
Przegląd
Przegląd
Ten samouczek ma na celu pomóc Ci nauczyć się tworzyć własne potoki uczenia maszynowego przy użyciu TensorFlow Extended (TFX) i Apache Airflow jako koordynatora. Działa na Vertex AI Workbench i wykazuje integrację z TFX i TensorBoard, a także interakcję z TFX w środowisku Jupyter Lab.
Co będziesz robić?
Dowiesz się, jak utworzyć potok ML przy użyciu TFX
- Potok TFX to skierowany graf acykliczny, w skrócie „DAG”. Często będziemy nazywać rurociągi DAG.
- Potoki TFX są odpowiednie, gdy będziesz wdrażać produkcyjną aplikację ML
- Potoki TFX są odpowiednie, gdy zbiory danych są duże lub mogą stać się duże
- Potoki TFX są odpowiednie, gdy ważna jest spójność szkolenia/obsługi
- Potoki TFX są odpowiednie, gdy ważne jest zarządzanie wersjami na potrzeby wnioskowania
- Google używa potoków TFX do produkcyjnego uczenia maszynowego
Aby dowiedzieć się więcej, zobacz Podręcznik użytkownika TFX .
Będziesz postępować zgodnie z typowym procesem rozwoju ML:
- Pozyskiwanie, zrozumienie i czyszczenie naszych danych
- Inżynieria funkcji
- Szkolenie
- Analiza wydajności modelu
- Spieniaj, spłucz, powtórz
- Gotowy do produkcji
Apache Airflow do orkiestracji rurociągów
Orkiestratorzy TFX są odpowiedzialni za planowanie komponentów potoku TFX w oparciu o zależności zdefiniowane przez potok. TFX został zaprojektowany tak, aby można go było przenosić do wielu środowisk i struktur orkiestracji. Jednym z domyślnych orkiestratorów obsługiwanych przez TFX jest Apache Airflow . To laboratorium ilustruje użycie Apache Airflow do orkiestracji potoku TFX. Apache Airflow to platforma do programowego tworzenia, planowania i monitorowania przepływów pracy. TFX używa Airflow do tworzenia przepływów pracy w postaci ukierunkowanych grafów acyklicznych (DAG) zadań. Bogaty interfejs użytkownika ułatwia wizualizację potoków działających w produkcji, monitorowanie postępu i rozwiązywanie problemów w razie potrzeby. Przepływy pracy Apache Airflow są zdefiniowane jako kod. Dzięki temu są łatwiejsze w utrzymaniu, wersjonowalne, testowalne i współpracujące. Apache Airflow nadaje się do rurociągów przetwarzania wsadowego. Jest lekki i łatwy do nauczenia.
W tym przykładzie uruchomimy potok TFX na instancji, ręcznie konfigurując przepływ powietrza.
Inne domyślne orkiestratory obsługiwane przez TFX to Apache Beam i Kubeflow. Apache Beam może działać na wielu backendach przetwarzania danych (Beam Ruunners). Cloud Dataflow to jeden z takich modułów uruchamiających wiązkę, którego można używać do uruchamiania potoków TFX. Apache Beam może być używany zarówno do potoków przesyłania strumieniowego, jak i przetwarzania wsadowego.
Kubeflow to platforma uczenia maszynowego o otwartym kodzie źródłowym, która umożliwia proste, przenośne i skalowalne wdrażanie przepływów pracy uczenia maszynowego (ML) w Kubernetes. Kubeflow może służyć jako orkiestrator dla potoków TFFX, gdy trzeba je wdrożyć w klastrach Kubernetes. Ponadto możesz także użyć własnego niestandardowego koordynatora do uruchomienia potoku TFX.
Przeczytaj więcej o przepływie powietrza tutaj .
Zbiór danych o taksówkach w Chicago


Będziesz korzystać ze zbioru danych dotyczących przejazdów taksówkami opublikowanego przez miasto Chicago.
Cel modelu – Klasyfikacja binarna
Czy klient otrzyma napiwek większy czy mniejszy niż 20%?
