
Giới thiệu
Hướng dẫn này được thiết kế để giới thiệu Đường dẫn TensorFlow Extended (TFX) và AIPlatform , đồng thời giúp bạn tìm hiểu cách tạo quy trình máy học của riêng mình trên Google Cloud. Nó cho thấy sự tích hợp với TFX, Đường ống nền tảng AI và Kubeflow, cũng như sự tương tác với TFX trong sổ ghi chép Jupyter.
Khi kết thúc hướng dẫn này, bạn sẽ tạo và chạy Đường ống ML, được lưu trữ trên Google Cloud. Bạn sẽ có thể hình dung kết quả của mỗi lần chạy và xem dòng dõi của các tạo phẩm đã tạo.
Bạn sẽ tuân theo quy trình phát triển ML điển hình, bắt đầu bằng việc kiểm tra tập dữ liệu và kết thúc bằng một quy trình hoạt động hoàn chỉnh. Trong quá trình này, bạn sẽ khám phá các cách gỡ lỗi và cập nhật quy trình của mình cũng như đo lường hiệu suất.
Bộ dữ liệu taxi Chicago


Bạn đang sử dụng tập dữ liệu Taxi Trips do Thành phố Chicago phát hành.
Bạn có thể đọc thêm về tập dữ liệu trong Google BigQuery . Khám phá tập dữ liệu đầy đủ trong giao diện người dùng BigQuery .
Mục tiêu mẫu - Phân loại nhị phân
Khách hàng sẽ tip nhiều hay ít hơn 20%?
1. Thiết lập dự án Google Cloud
1.a Thiết lập môi trường của bạn trên Google Cloud
Để bắt đầu, bạn cần có Tài khoản Google Cloud. Nếu bạn đã có rồi, hãy chuyển sang phần Tạo dự án mới .
Đi tới Bảng điều khiển đám mây của Google .
Đồng ý với các điều khoản và điều kiện của Google Cloud
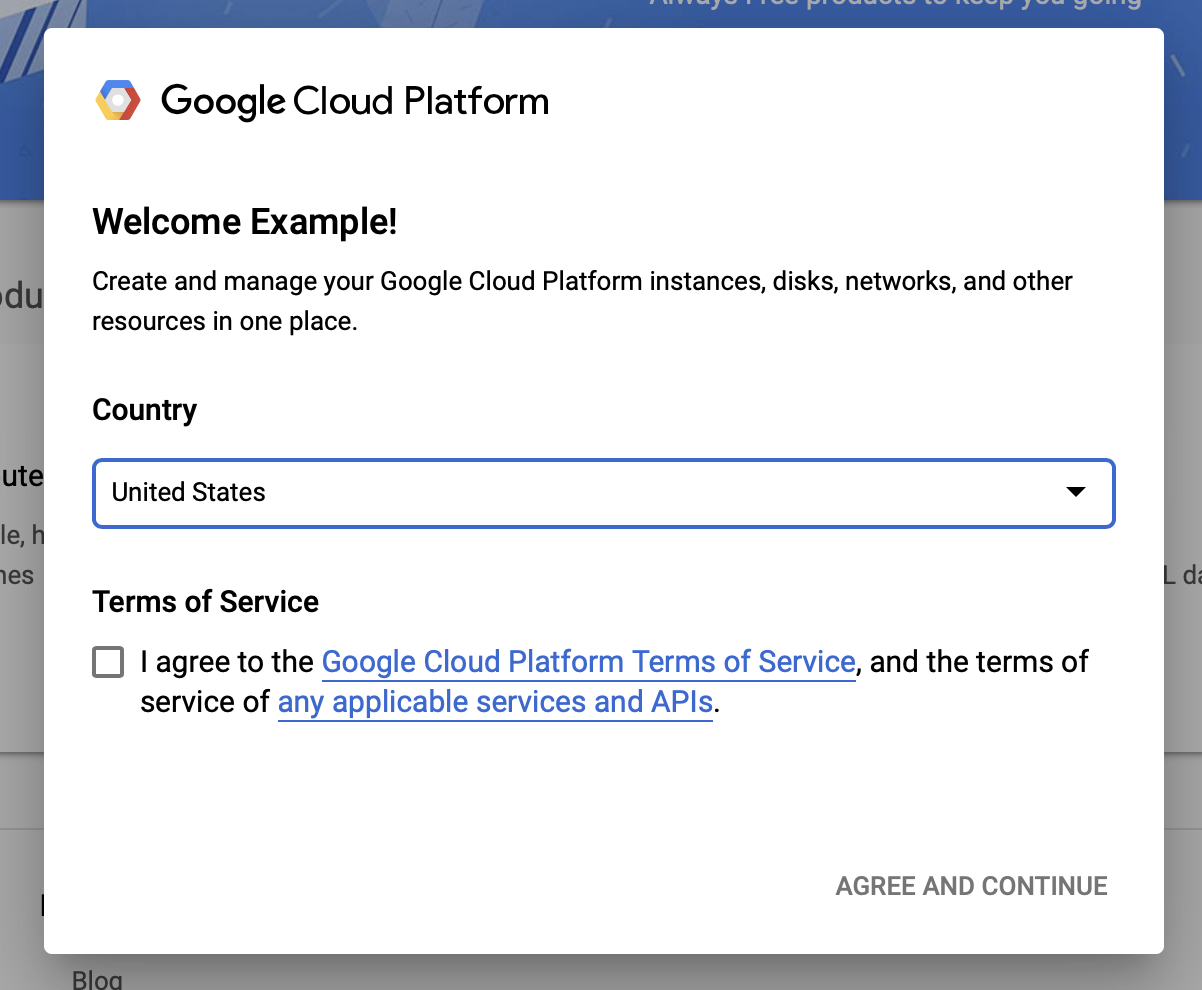
Nếu bạn muốn bắt đầu với tài khoản dùng thử miễn phí, hãy nhấp vào Dùng thử miễn phí (hoặc Bắt đầu miễn phí ).
