
Descripción general
Descripción general
Este tutorial está diseñado para ayudarlo a aprender a crear sus propios canales de aprendizaje automático utilizando TensorFlow Extended (TFX) y Apache Airflow como orquestador. Se ejecuta en Vertex AI Workbench y muestra la integración con TFX y TensorBoard, así como la interacción con TFX en un entorno de Jupyter Lab.
¿Qué estarás haciendo?
Aprenderá cómo crear una canalización de ML usando TFX.
- Una tubería TFX es un gráfico acíclico dirigido o "DAG". A menudo nos referiremos a las tuberías como DAG.
- Las canalizaciones TFX son apropiadas cuando implementará una aplicación de aprendizaje automático en producción.
- Las canalizaciones TFX son apropiadas cuando los conjuntos de datos son grandes o pueden llegar a ser grandes.
- Los canales TFX son apropiados cuando la coherencia entre la capacitación y el servicio es importante
- Las canalizaciones TFX son apropiadas cuando la gestión de versiones para la inferencia es importante
- Google utiliza canalizaciones TFX para ML de producción
Consulte la Guía del usuario de TFX para obtener más información.
Seguirá un proceso típico de desarrollo de ML:
- Ingerir, comprender y limpiar nuestros datos
- Ingeniería de características
- Capacitación
- Analizar el rendimiento del modelo
- Enjabonar, enjuagar, repetir
- Listo para la producción
Apache Airflow para la orquestación de tuberías
Los orquestadores de TFX son responsables de programar los componentes de la canalización TFX en función de las dependencias definidas por la canalización. TFX está diseñado para ser portátil a múltiples entornos y marcos de orquestación. Uno de los orquestadores predeterminados admitidos por TFX es Apache Airflow . Esta práctica de laboratorio ilustra el uso de Apache Airflow para la orquestación de canalizaciones TFX. Apache Airflow es una plataforma para crear, programar y monitorear flujos de trabajo mediante programación. TFX utiliza Airflow para crear flujos de trabajo como gráficos acíclicos dirigidos (DAG) de tareas. La rica interfaz de usuario facilita la visualización de canalizaciones que se ejecutan en producción, el seguimiento del progreso y la resolución de problemas cuando sea necesario. Los flujos de trabajo de Apache Airflow se definen como código. Esto los hace más mantenibles, versionables, comprobables y colaborativos. Apache Airflow es adecuado para tuberías de procesamiento por lotes. Es liviano y fácil de aprender.
En este ejemplo, ejecutaremos una canalización TFX en una instancia configurando Airflow manualmente.
Los otros orquestadores predeterminados admitidos por TFX son Apache Beam y Kubeflow. Apache Beam puede ejecutarse en múltiples servidores de procesamiento de datos (Beam Ruunners). Cloud Dataflow es uno de esos ejecutores de haces que se puede utilizar para ejecutar canalizaciones TFX. Apache Beam se puede utilizar para canalizaciones de procesamiento por secuencias y por lotes.
Kubeflow es una plataforma de aprendizaje automático de código abierto dedicada a hacer que las implementaciones de flujos de trabajo de aprendizaje automático (ML) en Kubernetes sean simples, portátiles y escalables. Kubeflow se puede utilizar como orquestador para canalizaciones TFFX cuando es necesario implementarlas en clústeres de Kubernetes. Además, también puede utilizar su propio orquestador personalizado para ejecutar una canalización TFX.
Lea más sobre el flujo de aire aquí .
Conjunto de datos de taxis de Chicago


Utilizará el conjunto de datos de Taxi Trips publicado por la ciudad de Chicago.
Objetivo del modelo: clasificación binaria
¿El cliente dará una propina mayor o menor al 20%?
Configurar el proyecto de Google Cloud
Antes de hacer clic en el botón Iniciar laboratorio, lea estas instrucciones. Los laboratorios están cronometrados y no puedes pausarlos. El cronómetro, que comienza cuando haces clic en Iniciar laboratorio , muestra durante cuánto tiempo los recursos de Google Cloud estarán disponibles para ti.
Esta práctica de laboratorio le permite realizar las actividades de laboratorio usted mismo en un entorno de nube real, no en un entorno de simulación o demostración. Lo hace proporcionándole credenciales nuevas y temporales que utiliza para iniciar sesión y acceder a Google Cloud durante la duración de la práctica de laboratorio.
