
Введение
Это руководство предназначено для ознакомления с конвейерами TensorFlow Extended (TFX) и AIPlatform , а также поможет вам научиться создавать собственные конвейеры машинного обучения в Google Cloud. Здесь показана интеграция с TFX, AI Platform Pipelines и Kubeflow, а также взаимодействие с TFX в ноутбуках Jupyter.
В конце этого руководства вы создадите и запустите конвейер машинного обучения, размещенный в Google Cloud. Вы сможете визуализировать результаты каждого запуска и просмотреть происхождение созданных артефактов.
Вы будете следовать типичному процессу разработки машинного обучения, начиная с изучения набора данных и заканчивая полным рабочим конвейером. Попутно вы изучите способы отладки и обновления вашего конвейера, а также измерения производительности.
Набор данных такси Чикаго


Вы используете набор данных Taxi Trips , опубликованный властями города Чикаго.
Подробнее о наборе данных можно прочитать в Google BigQuery . Изучите полный набор данных в пользовательском интерфейсе BigQuery .
Цель модели — двоичная классификация
Будет ли клиент давать чаевые больше или меньше 20%?
1. Настройте проект Google Cloud.
1.a Настройте свою среду в Google Cloud
Для начала вам понадобится учетная запись Google Cloud. Если он у вас уже есть, перейдите к «Создать новый проект» .
Перейдите в облачную консоль Google .
Согласитесь с условиями использования Google Cloud
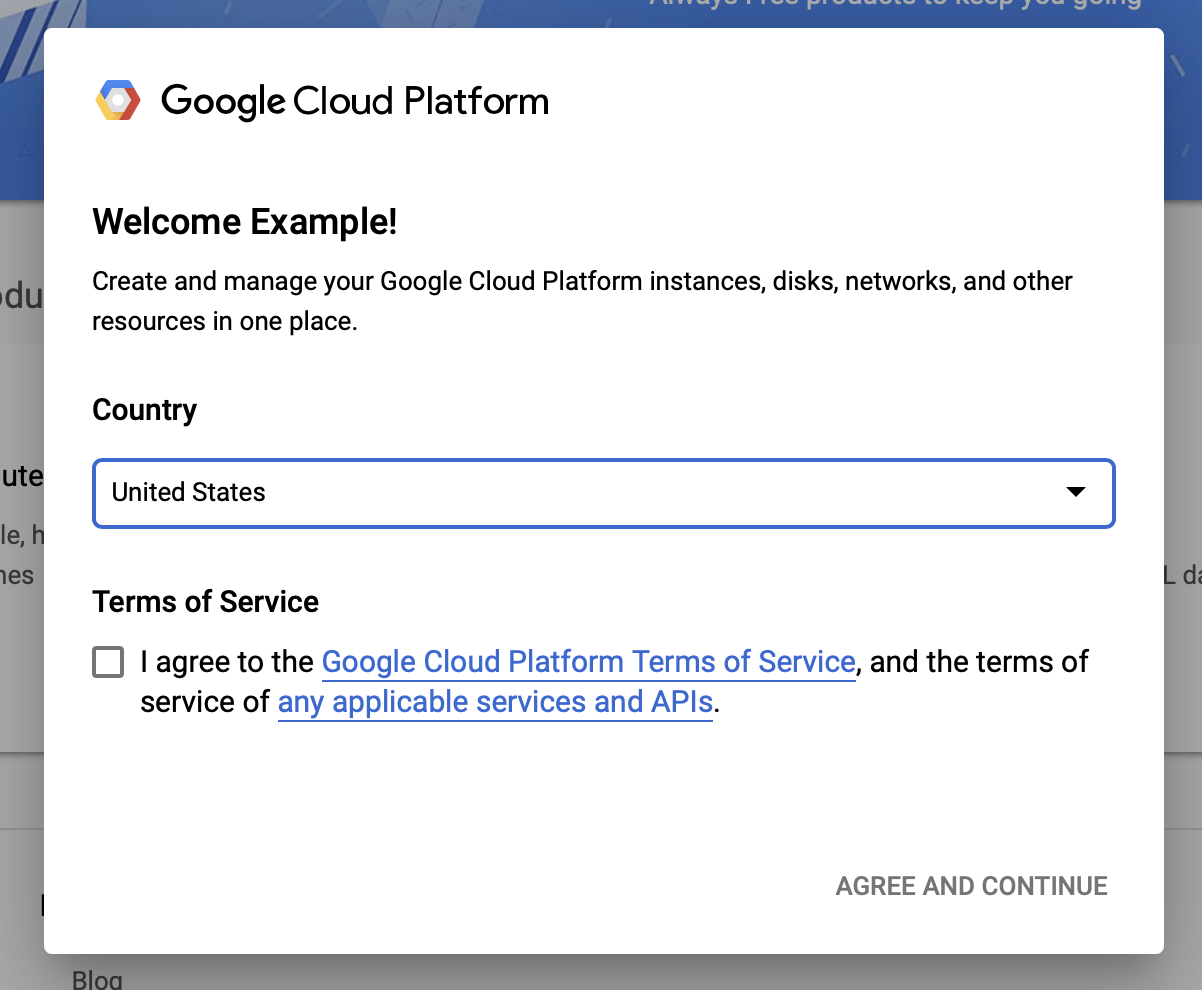
Если вы хотите начать с бесплатной пробной учетной записи, нажмите «Попробовать бесплатно» (или «Начать бесплатно » ).
