
|
|
|
 View source on GitHub
View source on GitHub
|
|
This tutorial contains an introduction to word embeddings. You will train your own word embeddings using a simple Keras model for a sentiment classification task, and then visualize them in the Embedding Projector (shown in the image below).

Representing text as numbers
Machine learning models take vectors (arrays of numbers) as input. When working with text, the first thing you must do is come up with a strategy to convert strings to numbers (or to "vectorize" the text) before feeding it to the model. In this section, you will look at three strategies for doing so.
One-hot encodings
As a first idea, you might "one-hot" encode each word in your vocabulary. Consider the sentence "The cat sat on the mat". The vocabulary (or unique words) in this sentence is (cat, mat, on, sat, the). To represent each word, you will create a zero vector with length equal to the vocabulary, then place a one in the index that corresponds to the word. This approach is shown in the following diagram.
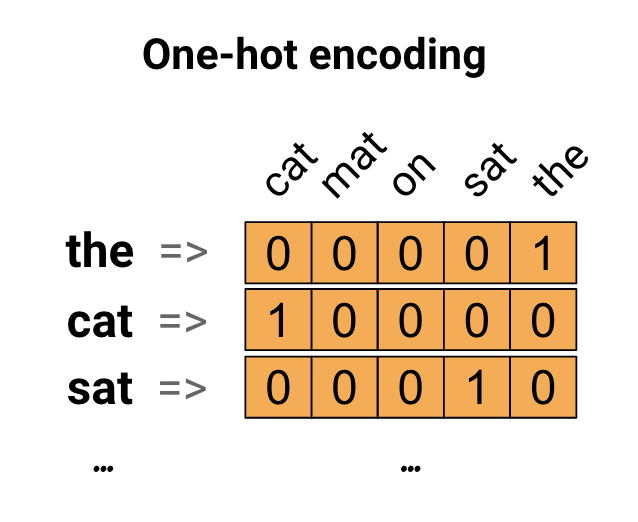
To create a vector that contains the encoding of the sentence, you could then concatenate the one-hot vectors for each word.
Encode each word with a unique number
A second approach you might try is to encode each word using a unique number. Continuing the example above, you could assign 1 to "cat", 2 to "mat", and so on. You could then encode the sentence "The cat sat on the mat" as a dense vector like [5, 1, 4, 3, 5, 2]. This approach is efficient. Instead of a sparse vector, you now have a dense one (where all elements are full).
There are two downsides to this approach, however:
The integer-encoding is arbitrary (it does not capture any relationship between words).
An integer-encoding can be challenging for a model to interpret. A linear classifier, for example, learns a single weight for each feature. Because there is no relationship between the similarity of any two words and the similarity of their encodings, this feature-weight combination is not meaningful.
Word embeddings
Word embeddings give us a way to use an efficient, dense representation in which similar words have a similar encoding. Importantly, you do not have to specify this encoding by hand. An embedding is a dense vector of floating point values (the length of the vector is a parameter you specify). Instead of specifying the values for the embedding manually, they are trainable parameters (weights learned by the model during training, in the same way a model learns weights for a dense layer). It is common to see word embeddings that are 8-dimensional (for small datasets), up to 1024-dimensions when working with large datasets. A higher dimensional embedding can capture fine-grained relationships between words, but takes more data to learn.
