
Обзор
Обзор
Это руководство призвано помочь вам научиться создавать собственные конвейеры машинного обучения, используя TensorFlow Extended (TFX) и Apache Airflow в качестве оркестратора. Он работает на Vertex AI Workbench и демонстрирует интеграцию с TFX и TensorBoard, а также взаимодействие с TFX в среде Jupyter Lab.
Что ты будешь делать?
Вы узнаете, как создать конвейер машинного обучения с помощью TFX.
- Конвейер TFX представляет собой направленный ациклический граф или «DAG». Мы часто будем называть конвейеры DAG.
- Конвейеры TFX подходят, когда вы собираетесь развертывать производственное приложение ML.
- Конвейеры TFX подходят, когда наборы данных большие или могут вырасти до больших размеров.
- Конвейеры TFX подходят, когда важна последовательность обучения/обслуживания.
- Конвейеры TFX подходят, когда важно управление версиями для вывода.
- Google использует конвейеры TFX для производственного машинного обучения
Дополнительную информацию см. в руководстве пользователя TFX .
Вы будете следовать типичному процессу разработки ML:
- Получение, понимание и очистка наших данных
- Разработка функций
- Обучение
- Анализ производительности модели
- Вспенить, промыть, повторить
- Готов к производству
Apache Airflow для оркестровки конвейеров
Оркестраторы TFX отвечают за планирование компонентов конвейера TFX на основе зависимостей, определенных конвейером. TFX спроектирован таким образом, чтобы его можно было переносить в различные среды и платформы оркестровки. Одним из оркестраторов по умолчанию, поддерживаемых TFX, является Apache Airflow . В этой лабораторной работе показано использование Apache Airflow для оркестровки конвейера TFX. Apache Airflow — это платформа для программного создания, планирования и мониторинга рабочих процессов. TFX использует Airflow для создания рабочих процессов в виде направленных ациклических графов (DAG) задач. Богатый пользовательский интерфейс позволяет легко визуализировать рабочие конвейеры, отслеживать ход выполнения и устранять проблемы, когда это необходимо. Рабочие процессы Apache Airflow определяются как код. Это делает их более удобными в сопровождении, версиями, тестируемыми и пригодными для совместной работы. Apache Airflow подходит для конвейеров пакетной обработки. Он легкий и простой в освоении.
В этом примере мы собираемся запустить конвейер TFX на экземпляре, вручную настроив Airflow.
Другими оркестраторами по умолчанию, поддерживаемыми TFX, являются Apache Beam и Kubeflow. Apache Beam может работать на нескольких серверах обработки данных (Beam Ruunners). Cloud Dataflow — один из таких средств управления лучами, который можно использовать для запуска конвейеров TFX. Apache Beam можно использовать как для конвейеров потоковой передачи, так и для пакетной обработки.
Kubeflow — это платформа машинного обучения с открытым исходным кодом, призванная сделать развертывание рабочих процессов машинного обучения (ML) в Kubernetes простым, портативным и масштабируемым. Kubeflow можно использовать в качестве оркестратора конвейеров TFFX, когда их необходимо развернуть в кластерах Kubernetes. Кроме того, вы также можете использовать собственный оркестратор для запуска конвейера TFX.
Подробнее об Airflow читайте здесь .
Набор данных такси Чикаго


Вы будете использовать набор данных Taxi Trips , опубликованный властями города Чикаго.
Цель модели — двоичная классификация
Будет ли клиент давать чаевые больше или меньше 20%?
Настройте проект Google Cloud
Прежде чем нажать кнопку «Начать лабораторию», прочтите эти инструкции. Лабораторные работы рассчитаны по времени, и вы не можете приостановить их. Таймер, который запускается при нажатии кнопки «Начать лабораторию» , показывает, как долго ресурсы Google Cloud будут вам доступны.