Skonfiguruj projekt Google Cloud
Zanim klikniesz przycisk Rozpocznij laboratorium Przeczytaj te instrukcje. Laboratoria mają ograniczony czas i nie można ich wstrzymać. Licznik uruchamiający się po kliknięciu przycisku Rozpocznij laboratorium pokazuje, jak długo zasoby Google Cloud będą Ci udostępniane.
To praktyczne laboratorium pozwala na samodzielne wykonanie ćwiczeń laboratoryjnych w prawdziwym środowisku chmury, a nie w środowisku symulacyjnym lub demonstracyjnym. Robi to, udostępniając nowe, tymczasowe dane uwierzytelniające, których będziesz używać do logowania się i uzyskiwania dostępu do Google Cloud na czas trwania laboratorium.
Czego potrzebujesz Aby ukończyć to laboratorium, potrzebujesz:
- Dostęp do standardowej przeglądarki internetowej (zalecana przeglądarka Chrome).
- Czas zakończyć laboratorium.
Jak rozpocząć laboratorium i zalogować się do Google Cloud Console 1. Kliknij przycisk Rozpocznij laboratorium . Jeśli musisz zapłacić za laboratorium, otworzy się wyskakujące okienko, w którym możesz wybrać metodę płatności. Po lewej stronie znajduje się panel zawierający tymczasowe poświadczenia, których musisz użyć w tym laboratorium.
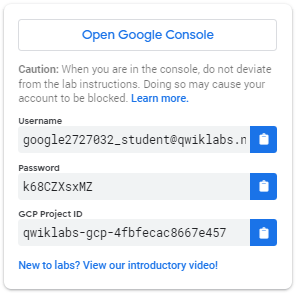
- Skopiuj nazwę użytkownika, a następnie kliknij Otwórz konsolę Google . Laboratorium uruchamia zasoby, a następnie otwiera kolejną kartę wyświetlającą stronę logowania .
Wskazówka: otwieraj karty w oddzielnych oknach, obok siebie.
- Na stronie logowania wklej nazwę użytkownika skopiowaną z lewego panelu. Następnie skopiuj i wklej hasło.
- Klikaj na kolejne strony:
- Zaakceptuj warunki.
Nie dodawaj opcji odzyskiwania ani uwierzytelniania dwuskładnikowego (ponieważ jest to konto tymczasowe).
Nie zapisuj się na bezpłatne okresy próbne.
Po kilku chwilach na tej karcie otworzy się Cloud Console.
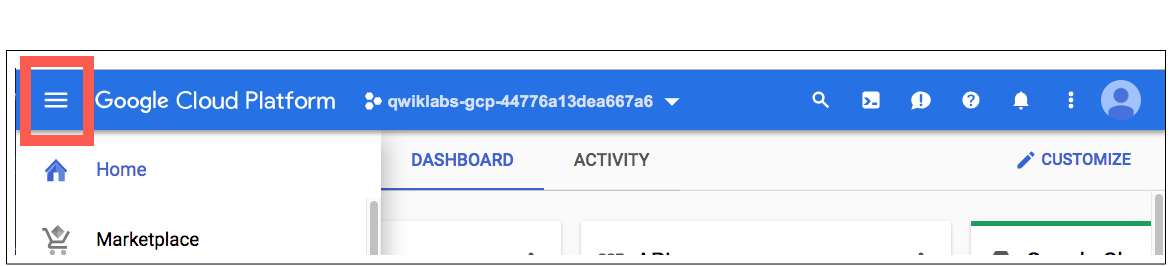
Aktywuj Cloud Shell
Cloud Shell to maszyna wirtualna wyposażona w narzędzia programistyczne. Oferuje trwały katalog domowy o pojemności 5 GB i działa w chmurze Google. Cloud Shell zapewnia dostęp z wiersza poleceń do zasobów Google Cloud.
W Cloud Console, na prawym górnym pasku narzędzi kliknij przycisk Aktywuj Cloud Shell .
Kliknij Kontynuuj .
Udostępnienie i połączenie ze środowiskiem zajmuje kilka chwil. Po nawiązaniu połączenia jesteś już uwierzytelniony, a projekt jest ustawiony na Twój _PROJECT ID . Na przykład:

gcloud to narzędzie wiersza poleceń dla Google Cloud. Jest preinstalowany w Cloud Shell i obsługuje uzupełnianie kart.