Выберите свою страну.
Согласитесь с условиями обслуживания.
Введите платежные данные.
На этом этапе с вас не будет взиматься плата. Если у вас нет других проектов Google Cloud, вы можете пройти это руководство, не превышая ограничений уровня бесплатного пользования Google Cloud , который включает максимум 8 ядер, работающих одновременно.
1.б Создайте новый проект.
- На главной панели управления Google Cloud щелкните раскрывающийся список проекта рядом с заголовком Google Cloud Platform и выберите «Новый проект» .
- Дайте своему проекту имя и введите другие сведения о проекте.
- После создания проекта обязательно выберите его из раскрывающегося списка проектов.
2. Настройка и развертывание конвейера платформы AI в новом кластере Kubernetes.
Перейдите на страницу «Кластеры конвейеров платформы AI» .
В главном меню навигации: ≡ > Платформа AI > Трубопроводы.
Нажмите + Новый экземпляр , чтобы создать новый кластер.
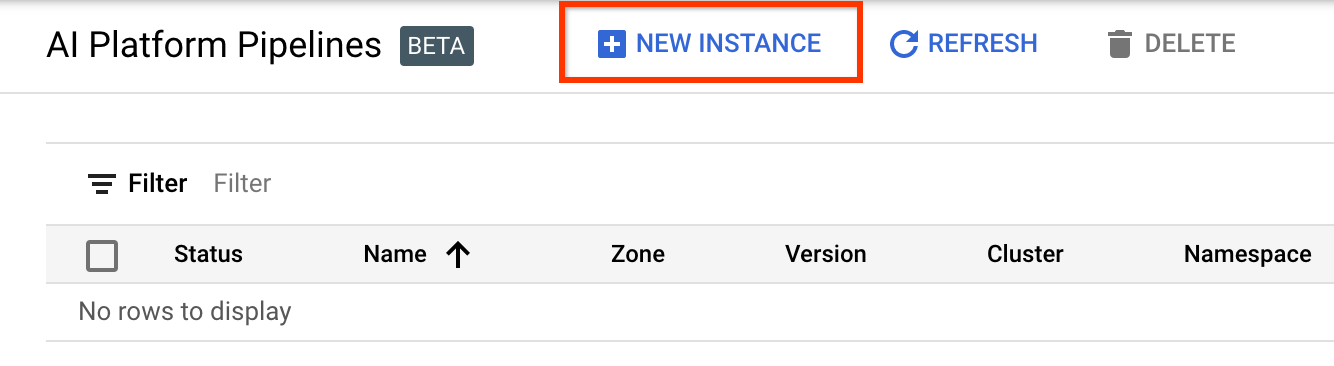
На странице обзора Kubeflow Pipelines нажмите « Настроить» .

Нажмите «Включить», чтобы включить API Kubernetes Engine.
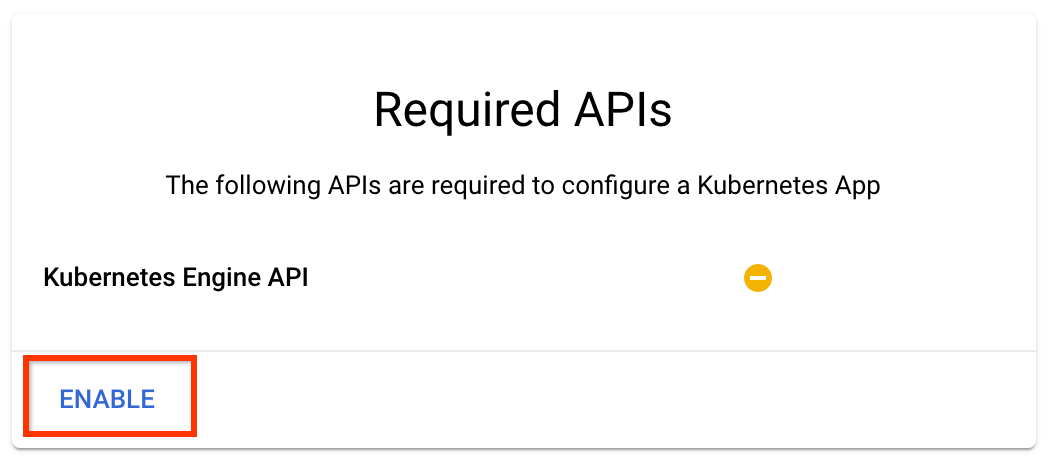
На странице «Развертывание конвейеров Kubeflow» :
Выберите зону (или «регион») для вашего кластера. Сеть и подсеть можно настроить, но для целей данного руководства мы оставим их по умолчанию.
