
Introducción
Este tutorial está diseñado para presentar TensorFlow Extended (TFX) y AIPlatform Pipelines , y ayudarlo a aprender a crear sus propios canales de aprendizaje automático en Google Cloud. Muestra la integración con TFX, AI Platform Pipelines y Kubeflow, así como la interacción con TFX en portátiles Jupyter.
Al final de este tutorial, habrá creado y ejecutado un ML Pipeline, alojado en Google Cloud. Podrás visualizar los resultados de cada ejecución y ver el linaje de los artefactos creados.
Seguirá un proceso típico de desarrollo de ML, comenzando por examinar el conjunto de datos y terminando con un proceso de trabajo completo. A lo largo del camino, explorará formas de depurar y actualizar su canalización, y medir el rendimiento.
Conjunto de datos de taxis de Chicago


Estás utilizando el conjunto de datos de Taxi Trips publicado por la ciudad de Chicago.
Puede leer más sobre el conjunto de datos en Google BigQuery . Explora el conjunto de datos completo en la interfaz de usuario de BigQuery .
Objetivo del modelo: clasificación binaria
¿El cliente dará una propina mayor o menor al 20%?
1. Configurar un proyecto de Google Cloud
1.a Configura tu entorno en Google Cloud
Para comenzar, necesita una cuenta de Google Cloud. Si ya tiene uno, pase a Crear nuevo proyecto .
Vaya a la consola de Google Cloud .
Acepta los términos y condiciones de Google Cloud
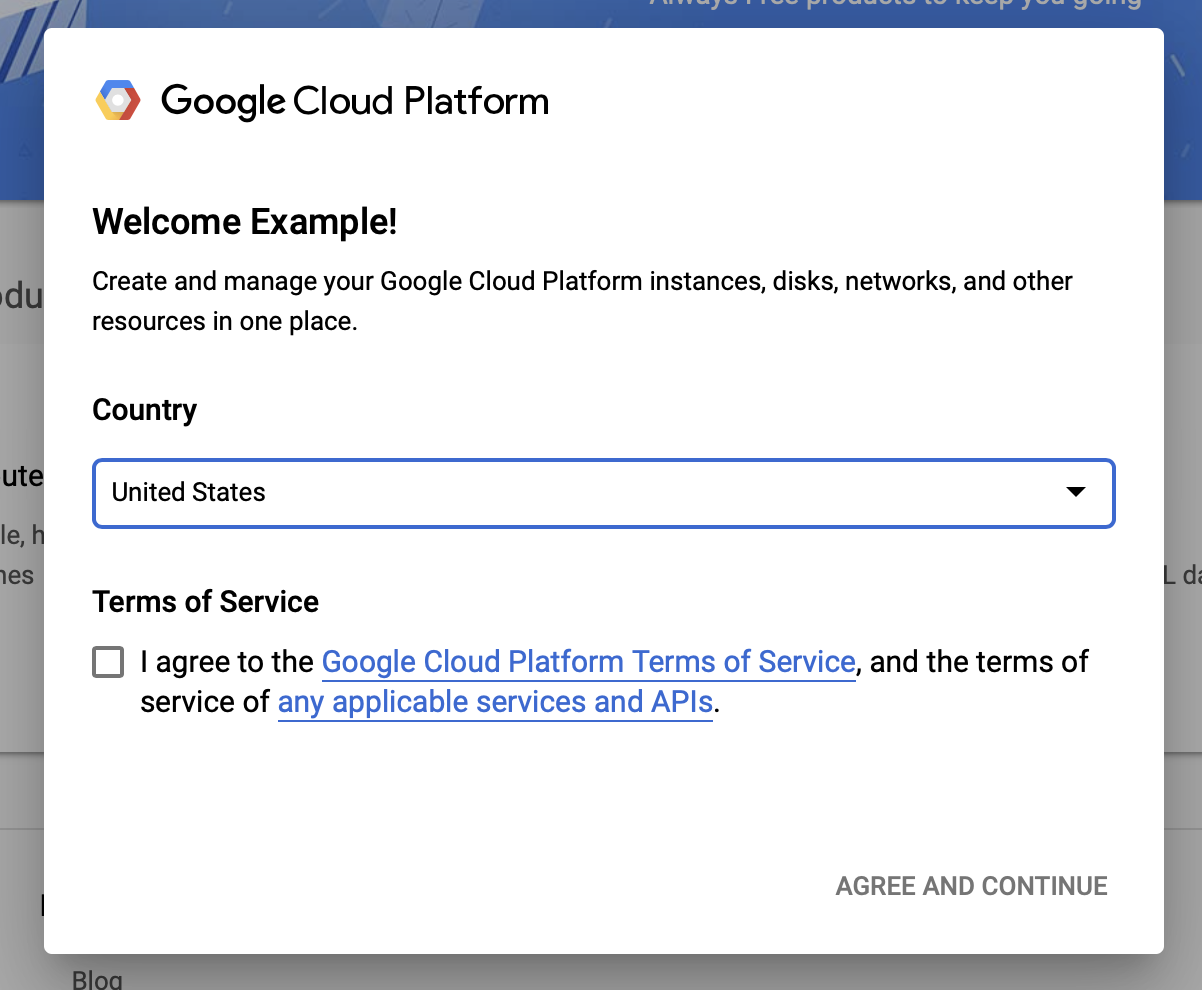
Si desea comenzar con una cuenta de prueba gratuita, haga clic en Probar gratis (o Empezar gratis ).
