
مقدمة
تم تصميم هذا البرنامج التعليمي لتقديم TensorFlow Extended (TFX) و AIPlatform Pipelines ، ومساعدتك على تعلم كيفية إنشاء مسارات التعلم الآلي الخاصة بك على Google Cloud. يُظهر التكامل مع TFX، وAI Platform Pipelines، وKubeflow، بالإضافة إلى التفاعل مع TFX في دفاتر ملاحظات Jupyter.
في نهاية هذا البرنامج التعليمي، ستكون قد قمت بإنشاء وتشغيل ML Pipeline، المستضاف على Google Cloud. ستكون قادرًا على تصور نتائج كل جولة، وعرض نسب القطع الأثرية التي تم إنشاؤها.
ستتبع عملية تطوير تعلم الآلة النموذجية، بدءًا من فحص مجموعة البيانات، وانتهاءً بمسار عمل كامل. على طول الطريق، سوف تستكشف طرقًا لتصحيح الأخطاء وتحديث المسار الخاص بك، وقياس الأداء.
مجموعة بيانات تاكسي شيكاغو


أنت تستخدم مجموعة بيانات رحلات سيارات الأجرة الصادرة عن مدينة شيكاغو.
يمكنك قراءة المزيد حول مجموعة البيانات في Google BigQuery . استكشف مجموعة البيانات الكاملة في BigQuery UI .
الهدف النموذجي - التصنيف الثنائي
هل سيقدم العميل إكرامية أكثر أو أقل من 20%؟
1. قم بإعداد مشروع Google Cloud
1.أ قم بإعداد بيئتك على Google Cloud
للبدء، تحتاج إلى حساب Google Cloud. إذا كان لديك واحدًا بالفعل، فانتقل إلى إنشاء مشروع جديد .
انتقل إلى Google Cloud Console .
الموافقة على شروط وأحكام Google Cloud
إذا كنت ترغب في البدء باستخدام حساب تجريبي مجاني، فانقر فوق "تجربة مجانًا" (أو " البدء مجانًا ").
اختر بلدك.
الموافقة على شروط الخدمة.
أدخل تفاصيل الفواتير.
لن يتم محاسبتك في هذه المرحلة. إذا لم يكن لديك مشاريع Google Cloud أخرى، فيمكنك إكمال هذا البرنامج التعليمي دون تجاوز حدود الطبقة المجانية من Google Cloud ، والتي تتضمن 8 مراكز كحد أقصى تعمل في نفس الوقت.
1.ب إنشاء مشروع جديد.
- من لوحة تحكم Google Cloud الرئيسية ، انقر على القائمة المنسدلة للمشروع بجوار رأس Google Cloud Platform ، وحدد مشروع جديد .
- قم بتسمية مشروعك وأدخل تفاصيل المشروع الأخرى
- بمجرد إنشاء المشروع، تأكد من تحديده من القائمة المنسدلة للمشروع.
2. قم بإعداد ونشر AI Platform Pipeline على مجموعة Kubernetes جديدة
انتقل إلى صفحة مجموعات خطوط أنابيب منصة الذكاء الاصطناعي .
ضمن قائمة التنقل الرئيسية: ≡ > منصة الذكاء الاصطناعي > خطوط الأنابيب
انقر فوق + مثيل جديد لإنشاء مجموعة جديدة.
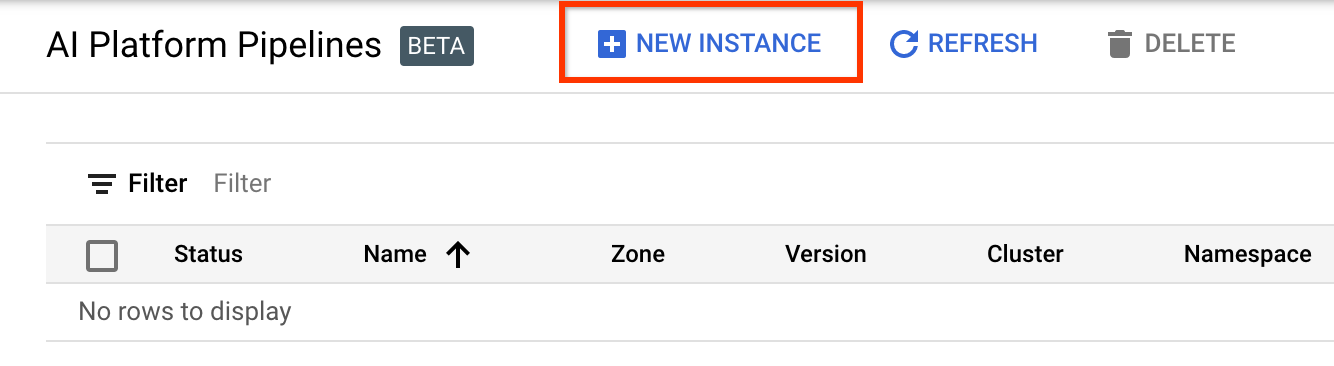
في صفحة النظرة العامة على خطوط أنابيب Kubeflow ، انقر فوق تكوين .