ВАЖНО Установите флажок Разрешить доступ к следующим облачным API . (Это необходимо для того, чтобы этот кластер имел доступ к другим частям вашего проекта. Если вы пропустите этот шаг, исправить его позже будет немного сложнее.)
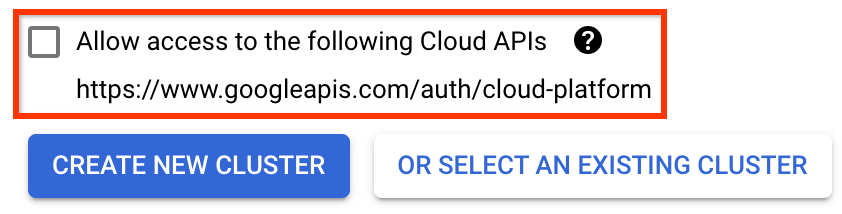
Нажмите «Создать новый кластер» и подождите несколько минут, пока кластер не будет создан. Это займет несколько минут. Когда он завершится, вы увидите сообщение типа:
Кластер «cluster-1» успешно создан в зоне «us-central1-a».
Выберите пространство имен и имя экземпляра (можно использовать значения по умолчанию). Для целей данного руководства не проверяйте executor.emissary или Managedstorage.enabled .
Нажмите «Развернуть» и подождите несколько секунд, пока конвейер не будет развернут. Развертывая Kubeflow Pipelines, вы принимаете Условия обслуживания.
3. Настройте экземпляр Cloud AI Platform Notebook.
Перейдите на страницу Vertex AI Workbench . При первом запуске Workbench вам необходимо включить API ноутбуков.
В главном меню навигации: ≡ -> Vertex AI -> Workbench.
При появлении запроса включите API Compute Engine.
Создайте новый блокнот с установленным TensorFlow Enterprise 2.7 (или более поздней версии).
Новый ноутбук -> TensorFlow Enterprise 2.7 -> Без графического процессора
Выберите регион и зону и дайте экземпляру записной книжки имя.
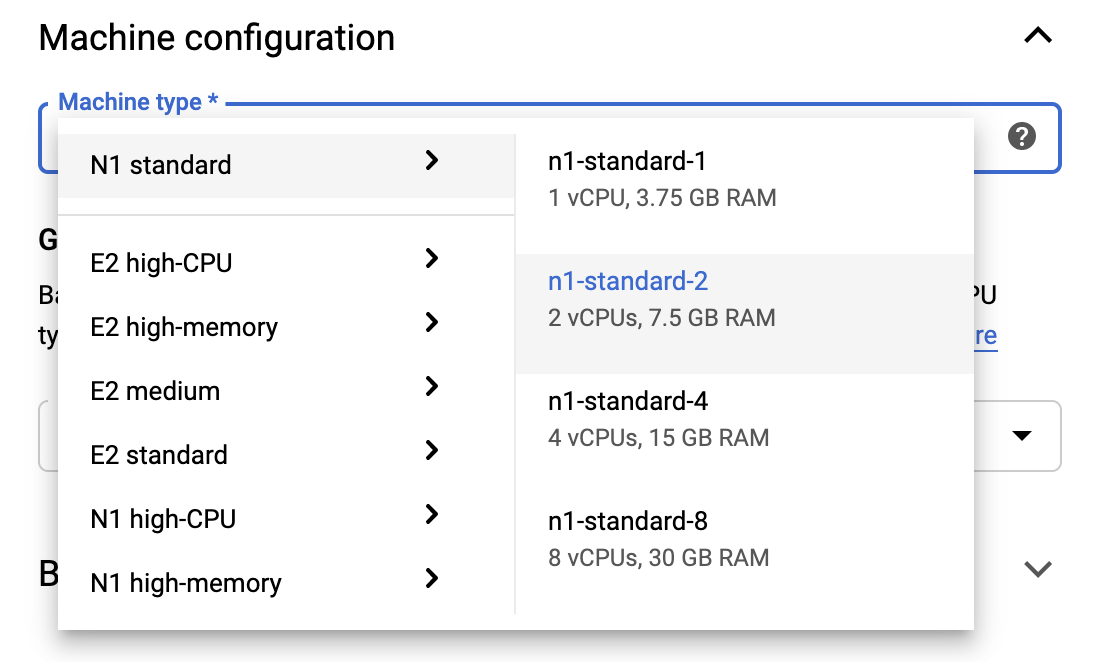
Чтобы оставаться в пределах уровня бесплатного пользования, вам может потребоваться изменить настройки по умолчанию здесь, чтобы уменьшить количество виртуальных ЦП, доступных для этого экземпляра, с 4 до 2:
- Выберите «Дополнительные параметры» в нижней части формы «Новый блокнот» .
