
מָבוֹא
מדריך זה נועד להציג את TensorFlow Extended (TFX) ו- AIPlatform Pipelines , ולעזור לך ללמוד ליצור צינורות למידת מכונה משלך ב-Google Cloud. זה מציג אינטגרציה עם TFX, AI Platform Pipelines ו-Kubeflow, כמו גם אינטראקציה עם TFX במחברות של Jupyter.
בסוף מדריך זה, תיצור ותפעיל צינור ML, המתארח ב-Google Cloud. תוכל לדמיין את התוצאות של כל ריצה, ולראות את השושלת של החפצים שנוצרו.
אתה תעקוב אחר תהליך פיתוח ML טיפוסי, החל מבדיקת מערך הנתונים, וכלה בצינור עבודה שלם. לאורך הדרך תחקור דרכים לנפות באגים ולעדכן את הצינור שלך, ולמדוד ביצועים.
ערכת נתונים של שיקגו מוניות


אתה משתמש במערך הנתונים של Taxi Trips שפורסם על ידי עיריית שיקגו.
תוכל לקרוא עוד על מערך הנתונים ב- Google BigQuery . חקור את מערך הנתונים המלא בממשק המשתמש של BigQuery .
יעד מודל - סיווג בינארי
האם הלקוח טיפ יותר או פחות מ-20%?
1. הגדר פרויקט של Google Cloud
1.א הגדר את הסביבה שלך ב-Google Cloud
כדי להתחיל, אתה צריך חשבון Google Cloud. אם כבר יש לך אחד, דלג קדימה ליצירת פרויקט חדש .
עבור אל Google Cloud Console .
הסכים לתנאים ולהגבלות של Google Cloud

אם תרצה להתחיל עם חשבון ניסיון בחינם, לחץ על נסה בחינם (או התחל בחינם ).
בחר את המדינה שלך.
הסכים לתנאי השירות.
הזן פרטי חיוב.
לא תחויב בשלב זה. אם אין לך פרויקטים אחרים של Google Cloud, תוכל להשלים מדריך זה מבלי לחרוג ממגבלות Google Cloud Free Tier , הכוללות מקסימום 8 ליבות הפועלות בו-זמנית.
1.ב צור פרויקט חדש.
- ממרכז השליטה הראשי של Google Cloud , לחץ על התפריט הנפתח של הפרויקט לצד הכותרת של Google Cloud Platform ובחר פרויקט חדש .
- תן לפרויקט שלך שם והזן פרטי פרויקט אחרים
- לאחר שיצרת פרויקט, הקפד לבחור אותו מהתפריט הנפתח של הפרויקט.
2. הגדר ופריסה של צינור AI Platform על אשכול Kubernetes חדש
עבור לדף AI Platform Pipelines Clusters .
תחת תפריט הניווט הראשי: ≡ > פלטפורמת AI > Pipelines
לחץ על + מופע חדש כדי ליצור אשכול חדש.

בדף הסקירה הכללית של Kubeflow Pipelines , לחץ על הגדר .

לחץ על "הפעל" כדי להפעיל את Kubernetes Engine API
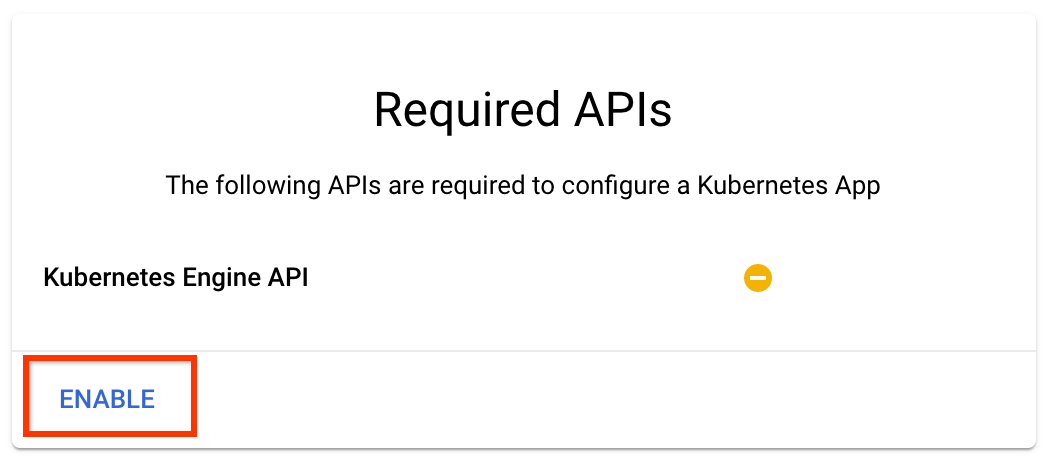
בדף פריסת צינורות Kubeflow :
בחר אזור (או "אזור") עבור האשכול שלך. ניתן להגדיר את הרשת ואת רשת המשנה, אך למטרות הדרכה זו נשאיר אותן כברירת מחדל.
