
परिचय
यह ट्यूटोरियल टेन्सरफ्लो एक्सटेंडेड (टीएफएक्स) और एआईप्लेटफॉर्म पाइपलाइनों को पेश करने के लिए डिज़ाइन किया गया है, और आपको Google क्लाउड पर अपनी खुद की मशीन लर्निंग पाइपलाइन बनाना सीखने में मदद करता है। यह टीएफएक्स, एआई प्लेटफॉर्म पाइपलाइन और क्यूबफ्लो के साथ एकीकरण के साथ-साथ ज्यूपिटर नोटबुक में टीएफएक्स के साथ इंटरैक्शन दिखाता है।
इस ट्यूटोरियल के अंत में, आपने Google क्लाउड पर होस्ट की गई एक एमएल पाइपलाइन बनाई और चलायी होगी। आप प्रत्येक दौड़ के परिणामों की कल्पना करने और निर्मित कलाकृतियों की वंशावली को देखने में सक्षम होंगे।
आप एक सामान्य एमएल विकास प्रक्रिया का पालन करेंगे, जो डेटासेट की जांच से शुरू होगी और एक पूर्ण कामकाजी पाइपलाइन के साथ समाप्त होगी। रास्ते में आप अपनी पाइपलाइन को डीबग और अपडेट करने और प्रदर्शन को मापने के तरीकों का पता लगाएंगे।
शिकागो टैक्सी डेटासेट


आप शिकागो शहर द्वारा जारी टैक्सी ट्रिप डेटासेट का उपयोग कर रहे हैं।
आप Google BigQuery में डेटासेट के बारे में अधिक पढ़ सकते हैं। BigQuery UI में संपूर्ण डेटासेट का अन्वेषण करें।
मॉडल लक्ष्य - बाइनरी वर्गीकरण
क्या ग्राहक 20% से अधिक या कम टिप देगा?
1. एक Google क्लाउड प्रोजेक्ट सेट करें
1.a अपना परिवेश Google क्लाउड पर सेट करें
आरंभ करने के लिए, आपको एक Google क्लाउड खाते की आवश्यकता है। यदि आपके पास पहले से ही एक है, तो नया प्रोजेक्ट बनाने के लिए आगे बढ़ें।
Google क्लाउड कंसोल पर जाएं.
Google क्लाउड के नियम और शर्तों से सहमत हों
यदि आप निःशुल्क परीक्षण खाते के साथ शुरुआत करना चाहते हैं, तो मुफ़्त में आज़माएँ (या मुफ़्त में आरंभ करें ) पर क्लिक करें।
अपने देश का चयन करॊ।
सेवा की शर्तों से सहमत हैं.
बिलिंग विवरण दर्ज करें.
इस बिंदु पर आपसे शुल्क नहीं लिया जाएगा. यदि आपके पास कोई अन्य Google क्लाउड प्रोजेक्ट नहीं है, तो आप Google क्लाउड फ्री टियर सीमा को पार किए बिना इस ट्यूटोरियल को पूरा कर सकते हैं, जिसमें एक ही समय में चलने वाले अधिकतम 8 कोर शामिल हैं।
1.बी एक नया प्रोजेक्ट बनाएं।
- मुख्य Google क्लाउड डैशबोर्ड से, Google क्लाउड प्लेटफ़ॉर्म हेडर के आगे प्रोजेक्ट ड्रॉपडाउन पर क्लिक करें और नया प्रोजेक्ट चुनें।