Qué necesita Para completar esta práctica de laboratorio, necesita:
- Acceso a un navegador de Internet estándar (se recomienda el navegador Chrome).
- Es hora de completar el laboratorio.
Cómo iniciar su laboratorio e iniciar sesión en Google Cloud Console 1. Haga clic en el botón Iniciar laboratorio . Si necesita pagar por el laboratorio, se abre una ventana emergente para que seleccione su método de pago. A la izquierda hay un panel con las credenciales temporales que debe usar para esta práctica de laboratorio.
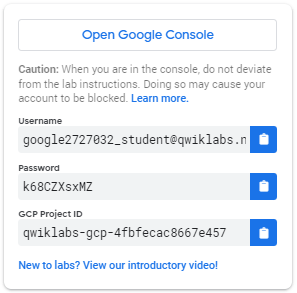
- Copie el nombre de usuario y luego haga clic en Abrir Google Console . El laboratorio activa los recursos y luego abre otra pestaña que muestra la página de inicio de sesión .
Consejo: abra las pestañas en ventanas separadas, una al lado de la otra.
- En la página de inicio de sesión , pegue el nombre de usuario que copió del panel izquierdo. Luego copie y pegue la contraseña.
- Haga clic en las páginas siguientes:
- Acepta los términos y condiciones.
No agregue opciones de recuperación ni autenticación de dos factores (porque se trata de una cuenta temporal).
No te registres para pruebas gratuitas.
Después de unos momentos, se abre Cloud Console en esta pestaña.
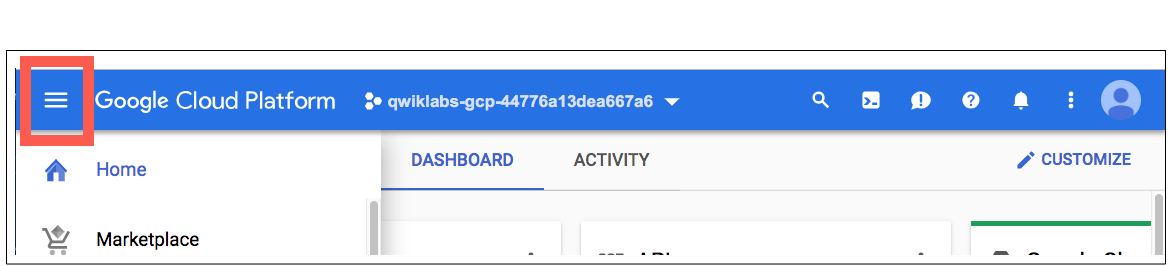
Activar Cloud Shell
Cloud Shell es una máquina virtual cargada de herramientas de desarrollo. Ofrece un directorio de inicio persistente de 5 GB y se ejecuta en Google Cloud. Cloud Shell proporciona acceso a la línea de comandos a sus recursos de Google Cloud.
En Cloud Console, en la barra de herramientas superior derecha, haga clic en el botón Activar Cloud Shell .
Haga clic en Continuar .
Se necesitan unos momentos para aprovisionarse y conectarse al entorno. Cuando esté conectado, ya estará autenticado y el proyecto estará configurado en su _PROJECT ID . Por ejemplo:

gcloud es la herramienta de línea de comandos de Google Cloud. Viene preinstalado en Cloud Shell y admite la función de tabulación.
Puede enumerar el nombre de la cuenta activa con este comando:
gcloud auth list
(Producción)
ACTIVO: * CUENTA: estudiante-01-xxxxxxxxxxxx@qwiklabs.net Para configurar la cuenta activa, ejecute: $ gcloud config set account
ACCOUNT
Puede enumerar el ID del proyecto con este comando: gcloud config list project (Salida)
proyecto [central] =
(Salida de ejemplo)
proyecto [núcleo] = qwiklabs-gcp-44776a13dea667a6
Para obtener la documentación completa de gcloud, consulta la descripción general de la herramienta de línea de comandos de gcloud .