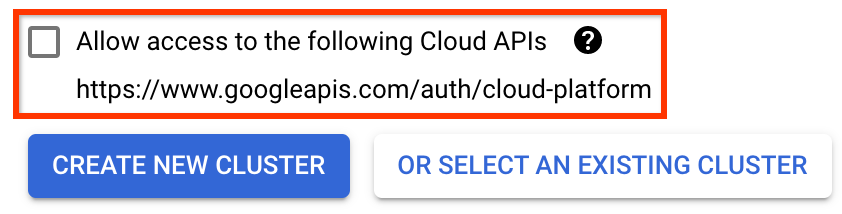
חשוב סמן את התיבה שכותרתה אפשר גישה לממשקי API הענן הבאים . (זה נדרש כדי שהאשכול הזה יוכל לגשת לחלקים האחרים של הפרויקט שלך. אם פספסת את השלב הזה, תיקון זה מאוחר יותר הוא קצת מסובך).
לחץ על צור אשכול חדש והמתן מספר דקות עד שהאשכול נוצר. זה ייקח כמה דקות. כשזה יסתיים תראה הודעה כמו:
אשכול "אשכול-1" נוצר בהצלחה באזור "us-central1-a".
בחר מרחב שמות ושם מופע (שימוש בברירות המחדל הוא בסדר). למטרות מדריך זה אל תבדוק את executor.emissary או managedstorage.enabled .
לחץ על 'פרוס' והמתן מספר רגעים עד שהצינור יתבצע. על ידי פריסת Kubeflow Pipelines, אתה מקבל את התנאים וההגבלות.
3. הגדר מופע Cloud AI Platform Notebook.
עבור לדף Vertex AI Workbench . בפעם הראשונה שתפעיל את Workbench תצטרך להפעיל את ה-API של Notebooks.
תחת תפריט הניווט הראשי: ≡ -> Vertex AI -> Workbench
אם תתבקש, הפעל את Compute Engine API.
צור מחברת חדשה עם TensorFlow Enterprise 2.7 (או למעלה) מותקן.

מחברת חדשה -> TensorFlow Enterprise 2.7 -> ללא GPU
בחר אזור ואזור, ותן למופע המחברת שם.
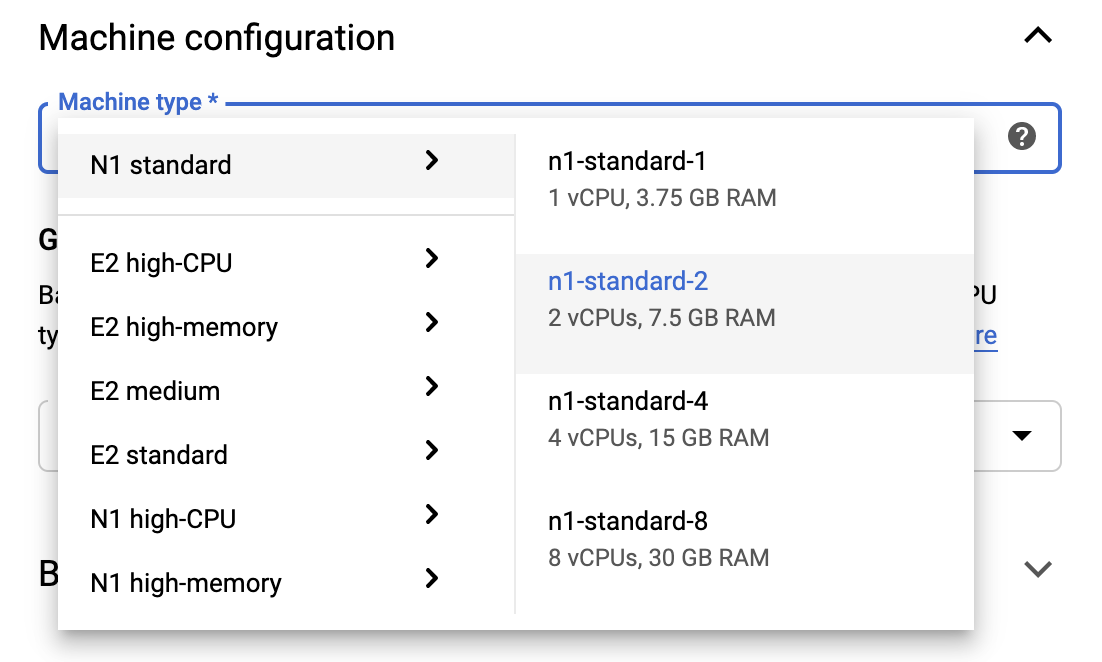
כדי להישאר בגבולות ה-Free Tier, ייתכן שיהיה עליך לשנות את הגדרות ברירת המחדל כאן כדי לצמצם את מספר ה-vCPUs הזמינים למופע זה מ-4 ל-2:
- בחר אפשרויות מתקדמות בתחתית טופס המחברת החדשה .
