
معرفی
این آموزش برای معرفی TensorFlow Extended (TFX) و AIPlatform Pipelines طراحی شده است و به شما کمک می کند تا یاد بگیرید خطوط لوله یادگیری ماشین خود را در Google Cloud ایجاد کنید. این یکپارچگی با TFX، AI Platform Pipelines و Kubeflow و همچنین تعامل با TFX در نوت بوک های Jupyter را نشان می دهد.
در پایان این آموزش، شما یک خط لوله ML را ایجاد و اجرا خواهید کرد که در Google Cloud میزبانی شده است. شما میتوانید نتایج هر اجرا را تجسم کنید و دودمان مصنوعات ایجاد شده را مشاهده کنید.
شما یک فرآیند معمولی توسعه ML را دنبال خواهید کرد که با بررسی مجموعه داده شروع می شود و به یک خط لوله کاری کامل ختم می شود. در طول مسیر، راههایی برای اشکالزدایی و بهروزرسانی خط لوله خود و اندازهگیری عملکرد را بررسی خواهید کرد.
مجموعه داده تاکسی شیکاگو


شما از مجموعه داده سفرهای تاکسی منتشر شده توسط شهر شیکاگو استفاده می کنید.
میتوانید اطلاعات بیشتری درباره مجموعه داده در Google BigQuery بخوانید . مجموعه داده کامل را در رابط کاربری BigQuery کاوش کنید.
هدف مدل - طبقه بندی باینری
آیا مشتری بیشتر از 20 درصد انعام می دهد؟
1. یک پروژه Google Cloud راه اندازی کنید
1.a محیط خود را در Google Cloud تنظیم کنید
برای شروع، به یک حساب Google Cloud نیاز دارید. اگر قبلاً یکی دارید، به ایجاد پروژه جدید بروید.
به Google Cloud Console بروید.
با شرایط و ضوابط Google Cloud موافقت کنید
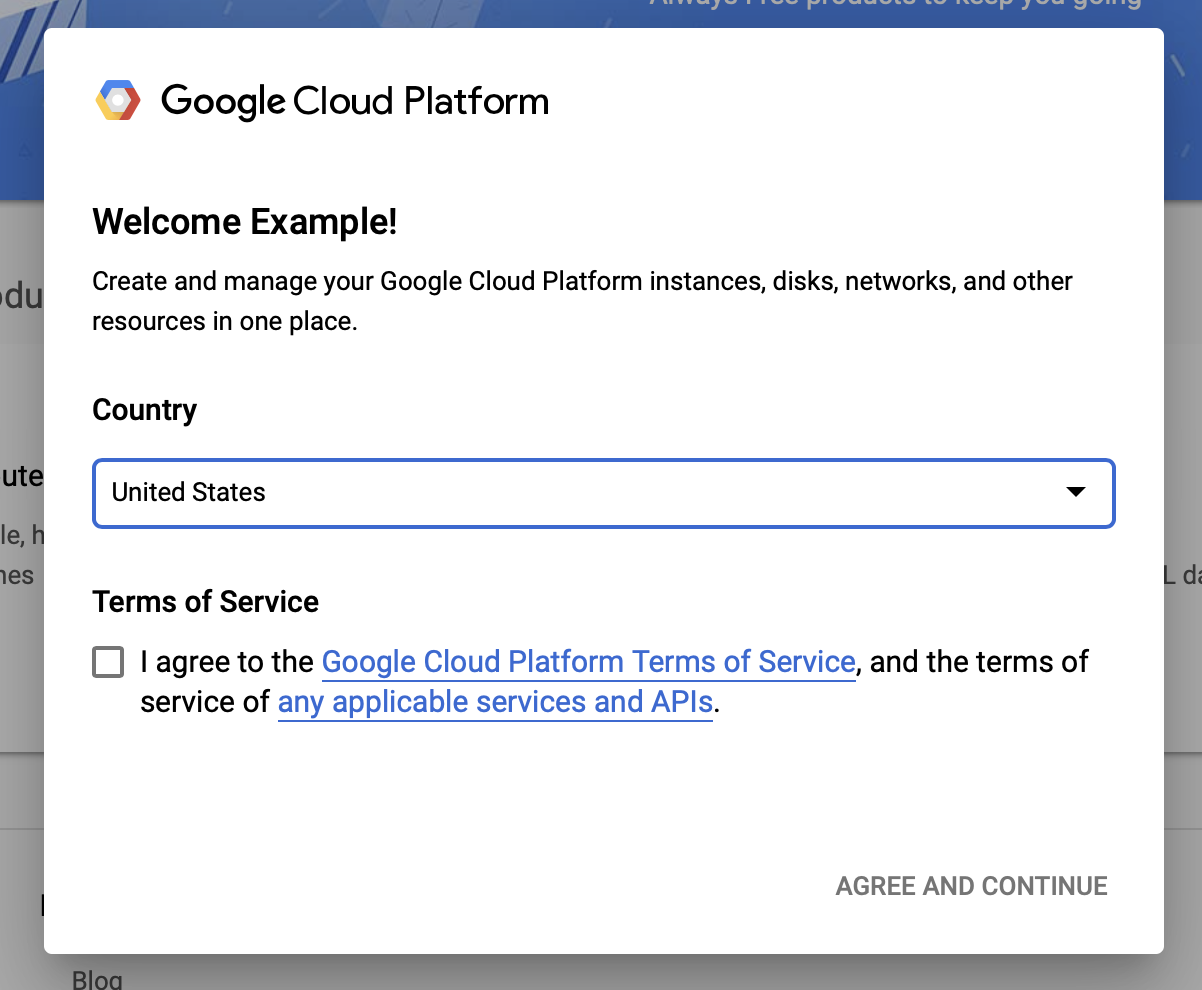
اگر میخواهید با یک حساب آزمایشی رایگان شروع کنید، روی Try For Free (یا شروع به کار رایگان ) کلیک کنید.
