
導入
このチュートリアルは、TensorFlow Extended(TFX)とAIPlatform Pipelinesを紹介し、Google Cloud 上で独自の機械学習パイプラインを作成する方法を学習できるように設計されています。 TFX、AI Platform Pipelines、Kubeflow との統合、および Jupyter ノートブックでの TFX との対話を示しています。
このチュートリアルの最後には、Google Cloud でホストされる ML パイプラインを作成して実行することができます。各実行の結果を視覚化し、作成されたアーティファクトの系統を確認できるようになります。
一般的な ML 開発プロセスに従い、データセットの調査から始めて、完全に動作するパイプラインを完成させます。その過程で、パイプラインをデバッグおよび更新し、パフォーマンスを測定する方法を検討します。
シカゴのタクシー データセット


シカゴ市がリリースしたTaxi Trips データセットを使用しています。
データセットの詳細については、 Google BigQueryをご覧ください。 BigQuery UIで完全なデータセットを探索します。
モデルの目標 - 二項分類
顧客のチップは 20% より多くなりますか、それとも少なくなりますか?
1. Google Cloud プロジェクトをセットアップする
1.a Google Cloud で環境をセットアップする
始めるには、Google Cloud アカウントが必要です。すでに持っている場合は、 「 新しいプロジェクトの作成 」に進んでください。
Google Cloud コンソールに移動します。
Google Cloud の利用規約に同意する
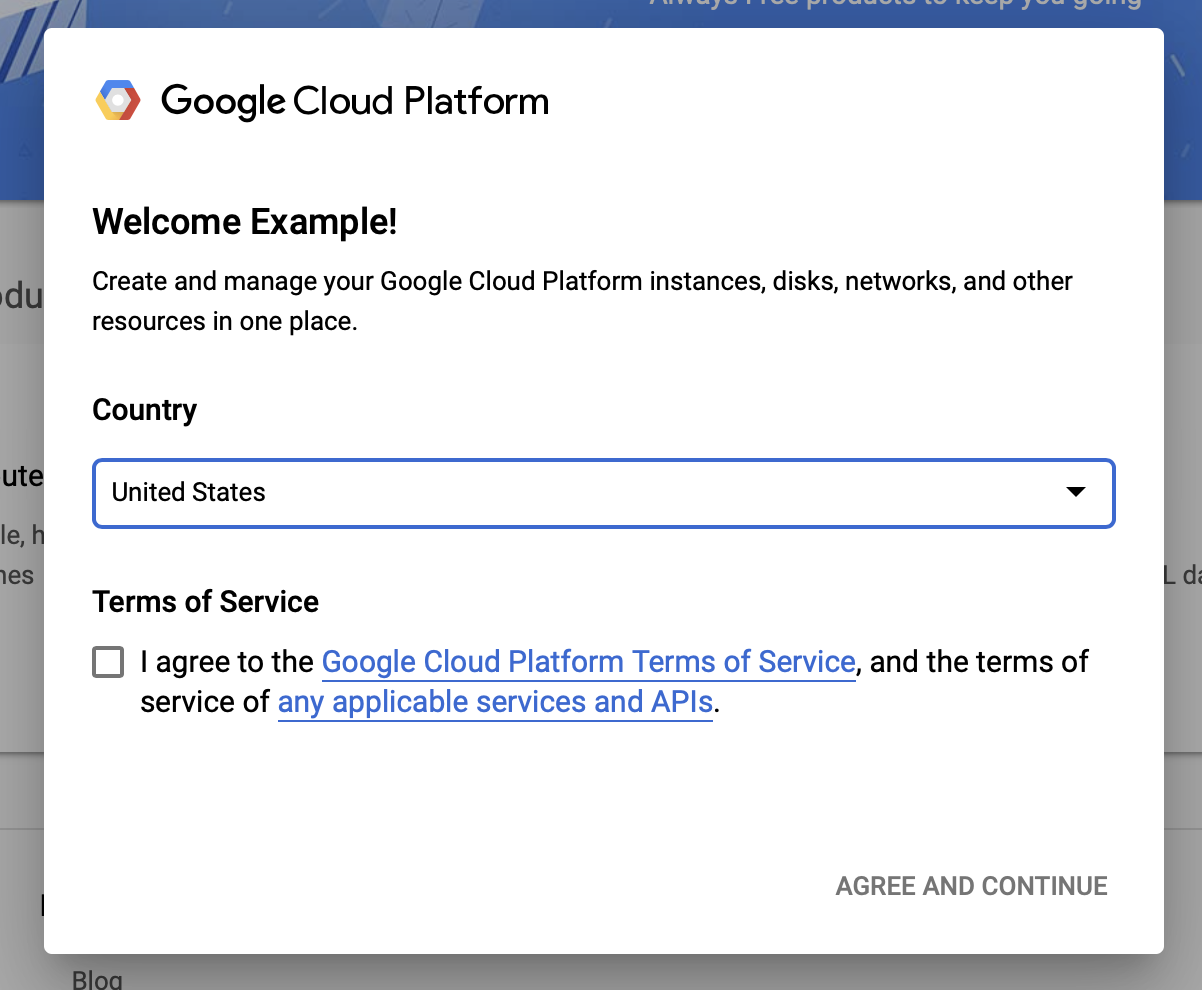
無料トライアルアカウントを開始したい場合は、 「Try For Free」 (または「Get Started for free 」) をクリックします。
あなたの国を選択してください。
利用規約に同意します。
請求の詳細を入力します。