В разделе «Конфигурация компьютера» вы можете выбрать конфигурацию с 1 или 2 виртуальными ЦП, если вам нужно оставаться на бесплатном уровне.
Подождите, пока будет создана новая записная книжка, а затем нажмите «Включить API записных книжек».
4. Запустите блокнот «Начало работы».
Перейдите на страницу «Кластеры конвейеров платформы AI» .
В главном меню навигации: ≡ -> Платформа AI -> Конвейеры.
В строке кластера, который вы используете в этом руководстве, нажмите «Открыть панель мониторинга конвейеров» .

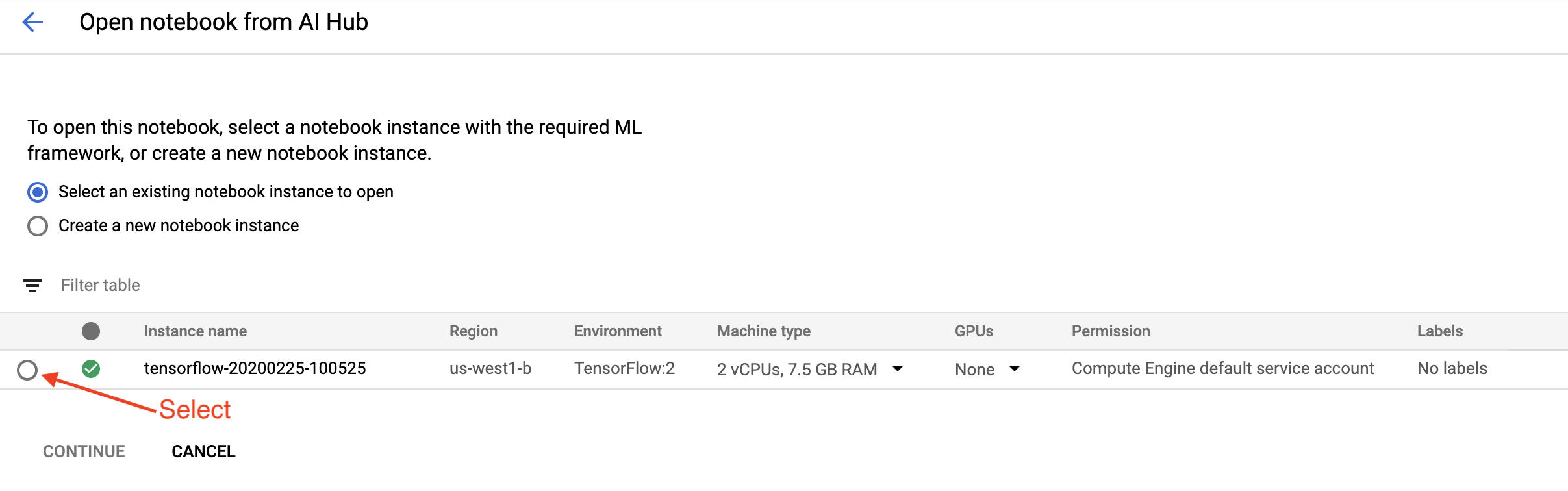
На странице «Начало работы» нажмите «Открыть блокнот Cloud AI Platform в Google Cloud» .

Выберите экземпляр Notebook, который вы используете для этого руководства, нажмите «Продолжить» , а затем «Подтвердить» .
5. Продолжаем работать в Блокноте.
Установить
Записная книжка по началу работы начинается с установки TFX и Kubeflow Pipelines (KFP) на виртуальную машину, на которой работает Jupyter Lab.
Затем он проверяет, какая версия TFX установлена, выполняет импорт, а также устанавливает и печатает идентификатор проекта:

Подключитесь к своим облачным сервисам Google
Для конфигурации конвейера требуется идентификатор вашего проекта, который вы можете получить через блокнот и установить в качестве переменной среды.