Chọn đất nước của bạn.
Đồng ý với điều khoản dịch vụ.
Nhập chi tiết thanh toán.
Bạn sẽ không bị tính phí vào thời điểm này. Nếu không có dự án Google Cloud nào khác, bạn có thể hoàn thành hướng dẫn này mà không vượt quá giới hạn Bậc miễn phí của Google Cloud , bao gồm tối đa 8 lõi chạy cùng lúc.
1.b Tạo một dự án mới.
- Từ trang tổng quan chính của Google Cloud , hãy nhấp vào menu thả xuống dự án bên cạnh tiêu đề Google Cloud Platform và chọn Dự án mới .
- Đặt tên cho dự án của bạn và nhập các chi tiết dự án khác
- Khi bạn đã tạo một dự án, hãy đảm bảo chọn dự án đó từ trình đơn thả xuống của dự án.
2. Thiết lập và triển khai Đường dẫn nền tảng AI trên cụm Kubernetes mới
Chuyển đến trang Cụm quy trình nền tảng AI .
Trong Menu Điều hướng Chính: ≡ > Nền tảng AI > Đường ống
Nhấp vào + Phiên bản mới để tạo cụm mới.
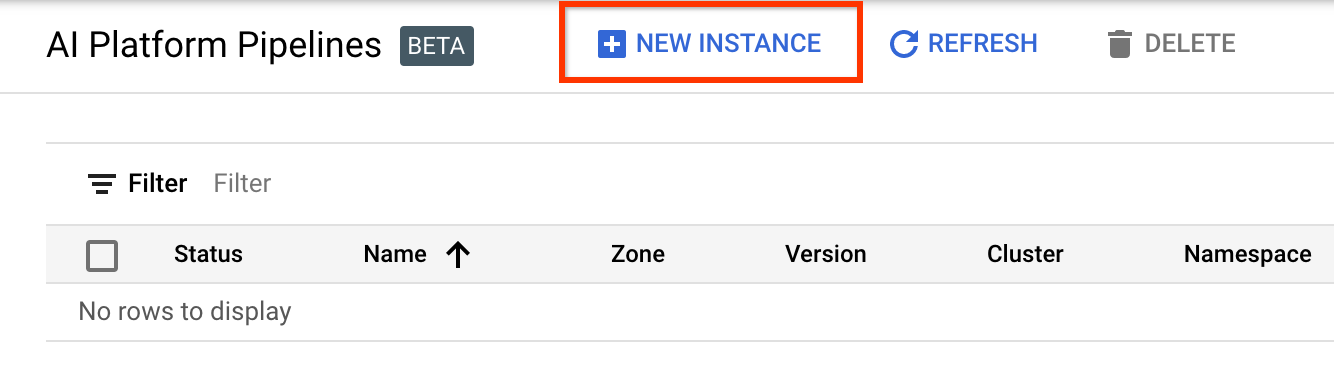
Trên trang tổng quan về Quy trình Kubeflow , nhấp vào Cấu hình .

Nhấp vào "Bật" để bật API Kubernetes Engine
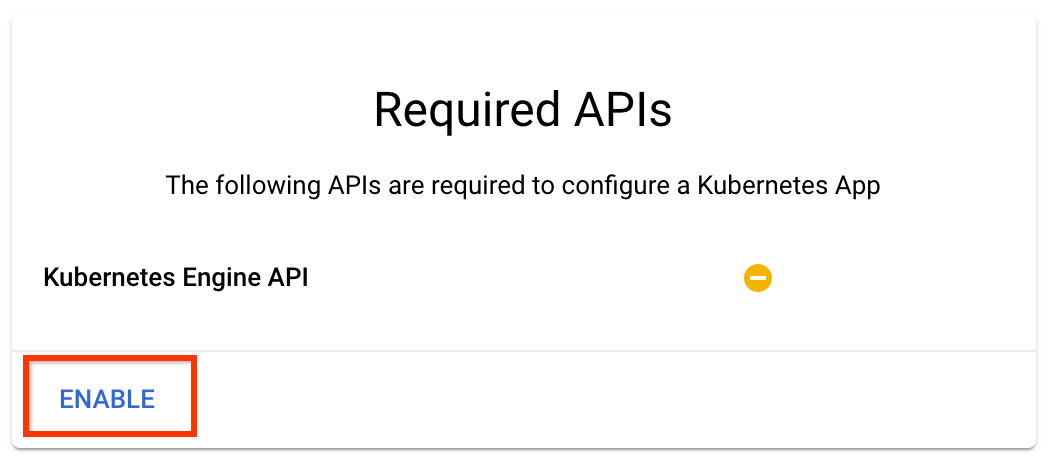
Trên trang Triển khai quy trình Kubeflow :
Chọn một vùng (hoặc "vùng") cho cụm của bạn. Mạng và mạng con có thể được thiết lập, nhưng vì mục đích của hướng dẫn này, chúng tôi sẽ để chúng làm mặc định.
QUAN TRỌNG Chọn hộp có nhãn Cho phép truy cập vào các API đám mây sau . (Điều này là bắt buộc để cụm này truy cập vào các phần khác trong dự án của bạn. Nếu bạn bỏ lỡ bước này, việc sửa nó sau này sẽ hơi phức tạp một chút.)