この時点では料金はかかりません。他に Google Cloud プロジェクトがない場合は、 Google Cloud の無料利用枠の制限を超えずにこのチュートリアルを完了できます。これには、最大 8 コアの同時実行が含まれます。
1.b 新しいプロジェクトを作成します。
- メインの Google Cloud ダッシュボードから、 Google Cloud Platformヘッダーの横にあるプロジェクト ドロップダウンをクリックし、 [新しいプロジェクト]を選択します。
- プロジェクトに名前を付け、その他のプロジェクトの詳細を入力します
- プロジェクトを作成したら、必ずプロジェクトのドロップダウンから選択してください。
2. 新しい Kubernetes クラスターに AI Platform Pipeline をセットアップしてデプロイする
AI Platform Pipelines Clustersページに移動します。
メイン ナビゲーション メニューの下: ≡ > AI プラットフォーム > パイプライン
[+ 新しいインスタンス]をクリックして、新しいクラスターを作成します。
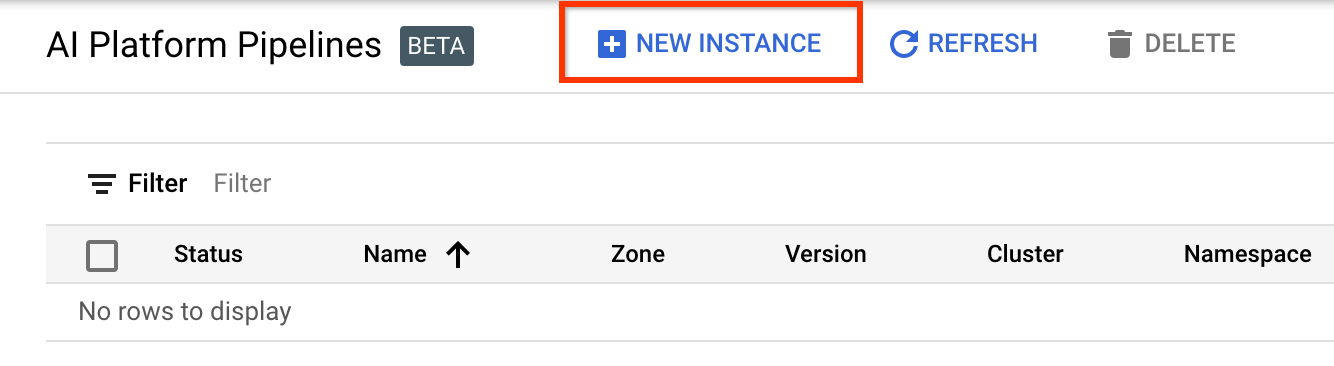
Kubeflow Pipelines の概要ページで、 [構成] をクリックします。

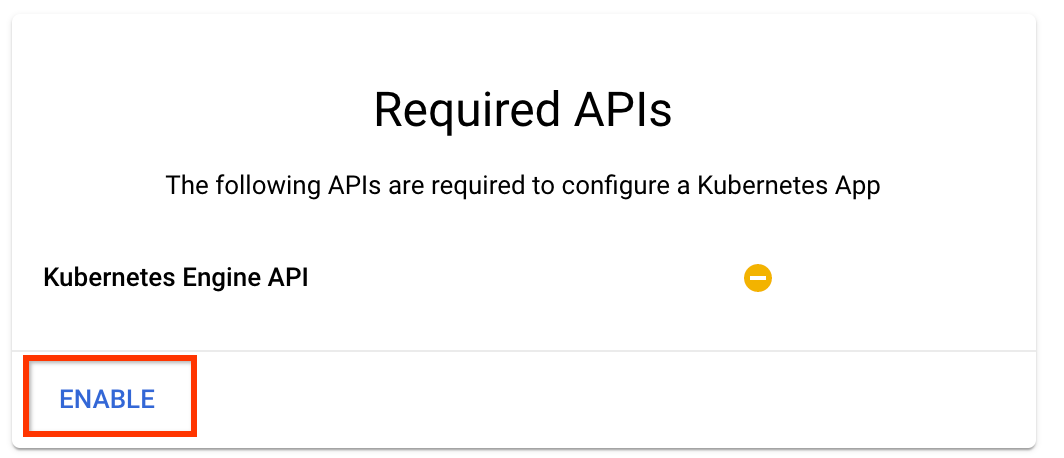
「有効にする」をクリックして Kubernetes Engine API を有効にします。
[Kubeflow パイプラインのデプロイ]ページで:
クラスターのゾーン(または「リージョン」) を選択します。ネットワークとサブネットワークは設定できますが、このチュートリアルではデフォルトのままにしておきます。
重要[次のクラウド API へのアクセスを許可する]チェックボックスをオンにします。 (これは、このクラスターがプロジェクトの他の部分にアクセスするために必要です。この手順を怠ると、後で修正するのが少し難しくなります。)
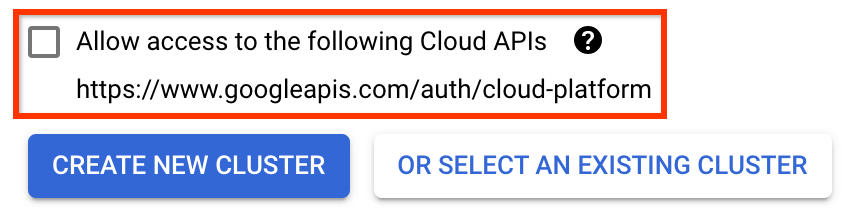
[新しいクラスターの作成] をクリックし、クラスターが作成されるまで数分間待ちます。これには数分かかります。完了すると、次のようなメッセージが表示されます。
