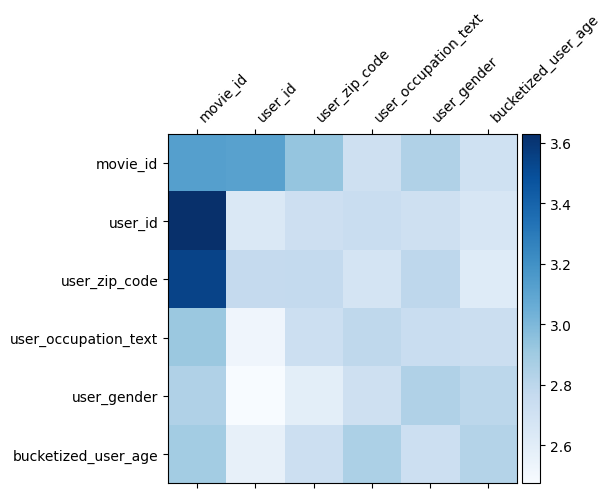
Весовая матрица \(W\) в DCN показывает , что функция пересекает модель научилась быть важным. Напомним , что в предыдущем примере игрушек, важность взаимодействия между \(i\)-м и \(j\)-м показывает захватывается (\(i, j\)) -й элемент \(W\).
Что немного отличается здесь является то , что функция вложения размером 32 вместо размера 1. Таким образом, значение будет характеризоваться \((i, j)\)-м блок\(W_{i,j}\) , который имеет размерность 32 на 32. В дальнейшем мы визуализировать норму Фробениуса [ 4 ] \(||W_{i,j}||_F\) каждого блока, и большую норму хотела бы предложить более высокое значение (при условии вложения особенностей имеет одинаковые шкалы).
Помимо нормы блока, мы также можем визуализировать всю матрицу или среднее / медианное / максимальное значение каждого блока.
model = dcn_result["model"][0]
mat = model._cross_layer._dense.kernel
features = model._all_features
block_norm = np.ones([len(features), len(features)])
dim = model.embedding_dimension
# Compute the norms of the blocks.
for i in range(len(features)):
for j in range(len(features)):
block = mat[i * dim:(i + 1) * dim,
j * dim:(j + 1) * dim]
block_norm[i,j] = np.linalg.norm(block, ord="fro")
plt.figure(figsize=(9,9))
im = plt.matshow(block_norm, cmap=plt.cm.Blues)
ax = plt.gca()
divider = make_axes_locatable(plt.gca())
cax = divider.append_axes("right", size="5%", pad=0.05)
plt.colorbar(im, cax=cax)
cax.tick_params(labelsize=10)
_ = ax.set_xticklabels([""] + features, rotation=45, ha="left", fontsize=10)
_ = ax.set_yticklabels([""] + features, fontsize=10)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:23: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:24: UserWarning: FixedFormatter should only be used together with FixedLocator <Figure size 648x648 with 0 Axes>
Вот и все для этого колаба! Мы надеемся, что вам понравилось изучать основы DCN и распространенные способы ее использования. Если вы заинтересованы в получении дополнительной информации , вы можете проверить два соответствующих документ: DCN-v1-бумага , DCN-v2-бумага .
использованная литература
DCN V2: Повышение Deep & Cross Сеть и практические уроки для Web-масштабного обучения ранжировать системы .
Руокси Ван, Ракеш Шиванна, Дерек Чжиюань Ченг, Сагар Джайн, Донг Линь, Личан Хонг, Эд Чи. (2020)
Deep & Cross сеть Ad Click Предсказания .
Жуйси Ван, Бинь Фу, Ганг Фу, Минлян Ван. (AdKDD 2017)