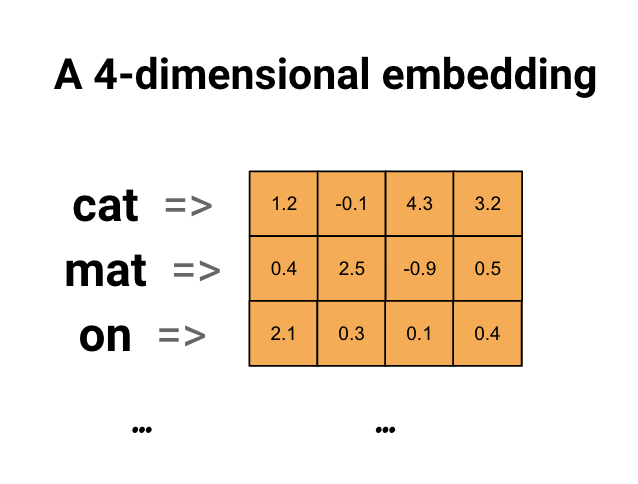
Above is a diagram for a word embedding. Each word is represented as a 4-dimensional vector of floating point values. Another way to think of an embedding is as "lookup table". After these weights have been learned, you can encode each word by looking up the dense vector it corresponds to in the table.
Setup
import io
import os
import re
import shutil
import string
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, Embedding, GlobalAveragePooling1D
from tensorflow.keras.layers import TextVectorization
2022-12-14 12:16:56.601690: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory 2022-12-14 12:16:56.601797: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory 2022-12-14 12:16:56.601808: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
Download the IMDb Dataset
You will use the Large Movie Review Dataset through the tutorial. You will train a sentiment classifier model on this dataset and in the process learn embeddings from scratch. To read more about loading a dataset from scratch, see the Loading text tutorial.
Download the dataset using Keras file utility and take a look at the directories.
url = "https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz"
dataset = tf.keras.utils.get_file("aclImdb_v1.tar.gz", url,
untar=True, cache_dir='.',
cache_subdir='')
dataset_dir = os.path.join(os.path.dirname(dataset), 'aclImdb')
os.listdir(dataset_dir)
Downloading data from https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz 84125825/84125825 [==============================] - 3s 0us/step ['test', 'imdb.vocab', 'README', 'train', 'imdbEr.txt']
Take a look at the train/ directory. It has pos and neg folders with movie reviews labelled as positive and negative respectively. You will use reviews from pos and neg folders to train a binary classification model.
train_dir = os.path.join(dataset_dir, 'train')
os.listdir(train_dir)
['pos', 'neg', 'unsupBow.feat', 'urls_pos.txt', 'unsup', 'urls_neg.txt', 'urls_unsup.txt', 'labeledBow.feat']
The train directory also has additional folders which should be removed before creating training dataset.
remove_dir = os.path.join(train_dir, 'unsup')
shutil.rmtree(remove_dir)
Next, create a tf.data.Dataset using tf.keras.utils.text_dataset_from_directory. You can read more about using this utility in this text classification tutorial.
Use the train directory to create both train and validation datasets with a split of 20% for validation.
batch_size = 1024
seed = 123
train_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train', batch_size=batch_size, validation_split=0.2,
subset='training', seed=seed)
val_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train', batch_size=batch_size, validation_split=0.2,
subset='validation', seed=seed)
Found 25000 files belonging to 2 classes. Using 20000 files for training. Found 25000 files belonging to 2 classes. Using 5000 files for validation.
Take a look at a few movie reviews and their labels (1: positive, 0: negative) from the train dataset.