- अपने प्रोजेक्ट को एक नाम दें और अन्य प्रोजेक्ट विवरण दर्ज करें
- एक बार जब आप कोई प्रोजेक्ट बना लें, तो उसे प्रोजेक्ट ड्रॉप-डाउन से चुनना सुनिश्चित करें।
2. नए Kubernetes क्लस्टर पर AI प्लेटफ़ॉर्म पाइपलाइन स्थापित करें और तैनात करें
एआई प्लेटफ़ॉर्म पाइपलाइन क्लस्टर पृष्ठ पर जाएँ।
मुख्य नेविगेशन मेनू के अंतर्गत: ≡ > एआई प्लेटफ़ॉर्म > पाइपलाइन
नया क्लस्टर बनाने के लिए + नया इंस्टेंस पर क्लिक करें।
क्यूबफ़्लो पाइपलाइन अवलोकन पृष्ठ पर, कॉन्फ़िगर करें पर क्लिक करें।

कुबेरनेट्स इंजन एपीआई को सक्षम करने के लिए "सक्षम करें" पर क्लिक करें
परिनियोजन क्यूबफ़्लो पाइपलाइन पृष्ठ पर:
अपने क्लस्टर के लिए एक ज़ोन (या "क्षेत्र") चुनें। नेटवर्क और सबनेटवर्क सेट किया जा सकता है, लेकिन इस ट्यूटोरियल के प्रयोजनों के लिए हम उन्हें डिफ़ॉल्ट के रूप में छोड़ देंगे।
महत्वपूर्ण निम्नलिखित क्लाउड एपीआई तक पहुंच की अनुमति दें लेबल वाले बॉक्स को चेक करें। (इस क्लस्टर के लिए आपके प्रोजेक्ट के अन्य हिस्सों तक पहुंचने के लिए यह आवश्यक है। यदि आप इस चरण को चूक जाते हैं, तो इसे बाद में ठीक करना थोड़ा मुश्किल है।)

नया क्लस्टर बनाएं पर क्लिक करें, और क्लस्टर बनने तक कई मिनट तक प्रतीक्षा करें। इसमें कुछ मिनट लगेंगे. जब यह पूरा हो जाएगा तो आपको एक संदेश दिखाई देगा जैसे:
क्लस्टर "क्लस्टर-1" जोन "यूएस-सेंट्रल1-ए" में सफलतापूर्वक बनाया गया।
एक नेमस्पेस और इंस्टेंस नाम चुनें (डिफ़ॉल्ट का उपयोग करना ठीक है)। इस ट्यूटोरियल के प्रयोजनों के लिए executor.emissary या Managestorage.enabled की जाँच न करें।
परिनियोजन पर क्लिक करें, और पाइपलाइन तैनात होने तक कई क्षण प्रतीक्षा करें। क्यूबफ्लो पाइपलाइनों को तैनात करके, आप सेवा की शर्तों को स्वीकार करते हैं।
3. क्लाउड एआई प्लेटफ़ॉर्म नोटबुक इंस्टेंस सेट करें।
वर्टेक्स एआई वर्कबेंच पेज पर जाएं। पहली बार जब आप वर्कबेंच चलाएंगे तो आपको नोटबुक एपीआई को सक्षम करने की आवश्यकता होगी।
मुख्य नेविगेशन मेनू के अंतर्गत: ≡ -> वर्टेक्स एआई -> वर्कबेंच
यदि संकेत दिया जाए, तो कंप्यूट इंजन एपीआई सक्षम करें।
TensorFlow Enterprise 2.7 (या ऊपर) इंस्टॉल करके एक नया नोटबुक बनाएं।
नया नोटबुक -> टेन्सरफ्लो एंटरप्राइज 2.7 -> बिना जीपीयू के