کشورت را انتخاب کن.
با شرایط خدمات موافقت کنید.
جزئیات صورتحساب را وارد کنید
در این مرحله از شما هزینه ای دریافت نمی شود. اگر هیچ پروژه Google Cloud دیگری ندارید، میتوانید این آموزش را بدون تجاوز از محدودیتهای Google Cloud Free Tier ، که شامل حداکثر 8 هسته در حال اجرا به طور همزمان است، تکمیل کنید.
1.b یک پروژه جدید ایجاد کنید.
- از داشبورد اصلی Google Cloud ، روی منوی کشویی پروژه در کنار سرصفحه Google Cloud Platform کلیک کنید و پروژه جدید را انتخاب کنید.
- به پروژه خود یک نام بدهید و سایر جزئیات پروژه را وارد کنید
- پس از ایجاد یک پروژه، مطمئن شوید که آن را از کشویی پروژه انتخاب کنید.
2. یک خط لوله پلتفرم هوش مصنوعی را در یک خوشه جدید Kubernetes راه اندازی و استقرار دهید
به صفحه AI Platform Pipelines Cluster بروید.
در منوی اصلی پیمایش: ≡ > AI Platform > Pipelines
برای ایجاد یک خوشه جدید، روی + New Instance کلیک کنید.
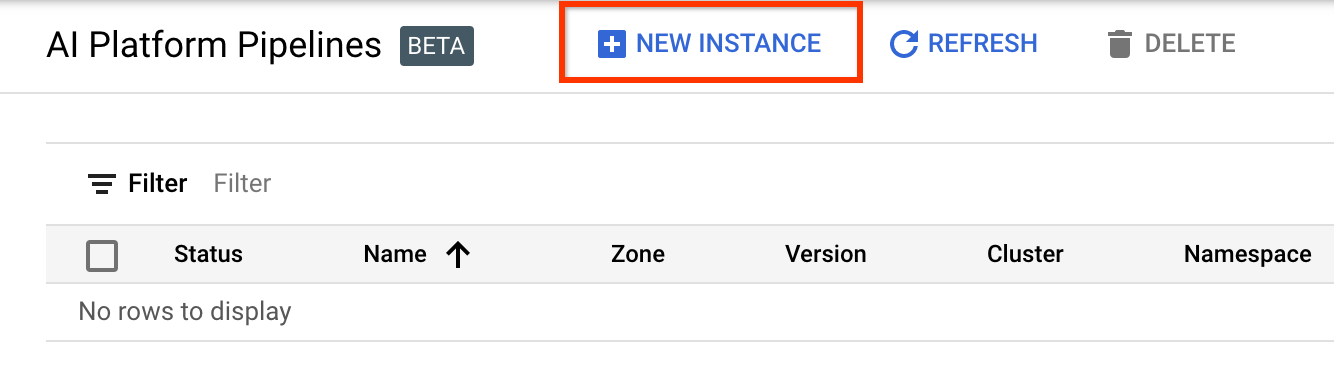
در صفحه نمای کلی خطوط لوله Kubeflow ، روی پیکربندی کلیک کنید.

برای فعال کردن Kubernetes Engine API روی "فعال کردن" کلیک کنید
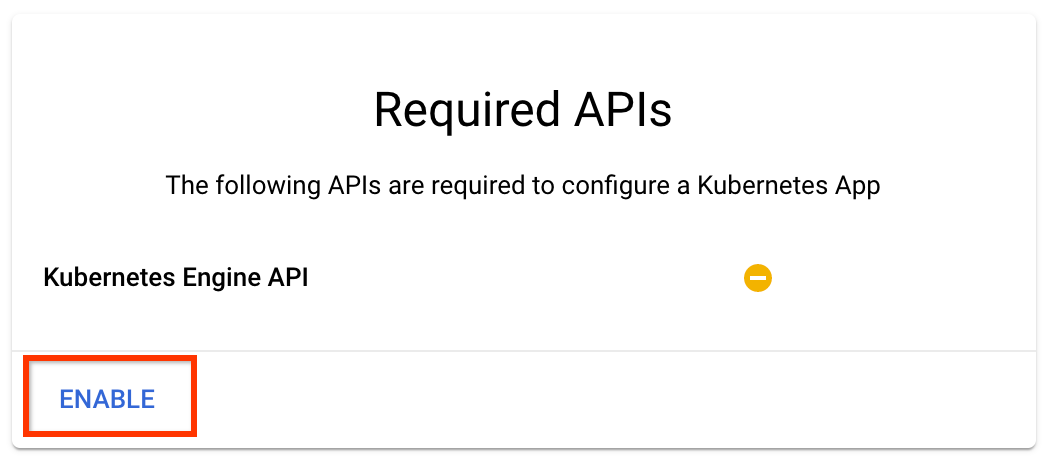
در صفحه Deploy Kubeflow Pipelines :
یک منطقه (یا "منطقه") برای خوشه خود انتخاب کنید. شبکه و زیرشبکه را می توان تنظیم کرد، اما برای اهداف این آموزش ما آنها را به عنوان پیش فرض می گذاریم.