انقر فوق "تمكين" لتمكين Kubernetes Engine API
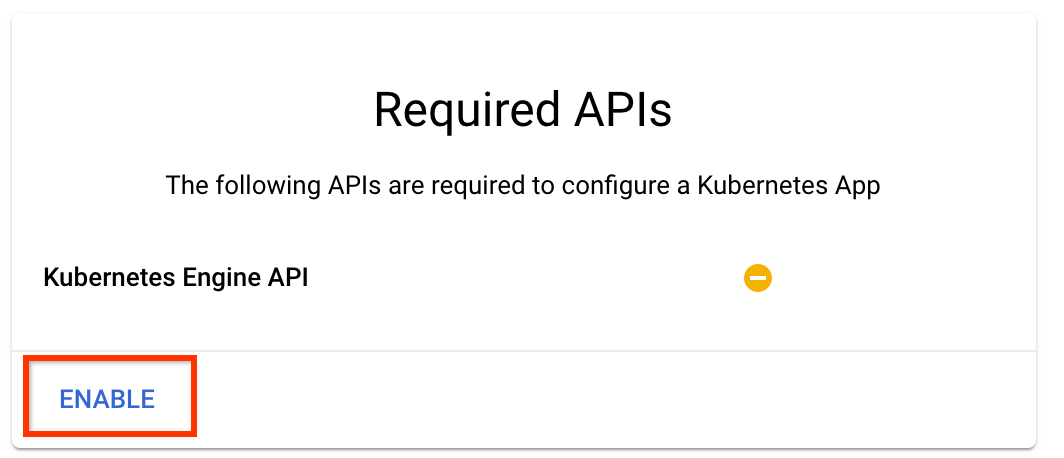
في صفحة نشر خطوط أنابيب Kubeflow :
حدد منطقة (أو "منطقة") لمجموعتك. يمكن ضبط الشبكة والشبكة الفرعية، ولكن لأغراض هذا البرنامج التعليمي، سنتركهما كإعدادات افتراضية.
هام حدد المربع المسمى السماح بالوصول إلى واجهات برمجة التطبيقات السحابية التالية . (هذا مطلوب حتى تتمكن هذه المجموعة من الوصول إلى الأجزاء الأخرى من مشروعك. إذا فاتتك هذه الخطوة، فسيكون إصلاحها لاحقًا أمرًا صعبًا بعض الشيء.)
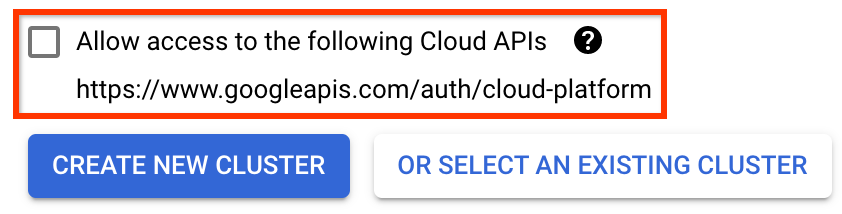
انقر فوق إنشاء مجموعة جديدة ، وانتظر عدة دقائق حتى يتم إنشاء المجموعة. سيستغرق هذا بضع دقائق. عند اكتماله ستظهر لك رسالة مثل:
تم إنشاء المجموعة "cluster-1" بنجاح في المنطقة "us-central1-a".
حدد مساحة الاسم واسم المثيل (استخدام الإعدادات الافتراضية أمر جيد). لأغراض هذا البرنامج التعليمي، لا تقم بتحديد executor.emissary أو Managedstorage.enabled .
انقر فوق نشر ، وانتظر عدة دقائق حتى يتم نشر خط الأنابيب. من خلال نشر خطوط أنابيب Kubeflow، فإنك توافق على شروط الخدمة.
3. قم بإعداد مثيل Cloud AI Platform Notebook.
انتقل إلى صفحة Vertex AI Workbench . في المرة الأولى التي تقوم فيها بتشغيل Workbench، ستحتاج إلى تمكين Notebooks API.
ضمن قائمة التنقل الرئيسية: ≡ -> Vertex AI -> Workbench
إذا طُلب منك ذلك، قم بتمكين Compute Engine API.
قم بإنشاء كمبيوتر محمول جديد مثبت عليه TensorFlow Enterprise 2.7 (أو أعلى).
كمبيوتر محمول جديد -> TensorFlow Enterprise 2.7 -> بدون وحدة معالجة الرسومات
حدد منطقة ومنطقة، ثم قم بتسمية مثيل دفتر الملاحظات.