Habilitar los servicios de Google Cloud
- En Cloud Shell, usa gcloud para habilitar los servicios usados en el laboratorio.
gcloud services enable notebooks.googleapis.com
Implementar una instancia de Vertex Notebook
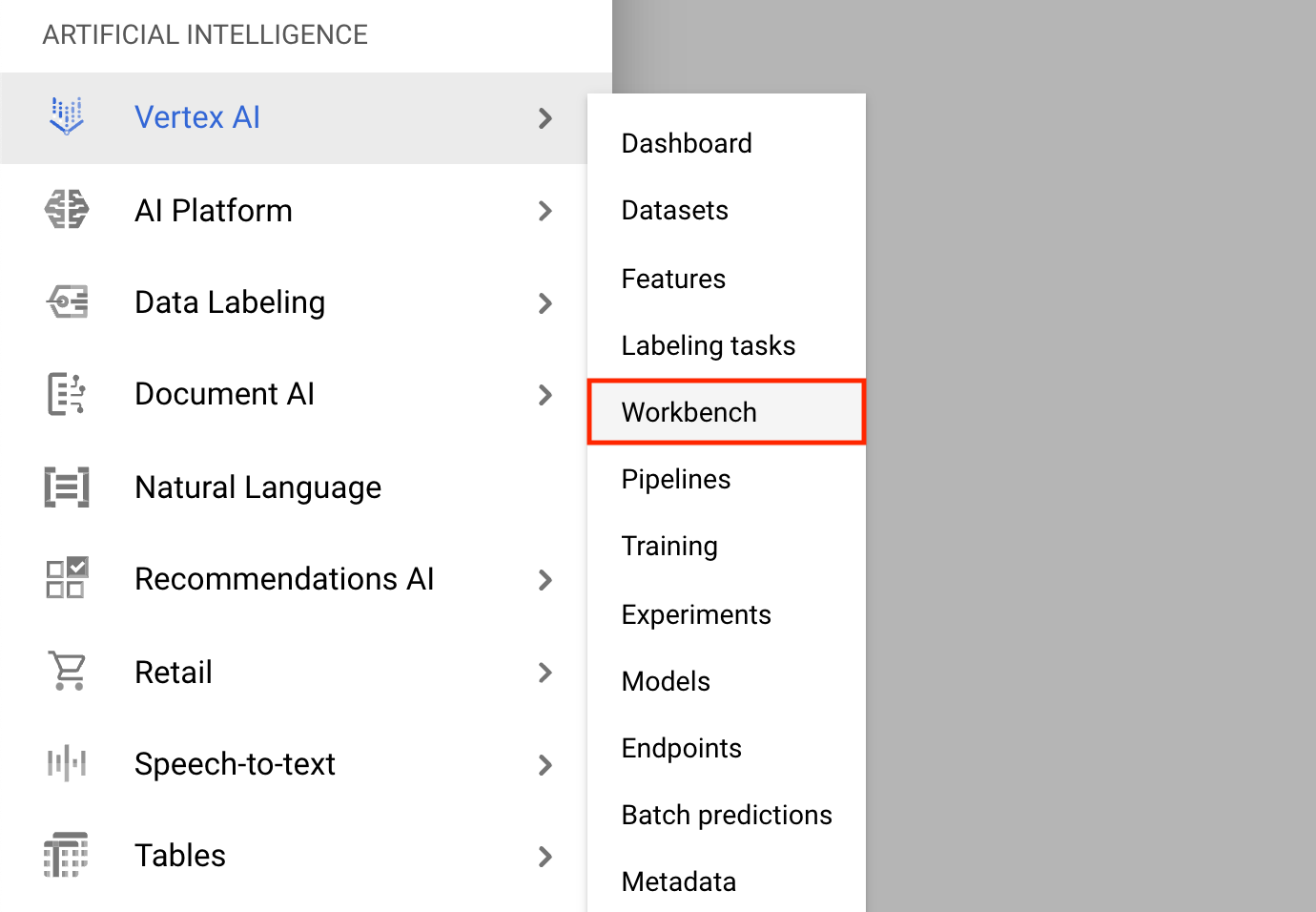
- Haga clic en el menú de navegación y navegue hasta Vertex AI , luego hasta Workbench .