for text_batch, label_batch in train_ds.take(1):
for i in range(5):
print(label_batch[i].numpy(), text_batch.numpy()[i])
0 b"Oh My God! Please, for the love of all that is holy, Do Not Watch This Movie! It it 82 minutes of my life I will never get back. Sure, I could have stopped watching half way through. But I thought it might get better. It Didn't. Anyone who actually enjoyed this movie is one seriously sick and twisted individual. No wonder us Australians/New Zealanders have a terrible reputation when it comes to making movies. Everything about this movie is horrible, from the acting to the editing. I don't even normally write reviews on here, but in this case I'll make an exception. I only wish someone had of warned me before I hired this catastrophe" 1 b'This movie is SOOOO funny!!! The acting is WONDERFUL, the Ramones are sexy, the jokes are subtle, and the plot is just what every high schooler dreams of doing to his/her school. I absolutely loved the soundtrack as well as the carefully placed cynicism. If you like monty python, You will love this film. This movie is a tad bit "grease"esk (without all the annoying songs). The songs that are sung are likable; you might even find yourself singing these songs once the movie is through. This musical ranks number two in musicals to me (second next to the blues brothers). But please, do not think of it as a musical per say; seeing as how the songs are so likable, it is hard to tell a carefully choreographed scene is taking place. I think of this movie as more of a comedy with undertones of romance. You will be reminded of what it was like to be a rebellious teenager; needless to say, you will be reminiscing of your old high school days after seeing this film. Highly recommended for both the family (since it is a very youthful but also for adults since there are many jokes that are funnier with age and experience.' 0 b"Alex D. Linz replaces Macaulay Culkin as the central figure in the third movie in the Home Alone empire. Four industrial spies acquire a missile guidance system computer chip and smuggle it through an airport inside a remote controlled toy car. Because of baggage confusion, grouchy Mrs. Hess (Marian Seldes) gets the car. She gives it to her neighbor, Alex (Linz), just before the spies turn up. The spies rent a house in order to burglarize each house in the neighborhood until they locate the car. Home alone with the chicken pox, Alex calls 911 each time he spots a theft in progress, but the spies always manage to elude the police while Alex is accused of making prank calls. The spies finally turn their attentions toward Alex, unaware that he has rigged devices to cleverly booby-trap his entire house. Home Alone 3 wasn't horrible, but probably shouldn't have been made, you can't just replace Macauley Culkin, Joe Pesci, or Daniel Stern. Home Alone 3 had some funny parts, but I don't like when characters are changed in a movie series, view at own risk." 0 b"There's a good movie lurking here, but this isn't it. The basic idea is good: to explore the moral issues that would face a group of young survivors of the apocalypse. But the logic is so muddled that it's impossible to get involved.<br /><br />For example, our four heroes are (understandably) paranoid about catching the mysterious airborne contagion that's wiped out virtually all of mankind. Yet they wear surgical masks some times, not others. Some times they're fanatical about wiping down with bleach any area touched by an infected person. Other times, they seem completely unconcerned.<br /><br />Worse, after apparently surviving some weeks or months in this new kill-or-be-killed world, these people constantly behave like total newbs. They don't bother accumulating proper equipment, or food. They're forever running out of fuel in the middle of nowhere. They don't take elementary precautions when meeting strangers. And after wading through the rotting corpses of the entire human race, they're as squeamish as sheltered debutantes. You have to constantly wonder how they could have survived this long... and even if they did, why anyone would want to make a movie about them.<br /><br />So when these dweebs stop to agonize over the moral dimensions of their actions, it's impossible to take their soul-searching seriously. Their actions would first have to make some kind of minimal sense.<br /><br />On top of all this, we must contend with the dubious acting abilities of Chris Pine. His portrayal of an arrogant young James T Kirk might have seemed shrewd, when viewed in isolation. But in Carriers he plays on exactly that same note: arrogant and boneheaded. It's impossible not to suspect that this constitutes his entire dramatic range.<br /><br />On the positive side, the film *looks* excellent. It's got an over-sharp, saturated look that really suits the southwestern US locale. But that can't save the truly feeble writing nor the paper-thin (and annoying) characters. Even if you're a fan of the end-of-the-world genre, you should save yourself the agony of watching Carriers." 0 b'I saw this movie at an actual movie theater (probably the \\(2.00 one) with my cousin and uncle. We were around 11 and 12, I guess, and really into scary movies. I remember being so excited to see it because my cool uncle let us pick the movie (and we probably never got to do that again!) and sooo disappointed afterwards!! Just boring and not scary. The only redeeming thing I can remember was Corky Pigeon from Silver Spoons, and that wasn\'t all that great, just someone I recognized. I\'ve seen bad movies before and this one has always stuck out in my mind as the worst. This was from what I can recall, one of the most boring, non-scary, waste of our collective \\)6, and a waste of film. I have read some of the reviews that say it is worth a watch and I say, "Too each his own", but I wouldn\'t even bother. Not even so bad it\'s good.'