# Read GCP project id from env.
shell_output=!gcloud config list --format 'value(core.project)' 2>/dev/null
GCP_PROJECT_ID=shell_output[0]
print("GCP project ID:" + GCP_PROJECT_ID)
Теперь установите конечную точку кластера KFP.
Его можно найти по URL-адресу информационной панели Pipelines. Перейдите на панель управления Kubeflow Pipeline и посмотрите URL-адрес. Конечная точка – это все в URL-адресе , начиная с https:// и заканчивая googleusercontent.com включительно.
ENDPOINT='' # Enter YOUR ENDPOINT here.
Затем блокнот задает уникальное имя для пользовательского образа Docker:
# Docker image name for the pipeline image
CUSTOM_TFX_IMAGE='gcr.io/' + GCP_PROJECT_ID + '/tfx-pipeline'
6. Скопируйте шаблон в каталог вашего проекта.
Отредактируйте следующую ячейку блокнота, чтобы задать имя для вашего конвейера. В этом уроке мы будем использовать my_pipeline .
PIPELINE_NAME="my_pipeline"
PROJECT_DIR=os.path.join(os.path.expanduser("~"),"imported",PIPELINE_NAME)
Затем ноутбук использует интерфейс командной строки tfx для копирования шаблона конвейера. В этом руководстве используется набор данных «Такси Чикаго» для выполнения двоичной классификации, поэтому в шаблоне задается модель taxi :
!tfx template copy \
--pipeline-name={PIPELINE_NAME} \
--destination-path={PROJECT_DIR} \
--model=taxi
Затем записная книжка меняет свой контекст CWD на каталог проекта:
%cd {PROJECT_DIR}
Просмотрите файлы конвейера
В левой части записной книжки Cloud AI Platform вы должны увидеть файловый браузер. Должен быть каталог с именем вашего конвейера ( my_pipeline ). Откройте его и просмотрите файлы. (Вы также сможете открывать их и редактировать из среды записной книжки.)
# You can also list the files from the shellls
Команда tfx template copy приведенная выше, создала базовый каркас файлов, которые создают конвейер. К ним относятся исходные коды Python, примеры данных и блокноты Jupyter. Они предназначены для этого конкретного примера. Для ваших собственных конвейеров это будут вспомогательные файлы, необходимые вашему конвейеру.
Вот краткое описание файлов Python.
-
pipeline— этот каталог содержит определение конвейера.-
configs.py— определяет общие константы для участников конвейера. -
pipeline.py— определяет компоненты TFX и конвейер.
-
-
models— этот каталог содержит определения моделей машинного обучения.-
features.pyfeatures_test.py— определяет функции модели. -
preprocessing.py/preprocessing_test.py— определяет задания предварительной обработки с использованиемtf::Transform -
estimator— этот каталог содержит модель на основе оценщика.-
constants.py— определяет константы модели. -
model.py/model_test.py— определяет модель DNN с использованием средства оценки TF.
-
-
keras— этот каталог содержит модель на основе Keras.-
constants.py— определяет константы модели. -
model.py/model_test.py— определяет модель DNN с использованием Keras.
-
-
-
beam_runner.py— определите бегунов для каждого механизма оркестровкиkubeflow_runner.py
7. Запустите свой первый конвейер TFX на Kubeflow.
Ноутбук запустит конвейер с помощью команды CLI tfx run .
Подключиться к хранилищу
Запуск конвейеров создает артефакты, которые необходимо хранить в ML-Metadata . Артефакты относятся к полезным нагрузкам, которые представляют собой файлы, которые должны храниться в файловой системе или блочном хранилище. В этом руководстве мы будем использовать GCS для хранения полезных данных метаданных, используя корзину, созданную автоматически во время установки. Его имя будет <your-project-id>-kubeflowpipelines-default .
Создайте конвейер
Блокнот загрузит наши образцы данных в корзину GCS, чтобы мы могли использовать их в нашем конвейере позже.
gsutil cp data/data.csv gs://{GOOGLE_CLOUD_PROJECT}-kubeflowpipelines-default/tfx-template/data/taxi/data.csv Затем ноутбук использует команду tfx pipeline create для создания конвейера.
!tfx pipeline create \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT} \
--build-image
При создании конвейера будет создан Dockerfile для создания образа Docker. Не забудьте добавить эти файлы в свою систему контроля версий (например, git) вместе с другими исходными файлами.
Запустите конвейер
Затем блокнот использует команду tfx run create чтобы начать выполнение вашего конвейера. Вы также увидите этот запуск в списке «Эксперименты» на панели инструментов Kubeflow Pipelines.
tfx run create --pipeline-name={PIPELINE_NAME} --endpoint={ENDPOINT}Вы можете просмотреть свой конвейер на панели инструментов Kubeflow Pipelines.