クラスター「cluster-1」がゾーン「us-central1-a」に正常に作成されました。
ネームスペースとインスタンス名を選択します (デフォルトを使用しても問題ありません)。このチュートリアルの目的では、 executor.emissaryまたはmanagestorage.enabled をチェックしないでください。
[デプロイ] をクリックし、パイプラインがデプロイされるまで数分間待ちます。 Kubeflow Pipelines をデプロイすると、利用規約に同意したことになります。
3. Cloud AI Platform Notebook インスタンスをセットアップします。
Vertex AI ワークベンチのページに移動します。初めて Workbench を実行するときは、Notebooks API を有効にする必要があります。
メイン ナビゲーション メニューの下: ≡ -> Vertex AI -> ワークベンチ
プロンプトが表示されたら、Compute Engine API を有効にします。
TensorFlow Enterprise 2.7 (またはそれ以降) がインストールされた新しいノートブックを作成します。
新しいノートブック -> TensorFlow Enterprise 2.7 -> GPU なし
リージョンとゾーンを選択し、ノートブック インスタンスに名前を付けます。
無料利用枠の制限内に収まるようにするには、ここでデフォルト設定を変更して、このインスタンスで使用できる vCPU の数を 4 から 2 に減らす必要がある場合があります。
- [新しいノートブック] フォームの下部にある[詳細オプション]を選択します。
無料利用枠を維持する必要がある場合は、 [マシン構成]で 1 つまたは 2 つの vCPU を備えた構成を選択することもできます。
新しいノートブックが作成されるのを待ち、 「ノートブック API を有効にする」をクリックします。
4. Getting Started Notebook を起動します。
AI Platform Pipelines Clustersページに移動します。