תחת תצורת מכונה, ייתכן שתרצה לבחור תצורה עם 1 או 2 vCPUs אם אתה צריך להישאר בשכבה החינמית.
המתן עד שהמחברת החדשה תיווצר, ולאחר מכן לחץ על Enable Notebooks API
4. הפעל את מחברת התחלת העבודה
עבור לדף AI Platform Pipelines Clusters .
תחת תפריט הניווט הראשי: ≡ -> AI Platform -> Pipelines
בשורה של האשכול שבו אתה משתמש במדריך זה, לחץ על פתח את לוח המחוונים של צינורות .

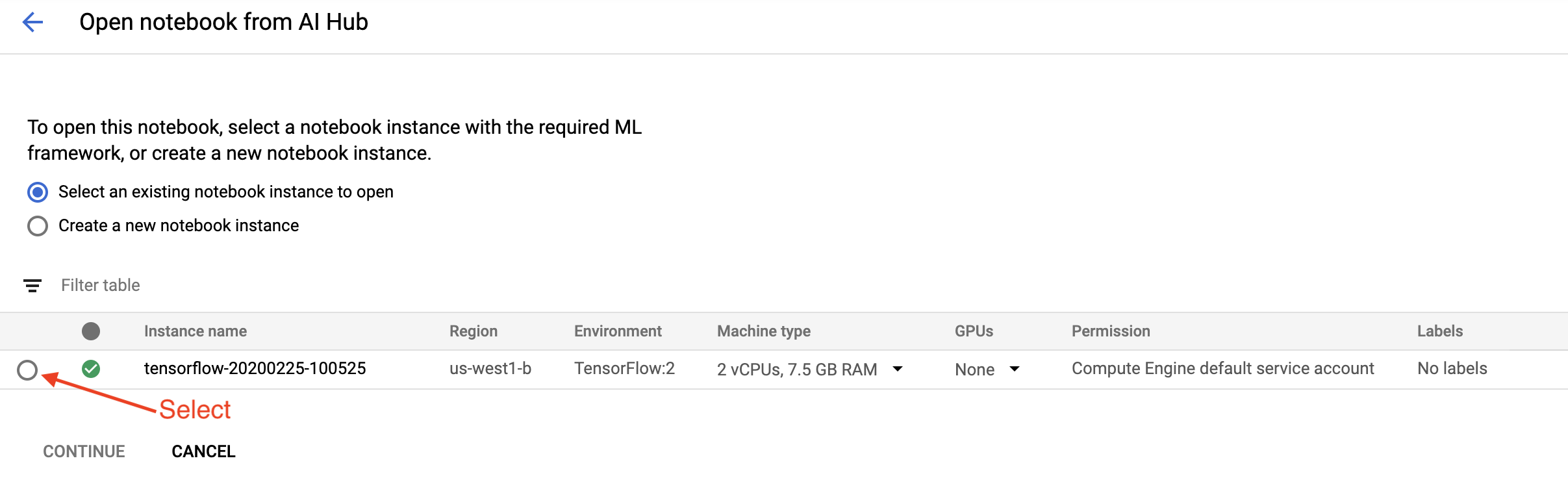
בדף תחילת העבודה , לחץ על פתח מחברת Cloud AI Platform ב-Google Cloud .

בחר את המופע של Notebook שבו אתה משתמש עבור מדריך זה והמשך , ולאחר מכן אשר .
5. המשך לעבוד במחברת
לְהַתְקִין
ה-Getting Started Notebook מתחיל בהתקנת TFX ו- Kubeflow Pipelines (KFP) ב-VM שבו פועלת Jupyter Lab.
