
拡張されたTensorFlowの主要コンポーネントの例
 GitHubでソースを表示
GitHubでソースを表示このコラボノートブックの例は、TensorFlow Data Validation(TFDV)を使用してデータセットを調査および視覚化する方法を示しています。これには、記述統計の確認、スキーマの推測、異常のチェックと修正、データセットのドリフトとスキューのチェックが含まれます。データセットの特性を理解することが重要です。これには、本番パイプラインで時間の経過とともにどのように変化する可能性があるかなどが含まれます。また、データの異常を探し、トレーニング、評価、および提供データセットを比較して、それらが一貫していることを確認することも重要です。
シカゴ市がリリースしたタクシートリップデータセットのデータを使用します。
GoogleBigQueryのデータセットの詳細をご覧ください。 BigQueryUIで完全なデータセットを調べます。
データセットの列は次のとおりです。
| Pickup_community_area | 運賃 | trip_start_month |
| trip_start_hour | trip_start_day | trip_start_timestamp |
| Pickup_latitude | Pickup_longitude | dropoff_latitude |
| dropoff_longitude | trip_miles | Pickup_census_tract |
| dropoff_census_tract | 支払いタイプ | 会社 |
| trip_seconds | dropoff_community_area | チップ |
パッケージをインストールしてインポートする
TensorFlowデータ検証用のパッケージをインストールします。
アップグレードピップ
ローカルで実行しているときにシステムでPipをアップグレードしないようにするには、Colabで実行していることを確認してください。もちろん、ローカルシステムは個別にアップグレードできます。
try:
import colab
!pip install --upgrade pip
except:
pass
データ検証パッケージをインストールする
TensorFlow DataValidationパッケージと依存関係をインストールします。これには数分かかります。互換性のない依存関係バージョンに関する警告とエラーが表示される場合があります。これについては、次のセクションで解決します。
print('Installing TensorFlow Data Validation')
!pip install --upgrade 'tensorflow_data_validation[visualization]<2'
TensorFlowをインポートし、更新されたパッケージをリロードします
前の手順では、Gooogle Colab環境のデフォルトパッケージが更新されるため、新しい依存関係を解決するには、パッケージリソースをリロードする必要があります。
import pkg_resources
import importlib
importlib.reload(pkg_resources)