メイン ナビゲーション メニューの下: ≡ -> AI プラットフォーム -> パイプライン
このチュートリアルで使用しているクラスターの行で、 「Open Pipelines Dashboard」をクリックします。

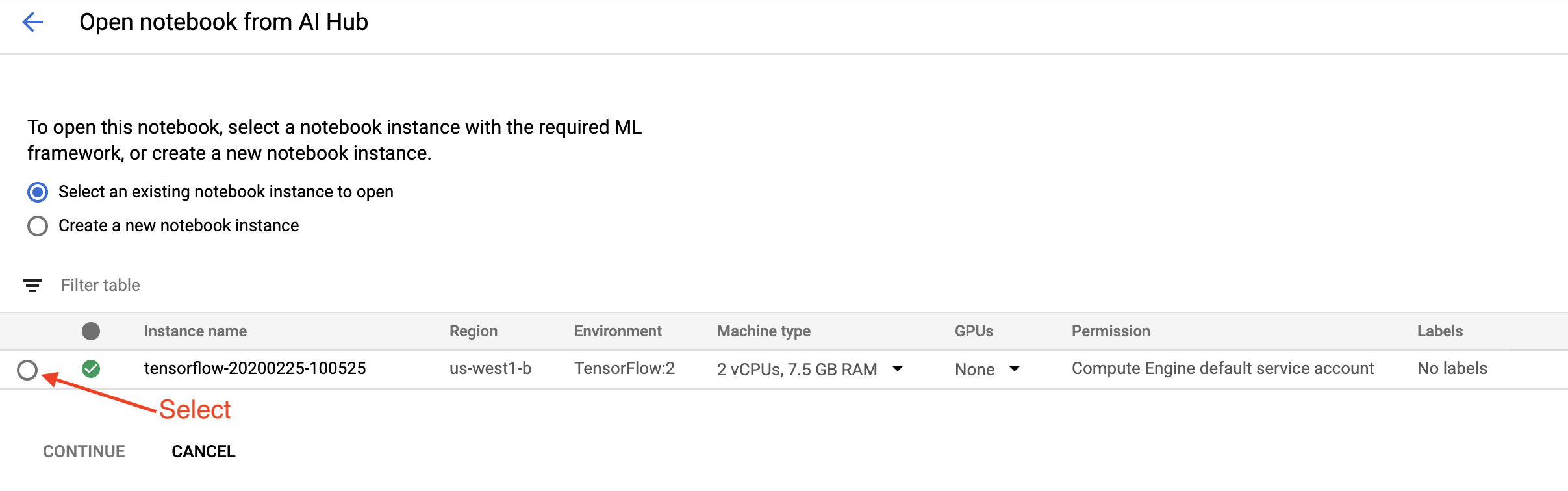
[はじめに]ページで、 [Google Cloud で Cloud AI Platform Notebook を開く] をクリックします。

このチュートリアルで使用している Notebook インスタンスを選択して「続行」し、 「確認」をクリックします。
5. ノートブックで作業を続けます
インストール
Getting Started Notebook は、Jupyter Lab が実行されている VM にTFXとKubeflow Pipelines (KFP) をインストールすることから始まります。
次に、インストールされている TFX のバージョンを確認し、インポートを実行し、プロジェクト ID を設定して出力します。

Google Cloud サービスに接続する
パイプライン構成にはプロジェクト ID が必要です。プロジェクト ID はノートブックから取得し、環境変数として設定できます。
# Read GCP project id from env.
shell_output=!gcloud config list --format 'value(core.project)' 2>/dev/null
GCP_PROJECT_ID=shell_output[0]
print("GCP project ID:" + GCP_PROJECT_ID)
次に、KFP クラスターのエンドポイントを設定します。
これは、パイプライン ダッシュボードの URL から見つけることができます。 Kubeflow Pipeline ダッシュボードに移動し、URL を確認します。エンドポイントは、 https://で始まりgoogleusercontent.comまでの URL 内のすべてです。
ENDPOINT='' # Enter YOUR ENDPOINT here.