Za pomocą tego polecenia możesz wyświetlić listę aktywnych nazw kont:
gcloud auth list
(Wyjście)
AKTYWNE: * KONTO: student-01-xxxxxxxxxxxx@qwiklabs.net Aby ustawić aktywne konto, uruchom: $ gcloud config set account
ACCOUNT
Możesz wyświetlić identyfikator projektu za pomocą tego polecenia: gcloud config list project (wyjście)
[podstawowy] projekt =
(Przykładowe wyjście)
[rdzeniowy] projekt = qwiklabs-gcp-44776a13dea667a6
Pełną dokumentację gcloud znajdziesz w omówieniu narzędzia wiersza poleceń gcloud .
Włącz usługi Google Cloud
- W Cloud Shell użyj gcloud, aby włączyć usługi używane w laboratorium.
gcloud services enable notebooks.googleapis.com
Wdróż instancję Vertex Notebook
- Kliknij menu nawigacji i przejdź do Vertex AI , a następnie do Workbench .
Na stronie Instancje notatnika kliknij opcję Nowy notatnik .
W menu Dostosuj instancję wybierz TensorFlow Enterprise i wybierz wersję TensorFlow Enterprise 2.x (z LTS) > Bez procesorów graficznych .
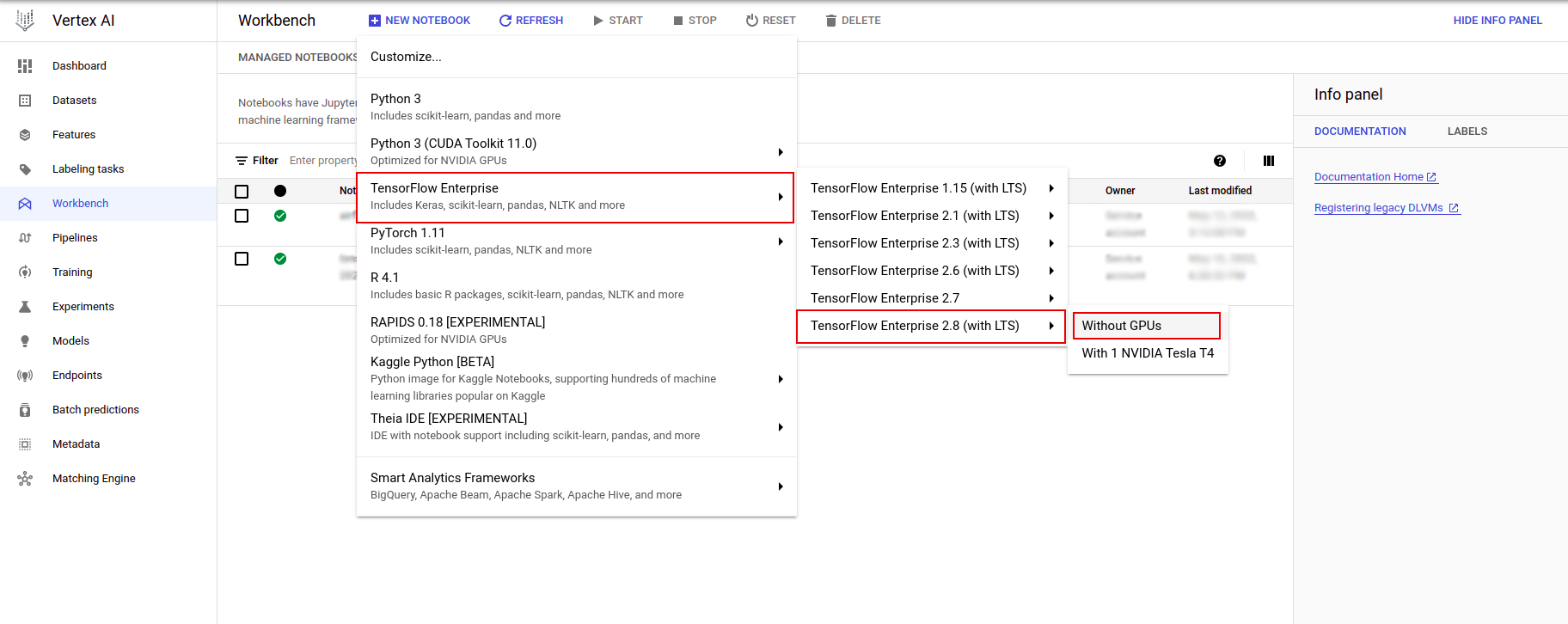
W oknie dialogowym Nowa instancja notatnika kliknij ikonę ołówka, aby edytować właściwości instancji.