एक क्षेत्र और ज़ोन चुनें, और नोटबुक इंस्टेंस को एक नाम दें।
फ्री टियर सीमा के भीतर रहने के लिए, आपको इस उदाहरण के लिए उपलब्ध वीसीपीयू की संख्या को 4 से घटाकर 2 करने के लिए यहां डिफ़ॉल्ट सेटिंग्स को बदलने की आवश्यकता हो सकती है:
- नए नोटबुक फॉर्म के नीचे उन्नत विकल्प चुनें।
यदि आपको फ्री टियर में रहना है तो मशीन कॉन्फ़िगरेशन के अंतर्गत आप 1 या 2 वीसीपीयू के साथ कॉन्फ़िगरेशन का चयन करना चाह सकते हैं।
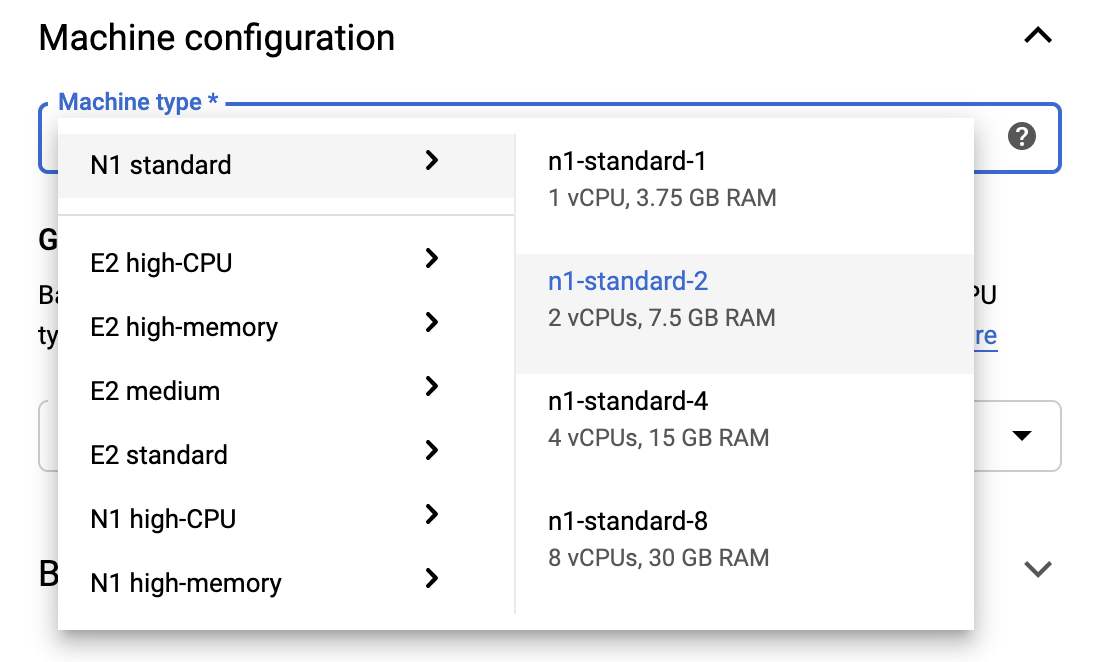
नई नोटबुक बनने तक प्रतीक्षा करें और फिर नोटबुक एपीआई सक्षम करें पर क्लिक करें
4. प्रारंभ करना नोटबुक लॉन्च करें
एआई प्लेटफ़ॉर्म पाइपलाइन क्लस्टर पृष्ठ पर जाएँ।
मुख्य नेविगेशन मेनू के अंतर्गत: ≡ -> एआई प्लेटफ़ॉर्म -> पाइपलाइन
इस ट्यूटोरियल में आप जिस क्लस्टर का उपयोग कर रहे हैं उसकी लाइन पर, पाइपलाइन डैशबोर्ड खोलें पर क्लिक करें।

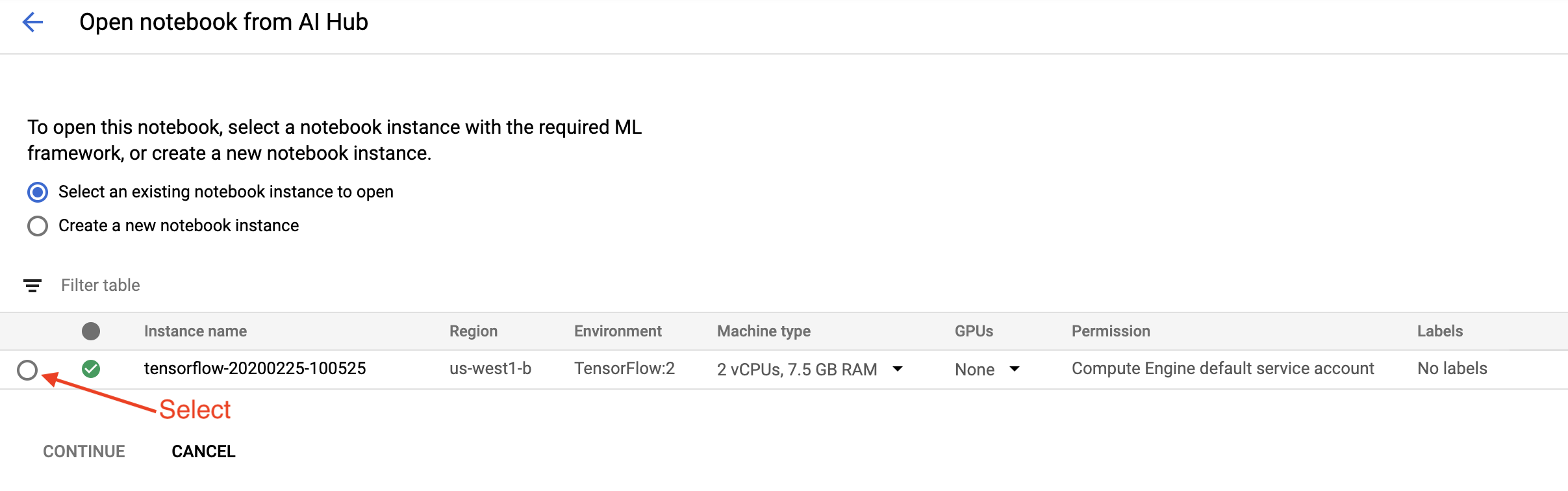
प्रारंभ करना पृष्ठ पर, Google क्लाउड पर क्लाउड AI प्लेटफ़ॉर्म नोटबुक खोलें पर क्लिक करें।

इस ट्यूटोरियल के लिए आप जिस नोटबुक इंस्टेंस का उपयोग कर रहे हैं उसे चुनें और जारी रखें , और फिर पुष्टि करें ।
5. नोटबुक में काम करना जारी रखें
स्थापित करना
गेटिंग स्टार्टेड नोटबुक उस वीएम में टीएफएक्स और क्यूबफ्लो पाइपलाइन (केएफपी) स्थापित करके शुरू होती है, जिसमें ज्यूपिटर लैब चल रही है।
इसके बाद यह जांचता है कि टीएफएक्स का कौन सा संस्करण स्थापित है, एक आयात करता है, और प्रोजेक्ट आईडी सेट और प्रिंट करता है:

अपनी Google क्लाउड सेवाओं से जुड़ें
पाइपलाइन कॉन्फ़िगरेशन के लिए आपके प्रोजेक्ट आईडी की आवश्यकता होती है, जिसे आप नोटबुक के माध्यम से प्राप्त कर सकते हैं और एक पर्यावरण चर के रूप में सेट कर सकते हैं।
# Read GCP project id from env.
shell_output=!gcloud config list --format 'value(core.project)' 2>/dev/null
GCP_PROJECT_ID=shell_output[0]
print("GCP project ID:" + GCP_PROJECT_ID)
अब अपना KFP क्लस्टर एंडपॉइंट सेट करें।
इसे पाइपलाइन डैशबोर्ड के URL से पाया जा सकता है। क्यूबफ्लो पाइपलाइन डैशबोर्ड पर जाएं और यूआरएल देखें। समापन बिंदु यूआरएल में https:// से शुरू होकर googleusercontent.com तक सब कुछ है।
ENDPOINT='' # Enter YOUR ENDPOINT here.
