
Khi dữ liệu của bạn nằm trong đường dẫn TFX, bạn có thể sử dụng các thành phần TFX để phân tích và chuyển đổi dữ liệu đó. Bạn có thể sử dụng những công cụ này ngay cả trước khi đào tạo mô hình.
Có nhiều lý do để phân tích và chuyển đổi dữ liệu của bạn:
- Để tìm ra vấn đề trong dữ liệu của bạn. Các vấn đề thường gặp bao gồm:
- Thiếu dữ liệu, chẳng hạn như các đối tượng địa lý có giá trị trống.
- Các nhãn được coi là các tính năng để mô hình của bạn có thể xem trước câu trả lời đúng trong quá trình đào tạo.
- Các tính năng có giá trị nằm ngoài phạm vi bạn mong đợi.
- Dữ liệu bất thường.
- Mô hình chuyển giao đã học có quá trình xử lý trước không khớp với dữ liệu huấn luyện.
- Để thiết kế các bộ tính năng hiệu quả hơn. Ví dụ: bạn có thể xác định:
- Đặc biệt là các tính năng thông tin.
- Tính năng dư thừa.
- Các tính năng có quy mô rất khác nhau đến mức chúng có thể làm chậm quá trình học tập.
- Các tính năng có ít hoặc không có thông tin dự đoán duy nhất.
Các công cụ TFX vừa có thể giúp tìm lỗi dữ liệu vừa hỗ trợ kỹ thuật tính năng.
Xác thực dữ liệu TensorFlow
Tổng quan
Xác thực dữ liệu TensorFlow xác định các điểm bất thường trong quá trình đào tạo và cung cấp dữ liệu, đồng thời có thể tự động tạo lược đồ bằng cách kiểm tra dữ liệu. Thành phần này có thể được cấu hình để phát hiện các loại bất thường khác nhau trong dữ liệu. Nó có thể
- Thực hiện kiểm tra tính hợp lệ bằng cách so sánh số liệu thống kê dữ liệu với lược đồ mã hóa các kỳ vọng của người dùng.
- Phát hiện độ lệch phục vụ đào tạo bằng cách so sánh các ví dụ trong dữ liệu đào tạo và phục vụ.
- Phát hiện sự trôi dạt dữ liệu bằng cách xem xét một loạt dữ liệu.
Chúng tôi ghi lại từng chức năng này một cách độc lập:
Xác thực ví dụ dựa trên lược đồ
Xác thực dữ liệu TensorFlow xác định mọi điểm bất thường trong dữ liệu đầu vào bằng cách so sánh số liệu thống kê dữ liệu với lược đồ. Lược đồ mã hóa các thuộc tính mà dữ liệu đầu vào dự kiến sẽ đáp ứng, chẳng hạn như kiểu dữ liệu hoặc giá trị phân loại và người dùng có thể sửa đổi hoặc thay thế.
Xác thực dữ liệu Tensorflow thường được gọi nhiều lần trong bối cảnh của đường dẫn TFX: (i) cho mỗi phần tách thu được từ exampleGen, (ii) cho tất cả dữ liệu được chuyển đổi trước được Transform sử dụng và (iii) cho tất cả dữ liệu sau chuyển đổi được tạo bởi Biến đổi. Khi được gọi trong ngữ cảnh Chuyển đổi (ii-iii), các tùy chọn thống kê và các ràng buộc dựa trên lược đồ có thể được đặt bằng cách xác định stats_options_updater_fn . Điều này đặc biệt hữu ích khi xác thực dữ liệu phi cấu trúc (ví dụ: các tính năng văn bản). Xem mã người dùng để biết ví dụ.
Tính năng lược đồ nâng cao
Phần này bao gồm cấu hình lược đồ nâng cao hơn có thể trợ giúp với các thiết lập đặc biệt.
Tính năng thưa thớt
Việc mã hóa các tính năng thưa thớt trong Ví dụ thường giới thiệu nhiều Tính năng được mong đợi có cùng giá trị cho tất cả các Ví dụ. Ví dụ: tính năng thưa thớt:
WeightedCategories = [('CategoryA', 0.3), ('CategoryX', 0.7)]
WeightedCategoriesIndex = ['CategoryA', 'CategoryX']
WeightedCategoriesValue = [0.3, 0.7]
sparse_feature {
name: 'WeightedCategories'
index_feature { name: 'WeightedCategoriesIndex' }
value_feature { name: 'WeightedCategoriesValue' }
}
Định nghĩa đối tượng thưa thớt yêu cầu một hoặc nhiều chỉ mục và một đối tượng giá trị đề cập đến các đối tượng tồn tại trong lược đồ. Việc xác định rõ ràng các tính năng thưa thớt cho phép TFDV kiểm tra xem giá trị của tất cả các tính năng được giới thiệu có khớp hay không.