W polu Nazwa instancji wprowadź nazwę swojej instancji.
W polu Region wybierz
us-east1, a w polu Strefa wybierz strefę w wybranym regionie.Przewiń w dół do Konfiguracja maszyny i wybierz e2-standard-2 dla Typ maszyny.
Pozostaw pozostałe pola z ich wartościami domyślnymi i kliknij Utwórz .
Po kilku minutach konsola Vertex AI wyświetli nazwę Twojej instancji, a następnie Open Jupyterlab .
- Kliknij opcję Otwórz JupyterLab . Okno JupyterLab otworzy się w nowej karcie.
Skonfiguruj środowisko
Sklonuj repozytorium laboratorium
Następnie sklonujesz repozytorium tfx w instancji JupyterLab. 1. W JupyterLab kliknij ikonę Terminal , aby otworzyć nowy terminal.
Cancel w przypadku opcji Kompilacja zalecana.
- Aby sklonować repozytorium
tfxGithub, wpisz następujące polecenie i naciśnij Enter .
git clone https://github.com/tensorflow/tfx.git
- Aby potwierdzić, że sklonowałeś repozytorium, kliknij dwukrotnie katalog
tfxi potwierdź, że widzisz jego zawartość.
Zainstaluj zależności laboratoryjne
- Uruchom następujące polecenie, aby przejść do folderu
tfx/tfx/examples/airflow_workshop/taxi/setup/, a następnie uruchom./setup_demo.sh, aby zainstalować zależności laboratoryjne:
cd ~/tfx/tfx/examples/airflow_workshop/taxi/setup/
./setup_demo.sh
Powyższy kod będzie
- Zainstaluj wymagane pakiety.
- Utwórz folder
airfloww folderze domowym. - Skopiuj folder
dagsztfx/tfx/examples/airflow_workshop/taxi/setup/do folderu~/airflow/. - Skopiuj plik csv z
tfx/tfx/examples/airflow_workshop/taxi/setup/datado~/airflow/data.
Konfigurowanie serwera Airflow
Utwórz regułę zapory sieciowej, aby uzyskać dostęp do serwera przepływu powietrza w przeglądarce