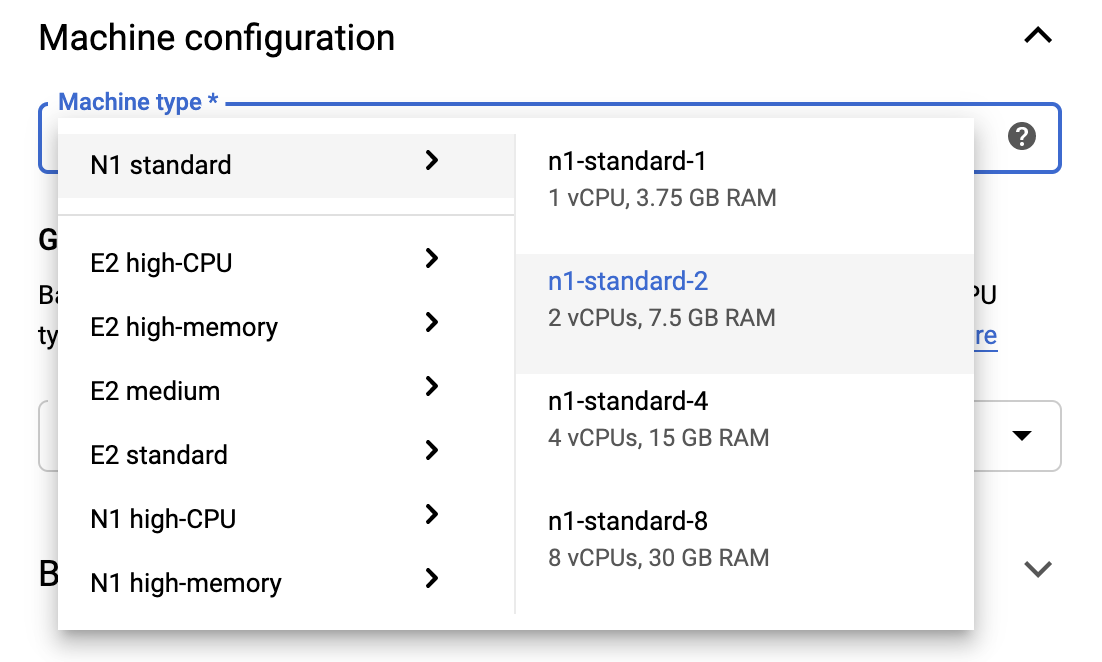
للبقاء ضمن حدود الطبقة المجانية، قد تحتاج إلى تغيير الإعدادات الافتراضية هنا لتقليل عدد وحدات المعالجة المركزية الافتراضية المتاحة لهذا المثيل من 4 إلى 2:
- حدد خيارات متقدمة في أسفل نموذج دفتر الملاحظات الجديد .
ضمن تكوين الجهاز، قد ترغب في تحديد تكوين باستخدام 1 أو 2 وحدات معالجة مركزية افتراضية (vCPUs) إذا كنت بحاجة إلى البقاء في الطبقة المجانية.
انتظر حتى يتم إنشاء دفتر الملاحظات الجديد، ثم انقر فوق تمكين Notebooks API
4. قم بتشغيل دفتر الملاحظات الخاص ببدء الاستخدام
انتقل إلى صفحة مجموعات خطوط أنابيب منصة الذكاء الاصطناعي .
ضمن قائمة التنقل الرئيسية: ≡ -> منصة الذكاء الاصطناعي -> خطوط الأنابيب
في سطر المجموعة التي تستخدمها في هذا البرنامج التعليمي، انقر فوق Open Pipelines Dashboard .

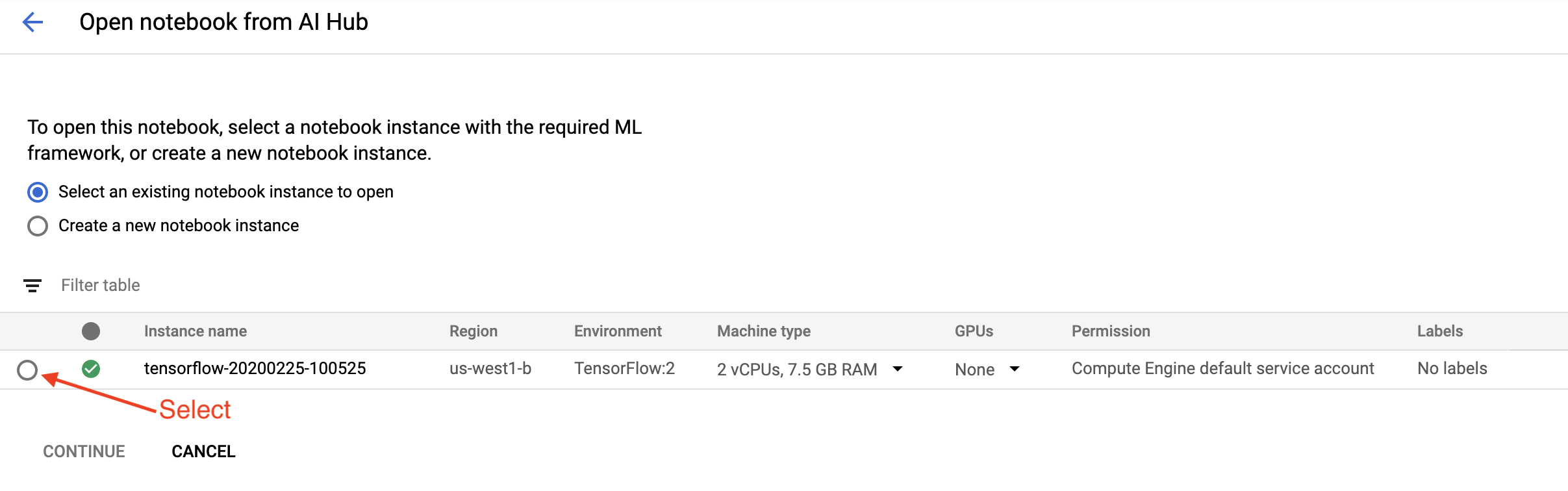
في صفحة البدء ، انقر فوق Open a Cloud AI Platform Notebook on Google Cloud .