Một số trường hợp sử dụng đưa ra các hạn chế về giá trị tương tự giữa các Tính năng, nhưng không nhất thiết phải mã hóa một tính năng thưa thớt. Sử dụng tính năng thưa thớt sẽ bỏ chặn bạn, nhưng không lý tưởng.
Môi trường lược đồ
Theo mặc định, việc xác thực giả định rằng tất cả các Ví dụ trong một quy trình đều tuân thủ một lược đồ duy nhất. Trong một số trường hợp, việc giới thiệu các biến thể lược đồ nhỏ là cần thiết, chẳng hạn như các tính năng được sử dụng làm nhãn là bắt buộc trong quá trình đào tạo (và phải được xác thực) nhưng lại bị thiếu trong quá trình cung cấp. Môi trường có thể được sử dụng để thể hiện các yêu cầu như vậy, cụ thể là default_environment() , in_environment() , not_in_environment() .
Ví dụ: giả sử một tính năng có tên 'LABEL' là bắt buộc để đào tạo nhưng dự kiến sẽ bị thiếu khi phân phát. Điều này có thể được thể hiện bằng:
- Xác định hai môi trường riêng biệt trong lược đồ: ["SERVING", "ĐÀO TẠO"] và chỉ liên kết 'LABEL' với môi trường "ĐÀO TẠO".
- Liên kết dữ liệu huấn luyện với môi trường "ĐÀO TẠO" và dữ liệu phục vụ với môi trường "PHỤC VỤ".
Tạo lược đồ
Lược đồ dữ liệu đầu vào được chỉ định làm một phiên bản của Lược đồ TensorFlow.
Thay vì xây dựng lược đồ theo cách thủ công từ đầu, nhà phát triển có thể dựa vào việc xây dựng lược đồ tự động của Xác thực dữ liệu TensorFlow. Cụ thể, Xác thực dữ liệu TensorFlow tự động xây dựng lược đồ ban đầu dựa trên số liệu thống kê được tính toán trên dữ liệu đào tạo có sẵn trong quy trình. Người dùng có thể chỉ cần xem lại lược đồ được tạo tự động này, sửa đổi nó khi cần, kiểm tra nó vào hệ thống kiểm soát phiên bản và đẩy nó một cách rõ ràng vào quy trình để xác thực thêm.
TFDV bao gồm infer_schema() để tự động tạo lược đồ. Ví dụ:
schema = tfdv.infer_schema(statistics=train_stats)
tfdv.display_schema(schema=schema)
Điều này kích hoạt việc tạo lược đồ tự động dựa trên các quy tắc sau:
Nếu một lược đồ đã được tạo tự động thì nó sẽ được sử dụng như cũ.
Mặt khác, Xác thực dữ liệu TensorFlow sẽ kiểm tra số liệu thống kê dữ liệu có sẵn và tính toán lược đồ phù hợp cho dữ liệu.
Lưu ý: Lược đồ được tạo tự động là nỗ lực tốt nhất và chỉ cố gắng suy ra các thuộc tính cơ bản của dữ liệu. Rất mong người dùng xem xét và sửa đổi khi cần thiết.
Phát hiện sai lệch đào tạo-phục vụ
Tổng quan
Xác thực dữ liệu TensorFlow có thể phát hiện độ lệch phân phối giữa dữ liệu đào tạo và phân phối. Độ lệch phân phối xảy ra khi việc phân phối các giá trị đặc trưng cho dữ liệu huấn luyện khác biệt đáng kể so với việc phân phối dữ liệu. Một trong những nguyên nhân chính gây ra sai lệch phân phối là sử dụng một kho dữ liệu hoàn toàn khác để tạo dữ liệu huấn luyện nhằm khắc phục tình trạng thiếu dữ liệu ban đầu trong kho dữ liệu mong muốn. Một lý do khác là cơ chế lấy mẫu bị lỗi, chỉ chọn một mẫu phụ của dữ liệu phân phát để huấn luyện.
Kịch bản ví dụ
Xem Hướng dẫn bắt đầu xác thực dữ liệu TensorFlow để biết thông tin về cách định cấu hình phát hiện độ lệch phục vụ đào tạo.