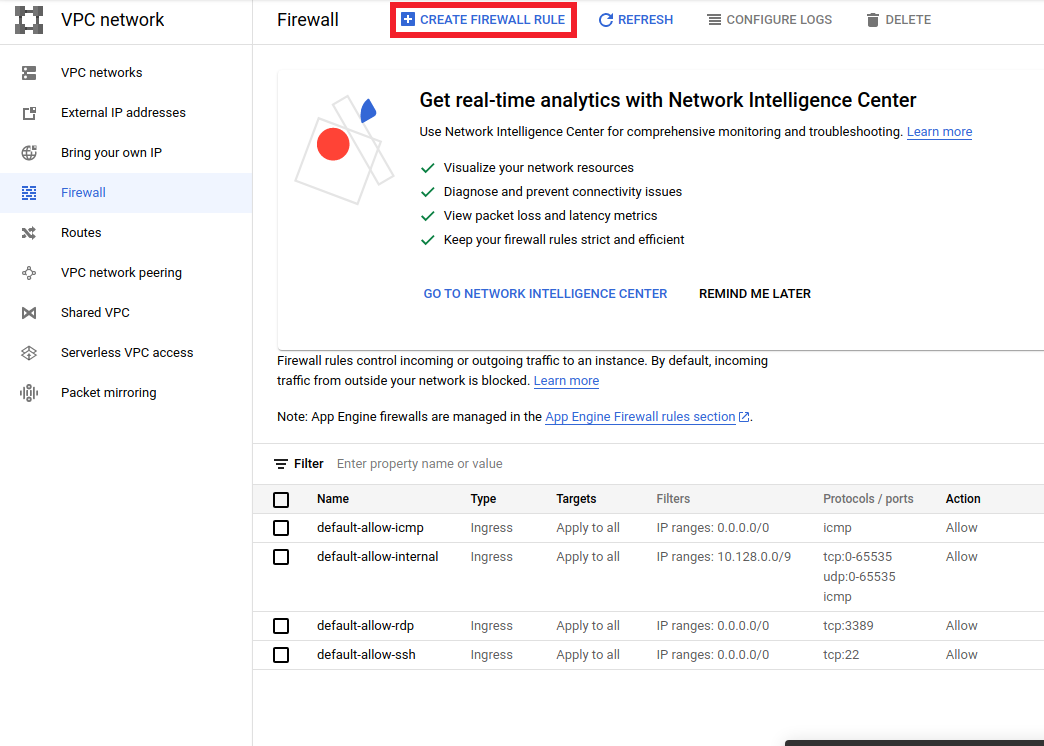
- Przejdź do
<a href="https://console.cloud.google.com/networking/firewalls/list">https://console.cloud.google.com/networking/firewalls/list</a>i upewnij się, że nazwa projektu została odpowiednio wybrana - Kliknij opcję
CREATE FIREWALL RULEu góry
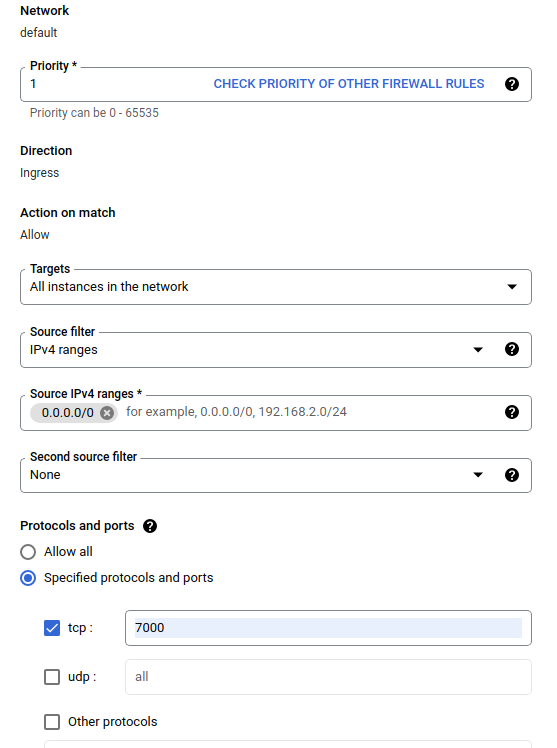
W oknie dialogowym Utwórz zaporę sieciową wykonaj poniższe czynności.
- W polu Name wpisz
airflow-tfx. - W polu Priorytet wybierz opcję
1. - W polu Cele wybierz
All instances in the network. - W polu Zakresy źródłowego IPv4 wybierz
0.0.0.0/0 - W polu Protokoły i porty kliknij
tcpi wpisz7000w polu oboktcp - Kliknij
Create.
Uruchom serwer przepływu powietrza ze swojej powłoki
W oknie terminala Jupyter Lab przejdź do katalogu domowego, uruchom polecenie airflow users create , aby utworzyć użytkownika administratora dla przepływu powietrza:
cd
airflow users create --role Admin --username admin --email admin --firstname admin --lastname admin --password admin
Następnie uruchom airflow webserver i polecenie airflow scheduler , aby uruchomić serwer. Wybierz port 7000 , ponieważ jest on dozwolony przez zaporę ogniową.
nohup airflow webserver -p 7000 &> webserver.out &
nohup airflow scheduler &> scheduler.out &
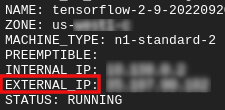
Zdobądź zewnętrzne IP
- W Cloud Shell użyj
gcloud, aby uzyskać zewnętrzny adres IP.
gcloud compute instances list
Uruchamianie DAG/potoku
W przeglądarce
Otwórz przeglądarkę i przejdź do http://
- Na stronie logowania wprowadź nazwę użytkownika (
admin) i hasło (admin), które wybrałeś podczas uruchamiania poleceniaairflow users create.