Selecciona tu país.
Acepta los términos de servicio.
Ingrese los detalles de facturación.
No se le cobrará en este momento. Si no tiene otros proyectos de Google Cloud, puede completar este tutorial sin exceder los límites de la capa gratuita de Google Cloud , que incluye un máximo de 8 núcleos ejecutándose al mismo tiempo.
1.b Crear un nuevo proyecto.
- Desde el panel principal de Google Cloud , haga clic en el menú desplegable del proyecto junto al encabezado de Google Cloud Platform y seleccione Nuevo proyecto .
- Dale un nombre a tu proyecto e ingresa otros detalles del proyecto.
- Una vez que haya creado un proyecto, asegúrese de seleccionarlo en el menú desplegable de proyectos.
2. Configurar e implementar AI Platform Pipeline en un nuevo clúster de Kubernetes
Vaya a la página Clústeres de canalizaciones de AI Platform .
En el menú de navegación principal: ≡ > AI Platform > Pipelines
Haga clic en + Nueva instancia para crear un nuevo clúster.

En la página de descripción general de Kubeflow Pipelines , haga clic en Configurar .

Haga clic en "Habilitar" para habilitar la API de Kubernetes Engine
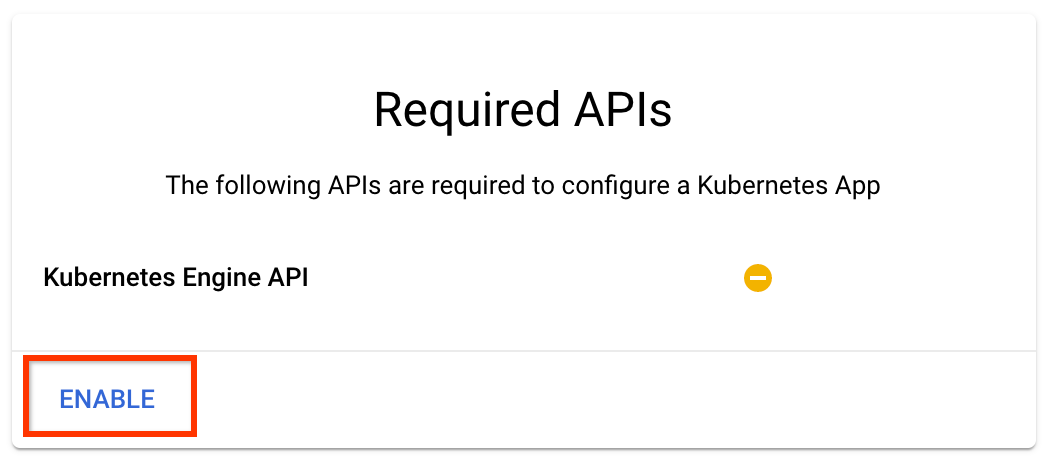
En la página Implementar canalizaciones de Kubeflow :
Seleccione una zona (o "región") para su clúster. La red y la subred se pueden configurar, pero para los fines de este tutorial las dejaremos como predeterminadas.
IMPORTANTE Marque la casilla denominada Permitir acceso a las siguientes API de la nube . (Esto es necesario para que este clúster acceda a las otras partes de su proyecto. Si omite este paso, solucionarlo más tarde es un poco complicado).

Haga clic en Crear nuevo clúster y espere varios minutos hasta que se haya creado el clúster. Esto tardará unos minutos. Cuando se complete, verá un mensaje como:
El clúster "cluster-1" se creó correctamente en la zona "us-central1-a".
