
| |  GitHubでソースを表示 GitHubでソースを表示 | |
このテキスト分類チュートリアル列車リカレントニューラルネットワーク上のIMDB大きな映画のレビューデータセット評判分析のために。
設定
import numpy as np
import tensorflow_datasets as tfds
import tensorflow as tf
tfds.disable_progress_bar()
インポートmatplotlibプロットグラフにヘルパー関数を作成します。
import matplotlib.pyplot as plt
def plot_graphs(history, metric):
plt.plot(history.history[metric])
plt.plot(history.history['val_'+metric], '')
plt.xlabel("Epochs")
plt.ylabel(metric)
plt.legend([metric, 'val_'+metric])
入力パイプラインを設定する
IMDB大映画レビューデータセットは、バイナリ分類データセット-すべての口コミを正または負の感情のいずれかを持っています。
使用してデータセットをダウンロードしてくださいTFDSを。参照してくださいロードテキストチュートリアル手動でこの種のデータをロードする方法の詳細については、を。
dataset, info = tfds.load('imdb_reviews', with_info=True,
as_supervised=True)
train_dataset, test_dataset = dataset['train'], dataset['test']
train_dataset.element_spec
(TensorSpec(shape=(), dtype=tf.string, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
最初に、これは(テキスト、ラベルのペア)のデータセットを返します。
for example, label in train_dataset.take(1):
print('text: ', example.numpy())
print('label: ', label.numpy())
text: b"This was an absolutely terrible movie. Don't be lured in by Christopher Walken or Michael Ironside. Both are great actors, but this must simply be their worst role in history. Even their great acting could not redeem this movie's ridiculous storyline. This movie is an early nineties US propaganda piece. The most pathetic scenes were those when the Columbian rebels were making their cases for revolutions. Maria Conchita Alonso appeared phony, and her pseudo-love affair with Walken was nothing but a pathetic emotional plug in a movie that was devoid of any real meaning. I am disappointed that there are movies like this, ruining actor's like Christopher Walken's good name. I could barely sit through it." label: 0
次の訓練のためのデータをシャッフルし、これらのバッチの作成(text, label)のペアを:
BUFFER_SIZE = 10000
BATCH_SIZE = 64
train_dataset = train_dataset.shuffle(BUFFER_SIZE).batch(BATCH_SIZE).prefetch(tf.data.AUTOTUNE)
test_dataset = test_dataset.batch(BATCH_SIZE).prefetch(tf.data.AUTOTUNE)
for example, label in train_dataset.take(1):
print('texts: ', example.numpy()[:3])
print()
print('labels: ', label.numpy()[:3])
texts: [b'This is arguably the worst film I have ever seen, and I have quite an appetite for awful (and good) movies. It could (just) have managed a kind of adolescent humour if it had been consistently tongue-in-cheek --\xc3\xa0 la ROCKY HORROR PICTURE SHOW, which was really very funny. Other movies, like PLAN NINE FROM OUTER SPACE, manage to be funny while (apparently) trying to be serious. As to the acting, it looks like they rounded up brain-dead teenagers and asked them to ad-lib the whole production. Compared to them, Tom Cruise looks like Alec Guinness. There was one decent interpretation -- that of the older ghoul-busting broad on the motorcycle.' b"I saw this film in the worst possible circumstance. I'd already missed 15 minutes when I woke up to it on an international flight between Sydney and Seoul. I didn't know what I was watching, I thought maybe it was a movie of the week, but quickly became riveted by the performance of the lead actress playing a young woman who's child had been kidnapped. The premise started taking twist and turns I didn't see coming and by the end credits I was scrambling through the the in-flight guide to figure out what I had just watched. Turns out I was belatedly discovering Do-yeon Jeon who'd won Best Actress at Cannes for the role. I don't know if Secret Sunshine is typical of Korean cinema but I'm off to the DVD store to discover more." b"Hello. I am Paul Raddick, a.k.a. Panic Attack of WTAF, Channel 29 in Philadelphia. Let me tell you about this god awful movie that powered on Adam Sandler's film career but was digitized after a short time.