حدد مثيل Notebook الذي تستخدمه لهذا البرنامج التعليمي، ثم قم بالمتابعة ، ثم قم بالتأكيد .
5. تابع العمل في دفتر الملاحظات
ثَبَّتَ
يبدأ دفتر ملاحظات البدء بتثبيت TFX و Kubeflow Pipelines (KFP) في الجهاز الظاهري الذي يعمل فيه Jupyter Lab.
ثم يتحقق بعد ذلك من إصدار TFX المثبت، ويقوم بالاستيراد، ويقوم بتعيين معرف المشروع وطباعته:

تواصل مع خدمات Google Cloud الخاصة بك
يحتاج تكوين المسار إلى معرف المشروع الخاص بك، والذي يمكنك الحصول عليه من خلال دفتر الملاحظات وتعيينه كمتغير بيئي.
# Read GCP project id from env.
shell_output=!gcloud config list --format 'value(core.project)' 2>/dev/null
GCP_PROJECT_ID=shell_output[0]
print("GCP project ID:" + GCP_PROJECT_ID)
الآن قم بتعيين نقطة نهاية مجموعة KFP الخاصة بك.
يمكن العثور على ذلك من عنوان URL الخاص بلوحة معلومات خطوط الأنابيب. انتقل إلى لوحة معلومات Kubeflow Pipeline وانظر إلى عنوان URL. نقطة النهاية هي كل شيء في عنوان URL بدءًا من https:// وحتى googleusercontent.com .
ENDPOINT='' # Enter YOUR ENDPOINT here.
يقوم دفتر الملاحظات بعد ذلك بتعيين اسم فريد لصورة Docker المخصصة:
# Docker image name for the pipeline image
CUSTOM_TFX_IMAGE='gcr.io/' + GCP_PROJECT_ID + '/tfx-pipeline'
6. انسخ قالبًا إلى دليل المشروع الخاص بك
قم بتحرير خلية دفتر الملاحظات التالية لتعيين اسم لخط الأنابيب الخاص بك. في هذا البرنامج التعليمي سوف نستخدم my_pipeline .
PIPELINE_NAME="my_pipeline"
PROJECT_DIR=os.path.join(os.path.expanduser("~"),"imported",PIPELINE_NAME)
يستخدم الكمبيوتر الدفتري بعد ذلك tfx CLI لنسخ قالب خط الأنابيب. يستخدم هذا البرنامج التعليمي مجموعة بيانات Chicago Taxi لإجراء تصنيف ثنائي، لذا يقوم القالب بتعيين النموذج على taxi :
!tfx template copy \
--pipeline-name={PIPELINE_NAME} \
--destination-path={PROJECT_DIR} \
--model=taxi
يقوم دفتر الملاحظات بعد ذلك بتغيير سياق CWD الخاص به إلى دليل المشروع:
%cd {PROJECT_DIR}
تصفح ملفات خطوط الأنابيب
على الجانب الأيسر من Cloud AI Platform Notebook، من المفترض أن تشاهد متصفح الملفات. يجب أن يكون هناك دليل باسم خط الأنابيب الخاص بك ( my_pipeline ). فتحه وعرض الملفات. (ستكون قادرًا على فتحها وتحريرها من بيئة دفتر الملاحظات أيضًا.)
# You can also list the files from the shellls
أنشأ أمر tfx template copy أعلاه مجموعة أساسية من الملفات التي تبني خط أنابيب. يتضمن ذلك أكواد مصدر Python ونماذج البيانات ودفاتر Jupyter. هذه مخصصة لهذا المثال بالذات. بالنسبة لخطوط الأنابيب الخاصة بك، ستكون هذه هي الملفات الداعمة التي يتطلبها خط الأنابيب الخاص بك.
فيما يلي وصف موجز لملفات بايثون.
-
pipeline- يحتوي هذا الدليل على تعريف خط الأنابيب-
configs.py— يحدد الثوابت المشتركة لمشغلي خطوط الأنابيب -
pipeline.py- يحدد مكونات TFX وخط الأنابيب
-
-
models- يحتوي هذا الدليل على تعريفات نماذج تعلم الآلة.-
features.pyfeatures_test.py— يحدد ميزات النموذج -
preprocessing.py/preprocessing_test.py- يحدد مهام المعالجة المسبقة باستخدامtf::Transform -
estimator- يحتوي هذا الدليل على نموذج قائم على المقدر.-
constants.py— يحدد ثوابت النموذج -
model.py/model_test.py— يحدد نموذج DNN باستخدام مقدر TF
-
-
keras- يحتوي هذا الدليل على نموذج يستند إلى Keras.-
constants.py— يحدد ثوابت النموذج -
model.py/model_test.py- يحدد نموذج DNN باستخدام Keras
-
-
-
beam_runner.py/kubeflow_runner.py- تحديد العدائين لكل محرك تزامن
7. قم بتشغيل أول خط أنابيب TFX على Kubeflow
سيقوم الكمبيوتر المحمول بتشغيل خط الأنابيب باستخدام الأمر tfx run CLI.