Seleccione un espacio de nombres y un nombre de instancia (usar los valores predeterminados está bien). Para los fines de este tutorial, no marque executor.emissary o wantedstorage.enabled .
Haga clic en Implementar y espere unos momentos hasta que se haya implementado la canalización. Al implementar Kubeflow Pipelines, acepta los Términos de servicio.
3. Configure la instancia de Cloud AI Platform Notebook.
Vaya a la página de Vertex AI Workbench . La primera vez que ejecute Workbench, deberá habilitar la API de Notebooks.
En el menú de navegación principal: ≡ -> Vertex AI -> Workbench
Si se le solicita, habilite la API de Compute Engine.
Cree una nueva computadora portátil con TensorFlow Enterprise 2.7 (o superior) instalado.

Nueva computadora portátil -> TensorFlow Enterprise 2.7 -> Sin GPU
Seleccione una región y zona y asigne un nombre a la instancia del cuaderno.
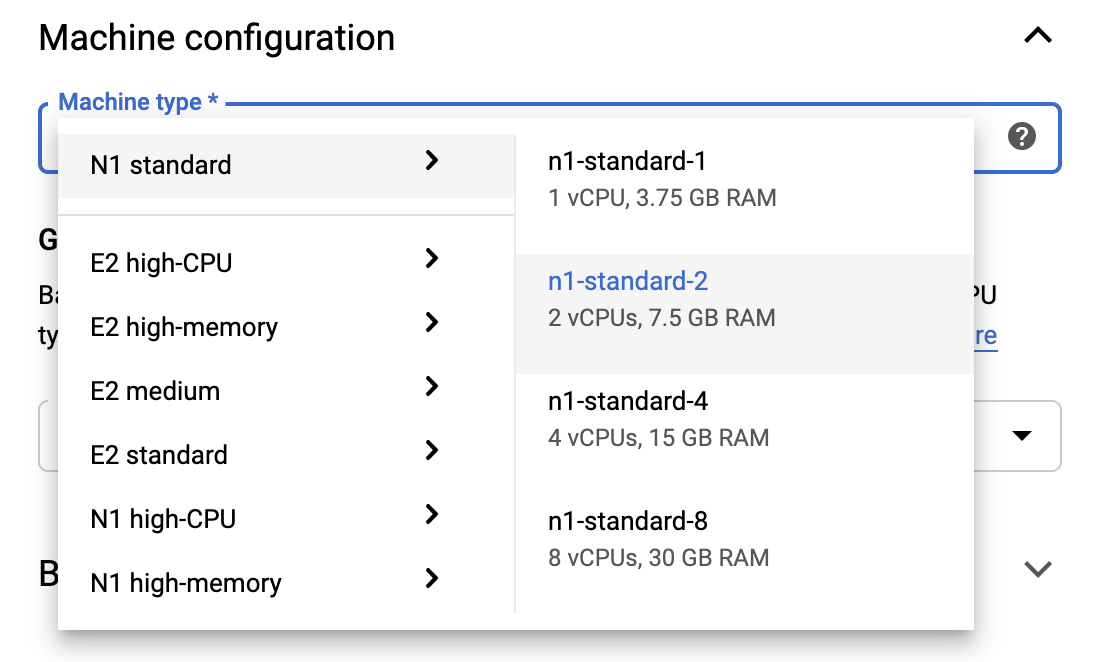
Para permanecer dentro de los límites de la capa gratuita, es posible que deba cambiar la configuración predeterminada aquí para reducir la cantidad de vCPU disponibles para esta instancia de 4 a 2:
- Seleccione Opciones avanzadas en la parte inferior del formulario Nuevo cuaderno .
En Configuración de la máquina, es posible que desee seleccionar una configuración con 1 o 2 vCPU si necesita permanecer en el nivel gratuito.
Espere a que se cree el nuevo cuaderno y luego haga clic en Habilitar API de cuadernos.
4. Inicie el cuaderno de introducción.
Vaya a la página Clústeres de canalizaciones de AI Platform .
En el menú de navegación principal: ≡ -> AI Platform -> Pipelines
En la línea del clúster que está utilizando en este tutorial, haga clic en Abrir panel de canalizaciones .

En la página Introducción , haga clic en Abrir un cuaderno de Cloud AI Platform en Google Cloud .

Seleccione la instancia de Notebook que está utilizando para este tutorial, Continuar y luego Confirmar .