<br /><br />Going Overboard is about an aspiring comedian played by Sandler who gets a job on a cruise ship and fails...or so I thought. Sandler encounters babes that like History of the World Part 1 and Rebound. The babes were supposed to be engaged, but, actually, they get executed by Sawtooth, the meanest cannibal the world has ever known. Adam Sandler fared bad in Going Overboard, but fared better in Big Daddy, Billy Madison, and Jen Leone's favorite, 50 First Dates. Man, Drew Barrymore was one hot chick. Spanglish is red hot, Going Overboard ain't Dooley squat! End of file."] labels: [0 1 0]
テキストエンコーダーを作成する
ロードされた生のテキストtfdsそれがモデルで使用することができます前に処理する必要があります。訓練のためのプロセスのテキストへの最も簡単な方法は、使用しているTextVectorization層を。このレイヤーには多くの機能がありますが、このチュートリアルはデフォルトの動作に固執しています。
レイヤーを作成し、レイヤーのにデータセットのテキストを渡し.adapt方法:
VOCAB_SIZE = 1000
encoder = tf.keras.layers.TextVectorization(
max_tokens=VOCAB_SIZE)
encoder.adapt(train_dataset.map(lambda text, label: text))
.adapt方法は、層の語彙を設定します。これが最初の20個のトークンです。パディングと不明なトークンの後、頻度で並べ替えられます。
vocab = np.array(encoder.get_vocabulary())
vocab[:20]
array(['', '[UNK]', 'the', 'and', 'a', 'of', 'to', 'is', 'in', 'it', 'i',
'this', 'that', 'br', 'was', 'as', 'for', 'with', 'movie', 'but'],
dtype='<U14')
語彙が設定されると、レイヤーはテキストをインデックスにエンコードできます。 (あなたが固定設定しない限り、インデックスのテンソルは、バッチ内の最も長いシーケンスに0で埋められているoutput_sequence_length ):
encoded_example = encoder(example)[:3].numpy()
encoded_example
array([[ 11, 7, 1, ..., 0, 0, 0],
[ 10, 208, 11, ..., 0, 0, 0],
[ 1, 10, 237, ..., 0, 0, 0]])
デフォルト設定では、プロセスを完全に元に戻すことはできません。その主な理由は3つあります。
- デフォルト値
preprocessing.TextVectorizationのstandardize引数がある"lower_and_strip_punctuation"。 - 語彙のサイズが制限され、文字ベースのフォールバックがないため、不明なトークンがいくつか発生します。
for n in range(3):
print("Original: ", example[n].numpy())
print("Round-trip: ", " ".join(vocab[encoded_example[n]]))
print()
Original: b'This is arguably the worst film I have ever seen, and I have quite an appetite for awful (and good) movies. It could (just) have managed a kind of adolescent humour if it had been consistently tongue-in-cheek --\xc3\xa0 la ROCKY HORROR PICTURE SHOW, which was really very funny. Other movies, like PLAN NINE FROM OUTER SPACE, manage to be funny while (apparently) trying to be serious. As to the acting, it looks like they rounded up brain-dead teenagers and asked them to ad-lib the whole production. Compared to them, Tom Cruise looks like Alec Guinness. There was one decent interpretation -- that of the older ghoul-busting broad on the motorcycle.' Round-trip: this is [UNK] the worst film i have ever seen and i have quite an [UNK] for awful and good movies it could just have [UNK] a kind of [UNK] [UNK] if it had been [UNK] [UNK] [UNK] la [UNK] horror picture show which was really very funny other movies like [UNK] [UNK] from [UNK] space [UNK] to be funny while apparently trying to be serious as to the acting it looks like they [UNK] up [UNK] [UNK] and [UNK] them to [UNK] the whole production [UNK] to them tom [UNK] looks like [UNK] [UNK] there was one decent [UNK] that of the older [UNK] [UNK] on the [UNK] Original: b"I saw this film in the worst possible circumstance. I'd already missed 15 minutes when I woke up to it on an international flight between Sydney and Seoul. I didn't know what I was watching, I thought maybe it was a movie of the week, but quickly became riveted by the performance of the lead actress playing a young woman who's child had been kidnapped. The premise started taking twist and turns I didn't see coming and by the end credits I was scrambling through the the in-flight guide to figure out what I had just watched. Turns out I was belatedly discovering Do-yeon Jeon who'd won Best Actress at Cannes for the role. I don't know if