الاتصال بالتخزين
يؤدي تشغيل خطوط الأنابيب إلى إنشاء عناصر يجب تخزينها في ML-Metadata . تشير القطع الأثرية إلى الحمولات، وهي الملفات التي يجب تخزينها في نظام الملفات أو تخزين الكتلة. في هذا البرنامج التعليمي، سنستخدم GCS لتخزين حمولات البيانات التعريفية الخاصة بنا، باستخدام المجموعة التي تم إنشاؤها تلقائيًا أثناء الإعداد. سيكون اسمه <your-project-id>-kubeflowpipelines-default .
إنشاء خط الأنابيب
سيقوم دفتر الملاحظات بتحميل بيانات العينة الخاصة بنا إلى مجموعة GCS حتى نتمكن من استخدامها في مسارنا لاحقًا.
gsutil cp data/data.csv gs://{GOOGLE_CLOUD_PROJECT}-kubeflowpipelines-default/tfx-template/data/taxi/data.csv يستخدم الكمبيوتر الدفتري بعد ذلك أمر tfx pipeline create لإنشاء خط الأنابيب.
!tfx pipeline create \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT} \
--build-image
أثناء إنشاء خط الأنابيب، سيتم إنشاء Dockerfile لإنشاء صورة Docker. لا تنس إضافة هذه الملفات إلى نظام التحكم بالمصدر لديك (على سبيل المثال، git) بالإضافة إلى الملفات المصدر الأخرى.
قم بتشغيل خط الأنابيب
يستخدم الكمبيوتر الدفتري بعد ذلك الأمر tfx run create لبدء عملية تنفيذ لخط الأنابيب الخاص بك. ستشاهد أيضًا هذا التشغيل مدرجًا ضمن التجارب في لوحة معلومات خطوط أنابيب Kubeflow.
tfx run create --pipeline-name={PIPELINE_NAME} --endpoint={ENDPOINT}يمكنك عرض خط الأنابيب الخاص بك من لوحة معلومات خطوط أنابيب Kubeflow.
8. التحقق من صحة البيانات الخاصة بك
المهمة الأولى في أي مشروع لعلم البيانات أو تعلم الآلة هي فهم البيانات وتنظيفها.
- فهم أنواع البيانات لكل ميزة
- ابحث عن الحالات الشاذة والقيم المفقودة
- فهم التوزيعات لكل ميزة
عناصر


- يقوم exampleGen باستيعاب مجموعة بيانات الإدخال وتقسيمها.
- تقوم StatisticsGen بحساب إحصائيات مجموعة البيانات.
- يقوم SchemaGen SchemaGen بفحص الإحصائيات وإنشاء مخطط البيانات.
- يبحث exampleValidator عن الحالات الشاذة والقيم المفقودة في مجموعة البيانات.
في محرر ملفات Jupyter lab:
في pipeline / pipeline.py ، قم بإلغاء تعليق الأسطر التي تلحق هذه المكونات بخط الأنابيب الخاص بك:
# components.append(statistics_gen)
# components.append(schema_gen)
# components.append(example_validator)
(تم تمكين ExampleGen بالفعل عندما تم نسخ ملفات القالب.)
قم بتحديث خط الأنابيب وأعد تشغيله
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
تحقق من خط الأنابيب
بالنسبة إلى Kubeflow Orchestrator، قم بزيارة لوحة معلومات KFP وابحث عن مخرجات خط الأنابيب في الصفحة لتشغيل خط الأنابيب الخاص بك. انقر فوق علامة التبويب "التجارب" الموجودة على اليسار، ثم انقر فوق "جميع عمليات التشغيل" في صفحة التجارب. يجب أن تكون قادرًا على العثور على التشغيل باسم خط الأنابيب الخاص بك.
مثال أكثر تقدما
المثال المقدم هنا يهدف فقط إلى البدء. للحصول على مثال أكثر تقدمًا، راجع TensorFlow Data Validation Colab .
لمزيد من المعلومات حول استخدام TFDV لاستكشاف مجموعة البيانات والتحقق من صحتها، راجع الأمثلة على Tensorflow.org .
9. هندسة الميزات
يمكنك زيادة الجودة التنبؤية لبياناتك و/أو تقليل الأبعاد باستخدام هندسة الميزات.
- الصلبان الميزة
- المفردات
- التضمين
- PCA
- الترميز القاطع
إحدى فوائد استخدام TFX هي أنك ستكتب رمز التحويل الخاص بك مرة واحدة، وستكون التحويلات الناتجة متسقة بين التدريب والخدمة.
عناصر

- يقوم التحويل بإجراء هندسة الميزات على مجموعة البيانات.
في محرر ملفات Jupyter lab:
في pipeline / pipeline.py ، ابحث عن السطر الذي يُلحق التحويل بخط الأنابيب وقم بإلغاء التعليق عليه.