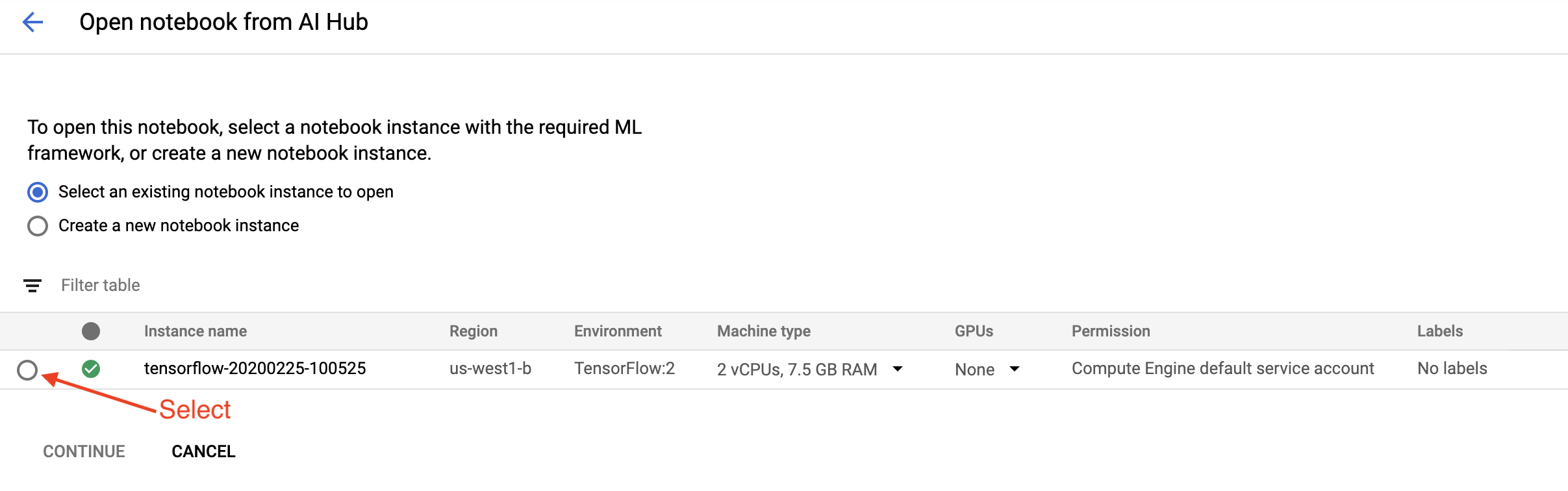
5. Continuar trabajando en el Notebook.
Instalar
El cuaderno de introducción comienza instalando TFX y Kubeflow Pipelines (KFP) en la máquina virtual en la que se ejecuta Jupyter Lab.
Luego verifica qué versión de TFX está instalada, realiza una importación y configura e imprime la ID del proyecto:

Conéctate con tus servicios de Google Cloud
La configuración de la canalización necesita el ID de su proyecto, que puede obtener a través del cuaderno y configurar como una variable ambiental.
# Read GCP project id from env.
shell_output=!gcloud config list --format 'value(core.project)' 2>/dev/null
GCP_PROJECT_ID=shell_output[0]
print("GCP project ID:" + GCP_PROJECT_ID)
Ahora configure el punto final de su clúster KFP.
Esto se puede encontrar en la URL del panel de Pipelines. Vaya al panel de Kubeflow Pipeline y observe la URL. El punto final es todo lo que está en la URL , comenzando con https:// hasta googleusercontent.com inclusive.
ENDPOINT='' # Enter YOUR ENDPOINT here.
Luego, el cuaderno establece un nombre único para la imagen de Docker personalizada:
# Docker image name for the pipeline image
CUSTOM_TFX_IMAGE='gcr.io/' + GCP_PROJECT_ID + '/tfx-pipeline'
6. Copie una plantilla en el directorio de su proyecto.
Edite la siguiente celda del cuaderno para establecer un nombre para su canalización. En este tutorial usaremos my_pipeline .
PIPELINE_NAME="my_pipeline"
PROJECT_DIR=os.path.join(os.path.expanduser("~"),"imported",PIPELINE_NAME)
Luego, el cuaderno usa la CLI tfx para copiar la plantilla de canalización. Este tutorial utiliza el conjunto de datos de Chicago Taxi para realizar una clasificación binaria, por lo que la plantilla configura el modelo para taxi :
!tfx template copy \
--pipeline-name={PIPELINE_NAME} \
--destination-path={PROJECT_DIR} \
--model=taxi
Luego, el cuaderno cambia su contexto CWD al directorio del proyecto:
%cd {PROJECT_DIR}
Explorar los archivos de canalización
En el lado izquierdo del cuaderno de Cloud AI Platform, debería ver un explorador de archivos. Debería haber un directorio con el nombre de su canalización ( my_pipeline ). Ábrelo y mira los archivos. (También podrás abrirlos y editarlos desde el entorno del cuaderno).