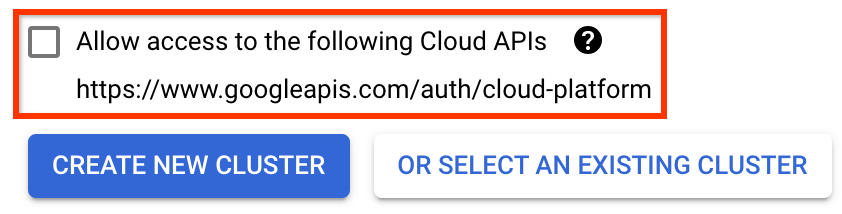
Nhấp vào Tạo cụm mới và đợi vài phút cho đến khi cụm được tạo. Điều này sẽ mất một vài phút. Khi nó hoàn thành, bạn sẽ thấy một thông báo như:
Cụm "cluster-1" được tạo thành công trong vùng "us-central1-a".
Chọn một vùng tên và tên phiên bản (sử dụng giá trị mặc định là được). Vì mục đích của hướng dẫn này, không kiểm tra executor.emissary hoặc Managedstorage.enabled .
Nhấp vào Triển khai và đợi một lát cho đến khi quy trình được triển khai. Bằng cách triển khai Kubeflow Pipelines, bạn chấp nhận Điều khoản dịch vụ.
3. Thiết lập phiên bản Cloud AI Platform Notebook.
Chuyển đến trang Bàn làm việc AI của Vertex . Lần đầu tiên chạy Workbench, bạn sẽ cần bật API Notebooks.
Trong Menu Điều hướng Chính: ≡ -> Vertex AI -> Bàn làm việc
Nếu được nhắc, hãy bật API Công cụ Điện toán.
Tạo một Notebook mới đã cài đặt TensorFlow Enterprise 2.7 (hoặc cao hơn).
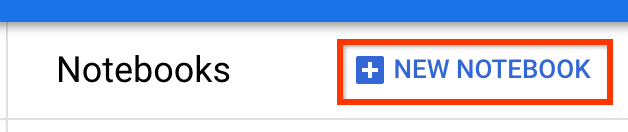
Máy tính xách tay mới -> TensorFlow Enterprise 2.7 -> Không có GPU
Chọn một vùng và vùng rồi đặt tên cho phiên bản sổ ghi chép.
Để duy trì giới hạn Bậc miễn phí, bạn có thể cần thay đổi cài đặt mặc định tại đây để giảm số lượng vCPU có sẵn cho phiên bản này từ 4 xuống 2:
- Chọn Tùy chọn nâng cao ở cuối biểu mẫu Sổ ghi chép mới .
Trong Cấu hình máy, bạn có thể muốn chọn cấu hình có 1 hoặc 2 vCPU nếu bạn cần duy trì cấp miễn phí.
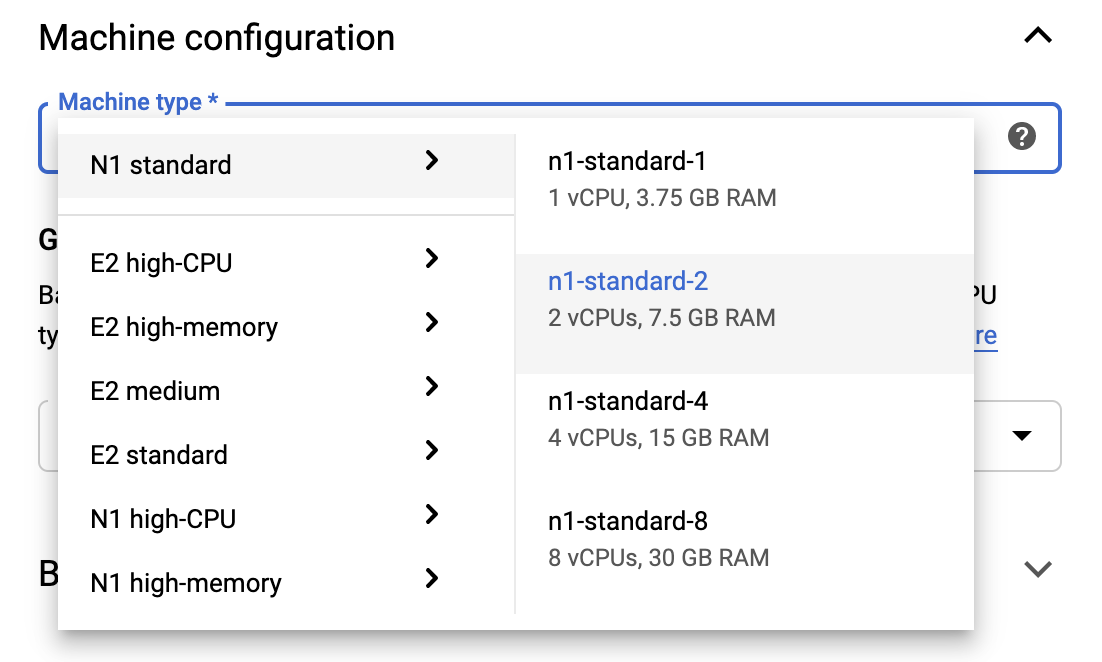
Đợi sổ ghi chép mới được tạo rồi bấm vào Bật API sổ ghi chép
4. Khởi chạy Notebook Bắt đầu
Chuyển đến trang Cụm quy trình nền tảng AI .