مهم کادر با عنوان اجازه دسترسی به APIهای ابری زیر را علامت بزنید. (این برای این خوشه برای دسترسی به سایر قطعات پروژه شما لازم است. اگر این مرحله را از دست دادید، رفع آن بعداً کمی مشکل است.)
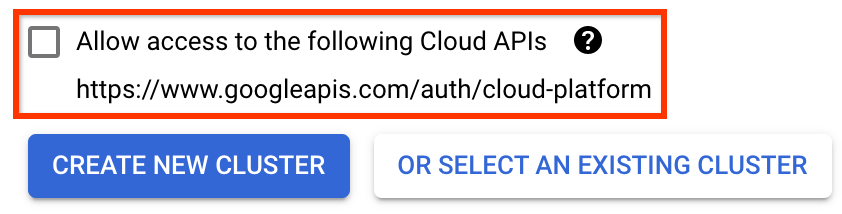
روی Create New Cluster کلیک کنید و چند دقیقه صبر کنید تا خوشه ایجاد شود. این چند دقیقه زمان خواهد برد. پس از تکمیل، پیامی مانند:
خوشه "cluster-1" با موفقیت در منطقه "us-central1-a" ایجاد شد.
فضای نام و نام نمونه را انتخاب کنید (استفاده از پیش فرض ها خوب است). برای اهداف این آموزش ، executor.emisary یا managerstorage.enabled را بررسی نکنید.
روی Deploy کلیک کنید و چند لحظه صبر کنید تا خط لوله مستقر شود. با استقرار Kubeflow Pipelines، شرایط خدمات را می پذیرید.
3. نمونه نوت بوک پلتفرم Cloud AI را تنظیم کنید.
به صفحه Vertex AI Workbench بروید. اولین باری که Workbench را اجرا می کنید، باید API Notebooks را فعال کنید.
در منوی اصلی پیمایش: ≡ -> Vertex AI -> Workbench
اگر از شما خواسته شد، Compute Engine API را فعال کنید.
یک نوت بوک جدید با نصب TensorFlow Enterprise 2.7 (یا بالاتر) ایجاد کنید.
نوت بوک جدید -> TensorFlow Enterprise 2.7 -> بدون GPU
یک منطقه و منطقه را انتخاب کنید و به نمونه نوت بوک یک نام بدهید.
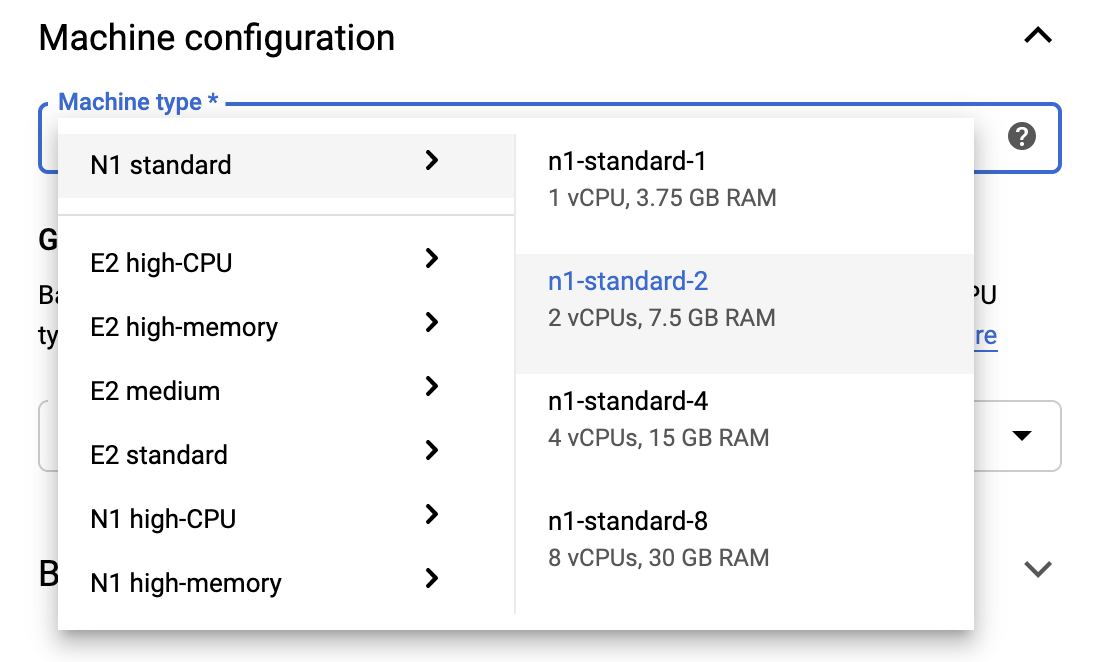
برای ماندن در محدوده های Free Tier، ممکن است لازم باشد تنظیمات پیش فرض را در اینجا تغییر دهید تا تعداد vCPU های موجود برای این نمونه را از 4 به 2 کاهش دهید:
- گزینه های پیشرفته را در پایین فرم نوت بوک جدید انتخاب کنید.
در قسمت پیکربندی ماشین، اگر نیاز به ماندن در ردیف آزاد دارید، ممکن است بخواهید پیکربندی با 1 یا 2 vCPU را انتخاب کنید.
منتظر بمانید تا نوت بوک جدید ایجاد شود و سپس روی Enable Notebooks API کلیک کنید
4. Notebook Getting Started را راه اندازی کنید
به صفحه AI Platform Pipelines Cluster بروید.