# You can also list the files from the shellls
El comando tfx template copy anterior creó una estructura básica de archivos que construyen una canalización. Estos incluyen códigos fuente de Python, datos de muestra y cuadernos de Jupyter. Estos están destinados a este ejemplo en particular. Para sus propias canalizaciones, estos serían los archivos de soporte que requiere su canalización.
Aquí hay una breve descripción de los archivos de Python.
-
pipeline: este directorio contiene la definición de la canalización.-
configs.py: define constantes comunes para los corredores de canalización -
pipeline.py: define los componentes TFX y una canalización
-
-
models: este directorio contiene definiciones de modelos de ML.-
features.pyfeatures_test.py: define características para el modelo -
preprocessing.py/preprocessing_test.py— define trabajos de preprocesamiento usandotf::Transform -
estimator: este directorio contiene un modelo basado en Estimator.-
constants.py: define las constantes del modelo. -
model.py/model_test.py: define el modelo DNN utilizando el estimador TF
-
-
keras: este directorio contiene un modelo basado en Keras.-
constants.py: define las constantes del modelo. -
model.py/model_test.py: define el modelo DNN usando Keras
-
-
-
beam_runner.py/kubeflow_runner.py: define ejecutores para cada motor de orquestación
7. Ejecute su primera canalización TFX en Kubeflow
El portátil ejecutará la canalización utilizando el comando CLI tfx run .
Conectarse al almacenamiento
Las canalizaciones en ejecución crean artefactos que deben almacenarse en ML-Metadata . Los artefactos se refieren a cargas útiles, que son archivos que deben almacenarse en un sistema de archivos o almacenamiento en bloque. Para este tutorial, usaremos GCS para almacenar nuestras cargas de metadatos, usando el depósito que se creó automáticamente durante la configuración. Su nombre será <your-project-id>-kubeflowpipelines-default .
Crear la canalización
El cuaderno cargará nuestros datos de muestra en el depósito de GCS para que podamos usarlos en nuestra canalización más adelante.
gsutil cp data/data.csv gs://{GOOGLE_CLOUD_PROJECT}-kubeflowpipelines-default/tfx-template/data/taxi/data.csv Luego, el cuaderno utiliza el comando tfx pipeline create para crear la canalización.
!tfx pipeline create \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT} \
--build-image
Mientras se crea una canalización, se generará Dockerfile para crear una imagen de Docker. No olvide agregar estos archivos a su sistema de control de código fuente (por ejemplo, git) junto con otros archivos fuente.
ejecutar la tubería
Luego, el cuaderno utiliza el comando tfx run create para iniciar una ejecución de su canalización. También verá esta ejecución en la lista de Experimentos en el Panel de control de canalizaciones de Kubeflow.
tfx run create --pipeline-name={PIPELINE_NAME} --endpoint={ENDPOINT}Puede ver su canalización desde el panel de canalizaciones de Kubeflow.
8. Valida tus datos
La primera tarea en cualquier proyecto de ciencia de datos o ML es comprender y limpiar los datos.
- Comprender los tipos de datos para cada característica
- Busque anomalías y valores faltantes.
- Comprender las distribuciones de cada característica.
Componentes


- EjemploGen ingiere y divide el conjunto de datos de entrada.
- StatisticsGen calcula estadísticas para el conjunto de datos.
- SchemaGen SchemaGen examina las estadísticas y crea un esquema de datos.
- EjemploValidator busca anomalías y valores faltantes en el conjunto de datos.
En el editor de archivos de laboratorio de Jupyter:
En pipeline / pipeline.py , descomente las líneas que agregan estos componentes a su pipeline:
# components.append(statistics_gen)
# components.append(schema_gen)
# components.append(example_validator)
( ExampleGen ya estaba habilitado cuando se copiaron los archivos de plantilla).
Actualice la canalización y vuelva a ejecutarla
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
comprobar la tubería
Para Kubeflow Orchestrator, visite el panel de KFP y busque resultados de canalización en la página para la ejecución de su canalización. Haga clic en la pestaña "Experimentos" a la izquierda y en "Todas las ejecuciones" en la página Experimentos. Debería poder encontrar la ejecución con el nombre de su canalización.