Trong Menu Điều hướng Chính: ≡ -> Nền tảng AI -> Đường ống
Trên dòng dành cho cụm bạn đang sử dụng trong hướng dẫn này, hãy nhấp vào Mở bảng thông tin quy trình .

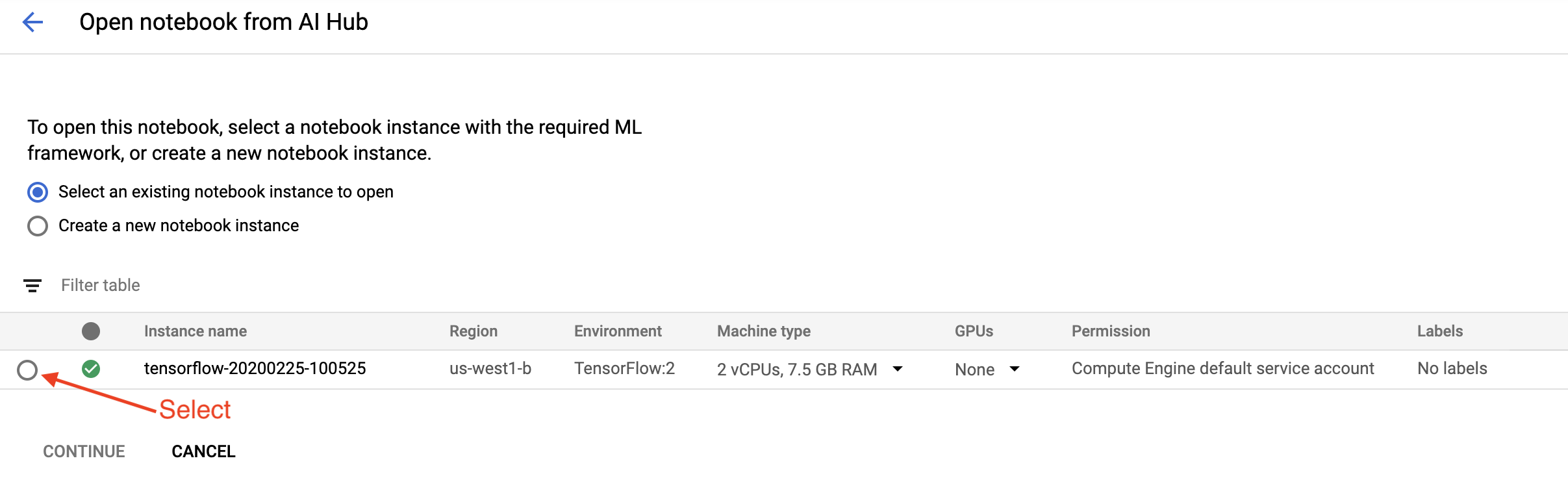
Trên trang Bắt đầu , nhấp vào Mở sổ ghi chép nền tảng đám mây AI trên Google Cloud .

Chọn phiên bản Notebook bạn đang sử dụng cho hướng dẫn này và Tiếp tục , sau đó Xác nhận .
5. Tiếp tục làm việc trong Notebook
Cài đặt
Sổ tay bắt đầu bắt đầu bằng cách cài đặt TFX và Kubeflow Pipelines (KFP) vào VM mà Jupyter Lab đang chạy trong đó.
Sau đó, nó sẽ kiểm tra phiên bản TFX nào đã được cài đặt, thực hiện nhập, đặt và in ID dự án:

Kết nối với các dịch vụ Google Cloud của bạn
Cấu hình quy trình cần ID dự án của bạn mà bạn có thể lấy thông qua sổ ghi chép và đặt làm biến môi trường.
# Read GCP project id from env.
shell_output=!gcloud config list --format 'value(core.project)' 2>/dev/null
GCP_PROJECT_ID=shell_output[0]
print("GCP project ID:" + GCP_PROJECT_ID)
Bây giờ hãy đặt điểm cuối cụm KFP của bạn.
Điều này có thể được tìm thấy từ URL của bảng điều khiển Pipelines. Đi tới bảng điều khiển Kubeflow Pipeline và xem URL. Điểm cuối là mọi thứ trong URL bắt đầu bằng https:// , cho đến và bao gồm cả googleusercontent.com .
ENDPOINT='' # Enter YOUR ENDPOINT here.
Sau đó, sổ ghi chép sẽ đặt một tên duy nhất cho hình ảnh Docker tùy chỉnh:
# Docker image name for the pipeline image
CUSTOM_TFX_IMAGE='gcr.io/' + GCP_PROJECT_ID + '/tfx-pipeline'
6. Sao chép mẫu vào thư mục dự án của bạn
Chỉnh sửa ô sổ ghi chép tiếp theo để đặt tên cho quy trình của bạn. Trong hướng dẫn này, chúng tôi sẽ sử dụng my_pipeline .
PIPELINE_NAME="my_pipeline"
PROJECT_DIR=os.path.join(os.path.expanduser("~"),"imported",PIPELINE_NAME)
Sau đó, sổ ghi chép sử dụng tfx CLI để sao chép mẫu đường dẫn. Hướng dẫn này sử dụng tập dữ liệu Chicago Taxi để thực hiện phân loại nhị phân, do đó, mẫu sẽ đặt mô hình thành taxi :
!tfx template copy \
--pipeline-name={PIPELINE_NAME} \
--destination-path={PROJECT_DIR} \
--model=taxi
Sau đó, sổ ghi chép sẽ thay đổi bối cảnh CWD của nó thành thư mục dự án:
%cd {PROJECT_DIR}
Duyệt các tập tin đường ống
Ở phía bên trái của Cloud AI Platform Notebook, bạn sẽ thấy một trình duyệt tệp. Cần có một thư mục có tên đường dẫn của bạn ( my_pipeline ). Mở nó và xem các tập tin. (Bạn cũng có thể mở chúng và chỉnh sửa từ môi trường sổ ghi chép.)