फिर नोटबुक कस्टम डॉकर छवि के लिए एक अद्वितीय नाम सेट करता है:
# Docker image name for the pipeline image
CUSTOM_TFX_IMAGE='gcr.io/' + GCP_PROJECT_ID + '/tfx-pipeline'
6. अपनी प्रोजेक्ट निर्देशिका में एक टेम्पलेट कॉपी करें
अपनी पाइपलाइन के लिए एक नाम सेट करने के लिए अगली नोटबुक सेल संपादित करें। इस ट्यूटोरियल में हम my_pipeline उपयोग करेंगे।
PIPELINE_NAME="my_pipeline"
PROJECT_DIR=os.path.join(os.path.expanduser("~"),"imported",PIPELINE_NAME)
फिर नोटबुक पाइपलाइन टेम्पलेट को कॉपी करने के लिए tfx CLI का उपयोग करता है। यह ट्यूटोरियल बाइनरी वर्गीकरण करने के लिए शिकागो टैक्सी डेटासेट का उपयोग करता है, इसलिए टेम्पलेट मॉडल को taxi पर सेट करता है:
!tfx template copy \
--pipeline-name={PIPELINE_NAME} \
--destination-path={PROJECT_DIR} \
--model=taxi
फिर नोटबुक अपने CWD संदर्भ को प्रोजेक्ट निर्देशिका में बदल देती है:
%cd {PROJECT_DIR}
पाइपलाइन फ़ाइलें ब्राउज़ करें
क्लाउड एआई प्लेटफ़ॉर्म नोटबुक के बाईं ओर, आपको एक फ़ाइल ब्राउज़र देखना चाहिए। आपके पाइपलाइन नाम ( my_pipeline ) के साथ एक निर्देशिका होनी चाहिए। इसे खोलें और फ़ाइलें देखें. (आप उन्हें नोटबुक परिवेश से खोलने और संपादित करने में भी सक्षम होंगे।)
# You can also list the files from the shellls
ऊपर दिए गए tfx template copy कमांड ने फ़ाइलों का एक बुनियादी ढांचा तैयार किया जो एक पाइपलाइन का निर्माण करता है। इनमें पायथन स्रोत कोड, नमूना डेटा और ज्यूपिटर नोटबुक शामिल हैं। ये इस विशेष उदाहरण के लिए हैं। आपकी अपनी पाइपलाइनों के लिए ये सहायक फ़ाइलें होंगी जिनकी आपकी पाइपलाइन को आवश्यकता है।
यहां पायथन फ़ाइलों का संक्षिप्त विवरण दिया गया है।
-
pipeline- इस निर्देशिका में पाइपलाइन की परिभाषा शामिल है-
configs.py- पाइपलाइन धावकों के लिए सामान्य स्थिरांक को परिभाषित करता है -
pipeline.py- TFX घटकों और एक पाइपलाइन को परिभाषित करता है
-
-
models- इस निर्देशिका में एमएल मॉडल परिभाषाएँ शामिल हैं।-
features.pyfeatures_test.py- मॉडल के लिए सुविधाओं को परिभाषित करता है -
preprocessing.py/preprocessing_test.py-tf::Transformका उपयोग करके प्रीप्रोसेसिंग नौकरियों को परिभाषित करता है -
estimator- इस निर्देशिका में एक अनुमानक आधारित मॉडल शामिल है।-
constants.py- मॉडल के स्थिरांक को परिभाषित करता है -
model.py/model_test.py- TF अनुमानक का उपयोग करके DNN मॉडल को परिभाषित करता है
-
-
keras- इस निर्देशिका में केरस आधारित मॉडल शामिल है।-
constants.py- मॉडल के स्थिरांक को परिभाषित करता है -
model.py/model_test.py- केरस का उपयोग करके DNN मॉडल को परिभाषित करता है
-
-
-
beam_runner.py/kubeflow_runner.py- प्रत्येक ऑर्केस्ट्रेशन इंजन के लिए धावकों को परिभाषित करें
7. अपनी पहली TFX पाइपलाइन Kubeflow पर चलाएँ
नोटबुक tfx run CLI कमांड का उपयोग करके पाइपलाइन चलाएगा।
भंडारण से कनेक्ट करें
चलने वाली पाइपलाइनें कलाकृतियों का निर्माण करती हैं जिन्हें एमएल-मेटाडेटा में संग्रहीत किया जाना है। कलाकृतियाँ पेलोड को संदर्भित करती हैं, जो फ़ाइलें हैं जिन्हें फ़ाइल सिस्टम या ब्लॉक स्टोरेज में संग्रहीत किया जाना चाहिए। इस ट्यूटोरियल के लिए, हम अपने मेटाडेटा पेलोड को स्टोर करने के लिए GCS का उपयोग करेंगे, सेटअप के दौरान स्वचालित रूप से बनाई गई बकेट का उपयोग करके। इसका नाम <your-project-id>-kubeflowpipelines-default होगा।
पाइपलाइन बनाएं
नोटबुक हमारे नमूना डेटा को जीसीएस बकेट में अपलोड करेगा ताकि हम इसे बाद में अपनी पाइपलाइन में उपयोग कर सकें।
gsutil cp data/data.csv gs://{GOOGLE_CLOUD_PROJECT}-kubeflowpipelines-default/tfx-template/data/taxi/data.csv फिर नोटबुक पाइपलाइन बनाने के लिए tfx pipeline create कमांड का उपयोग करता है।
!tfx pipeline create \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT} \
--build-image
पाइपलाइन बनाते समय, Docker छवि बनाने के लिए Dockerfile उत्पन्न की जाएगी। इन फ़ाइलों को अन्य स्रोत फ़ाइलों के साथ अपने स्रोत नियंत्रण सिस्टम (उदाहरण के लिए, git) में जोड़ना न भूलें।
पाइपलाइन चलाएँ
नोटबुक तब आपकी पाइपलाइन का निष्पादन रन शुरू करने के लिए tfx run create कमांड का उपयोग करता है। आप इस रन को क्यूबफ़्लो पाइपलाइन डैशबोर्ड में प्रयोगों के अंतर्गत सूचीबद्ध भी देखेंगे।