<module 'pkg_resources' from '/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py'>
続行する前に、TensorFlowのバージョンとデータ検証を確認してください。
import tensorflow as tf
import tensorflow_data_validation as tfdv
print('TF version:', tf.__version__)
print('TFDV version:', tfdv.version.__version__)
TF version: 2.7.0 TFDV version: 1.5.0
データセットをロードする
Google CloudStorageからデータセットをダウンロードします。
import os
import tempfile, urllib, zipfile
# Set up some globals for our file paths
BASE_DIR = tempfile.mkdtemp()
DATA_DIR = os.path.join(BASE_DIR, 'data')
OUTPUT_DIR = os.path.join(BASE_DIR, 'chicago_taxi_output')
TRAIN_DATA = os.path.join(DATA_DIR, 'train', 'data.csv')
EVAL_DATA = os.path.join(DATA_DIR, 'eval', 'data.csv')
SERVING_DATA = os.path.join(DATA_DIR, 'serving', 'data.csv')
# Download the zip file from GCP and unzip it
zip, headers = urllib.request.urlretrieve('https://storage.googleapis.com/artifacts.tfx-oss-public.appspot.com/datasets/chicago_data.zip')
zipfile.ZipFile(zip).extractall(BASE_DIR)
zipfile.ZipFile(zip).close()
print("Here's what we downloaded:")
!ls -R {os.path.join(BASE_DIR, 'data')}
Here's what we downloaded: /tmp/tmp_waiqx43/data: eval serving train /tmp/tmp_waiqx43/data/eval: data.csv /tmp/tmp_waiqx43/data/serving: data.csv /tmp/tmp_waiqx43/data/train: data.csv
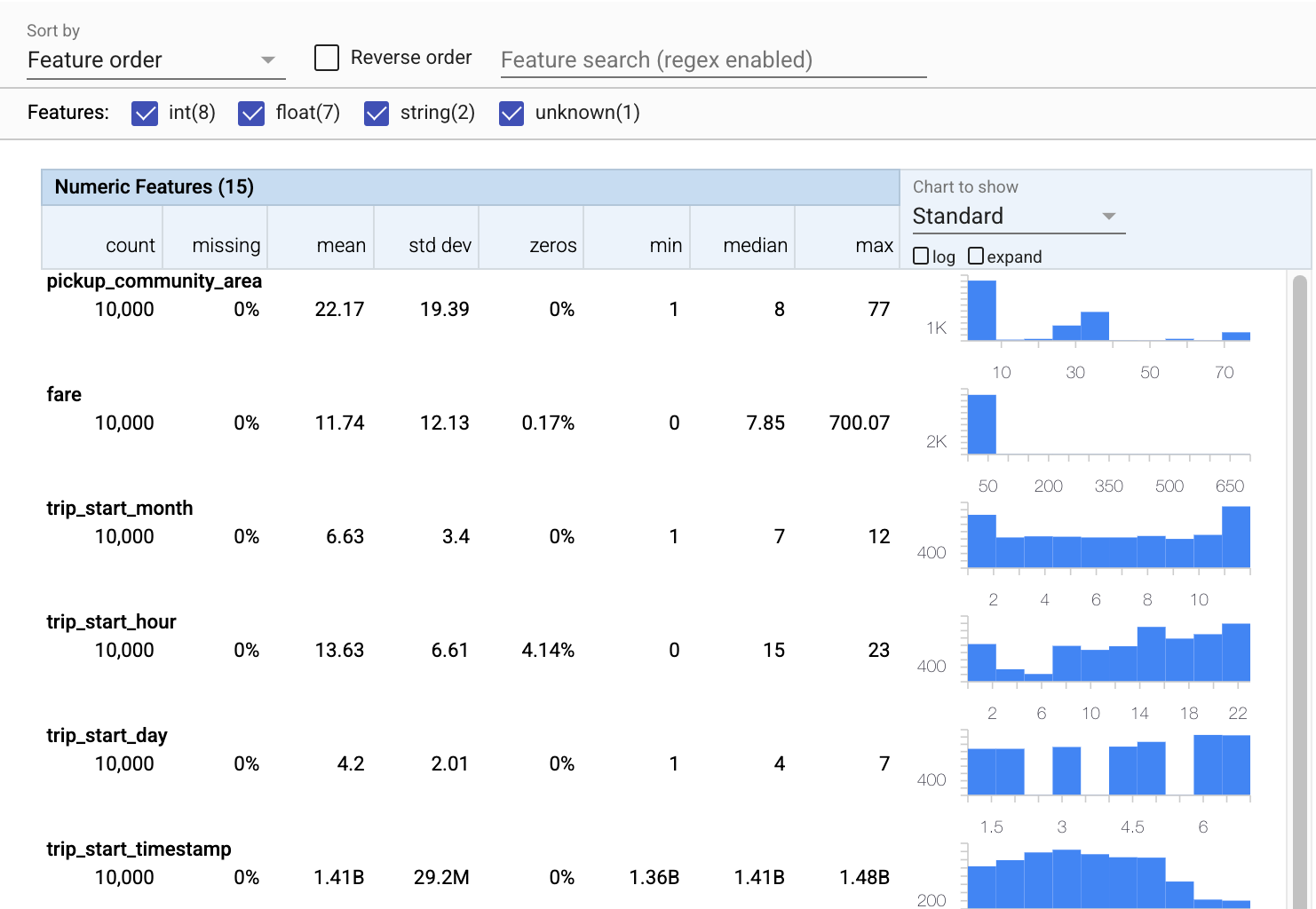
統計の計算と視覚化
まず、 tfdv.generate_statistics_from_csvを使用して、トレーニングデータの統計を計算します。 (きびきびとした警告は無視してください)
TFDVは、存在する機能とその値の分布の形状に関してデータの概要をすばやく提供する記述統計を計算できます。