8. Проверьте свои данные
Первой задачей в любом проекте по науке о данных или ML-проекте является понимание и очистка данных.
- Понимание типов данных для каждого объекта
- Ищите аномалии и пропущенные значения
- Понимание распределения каждой функции
Компоненты


- ПримерGen принимает и разделяет входной набор данных.
- СтатистикаГен вычисляет статистику для набора данных.
- SchemaGen SchemaGen анализирует статистику и создает схему данных.
- ПримерВалидатор ищет аномалии и пропущенные значения в наборе данных.
В редакторе файлов Jupyter Lab:
В pipeline / pipeline.py раскомментируйте строки, которые добавляют эти компоненты в ваш конвейер:
# components.append(statistics_gen)
# components.append(schema_gen)
# components.append(example_validator)
( ExampleGen уже был включен при копировании файлов шаблонов.)
Обновите конвейер и перезапустите его.
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
Проверьте трубопровод
Для Kubeflow Orchestrator посетите панель управления KFP и найдите выходные данные конвейера на странице запуска вашего конвейера. Нажмите вкладку «Эксперименты» слева и «Все прогоны» на странице «Эксперименты». Вы сможете найти запуск по названию вашего конвейера.
Более продвинутый пример
Представленный здесь пример на самом деле предназначен только для начала. Более продвинутый пример см. в TensorFlow Data Validation Colab .
Дополнительную информацию об использовании TFDV для исследования и проверки набора данных см. в примерах на tensorflow.org .
9. Разработка функций
Вы можете повысить качество прогнозирования ваших данных и/или уменьшить размерность с помощью разработки функций.
- Кресты функций
- Словари
- Вложения
- СПС
- Категориальное кодирование
Одним из преимуществ использования TFX является то, что вы напишете код преобразования один раз, и полученные преобразования будут согласованы между обучением и обслуживанием.
Компоненты

- Transform выполняет разработку функций набора данных.
В редакторе файлов Jupyter Lab:
В pipeline / pipeline.py найдите и раскомментируйте строку, которая добавляет Transform к конвейеру.
# components.append(transform)
Обновите конвейер и перезапустите его.
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
Проверьте выходы конвейера
Для Kubeflow Orchestrator посетите панель управления KFP и найдите выходные данные конвейера на странице запуска вашего конвейера. Нажмите вкладку «Эксперименты» слева и «Все прогоны» на странице «Эксперименты». Вы сможете найти запуск по названию вашего конвейера.
Более продвинутый пример
Представленный здесь пример на самом деле предназначен только для начала. Более продвинутый пример см. в TensorFlow Transform Colab .
10. Обучение
Обучите модель TensorFlow с помощью красивых, чистых и преобразованных данных.
- Включите преобразования из предыдущего шага, чтобы они применялись последовательно.
- Сохраните результаты как SavedModel для производства.
- Визуализируйте и исследуйте процесс обучения с помощью TensorBoard.
- Также сохраните EvalSavedModel для анализа производительности модели.
Компоненты
- Тренер обучает модель TensorFlow.
В редакторе файлов Jupyter Lab:
В pipeline / pipeline.py найдите и раскомментируйте файл, который добавляет Trainer к конвейеру:
# components.append(trainer)
Обновите конвейер и перезапустите его.
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
Проверьте выходы конвейера
Для Kubeflow Orchestrator посетите панель управления KFP и найдите выходные данные конвейера на странице запуска вашего конвейера. Нажмите вкладку «Эксперименты» слева и «Все прогоны» на странице «Эксперименты». Вы сможете найти запуск по названию вашего конвейера.
Более продвинутый пример
Представленный здесь пример на самом деле предназначен только для начала. Более продвинутый пример смотрите в TensorBoard Tutorial .
11. Анализ производительности модели
Понимание большего, чем просто показатели верхнего уровня.
- Пользователи оценивают производительность модели только для своих запросов.
- Низкая производительность на фрагментах данных может быть скрыта метриками верхнего уровня.
- Справедливость модели важна
- Часто ключевые группы пользователей или данных очень важны и могут быть небольшими.
- Работа в критических, но необычных условиях
- Производительность для ключевых аудиторий, таких как влиятельные лица
- Если вы заменяете модель, которая сейчас находится в производстве, сначала убедитесь, что новая лучше.
Компоненты
- Оценщик проводит глубокий анализ результатов обучения.
В редакторе файлов Jupyter Lab:
В pipeline / pipeline.py найдите и раскомментируйте строку, которая добавляет Evaluator к конвейеру:
components.append(evaluator)
Обновите конвейер и перезапустите его.