tfx run create --pipeline-name={PIPELINE_NAME} --endpoint={ENDPOINT}आप अपनी पाइपलाइन को क्यूबफ़्लो पाइपलाइन डैशबोर्ड से देख सकते हैं।
8. अपना डेटा मान्य करें
किसी भी डेटा साइंस या एमएल प्रोजेक्ट में पहला काम डेटा को समझना और साफ करना है।
- प्रत्येक सुविधा के लिए डेटा प्रकार को समझें
- विसंगतियों और लुप्त मूल्यों की तलाश करें
- प्रत्येक सुविधा के वितरण को समझें
अवयव


- exampleGen इनपुट डेटासेट को अंतर्ग्रहण और विभाजित करता है।
- स्टैटिस्टिक्सजेन डेटासेट के लिए आंकड़ों की गणना करता है।
- SchemaGen SchemaGen आंकड़ों की जांच करता है और एक डेटा स्कीमा बनाता है।
- उदाहरण सत्यापनकर्ता डेटासेट में विसंगतियों और गुम मानों की तलाश करता है।
ज्यूपिटर लैब फ़ाइल संपादक में:
pipeline / pipeline.py में, उन पंक्तियों को अनटिप्पणी करें जो इन घटकों को आपकी पाइपलाइन में जोड़ती हैं:
# components.append(statistics_gen)
# components.append(schema_gen)
# components.append(example_validator)
(टेम्पलेट फ़ाइलों की प्रतिलिपि बनाते समय ExampleGen पहले से ही सक्षम था।)
पाइपलाइन को अद्यतन करें और इसे पुनः चलाएँ
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
पाइपलाइन की जाँच करें
क्यूबफ्लो ऑर्केस्ट्रेटर के लिए, केएफपी डैशबोर्ड पर जाएं और अपने पाइपलाइन रन के लिए पेज में पाइपलाइन आउटपुट ढूंढें। बाईं ओर "प्रयोग" टैब पर क्लिक करें, और प्रयोग पृष्ठ में "सभी रन" पर क्लिक करें। आपको अपनी पाइपलाइन के नाम के साथ रन ढूंढने में सक्षम होना चाहिए।
अधिक उन्नत उदाहरण
यहां प्रस्तुत उदाहरण वास्तव में केवल आपको आरंभ करने के लिए है। अधिक उन्नत उदाहरण के लिए TensorFlow डेटा वैलिडेशन कोलैब देखें।
किसी डेटासेट का अन्वेषण और सत्यापन करने के लिए TFDV का उपयोग करने के बारे में अधिक जानकारी के लिए, Tensorflow.org पर उदाहरण देखें ।
9. फ़ीचर इंजीनियरिंग
आप फीचर इंजीनियरिंग के साथ अपने डेटा की पूर्वानुमानित गुणवत्ता बढ़ा सकते हैं और/या आयामीता कम कर सकते हैं।
- फ़ीचर क्रॉस
- शब्दसंग्रह
- एंबेडिंग
- पीसीए
- श्रेणीबद्ध एन्कोडिंग
टीएफएक्स का उपयोग करने का एक लाभ यह है कि आप अपना परिवर्तन कोड एक बार लिखेंगे, और परिणामी परिवर्तन प्रशिक्षण और सेवा के बीच सुसंगत होंगे।
अवयव

- ट्रांसफ़ॉर्म डेटासेट पर फ़ीचर इंजीनियरिंग निष्पादित करता है।
ज्यूपिटर लैब फ़ाइल संपादक में:
pipeline / pipeline.py में, उस लाइन को ढूंढें और अनकम्मेंट करें जो ट्रांसफॉर्म को पाइपलाइन से जोड़ती है।
# components.append(transform)
पाइपलाइन को अद्यतन करें और इसे पुनः चलाएँ
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
पाइपलाइन आउटपुट की जाँच करें
क्यूबफ्लो ऑर्केस्ट्रेटर के लिए, केएफपी डैशबोर्ड पर जाएं और अपने पाइपलाइन रन के लिए पेज में पाइपलाइन आउटपुट ढूंढें। बाईं ओर "प्रयोग" टैब पर क्लिक करें, और प्रयोग पृष्ठ में "सभी रन" पर क्लिक करें। आपको अपनी पाइपलाइन के नाम के साथ रन ढूंढने में सक्षम होना चाहिए।
अधिक उन्नत उदाहरण
यहां प्रस्तुत उदाहरण वास्तव में केवल आपको आरंभ करने के लिए है। अधिक उन्नत उदाहरण के लिए TensorFlow Transform Colab देखें।
10. प्रशिक्षण
अपने अच्छे, स्वच्छ, रूपांतरित डेटा के साथ एक TensorFlow मॉडल को प्रशिक्षित करें।
- पिछले चरण के परिवर्तनों को शामिल करें ताकि उन्हें लगातार लागू किया जा सके
- उत्पादन के लिए परिणामों को SaveModel के रूप में सहेजें
- TensorBoard का उपयोग करके प्रशिक्षण प्रक्रिया की कल्पना करें और उसका अन्वेषण करें
- मॉडल प्रदर्शन के विश्लेषण के लिए एक इवलसेव्डमॉडल भी सहेजें
अवयव
- ट्रेनर एक TensorFlow मॉडल को प्रशिक्षित करता है।
ज्यूपिटर लैब फ़ाइल संपादक में:
pipeline / pipeline.py में, ट्रेनर को पाइपलाइन में जोड़ने वाले को ढूंढें और अनकम्मेंट करें:
# components.append(trainer)
पाइपलाइन को अद्यतन करें और इसे पुनः चलाएँ
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
पाइपलाइन आउटपुट की जाँच करें
क्यूबफ्लो ऑर्केस्ट्रेटर के लिए, केएफपी डैशबोर्ड पर जाएं और अपने पाइपलाइन रन के लिए पेज में पाइपलाइन आउटपुट ढूंढें। बाईं ओर "प्रयोग" टैब पर क्लिक करें, और प्रयोग पृष्ठ में "सभी रन" पर क्लिक करें। आपको अपनी पाइपलाइन के नाम के साथ रन ढूंढने में सक्षम होना चाहिए।
अधिक उन्नत उदाहरण
यहां प्रस्तुत उदाहरण वास्तव में केवल आपको आरंभ करने के लिए है। अधिक उन्नत उदाहरण के लिए TensorBoard ट्यूटोरियल देखें।
11. मॉडल प्रदर्शन का विश्लेषण