Secret Sunshine is typical of Korean cinema but I'm off to the DVD store to discover more." Round-trip: i saw this film in the worst possible [UNK] id already [UNK] [UNK] minutes when i [UNK] up to it on an [UNK] [UNK] between [UNK] and [UNK] i didnt know what i was watching i thought maybe it was a movie of the [UNK] but quickly became [UNK] by the performance of the lead actress playing a young woman whos child had been [UNK] the premise started taking twist and turns i didnt see coming and by the end credits i was [UNK] through the the [UNK] [UNK] to figure out what i had just watched turns out i was [UNK] [UNK] [UNK] [UNK] [UNK] [UNK] best actress at [UNK] for the role i dont know if secret [UNK] is typical of [UNK] cinema but im off to the dvd [UNK] to [UNK] more Original: b"Hello. I am Paul Raddick, a.k.a. Panic Attack of WTAF, Channel 29 in Philadelphia. Let me tell you about this god awful movie that powered on Adam Sandler's film career but was digitized after a short time.<br /><br />Going Overboard is about an aspiring comedian played by Sandler who gets a job on a cruise ship and fails...or so I thought. Sandler encounters babes that like History of the World Part 1 and Rebound. The babes were supposed to be engaged, but, actually, they get executed by Sawtooth, the meanest cannibal the world has ever known. Adam Sandler fared bad in Going Overboard, but fared better in Big Daddy, Billy Madison, and Jen Leone's favorite, 50 First Dates. Man, Drew Barrymore was one hot chick. Spanglish is red hot, Going Overboard ain't Dooley squat! End of file." Round-trip: [UNK] i am paul [UNK] [UNK] [UNK] [UNK] of [UNK] [UNK] [UNK] in [UNK] let me tell you about this god awful movie that [UNK] on [UNK] [UNK] film career but was [UNK] after a short [UNK] br going [UNK] is about an [UNK] [UNK] played by [UNK] who gets a job on a [UNK] [UNK] and [UNK] so i thought [UNK] [UNK] [UNK] that like history of the world part 1 and [UNK] the [UNK] were supposed to be [UNK] but actually they get [UNK] by [UNK] the [UNK] [UNK] the world has ever known [UNK] [UNK] [UNK] bad in going [UNK] but [UNK] better in big [UNK] [UNK] [UNK] and [UNK] [UNK] favorite [UNK] first [UNK] man [UNK] [UNK] was one hot [UNK] [UNK] is red hot going [UNK] [UNK] [UNK] [UNK] end of [UNK]
モデルを作成する
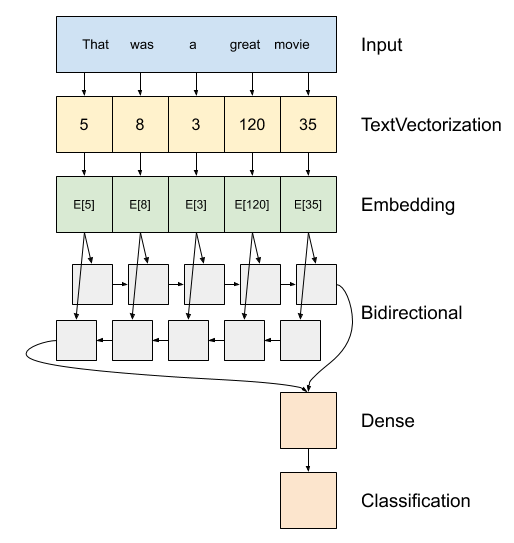
上はモデルの図です。
このモデルは、として構築することができ
tf.keras.Sequential。第一層は、
encoderトークンインデックスの配列にテキストを変換し、。エンコーダーの後に埋め込みレイヤーがあります。埋め込みレイヤーは、単語ごとに1つのベクトルを格納します。呼び出されると、単語インデックスのシーケンスをベクトルのシーケンスに変換します。これらのベクトルは訓練可能です。 (十分なデータで)トレーニングした後、同様の意味を持つ単語は、多くの場合、同様のベクトルを持ちます。
このインデックス・ルックアップは、はるかに効率的介してワンホットエンコードされたベクトルを渡す等価演算より
tf.keras.layers.Dense層。リカレントニューラルネットワーク(RNN)は、要素を反復処理することによってシーケンス入力を処理します。 RNNは、あるタイムステップからの出力を次のタイムステップの入力に渡します。
tf.keras.layers.Bidirectionalラッパーはまた、RNN層を使用することができます。これにより、入力がRNNレイヤーを介して順方向および逆方向に伝播され、最終出力が連結されます。双方向RNNの主な利点は、入力の先頭からの信号を、出力に影響を与えるためにすべてのタイムステップで処理する必要がないことです。
双方向RNNの主な欠点は、単語が最後に追加されるため、予測を効率的にストリーミングできないことです。
RNNは、単一のベクターに配列を変換した後、2
layers.Dense分類出力として単一ロジットこのベクトル表現から、いくつかの最終的な処理、および変換を行います。
これを実装するためのコードは次のとおりです。
model = tf.keras.Sequential([
encoder,
tf.keras.layers.Embedding(
input_dim=len(encoder.get_vocabulary()),
output_dim=64,
# Use masking to handle the variable sequence lengths
mask_zero=True),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64)),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(1)
])
モデル内のすべてのレイヤーには単一の入力しかなく、単一の出力を生成するため、ここではKerasシーケンシャルモデルが使用されていることに注意してください。ステートフルRNNレイヤーを使用する場合は、Keras機能APIまたはモデルサブクラス化を使用してモデルを構築し、RNNレイヤーの状態を取得して再利用できるようにすることができます。ご確認くださいKeras RNNガイドを詳細については。
埋め込み層のマスキング用途が変化する配列の長さを処理します。後の全ての層Embeddingサポートマスキング:
print([layer.supports_masking for layer in model.layers])
[False, True, True, True, True]