Эта практическая лабораторная работа позволяет вам выполнять лабораторные работы самостоятельно в реальной облачной среде, а не в симуляционной или демонстрационной среде. Для этого вам будут предоставлены новые временные учетные данные, которые вы будете использовать для входа и доступа к Google Cloud на время лабораторной работы.
Что вам понадобится Для выполнения этой лабораторной работы вам понадобится:
- Доступ к стандартному интернет-браузеру (рекомендуется браузер Chrome).
- Пора завершить лабораторию.
Как запустить лабораторию и войти в консоль Google Cloud 1. Нажмите кнопку «Начать лабораторию» . Если вам нужно оплатить лабораторную работу, откроется всплывающее окно, в котором вы сможете выбрать способ оплаты. Слева находится панель, заполненная временными учетными данными, которые вы должны использовать для этой лабораторной работы.
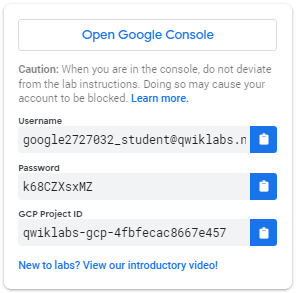
- Скопируйте имя пользователя и нажмите «Открыть консоль Google» . Лаборатория запускает ресурсы, а затем открывает другую вкладку, на которой отображается страница входа .
Совет: Открывайте вкладки в отдельных окнах рядом.

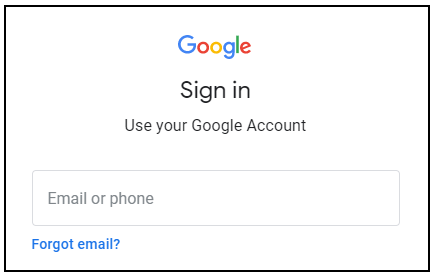
- На странице входа вставьте имя пользователя, скопированное с левой панели. Затем скопируйте и вставьте пароль.
- Пролистывайте последующие страницы:
- Примите условия.
Не добавляйте параметры восстановления или двухфакторную аутентификацию (потому что это временная учетная запись).
Не подписывайтесь на бесплатные пробные версии.
Через несколько секунд на этой вкладке откроется Cloud Console.
Активировать Cloud Shell
Cloud Shell — это виртуальная машина, на которой загружены инструменты разработки. Он предлагает постоянный домашний каталог объемом 5 ГБ и работает в облаке Google. Cloud Shell обеспечивает доступ к вашим ресурсам Google Cloud из командной строки.
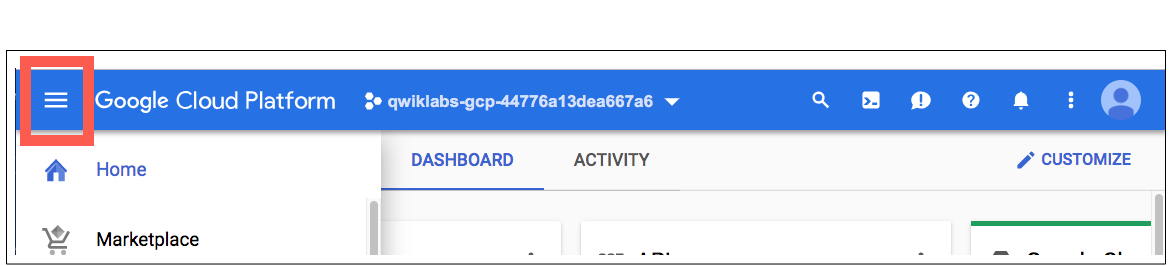
В Cloud Console на верхней правой панели инструментов нажмите кнопку «Активировать Cloud Shell» .
Нажмите Продолжить .
Подготовка среды и подключение к ней занимает несколько минут. Когда вы подключены, вы уже прошли аутентификацию, и для проекта установлен ваш _PROJECT ID . Например:

gcloud — это инструмент командной строки для Google Cloud. Он предварительно установлен в Cloud Shell и поддерживает завершение табуляции.