次に、ノートブックはカスタム Docker イメージに一意の名前を設定します。
# Docker image name for the pipeline image
CUSTOM_TFX_IMAGE='gcr.io/' + GCP_PROJECT_ID + '/tfx-pipeline'
6. テンプレートをプロジェクト ディレクトリにコピーします。
次のノートブックのセルを編集して、パイプラインの名前を設定します。このチュートリアルでは、 my_pipelineを使用します。
PIPELINE_NAME="my_pipeline"
PROJECT_DIR=os.path.join(os.path.expanduser("~"),"imported",PIPELINE_NAME)
次に、ノートブックはtfx CLI を使用してパイプライン テンプレートをコピーします。このチュートリアルでは、 Chicago Taxi データセットを使用してバイナリ分類を実行するため、テンプレートはモデルをtaxiに設定します。
!tfx template copy \
--pipeline-name={PIPELINE_NAME} \
--destination-path={PROJECT_DIR} \
--model=taxi
次に、ノートブックは CWD コンテキストをプロジェクト ディレクトリに変更します。
%cd {PROJECT_DIR}
パイプライン ファイルを参照する
Cloud AI Platform Notebook の左側に、ファイル ブラウザーが表示されます。パイプライン名 ( my_pipeline ) のディレクトリがあるはずです。それを開いてファイルを表示します。 (ノートブック環境からも開いて編集できるようになります。)
# You can also list the files from the shellls
上記のtfx template copyコマンドは、パイプラインを構築するファイルの基本的な足場を作成しました。これらには、Python ソース コード、サンプル データ、Jupyter ノートブックが含まれます。これらはこの特定の例を対象としています。独自のパイプラインの場合、これらはパイプラインに必要なサポート ファイルになります。
ここでは Python ファイルについて簡単に説明します。
-
pipeline- このディレクトリにはパイプラインの定義が含まれますconfigs.py— パイプライン ランナーの共通定数を定義しますpipeline.py— TFX コンポーネントとパイプラインを定義します
models- このディレクトリには ML モデル定義が含まれています。-
features.pyfeatures_test.py— モデルの特徴を定義します preprocessing.py/preprocessing_test.py—tf::Transformを使用して前処理ジョブを定義しますestimator- このディレクトリには Estimator ベースのモデルが含まれています。-
constants.py— モデルの定数を定義します model.py/model_test.py— TF 推定器を使用して DNN モデルを定義します
-
keras- このディレクトリには Keras ベースのモデルが含まれています。-
constants.py— モデルの定数を定義します model.py/model_test.py— Keras を使用して DNN モデルを定義します
-
-
beam_runner.py/kubeflow_runner.py— 各オーケストレーション エンジンのランナーを定義します
7. Kubeflow で最初の TFX パイプラインを実行する
ノートブックは、 tfx run CLI コマンドを使用してパイプラインを実行します。
ストレージに接続する
パイプラインを実行すると、 ML-Metadataに保存する必要があるアーティファクトが作成されます。アーティファクトとは、ファイル システムまたはブロック ストレージに保存する必要があるファイルであるペイロードを指します。このチュートリアルでは、セットアップ中に自動的に作成されたバケットを使用して、GCS を使用してメタデータ ペイロードを保存します。その名前は<your-project-id>-kubeflowpipelines-defaultになります。
パイプラインを作成する
ノートブックはサンプル データを GCS バケットにアップロードし、後でパイプラインで使用できるようにします。
gsutil cp data/data.csv gs://{GOOGLE_CLOUD_PROJECT}-kubeflowpipelines-default/tfx-template/data/taxi/data.csv次に、ノートブックはtfx pipeline createコマンドを使用してパイプラインを作成します。
!tfx pipeline create \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT} \
--build-image
パイプラインの作成中に、Docker イメージを構築するためのDockerfileが生成されます。これらのファイルを他のソース ファイルとともにソース管理システム (git など) に追加することを忘れないでください。
パイプラインを実行する
次に、ノートブックはtfx run createコマンドを使用してパイプラインの実行を開始します。この実行は、Kubeflow Pipelines ダッシュボードの [実験] の下にリストされていることも確認できます。
tfx run create --pipeline-name={PIPELINE_NAME} --endpoint={ENDPOINT}Kubeflow Pipelines ダッシュボードからパイプラインを表示できます。
8. データを検証する
データ サイエンスまたは ML プロジェクトの最初のタスクは、データを理解してクリーンアップすることです。
- 各特徴のデータ型を理解する
- 異常値や欠損値を探す
- 各特徴の分布を理解する
コンポーネント


- ExampleGen は、入力データセットを取り込んで分割します。
- StatisticsGen は、データセットの統計を計算します。
- SchemaGen SchemaGen は統計を調べてデータ スキーマを作成します。
- ExampleValidator は、データセット内の異常値と欠損値を探します。