# components.append(transform)
قم بتحديث خط الأنابيب وأعد تشغيله
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
التحقق من مخرجات خط الأنابيب
بالنسبة إلى Kubeflow Orchestrator، قم بزيارة لوحة معلومات KFP وابحث عن مخرجات خط الأنابيب في الصفحة الخاصة بتشغيل خط الأنابيب الخاص بك. انقر فوق علامة التبويب "التجارب" الموجودة على اليسار، ثم انقر فوق "جميع عمليات التشغيل" في صفحة التجارب. يجب أن تكون قادرًا على العثور على التشغيل باستخدام اسم خط الأنابيب الخاص بك.
مثال أكثر تقدما
المثال المقدم هنا يهدف فقط إلى البدء. للحصول على مثال أكثر تقدمًا، راجع TensorFlow Transform Colab .
10. التدريب
قم بتدريب نموذج TensorFlow باستخدام بياناتك الجميلة والنظيفة والمحولة.
- قم بتضمين التحويلات من الخطوة السابقة بحيث يتم تطبيقها بشكل متسق
- احفظ النتائج كنموذج محفوظ للإنتاج
- تصور واستكشف عملية التدريب باستخدام TensorBoard
- قم أيضًا بحفظ EvalSavedModel لتحليل أداء النموذج
عناصر
- يقوم المدرب بتدريب نموذج TensorFlow.
في محرر ملفات Jupyter lab:
في pipeline / pipeline.py ، ابحث عن الذي يُلحق Trainer بمسار الأنابيب وقم بإلغاء التعليق عليه:
# components.append(trainer)
قم بتحديث خط الأنابيب وأعد تشغيله
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
التحقق من مخرجات خط الأنابيب
بالنسبة إلى Kubeflow Orchestrator، قم بزيارة لوحة معلومات KFP وابحث عن مخرجات خط الأنابيب في الصفحة الخاصة بتشغيل خط الأنابيب الخاص بك. انقر فوق علامة التبويب "التجارب" الموجودة على اليسار، ثم انقر فوق "جميع عمليات التشغيل" في صفحة التجارب. يجب أن تكون قادرًا على العثور على التشغيل باستخدام اسم خط الأنابيب الخاص بك.
مثال أكثر تقدما
المثال المقدم هنا يهدف فقط إلى البدء. للحصول على مثال أكثر تقدمًا، راجع البرنامج التعليمي لـ TensorBoard .
11. تحليل أداء النموذج
فهم أكثر من مجرد مقاييس المستوى الأعلى.
- يختبر المستخدمون أداء النموذج لاستعلاماتهم فقط
- يمكن إخفاء الأداء الضعيف على شرائح البيانات من خلال مقاييس المستوى الأعلى
- إن عدالة النموذج أمر مهم
- غالبًا ما تكون المجموعات الفرعية الرئيسية من المستخدمين أو البيانات مهمة جدًا، وقد تكون صغيرة
- الأداء في ظروف حرجة ولكن غير عادية
- الأداء للجماهير الرئيسية مثل المؤثرين
- إذا كنت تستبدل نموذجًا قيد الإنتاج حاليًا، فتأكد أولاً من أن النموذج الجديد أفضل
عناصر
- يقوم المقيم بإجراء تحليل عميق لنتائج التدريب.
في محرر ملفات Jupyter lab:
في pipeline / pipeline.py ، ابحث عن السطر الذي يُلحق المُقيم بخط الأنابيب وقم بإلغاء التعليق عليه:
components.append(evaluator)
قم بتحديث خط الأنابيب وأعد تشغيله
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
التحقق من مخرجات خط الأنابيب
بالنسبة إلى Kubeflow Orchestrator، قم بزيارة لوحة معلومات KFP وابحث عن مخرجات خط الأنابيب في الصفحة الخاصة بتشغيل خط الأنابيب الخاص بك. انقر فوق علامة التبويب "التجارب" الموجودة على اليسار، ثم انقر فوق "جميع عمليات التشغيل" في صفحة التجارب. يجب أن تكون قادرًا على العثور على التشغيل باستخدام اسم خط الأنابيب الخاص بك.
12. خدمة النموذج
إذا كان النموذج الجديد جاهزا، فاجعله كذلك.
- يقوم Pusher بنشر SavedModels في مواقع معروفة
تتلقى أهداف النشر نماذج جديدة من مواقع معروفة
- خدمة TensorFlow
- TensorFlow لايت
- TensorFlow شبيبة
- محور TensorFlow
عناصر
- يقوم Pusher بنشر النموذج على البنية التحتية للخدمة.
في محرر ملفات Jupyter lab:
في pipeline / pipeline.py ، ابحث عن السطر الذي يُلحق Pusher بخط الأنابيب وقم بإلغاء التعليق عليه:
# components.append(pusher)
التحقق من مخرجات خط الأنابيب
بالنسبة إلى Kubeflow Orchestrator، قم بزيارة لوحة معلومات KFP وابحث عن مخرجات خط الأنابيب في الصفحة لتشغيل خط الأنابيب الخاص بك. انقر فوق علامة التبويب "التجارب" الموجودة على اليسار، ثم انقر فوق "جميع عمليات التشغيل" في صفحة التجارب. يجب أن تكون قادرًا على العثور على التشغيل باستخدام اسم خط الأنابيب الخاص بك.