これが期待どおりに機能することを確認するには、文を2回評価します。まず、単独でマスクするパディングはありません。
# predict on a sample text without padding.
sample_text = ('The movie was cool. The animation and the graphics '
'were out of this world. I would recommend this movie.')
predictions = model.predict(np.array([sample_text]))
print(predictions[0])
[-0.00012211]
ここで、より長い文のバッチで再度評価します。結果は同じである必要があります。
# predict on a sample text with padding
padding = "the " * 2000
predictions = model.predict(np.array([sample_text, padding]))
print(predictions[0])
[-0.00012211]
Kerasモデルをコンパイルして、トレーニングプロセスを構成します。
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(1e-4),
metrics=['accuracy'])
モデルをトレーニングする
history = model.fit(train_dataset, epochs=10,
validation_data=test_dataset,
validation_steps=30)
Epoch 1/10 391/391 [==============================] - 39s 84ms/step - loss: 0.6454 - accuracy: 0.5630 - val_loss: 0.4888 - val_accuracy: 0.7568 Epoch 2/10 391/391 [==============================] - 30s 75ms/step - loss: 0.3925 - accuracy: 0.8200 - val_loss: 0.3663 - val_accuracy: 0.8464 Epoch 3/10 391/391 [==============================] - 30s 75ms/step - loss: 0.3319 - accuracy: 0.8525 - val_loss: 0.3402 - val_accuracy: 0.8385 Epoch 4/10 391/391 [==============================] - 30s 75ms/step - loss: 0.3183 - accuracy: 0.8616 - val_loss: 0.3289 - val_accuracy: 0.8438 Epoch 5/10 391/391 [==============================] - 30s 75ms/step - loss: 0.3088 - accuracy: 0.8656 - val_loss: 0.3254 - val_accuracy: 0.8646 Epoch 6/10 391/391 [==============================] - 32s 81ms/step - loss: 0.3043 - accuracy: 0.8686 - val_loss: 0.3242 - val_accuracy: 0.8521 Epoch 7/10 391/391 [==============================] - 30s 76ms/step - loss: 0.3019 - accuracy: 0.8696 - val_loss: 0.3315 - val_accuracy: 0.8609 Epoch 8/10 391/391 [==============================] - 32s 76ms/step - loss: 0.3007 - accuracy: 0.8688 - val_loss: 0.3245 - val_accuracy: 0.8609 Epoch 9/10 391/391 [==============================] - 31s 77ms/step - loss: 0.2981 - accuracy: 0.8707 - val_loss: 0.3294 - val_accuracy: 0.8599 Epoch 10/10 391/391 [==============================] - 31s 78ms/step - loss: 0.2969 - accuracy: 0.8742 - val_loss: 0.3218 - val_accuracy: 0.8547
test_loss, test_acc = model.evaluate(test_dataset)
print('Test Loss:', test_loss)
print('Test Accuracy:', test_acc)
391/391 [==============================] - 15s 38ms/step - loss: 0.3185 - accuracy: 0.8582 Test Loss: 0.3184521794319153 Test Accuracy: 0.8581600189208984
plt.figure(figsize=(16, 8))
plt.subplot(1, 2, 1)
plot_graphs(history, 'accuracy')
plt.ylim(None, 1)
plt.subplot(1, 2, 2)
plot_graphs(history, 'loss')
plt.ylim(0, None)
(0.0, 0.6627909764647484)

新しい文で予測を実行します。
予測が> = 0.0の場合は正であり、それ以外の場合は負です。
sample_text = ('The movie was cool. The animation and the graphics '
'were out of this world. I would recommend this movie.')