Вы можете указать имя активной учетной записи с помощью этой команды:
gcloud auth list
(Выход)
АКТИВНЫЙ: * АККАУНТ: студент-01-xxxxxxxxxxxx@qwiklabs.net Чтобы установить активную учетную запись, запустите: $ gcloud config set account
ACCOUNT
Вы можете указать идентификатор проекта с помощью этой команды: gcloud config list project (Выход)
[основной] проект =
(Пример вывода)
[основной] проект = qwiklabs-gcp-44776a13dea667a6
Полную документацию по gcloud см. в обзоре инструмента командной строки gcloud .
Включить облачные сервисы Google
- В Cloud Shell используйте gcloud, чтобы включить службы, используемые в лаборатории.
gcloud services enable notebooks.googleapis.com
Развертывание экземпляра Vertex Notebook
- Нажмите на меню навигации и перейдите к Vertex AI , затем к Workbench .
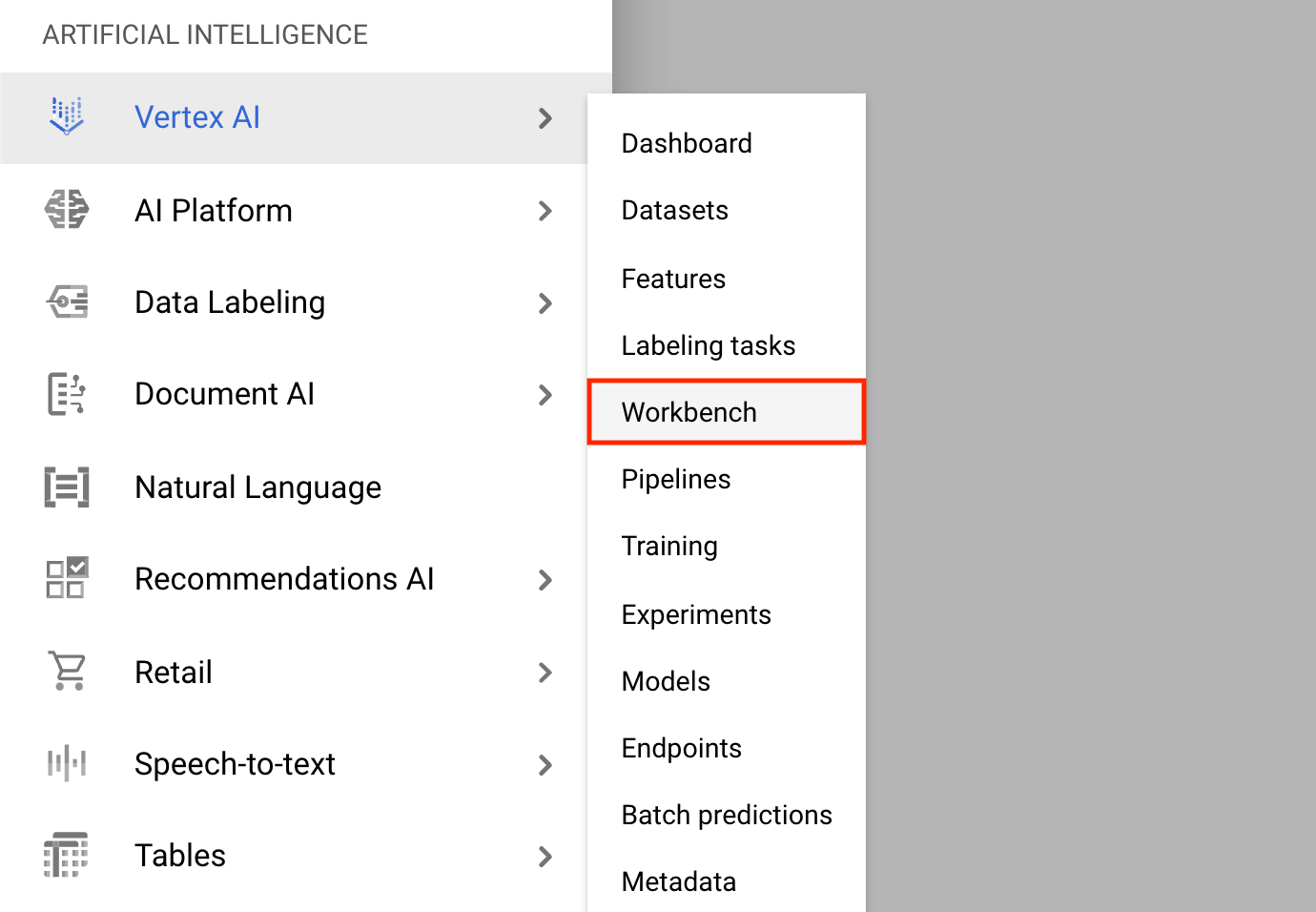
На странице «Экземпляры блокнота» нажмите «Новый блокнот» .