Ejemplo más avanzado
El ejemplo presentado aquí en realidad sólo pretende ayudarle a empezar. Para ver un ejemplo más avanzado, consulte la Colaboración de validación de datos de TensorFlow .
Para obtener más información sobre el uso de TFDV para explorar y validar un conjunto de datos, consulte los ejemplos en tensorflow.org .
9. Ingeniería de funciones
Puede aumentar la calidad predictiva de sus datos y/o reducir la dimensionalidad con la ingeniería de funciones.
- Cruces de características
- Vocabularios
- Incrustaciones
- PCA
- Codificación categórica
Uno de los beneficios de usar TFX es que escribirá su código de transformación una vez y las transformaciones resultantes serán consistentes entre el entrenamiento y la publicación.
Componentes

- Transform realiza ingeniería de características en el conjunto de datos.
En el editor de archivos de laboratorio de Jupyter:
En pipeline / pipeline.py , busque y descomente la línea que agrega Transform a la tubería.
# components.append(transform)
Actualice la canalización y vuelva a ejecutarla
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
Verificar las salidas de la tubería
Para Kubeflow Orchestrator, visite el panel de KFP y busque resultados de canalización en la página para la ejecución de su canalización. Haga clic en la pestaña "Experimentos" a la izquierda y en "Todas las ejecuciones" en la página Experimentos. Debería poder encontrar la ejecución con el nombre de su canalización.
Ejemplo más avanzado
El ejemplo presentado aquí en realidad sólo pretende ayudarle a empezar. Para ver un ejemplo más avanzado, consulte TensorFlow Transform Colab .
10. Entrenamiento
Entrene un modelo de TensorFlow con sus datos bonitos, limpios y transformados.
- Incluya las transformaciones del paso anterior para que se apliquen de manera consistente.
- Guarde los resultados como SavedModel para producción.
- Visualice y explore el proceso de capacitación usando TensorBoard
- Guarde también un EvalSavedModel para analizar el rendimiento del modelo.
Componentes
- Trainer entrena un modelo de TensorFlow.
En el editor de archivos de laboratorio de Jupyter:
En pipeline / pipeline.py , busque y descomente el elemento que agrega Trainer al pipeline:
# components.append(trainer)
Actualice la canalización y vuelva a ejecutarla
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
Verificar las salidas de la tubería
Para Kubeflow Orchestrator, visite el panel de KFP y busque resultados de canalización en la página para la ejecución de su canalización. Haga clic en la pestaña "Experimentos" a la izquierda y en "Todas las ejecuciones" en la página Experimentos. Debería poder encontrar la ejecución con el nombre de su canalización.
Ejemplo más avanzado
El ejemplo presentado aquí en realidad sólo pretende ayudarle a empezar. Para ver un ejemplo más avanzado, consulte el tutorial de TensorBoard .
11. Análisis del rendimiento del modelo.
Comprender más que solo las métricas de nivel superior.
- Los usuarios experimentan el rendimiento del modelo solo para sus consultas.
- El rendimiento deficiente en sectores de datos puede ocultarse mediante métricas de nivel superior
- La equidad del modelo es importante
- A menudo, los subconjuntos clave de usuarios o datos son muy importantes y pueden ser pequeños.
- Rendimiento en condiciones críticas pero inusuales
- Rendimiento para audiencias clave como influencers
- Si está reemplazando un modelo que está actualmente en producción, primero asegúrese de que el nuevo sea mejor.
Componentes
- El evaluador realiza un análisis profundo de los resultados de la capacitación.
En el editor de archivos de laboratorio de Jupyter:
En pipeline / pipeline.py , busque y descomente la línea que agrega Evaluator al pipeline:
components.append(evaluator)
Actualice la canalización y vuelva a ejecutarla
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
Verificar las salidas de la tubería
Para Kubeflow Orchestrator, visite el panel de KFP y busque resultados de canalización en la página para la ejecución de su canalización. Haga clic en la pestaña "Experimentos" a la izquierda y en "Todas las ejecuciones" en la página Experimentos. Debería poder encontrar la ejecución con el nombre de su canalización.
12. Al servicio del modelo
Si el nuevo modelo está listo, que así sea.
- Pusher implementa SavedModels en ubicaciones conocidas
Los objetivos de implementación reciben nuevos modelos de ubicaciones conocidas
- Servicio de TensorFlow
- TensorFlow Lite
- TensorFlowJS
- Centro TensorFlow
Componentes
- Pusher implementa el modelo en una infraestructura de servicio.