内部的には、TFDVはApache Beamのデータ並列処理フレームワークを使用して、大規模なデータセットの統計計算をスケーリングします。 TFDVとより深く統合したいアプリケーション(たとえば、データ生成パイプラインの最後に統計生成をアタッチする)の場合、APIは統計生成用のBeamPTransformも公開します。
train_stats = tfdv.generate_statistics_from_csv(data_location=TRAIN_DATA)
WARNING:apache_beam.runners.interactive.interactive_environment:Dependencies required for Interactive Beam PCollection visualization are not available, please use: `pip install apache-beam[interactive]` to install necessary dependencies to enable all data visualization features. WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter. WARNING:apache_beam.io.tfrecordio:Couldn't find python-snappy so the implementation of _TFRecordUtil._masked_crc32c is not as fast as it could be. WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_data_validation/utils/stats_util.py:246: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)` WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow_data_validation/utils/stats_util.py:246: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)`
次に、ファセットを使用してトレーニングデータの簡潔な視覚化を作成するtfdv.visualize_statisticsを使用しましょう。
- 数値の特徴とカテゴリの特徴が別々に視覚化され、各特徴の分布を示すグラフが表示されていることに注意してください。
- 値が欠落しているかゼロの機能は、それらの機能の例に問題がある可能性があることを視覚的に示すために、パーセンテージを赤で表示することに注意してください。パーセンテージは、その機能の値が欠落しているかゼロである例のパーセンテージです。
-
pickup_census_tractの値を持つ例がないことに注意してください。これは次元削減の機会です! - グラフの上にある[展開]をクリックして、表示を変更してみてください
- グラフのバーにカーソルを合わせて、バケットの範囲とカウントを表示してみてください