केवल शीर्ष स्तर के मेट्रिक्स से अधिक को समझना।
- उपयोगकर्ता केवल अपने प्रश्नों के लिए मॉडल प्रदर्शन का अनुभव करते हैं
- डेटा के स्लाइस पर खराब प्रदर्शन को शीर्ष स्तरीय मेट्रिक्स द्वारा छुपाया जा सकता है
- मॉडल निष्पक्षता महत्वपूर्ण है
- अक्सर उपयोगकर्ताओं या डेटा के मुख्य उपसमूह बहुत महत्वपूर्ण होते हैं, और छोटे भी हो सकते हैं
- गंभीर लेकिन असामान्य परिस्थितियों में प्रदर्शन
- प्रभावशाली लोगों जैसे प्रमुख दर्शकों के लिए प्रदर्शन
- यदि आप किसी ऐसे मॉडल को बदल रहे हैं जो वर्तमान में उत्पादन में है, तो पहले सुनिश्चित करें कि नया बेहतर है
अवयव
- मूल्यांकनकर्ता प्रशिक्षण परिणामों का गहन विश्लेषण करता है।
ज्यूपिटर लैब फ़ाइल संपादक में:
pipeline / pipeline.py में, उस लाइन को ढूंढें और अनकम्मेंट करें जो इवैल्यूएटर को पाइपलाइन से जोड़ती है:
components.append(evaluator)
पाइपलाइन को अद्यतन करें और इसे पुनः चलाएँ
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
पाइपलाइन आउटपुट की जाँच करें
क्यूबफ्लो ऑर्केस्ट्रेटर के लिए, केएफपी डैशबोर्ड पर जाएं और अपने पाइपलाइन रन के लिए पेज में पाइपलाइन आउटपुट ढूंढें। बाईं ओर "प्रयोग" टैब पर क्लिक करें, और प्रयोग पृष्ठ में "सभी रन" पर क्लिक करें। आपको अपनी पाइपलाइन के नाम के साथ रन ढूंढने में सक्षम होना चाहिए।
12. मॉडल की सेवा करना
यदि नया मॉडल तैयार है तो उसे तैयार कर लें।
- पुशर सेव्डमॉडल को प्रसिद्ध स्थानों पर तैनात करता है
परिनियोजन लक्ष्यों को प्रसिद्ध स्थानों से नए मॉडल प्राप्त होते हैं
- टेन्सरफ्लो सर्विंग
- टेन्सरफ्लो लाइट
- टेन्सरफ्लो जेएस
- टेन्सरफ्लो हब
अवयव
- पुशर मॉडल को एक सेवारत बुनियादी ढांचे में तैनात करता है।
ज्यूपिटर लैब फ़ाइल संपादक में:
pipeline / pipeline.py में, पुशर को पाइपलाइन से जोड़ने वाली लाइन को ढूंढें और अनकम्मेंट करें:
# components.append(pusher)
पाइपलाइन आउटपुट की जाँच करें
क्यूबफ्लो ऑर्केस्ट्रेटर के लिए, केएफपी डैशबोर्ड पर जाएं और अपने पाइपलाइन रन के लिए पेज में पाइपलाइन आउटपुट ढूंढें। बाईं ओर "प्रयोग" टैब पर क्लिक करें, और प्रयोग पृष्ठ में "सभी रन" पर क्लिक करें। आपको अपनी पाइपलाइन के नाम के साथ रन ढूंढने में सक्षम होना चाहिए।
उपलब्ध परिनियोजन लक्ष्य
आपने अब अपने मॉडल को प्रशिक्षित और मान्य कर लिया है, और आपका मॉडल अब उत्पादन के लिए तैयार है। अब आप अपने मॉडल को किसी भी TensorFlow परिनियोजन लक्ष्य पर परिनियोजित कर सकते हैं, जिनमें शामिल हैं:
- TensorFlow सर्विंग , आपके मॉडल को सर्वर या सर्वर फ़ार्म पर परोसने और REST और/या gRPC अनुमान अनुरोधों को संसाधित करने के लिए।
- TensorFlow Lite , आपके मॉडल को Android या iOS मूल मोबाइल एप्लिकेशन, या रास्पबेरी पाई, IoT, या माइक्रोकंट्रोलर एप्लिकेशन में शामिल करने के लिए।
- TensorFlow.js , अपने मॉडल को वेब ब्राउज़र या Node.JS एप्लिकेशन में चलाने के लिए।
अधिक उन्नत उदाहरण
ऊपर प्रस्तुत उदाहरण वास्तव में केवल आपको आरंभ करने के लिए है। नीचे अन्य क्लाउड सेवाओं के साथ एकीकरण के कुछ उदाहरण दिए गए हैं।
क्यूबफ्लो पाइपलाइन संसाधन संबंधी विचार
आपके कार्यभार की आवश्यकताओं के आधार पर, आपके क्यूबफ़्लो पाइपलाइन परिनियोजन के लिए डिफ़ॉल्ट कॉन्फ़िगरेशन आपकी आवश्यकताओं को पूरा कर भी सकता है और नहीं भी। आप KubeflowDagRunnerConfig पर अपनी कॉल में pipeline_operator_funcs का उपयोग करके अपने संसाधन कॉन्फ़िगरेशन को अनुकूलित कर सकते हैं।
pipeline_operator_funcs OpFunc आइटमों की एक सूची है, जो KFP पाइपलाइन स्पेक में सभी जेनरेट किए गए ContainerOp इंस्टेंसेस को बदल देती है, जो KubeflowDagRunner से संकलित है।
उदाहरण के लिए, मेमोरी को कॉन्फ़िगर करने के लिए हम आवश्यक मेमोरी की मात्रा घोषित करने के लिए set_memory_request उपयोग कर सकते हैं। ऐसा करने का एक सामान्य तरीका है set_memory_request के लिए एक रैपर बनाना और इसे पाइपलाइन OpFunc s की सूची में जोड़ने के लिए उपयोग करना:
def request_more_memory():
def _set_memory_spec(container_op):
container_op.set_memory_request('32G')
return _set_memory_spec
# Then use this opfunc in KubeflowDagRunner
pipeline_op_funcs = kubeflow_dag_runner.get_default_pipeline_operator_funcs()
pipeline_op_funcs.append(request_more_memory())
config = KubeflowDagRunnerConfig(
pipeline_operator_funcs=pipeline_op_funcs,
...