predictions = model.predict(np.array([sample_text]))
2つ以上のLSTMレイヤーをスタックします
Keras再発層は、によって制御される2つの利用可能なモード持ってreturn_sequencesコンストラクタ引数を:
場合
False、各入力シーケンス(形状の2次元テンソル(BATCH_SIZE、output_features))のための唯一の最後の出力を返します。これはデフォルトで、前のモデルで使用されていました。もし
True各タイムステップのための連続出力の完全な配列(形状の三次元テンソル返される(batch_size, timesteps, output_features)
ここにあるものと同様の情報ルックスの流れreturn_sequences=True :
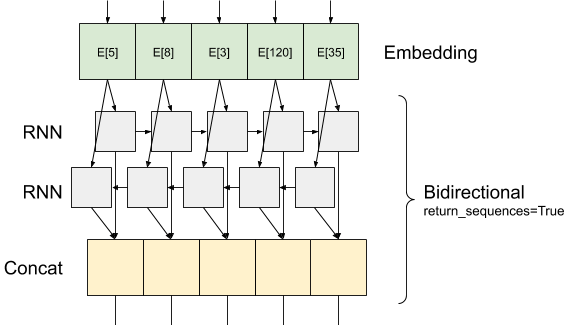
使用方法についての興味深いRNNしてreturn_sequences=Trueそれはこのように、他のRNN層に渡すことができるので、出力はまだ、入力のように、3軸を有することです。
model = tf.keras.Sequential([
encoder,
tf.keras.layers.Embedding(len(encoder.get_vocabulary()), 64, mask_zero=True),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64, return_sequences=True)),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(32)),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(1)
])
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(1e-4),
metrics=['accuracy'])
history = model.fit(train_dataset, epochs=10,
validation_data=test_dataset,
validation_steps=30)
Epoch 1/10 391/391 [==============================] - 71s 149ms/step - loss: 0.6502 - accuracy: 0.5625 - val_loss: 0.4923 - val_accuracy: 0.7573 Epoch 2/10 391/391 [==============================] - 55s 138ms/step - loss: 0.4067 - accuracy: 0.8198 - val_loss: 0.3727 - val_accuracy: 0.8271 Epoch 3/10 391/391 [==============================] - 54s 136ms/step - loss: 0.3417 - accuracy: 0.8543 - val_loss: 0.3343 - val_accuracy: 0.8510 Epoch 4/10 391/391 [==============================] - 53s 134ms/step - loss: 0.3242 - accuracy: 0.8607 - val_loss: 0.3268 - val_accuracy: 0.8568 Epoch 5/10 391/391 [==============================] - 53s 135ms/step - loss: 0.3174 - accuracy: 0.8652 - val_loss: 0.3213 - val_accuracy: 0.8516 Epoch 6/10 391/391 [==============================] - 52s 132ms/step - loss: 0.3098 - accuracy: 0.8671 - val_loss: 0.3294 - val_accuracy: 0.8547 Epoch 7/10 391/391 [==============================] - 53s 134ms/step - loss: 0.3063 - accuracy: 0.8697 - val_loss: 0.3158 - val_accuracy: 0.8594 Epoch 8/10 391/391 [==============================] - 52s 132ms/step - loss: 0.3043 - accuracy: 0.8692 - val_loss: 0.3184 - val_accuracy: 0.8521 Epoch 9/10 391/391 [==============================] - 53s 133ms/step - loss: 0.3016 - accuracy: 0.8704 - val_loss: 0.3208 - val_accuracy: 0.8609 Epoch 10/10 391/391 [==============================] - 54s 136ms/step - loss: 0.2975 - accuracy: 0.8740 - val_loss: 0.3301 - val_accuracy: 0.8651
test_loss, test_acc = model.evaluate(test_dataset)
print('Test Loss:', test_loss)
print('Test Accuracy:', test_acc)
391/391 [==============================] - 26s 65ms/step - loss: 0.3293 - accuracy: 0.8646 Test Loss: 0.329334557056427 Test Accuracy: 0.8646399974822998
# predict on a sample text without padding.
sample_text = ('The movie was not good. The animation and the graphics '
'were terrible. I would not recommend this movie.')
predictions = model.predict(np.array([sample_text]))
print(predictions)
[[-1.6796288]]
plt.figure(figsize=(16, 6))
plt.subplot(1, 2, 1)
plot_graphs(history, 'accuracy')
plt.subplot(1, 2, 2)
plot_graphs(history, 'loss')

以下のような他の既存の再発層チェックGRU層を。
カスタムのRNNを構築するにinterestiedしている場合、参照Keras RNNガイド。