- 対数スケールと線形スケールを切り替えてみて、ログスケールが
payment_typeカテゴリ機能に関する詳細をどのように明らかにするかに注目してください。 - [表示するグラフ]メニューから[分位数]を選択し、マーカーにカーソルを合わせて分位数のパーセンテージを表示してみてください
# docs-infra: no-execute
tfdv.visualize_statistics(train_stats)
スキーマを推測する
次に、 tfdv.infer_schemaを使用して、データのスキーマを作成しましょう。スキーマは、MLに関連するデータの制約を定義します。制約の例には、各機能のデータ型(数値かカテゴリか)、またはデータ内に存在する頻度が含まれます。カテゴリ機能の場合、スキーマはドメイン(受け入れ可能な値のリスト)も定義します。スキーマの作成は、特に多くの機能を備えたデータセットの場合、面倒な作業になる可能性があるため、TFDVは、記述統計に基づいてスキーマの初期バージョンを生成する方法を提供します。
スキーマを正しく取得することは重要です。これは、本番パイプラインの残りの部分が、TFDVが生成するスキーマが正しいことに依存するためです。スキーマはデータのドキュメントも提供するため、異なる開発者が同じデータで作業する場合に役立ちます。 tfdv.display_schemaを使用して、推測されたスキーマを表示し、確認できるようにします。
schema = tfdv.infer_schema(statistics=train_stats)
tfdv.display_schema(schema=schema)
評価データにエラーがないか確認してください
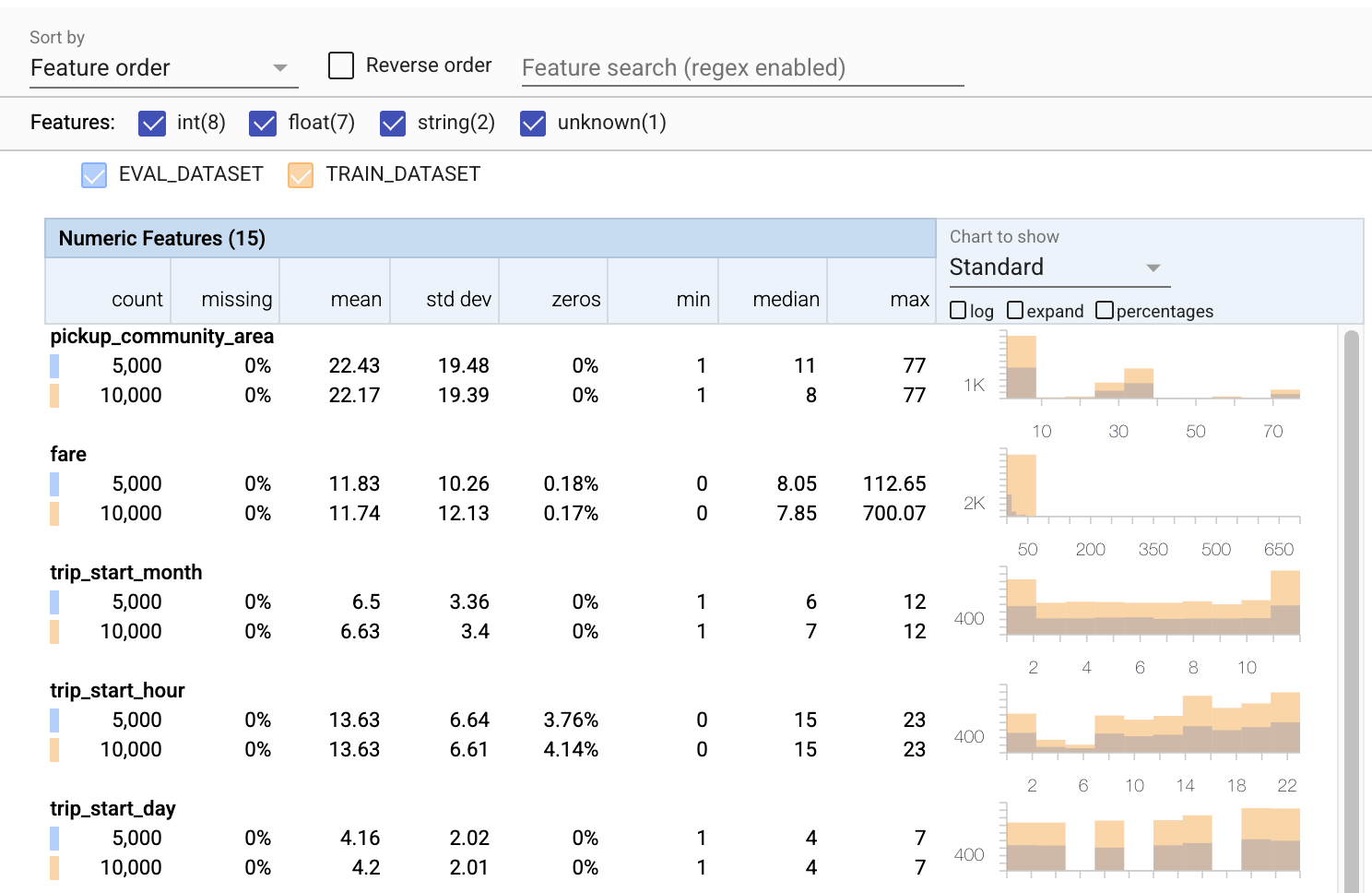
これまでは、トレーニングデータのみを確認してきました。同じスキーマを使用していることを含め、評価データがトレーニングデータと一致していることが重要です。また、評価データに、トレーニングデータとほぼ同じ数値特徴の値の例が含まれていることも重要です。これにより、評価中の損失面のカバレッジは、トレーニング中とほぼ同じになります。カテゴリ機能についても同じことが言えます。そうしないと、損失面の一部を評価しなかったため、評価中に特定されないトレーニングの問題が発生する可能性があります。
- 各機能に、トレーニングデータセットと評価データセットの両方の統計が含まれていることに注意してください。
- チャートにトレーニングデータセットと評価データセットの両方がオーバーレイされ、それらを簡単に比較できるようになっていることに注意してください。
- チャートにパーセンテージビューが含まれていることに注意してください。これは、ログまたはデフォルトの線形スケールと組み合わせることができます。
-
trip_milesの平均と中央値は、トレーニングデータセットと評価データセットで異なることに注意してください。それは問題を引き起こしますか? - うわー、最大の
tipsは、トレーニングデータセットと評価データセットで大きく異なります。それは問題を引き起こしますか? - 数値機能チャートで展開をクリックし、対数スケールを選択します。
trip_seconds機能を確認し、最大値の違いに注意してください。評価は損失面の一部を見逃しますか?