Configure the dataset for performance
These are two important methods you should use when loading data to make sure that I/O does not become blocking.
.cache() keeps data in memory after it's loaded off disk. This will ensure the dataset does not become a bottleneck while training your model. If your dataset is too large to fit into memory, you can also use this method to create a performant on-disk cache, which is more efficient to read than many small files.
.prefetch() overlaps data preprocessing and model execution while training.
You can learn more about both methods, as well as how to cache data to disk in the data performance guide.
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
Using the Embedding layer
Keras makes it easy to use word embeddings. Take a look at the Embedding layer.
The Embedding layer can be understood as a lookup table that maps from integer indices (which stand for specific words) to dense vectors (their embeddings). The dimensionality (or width) of the embedding is a parameter you can experiment with to see what works well for your problem, much in the same way you would experiment with the number of neurons in a Dense layer.
# Embed a 1,000 word vocabulary into 5 dimensions.
embedding_layer = tf.keras.layers.Embedding(1000, 5)
When you create an Embedding layer, the weights for the embedding are randomly initialized (just like any other layer). During training, they are gradually adjusted via backpropagation. Once trained, the learned word embeddings will roughly encode similarities between words (as they were learned for the specific problem your model is trained on).
If you pass an integer to an embedding layer, the result replaces each integer with the vector from the embedding table:
result = embedding_layer(tf.constant([1, 2, 3]))
result.numpy()
array([[ 0.03135875, 0.03640932, -0.00031054, 0.04873694, -0.03376802],
[ 0.00243857, -0.02919209, -0.01841091, -0.03684188, 0.02765827],
[-0.01245669, -0.01057661, -0.04422194, -0.0317696 , -0.00031216]],
dtype=float32)
For text or sequence problems, the Embedding layer takes a 2D tensor of integers, of shape (samples, sequence_length), where each entry is a sequence of integers. It can embed sequences of variable lengths. You could feed into the embedding layer above batches with shapes (32, 10) (batch of 32 sequences of length 10) or (64, 15) (batch of 64 sequences of length 15).
The returned tensor has one more axis than the input, the embedding vectors are aligned along the new last axis. Pass it a (2, 3) input batch and the output is (2, 3, N)
result = embedding_layer(tf.constant([[0, 1, 2], [3, 4, 5]]))
result.shape
TensorShape([2, 3, 5])
When given a batch of sequences as input, an embedding layer returns a 3D floating point tensor, of shape (samples, sequence_length, embedding_dimensionality). To convert from this sequence of variable length to a fixed representation there are a variety of standard approaches. You could use an RNN, Attention, or pooling layer before passing it to a Dense layer. This tutorial uses pooling because it's the simplest. The Text Classification with an RNN tutorial is a good next step.
Text preprocessing
Next, define the dataset preprocessing steps required for your sentiment classification model. Initialize a TextVectorization layer with the desired parameters to vectorize movie reviews. You can learn more about using this layer in the Text Classification tutorial.
# Create a custom standardization function to strip HTML break tags '<br />'.
def custom_standardization(input_data):
lowercase = tf.strings.lower(input_data)
stripped_html = tf.strings.regex_replace(lowercase, '<br />', ' ')
return tf.strings.regex_replace(stripped_html,
'[%s]' % re.escape(string.punctuation), '')