В меню «Настроить экземпляр» выберите TensorFlow Enterprise и выберите версию TensorFlow Enterprise 2.x (с LTS) > «Без графических процессоров» .
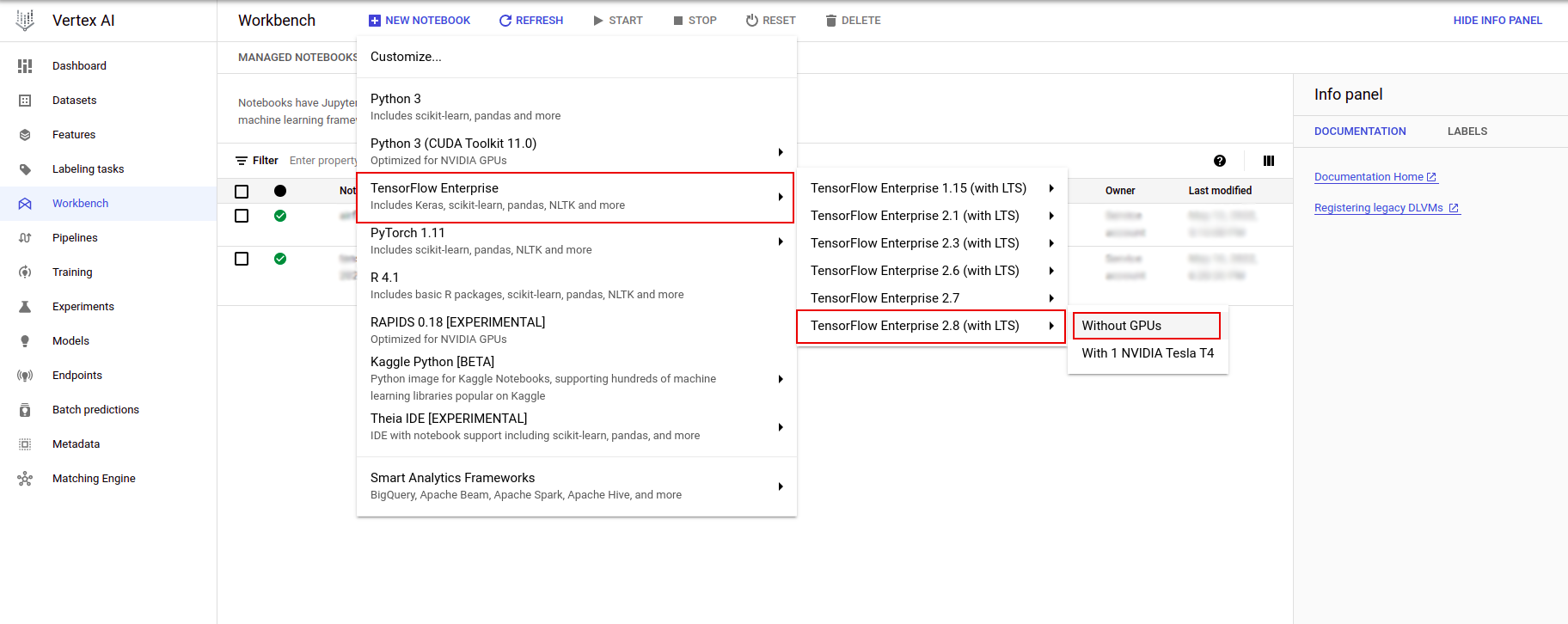
В диалоговом окне «Новый экземпляр блокнота» щелкните значок карандаша, чтобы изменить свойства экземпляра.