أهداف النشر المتاحة
لقد قمت الآن بتدريب النموذج الخاص بك والتحقق من صحته، وأصبح النموذج الخاص بك الآن جاهزًا للإنتاج. يمكنك الآن نشر نموذجك على أي من أهداف نشر TensorFlow، بما في ذلك:
- خدمة TensorFlow ، لخدمة النموذج الخاص بك على خادم أو مزرعة خوادم ومعالجة طلبات استدلال REST و/أو gRPC.
- TensorFlow Lite ، لتضمين النموذج الخاص بك في تطبيق جوال أصلي يعمل بنظام Android أو iOS، أو في تطبيق Raspberry Pi أو IoT أو وحدة التحكم الدقيقة.
- TensorFlow.js ، لتشغيل النموذج الخاص بك في متصفح الويب أو تطبيق Node.JS.
المزيد من الأمثلة المتقدمة
المثال الموضح أعلاه يهدف فقط إلى البدء. فيما يلي بعض الأمثلة على التكامل مع الخدمات السحابية الأخرى.
اعتبارات موارد خطوط أنابيب Kubeflow
اعتمادًا على متطلبات عبء العمل لديك، قد يلبي التكوين الافتراضي لنشر خطوط أنابيب Kubeflow احتياجاتك وقد لا يلبيها. يمكنك تخصيص تكوينات الموارد الخاصة بك باستخدام pipeline_operator_funcs في اتصالك بـ KubeflowDagRunnerConfig .
pipeline_operator_funcs عبارة عن قائمة بعناصر OpFunc ، والتي تحول جميع مثيلات ContainerOp التي تم إنشاؤها في مواصفات خط أنابيب KFP والتي تم تجميعها من KubeflowDagRunner .
على سبيل المثال، لتكوين الذاكرة يمكننا استخدام set_memory_request للإعلان عن مقدار الذاكرة المطلوبة. الطريقة النموذجية للقيام بذلك هي إنشاء غلاف لـ set_memory_request واستخدامه للإضافة إلى قائمة خطوط الأنابيب OpFunc s:
def request_more_memory():
def _set_memory_spec(container_op):
container_op.set_memory_request('32G')
return _set_memory_spec
# Then use this opfunc in KubeflowDagRunner
pipeline_op_funcs = kubeflow_dag_runner.get_default_pipeline_operator_funcs()
pipeline_op_funcs.append(request_more_memory())
config = KubeflowDagRunnerConfig(
pipeline_operator_funcs=pipeline_op_funcs,
...
)
kubeflow_dag_runner.KubeflowDagRunner(config=config).run(pipeline)
تتضمن وظائف تكوين الموارد المماثلة ما يلي:
-
set_memory_limit -
set_cpu_request -
set_cpu_limit -
set_gpu_limit
جرب BigQueryExampleGen
BigQuery عبارة عن مستودع بيانات سحابي بدون خادم وقابل للتطوير بشكل كبير وفعال من حيث التكلفة. يمكن استخدام BigQuery كمصدر لأمثلة التدريب على TFX. في هذه الخطوة، سنضيف BigQueryExampleGen إلى المسار.
في محرر ملفات Jupyter lab:
انقر نقرًا مزدوجًا لفتح pipeline.py . قم بالتعليق على CsvExampleGen وقم بإلغاء التعليق على السطر الذي ينشئ مثيل BigQueryExampleGen . تحتاج أيضًا إلى إلغاء التعليق على وسيطة query الخاصة بوظيفة create_pipeline .
نحن بحاجة إلى تحديد مشروع Google Cloud Platform الذي سيتم استخدامه لـ BigQuery، ويتم ذلك عن طريق تعيين --project في beam_pipeline_args عند إنشاء مسار.
انقر نقرًا مزدوجًا لفتح configs.py . قم بإلغاء التعليق على تعريف BIG_QUERY_WITH_DIRECT_RUNNER_BEAM_PIPELINE_ARGS و BIG_QUERY_QUERY . يجب عليك استبدال معرف المشروع وقيمة المنطقة في هذا الملف بالقيم الصحيحة لمشروع Google Cloud Platform الخاص بك.
تغيير الدليل مستوى واحد لأعلى. انقر فوق اسم الدليل أعلى قائمة الملفات. اسم الدليل هو اسم خط الأنابيب وهو my_pipeline إذا لم تقم بتغيير اسم خط الأنابيب.
انقر نقرًا مزدوجًا لفتح kubeflow_runner.py . قم بإلغاء التعليق على الوسيطتين query و beam_pipeline_args للدالة create_pipeline .
أصبح المسار الآن جاهزًا لاستخدام BigQuery كمصدر نموذجي. قم بتحديث المسار كما كان من قبل وقم بإنشاء عملية تنفيذ جديدة كما فعلنا في الخطوتين 5 و6.
قم بتحديث خط الأنابيب وأعد تشغيله
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
حاول تدفق البيانات
تستخدم العديد من مكونات TFX Apache Beam لتنفيذ خطوط أنابيب متوازية للبيانات، وهذا يعني أنه يمكنك توزيع أعباء عمل معالجة البيانات باستخدام Google Cloud Dataflow . في هذه الخطوة، سنقوم بتعيين منسق Kubeflow لاستخدام Dataflow كواجهة خلفية لمعالجة البيانات لـ Apache Beam.