לאחר מכן הוא בודק איזו גרסה של TFX מותקנת, מבצע ייבוא ומגדיר ומדפיס את מזהה הפרויקט:

התחבר לשירותי Google Cloud שלך
תצורת הצינור צריכה את מזהה הפרויקט שלך, אותו תוכל לקבל דרך המחברת ולהגדיר כמשתנה סביבתי.
# Read GCP project id from env.
shell_output=!gcloud config list --format 'value(core.project)' 2>/dev/null
GCP_PROJECT_ID=shell_output[0]
print("GCP project ID:" + GCP_PROJECT_ID)
כעת הגדר את נקודת הקצה של אשכול KFP שלך.
ניתן למצוא זאת מכתובת ה-URL של לוח המחוונים Pipelines. עבור אל לוח המחוונים של Kubeflow Pipeline והסתכל על כתובת האתר. נקודת הקצה היא כל מה שבכתובת האתר מתחיל ב- https:// , עד וכולל googleusercontent.com .
ENDPOINT='' # Enter YOUR ENDPOINT here.
לאחר מכן, המחברת מגדירה שם ייחודי לתמונת Docker המותאמת אישית:
# Docker image name for the pipeline image
CUSTOM_TFX_IMAGE='gcr.io/' + GCP_PROJECT_ID + '/tfx-pipeline'
6. העתק תבנית לספריית הפרויקט שלך
ערוך את התא הבא של המחברת כדי להגדיר שם לצינור שלך. במדריך זה נשתמש my_pipeline .
PIPELINE_NAME="my_pipeline"
PROJECT_DIR=os.path.join(os.path.expanduser("~"),"imported",PIPELINE_NAME)
לאחר מכן, המחברת משתמשת ב- tfx CLI כדי להעתיק את תבנית הצינור. מדריך זה משתמש במערך הנתונים של Chicago Taxi כדי לבצע סיווג בינארי, כך שהתבנית מגדירה את המודל taxi :
!tfx template copy \
--pipeline-name={PIPELINE_NAME} \
--destination-path={PROJECT_DIR} \
--model=taxi
לאחר מכן, המחברת משנה את הקשר CWD שלה לספריית הפרויקט:
%cd {PROJECT_DIR}
עיין בקבצי הצינור
בצד שמאל של ה-Cloud AI Platform Notebook, אתה אמור לראות דפדפן קבצים. צריכה להיות ספרייה עם שם הצינור שלך ( my_pipeline ). פתח אותו והצג את הקבצים. (תוכל לפתוח אותם ולערוך גם מסביבת המחברת.)
# You can also list the files from the shellls
פקודת tfx template copy למעלה יצרה פיגום בסיסי של קבצים הבונים צינור. אלה כוללים קודי מקור של Python, נתונים לדוגמה ומחברות Jupyter. אלה נועדו לדוגמא הספציפית הזו. עבור הצינורות שלך, אלו יהיו הקבצים התומכים שהצינור שלך דורש.
להלן תיאור קצר של קבצי Python.
-
pipeline- ספרייה זו מכילה את ההגדרה של הצינור-
configs.py- מגדיר קבועים נפוצים עבור רצי צינורות -
pipeline.py- מגדיר רכיבי TFX וצינור
-
-
models- ספרייה זו מכילה הגדרות מודל ML.-
features.pyfeatures_test.py- מגדיר תכונות עבור הדגם -
preprocessing.py/preprocessing_test.py- מגדיר עבודות עיבוד מקדים באמצעותtf::Transform -
estimator- ספרייה זו מכילה מודל מבוסס הערכה.-
constants.py- מגדיר קבועים של המודל -
model.py/model_test.py- מגדיר מודל DNN באמצעות מעריך TF
-
-
keras- ספרייה זו מכילה מודל מבוסס Keras.-
constants.py- מגדיר קבועים של המודל -
model.py/model_test.py- מגדיר מודל DNN באמצעות Keras
-
-
-
beam_runner.py/kubeflow_runner.py- הגדר רצים עבור כל מנוע תזמור
7. הפעל את צינור ה-TFX הראשון שלך ב-Kubeflow
המחברת תפעיל את הצינור באמצעות פקודת tfx run CLI.
התחבר לאחסון
צינורות פועלים יוצרים חפצים שיש לאחסן ב- ML-Metadata . חפצים מתייחסים למטענים, שהם קבצים שיש לאחסן במערכת קבצים או לחסום אחסון. עבור מדריך זה, נשתמש ב-GCS כדי לאחסן את עומסי המטא נתונים שלנו, באמצעות הדלי שנוצר באופן אוטומטי במהלך ההגדרה. השם שלו יהיה <your-project-id>-kubeflowpipelines-default .
