
TFX パイプラインコンポーネントの1つである ExampleGen コンポーネントはデータを TFX のパイプラインに投入します。 これは外部のファイルやサービスからデータを読み取り、ほかの TFX のコンポーネントが読み取る Examples を生成します。 また、一貫性のある方法でデータセットを分割します。分割は設定により変更可能です。 同時に機械学習のベストプラクティスに従い、データセットの並び替えを行います。
- 入力: CSV や
TFRecord、BigQuery といった外部のデータソースからのデータ - 出力:
tf.Exampleレコード
ExampleGen とその他のコンポーネント
ExampleGen は TensorFlow Data Validation ライブラリを利用するコンポーネントにデータを提供します。 これには SchemaGen、StatisticsGen、Example Validator が含まれます。 また、TensorFlow Transform を利用する Transform にもデータを提供し、最終的には推論時にデプロイメントターゲットへとデータを供給します。
ExampleGen コンポーネントの使い方
サポートされるデータソース (現在、CSV ファイル、TF Example フォーマットの TFRecord ファイル、BigQuery のクエリ結果、の3つがサポートされています) を用いる場合、ExampleGen コンポーネントは典型的には非常に簡単にデプロイ可能で、ほとんどカスタマイズを必要とせずに利用できます 典型的なコードは次のようになります:
from tfx.utils.dsl_utils import csv_input
from tfx.components.example_gen.csv_example_gen.component import CsvExampleGen
examples = csv_input(os.path.join(base_dir, 'data/simple'))
example_gen = CsvExampleGen(input=examples)
次のように、外部の TF Example 形式のファイルを直接読み込むこともできます:
from tfx.utils.dsl_utils import tfrecord_input
from tfx.components.example_gen.import_example_gen.component import ImportExampleGen
examples = tfrecord_input(path_to_tfrecord_dir)
example_gen = ImportExampleGen(input=examples)
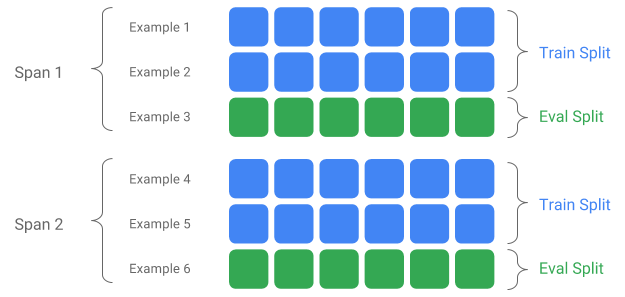
Span, Version, Split
Span は訓練用の Example をグループ化したものです。データがファイルシステムに永続的に保存されている 場合、それぞれの Span は別々のディレクトリに保存されているでしょう。Span が指し示す内容は TFX に ハードコードされていません。Span はある一日のデータを示すかもしれませんし、ある1時間のデータかも しれません。 Span は実行したいタスクにおいて意味のある任意のグループのことを示します。
それぞれの Span はデータの複数の Version を保持します。たとえば、ある Span に品質の良くないデータが 含まれていて、そこからいくつかの Example を取り除くことを考えると、これは Span のバージョンをあげます。 デフォルトでは TFX のコンポーネントは Span の最新のバージョンに対して操作を行います。
Span の各バージョンは、さらに Split に分割される場合があります。もっとも典型的な例では、Span を 訓練用と評価用の Split に分割します。
カスタム input/output split
ExampleGen が出力する 学習/評価 データの比率を変更するためには、output_config を ExampleGen コンポーネントに設定してください。
例を次に示します:
from tfx.proto import example_gen_pb2
# Input has a single split 'input_dir/*'.
# Output 2 splits: train:eval=3:1.
output = example_gen_pb2.Output(
split_config=example_gen_pb2.SplitConfig(splits=[
example_gen_pb2.SplitConfig.Split(name='train', hash_buckets=3),
example_gen_pb2.SplitConfig.Split(name='eval', hash_buckets=1)
]))
examples = csv_input(input_dir)
example_gen = CsvExampleGen(input=examples, output_config=output)
この例の中でどのように hash_buckets が設定されているかに注意してください。
すでに入力データが分割されている場合、input_config を ExampleGen コンポーネントに設定してください。
例を次に示します:
from tfx.proto import example_gen_pb2
# Input train split is 'input_dir/train/*', eval split is 'input_dir/eval/*'.
# Output splits are generated one-to-one mapping from input splits.
input = example_gen_pb2.Input(splits=[
example_gen_pb2.Input.Split(name='train', pattern='train/*'),
example_gen_pb2.Input.Split(name='eval', pattern='eval/*')
])
examples = csv_input(input_dir)
example_gen = CsvExampleGen(input=examples, input_config=input)
ファイルベースの ExampleGen コンポーネント (たとえば、 CsvExampleGen や ImportExampleGen) では、pattern は入力ファイルをまとめたディレクトリからの相対パスを glob 形式で記述したものになります。
クエリベースの ExampleGen コンポーネント (たとえば、BigQUeryExampleGen や PrestoExampleGen) では、pattern はSQLクエリになります。
デフォルトでは入力データをまとめたディレクトリには単一のファイルがあるものとして扱われます。また、学習/評価用のデータの分割は2:1の割合になるように行われます。
詳細については proto/example_gen.proto を参照してください。
Span
Span は入力する glob 形式の pattern において '{SPAN}' を用いて指定することで利用できます:
- SPAN で指定した箇所は数字とマッチし、データを SPAN の番号に対応付けます。 たとえば、'data_{SPAN}-*.tfrecord' は 'data_12-a.tfrecord', 'date_12-b.tfrecord' といったファイルを指し示します。
- SPAN が指定されない場合、常に Span を '0' 番として扱います。
- SPAN が指定された場合、パイプラインは最新の Span を処理し、メタデータに Span の番号を保存します。
例として、次の入力データが与えられたとします:
- '/tmp/span-01/train/data'
- '/tmp/span-01/eval/data'
- '/tmp/span-02/train/data'
- '/tmp/span-02/eval/data'
また、入力の設定が次のように与えられたとします:
splits {
name: 'train'
pattern: 'span-{SPAN}/train/*'
}
splits {
name: 'eval'
pattern: 'span-{SPAN}/eval/*'
}
この場合、パイプラインの処理は次のように実行されます:
- '/tmp/span-02/train/data' を train split として扱います
- '/tmp/span-02/eval/data' を eval split として扱います
また、Span の番号は '02' として扱います。もし '/tmp/span-03/...' が利用可能になった場合には、 単にパイプラインを再実行するだけで Span '03' が処理の対象になります。次のサンプルコードは Span の 指定の仕方を示しています:
from tfx.proto import example_gen_pb2
input = example_gen_pb2.Input(splits=[
example_gen_pb2.Input.Split(name='train',
pattern='span-{SPAN}/train/*'),
example_gen_pb2.Input.Split(name='eval',
pattern='span-{SPAN}/eval/*')
])
examples = csv_input('/tmp')
example_gen = CsvExampleGen(input=examples, input_config=input)
Version
カスタム ExampleGen
現在利用可能な ExampleGen コンポーネントが利用者のニーズに合わない場合、BaseExampleGenExecutor を用いて専用の ExampleGen コンポーネントを自作できます。
ファイルベースの ExampleGen の場合
BaseExampleGenExecutor を拡張するためには、まず、専用の Beam PTransform を作成し、学習/評価データを TF Example 形式に変換する処理を記述します。 たとえば、CsvExampleGen executorでは、分割されたCSVを入力とし、TF Example 形式に変換する処理を記述しています。
次に、BaseExampleGenExecutor を利用したコンポーネントを作成します。CsvExampleGen コンポーネント で同様のことを行っています。 他にも、専用の Executor を標準の ExampleGen コンポーネントに渡すことでも同様のことを実現できます。 例を次に示します:
from tfx.components.base import executor_spec
from tfx.components.example_gen.component import FileBasedExampleGen
from tfx.components.example_gen.csv_example_gen import executor
from tfx.utils.dsl_utils import external_input
examples = external_input(os.path.join(base_dir, 'data/simple'))
example_gen = FileBasedExampleGen(
input=examples,
custom_executor_spec=executor_spec.ExecutorClassSpec(executor.Executor))
現在、この手法を用いたAvro ファイルや Parquet ファイルの読み込み もサポートしています。
クエリベースの ExampleGen の場合
BaseExampleGenExecutor を拡張するためには、まず、専用の Beam PTransform を作成し、外部のデータソースからデータを読み込む処理を記述します。 次に、QueryBasedExampleGen を拡張したシンプルなコンポーネントを作成します。
コンポーネントは接続に関する追加の設定が必要な場合も、必要のない場合もあります。 たとえば、BigQuery executor は接続設定の詳細を抽象化した、デフォルトの beam.io コネクタを読み込みます。
Presto executorは専用の Beam PTransform と 専用の接続設定用 protobufが入力として必要になります。
専用の ExampleGen コンポーネントで接続の設定が必要な場合、新規に protobuf を作成し、オプションの execution パラメータである custom_config を通じてコンポーネントに渡してください。 次のコードは設定を行っているコンポーネントを利用する方法の例です。
from tfx.examples.custom_components.presto_example_gen.proto import presto_config_pb2
from tfx.examples.custom_components.presto_example_gen.presto_component.component import PrestoExampleGen
presto_config = presto_config_pb2.PrestoConnConfig(host='localhost', port=8080)
example_gen = PrestoExampleGen(presto_config, query='SELECT * FROM chicago_taxi_trips')