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
Проверьте выходы конвейера
Для Kubeflow Orchestrator посетите панель управления KFP и найдите выходные данные конвейера на странице запуска вашего конвейера. Нажмите вкладку «Эксперименты» слева и «Все прогоны» на странице «Эксперименты». Вы сможете найти запуск по названию вашего конвейера.
12. Обслуживание модели
Если новая модель готова, сделайте это.
- Pusher развертывает SavedModels в известных местах
Цели развертывания получают новые модели из известных мест.
- Обслуживание TensorFlow
- ТензорФлоу Лайт
- ТензорФлоу JS
- TensorFlow Hub
Компоненты
- Pusher развертывает модель в обслуживающей инфраструктуре.
В редакторе файлов Jupyter Lab:
В pipeline / pipeline.py найдите и раскомментируйте строку, которая добавляет Pusher к конвейеру:
# components.append(pusher)
Проверьте выходы конвейера
Для Kubeflow Orchestrator посетите панель управления KFP и найдите выходные данные конвейера на странице запуска вашего конвейера. Нажмите вкладку «Эксперименты» слева и «Все прогоны» на странице «Эксперименты». Вы сможете найти запуск по названию вашего конвейера.
Доступные цели развертывания
Теперь вы обучили и проверили свою модель, и теперь она готова к производству. Теперь вы можете развернуть свою модель на любой из целей развертывания TensorFlow, включая:
- TensorFlow Serving — для обслуживания вашей модели на сервере или ферме серверов и обработки запросов вывода REST и/или gRPC.
- TensorFlow Lite для включения вашей модели в собственное мобильное приложение Android или iOS или в приложение Raspberry Pi, IoT или микроконтроллера.
- TensorFlow.js для запуска вашей модели в веб-браузере или приложении Node.JS.
Более сложные примеры
Представленный выше пример на самом деле предназначен только для начала. Ниже приведены некоторые примеры интеграции с другими облачными сервисами.
Рекомендации по ресурсам Kubeflow Pipelines
В зависимости от требований вашей рабочей нагрузки конфигурация по умолчанию для вашего развертывания Kubeflow Pipelines может соответствовать или не соответствовать вашим потребностям. Вы можете настроить конфигурации своих ресурсов, используя pipeline_operator_funcs в вызове KubeflowDagRunnerConfig .
pipeline_operator_funcs — это список элементов OpFunc , который преобразует все сгенерированные экземпляры ContainerOp в спецификацию конвейера KFP, скомпилированную из KubeflowDagRunner .
Например, для настройки памяти мы можем использовать set_memory_request , чтобы объявить необходимый объем памяти. Типичный способ сделать это — создать оболочку для set_memory_request и использовать ее для добавления в список OpFunc конвейера:
def request_more_memory():
def _set_memory_spec(container_op):
container_op.set_memory_request('32G')
return _set_memory_spec
# Then use this opfunc in KubeflowDagRunner
pipeline_op_funcs = kubeflow_dag_runner.get_default_pipeline_operator_funcs()
pipeline_op_funcs.append(request_more_memory())
config = KubeflowDagRunnerConfig(
pipeline_operator_funcs=pipeline_op_funcs,
...
)
kubeflow_dag_runner.KubeflowDagRunner(config=config).run(pipeline)
Подобные функции настройки ресурсов включают в себя:
-
set_memory_limit -
set_cpu_request -
set_cpu_limit -
set_gpu_limit
Попробуйте BigQueryExampleGen
BigQuery — это бессерверное, масштабируемое и экономичное облачное хранилище данных. BigQuery можно использовать в качестве источника обучающих примеров в TFX. На этом этапе мы добавим BigQueryExampleGen в конвейер.
В редакторе файлов Jupyter Lab:
Дважды щелкните, чтобы открыть pipeline.py . Закомментируйте CsvExampleGen и раскомментируйте строку, которая создает экземпляр BigQueryExampleGen . Вам также необходимо раскомментировать аргумент query функции create_pipeline .
Нам нужно указать, какой проект GCP использовать для BigQuery, и это делается путем установки --project в beam_pipeline_args при создании конвейера.
Дважды щелкните, чтобы открыть configs.py . Раскомментируйте определение BIG_QUERY_WITH_DIRECT_RUNNER_BEAM_PIPELINE_ARGS и BIG_QUERY_QUERY . Вам следует заменить идентификатор проекта и значение региона в этом файле правильными значениями для вашего проекта GCP.
Измените каталог на уровень выше. Щелкните имя каталога над списком файлов. Имя каталога — это имя конвейера, то есть my_pipeline , если вы не меняли имя конвейера.
Дважды щелкните, чтобы открыть kubeflow_runner.py . Раскомментируйте два аргумента, query и beam_pipeline_args для функции create_pipeline .