# Compute stats for evaluation data
eval_stats = tfdv.generate_statistics_from_csv(data_location=EVAL_DATA)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
# docs-infra: no-execute
# Compare evaluation data with training data
tfdv.visualize_statistics(lhs_statistics=eval_stats, rhs_statistics=train_stats,
lhs_name='EVAL_DATASET', rhs_name='TRAIN_DATASET')
評価の異常をチェックする
評価データセットは、トレーニングデータセットのスキーマと一致していますか?これは、許容値の範囲を特定するカテゴリ機能にとって特に重要です。
# Check eval data for errors by validating the eval data stats using the previously inferred schema.
anomalies = tfdv.validate_statistics(statistics=eval_stats, schema=schema)
tfdv.display_anomalies(anomalies)
スキーマの評価の異常を修正する
おっとっと!評価データには、トレーニングデータにはなかった、 companyの新しい価値がいくつかあるようです。また、 payment_typeの新しい値があります。これらは異常と見なす必要がありますが、それらについて何をするかは、データに関するドメイン知識によって異なります。異常が本当にデータエラーを示している場合は、基になるデータを修正する必要があります。それ以外の場合は、スキーマを更新して、evalデータセットに値を含めることができます。
評価データセットを変更しない限り、すべてを修正することはできませんが、受け入れやすいスキーマで修正することはできます。これには、特定の機能の異常とは何かという見方を緩和することや、カテゴリ機能の欠落値を含めるようにスキーマを更新することが含まれます。 TFDVにより、修正が必要なものを見つけることができました。
今すぐこれらの修正を行ってから、もう一度確認してみましょう。
# Relax the minimum fraction of values that must come from the domain for feature company.
company = tfdv.get_feature(schema, 'company')
company.distribution_constraints.min_domain_mass = 0.9
# Add new value to the domain of feature payment_type.
payment_type_domain = tfdv.get_domain(schema, 'payment_type')
payment_type_domain.value.append('Prcard')
# Validate eval stats after updating the schema
updated_anomalies = tfdv.validate_statistics(eval_stats, schema)
tfdv.display_anomalies(updated_anomalies)
ねえ、それを見て!トレーニングと評価のデータに一貫性があることを確認しました。ありがとうTFDV;)
スキーマ環境
この例では「サービング」データセットも分割しているので、それも確認する必要があります。デフォルトでは、パイプライン内のすべてのデータセットは同じスキーマを使用する必要がありますが、多くの場合、例外があります。たとえば、教師あり学習では、データセットにラベルを含める必要がありますが、推論用のモデルを提供する場合、ラベルは含まれません。場合によっては、わずかなスキーマのバリエーションを導入する必要があります。
環境は、そのような要件を表現するために使用できます。特に、スキーマの機能は、 default_environment 、 in_environment 、およびnot_in_environmentを使用して一連の環境に関連付けることができます。
たとえば、このデータセットでは、 tips機能がトレーニングのラベルとして含まれていますが、提供データには含まれていません。環境を指定しないと、異常として表示されます。
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.プレースホルダー19
以下のtips機能を扱います。また、トリップ秒にはINT値があり、スキーマはFLOATを期待していました。 TFDVは、その違いを認識させることで、トレーニングと提供のためにデータを生成する方法の不一致を明らかにするのに役立ちます。モデルのパフォーマンスが低下するまで、時には壊滅的に、そのような問題に気付かないのは非常に簡単です。これは重大な問題である場合とそうでない場合がありますが、いずれにせよ、これはさらなる調査の原因となるはずです。
この場合、INT値をFLOATに安全に変換できるため、TFDVにスキーマを使用して型を推測するように指示します。今それをしましょう。
options = tfdv.StatsOptions(schema=schema, infer_type_from_schema=True)
serving_stats = tfdv.generate_statistics_from_csv(SERVING_DATA, stats_options=options)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)
tfdv.display_anomalies(serving_anomalies)
WARNING:root:Make sure that locally built Python SDK docker image has Python 3.7 interpreter.