צור את הצינור
המחברת תעלה את נתוני הדוגמאות שלנו ל-GCS bucket כדי שנוכל להשתמש בהם בצינור שלנו מאוחר יותר.
gsutil cp data/data.csv gs://{GOOGLE_CLOUD_PROJECT}-kubeflowpipelines-default/tfx-template/data/taxi/data.csv לאחר מכן, המחברת משתמשת בפקודה tfx pipeline create כדי ליצור את הצינור.
!tfx pipeline create \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT} \
--build-image
בזמן יצירת צינור, Dockerfile ייווצר כדי לבנות תמונת Docker. אל תשכח להוסיף את הקבצים האלה למערכת בקרת המקור שלך (לדוגמה, git) יחד עם קבצי מקור אחרים.
הפעל את הצינור
לאחר מכן, המחברת משתמשת בפקודה tfx run create כדי להתחיל ריצת ביצוע של הצינור שלך. אתה גם תראה את הריצה הזו ברשימה תחת ניסויים בלוח המחוונים של Kubeflow Pipelines.
tfx run create --pipeline-name={PIPELINE_NAME} --endpoint={ENDPOINT}אתה יכול להציג את הצינור שלך מלוח המחוונים של Kubeflow Pipelines.
8. אמת את הנתונים שלך
המשימה הראשונה בכל פרויקט מדעי נתונים או ML היא להבין ולנקות את הנתונים.
- הבן את סוגי הנתונים עבור כל תכונה
- חפש חריגות וערכים חסרים
- הבן את ההפצות עבור כל תכונה
רכיבים


- ExampleGen בולע ומפצל את מערך הנתונים של הקלט.
- StatisticsGen מחשב נתונים סטטיסטיים עבור מערך הנתונים.
- SchemaGen SchemaGen בוחנת את הסטטיסטיקה ויוצרת סכימת נתונים.
- ExampleValidator מחפש חריגות וערכים חסרים במערך הנתונים.
בעורך הקבצים של Jupyter Lab:
ב- pipeline / pipeline.py , בטל את ההערה לשורות שמצרפות את הרכיבים האלה לצינור שלך:
# components.append(statistics_gen)
# components.append(schema_gen)
# components.append(example_validator)
( ExampleGen כבר הופעל כאשר קובצי התבנית הועתקו.)
עדכן את הצינור והפעל אותו מחדש
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
בדוק את הצינור
עבור Kubeflow Orchestrator, בקר בלוח המחוונים של KFP ומצא פלטי צינור בדף עבור הפעלת הצינור שלך. לחץ על הכרטיסייה "ניסויים" בצד ימין, ועל "כל הריצות" בדף הניסויים. אתה אמור להיות מסוגל למצוא את הריצה עם שם הצינור שלך.
דוגמה מתקדמת יותר
הדוגמה המוצגת כאן נועדה למעשה רק כדי להתחיל. לדוגמא מתקדמת יותר, עיין ב- TensorFlow Data Validation Colab .
למידע נוסף על שימוש ב-TFDV כדי לחקור ולאמת מערך נתונים, עיין בדוגמאות באתר tensorflow.org .
9. הנדסת תכונות
אתה יכול להגדיל את איכות הניבוי של הנתונים שלך ו/או להפחית את הממדיות עם הנדסת תכונות.
- צלבי תכונה
- אוצר מילים
- הטבעות
- PCA
- קידוד קטגורי
אחד היתרונות של שימוש ב-TFX הוא שאתה תכתוב את קוד הטרנספורמציה שלך פעם אחת, והשינויים שיתקבלו יהיו עקביים בין אימון להגשה.
רכיבים

- Transform מבצעת הנדסת תכונות במערך הנתונים.
בעורך הקבצים של Jupyter Lab:
ב- pipeline / pipeline.py , מצא ובטל את ההערה של השורה שמצרפת את Transform לצינור.
# components.append(transform)
עדכן את הצינור והפעל אותו מחדש
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
בדוק את תפוקות הצינור
עבור Kubeflow Orchestrator, בקר בלוח המחוונים של KFP ומצא פלטי צינור בדף עבור הפעלת הצינור שלך. לחץ על הכרטיסייה "ניסויים" בצד ימין, ועל "כל הריצות" בדף הניסויים. אתה אמור להיות מסוגל למצוא את הריצה עם שם הצינור שלך.
דוגמה מתקדמת יותר
הדוגמה המוצגת כאן נועדה למעשה רק כדי להתחיל. לדוגמא מתקדמת יותר, עיין ב- TensorFlow Transform Colab .