در منوی اصلی پیمایش: ≡ -> AI Platform -> Pipelines
در خط خوشه ای که در این آموزش استفاده می کنید، روی Open Pipelines Dashboard کلیک کنید.

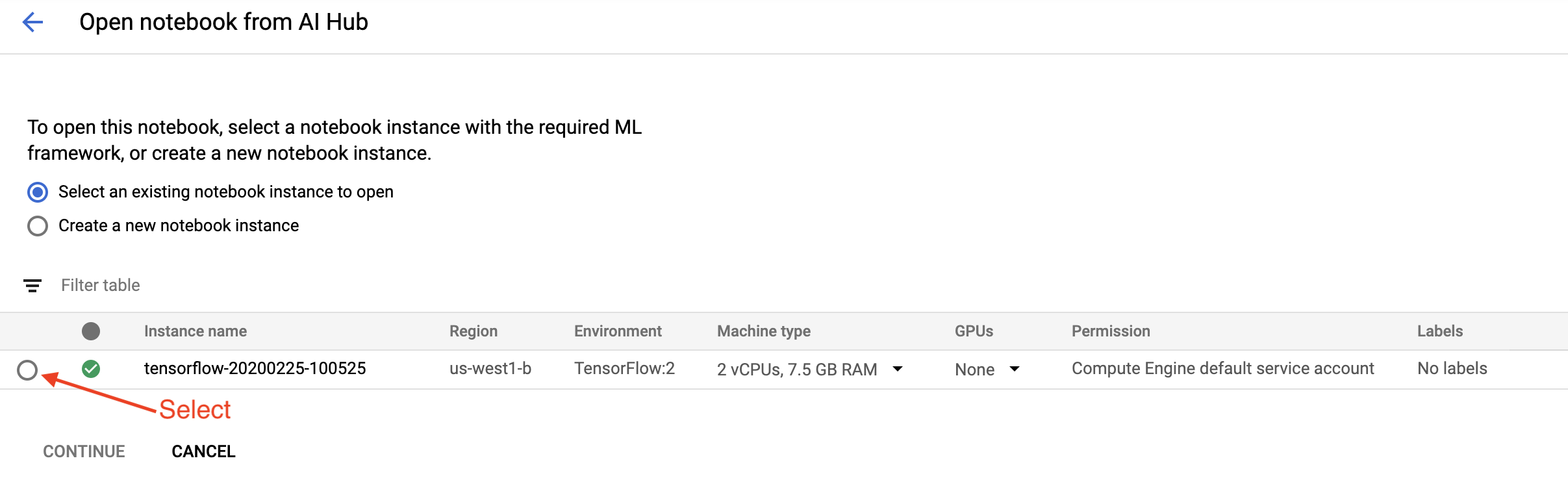
در صفحه شروع ، روی Open a Cloud AI Platform Notebook در Google Cloud کلیک کنید.

نمونه Notebook مورد استفاده برای این آموزش را انتخاب کنید و Continue و سپس Confirm را انتخاب کنید.
5. به کار در نوت بوک ادامه دهید
نصب
شروع نوت بوک با نصب TFX و Kubeflow Pipelines (KFP) در VM که آزمایشگاه Jupyter در آن اجرا می شود، شروع می شود.
سپس بررسی می کند که کدام نسخه از TFX نصب شده است، وارد کردن انجام می دهد و شناسه پروژه را تنظیم و چاپ می کند:

با خدمات Google Cloud خود ارتباط برقرار کنید
پیکربندی خط لوله به شناسه پروژه شما نیاز دارد که می توانید آن را از طریق دفترچه یادداشت دریافت کرده و به عنوان یک متغیر محیطی تنظیم کنید.
# Read GCP project id from env.
shell_output=!gcloud config list --format 'value(core.project)' 2>/dev/null
GCP_PROJECT_ID=shell_output[0]
print("GCP project ID:" + GCP_PROJECT_ID)
اکنون نقطه پایانی خوشه KFP خود را تنظیم کنید.
این را می توان از URL داشبورد Pipelines پیدا کرد. به داشبورد Kubeflow Pipeline بروید و به URL نگاه کنید. نقطه پایانی همه چیز در URL است که با https:// شروع می شود تا googleusercontent.com و شامل آن می شود.
ENDPOINT='' # Enter YOUR ENDPOINT here.
سپس نوت بوک یک نام منحصر به فرد برای تصویر سفارشی Docker تعیین می کند:
# Docker image name for the pipeline image
CUSTOM_TFX_IMAGE='gcr.io/' + GCP_PROJECT_ID + '/tfx-pipeline'
6. یک الگو را در فهرست پروژه خود کپی کنید
سلول نوت بوک بعدی را ویرایش کنید تا یک نام برای خط لوله خود تعیین کنید. در این آموزش my_pipeline استفاده خواهیم کرد.
PIPELINE_NAME="my_pipeline"
PROJECT_DIR=os.path.join(os.path.expanduser("~"),"imported",PIPELINE_NAME)
سپس نوت بوک از tfx CLI برای کپی کردن الگوی خط لوله استفاده می کند. این آموزش از مجموعه داده تاکسی شیکاگو برای انجام طبقه بندی باینری استفاده می کند، بنابراین الگو مدل را روی taxi تنظیم می کند:
!tfx template copy \
--pipeline-name={PIPELINE_NAME} \
--destination-path={PROJECT_DIR} \
--model=taxi
سپس نوت بوک زمینه CWD خود را به دایرکتوری پروژه تغییر می دهد:
%cd {PROJECT_DIR}
فایل های خط لوله را مرور کنید
در سمت چپ نوت بوک Cloud AI Platform، باید یک مرورگر فایل را ببینید. باید دایرکتوری با نام خط لوله شما ( my_pipeline ) وجود داشته باشد. آن را باز کنید و فایل ها را مشاهده کنید. (می توانید آنها را باز کرده و از محیط نوت بوک نیز ویرایش کنید.)