Jupyter ラボ ファイル エディターで:
pipeline / pipeline.pyで、これらのコンポーネントをパイプラインに追加する行のコメントを解除します。
# components.append(statistics_gen)
# components.append(schema_gen)
# components.append(example_validator)
(テンプレート ファイルがコピーされた時点で、 ExampleGenすでに有効になっていました。)
パイプラインを更新して再実行します
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
パイプラインを確認する
Kubeflow Orchestrator の場合は、KFP ダッシュボードにアクセスし、パイプライン実行のページでパイプライン出力を見つけます。左側の「実験」タブをクリックし、実験ページの「すべての実行」をクリックします。パイプラインの名前で実行を見つけることができるはずです。
より高度な例
ここで紹介した例は、実際には入門のみを目的としています。より高度な例については、TensorFlow Data Validation Colabを参照してください。
TFDV を使用してデータセットを探索および検証する方法の詳細については、 tensorflow.org の例を参照してください。
9. 特徴量エンジニアリング
特徴量エンジニアリングを使用して、データの予測品質を高めたり、次元を削減したりできます。
- 特徴クロス
- 語彙
- 埋め込み
- PCA
- カテゴリカルエンコーディング
TFX を使用する利点の 1 つは、変換コードを一度記述するだけで、結果として得られる変換がトレーニングと提供の間で一貫性を保つことです。
コンポーネント
![]()
- Transform は、データセットに対して特徴エンジニアリングを実行します。
Jupyter ラボ ファイル エディターで:
pipeline / pipeline.pyで、パイプラインにTransform を追加する行を見つけてコメントを解除します。
# components.append(transform)
パイプラインを更新して再実行します
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
パイプライン出力を確認する
Kubeflow Orchestrator の場合は、KFP ダッシュボードにアクセスし、パイプライン実行のページでパイプライン出力を見つけます。左側の「実験」タブをクリックし、実験ページの「すべての実行」をクリックします。パイプラインの名前で実行を見つけることができるはずです。
より高度な例
ここで紹介した例は、実際には入門のみを目的としています。より高度な例については、 TensorFlow Transform Colab を参照してください。
10. トレーニング
きれいで変換されたデータを使用して TensorFlow モデルをトレーニングします。
- 一貫して適用されるように、前のステップからの変換を含めます。
- 結果を実稼働用に SavedModel として保存します
- TensorBoard を使用してトレーニング プロセスを視覚化し、調査する
- モデルのパフォーマンス分析のために EvalSavedModel も保存します
コンポーネント
- トレーナーはTensorFlow モデルをトレーニングします。
Jupyter ラボ ファイル エディターで:
pipeline / pipeline.pyで、トレーナーをパイプラインに追加する を見つけてコメントを解除します。
# components.append(trainer)
パイプラインを更新して再実行します
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
パイプライン出力を確認する
Kubeflow Orchestrator の場合は、KFP ダッシュボードにアクセスし、パイプライン実行のページでパイプライン出力を見つけます。左側の「実験」タブをクリックし、実験ページの「すべての実行」をクリックします。パイプラインの名前で実行を見つけることができるはずです。
より高度な例
ここで紹介した例は、実際には入門のみを目的としています。より高度な例については、 「TensorBoard チュートリアル」を参照してください。
11. モデルのパフォーマンスの分析
トップレベルのメトリクス以上のことを理解します。
- ユーザーは自分のクエリに対してのみモデルのパフォーマンスを体験します
- データのスライスにおけるパフォーマンスの低下は、トップレベルのメトリクスによって隠蔽できる
- モデルの公平性は重要です
- 多くの場合、ユーザーまたはデータの主要なサブセットは非常に重要ですが、小さい場合があります。
- 危機的だが異常な状況におけるパフォーマンス
- インフルエンサーなどの主要視聴者向けのパフォーマンス
- 現在生産中のモデルを置き換える場合は、まず新しいモデルの方が優れているかどうかを確認してください
コンポーネント
- 評価者はトレーニング結果の詳細な分析を実行します。
Jupyter ラボ ファイル エディターで:
pipeline / pipeline.pyで、Evaluator をパイプラインに追加する行を見つけてコメントを解除します。
components.append(evaluator)
パイプラインを更新して再実行します
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
パイプライン出力を確認する
Kubeflow Orchestrator の場合は、KFP ダッシュボードにアクセスし、パイプライン実行のページでパイプライン出力を見つけます。左側の「実験」タブをクリックし、実験ページの「すべての実行」をクリックします。パイプラインの名前で実行を見つけることができるはずです。
12. モデルの提供
新しいモデルの準備ができている場合は、そうしてください。
- Pusher は SavedModel をよく知られた場所にデプロイします
導入ターゲットは有名な場所から新しいモデルを受け取ります
- TensorFlow の提供
- TensorFlow Lite
- TensorFlow JS
- TensorFlow ハブ
コンポーネント
- プッシャーは、サービスを提供するインフラストラクチャにモデルをデプロイします。