10. הדרכה
אימון מודל TensorFlow עם הנתונים הנחמדים, הנקיים, שעברו טרנספורמציה.
- כלול את התמורות מהשלב הקודם כך שיושמו באופן עקבי
- שמור את התוצאות בתור SavedModel לייצור
- הדמיין וחקור את תהליך האימון באמצעות TensorBoard
- שמור גם EvalSavedModel לניתוח ביצועי המודל
רכיבים
- מאמן מאמן דגם TensorFlow.
בעורך הקבצים של Jupyter Lab:
ב- pipeline / pipeline.py , מצא ובטל את ההערה שמצרף את המאמן לצינור:
# components.append(trainer)
עדכן את הצינור והפעל אותו מחדש
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
בדוק את תפוקות הצינור
עבור Kubeflow Orchestrator, בקר בלוח המחוונים של KFP ומצא פלטי צינור בדף עבור הפעלת הצינור שלך. לחץ על הכרטיסייה "ניסויים" בצד ימין, ועל "כל הריצות" בדף הניסויים. אתה אמור להיות מסוגל למצוא את הריצה עם שם הצינור שלך.
דוגמה מתקדמת יותר
הדוגמה המוצגת כאן נועדה למעשה רק כדי להתחיל. לדוגמא מתקדמת יותר, עיין במדריך של TensorBoard .
11. ניתוח ביצועי המודל
הבנת יותר מסתם המדדים ברמה העליונה.
- משתמשים חווים ביצועי מודל עבור השאילתות שלהם בלבד
- ביצועים גרועים בפרוסות נתונים יכולים להיות מוסתרים על ידי מדדים ברמה העליונה
- הוגנות המודל חשובה
- לעתים קרובות תת-קבוצות מפתח של משתמשים או נתונים חשובות מאוד, ועשויות להיות קטנות
- ביצועים בתנאים קריטיים אך יוצאי דופן
- ביצועים לקהלי מפתח כגון משפיענים
- אם אתה מחליף דגם שנמצא כעת בייצור, תחילה ודא שהחדש טוב יותר
רכיבים
- Evaluator מבצע ניתוח מעמיק של תוצאות האימון.
בעורך הקבצים של Jupyter Lab:
ב- pipeline / pipeline.py , מצא ובטל את ההערה של השורה שמצרפת את Evaluator לצינור:
components.append(evaluator)
עדכן את הצינור והפעל אותו מחדש
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
בדוק את תפוקות הצינור
עבור Kubeflow Orchestrator, בקר בלוח המחוונים של KFP ומצא פלטי צינור בדף עבור הפעלת הצינור שלך. לחץ על הכרטיסייה "ניסויים" בצד ימין, ועל "כל הריצות" בדף הניסויים. אתה אמור להיות מסוגל למצוא את הריצה עם שם הצינור שלך.
12. הגשת הדגם
אם הדגם החדש מוכן, הפוך אותו כך.
- Pusher פורס את SavedModels למיקומים ידועים
יעדי פריסה מקבלים דגמים חדשים ממקומות ידועים
- הגשה של TensorFlow
- TensorFlow Lite
- TensorFlow JS
- TensorFlow Hub
רכיבים
- Pusher פורס את המודל לתשתית שירות.
בעורך הקבצים של Jupyter Lab:
ב- pipeline / pipeline.py , מצא ובטל את ההערה של השורה שמצרפת את Pusher לצינור:
# components.append(pusher)
בדוק את תפוקות הצינור
עבור Kubeflow Orchestrator, בקר בלוח המחוונים של KFP ומצא פלטי צינור בדף עבור הפעלת הצינור שלך. לחץ על הכרטיסייה "ניסויים" בצד ימין, ועל "כל הריצות" בדף הניסויים. אתה אמור להיות מסוגל למצוא את הריצה עם שם הצינור שלך.
יעדי פריסה זמינים
כעת אימנת ואימתת את הדגם שלך, והדגם שלך מוכן כעת לייצור. כעת תוכל לפרוס את המודל שלך לכל אחד מיעדי הפריסה של TensorFlow, כולל:
- TensorFlow Serving , להגשת המודל שלך בשרת או בחוות שרתים ועיבוד בקשות מסקנות REST ו/או gRPC.
- TensorFlow Lite , עבור הכללת הדגם שלך באפליקציה סלולרית מקורית של אנדרואיד או iOS, או באפליקציית Raspberry Pi, IoT או מיקרו-בקר.