これで、 tips機能(ラベル)が異常として表示されます(「列が削除されました」)。もちろん、提供するデータにラベルが含まれることは想定されていないため、TFDVにそれを無視するように指示しましょう。
# All features are by default in both TRAINING and SERVING environments.
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
# Specify that 'tips' feature is not in SERVING environment.
tfdv.get_feature(schema, 'tips').not_in_environment.append('SERVING')
serving_anomalies_with_env = tfdv.validate_statistics(
serving_stats, schema, environment='SERVING')
tfdv.display_anomalies(serving_anomalies_with_env)
ドリフトとスキューを確認します
データセットがスキーマで設定された期待値に準拠しているかどうかをチェックすることに加えて、TFDVはドリフトとスキューを検出する機能も提供します。 TFDVは、スキーマで指定されたドリフト/スキューコンパレータに基づいてさまざまなデータセットの統計を比較することにより、このチェックを実行します。
ドリフト
ドリフト検出は、カテゴリ機能、およびトレーニングデータの異なる日の間など、データの連続するスパン間(つまり、スパンNとスパンN + 1の間)でサポートされます。ドリフトはL-無限距離で表され、ドリフトが許容範囲を超えたときに警告を受け取るようにしきい値距離を設定できます。正しい距離を設定することは、通常、ドメインの知識と実験を必要とする反復プロセスです。
斜め
TFDVは、データ内の3種類のスキュー(スキーマスキュー、機能スキュー、および分布スキュー)を検出できます。
スキーマスキュー
スキーマスキューは、トレーニングデータとサービングデータが同じスキーマに準拠していない場合に発生します。トレーニングデータとサービスデータの両方が同じスキーマに準拠することが期待されます。 2つの間に予想される偏差(ラベル機能はトレーニングデータにのみ存在し、サービングには存在しないなど)は、スキーマの環境フィールドを介して指定する必要があります。
機能スキュー
特徴スキューは、モデルがトレーニングする特徴値が、提供時に表示される特徴値と異なる場合に発生します。たとえば、これは次の場合に発生する可能性があります。
- いくつかの特徴値を提供するデータソースは、トレーニングと提供時間の間で変更されます
- トレーニングとサービングの間で機能を生成するための異なるロジックがあります。たとえば、2つのコードパスのいずれかでのみ変換を適用する場合です。
分布スキュー
分布スキューは、トレーニングデータセットの分布がサービングデータセットの分布と大幅に異なる場合に発生します。分布スキューの主な原因の1つは、トレーニングデータセットを生成するために異なるコードまたは異なるデータソースを使用することです。もう1つの理由は、トレーニングするサービングデータの代表的でないサブサンプルを選択するサンプリングメカニズムの欠陥です。
# Add skew comparator for 'payment_type' feature.
payment_type = tfdv.get_feature(schema, 'payment_type')
payment_type.skew_comparator.infinity_norm.threshold = 0.01
# Add drift comparator for 'company' feature.
company=tfdv.get_feature(schema, 'company')
company.drift_comparator.infinity_norm.threshold = 0.001
skew_anomalies = tfdv.validate_statistics(train_stats, schema,
previous_statistics=eval_stats,
serving_statistics=serving_stats)
tfdv.display_anomalies(skew_anomalies)
この例では、多少のドリフトが見られますが、設定したしきい値をはるかに下回っています。
スキーマをフリーズします
スキーマがレビューおよびキュレートされたので、「凍結」状態を反映するようにスキーマをファイルに保存します。
from tensorflow.python.lib.io import file_io
from google.protobuf import text_format
file_io.recursive_create_dir(OUTPUT_DIR)
schema_file = os.path.join(OUTPUT_DIR, 'schema.pbtxt')
tfdv.write_schema_text(schema, schema_file)
!cat {schema_file}
feature {
name: "pickup_community_area"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "fare"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_month"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_hour"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_day"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "trip_start_timestamp"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_latitude"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_longitude"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "dropoff_latitude"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_count: 1
}
}
feature {
name: "dropoff_longitude"
value_count {
min: 1
max: 1
}
type: FLOAT
presence {
min_count: 1
}
}
feature {