# Vocabulary size and number of words in a sequence.
vocab_size = 10000
sequence_length = 100
# Use the text vectorization layer to normalize, split, and map strings to
# integers. Note that the layer uses the custom standardization defined above.
# Set maximum_sequence length as all samples are not of the same length.
vectorize_layer = TextVectorization(
standardize=custom_standardization,
max_tokens=vocab_size,
output_mode='int',
output_sequence_length=sequence_length)
# Make a text-only dataset (no labels) and call adapt to build the vocabulary.
text_ds = train_ds.map(lambda x, y: x)
vectorize_layer.adapt(text_ds)
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow/python/autograph/pyct/static_analysis/liveness.py:83: Analyzer.lamba_check (from tensorflow.python.autograph.pyct.static_analysis.liveness) is deprecated and will be removed after 2023-09-23. Instructions for updating: Lambda fuctions will be no more assumed to be used in the statement where they are used, or at least in the same block. https://github.com/tensorflow/tensorflow/issues/56089
Create a classification model
Use the Keras Sequential API to define the sentiment classification model. In this case it is a "Continuous bag of words" style model.
- The
TextVectorizationlayer transforms strings into vocabulary indices. You have already initializedvectorize_layeras a TextVectorization layer and built its vocabulary by callingadaptontext_ds. Now vectorize_layer can be used as the first layer of your end-to-end classification model, feeding transformed strings into the Embedding layer. The
Embeddinglayer takes the integer-encoded vocabulary and looks up the embedding vector for each word-index. These vectors are learned as the model trains. The vectors add a dimension to the output array. The resulting dimensions are:(batch, sequence, embedding).The
GlobalAveragePooling1Dlayer returns a fixed-length output vector for each example by averaging over the sequence dimension. This allows the model to handle input of variable length, in the simplest way possible.The fixed-length output vector is piped through a fully-connected (
Dense) layer with 16 hidden units.The last layer is densely connected with a single output node.
embedding_dim=16
model = Sequential([
vectorize_layer,
Embedding(vocab_size, embedding_dim, name="embedding"),
GlobalAveragePooling1D(),
Dense(16, activation='relu'),
Dense(1)
])
Compile and train the model
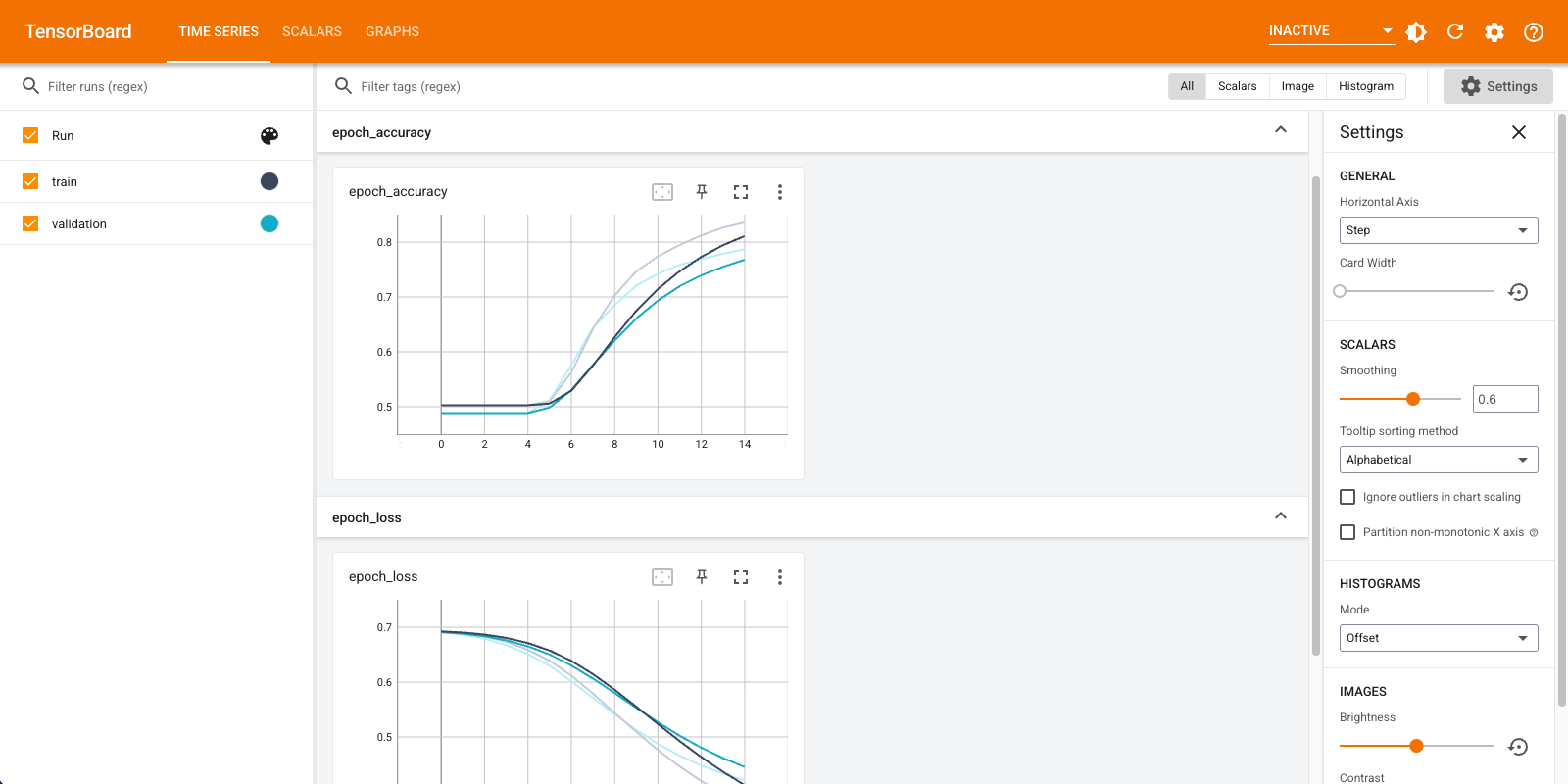
You will use TensorBoard to visualize metrics including loss and accuracy. Create a tf.keras.callbacks.TensorBoard.
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir="logs")