# You can also list the files from the shellls
Lệnh sao tfx template copy ở trên đã tạo một tập hợp các tệp cơ bản để xây dựng một đường dẫn. Chúng bao gồm mã nguồn Python, dữ liệu mẫu và sổ ghi chép Jupyter. Đây là những ý nghĩa cho ví dụ cụ thể này. Đối với các đường dẫn của riêng bạn, đây sẽ là các tệp hỗ trợ mà đường dẫn của bạn yêu cầu.
Dưới đây là mô tả ngắn gọn về các tệp Python.
-
pipeline- Thư mục này chứa định nghĩa của đường ống-
configs.py- xác định các hằng số chung cho người chạy đường ống -
pipeline.py- xác định các thành phần TFX và đường dẫn
-
-
models- Thư mục này chứa các định nghĩa mô hình ML.-
features.py- xác địnhfeatures_test.pytính năng cho mô hình -
preprocessing.py/preprocessing_test.py— xác định các công việc tiền xử lý bằng cách sử dụngtf::Transform -
estimator- Thư mục này chứa mô hình dựa trên Công cụ ước tính.-
constants.py- xác định các hằng số của mô hình -
model.py/model_test.py- xác định mô hình DNN bằng công cụ ước tính TF
-
-
keras- Thư mục này chứa mô hình dựa trên Keras.-
constants.py- xác định các hằng số của mô hình -
model.py/model_test.py- xác định mô hình DNN bằng Keras
-
-
-
beam_runner.py/kubeflow_runner.py- xác định người chạy cho từng công cụ điều phối
7. Chạy quy trình TFX đầu tiên của bạn trên Kubeflow
Sổ ghi chép sẽ chạy quy trình bằng lệnh tfx run CLI.
Kết nối với bộ lưu trữ
Các quy trình đang chạy tạo ra các thành phần lạ phải được lưu trữ trong Siêu dữ liệu ML . Hiện vật đề cập đến tải trọng, là các tệp phải được lưu trữ trong hệ thống tệp hoặc lưu trữ khối. Đối với hướng dẫn này, chúng tôi sẽ sử dụng GCS để lưu trữ tải trọng siêu dữ liệu của mình bằng cách sử dụng nhóm được tạo tự động trong quá trình thiết lập. Tên của nó sẽ là <your-project-id>-kubeflowpipelines-default .
Tạo đường ống
Sổ ghi chép sẽ tải dữ liệu mẫu của chúng tôi lên nhóm GCS để chúng tôi có thể sử dụng dữ liệu đó trong quy trình của mình sau này.
gsutil cp data/data.csv gs://{GOOGLE_CLOUD_PROJECT}-kubeflowpipelines-default/tfx-template/data/taxi/data.csv
Sau đó, sổ ghi chép sẽ sử dụng lệnh tfx pipeline create để tạo đường dẫn.
!tfx pipeline create \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT} \
--build-image
Trong khi tạo một đường dẫn, Dockerfile sẽ được tạo để xây dựng hình ảnh Docker. Đừng quên thêm các tệp này vào hệ thống kiểm soát nguồn của bạn (ví dụ: git) cùng với các tệp nguồn khác.
Chạy đường ống
Sau đó, sổ ghi chép sẽ sử dụng lệnh tfx run create để bắt đầu chạy quy trình của bạn. Bạn cũng sẽ thấy lần chạy này được liệt kê trong Thử nghiệm trên Bảng thông tin quy trình Kubeflow.
tfx run create --pipeline-name={PIPELINE_NAME} --endpoint={ENDPOINT}
Bạn có thể xem quy trình của mình từ Bảng thông tin quy trình Kubeflow.
8. Xác thực dữ liệu của bạn
Nhiệm vụ đầu tiên trong bất kỳ dự án khoa học dữ liệu hoặc ML nào là hiểu và làm sạch dữ liệu.
- Hiểu các kiểu dữ liệu cho từng tính năng
- Tìm kiếm sự bất thường và giá trị bị thiếu
- Hiểu cách phân phối cho từng tính năng
Các thành phần


- Ví dụGen nhập và phân chia tập dữ liệu đầu vào.
- StatsGen tính toán số liệu thống kê cho tập dữ liệu.
- SchemaGen SchemaGen kiểm tra số liệu thống kê và tạo lược đồ dữ liệu.
- Ví dụValidator tìm kiếm các điểm bất thường và giá trị bị thiếu trong tập dữ liệu.
Trong trình chỉnh sửa tệp phòng thí nghiệm Jupyter:
Trong pipeline / pipeline.py , bỏ ghi chú các dòng nối các thành phần này vào đường dẫn của bạn:
# components.append(statistics_gen)
# components.append(schema_gen)
# components.append(example_validator)
( ExampleGen đã được bật khi sao chép tệp mẫu.)
Cập nhật đường dẫn và chạy lại nó
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
Kiểm tra đường ống
Đối với Kubeflow Orchestrator, hãy truy cập bảng thông tin KFP và tìm đầu ra quy trình trong trang để chạy quy trình của bạn. Nhấp vào tab "Thử nghiệm" ở bên trái và "Tất cả các lần chạy" trong trang Thử nghiệm. Bạn sẽ có thể tìm thấy hoạt động có tên đường dẫn của bạn.