En el editor de archivos de laboratorio de Jupyter:
En pipeline / pipeline.py , busque y descomente la línea que agrega Pusher al pipeline:
# components.append(pusher)
Verificar las salidas de la tubería
Para Kubeflow Orchestrator, visite el panel de KFP y busque resultados de canalización en la página para la ejecución de su canalización. Haga clic en la pestaña "Experimentos" a la izquierda y en "Todas las ejecuciones" en la página Experimentos. Debería poder encontrar la ejecución con el nombre de su canalización.
Destinos de implementación disponibles
Ya ha entrenado y validado su modelo y su modelo ya está listo para producción. Ahora puede implementar su modelo en cualquiera de los objetivos de implementación de TensorFlow, incluidos:
- TensorFlow Serving , para servir su modelo en un servidor o granja de servidores y procesar solicitudes de inferencia REST y/o gRPC.
- TensorFlow Lite , para incluir tu modelo en una aplicación móvil nativa de Android o iOS, o en una aplicación Raspberry Pi, IoT o microcontrolador.
- TensorFlow.js , para ejecutar su modelo en un navegador web o aplicación Node.JS.
Ejemplos más avanzados
El ejemplo presentado anteriormente en realidad sólo pretende ayudarle a empezar. A continuación se muestran algunos ejemplos de integración con otros servicios en la nube.
Consideraciones sobre los recursos de Kubeflow Pipelines
Dependiendo de los requisitos de su carga de trabajo, la configuración predeterminada para su implementación de Kubeflow Pipelines puede satisfacer o no sus necesidades. Puede personalizar sus configuraciones de recursos usando pipeline_operator_funcs en su llamada a KubeflowDagRunnerConfig .
pipeline_operator_funcs es una lista de elementos OpFunc , que transforma todas las instancias ContainerOp generadas en la especificación de canalización de KFP que se compila a partir de KubeflowDagRunner .
Por ejemplo, para configurar la memoria podemos usar set_memory_request para declarar la cantidad de memoria necesaria. Una forma típica de hacerlo es crear un contenedor para set_memory_request y usarlo para agregarlo a la lista de OpFunc de canalización:
def request_more_memory():
def _set_memory_spec(container_op):
container_op.set_memory_request('32G')
return _set_memory_spec
# Then use this opfunc in KubeflowDagRunner
pipeline_op_funcs = kubeflow_dag_runner.get_default_pipeline_operator_funcs()
pipeline_op_funcs.append(request_more_memory())
config = KubeflowDagRunnerConfig(
pipeline_operator_funcs=pipeline_op_funcs,
...
)
kubeflow_dag_runner.KubeflowDagRunner(config=config).run(pipeline)
Funciones de configuración de recursos similares incluyen:
-
set_memory_limit -
set_cpu_request -
set_cpu_limit -
set_gpu_limit
Prueba BigQueryExampleGen
BigQuery es un almacén de datos en la nube sin servidor, altamente escalable y rentable. BigQuery se puede utilizar como fuente de ejemplos de capacitación en TFX. En este paso, agregaremos BigQueryExampleGen a la canalización.
En el editor de archivos de laboratorio de Jupyter:
Haga doble clic para abrir pipeline.py . Comente CsvExampleGen y descomente la línea que crea una instancia de BigQueryExampleGen . También es necesario descomentar el argumento query de la función create_pipeline .
Necesitamos especificar qué proyecto de GCP usar para BigQuery, y esto se hace configurando --project en beam_pipeline_args al crear una canalización.
Haga doble clic para abrir configs.py . Descomente la definición de BIG_QUERY_WITH_DIRECT_RUNNER_BEAM_PIPELINE_ARGS y BIG_QUERY_QUERY . Debes reemplazar la identificación del proyecto y el valor de la región en este archivo con los valores correctos para tu proyecto de GCP.
Cambie el directorio un nivel hacia arriba. Haga clic en el nombre del directorio encima de la lista de archivos. El nombre del directorio es el nombre de la canalización, que es my_pipeline si no cambió el nombre de la canalización.
Haga doble clic para abrir kubeflow_runner.py . Descomente dos argumentos, query y beam_pipeline_args , para la función create_pipeline .
Ahora la canalización está lista para usar BigQuery como fuente de ejemplo. Actualice la canalización como antes y cree una nueva ejecución como hicimos en los pasos 5 y 6.