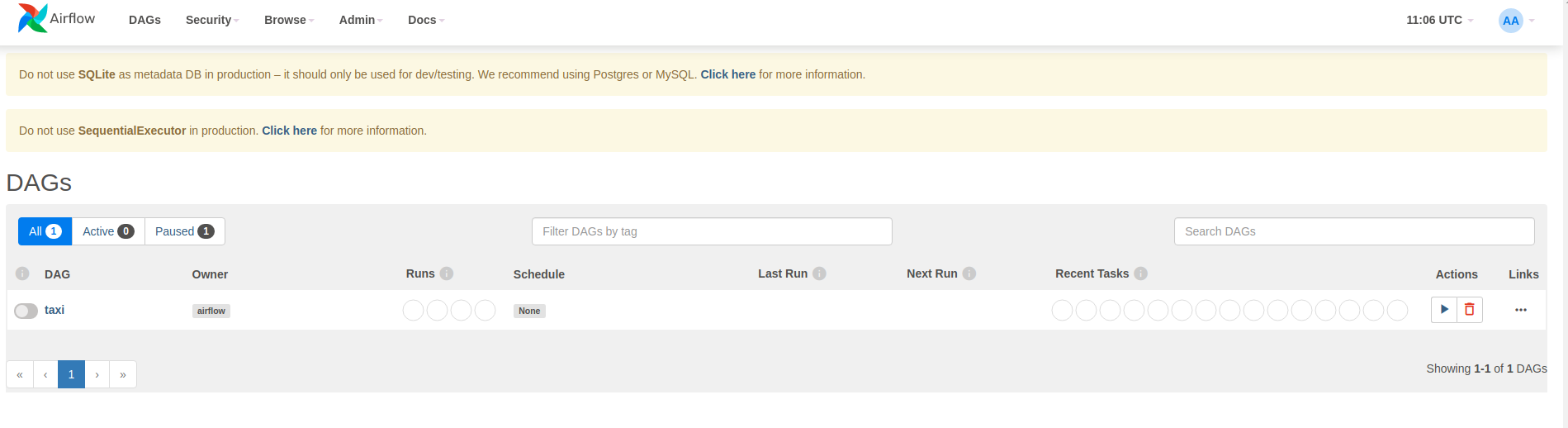
Airflow ładuje DAG z plików źródłowych Pythona. Pobiera każdy plik i wykonuje go. Następnie ładuje wszystkie obiekty DAG z tego pliku. Wszystkie pliki .py definiujące obiekty DAG zostaną wyświetlone jako potoki na stronie głównej przepływu powietrza.
W tym samouczku Airflow skanuje folder ~/airflow/dags/ w poszukiwaniu obiektów DAG.
Jeśli otworzysz plik ~/airflow/dags/taxi_pipeline.py i przewiniesz w dół, zobaczysz, że tworzy on i przechowuje obiekt DAG w zmiennej o nazwie DAG . Dlatego zostanie wyświetlony jako potok na stronie głównej przepływu powietrza, jak pokazano poniżej:
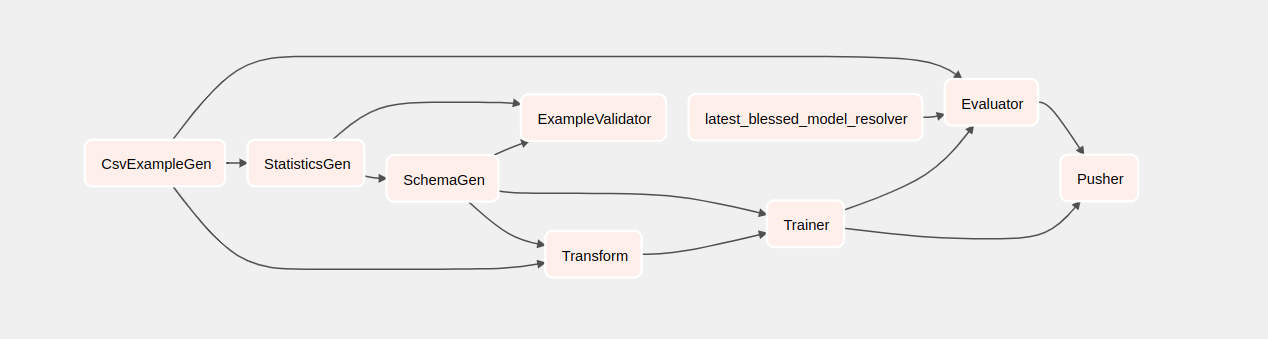
Jeśli klikniesz taksówkę, zostaniesz przekierowany do widoku siatki DAG. Możesz kliknąć opcję Graph na górze, aby wyświetlić widok wykresu DAG.