В поле «Имя экземпляра» введите имя вашего экземпляра.
В поле «Регион» выберите
us-east1, а в поле «Зона» выберите зону в пределах выбранного региона.Прокрутите вниз до раздела «Конфигурация машины» и выберите e2-standard-2 в поле «Тип машины».
Оставьте для остальных полей значения по умолчанию и нажмите «Создать» .
Через несколько минут консоль Vertex AI отобразит имя вашего экземпляра, а затем Open Jupyterlab .
- Нажмите «Открыть JupyterLab» . Окно JupyterLab откроется в новой вкладке.
Настройка среды
Клонировать репозиторий лаборатории
Далее вы клонируете репозиторий tfx в своем экземпляре JupyterLab. 1. В JupyterLab щелкните значок «Терминал» , чтобы открыть новый терминал.
Cancel для параметра «Рекомендуется сборка».
- Чтобы клонировать репозиторий
tfxGithub, введите следующую команду и нажмите Enter .
git clone https://github.com/tensorflow/tfx.git
- Чтобы подтвердить, что вы клонировали репозиторий, дважды щелкните каталог
tfxи убедитесь, что вы можете видеть его содержимое.
Установите лабораторные зависимости
- Выполните следующую команду, чтобы перейти в папку
tfx/tfx/examples/airflow_workshop/taxi/setup/, затем запустите./setup_demo.shдля установки лабораторных зависимостей:
cd ~/tfx/tfx/examples/airflow_workshop/taxi/setup/
./setup_demo.sh
Приведенный выше код будет
- Установите необходимые пакеты.
- Создайте папку
airflowв домашней папке. - Скопируйте папку
dagsизtfx/tfx/examples/airflow_workshop/taxi/setup/в папку~/airflow/. - Скопируйте файл csv из
tfx/tfx/examples/airflow_workshop/taxi/setup/dataв~/airflow/data.
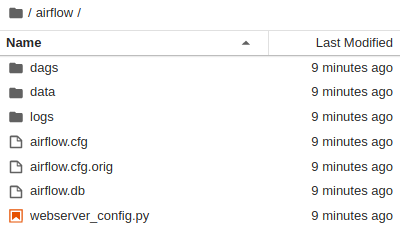
Настройка сервера Airflow
Создайте правило брандмауэра для доступа к серверу Airflow в браузере.
- Перейдите на
<a href="https://console.cloud.google.com/networking/firewalls/list">https://console.cloud.google.com/networking/firewalls/list</a>и убедитесь, что название проекта выбрано правильно - Нажмите кнопку
CREATE FIREWALL RULEвверху.