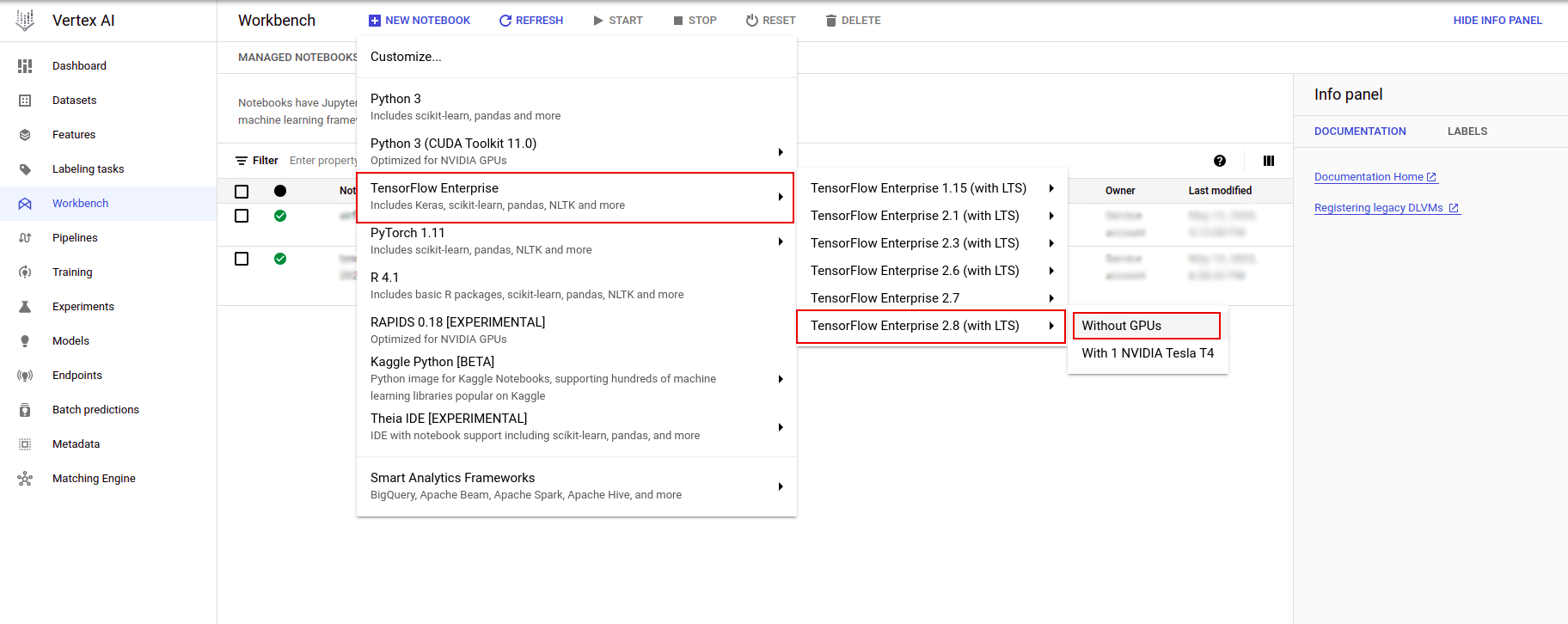
En la página Instancias de Notebook, haga clic en Nuevo Notebook .
En el menú Personalizar instancia, seleccione TensorFlow Enterprise y elija la versión de TensorFlow Enterprise 2.x (con LTS) > Sin GPU .
En el cuadro de diálogo Nueva instancia del cuaderno , haga clic en el ícono de lápiz para Editar propiedades de la instancia.
En Nombre de instancia , ingrese un nombre para su instancia.
Para Región , seleccione
us-east1y para Zona , seleccione una zona dentro de la región seleccionada.Desplácese hacia abajo hasta Configuración de la máquina y seleccione e2-standard-2 para Tipo de máquina.
Deje los campos restantes con sus valores predeterminados y haga clic en Crear .
Después de unos minutos, la consola de Vertex AI mostrará el nombre de su instancia, seguido de Open Jupyterlab .
- Haga clic en Abrir JupyterLab . Se abrirá una ventana de JupyterLab en una nueva pestaña.
Configurar el entorno
Clonar el repositorio del laboratorio
A continuación, clonarás el repositorio tfx en tu instancia de JupyterLab. 1. En JupyterLab, haga clic en el icono Terminal para abrir una nueva terminal.