)
kubeflow_dag_runner.KubeflowDagRunner(config=config).run(pipeline)
समान संसाधन कॉन्फ़िगरेशन फ़ंक्शंस में शामिल हैं:
-
set_memory_limit -
set_cpu_request -
set_cpu_limit -
set_gpu_limit
BigQueryExampleGen आज़माएँ
BigQuery एक सर्वर रहित, अत्यधिक स्केलेबल और लागत प्रभावी क्लाउड डेटा वेयरहाउस है। BigQuery का उपयोग TFX में उदाहरणों के प्रशिक्षण के लिए एक स्रोत के रूप में किया जा सकता है। इस चरण में, हम पाइपलाइन में BigQueryExampleGen जोड़ेंगे।
ज्यूपिटर लैब फ़ाइल संपादक में:
pipeline.py खोलने के लिए डबल-क्लिक करें । CsvExampleGen पर टिप्पणी करें और उस पंक्ति को अनकम्मेंट करें जो BigQueryExampleGen का उदाहरण बनाती है। आपको create_pipeline फ़ंक्शन के query तर्क को भी अनकम्मेंट करना होगा।
हमें यह निर्दिष्ट करने की आवश्यकता है कि BigQuery के लिए किस GCP प्रोजेक्ट का उपयोग करना है, और यह पाइपलाइन बनाते समय beam_pipeline_args में --project सेट करके किया जाता है।
configs.py खोलने के लिए डबल-क्लिक करें । BIG_QUERY_WITH_DIRECT_RUNNER_BEAM_PIPELINE_ARGS और BIG_QUERY_QUERY की परिभाषा को असंबद्ध करें। आपको इस फ़ाइल में प्रोजेक्ट आईडी और क्षेत्र मान को अपने GCP प्रोजेक्ट के लिए सही मानों से बदलना चाहिए।
निर्देशिका को एक स्तर ऊपर बदलें। फ़ाइल सूची के ऊपर निर्देशिका के नाम पर क्लिक करें। यदि आपने पाइपलाइन का नाम नहीं बदला है तो निर्देशिका का नाम पाइपलाइन का नाम है जो my_pipeline है।
kubeflow_runner.py खोलने के लिए डबल-क्लिक करें । create_pipeline फ़ंक्शन के लिए दो तर्क, query और beam_pipeline_args अनकम्मेंट करें।
अब पाइपलाइन उदाहरण स्रोत के रूप में BigQuery का उपयोग करने के लिए तैयार है। पाइपलाइन को पहले की तरह अपडेट करें और एक नया निष्पादन रन बनाएं जैसा हमने चरण 5 और 6 में किया था।
पाइपलाइन को अद्यतन करें और इसे पुनः चलाएँ
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
डेटाफ्लो आज़माएं
कई टीएफएक्स घटक डेटा-समानांतर पाइपलाइनों को लागू करने के लिए अपाचे बीम का उपयोग करते हैं , और इसका मतलब है कि आप Google क्लाउड डेटाफ़्लो का उपयोग करके डेटा प्रोसेसिंग वर्कलोड वितरित कर सकते हैं। इस चरण में, हम अपाचे बीम के लिए डेटा प्रोसेसिंग बैक-एंड के रूप में डेटाफ़्लो का उपयोग करने के लिए क्यूबफ़्लो ऑर्केस्ट्रेटर को सेट करेंगे।