# You can also list the files from the shellls
دستور tfx template copy در بالا یک داربست اساسی از فایلها ایجاد میکند که یک خط لوله ایجاد میکند. اینها شامل کدهای منبع پایتون، داده های نمونه و نوت بوک های Jupyter است. اینها برای این مثال خاص در نظر گرفته شده است. برای خطوط لوله خود، اینها فایل های پشتیبانی هستند که خط لوله شما به آن نیاز دارد.
در اینجا توضیحات مختصری از فایل های پایتون آورده شده است.
-
pipeline- این فهرست شامل تعریف خط لوله است-
configs.py- ثابت های رایج را برای اجراکنندگان خط لوله تعریف می کند -
pipeline.py- اجزای TFX و خط لوله را تعریف می کند
-
-
models- این فهرست شامل تعاریف مدل ML است.-
features.pyfeatures_test.py— ویژگی هایی را برای مدل تعریف می کند -
preprocessing.py/preprocessing_test.py— کارهای پیش پردازش را با استفاده ازtf::Transformتعریف می کند -
estimator- این دایرکتوری شامل یک مدل مبتنی بر برآوردگر است.-
constants.py- ثابت های مدل را تعریف می کند -
model.py/model_test.py- مدل DNN را با استفاده از برآوردگر TF تعریف می کند
-
-
keras- این فهرست شامل یک مدل مبتنی بر Keras است.-
constants.py- ثابت های مدل را تعریف می کند -
model.py/model_test.py- مدل DNN را با استفاده از Keras تعریف می کند
-
-
-
beam_runner.py/kubeflow_runner.py— دونده ها را برای هر موتور ارکستراسیون تعریف کنید
7. اولین خط لوله TFX خود را در Kubeflow اجرا کنید
نوت بوک خط لوله را با استفاده از دستور tfx run CLI اجرا می کند.
به حافظه وصل شوید
خطوط لوله در حال اجرا مصنوعاتی را ایجاد می کنند که باید در ML-Metadata ذخیره شوند. مصنوعات به بارهایی اشاره دارند که فایل هایی هستند که باید در یک سیستم فایل ذخیره شوند یا ذخیره سازی را مسدود کنند. برای این آموزش، ما از GCS برای ذخیره بارهای ابرداده خود، با استفاده از سطلی که به طور خودکار در حین راه اندازی ایجاد شده است، استفاده می کنیم. نام آن <your-project-id>-kubeflowpipelines-default خواهد بود.
خط لوله را ایجاد کنید
نوت بوک داده های نمونه ما را در سطل GCS آپلود می کند تا بتوانیم بعداً از آن در خط لوله خود استفاده کنیم.
gsutil cp data/data.csv gs://{GOOGLE_CLOUD_PROJECT}-kubeflowpipelines-default/tfx-template/data/taxi/data.csv
سپس نوت بوک از دستور tfx pipeline create برای ایجاد خط لوله استفاده می کند.
!tfx pipeline create \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT} \
--build-image
در حین ایجاد یک خط لوله، Dockerfile برای ساخت یک تصویر داکر تولید می شود. فراموش نکنید که این فایل ها را به سیستم کنترل منبع خود (مثلا git) به همراه فایل های منبع دیگر اضافه کنید.
خط لوله را اجرا کنید
سپس نوت بوک از دستور tfx run create برای شروع اجرای خط لوله شما استفاده می کند. همچنین این اجرا را در قسمت Experiments in Kubeflow Pipelines Dashboard مشاهده خواهید کرد.
tfx run create --pipeline-name={PIPELINE_NAME} --endpoint={ENDPOINT}
می توانید خط لوله خود را از داشبورد خطوط لوله Kubeflow مشاهده کنید.
8. داده های خود را اعتبار سنجی کنید
اولین وظیفه در هر پروژه علم داده یا ML، درک و پاکسازی داده ها است.
- انواع داده ها را برای هر ویژگی درک کنید
- به دنبال ناهنجاری ها و مقادیر گم شده باشید
- توزیع های هر ویژگی را درک کنید
اجزاء


- ExampleGen مجموعه داده ورودی را جذب و تقسیم می کند.
- StatisticsGen آمار مجموعه داده را محاسبه می کند.
- SchemaGen SchemaGen آمارها را بررسی می کند و یک طرح داده ایجاد می کند.
- ExampleValidator به دنبال ناهنجاری ها و مقادیر گم شده در مجموعه داده می گردد.
در ویرایشگر فایل آزمایشگاه Jupyter:
در pipeline / pipeline.py ، خطوطی را که این مؤلفهها را به خط لوله شما اضافه میکنند، لغو نظر کنید:
# components.append(statistics_gen)
# components.append(schema_gen)
# components.append(example_validator)
(هنگام کپی شدن فایل های الگو ExampleGen قبلاً فعال شده بود.)
خط لوله را به روز کنید و آن را دوباره اجرا کنید
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
خط لوله را بررسی کنید
برای Kubeflow Orchestrator، از داشبورد KFP دیدن کنید و خروجی های خط لوله را در صفحه برای اجرای خط لوله خود بیابید. روی برگه «آزمایشها» در سمت چپ و «همه اجراها» در صفحه آزمایشها کلیک کنید. شما باید بتوانید اجرا را با نام خط لوله خود پیدا کنید.