Jupyter ラボ ファイル エディターで:
pipeline / pipeline.pyで、Pusher をパイプラインに追加する行を見つけてコメントを解除します。
# components.append(pusher)
パイプライン出力を確認する
Kubeflow Orchestrator の場合は、KFP ダッシュボードにアクセスし、パイプライン実行のページでパイプライン出力を見つけます。左側の「実験」タブをクリックし、実験ページの「すべての実行」をクリックします。パイプラインの名前で実行を見つけることができるはずです。
利用可能な展開ターゲット
これでモデルのトレーニングと検証が完了し、モデルを運用する準備が整いました。これで、以下を含む任意の TensorFlow デプロイメント ターゲットにモデルをデプロイできるようになりました。
- TensorFlow Serving : サーバーまたはサーバー ファームでモデルを提供し、REST および/または gRPC 推論リクエストを処理します。
- TensorFlow Lite : Android または iOS のネイティブ モバイル アプリケーション、または Raspberry Pi、IoT、またはマイクロコントローラー アプリケーションにモデルを含めます。
- TensorFlow.js : Web ブラウザーまたは Node.JS アプリケーションでモデルを実行します。
より高度な例
上記の例は、実際には入門のみを目的としています。以下に、他のクラウド サービスとの統合の例をいくつか示します。
Kubeflow Pipelines リソースの考慮事項
ワークロードの要件に応じて、Kubeflow Pipelines デプロイメントのデフォルト構成がニーズを満たす場合と満たさない場合があります。 KubeflowDagRunnerConfigの呼び出しでpipeline_operator_funcsを使用してリソース構成をカスタマイズできます。
pipeline_operator_funcsは、 KubeflowDagRunnerからコンパイルされた KFP パイプライン仕様で生成されたすべてのContainerOpインスタンスを変換するOpFunc項目のリストです。
たとえば、メモリを構成するには、 set_memory_requestを使用して必要なメモリ量を宣言できます。これを行う一般的な方法は、 set_memory_requestのラッパーを作成し、それを使用してパイプラインOpFuncのリストに追加することです。
def request_more_memory():
def _set_memory_spec(container_op):
container_op.set_memory_request('32G')
return _set_memory_spec
# Then use this opfunc in KubeflowDagRunner
pipeline_op_funcs = kubeflow_dag_runner.get_default_pipeline_operator_funcs()
pipeline_op_funcs.append(request_more_memory())
config = KubeflowDagRunnerConfig(
pipeline_operator_funcs=pipeline_op_funcs,
...
)
kubeflow_dag_runner.KubeflowDagRunner(config=config).run(pipeline)
同様のリソース構成機能には次のものがあります。
-
set_memory_limit -
set_cpu_request -
set_cpu_limit -
set_gpu_limit
BigQueryExampleGen試してみる
BigQueryは、サーバーレスで拡張性が高く、コスト効率の高いクラウド データ ウェアハウスです。 BigQuery は、TFX のトレーニング サンプルのソースとして使用できます。このステップでは、 BigQueryExampleGenパイプラインに追加します。
Jupyter ラボ ファイル エディターで:
ダブルクリックしてpipeline.pyを開きます。 CsvExampleGenをコメントアウトし、 BigQueryExampleGenのインスタンスを作成する行のコメントを解除します。 create_pipeline関数のquery引数のコメントを解除する必要もあります。
BigQuery にどの GCP プロジェクトを使用するかを指定する必要があります。これは、パイプラインの作成時にbeam_pipeline_argsで--project設定することによって行われます。
ダブルクリックしてconfigs.pyを開きます。 BIG_QUERY_WITH_DIRECT_RUNNER_BEAM_PIPELINE_ARGSおよびBIG_QUERY_QUERYの定義のコメントを解除します。このファイル内のプロジェクト ID とリージョンの値を、GCP プロジェクトの正しい値に置き換える必要があります。
ディレクトリを 1 つ上のレベルに変更します。ファイルリストの上にあるディレクトリの名前をクリックします。ディレクトリの名前はパイプラインの名前になります。パイプライン名を変更しなかった場合は、 my_pipelineになります。
ダブルクリックしてkubeflow_runner.pyを開きます。 create_pipeline関数の 2 つの引数、 queryおよびbeam_pipeline_argsコメントを解除します。
これで、パイプラインで BigQuery をサンプル ソースとして使用できるようになりました。以前と同様にパイプラインを更新し、ステップ 5 と 6 で行ったように新しい実行実行を作成します。
パイプラインを更新して再実行します
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
データフローを試す
いくつかのTFX コンポーネントは Apache Beam を使用してデータ並列パイプラインを実装します。これは、 Google Cloud Dataflowを使用してデータ処理ワークロードを分散できることを意味します。このステップでは、Apache Beam のデータ処理バックエンドとして Dataflow を使用するように Kubeflow オーケストレーターを設定します。