Cancel para la compilación recomendada.
- Para clonar el repositorio
tfxGithub, escriba el siguiente comando y presione Enter .
git clone https://github.com/tensorflow/tfx.git
- Para confirmar que ha clonado el repositorio, haga doble clic en el directorio
tfxy confirme que puede ver su contenido.
Instalar dependencias de laboratorio
- Ejecute lo siguiente para ir a la carpeta
tfx/tfx/examples/airflow_workshop/taxi/setup/, luego ejecute./setup_demo.shpara instalar las dependencias del laboratorio:
cd ~/tfx/tfx/examples/airflow_workshop/taxi/setup/
./setup_demo.sh
El código anterior
- Instale los paquetes necesarios.
- Cree una carpeta
airflowen la carpeta de inicio. - Copie la carpeta
dagsde la carpetatfx/tfx/examples/airflow_workshop/taxi/setup/~/airflow/. - Copie el archivo csv de
tfx/tfx/examples/airflow_workshop/taxi/setup/dataa~/airflow/data.
Configurando el servidor de flujo de aire
Cree una regla de firewall para acceder al servidor de flujo de aire en el navegador
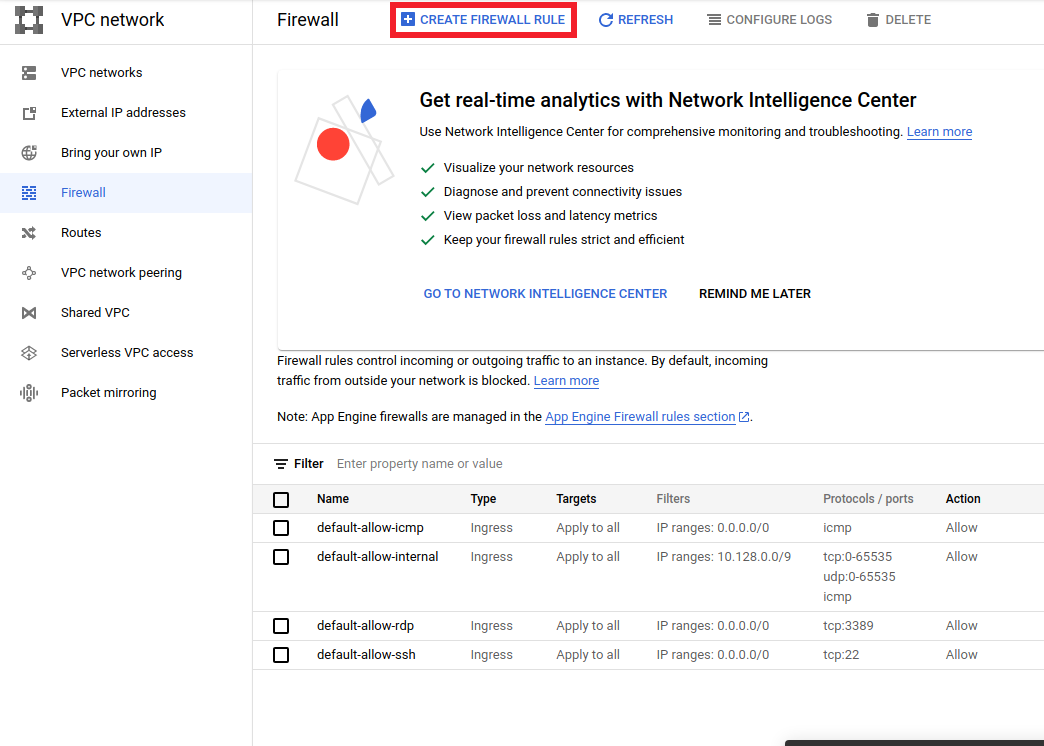
- Vaya a
<a href="https://console.cloud.google.com/networking/firewalls/list">https://console.cloud.google.com/networking/firewalls/list</a>y asegúrese el nombre del proyecto se selecciona apropiadamente - Haga clic en la opción
CREATE FIREWALL RULEen la parte superior
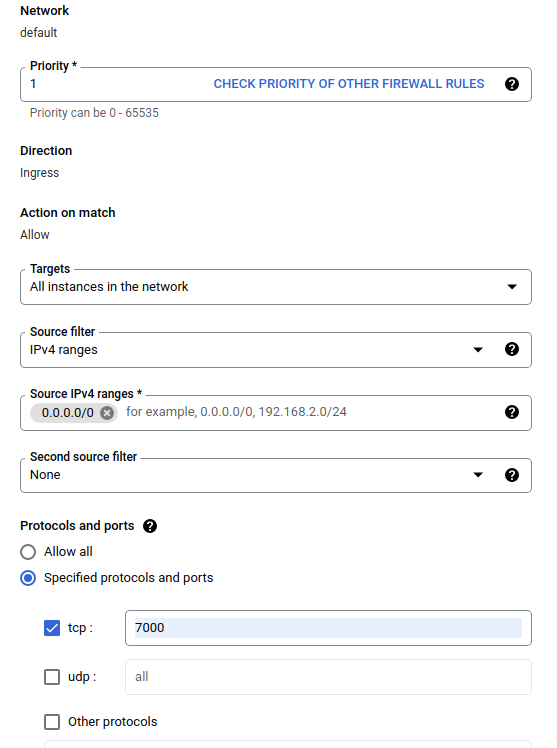