- TensorFlow.js , להפעלת הדגם שלך בדפדפן אינטרנט או ביישום Node.JS.
דוגמאות מתקדמות יותר
הדוגמה שהוצגה לעיל נועדה למעשה רק כדי להתחיל. להלן כמה דוגמאות לאינטגרציה עם שירותי ענן אחרים.
שיקולי משאבים של Kubeflow Pipelines
בהתאם לדרישות של עומס העבודה שלך, תצורת ברירת המחדל עבור פריסת ה-Kubeflow Pipelines שלך עשויה לענות על הצרכים שלך או לא. אתה יכול להתאים אישית את תצורות המשאבים שלך באמצעות pipeline_operator_funcs בקריאה שלך אל KubeflowDagRunnerConfig .
pipeline_operator_funcs היא רשימה של פריטי OpFunc , אשר הופכת את כל מופעי ContainerOp שנוצרו במפרט הצינור של KFP אשר מורכב מ- KubeflowDagRunner .
לדוגמה, כדי להגדיר זיכרון נוכל להשתמש ב- set_memory_request כדי להצהיר על כמות הזיכרון הדרושה. דרך טיפוסית לעשות זאת היא ליצור עטיפה עבור set_memory_request ולהשתמש בו כדי להוסיף לרשימת ה- OpFunc של הצינור:
def request_more_memory():
def _set_memory_spec(container_op):
container_op.set_memory_request('32G')
return _set_memory_spec
# Then use this opfunc in KubeflowDagRunner
pipeline_op_funcs = kubeflow_dag_runner.get_default_pipeline_operator_funcs()
pipeline_op_funcs.append(request_more_memory())
config = KubeflowDagRunnerConfig(
pipeline_operator_funcs=pipeline_op_funcs,
...
)
kubeflow_dag_runner.KubeflowDagRunner(config=config).run(pipeline)
פונקציות תצורת משאבים דומות כוללות:
-
set_memory_limit -
set_cpu_request -
set_cpu_limit -
set_gpu_limit
נסה BigQueryExampleGen
BigQuery הוא מחסן נתונים בענן חסר שרתים, ניתן להרחבה וחסכוני. ניתן להשתמש ב-BigQuery כמקור לדוגמאות הדרכה ב-TFX. בשלב זה, נוסיף BigQueryExampleGen לצינור.
בעורך הקבצים של Jupyter Lab:
לחץ פעמיים כדי לפתוח pipeline.py . שים לב ל- CsvExampleGen ובטל את ההערה לשורה שיוצרת מופע של BigQueryExampleGen . עליך גם לבטל את ההערה query של הפונקציה create_pipeline .
עלינו לציין באיזה פרויקט GCP להשתמש עבור BigQuery, וזה נעשה על ידי הגדרת --project ב- beam_pipeline_args בעת יצירת צינור.
לחץ פעמיים כדי לפתוח configs.py . בטל את ההערה להגדרה של BIG_QUERY_WITH_DIRECT_RUNNER_BEAM_PIPELINE_ARGS ו- BIG_QUERY_QUERY . עליך להחליף את מזהה הפרויקט ואת ערך האזור בקובץ זה בערכים הנכונים עבור פרויקט ה-GCP שלך.
שנה ספרייה רמה אחת למעלה. לחץ על שם הספרייה מעל רשימת הקבצים. שם הספרייה הוא שם הצינור שהוא my_pipeline אם לא שינית את שם הצינור.
לחץ פעמיים כדי לפתוח kubeflow_runner.py . בטל הערות לשני ארגומנטים, query ו- beam_pipeline_args , עבור הפונקציה create_pipeline .
כעת הצינור מוכן להשתמש ב-BigQuery כמקור לדוגמה. עדכן את הצינור כמו קודם וצור ריצת הפעלה חדשה כפי שעשינו בשלב 5 ו-6.
עדכן את הצינור והפעל אותו מחדש
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
נסה את Dataflow
מספר רכיבי TFX משתמשים ב-Apache Beam כדי ליישם צינורות מקבילים לנתונים, וזה אומר שאתה יכול להפיץ עומסי עבודה של עיבוד נתונים באמצעות Google Cloud Dataflow . בשלב זה, נגדיר את מתזמר Kubeflow להשתמש ב-Dataflow כחלק האחורי של עיבוד הנתונים עבור Apache Beam.