# Select your project:
gcloud config set project YOUR_PROJECT_ID
# Get a list of services that you can enable in your project:
gcloud services list --available | grep Dataflow
# If you don't see dataflow.googleapis.com listed, that means you haven't been
# granted access to enable the Dataflow API. See your account adminstrator.
# Enable the Dataflow service:
gcloud services enable dataflow.googleapis.com
pipelineダブルクリックしてディレクトリを変更し、ダブルクリックしてconfigs.pyを開きます。 GOOGLE_CLOUD_REGIONおよびDATAFLOW_BEAM_PIPELINE_ARGSの定義のコメントを解除します。
ディレクトリを 1 つ上のレベルに変更します。ファイルリストの上にあるディレクトリの名前をクリックします。ディレクトリの名前はパイプラインの名前であり、変更しなかった場合はmy_pipelineになります。
ダブルクリックしてkubeflow_runner.pyを開きます。 beam_pipeline_argsコメントを解除します。 (ステップ 7 で追加した現在のbeam_pipeline_argsも必ずコメントアウトしてください。)
パイプラインを更新して再実行します
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
Dataflow ジョブは、Cloud Console の Dataflowで見つけることができます。
KFP を使用したクラウド AI プラットフォームのトレーニングと予測をお試しください
TFX は、 Cloud AI Platform for Training and Predictionなど、いくつかのマネージド GCP サービスと相互運用します。 ML モデルをトレーニングするためのマネージド サービスである Cloud AI Platform Training を使用するようにTrainerコンポーネントを設定できます。さらに、モデルが構築され、提供する準備ができたら、モデルを Cloud AI Platform Prediction にプッシュして提供できます。このステップでは、Cloud AI Platform サービスを使用するようにTrainerコンポーネントとPusherコンポーネントを設定します。
ファイルを編集する前に、まずAI Platform Training & Prediction APIを有効にする必要がある場合があります。
pipelineダブルクリックしてディレクトリを変更し、ダブルクリックしてconfigs.pyを開きます。 GOOGLE_CLOUD_REGION 、 GCP_AI_PLATFORM_TRAINING_ARGS 、およびGCP_AI_PLATFORM_SERVING_ARGSの定義のコメントを解除します。カスタムで構築されたコンテナ イメージを使用して Cloud AI Platform Training でモデルをトレーニングするため、 GCP_AI_PLATFORM_TRAINING_ARGSのmasterConfig.imageUriを上記のCUSTOM_TFX_IMAGEと同じ値に設定する必要があります。
ディレクトリを 1 つ上のレベルに変更し、ダブルクリックしてkubeflow_runner.pyを開きます。 ai_platform_training_argsとai_platform_serving_argsコメントを解除します。
パイプラインを更新して再実行します
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
トレーニング ジョブはCloud AI Platform ジョブで見つけることができます。パイプラインが正常に完了すると、 Cloud AI Platform Modelsでモデルを見つけることができます。
14.独自のデータを使用する
このチュートリアルでは、シカゴ タクシー データセットを使用してモデルのパイプラインを作成しました。次に、独自のデータをパイプラインに入れてみます。データは、Google Cloud Storage、BigQuery、CSV ファイルなど、パイプラインがアクセスできるどこにでも保存できます。
データに合わせてパイプライン定義を変更する必要があります。
データがファイルに保存されている場合
kubeflow_runner.pyのDATA_PATHを変更して、場所を示します。
データが BigQuery に保存されている場合
- configs.py の
BIG_QUERY_QUERYをクエリ ステートメントに変更します。 -
models/features.pyに機能を追加します。 -
models/preprocessing.pyを変更して、トレーニング用に入力データを変換します。 - ML モデルを記述するために、
models/keras/model.pyおよびmodels/keras/constants.pyを変更します。
トレーナーについて詳しく見る
トレーニング パイプラインの詳細については、 「トレーナー コンポーネント ガイド」を参照してください。
掃除中
このプロジェクトで使用されているすべての Google Cloud リソースをクリーンアップするには、チュートリアルに使用したGoogle Cloud プロジェクトを削除します。
あるいは、次の各コンソールにアクセスして、個々のリソースをクリーンアップすることもできます。 - Google Cloud Storage - Google Container Registry - Google Kubernetes Engine