Ví dụ nâng cao hơn
Ví dụ được trình bày ở đây thực sự chỉ nhằm mục đích giúp bạn bắt đầu. Để biết ví dụ nâng cao hơn, hãy xem Colab xác thực dữ liệu TensorFlow .
Để biết thêm thông tin về cách sử dụng TFDV để khám phá và xác thực tập dữ liệu, hãy xem các ví dụ trên tensorflow.org .
9. Kỹ thuật tính năng
Bạn có thể tăng chất lượng dự đoán của dữ liệu và/hoặc giảm tính chiều bằng kỹ thuật tính năng.
- Tính năng chéo
- Từ Vựng
- Nhúng
- PCA
- Mã hóa phân loại
Một trong những lợi ích của việc sử dụng TFX là bạn sẽ viết mã chuyển đổi của mình một lần và các chuyển đổi kết quả sẽ nhất quán giữa đào tạo và phục vụ.
Các thành phần

- Transform thực hiện kỹ thuật tính năng trên tập dữ liệu.
Trong trình chỉnh sửa tệp phòng thí nghiệm Jupyter:
Trong pipeline / pipeline.py , tìm và bỏ ghi chú dòng nối thêm Transform vào đường ống.
# components.append(transform)
Cập nhật đường dẫn và chạy lại nó
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
Kiểm tra đầu ra đường ống
Đối với Kubeflow Orchestrator, hãy truy cập bảng thông tin KFP và tìm đầu ra quy trình trong trang để chạy quy trình của bạn. Nhấp vào tab "Thử nghiệm" ở bên trái và "Tất cả các lần chạy" trong trang Thử nghiệm. Bạn sẽ có thể tìm thấy hoạt động có tên đường dẫn của bạn.
Ví dụ nâng cao hơn
Ví dụ được trình bày ở đây thực sự chỉ nhằm mục đích giúp bạn bắt đầu. Để biết ví dụ nâng cao hơn, hãy xem TensorFlow Transform Colab .
10. Đào tạo
Huấn luyện mô hình TensorFlow với dữ liệu được chuyển đổi rõ ràng, đẹp đẽ của bạn.
- Bao gồm các phép biến đổi từ bước trước để chúng được áp dụng một cách nhất quán
- Lưu kết quả dưới dạng SavingModel để sản xuất
- Trực quan hóa và khám phá quá trình đào tạo bằng TensorBoard
- Đồng thời lưu EvalSavedModel để phân tích hiệu suất mô hình
Các thành phần
- Trainer đào tạo mô hình TensorFlow.
Trong trình chỉnh sửa tệp phòng thí nghiệm Jupyter:
Trong pipeline / pipeline.py , tìm và bỏ ghi chú phần bổ sung Trainer vào đường dẫn:
# components.append(trainer)
Cập nhật đường dẫn và chạy lại nó
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
Kiểm tra đầu ra đường ống
Đối với Kubeflow Orchestrator, hãy truy cập bảng thông tin KFP và tìm đầu ra quy trình trong trang để chạy quy trình của bạn. Nhấp vào tab "Thử nghiệm" ở bên trái và "Tất cả các lần chạy" trong trang Thử nghiệm. Bạn sẽ có thể tìm thấy hoạt động có tên đường dẫn của bạn.
Ví dụ nâng cao hơn
Ví dụ được trình bày ở đây thực sự chỉ nhằm mục đích giúp bạn bắt đầu. Để có ví dụ nâng cao hơn, hãy xem Hướng dẫn về TensorBoard .
11. Phân tích hiệu suất mô hình
Hiểu nhiều hơn chỉ là các số liệu cấp cao nhất.
- Người dùng chỉ trải nghiệm hiệu suất mô hình cho các truy vấn của họ
- Hiệu suất kém trên các phần dữ liệu có thể bị ẩn bởi các chỉ số cấp cao nhất
- Sự công bằng của mô hình là quan trọng
- Thông thường, các tập hợp con chính của người dùng hoặc dữ liệu rất quan trọng và có thể nhỏ.
- Hiệu suất trong điều kiện quan trọng nhưng bất thường
- Hiệu suất cho các đối tượng chính như người có ảnh hưởng
- Nếu bạn định thay thế một mẫu hiện đang được sản xuất, trước tiên hãy đảm bảo rằng mẫu mới tốt hơn
Các thành phần
- Người đánh giá thực hiện phân tích sâu về kết quả đào tạo.
Trong trình chỉnh sửa tệp phòng thí nghiệm Jupyter:
Trong pipeline / pipeline.py , tìm và bỏ ghi chú dòng nối thêm Trình đánh giá vào đường dẫn:
components.append(evaluator)
Cập nhật đường dẫn và chạy lại nó
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
Kiểm tra đầu ra đường ống
Đối với Kubeflow Orchestrator, hãy truy cập bảng thông tin KFP và tìm đầu ra quy trình trong trang để chạy quy trình của bạn. Nhấp vào tab "Thử nghiệm" ở bên trái và "Tất cả các lần chạy" trong trang Thử nghiệm. Bạn sẽ có thể tìm thấy hoạt động có tên đường dẫn của bạn.
12. Phục vụ người mẫu
Nếu mô hình mới đã sẵn sàng, hãy làm như vậy.
- Pusher triển khai SavingModels đến các vị trí nổi tiếng
Các mục tiêu triển khai nhận được mô hình mới từ các địa điểm nổi tiếng
- Phục vụ TensorFlow
- TensorFlow Lite
- TensorFlow JS
- Trung tâm TensorFlow
Các thành phần
- Pusher triển khai mô hình tới cơ sở hạ tầng phục vụ.