Phát hiện trôi dạt
Tính năng phát hiện độ lệch được hỗ trợ giữa các khoảng dữ liệu liên tiếp (tức là giữa khoảng N và khoảng N+1), chẳng hạn như giữa các ngày khác nhau của dữ liệu huấn luyện. Chúng tôi biểu thị sự trôi dạt theo khoảng cách L-vô cực cho các đặc điểm phân loại và độ phân kỳ Jensen-Shannon gần đúng cho các đặc điểm số. Bạn có thể đặt khoảng cách ngưỡng để nhận được cảnh báo khi độ lệch cao hơn mức chấp nhận được. Việc đặt khoảng cách chính xác thường là một quá trình lặp đi lặp lại đòi hỏi phải có kiến thức và thử nghiệm về miền.
Xem Hướng dẫn bắt đầu xác thực dữ liệu TensorFlow để biết thông tin về cách định cấu hình phát hiện sai lệch.
Sử dụng hình ảnh trực quan để kiểm tra dữ liệu của bạn
Xác thực dữ liệu TensorFlow cung cấp các công cụ để trực quan hóa việc phân phối các giá trị tính năng. Bằng cách kiểm tra các bản phân phối này trong sổ ghi chép Jupyter bằng Facets, bạn có thể nắm bắt được các sự cố thường gặp với dữ liệu.
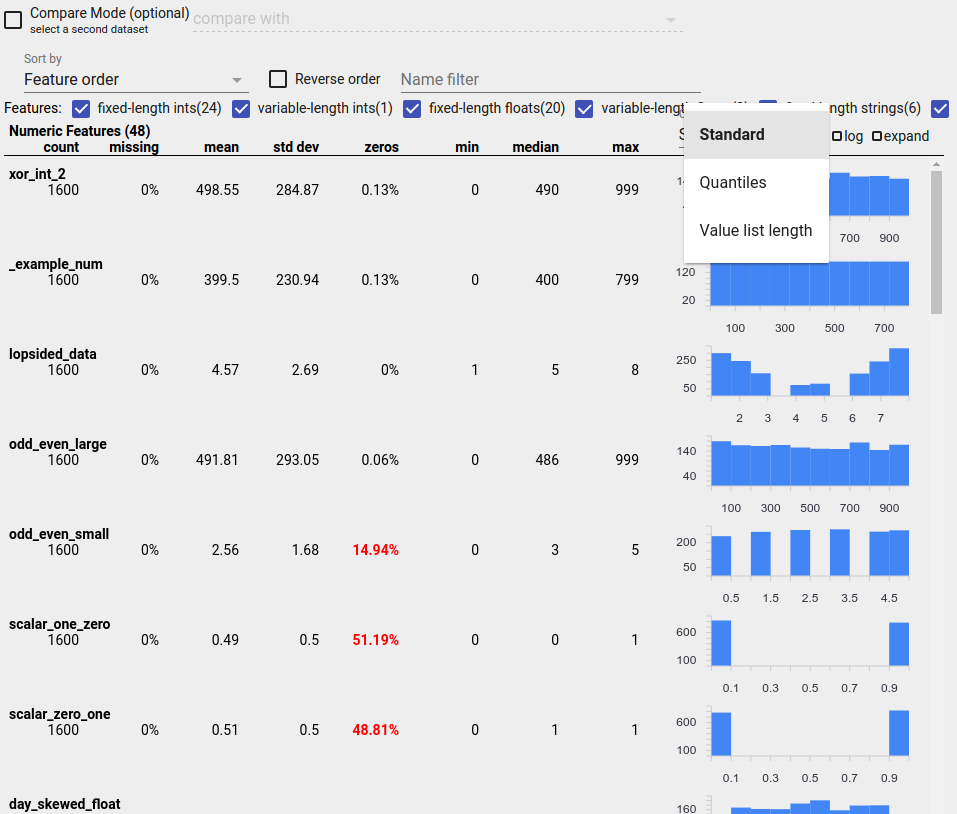
Xác định các bản phân phối đáng ngờ
Bạn có thể xác định các lỗi phổ biến trong dữ liệu của mình bằng cách sử dụng màn hình Tổng quan về các khía cạnh để tìm kiếm các phân phối đáng ngờ của các giá trị đối tượng.