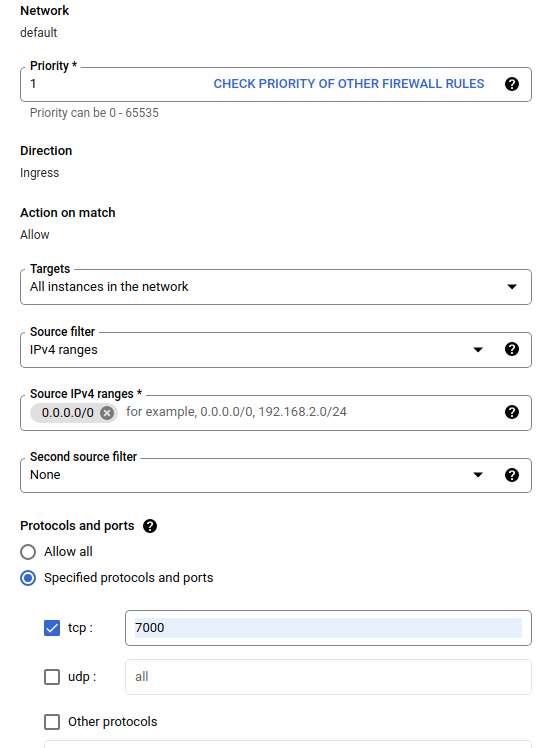
В диалоговом окне «Создание брандмауэра» выполните действия, перечисленные ниже.
- В поле «Имя» укажите
airflow-tfx. - Для Приоритета выберите
1. - В поле «Цели» выберите
All instances in the network. - Для диапазонов исходных IPv4 выберите
0.0.0.0/0 - В разделе «Протоколы и порты» нажмите
tcpи введите7000в поле рядом сtcp - Нажмите
Create.
Запустите сервер воздушного потока из своей оболочки
В окне терминала Jupyter Lab перейдите в домашний каталог и запустите команду airflow users create , чтобы создать пользователя-администратора для Airflow:
cd
airflow users create --role Admin --username admin --email admin --firstname admin --lastname admin --password admin
Затем запустите команду airflow webserver и airflow scheduler , чтобы запустить сервер. Выберите порт 7000 поскольку он разрешен через брандмауэр.
nohup airflow webserver -p 7000 &> webserver.out &
nohup airflow scheduler &> scheduler.out &
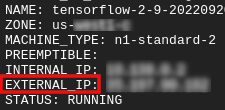
Получите свой внешний IP
- В Cloud Shell используйте
gcloud, чтобы получить внешний IP-адрес.
gcloud compute instances list
Запуск DAG/конвейера
В браузере
Откройте браузер и перейдите по адресу http://
- На странице входа введите имя пользователя (
admin) и пароль (admin), которые вы выбрали при запуске командыairflow users create.
Airflow загружает DAG из исходных файлов Python. Он берет каждый файл и выполняет его. Затем он загружает все объекты DAG из этого файла. Все файлы .py , определяющие объекты DAG, будут указаны как конвейеры на домашней странице airflow.
В этом руководстве Airflow сканирует папку ~/airflow/dags/ на наличие объектов DAG.
Если вы откроете ~/airflow/dags/taxi_pipeline.py и прокрутите вниз, вы увидите, что он создает и сохраняет объект DAG в переменной с именем DAG . Следовательно, он будет указан как трубопровод на домашней странице воздушного потока, как показано ниже:
Если вы нажмете «Такси», вы будете перенаправлены на представление сетки DAG. Вы можете нажать кнопку Graph вверху, чтобы получить графическое представление группы обеспечения доступности баз данных.