En el cuadro de diálogo Crear un firewall , siga los pasos que se enumeran a continuación.
- Para Nombre , escriba
airflow-tfx. - Para Prioridad , seleccione
1. - Para Destinos , seleccione
All instances in the network. - Para rangos de IPv4 de origen , seleccione
0.0.0.0/0 - Para Protocolos y puertos , haga clic en
tcpe ingrese7000en el cuadro al lado detcp - Haga clic en
Create.
Ejecute el servidor de flujo de aire desde su shell
En la ventana Terminal de Jupyter Lab, cambie al directorio de inicio, ejecute el comando airflow users create para crear un usuario administrador para Airflow:
cd
airflow users create --role Admin --username admin --email admin --firstname admin --lastname admin --password admin
Luego ejecute el airflow webserver y el comando airflow scheduler para ejecutar el servidor. Elija el puerto 7000 ya que está permitido a través del firewall.
nohup airflow webserver -p 7000 &> webserver.out &
nohup airflow scheduler &> scheduler.out &
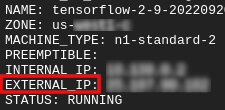
Consigue tu ip externa
- En Cloud Shell, usa
gcloudpara obtener la IP externa.
gcloud compute instances list
Ejecución de un DAG/canalización
en un navegador
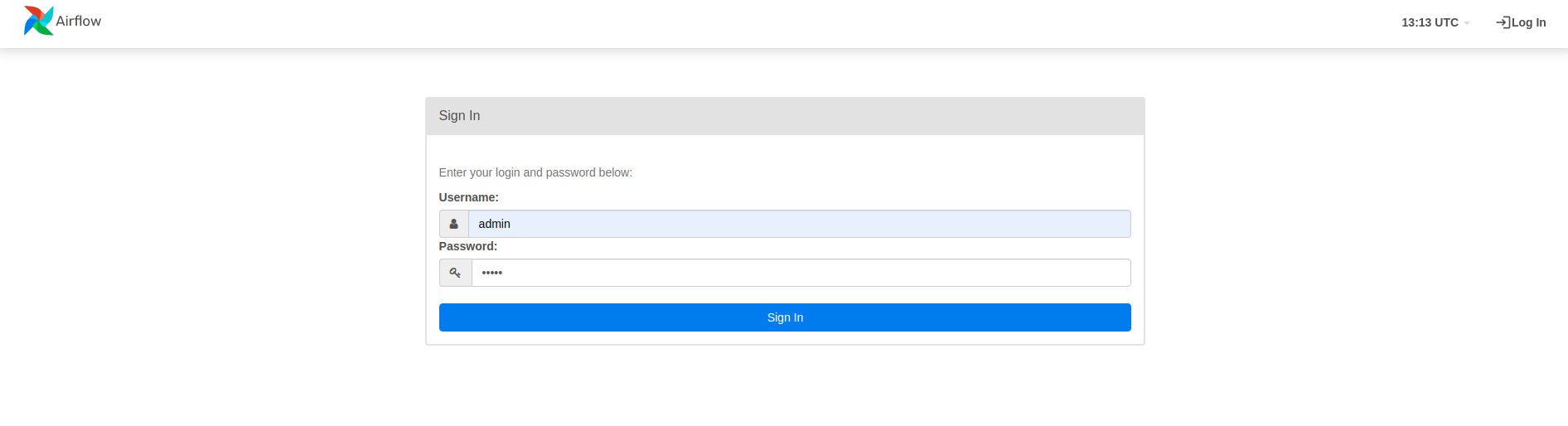
Abra un navegador y vaya a http://
- En la página de inicio de sesión, ingrese el nombre de usuario (
admin) y la contraseña (admin) que eligió al ejecutar el comandoairflow users create.