Теперь конвейер готов использовать BigQuery в качестве примера источника. Обновите конвейер, как раньше, и создайте новый запуск выполнения, как мы это делали на шагах 5 и 6.
Обновите конвейер и перезапустите его.
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
Попробуйте поток данных
Некоторые компоненты TFX используют Apache Beam для реализации конвейеров с параллельными данными, а это означает, что вы можете распределять рабочие нагрузки по обработке данных с помощью Google Cloud Dataflow . На этом этапе мы настроим оркестратор Kubeflow на использование Dataflow в качестве серверной части обработки данных для Apache Beam.
# Select your project:
gcloud config set project YOUR_PROJECT_ID
# Get a list of services that you can enable in your project:
gcloud services list --available | grep Dataflow
# If you don't see dataflow.googleapis.com listed, that means you haven't been
# granted access to enable the Dataflow API. See your account adminstrator.
# Enable the Dataflow service:
gcloud services enable dataflow.googleapis.com
Дважды щелкните pipeline , чтобы изменить каталог, и дважды щелкните, чтобы открыть configs.py . Раскомментируйте определения GOOGLE_CLOUD_REGION и DATAFLOW_BEAM_PIPELINE_ARGS .
Измените каталог на уровень выше. Щелкните имя каталога над списком файлов. Имя каталога — это имя конвейера, то есть my_pipeline , если вы не меняли его.
Дважды щелкните, чтобы открыть kubeflow_runner.py . Раскомментируйте beam_pipeline_args . (Также обязательно закомментируйте текущий beam_pipeline_args , который вы добавили на шаге 7.)
Обновите конвейер и перезапустите его.
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
Вы можете найти свои задания Dataflow в Dataflow в Cloud Console .
Попробуйте обучение и прогнозирование платформы Cloud AI с помощью KFP
TFX взаимодействует с несколькими управляемыми сервисами GCP, такими как облачная платформа искусственного интеллекта для обучения и прогнозирования . Вы можете настроить свой компонент Trainer на использование Cloud AI Platform Training, управляемого сервиса для обучения моделей машинного обучения. Более того, когда ваша модель построена и готова к использованию, вы можете отправить ее в Cloud AI Platform Prediction для обслуживания. На этом этапе мы настроим наш компонент Trainer и Pusher на использование сервисов Cloud AI Platform.
Прежде чем редактировать файлы, вам, возможно, придется сначала включить AI Platform Training & Prediction API .
Дважды щелкните pipeline , чтобы изменить каталог, и дважды щелкните, чтобы открыть configs.py . Раскомментируйте определения GOOGLE_CLOUD_REGION , GCP_AI_PLATFORM_TRAINING_ARGS и GCP_AI_PLATFORM_SERVING_ARGS . Мы будем использовать наш специально созданный образ контейнера для обучения модели в обучении Cloud AI Platform, поэтому нам следует установить masterConfig.imageUri в GCP_AI_PLATFORM_TRAINING_ARGS то же значение, что и для CUSTOM_TFX_IMAGE выше.
Измените каталог на один уровень выше и дважды щелкните, чтобы открыть kubeflow_runner.py . Раскомментируйте ai_platform_training_args и ai_platform_serving_args .
Обновите конвейер и перезапустите его.
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
Вы можете найти вакансии по обучению в разделе «Вакансии на платформе Cloud AI» . Если ваш конвейер завершился успешно, вы можете найти свою модель в разделе «Модели платформы Cloud AI» .
14. Используйте свои собственные данные
В этом уроке вы создали конвейер для модели, используя набор данных Chicago Taxi. Теперь попробуйте поместить в конвейер свои собственные данные. Ваши данные могут храниться везде, где конвейер может получить к ним доступ, включая Google Cloud Storage, BigQuery или файлы CSV.
Вам необходимо изменить определение конвейера, чтобы оно соответствовало вашим данным.
Если ваши данные хранятся в файлах
- Измените
DATA_PATHвkubeflow_runner.py, указав местоположение.
Если ваши данные хранятся в BigQuery
- Измените
BIG_QUERY_QUERYв configs.py на свой оператор запроса. - Добавьте функции в
models/features.py. - Измените
models/preprocessing.py, чтобы преобразовать входные данные для обучения . - Измените
models/keras/model.pyиmodels/keras/constants.py, чтобы описать вашу модель машинного обучения .
Узнать больше о тренере
Дополнительные сведения о конвейерах обучения см. в руководстве по компоненту Trainer .
Уборка
Чтобы очистить все ресурсы Google Cloud, используемые в этом проекте, вы можете удалить проект Google Cloud, который вы использовали в этом руководстве.
Кроме того, вы можете очистить отдельные ресурсы, посетив каждую консоль: - Google Cloud Storage - Google Container Registry - Google Kubernetes Engine .