Actualice la canalización y vuelva a ejecutarla
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
Pruebe el flujo de datos
Varios componentes TFX utilizan Apache Beam para implementar canalizaciones de datos paralelas, lo que significa que puede distribuir cargas de trabajo de procesamiento de datos mediante Google Cloud Dataflow . En este paso, configuraremos el orquestador de Kubeflow para que utilice Dataflow como back-end de procesamiento de datos para Apache Beam.
# Select your project:
gcloud config set project YOUR_PROJECT_ID
# Get a list of services that you can enable in your project:
gcloud services list --available | grep Dataflow
# If you don't see dataflow.googleapis.com listed, that means you haven't been
# granted access to enable the Dataflow API. See your account adminstrator.
# Enable the Dataflow service:
gcloud services enable dataflow.googleapis.com
Haga doble clic pipeline para cambiar de directorio y haga doble clic para abrir configs.py . Descomente la definición de GOOGLE_CLOUD_REGION y DATAFLOW_BEAM_PIPELINE_ARGS .
Cambie el directorio un nivel hacia arriba. Haga clic en el nombre del directorio encima de la lista de archivos. El nombre del directorio es el nombre de la tubería, que es my_pipeline si no la cambió.
Haga doble clic para abrir kubeflow_runner.py . Descomentar beam_pipeline_args . (También asegúrese de comentar beam_pipeline_args actuales que agregó en el Paso 7).
Actualice la canalización y vuelva a ejecutarla
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
Puedes encontrar tus trabajos de Dataflow en Dataflow en Cloud Console .
Pruebe el entrenamiento y predicción de Cloud AI Platform con KFP
TFX interopera con varios servicios administrados de GCP, como Cloud AI Platform for Training and Prediction . Puede configurar su componente Trainer para que utilice Cloud AI Platform Training, un servicio administrado para entrenar modelos de ML. Además, cuando su modelo esté construido y listo para ser servido, puede enviarlo a Cloud AI Platform Prediction para su entrega. En este paso, configuraremos nuestro componente Trainer y Pusher para utilizar los servicios de Cloud AI Platform.
Antes de editar archivos, es posible que primero tengas que habilitar la API de predicción y entrenamiento de AI Platform .
Haga doble clic pipeline para cambiar de directorio y haga doble clic para abrir configs.py . Descomente la definición de GOOGLE_CLOUD_REGION , GCP_AI_PLATFORM_TRAINING_ARGS y GCP_AI_PLATFORM_SERVING_ARGS . Usaremos nuestra imagen de contenedor personalizada para entrenar un modelo en Cloud AI Platform Training, por lo que debemos configurar masterConfig.imageUri en GCP_AI_PLATFORM_TRAINING_ARGS con el mismo valor que CUSTOM_TFX_IMAGE arriba.
Cambie el directorio un nivel hacia arriba y haga doble clic para abrir kubeflow_runner.py . Descomente ai_platform_training_args y ai_platform_serving_args .
Actualice la canalización y vuelva a ejecutarla
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
Puedes encontrar tus trabajos de formación en Cloud AI Platform Jobs . Si su canalización se completó correctamente, puede encontrar su modelo en Modelos de plataforma de IA en la nube .
14. Utiliza tus propios datos
En este tutorial, creó una canalización para un modelo utilizando el conjunto de datos de Chicago Taxi. Ahora intente poner sus propios datos en la canalización. Sus datos se pueden almacenar en cualquier lugar al que la canalización pueda acceder, incluidos Google Cloud Storage, BigQuery o archivos CSV.
Debe modificar la definición de la canalización para adaptarla a sus datos.
Si sus datos se almacenan en archivos
- Modifique
DATA_PATHenkubeflow_runner.py, indicando la ubicación.
Si tus datos se almacenan en BigQuery
- Modifique
BIG_QUERY_QUERYen configs.py a su declaración de consulta. - Agregue funciones en
models/features.py. - Modifique
models/preprocessing.pypara transformar los datos de entrada para el entrenamiento . - Modifique
models/keras/model.pyymodels/keras/constants.pypara describir su modelo de ML .
Más información sobre el entrenador
Consulte la guía de componentes de Trainer para obtener más detalles sobre los canales de capacitación.
limpiando
Para limpiar todos los recursos de Google Cloud utilizados en este proyecto, puede eliminar el proyecto de Google Cloud que utilizó para el tutorial.
Alternativamente, puede limpiar recursos individuales visitando cada consola: - Google Cloud Storage - Google Container Registry - Google Kubernetes Engine