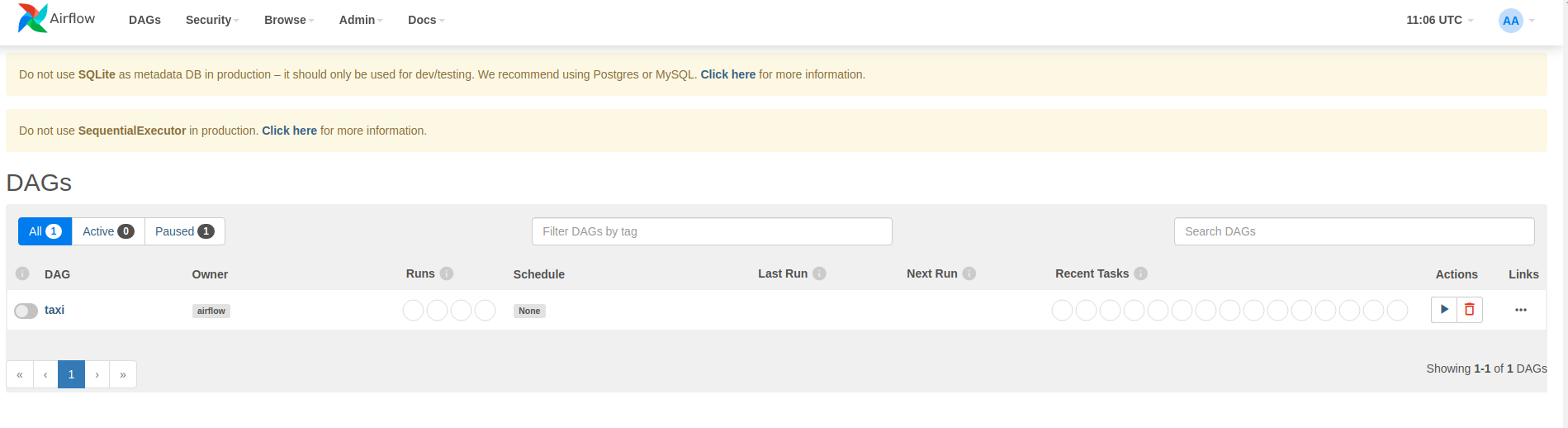
Airflow carga DAG desde archivos fuente de Python. Toma cada archivo y lo ejecuta. Luego carga cualquier objeto DAG de ese archivo. Todos los archivos .py que definen objetos DAG aparecerán como tuberías en la página de inicio del flujo de aire.
En este tutorial, Airflow escanea la carpeta ~/airflow/dags/ en busca de objetos DAG.