Dữ liệu không cân bằng
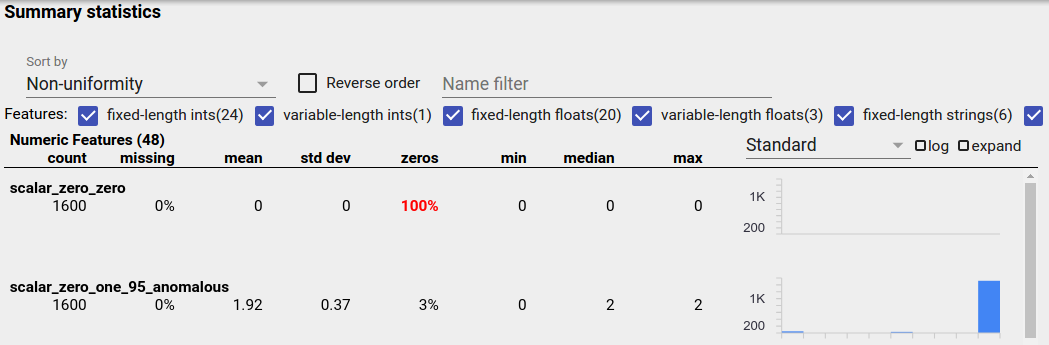
Đặc điểm không cân bằng là đặc điểm mà một giá trị chiếm ưu thế. Các tính năng không cân bằng có thể xảy ra một cách tự nhiên, nhưng nếu một tính năng luôn có cùng giá trị thì bạn có thể gặp lỗi dữ liệu. Để phát hiện các tính năng không cân bằng trong Tổng quan về khía cạnh, hãy chọn "Không đồng nhất" từ menu thả xuống "Sắp xếp theo".
Các tính năng không cân bằng nhất sẽ được liệt kê ở đầu mỗi danh sách loại tính năng. Ví dụ: ảnh chụp màn hình sau đây hiển thị một tính năng hoàn toàn bằng 0 và một tính năng thứ hai rất mất cân bằng, ở đầu danh sách "Tính năng số":
Dữ liệu được phân phối đồng đều
Đặc điểm được phân bố đồng đều là đặc điểm mà tất cả các giá trị có thể xuất hiện với tần số gần như nhau. Đối với dữ liệu không cân bằng, sự phân phối này có thể xảy ra một cách tự nhiên nhưng cũng có thể do lỗi dữ liệu tạo ra.
Để phát hiện các tính năng được phân phối đồng đều trong Tổng quan về các khía cạnh, hãy chọn "Không đồng nhất" từ danh sách thả xuống "Sắp xếp theo" và chọn hộp kiểm "Thứ tự đảo ngược":
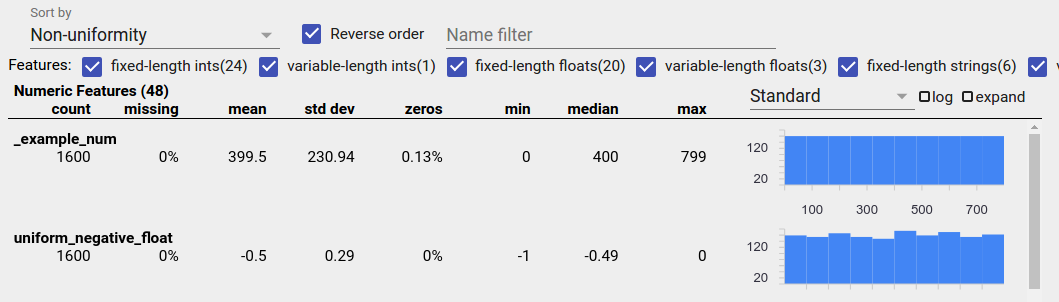
Dữ liệu chuỗi được biểu thị bằng biểu đồ thanh nếu có 20 giá trị duy nhất trở xuống và dưới dạng biểu đồ phân phối tích lũy nếu có hơn 20 giá trị duy nhất. Vì vậy, đối với dữ liệu chuỗi, các phân bố đồng đều có thể xuất hiện dưới dạng biểu đồ thanh phẳng như biểu đồ ở trên hoặc các đường thẳng như biểu đồ bên dưới:

Lỗi có thể tạo ra dữ liệu được phân phối đồng đều
Dưới đây là một số lỗi phổ biến có thể tạo ra dữ liệu được phân phối đồng đều:
Sử dụng chuỗi để biểu diễn các kiểu dữ liệu không phải chuỗi, chẳng hạn như ngày tháng. Ví dụ: bạn sẽ có nhiều giá trị duy nhất cho tính năng ngày giờ với các biểu thị như "2017-03-01-11-45-03". Các giá trị duy nhất sẽ được phân phối đồng đều.
Bao gồm các chỉ số như "số hàng" làm tính năng. Ở đây một lần nữa bạn có nhiều giá trị độc đáo.
Thiếu dữ liệu
Để kiểm tra xem một tính năng có thiếu hoàn toàn các giá trị hay không:
- Chọn "Số lượng còn thiếu/không" từ menu thả xuống "Sắp xếp theo".