Compile and train the model using the Adam optimizer and BinaryCrossentropy loss.
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(
train_ds,
validation_data=val_ds,
epochs=15,
callbacks=[tensorboard_callback])
Epoch 1/15 20/20 [==============================] - 7s 206ms/step - loss: 0.6920 - accuracy: 0.5028 - val_loss: 0.6904 - val_accuracy: 0.4886 Epoch 2/15 20/20 [==============================] - 1s 50ms/step - loss: 0.6879 - accuracy: 0.5028 - val_loss: 0.6856 - val_accuracy: 0.4886 Epoch 3/15 20/20 [==============================] - 1s 48ms/step - loss: 0.6815 - accuracy: 0.5028 - val_loss: 0.6781 - val_accuracy: 0.4886 Epoch 4/15 20/20 [==============================] - 1s 51ms/step - loss: 0.6713 - accuracy: 0.5028 - val_loss: 0.6663 - val_accuracy: 0.4886 Epoch 5/15 20/20 [==============================] - 1s 49ms/step - loss: 0.6566 - accuracy: 0.5028 - val_loss: 0.6506 - val_accuracy: 0.4886 Epoch 6/15 20/20 [==============================] - 1s 49ms/step - loss: 0.6377 - accuracy: 0.5028 - val_loss: 0.6313 - val_accuracy: 0.4886 Epoch 7/15 20/20 [==============================] - 1s 49ms/step - loss: 0.6148 - accuracy: 0.5057 - val_loss: 0.6090 - val_accuracy: 0.5068 Epoch 8/15 20/20 [==============================] - 1s 48ms/step - loss: 0.5886 - accuracy: 0.5724 - val_loss: 0.5846 - val_accuracy: 0.5864 Epoch 9/15 20/20 [==============================] - 1s 48ms/step - loss: 0.5604 - accuracy: 0.6427 - val_loss: 0.5596 - val_accuracy: 0.6368 Epoch 10/15 20/20 [==============================] - 1s 49ms/step - loss: 0.5316 - accuracy: 0.6967 - val_loss: 0.5351 - val_accuracy: 0.6758 Epoch 11/15 20/20 [==============================] - 1s 50ms/step - loss: 0.5032 - accuracy: 0.7372 - val_loss: 0.5121 - val_accuracy: 0.7102 Epoch 12/15 20/20 [==============================] - 1s 48ms/step - loss: 0.4764 - accuracy: 0.7646 - val_loss: 0.4912 - val_accuracy: 0.7344 Epoch 13/15 20/20 [==============================] - 1s 48ms/step - loss: 0.4516 - accuracy: 0.7858 - val_loss: 0.4727 - val_accuracy: 0.7492 Epoch 14/15 20/20 [==============================] - 1s 48ms/step - loss: 0.4290 - accuracy: 0.8029 - val_loss: 0.4567 - val_accuracy: 0.7584 Epoch 15/15 20/20 [==============================] - 1s 49ms/step - loss: 0.4085 - accuracy: 0.8163 - val_loss: 0.4429 - val_accuracy: 0.7674 <keras.callbacks.History at 0x7f5095954190>
With this approach the model reaches a validation accuracy of around 78% (note that the model is overfitting since training accuracy is higher).
You can look into the model summary to learn more about each layer of the model.
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