# Select your project:
gcloud config set project YOUR_PROJECT_ID
# Get a list of services that you can enable in your project:
gcloud services list --available | grep Dataflow
# If you don't see dataflow.googleapis.com listed, that means you haven't been
# granted access to enable the Dataflow API. See your account adminstrator.
# Enable the Dataflow service:
gcloud services enable dataflow.googleapis.com
निर्देशिका बदलने के लिए pipeline डबल-क्लिक करें, और configs.py खोलने के लिए डबल-क्लिक करें । GOOGLE_CLOUD_REGION और DATAFLOW_BEAM_PIPELINE_ARGS की परिभाषा को असंबद्ध करें।
निर्देशिका को एक स्तर ऊपर बदलें। फ़ाइल सूची के ऊपर निर्देशिका के नाम पर क्लिक करें। निर्देशिका का नाम पाइपलाइन का नाम है जो कि यदि आपने नहीं बदला है तो my_pipeline है।
kubeflow_runner.py खोलने के लिए डबल-क्लिक करें । beam_pipeline_args टिप्पणी हटाएं। (चरण 7 में आपके द्वारा जोड़े गए वर्तमान beam_pipeline_args पर टिप्पणी करना भी सुनिश्चित करें।)
पाइपलाइन को अद्यतन करें और इसे पुनः चलाएँ
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
आप क्लाउड कंसोल में डेटाफ़्लो में अपनी डेटाफ़्लो नौकरियां पा सकते हैं।
KFP के साथ क्लाउड AI प्लेटफ़ॉर्म प्रशिक्षण और भविष्यवाणी आज़माएँ
टीएफएक्स कई प्रबंधित जीसीपी सेवाओं के साथ इंटरऑपरेट करता है, जैसे प्रशिक्षण और भविष्यवाणी के लिए क्लाउड एआई प्लेटफॉर्म । आप अपने Trainer घटक को क्लाउड एआई प्लेटफ़ॉर्म ट्रेनिंग का उपयोग करने के लिए सेट कर सकते हैं, जो एमएल मॉडल के प्रशिक्षण के लिए एक प्रबंधित सेवा है। इसके अलावा, जब आपका मॉडल बन जाता है और सेवा के लिए तैयार हो जाता है, तो आप सेवा के लिए अपने मॉडल को क्लाउड एआई प्लेटफ़ॉर्म प्रेडिक्शन पर भेज सकते हैं। इस चरण में, हम क्लाउड एआई प्लेटफ़ॉर्म सेवाओं का उपयोग करने के लिए अपने Trainer और Pusher घटक को सेट करेंगे।
फ़ाइलों को संपादित करने से पहले, आपको पहले एआई प्लेटफ़ॉर्म ट्रेनिंग और प्रेडिक्शन एपीआई को सक्षम करना होगा।
निर्देशिका बदलने के लिए pipeline डबल-क्लिक करें, और configs.py खोलने के लिए डबल-क्लिक करें । GOOGLE_CLOUD_REGION , GCP_AI_PLATFORM_TRAINING_ARGS और GCP_AI_PLATFORM_SERVING_ARGS की परिभाषा को हटाएं। हम क्लाउड AI प्लेटफ़ॉर्म प्रशिक्षण में एक मॉडल को प्रशिक्षित करने के लिए अपनी कस्टम निर्मित कंटेनर छवि का उपयोग करेंगे, इसलिए हमें GCP_AI_PLATFORM_TRAINING_ARGS में masterConfig.imageUri उपरोक्त CUSTOM_TFX_IMAGE के समान मान पर सेट करना चाहिए।
निर्देशिका को एक स्तर ऊपर बदलें, और kubeflow_runner.py खोलने के लिए डबल-क्लिक करें । ai_platform_training_args और ai_platform_serving_args टिप्पणी हटाएँ।
पाइपलाइन को अद्यतन करें और इसे पुनः चलाएँ
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
आप क्लाउड एआई प्लेटफ़ॉर्म जॉब्स में अपनी प्रशिक्षण नौकरियां पा सकते हैं। यदि आपकी पाइपलाइन सफलतापूर्वक पूरी हो गई है, तो आप अपना मॉडल क्लाउड एआई प्लेटफ़ॉर्म मॉडल में पा सकते हैं।
14. अपने स्वयं के डेटा का उपयोग करें
इस ट्यूटोरियल में, आपने शिकागो टैक्सी डेटासेट का उपयोग करके एक मॉडल के लिए एक पाइपलाइन बनाई। अब अपना डेटा पाइपलाइन में डालने का प्रयास करें। आपका डेटा कहीं भी संग्रहीत किया जा सकता है जहां पाइपलाइन उस तक पहुंच सकती है, जिसमें Google क्लाउड स्टोरेज, BigQuery, या CSV फ़ाइलें शामिल हैं।
आपको अपने डेटा को समायोजित करने के लिए पाइपलाइन परिभाषा को संशोधित करने की आवश्यकता है।
यदि आपका डेटा फाइलों में संग्रहीत है
- स्थान दर्शाते हुए,
kubeflow_runner.pyमेंDATA_PATHसंशोधित करें।
यदि आपका डेटा BigQuery में संग्रहीत है
- अपने क्वेरी कथन में configs.py में
BIG_QUERY_QUERYसंशोधित करें। -
models/features.pyमें सुविधाएँ जोड़ें। - प्रशिक्षण के लिए इनपुट डेटा को बदलने के लिए
models/preprocessing.pyसंशोधित करें। - अपने एमएल मॉडल का वर्णन करने के लिए
models/keras/model.pyऔरmodels/keras/constants.pyको संशोधित करें।
ट्रेनर के बारे में और जानें
प्रशिक्षण पाइपलाइनों पर अधिक जानकारी के लिए ट्रेनर घटक मार्गदर्शिका देखें।
सफाई
इस प्रोजेक्ट में उपयोग किए गए सभी Google क्लाउड संसाधनों को साफ़ करने के लिए, आप ट्यूटोरियल के लिए उपयोग किए गए Google क्लाउड प्रोजेक्ट को हटा सकते हैं।
वैकल्पिक रूप से, आप प्रत्येक कंसोल पर जाकर व्यक्तिगत संसाधनों को साफ़ कर सकते हैं: - Google क्लाउड स्टोरेज - Google कंटेनर रजिस्ट्री - Google Kubernetes इंजन