نمونه پیشرفته تر
مثال ارائه شده در اینجا در واقع فقط برای شروع کار است. برای مثال پیشرفته تر TensorFlow Data Validation Colab را ببینید.
برای اطلاعات بیشتر در مورد استفاده از TFDV برای کاوش و اعتبارسنجی یک مجموعه داده، به مثالها در tensorflow.org مراجعه کنید .
9. مهندسی ویژگی
می توانید کیفیت پیش بینی داده های خود را افزایش دهید و/یا ابعاد را با مهندسی ویژگی کاهش دهید.
- صلیب های ویژه
- واژگان
- جاسازی ها
- PCA
- رمزگذاری طبقه بندی شده
یکی از مزایای استفاده از TFX این است که شما کد تبدیل خود را یک بار می نویسید و تبدیل های حاصل بین آموزش و سرویس دهی سازگار خواهد بود.
اجزاء

- Transform مهندسی ویژگی را روی مجموعه داده انجام می دهد.
در ویرایشگر فایل آزمایشگاه Jupyter:
در pipeline / pipeline.py ، خطی را که Transform به خط لوله اضافه می کند، بیابید و از نظر خارج کنید.
# components.append(transform)
خط لوله را به روز کنید و آن را دوباره اجرا کنید
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
خروجی های خط لوله را بررسی کنید
برای Kubeflow Orchestrator، از داشبورد KFP دیدن کنید و خروجی های خط لوله را در صفحه برای اجرای خط لوله خود بیابید. روی برگه «آزمایشها» در سمت چپ و «همه اجراها» در صفحه آزمایشها کلیک کنید. شما باید بتوانید اجرا را با نام خط لوله خود پیدا کنید.
نمونه پیشرفته تر
مثال ارائه شده در اینجا در واقع فقط برای شروع کار است. برای مثال پیشرفته تر TensorFlow Transform Colab را ببینید.
10. آموزش
یک مدل TensorFlow را با داده های زیبا، تمیز و تبدیل شده خود آموزش دهید.
- دگرگونی های مرحله قبل را بگنجانید تا به طور مداوم اعمال شوند
- نتایج را به عنوان SavedModel برای تولید ذخیره کنید
- فرآیند آموزش را با استفاده از TensorBoard تجسم و کشف کنید
- همچنین یک EvalSavedModel را برای تجزیه و تحلیل عملکرد مدل ذخیره کنید
اجزاء
- ترینر یک مدل TensorFlow را آموزش می دهد.
در ویرایشگر فایل آزمایشگاه Jupyter:
در pipeline / pipeline.py ، موردی را که Trainer را به خط لوله اضافه میکند، پیدا کرده و از نظر خارج کنید:
# components.append(trainer)
خط لوله را به روز کنید و آن را دوباره اجرا کنید
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
خروجی های خط لوله را بررسی کنید
برای Kubeflow Orchestrator، از داشبورد KFP دیدن کنید و خروجی های خط لوله را در صفحه برای اجرای خط لوله خود بیابید. روی برگه «آزمایشها» در سمت چپ و «همه اجراها» در صفحه آزمایشها کلیک کنید. شما باید بتوانید اجرا را با نام خط لوله خود پیدا کنید.
نمونه پیشرفته تر
مثال ارائه شده در اینجا در واقع فقط برای شروع کار است. برای مثال پیشرفته تر به آموزش TensorBoard مراجعه کنید.
11. تجزیه و تحلیل عملکرد مدل
درک بیشتر از معیارهای سطح بالا.
- کاربران عملکرد مدل را فقط برای درخواست های خود تجربه می کنند
- عملکرد ضعیف در بخشهایی از دادهها را میتوان با معیارهای سطح بالا پنهان کرد
- انصاف مدل مهم است
- اغلب زیرمجموعه های کلیدی کاربران یا داده ها بسیار مهم هستند و ممکن است کوچک باشند
- عملکرد در شرایط بحرانی اما غیرعادی
- عملکرد برای مخاطبان کلیدی مانند اینفلوئنسرها
- اگر در حال تعویض مدلی هستید که در حال حاضر در حال تولید است، ابتدا مطمئن شوید که مدل جدید بهتر است
اجزاء
- ارزیاب تجزیه و تحلیل عمیق نتایج آموزش را انجام می دهد.
در ویرایشگر فایل آزمایشگاه Jupyter:
در pipeline / pipeline.py ، خطی را که Evaluator را به خط لوله اضافه می کند، بیابید و از نظر خارج کنید:
components.append(evaluator)
خط لوله را به روز کنید و آن را دوباره اجرا کنید
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
خروجی های خط لوله را بررسی کنید
برای Kubeflow Orchestrator، از داشبورد KFP دیدن کنید و خروجی های خط لوله را در صفحه برای اجرای خط لوله خود بیابید. روی برگه «آزمایشها» در سمت چپ و «همه اجراها» در صفحه آزمایشها کلیک کنید. شما باید بتوانید اجرا را با نام خط لوله خود پیدا کنید.
12. خدمت مدل
اگر مدل جدید آماده است، آن را درست کنید.
- Pusher SavedModels را در مکان های شناخته شده مستقر می کند
اهداف استقرار مدل های جدید را از مکان های شناخته شده دریافت می کنند
- سرویس TensorFlow
- TensorFlow Lite
- TensorFlow JS
- تنسورفلو هاب
اجزاء
- Pusher مدل را به یک زیرساخت خدمت رسانی مستقر می کند.