- Chọn hộp kiểm "Đảo ngược thứ tự".
- Nhìn vào cột "thiếu" để biết tỷ lệ phần trăm các trường hợp có giá trị bị thiếu cho một đối tượng địa lý.
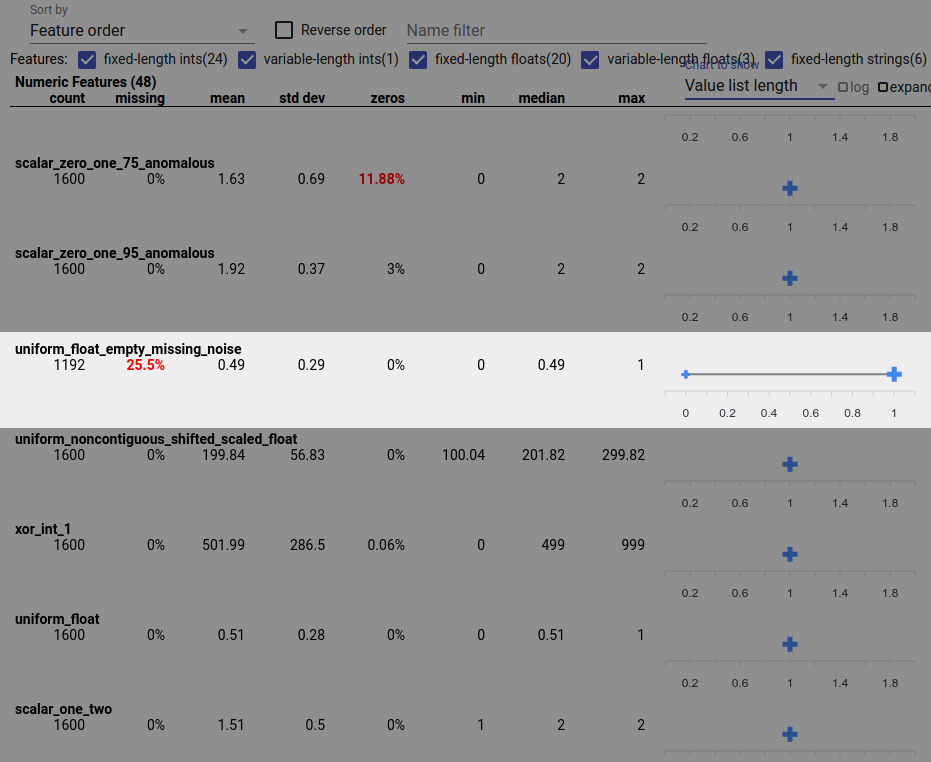
Lỗi dữ liệu cũng có thể khiến giá trị tính năng không đầy đủ. Ví dụ: bạn có thể mong đợi danh sách giá trị của đối tượng luôn có ba phần tử và phát hiện ra rằng đôi khi nó chỉ có một phần tử. Để kiểm tra các giá trị không đầy đủ hoặc các trường hợp khác trong đó danh sách giá trị đối tượng không có số phần tử như mong đợi:
Chọn "Độ dài danh sách giá trị" từ menu thả xuống "Biểu đồ để hiển thị" ở bên phải.
Nhìn vào biểu đồ bên phải của mỗi hàng tính năng. Biểu đồ hiển thị phạm vi độ dài danh sách giá trị cho đối tượng địa lý. Ví dụ: hàng được đánh dấu trong ảnh chụp màn hình bên dưới hiển thị một tính năng có một số danh sách giá trị có độ dài bằng 0:
Sự khác biệt lớn về quy mô giữa các tính năng
Nếu các đặc điểm của bạn có quy mô khác nhau thì mô hình có thể gặp khó khăn khi học. Ví dụ: nếu một số tính năng thay đổi từ 0 đến 1 và các tính năng khác thay đổi từ 0 đến 1.000.000.000 thì bạn có sự khác biệt lớn về quy mô. So sánh các cột "tối đa" và "tối thiểu" giữa các đối tượng để tìm các tỷ lệ khác nhau.
Hãy cân nhắc việc chuẩn hóa các giá trị đặc trưng để giảm bớt những biến thể lớn này.
Nhãn có nhãn không hợp lệ
Công cụ ước tính của TensorFlow có các hạn chế về loại dữ liệu mà chúng chấp nhận làm nhãn. Ví dụ: bộ phân loại nhị phân thường chỉ hoạt động với nhãn {0, 1}.
Xem lại các giá trị nhãn trong Tổng quan về khía cạnh và đảm bảo chúng tuân thủ các yêu cầu của Công cụ ước tính .