# Select your project:
gcloud config set project YOUR_PROJECT_ID
# Get a list of services that you can enable in your project:
gcloud services list --available | grep Dataflow
# If you don't see dataflow.googleapis.com listed, that means you haven't been
# granted access to enable the Dataflow API. See your account adminstrator.
# Enable the Dataflow service:
gcloud services enable dataflow.googleapis.com
לחץ פעמיים pipeline כדי לשנות ספרייה, ולחץ פעמיים כדי לפתוח configs.py . בטל את ההערה להגדרה של GOOGLE_CLOUD_REGION ו- DATAFLOW_BEAM_PIPELINE_ARGS .
שנה ספרייה רמה אחת למעלה. לחץ על שם הספרייה מעל רשימת הקבצים. שם הספרייה הוא שם הצינור שהוא my_pipeline אם לא שינית.
לחץ פעמיים כדי לפתוח kubeflow_runner.py . בטל הערה beam_pipeline_args . (כמו כן הקפד להגיב על beam_pipeline_args נוכחיים שהוספת בשלב 7.)
עדכן את הצינור והפעל אותו מחדש
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
אתה יכול למצוא את משרות ה-Dataflow שלך ב- Dataflow ב-Cloud Console .
נסה הדרכה וחיזוי פלטפורמת AI בענן עם KFP
TFX פועלת יחד עם מספר שירותי GCP מנוהלים, כגון Cloud AI Platform for Training and Prediction . אתה יכול להגדיר את רכיב Trainer שלך לשימוש ב-Cloud AI Platform Training, שירות מנוהל לאימון מודלים של ML. יתרה מכך, כאשר הדגם שלך בנוי ומוכן להגשה, אתה יכול לדחוף את המודל שלך ל-Cloud AI Platform Prediction לצורך הגשה. בשלב זה, נגדיר את רכיב Trainer וה- Pusher שלנו לשימוש בשירותי Cloud AI Platform.
לפני עריכת קבצים, ייתכן שתצטרך להפעיל תחילה AI Platform Training & Prediction API .
לחץ פעמיים pipeline כדי לשנות ספרייה, ולחץ פעמיים כדי לפתוח configs.py . בטל את ההערה להגדרה של GOOGLE_CLOUD_REGION , GCP_AI_PLATFORM_TRAINING_ARGS ו- GCP_AI_PLATFORM_SERVING_ARGS . אנו נשתמש בתמונת המיכל הבנויה בהתאמה אישית כדי להכשיר מודל ב-Cloud AI Platform Training, לכן עלינו להגדיר masterConfig.imageUri ב- GCP_AI_PLATFORM_TRAINING_ARGS לאותו ערך כמו CUSTOM_TFX_IMAGE לעיל.
שנה את הספרייה רמה אחת למעלה ולחץ פעמיים כדי לפתוח kubeflow_runner.py . בטל הערות ai_platform_training_args ו- ai_platform_serving_args .
עדכן את הצינור והפעל אותו מחדש
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
אתה יכול למצוא את משרות ההדרכה שלך ב- Cloud AI Platform Jobs . אם הצינור שלך הושלם בהצלחה, תוכל למצוא את הדגם שלך ב- Cloud AI Platform Models .
14. השתמש בנתונים שלך
במדריך זה, יצרת צינור למודל באמצעות מערך הנתונים של Chicago Taxi. כעת נסה להכניס את הנתונים שלך לצינור. ניתן לאחסן את הנתונים שלך בכל מקום שבו הצינור יכול לגשת אליהם, כולל Google Cloud Storage, BigQuery או קובצי CSV.
עליך לשנות את הגדרת הצינור כדי להתאים לנתונים שלך.
אם הנתונים שלך מאוחסנים בקבצים
- שנה
DATA_PATHב-kubeflow_runner.py, תוך ציון המיקום.
אם הנתונים שלך מאוחסנים ב-BigQuery
- שנה
BIG_QUERY_QUERYב-configs.py להצהרת השאילתה שלך. - הוסף תכונות ב-
models/features.py. - שנה
models/preprocessing.pyכדי להפוך נתוני קלט להדרכה . - שנה
models/keras/model.pyואתmodels/keras/constants.pyכדי לתאר את מודל ה-ML שלך .
למידע נוסף על Trainer
ראה מדריך רכיבי מאמן לפרטים נוספים על צינורות הדרכה.
מנקים
כדי לנקות את כל המשאבים של Google Cloud המשמשים בפרויקט זה, אתה יכול למחוק את פרויקט Google Cloud שבו השתמשת עבור המדריך.
לחלופין, תוכל לנקות משאבים בודדים על ידי ביקור בכל אחת מהקונסולות: - Google Cloud Storage - Google Container Registry - Google Kubernetes Engine