text_vectorization (TextVec (None, 100) 0
torization)
embedding (Embedding) (None, 100, 16) 160000
global_average_pooling1d (G (None, 16) 0
lobalAveragePooling1D)
dense (Dense) (None, 16) 272
dense_1 (Dense) (None, 1) 17
=================================================================
Total params: 160,289
Trainable params: 160,289
Non-trainable params: 0
_________________________________________________________________
Visualize the model metrics in TensorBoard.
#docs_infra: no_execute
%load_ext tensorboard
%tensorboard --logdir logs
Retrieve the trained word embeddings and save them to disk
Next, retrieve the word embeddings learned during training. The embeddings are weights of the Embedding layer in the model. The weights matrix is of shape (vocab_size, embedding_dimension).
Obtain the weights from the model using get_layer() and get_weights(). The get_vocabulary() function provides the vocabulary to build a metadata file with one token per line.
weights = model.get_layer('embedding').get_weights()[0]
vocab = vectorize_layer.get_vocabulary()
Write the weights to disk. To use the Embedding Projector, you will upload two files in tab separated format: a file of vectors (containing the embedding), and a file of meta data (containing the words).
out_v = io.open('vectors.tsv', 'w', encoding='utf-8')
out_m = io.open('metadata.tsv', 'w', encoding='utf-8')
for index, word in enumerate(vocab):
if index == 0:
continue # skip 0, it's padding.
vec = weights[index]
out_v.write('\t'.join([str(x) for x in vec]) + "\n")
out_m.write(word + "\n")
out_v.close()
out_m.close()
If you are running this tutorial in Colaboratory, you can use the following snippet to download these files to your local machine (or use the file browser, View -> Table of contents -> File browser).
try:
from google.colab import files
files.download('vectors.tsv')
files.download('metadata.tsv')
except Exception:
pass
Visualize the embeddings
To visualize the embeddings, upload them to the embedding projector.
Open the Embedding Projector (this can also run in a local TensorBoard instance).
Click on "Load data".
Upload the two files you created above:
vecs.tsvandmeta.tsv.
The embeddings you have trained will now be displayed. You can search for words to find their closest neighbors. For example, try searching for "beautiful". You may see neighbors like "wonderful".
Next Steps
This tutorial has shown you how to train and visualize word embeddings from scratch on a small dataset.
To train word embeddings using Word2Vec algorithm, try the Word2Vec tutorial.
To learn more about advanced text processing, read the Transformer model for language understanding.