Trong trình chỉnh sửa tệp phòng thí nghiệm Jupyter:
Trong pipeline / pipeline.py , tìm và bỏ ghi chú dòng nối thêm Pusher vào đường ống:
# components.append(pusher)
Kiểm tra đầu ra đường ống
Đối với Kubeflow Orchestrator, hãy truy cập bảng thông tin KFP và tìm đầu ra quy trình trong trang để chạy quy trình của bạn. Nhấp vào tab "Thử nghiệm" ở bên trái và "Tất cả các lần chạy" trong trang Thử nghiệm. Bạn sẽ có thể tìm thấy hoạt động có tên đường dẫn của bạn.
Mục tiêu triển khai có sẵn
Bây giờ bạn đã đào tạo và xác thực mô hình của mình và mô hình của bạn hiện đã sẵn sàng để sản xuất. Bây giờ bạn có thể triển khai mô hình của mình tới bất kỳ mục tiêu triển khai TensorFlow nào, bao gồm:
- Phục vụ TensorFlow , để phục vụ mô hình của bạn trên máy chủ hoặc cụm máy chủ và xử lý các yêu cầu suy luận REST và/hoặc gRPC.
- TensorFlow Lite , để đưa mô hình của bạn vào ứng dụng di động gốc Android hoặc iOS hoặc trong ứng dụng Raspberry Pi, IoT hoặc vi điều khiển.
- TensorFlow.js , để chạy mô hình của bạn trong trình duyệt web hoặc ứng dụng Node.JS.
Ví dụ nâng cao hơn
Ví dụ được trình bày ở trên thực sự chỉ nhằm mục đích giúp bạn bắt đầu. Dưới đây là một số ví dụ về tích hợp với các dịch vụ Đám mây khác.
Các cân nhắc về tài nguyên của Kubeflow Pipelines
Tùy thuộc vào yêu cầu của khối lượng công việc, cấu hình mặc định để triển khai Đường ống Kubeflow có thể đáp ứng hoặc không đáp ứng được nhu cầu của bạn. Bạn có thể tùy chỉnh cấu hình tài nguyên của mình bằng cách sử dụng pipeline_operator_funcs trong lệnh gọi tới KubeflowDagRunnerConfig .
pipeline_operator_funcs là danh sách các mục OpFunc , giúp chuyển đổi tất cả các phiên bản ContainerOp được tạo trong thông số đường ống KFP được biên dịch từ KubeflowDagRunner .
Ví dụ: để định cấu hình bộ nhớ, chúng ta có thể sử dụng set_memory_request để khai báo dung lượng bộ nhớ cần thiết. Một cách điển hình để làm điều đó là tạo một trình bao bọc cho set_memory_request và sử dụng nó để thêm vào danh sách quy trình OpFunc s:
def request_more_memory():
def _set_memory_spec(container_op):
container_op.set_memory_request('32G')
return _set_memory_spec
# Then use this opfunc in KubeflowDagRunner
pipeline_op_funcs = kubeflow_dag_runner.get_default_pipeline_operator_funcs()
pipeline_op_funcs.append(request_more_memory())
config = KubeflowDagRunnerConfig(
pipeline_operator_funcs=pipeline_op_funcs,
...
)
kubeflow_dag_runner.KubeflowDagRunner(config=config).run(pipeline)
Các chức năng cấu hình tài nguyên tương tự bao gồm:
-
set_memory_limit -
set_cpu_request -
set_cpu_limit -
set_gpu_limit
Hãy dùng thử BigQueryExampleGen
BigQuery là kho dữ liệu đám mây không có máy chủ, có khả năng mở rộng cao và tiết kiệm chi phí. BigQuery có thể được sử dụng làm nguồn đào tạo các ví dụ về TFX. Trong bước này, chúng tôi sẽ thêm BigQueryExampleGen vào quy trình.
Trong trình chỉnh sửa tệp phòng thí nghiệm Jupyter:
Nhấp đúp để mở pipeline.py . Nhận xét CsvExampleGen và bỏ ghi chú dòng tạo phiên bản của BigQueryExampleGen . Bạn cũng cần bỏ ghi chú đối số query của hàm create_pipeline .
Chúng ta cần chỉ định dự án GCP nào sẽ sử dụng cho BigQuery và việc này được thực hiện bằng cách đặt --project trong beam_pipeline_args khi tạo quy trình.
Bấm đúp để mở configs.py . Bỏ ghi chú định nghĩa của BIG_QUERY_WITH_DIRECT_RUNNER_BEAM_PIPELINE_ARGS và BIG_QUERY_QUERY . Bạn nên thay thế id dự án và giá trị vùng trong tệp này bằng các giá trị chính xác cho dự án GCP của bạn.
Thay đổi thư mục lên một cấp. Bấm vào tên của thư mục phía trên danh sách tập tin. Tên của thư mục là tên của đường dẫn là my_pipeline nếu bạn không thay đổi tên đường dẫn.
Nhấp đúp để mở kubeflow_runner.py . Bỏ ghi chú hai đối số, query và beam_pipeline_args , cho hàm create_pipeline .
Bây giờ quy trình đã sẵn sàng để sử dụng BigQuery làm nguồn mẫu. Cập nhật quy trình như trước và tạo một lần chạy thực thi mới như chúng tôi đã làm ở bước 5 và 6.