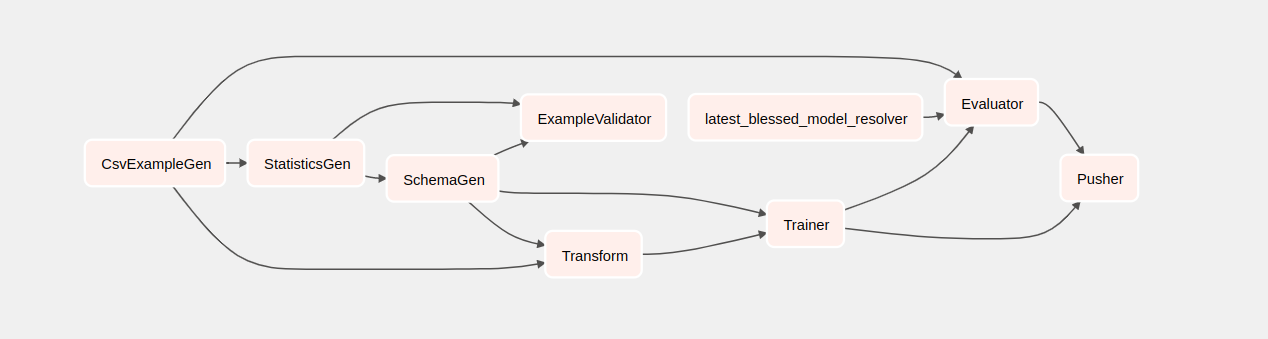
Запустить конвейер такси
На главной странице вы можете увидеть кнопки, которые можно использовать для взаимодействия с группой обеспечения доступности баз данных.
Под заголовком действий нажмите кнопку триггера , чтобы запустить конвейер.
На странице такси DAG используйте кнопку справа, чтобы обновить состояние графического представления DAG во время работы конвейера. Кроме того, вы можете включить автоматическое обновление , чтобы дать Airflow указание автоматически обновлять представление графика при изменении состояния.
Вы также можете использовать интерфейс командной строки Airflow в терминале для включения и запуска групп DAG:
# enable/disable
airflow pause <your DAG name>
airflow unpause <your DAG name>
# trigger
airflow trigger_dag <your DAG name>
Ожидание завершения конвейера
После запуска конвейера в представлении DAG вы можете наблюдать за ходом работы конвейера во время его работы. По мере запуска каждого компонента цвет контура компонента на графике DAG будет меняться, показывая его состояние. Когда компонент завершит обработку, контур станет темно-зеленым, показывая, что обработка завершена.
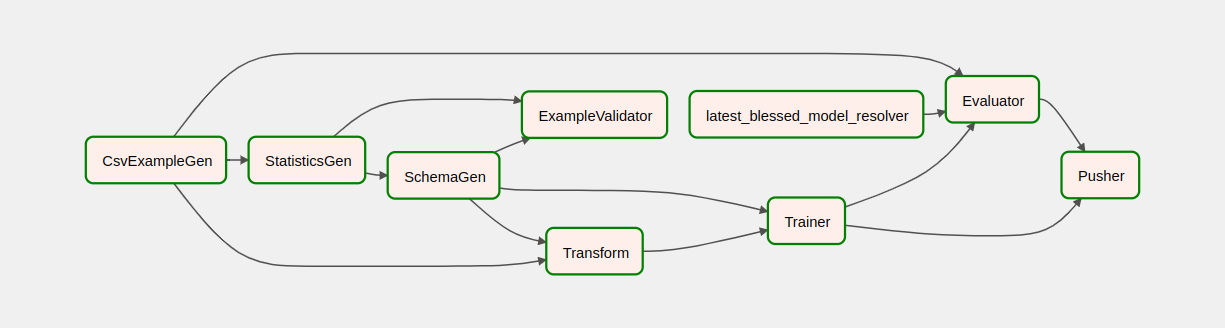
Понимание компонентов
Теперь мы подробно рассмотрим компоненты этого конвейера и индивидуально рассмотрим результаты, получаемые на каждом этапе конвейера.
В JupyterLab перейдите в
~/tfx/tfx/examples/airflow_workshop/taxi/notebooks/Откройте блокнот.ipynb.

Продолжайте лабораторную работу в блокноте и запускайте каждую ячейку, нажимая кнопку «Выполнить» (
 ) в верхней части экрана. Альтернативно вы можете выполнить код в ячейке с помощью SHIFT + ENTER .
) в верхней части экрана. Альтернативно вы можете выполнить код в ячейке с помощью SHIFT + ENTER .
Прочтите повествование и убедитесь, что вы понимаете, что происходит в каждой ячейке.