در ویرایشگر فایل آزمایشگاه Jupyter:
در pipeline / pipeline.py ، خطی را که Pusher را به خط لوله اضافه می کند، پیدا کرده و از نظر خارج کنید:
# components.append(pusher)
خروجی های خط لوله را بررسی کنید
برای Kubeflow Orchestrator، از داشبورد KFP دیدن کنید و خروجی های خط لوله را در صفحه برای اجرای خط لوله خود بیابید. روی برگه «آزمایشها» در سمت چپ و «همه اجراها» در صفحه آزمایشها کلیک کنید. شما باید بتوانید اجرا را با نام خط لوله خود پیدا کنید.
اهداف استقرار در دسترس
شما اکنون مدل خود را آموزش داده و اعتبارسنجی کرده اید و مدل شما اکنون آماده تولید است. اکنون می توانید مدل خود را در هر یک از اهداف استقرار TensorFlow، از جمله:
- TensorFlow Serving ، برای ارائه مدل شما در سرور یا مزرعه سرور و پردازش درخواستهای استنتاج REST و/یا gRPC.
- TensorFlow Lite ، برای گنجاندن مدل شما در یک برنامه تلفن همراه بومی Android یا iOS، یا در برنامه Raspberry Pi، IoT یا میکروکنترلر.
- TensorFlow.js برای اجرای مدل خود در مرورگر وب یا برنامه Node.JS.
نمونه های پیشرفته تر
مثال ارائه شده در بالا در واقع فقط برای شروع کار است. در زیر چند نمونه از ادغام با سایر سرویس های Cloud آورده شده است.
ملاحظات منابع خط لوله Kubeflow
بسته به نیازهای حجم کاری شما، پیکربندی پیش فرض برای استقرار خطوط لوله Kubeflow شما ممکن است نیازهای شما را برآورده کند یا نکند. میتوانید پیکربندیهای منابع خود را با استفاده از pipeline_operator_funcs در تماس خود با KubeflowDagRunnerConfig سفارشی کنید.
pipeline_operator_funcs لیستی از آیتم های OpFunc است که تمام نمونه های ContainerOp تولید شده را در مشخصات خط لوله KFP که از KubeflowDagRunner کامپایل شده است، تبدیل می کند.
به عنوان مثال، برای پیکربندی حافظه، میتوانیم از set_memory_request برای اعلام میزان حافظه مورد نیاز استفاده کنیم. یک راه معمولی برای انجام این کار، ایجاد یک پوشش برای set_memory_request و استفاده از آن برای اضافه کردن به لیست لوله های OpFunc s است:
def request_more_memory():
def _set_memory_spec(container_op):
container_op.set_memory_request('32G')
return _set_memory_spec
# Then use this opfunc in KubeflowDagRunner
pipeline_op_funcs = kubeflow_dag_runner.get_default_pipeline_operator_funcs()
pipeline_op_funcs.append(request_more_memory())
config = KubeflowDagRunnerConfig(
pipeline_operator_funcs=pipeline_op_funcs,
...
)
kubeflow_dag_runner.KubeflowDagRunner(config=config).run(pipeline)
توابع پیکربندی منابع مشابه عبارتند از:
-
set_memory_limit -
set_cpu_request -
set_cpu_limit -
set_gpu_limit
BigQueryExampleGen امتحان کنید
BigQuery یک انبار داده ابری بدون سرور، بسیار مقیاس پذیر و مقرون به صرفه است. BigQuery می تواند به عنوان منبعی برای مثال های آموزشی در TFX استفاده شود. در این مرحله BigQueryExampleGen به خط لوله اضافه می کنیم.
در ویرایشگر فایل آزمایشگاه Jupyter:
برای باز کردن pipeline.py دوبار کلیک کنید . CsvExampleGen را کامنت کنید و خطی را که نمونه ای از BigQueryExampleGen ایجاد می کند، لغو نظر کنید. همچنین باید آرگومان query تابع create_pipeline را از حالت نظر خارج کنید.
ما باید مشخص کنیم که از کدام پروژه GCP برای BigQuery استفاده کنیم و این کار با تنظیم --project در beam_pipeline_args هنگام ایجاد خط لوله انجام می شود.
برای باز کردن configs.py دوبار کلیک کنید . تعریف BIG_QUERY_WITH_DIRECT_RUNNER_BEAM_PIPELINE_ARGS و BIG_QUERY_QUERY لغو نظر کنید. شما باید شناسه پروژه و مقدار منطقه را در این فایل با مقادیر صحیح پروژه GCP خود جایگزین کنید.
دایرکتوری را یک سطح به بالا تغییر دهید. روی نام دایرکتوری بالای لیست فایل کلیک کنید. نام دایرکتوری نام خط لوله است که اگر نام خط لوله را تغییر نداده باشید my_pipeline است.
برای باز کردن kubeflow_runner.py دوبار کلیک کنید . دو آرگومان query و beam_pipeline_args را برای تابع create_pipeline از نظر خارج کنید.
اکنون خط لوله آماده استفاده از BigQuery به عنوان منبع نمونه است. خط لوله را مانند قبل به روز کنید و یک اجرای جدید مانند مراحل 5 و 6 ایجاد کنید.