Cập nhật đường dẫn và chạy lại nó
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
Hãy thử luồng dữ liệu
Một số Thành phần TFX sử dụng Apache Beam để triển khai các đường dẫn song song dữ liệu và điều đó có nghĩa là bạn có thể phân phối khối lượng công việc xử lý dữ liệu bằng cách sử dụng Google Cloud Dataflow . Trong bước này, chúng ta sẽ thiết lập bộ điều phối Kubeflow để sử dụng Dataflow làm back-end xử lý dữ liệu cho Apache Beam.
# Select your project:
gcloud config set project YOUR_PROJECT_ID
# Get a list of services that you can enable in your project:
gcloud services list --available | grep Dataflow
# If you don't see dataflow.googleapis.com listed, that means you haven't been
# granted access to enable the Dataflow API. See your account adminstrator.
# Enable the Dataflow service:
gcloud services enable dataflow.googleapis.com
Bấm đúp vào pipeline để thay đổi thư mục và bấm đúp để mở configs.py . Bỏ ghi chú định nghĩa của GOOGLE_CLOUD_REGION và DATAFLOW_BEAM_PIPELINE_ARGS .
Thay đổi thư mục lên một cấp. Bấm vào tên của thư mục phía trên danh sách tập tin. Tên của thư mục là tên của đường ống là my_pipeline nếu bạn không thay đổi.
Nhấp đúp để mở kubeflow_runner.py . Bỏ ghi chú beam_pipeline_args . (Ngoài ra, hãy đảm bảo nhận xét beam_pipeline_args hiện tại mà bạn đã thêm ở Bước 7.)
Cập nhật đường dẫn và chạy lại nó
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
Bạn có thể tìm thấy các công việc Dataflow của mình trong Dataflow trên Cloud Console .
Hãy thử đào tạo và dự đoán nền tảng AI trên nền tảng đám mây với KFP
TFX tương tác với một số dịch vụ GCP được quản lý, chẳng hạn như Nền tảng đám mây AI để đào tạo và dự đoán . Bạn có thể đặt thành phần Trainer của mình để sử dụng Đào tạo nền tảng AI trên nền tảng đám mây, một dịch vụ được quản lý để đào tạo các mô hình ML. Hơn nữa, khi mô hình của bạn được xây dựng và sẵn sàng phục vụ, bạn có thể đẩy mô hình của mình lên Dự đoán nền tảng AI trên nền tảng đám mây để phân phối. Trong bước này, chúng tôi sẽ thiết lập thành phần Trainer và Pusher để sử dụng các dịch vụ Nền tảng Cloud AI.
Trước khi chỉnh sửa tệp, trước tiên bạn có thể phải bật API dự đoán và đào tạo nền tảng AI .
Bấm đúp vào pipeline để thay đổi thư mục và bấm đúp để mở configs.py . Bỏ ghi chú định nghĩa của GOOGLE_CLOUD_REGION , GCP_AI_PLATFORM_TRAINING_ARGS và GCP_AI_PLATFORM_SERVING_ARGS . Chúng tôi sẽ sử dụng hình ảnh vùng chứa được xây dựng tùy chỉnh để đào tạo mô hình trong Đào tạo nền tảng AI trên nền tảng đám mây, vì vậy, chúng tôi nên đặt masterConfig.imageUri trong GCP_AI_PLATFORM_TRAINING_ARGS thành cùng giá trị như CUSTOM_TFX_IMAGE ở trên.
Thay đổi thư mục lên một cấp và nhấp đúp để mở kubeflow_runner.py . Bỏ ghi chú ai_platform_training_args và ai_platform_serving_args .
Cập nhật đường dẫn và chạy lại nó
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
Bạn có thể tìm thấy công việc đào tạo của mình trong Công việc nền tảng đám mây AI . Nếu quy trình của bạn hoàn tất thành công, bạn có thể tìm thấy mô hình của mình trong Mô hình nền tảng AI trên đám mây .
14. Sử dụng dữ liệu của riêng bạn
Trong hướng dẫn này, bạn đã tạo quy trình cho một mô hình bằng cách sử dụng bộ dữ liệu Chicago Taxi. Bây giờ hãy thử đưa dữ liệu của riêng bạn vào quy trình. Dữ liệu của bạn có thể được lưu trữ ở bất kỳ nơi nào mà quy trình có thể truy cập, bao gồm các tệp Google Cloud Storage, BigQuery hoặc CSV.
Bạn cần sửa đổi định nghĩa quy trình để phù hợp với dữ liệu của mình.
Nếu dữ liệu của bạn được lưu trữ trong các tập tin
- Sửa đổi
DATA_PATHtrongkubeflow_runner.py, cho biết vị trí.
Nếu dữ liệu của bạn được lưu trữ trong BigQuery
- Sửa đổi
BIG_QUERY_QUERYtrong configs.py thành câu lệnh truy vấn của bạn. - Thêm tính năng trong
models/features.py. - Sửa đổi
models/preprocessing.pyđể chuyển đổi dữ liệu đầu vào cho việc huấn luyện . - Sửa đổi
models/keras/model.pyvàmodels/keras/constants.pyđể mô tả mô hình ML của bạn .
Tìm hiểu thêm về Huấn luyện viên
Xem hướng dẫn về thành phần dành cho huấn luyện viên để biết thêm chi tiết về quy trình đào tạo.
Dọn dẹp
Để dọn sạch tất cả tài nguyên Google Cloud được sử dụng trong dự án này, bạn có thể xóa dự án Google Cloud mà bạn đã sử dụng cho hướng dẫn.
Ngoài ra, bạn có thể dọn sạch các tài nguyên riêng lẻ bằng cách truy cập từng bảng điều khiển: - Google Cloud Storage - Google Container Register - Google Kubernetes Engine