Si abre ~/airflow/dags/taxi_pipeline.py y se desplaza hasta el final, puede ver que crea y almacena un objeto DAG en una variable llamada DAG . Por lo tanto, aparecerá como tubería en la página de inicio de flujo de aire como se muestra a continuación:
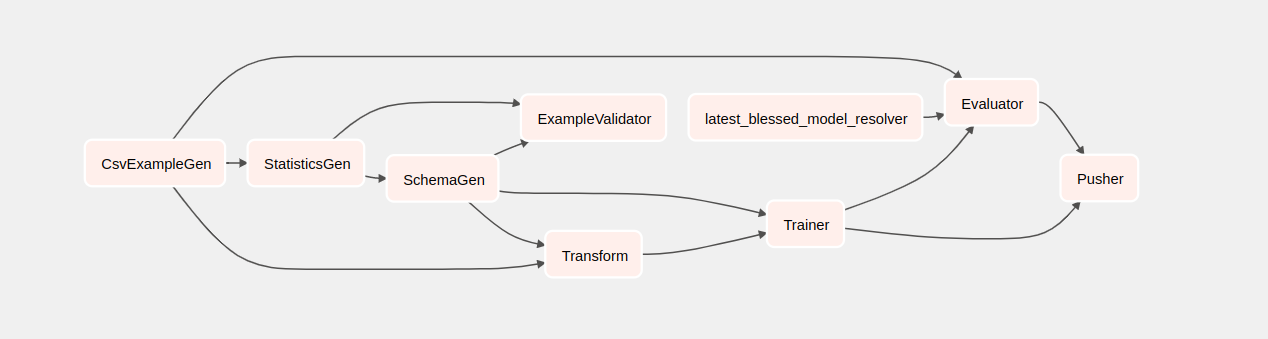
Si hace clic en taxi, será redirigido a la vista de cuadrícula del DAG. Puede hacer clic en la opción Graph en la parte superior para obtener la vista gráfica del DAG.
Activar el oleoducto del taxi
En la página de inicio puede ver los botones que se pueden utilizar para interactuar con el DAG.
Debajo del encabezado de acciones , haga clic en el botón de activación para activar la canalización.
En la página del DAG del taxi, use el botón de la derecha para actualizar el estado de la vista gráfica del DAG a medida que se ejecuta la tubería. Además, puede habilitar la actualización automática para indicarle a Airflow que actualice automáticamente la vista del gráfico a medida que cambia el estado.
También puede usar Airflow CLI en la terminal para habilitar y activar sus DAG:
# enable/disable
airflow pause <your DAG name>
airflow unpause <your DAG name>
# trigger
airflow trigger_dag <your DAG name>
Esperando a que se complete el oleoducto
Una vez que haya activado su canalización, en la vista DAG, puede observar el progreso de su canalización mientras se ejecuta. A medida que se ejecuta cada componente, el color del contorno del componente en el gráfico DAG cambiará para mostrar su estado. Cuando un componente haya terminado de procesarse, el contorno se volverá verde oscuro para mostrar que ya está hecho.
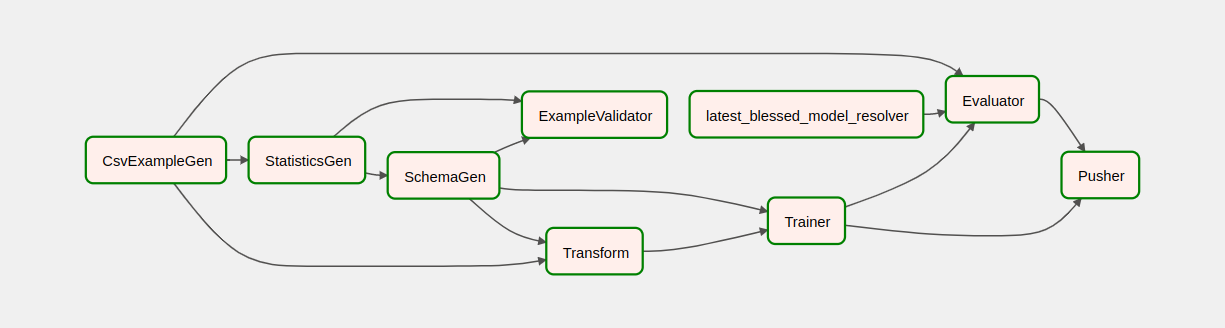
Entendiendo los componentes
Ahora veremos los componentes de este proceso en detalle y analizaremos individualmente los resultados producidos por cada paso del proceso.
En JupyterLab, vaya a
~/tfx/tfx/examples/airflow_workshop/taxi/notebooks/Abra notebook.ipynb.

Continúe con la práctica de laboratorio en el cuaderno y ejecute cada celda haciendo clic en Ejecutar (
 ) icono en la parte superior de la pantalla. Alternativamente, puede ejecutar el código en una celda con SHIFT + ENTER .
) icono en la parte superior de la pantalla. Alternativamente, puede ejecutar el código en una celda con SHIFT + ENTER .
Lea la narrativa y asegúrese de comprender lo que sucede en cada celda.