# Select your project:
gcloud config set project YOUR_PROJECT_ID
# Get a list of services that you can enable in your project:
gcloud services list --available | grep Dataflow
# If you don't see dataflow.googleapis.com listed, that means you haven't been
# granted access to enable the Dataflow API. See your account adminstrator.
# Enable the Dataflow service:
gcloud services enable dataflow.googleapis.com
انقر نقرًا مزدوجًا pipeline لتغيير الدليل، وانقر نقرًا مزدوجًا لفتح configs.py . قم بإلغاء التعليق على تعريف GOOGLE_CLOUD_REGION و DATAFLOW_BEAM_PIPELINE_ARGS .
تغيير الدليل مستوى واحد لأعلى. انقر فوق اسم الدليل أعلى قائمة الملفات. اسم الدليل هو اسم خط الأنابيب وهو my_pipeline إذا لم تتغير.
انقر نقرًا مزدوجًا لفتح kubeflow_runner.py . قم بإلغاء التعليق beam_pipeline_args . (تأكد أيضًا من التعليق على beam_pipeline_args الحالية التي أضفتها في الخطوة 7.)
قم بتحديث خط الأنابيب وأعد تشغيله
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
يمكنك العثور على وظائف Dataflow الخاصة بك في Dataflow في Cloud Console .
جرّب التدريب والتنبؤ بمنصة Cloud AI Platform مع KFP
تتفاعل TFX مع العديد من خدمات Google Cloud Platform المُدارة، مثل Cloud AI Platform للتدريب والتنبؤ . يمكنك ضبط مكون Trainer الخاص بك لاستخدام Cloud AI Platform Training، وهي خدمة مُدارة لتدريب نماذج ML. علاوة على ذلك، عندما يتم إنشاء النموذج الخاص بك ويكون جاهزًا للعرض، يمكنك دفع النموذج الخاص بك إلى Cloud AI Platform Prediction للعرض. في هذه الخطوة، سنقوم بتعيين مكون Trainer Pusher لاستخدام خدمات Cloud AI Platform.
قبل تحرير الملفات، قد يتعين عليك أولاً تمكين AI Platform Training & Prediction API .
انقر نقرًا مزدوجًا pipeline لتغيير الدليل، وانقر نقرًا مزدوجًا لفتح configs.py . قم بإلغاء التعليق على تعريف GOOGLE_CLOUD_REGION و GCP_AI_PLATFORM_TRAINING_ARGS و GCP_AI_PLATFORM_SERVING_ARGS . سنستخدم صورة الحاوية المخصصة لدينا لتدريب نموذج على Cloud AI Platform Training، لذا يجب علينا تعيين masterConfig.imageUri في GCP_AI_PLATFORM_TRAINING_ARGS على نفس قيمة CUSTOM_TFX_IMAGE أعلاه.
قم بتغيير الدليل إلى مستوى أعلى، ثم انقر نقرًا مزدوجًا لفتح kubeflow_runner.py . قم بإلغاء التعليق ai_platform_training_args و ai_platform_serving_args .
قم بتحديث خط الأنابيب وأعد تشغيله
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
يمكنك العثور على وظائف التدريب الخاصة بك في Cloud AI Platform Jobs . إذا اكتمل المسار الخاص بك بنجاح، فيمكنك العثور على النموذج الخاص بك في Cloud AI Platform Models .
14. استخدم بياناتك الخاصة
في هذا البرنامج التعليمي، قمت بإنشاء مسار لنموذج باستخدام مجموعة بيانات Chicago Taxi. حاول الآن وضع بياناتك الخاصة في المسار. يمكن تخزين بياناتك في أي مكان يمكن لخط الأنابيب الوصول إليه، بما في ذلك ملفات Google Cloud Storage أو BigQuery أو CSV.
تحتاج إلى تعديل تعريف خط الأنابيب لاستيعاب بياناتك.
إذا تم تخزين البيانات الخاصة بك في الملفات
- قم بتعديل
DATA_PATHفيkubeflow_runner.py، مع الإشارة إلى الموقع.
إذا تم تخزين بياناتك في BigQuery
- قم بتعديل
BIG_QUERY_QUERYفي configs.py إلى بيان الاستعلام الخاص بك. - إضافة ميزات في
models/features.py. - تعديل
models/preprocessing.pyلتحويل بيانات الإدخال للتدريب . - قم بتعديل
models/keras/model.pymodels/keras/constants.pyلوصف نموذج ML الخاص بك .
اعرف المزيد عن المدرب
راجع دليل مكونات المدرب لمزيد من التفاصيل حول مسارات التدريب.
تنظيف
لتنظيف جميع موارد Google Cloud المستخدمة في هذا المشروع، يمكنك حذف مشروع Google Cloud الذي استخدمته في البرنامج التعليمي.
وبدلاً من ذلك، يمكنك تنظيف الموارد الفردية من خلال زيارة كل وحدة تحكم: - Google Cloud Storage - Google Container Registry - Google Kubernetes Engine