name: "trip_miles"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "pickup_census_tract"
type: BYTES
presence {
min_count: 0
}
}
feature {
name: "dropoff_census_tract"
value_count {
min: 1
max: 1
}
type: INT
presence {
min_count: 1
}
}
feature {
name: "payment_type"
type: BYTES
domain: "payment_type"
presence {
min_fraction: 1.0
min_count: 1
}
skew_comparator {
infinity_norm {
threshold: 0.01
}
}
shape {
dim {
size: 1
}
}
}
feature {
name: "company"
value_count {
min: 1
max: 1
}
type: BYTES
domain: "company"
presence {
min_count: 1
}
distribution_constraints {
min_domain_mass: 0.9
}
drift_comparator {
infinity_norm {
threshold: 0.001
}
}
}
feature {
name: "trip_seconds"
type: INT
presence {
min_fraction: 1.0
min_count: 1
}
shape {
dim {
size: 1
}
}
}
feature {
name: "dropoff_community_area"
value_count {
min: 1
max: 1
}
type: INT
presence {
min_count: 1
}
}
feature {
name: "tips"
type: FLOAT
presence {
min_fraction: 1.0
min_count: 1
}
not_in_environment: "SERVING"
shape {
dim {
size: 1
}
}
}
string_domain {
name: "payment_type"
value: "Cash"
value: "Credit Card"
value: "Dispute"
value: "No Charge"
value: "Pcard"
value: "Unknown"
value: "Prcard"
}
string_domain {
name: "company"
value: "0118 - 42111 Godfrey S.Awir"
value: "0694 - 59280 Chinesco Trans Inc"
value: "1085 - 72312 N and W Cab Co"
value: "2733 - 74600 Benny Jona"
value: "2809 - 95474 C & D Cab Co Inc."
value: "3011 - 66308 JBL Cab Inc."
value: "3152 - 97284 Crystal Abernathy"
value: "3201 - C&D Cab Co Inc"
value: "3201 - CID Cab Co Inc"
value: "3253 - 91138 Gaither Cab Co."
value: "3385 - 23210 Eman Cab"
value: "3623 - 72222 Arrington Enterprises"
value: "3897 - Ilie Malec"
value: "4053 - Adwar H. Nikola"
value: "4197 - 41842 Royal Star"
value: "4615 - 83503 Tyrone Henderson"
value: "4615 - Tyrone Henderson"
value: "4623 - Jay Kim"
value: "5006 - 39261 Salifu Bawa"
value: "5006 - Salifu Bawa"
value: "5074 - 54002 Ahzmi Inc"
value: "5074 - Ahzmi Inc"
value: "5129 - 87128"
value: "5129 - 98755 Mengisti Taxi"
value: "5129 - Mengisti Taxi"
value: "5724 - KYVI Cab Inc"
value: "585 - Valley Cab Co"
value: "5864 - 73614 Thomas Owusu"
value: "5864 - Thomas Owusu"
value: "5874 - 73628 Sergey Cab Corp."
value: "5997 - 65283 AW Services Inc."
value: "5997 - AW Services Inc."
value: "6488 - 83287 Zuha Taxi"
value: "6743 - Luhak Corp"
value: "Blue Ribbon Taxi Association Inc."
value: "C & D Cab Co Inc"
value: "Chicago Elite Cab Corp."
value: "Chicago Elite Cab Corp. (Chicago Carriag"
value: "Chicago Medallion Leasing INC"
value: "Chicago Medallion Management"
value: "Choice Taxi Association"
value: "Dispatch Taxi Affiliation"
value: "KOAM Taxi Association"
value: "Northwest Management LLC"
value: "Taxi Affiliation Services"
value: "Top Cab Affiliation"
}
default_environment: "TRAINING"
default_environment: "SERVING"
TFDVを使用する場合
ここで行ったように、TFDVはトレーニングパイプラインの開始にのみ適用されると考えるのは簡単ですが、実際には多くの用途があります。さらにいくつかあります:
- 推論のために新しいデータを検証して、突然悪い機能を受け取り始めていないことを確認します
- 推論のために新しいデータを検証して、モデルが決定面のその部分でトレーニングされていることを確認します
- データを変換して特徴エンジニアリング(おそらくTensorFlow Transformを使用)を行った後にデータを検証して、何か間違ったことをしていないことを確認します