خط لوله را به روز کنید و آن را دوباره اجرا کنید
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
Dataflow را امتحان کنید
چندین مؤلفه TFX از Apache Beam برای پیادهسازی خطوط لوله موازی داده استفاده میکنند و به این معنی است که میتوانید بارهای کاری پردازش داده را با استفاده از Google Cloud Dataflow توزیع کنید. در این مرحله، ارکستراتور Kubeflow را تنظیم می کنیم تا از Dataflow به عنوان پشتیبان پردازش داده برای Apache Beam استفاده کند.
# Select your project:
gcloud config set project YOUR_PROJECT_ID
# Get a list of services that you can enable in your project:
gcloud services list --available | grep Dataflow
# If you don't see dataflow.googleapis.com listed, that means you haven't been
# granted access to enable the Dataflow API. See your account adminstrator.
# Enable the Dataflow service:
gcloud services enable dataflow.googleapis.com
برای تغییر دایرکتوری روی pipeline دوبار کلیک کنید و برای باز کردن configs.py دوبار کلیک کنید . تعریف GOOGLE_CLOUD_REGION و DATAFLOW_BEAM_PIPELINE_ARGS را لغو نظر کنید.
دایرکتوری را یک سطح به بالا تغییر دهید. روی نام دایرکتوری بالای لیست فایل کلیک کنید. نام دایرکتوری نام خط لوله است که اگر تغییر ندادید my_pipeline است.
برای باز کردن kubeflow_runner.py دوبار کلیک کنید . uncomment beam_pipeline_args . (همچنین مطمئن شوید که beam_pipeline_args فعلی را که در مرحله 7 اضافه کرده اید، نظر دهید.)
خط لوله را به روز کنید و آن را دوباره اجرا کنید
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
میتوانید کارهای Dataflow خود را در Dataflow در Cloud Console پیدا کنید.
آموزش و پیشبینی پلتفرم هوش مصنوعی ابری را با KFP امتحان کنید
TFX با چندین سرویس GCP مدیریت شده، مانند پلتفرم Cloud AI for Training and Prediction، تعامل دارد. میتوانید جزء Trainer خود را طوری تنظیم کنید که از Cloud AI Platform Training، یک سرویس مدیریتشده برای آموزش مدلهای ML استفاده کند. علاوه بر این، وقتی مدل شما ساخته شد و آماده ارائه شد، میتوانید مدل خود را برای ارائه به پیشبینی پلتفرم هوش مصنوعی ابری فشار دهید . در این مرحله، ما مولفه Trainer و Pusher خود را برای استفاده از خدمات پلتفرم Cloud AI تنظیم می کنیم.
قبل از ویرایش فایلها، ابتدا باید API آموزش و پیشبینی پلتفرم هوش مصنوعی را فعال کنید.
برای تغییر دایرکتوری روی pipeline دوبار کلیک کنید و برای باز کردن configs.py دوبار کلیک کنید . تعریف GOOGLE_CLOUD_REGION ، GCP_AI_PLATFORM_TRAINING_ARGS و GCP_AI_PLATFORM_SERVING_ARGS را لغو نظر کنید. ما از تصویر کانتینر ساخته شده سفارشی خود برای آموزش یک مدل در Cloud AI Platform Training استفاده خواهیم کرد، بنابراین باید masterConfig.imageUri در GCP_AI_PLATFORM_TRAINING_ARGS روی همان مقدار CUSTOM_TFX_IMAGE در بالا تنظیم کنیم.
دایرکتوری را یک سطح به بالا تغییر دهید و برای باز کردن kubeflow_runner.py دوبار کلیک کنید . ai_platform_training_args و ai_platform_serving_args را حذف کنید.
خط لوله را به روز کنید و آن را دوباره اجرا کنید
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
می توانید مشاغل آموزشی خود را در مشاغل پلتفرم هوش مصنوعی ابری بیابید. اگر خط لوله شما با موفقیت تکمیل شد، میتوانید مدل خود را در مدلهای پلتفرم هوش مصنوعی ابری پیدا کنید.
14. از داده های خود استفاده کنید
در این آموزش، شما یک خط لوله برای یک مدل با استفاده از مجموعه داده تاکسی شیکاگو ساختید. اکنون سعی کنید داده های خود را در خط لوله قرار دهید. دادههای شما را میتوان در هر جایی که خط لوله میتواند به آنها دسترسی داشته باشد، از جمله فایلهای Google Cloud Storage، BigQuery یا فایلهای CSV ذخیره کرد.
شما باید تعریف خط لوله را تغییر دهید تا داده های خود را در خود جای دهد.
اگر داده های شما در فایل ها ذخیره می شود
-
DATA_PATHدرkubeflow_runner.pyتغییر دهید، با نشان دادن مکان.
اگر داده های شما در BigQuery ذخیره شده است
-
BIG_QUERY_QUERYدر configs.py به عبارت پرس و جو خود تغییر دهید. - افزودن ویژگی ها در
models/features.py. - تغییر
models/preprocessing.pyبرای تبدیل داده های ورودی برای آموزش . -
models/keras/model.pyوmodels/keras/constants.pyرا برای توصیف مدل ML خود تغییر دهید.
درباره ترینر بیشتر بدانید
برای جزئیات بیشتر در مورد خطوط لوله آموزشی ، راهنمای اجزای Trainer را ببینید.
تمیز کردن
برای پاکسازی تمام منابع Google Cloud مورد استفاده در این پروژه، میتوانید پروژه Google Cloud را که برای آموزش استفاده کردهاید حذف کنید .
از طرف دیگر، میتوانید با مراجعه به هر کنسول، منابع فردی را پاکسازی کنید: - Google Cloud Storage - Google Container Registry - Google Kubernetes Engine