Uruchom rurociąg taksówkowy
Na stronie głównej widoczne są przyciski umożliwiające interakcję z DAG.
Pod nagłówkiem działań kliknij przycisk wyzwalacza , aby uruchomić potok.
Na stronie DAG taksówki użyj przycisku po prawej stronie, aby odświeżyć stan widoku wykresu DAG podczas pracy rurociągu. Dodatkowo możesz włączyć opcję Automatyczne odświeżanie , aby Airflow automatycznie odświeżał widok wykresu w przypadku zmiany stanu.
Możesz także użyć interfejsu CLI Airflow w terminalu, aby włączyć i uruchomić DAG:
# enable/disable
airflow pause <your DAG name>
airflow unpause <your DAG name>
# trigger
airflow trigger_dag <your DAG name>
Czekamy na ukończenie rurociągu
Po uruchomieniu potoku w widoku DAG możesz obserwować postęp potoku w trakcie jego działania. Po uruchomieniu każdego komponentu kolor konturu komponentu na wykresie DAG zmieni się, aby pokazać jego stan. Kiedy komponent zakończy przetwarzanie, kontur zmieni kolor na ciemnozielony, co oznacza, że proces został zakończony.
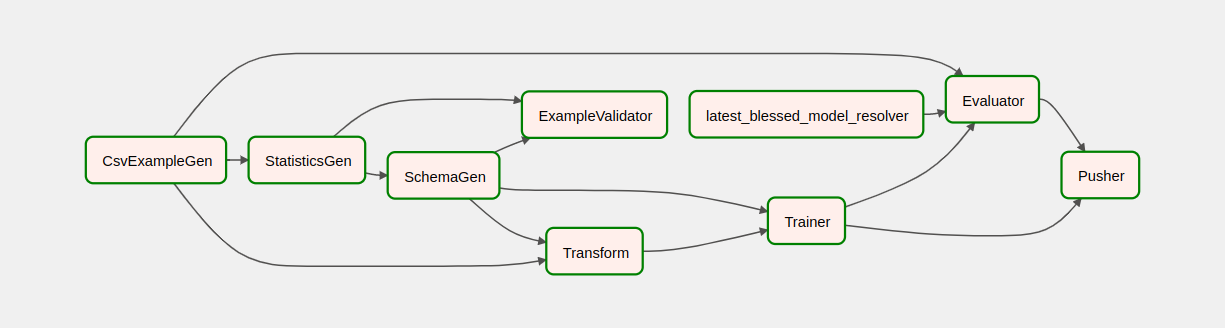
Zrozumienie komponentów
Teraz przyjrzymy się szczegółowo elementom tego potoku i indywidualnie przyjrzymy się produktom wytwarzanym na każdym etapie potoku.
W JupyterLab przejdź do
~/tfx/tfx/examples/airflow_workshop/taxi/notebooks/Otwórz notatnik.ipynb.

Kontynuuj ćwiczenia w notatniku i uruchom każdą komórkę, klikając przycisk Uruchom (
 ) u góry ekranu. Alternatywnie możesz wykonać kod w komórce za pomocą SHIFT + ENTER .
) u góry ekranu. Alternatywnie możesz wykonać kod w komórce za pomocą SHIFT + ENTER .
Przeczytaj narrację i upewnij się, że rozumiesz, co dzieje się w każdej komórce.