
Copyright 2018 The TF-Agents Authors.
| |
 GitHub でソースを表示{ GitHub でソースを表示{ |
はじめに
この例は、Cartpole環境でTF-Agentsライブラリを使用して DQN(Deep Q Networks)エージェントをトレーニングする方法を示しています。

ここでは、トレーニング、評価、データ収集のための強化学習(RL)パイプラインのすべてのコンポーネントについて説明します。
このコードをライブで実行するには、上の [Google Colabで実行] リンクをクリックしてください。
セットアップ
以下の依存関係をインストールしていない場合は、実行します。
sudo apt-get install -y xvfb ffmpegpip install -q 'gym==0.10.11'pip install -q 'imageio==2.4.0'pip install -q PILLOWpip install -q 'pyglet==1.3.2'pip install -q pyvirtualdisplaypip install -q tf-agents
from __future__ import absolute_import, division, print_function
import base64
import imageio
import IPython
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import PIL.Image
import pyvirtualdisplay
import tensorflow as tf
from tf_agents.agents.dqn import dqn_agent
from tf_agents.drivers import dynamic_step_driver
from tf_agents.environments import suite_gym
from tf_agents.environments import tf_py_environment
from tf_agents.eval import metric_utils
from tf_agents.metrics import tf_metrics
from tf_agents.networks import q_network
from tf_agents.policies import random_tf_policy
from tf_agents.replay_buffers import tf_uniform_replay_buffer
from tf_agents.trajectories import trajectory
from tf_agents.utils import common
tf.compat.v1.enable_v2_behavior()
# Set up a virtual display for rendering OpenAI gym environments.
display = pyvirtualdisplay.Display(visible=0, size=(1400, 900)).start()
tf.version.VERSION
'2.4.1'
ハイパーパラメータ
num_iterations = 20000 # @param {type:"integer"}
initial_collect_steps = 1000 # @param {type:"integer"}
collect_steps_per_iteration = 1 # @param {type:"integer"}
replay_buffer_max_length = 100000 # @param {type:"integer"}
batch_size = 64 # @param {type:"integer"}
learning_rate = 1e-3 # @param {type:"number"}
log_interval = 200 # @param {type:"integer"}
num_eval_episodes = 10 # @param {type:"integer"}
eval_interval = 1000 # @param {type:"integer"}
環境
強化学習(RL)では、環境はタスクまたは解決すべき問題を表します。標準環境は、tf_agents.environmentsスイートを使用して TF-Agent で作成できます。TF-Agent には、OpenAI Gym、Atari、DM Control などのソースから環境を読み込むためのスイートがあります。
OpenAI Gym スイートから CartPole 環境を読み込みます。
env_name = 'CartPole-v0'
env = suite_gym.load(env_name)
この環境をレンダリングして、どのように見えるかを確認できます。台車の上に自由に振り動く棒を立て、その棒が倒れないように台車を左右に動かすことが目標です。
env.reset()
PIL.Image.fromarray(env.render())
environment.stepメソッドは、環境内でactionを取り、環境の次の観測と行動の報酬を含むTimeStepタプルを返します。
time_step_spec()メソッドは、TimeStepタプルの仕様を返します。そのobservation属性は、観測の形状、データ型、および許容値の範囲を示します。reward属性は、報酬についての同じ詳細を示します。
print('Observation Spec:')
print(env.time_step_spec().observation)
Observation Spec:
BoundedArraySpec(shape=(4,), dtype=dtype('float32'), name='observation', minimum=[-4.8000002e+00 -3.4028235e+38 -4.1887903e-01 -3.4028235e+38], maximum=[4.8000002e+00 3.4028235e+38 4.1887903e-01 3.4028235e+38])
print('Reward Spec:')
print(env.time_step_spec().reward)
Reward Spec:
ArraySpec(shape=(), dtype=dtype('float32'), name='reward')
action_spec()メソッドは、有効な行動の形状、データタイプ、および許容値を返します。
print('Action Spec:')
print(env.action_spec())
Action Spec:
BoundedArraySpec(shape=(), dtype=dtype('int64'), name='action', minimum=0, maximum=1)
CartPole 環境では
observationは以下の 4 つの float 型の配列です。- 台車の位置と速度
- 棒の角度位置と速度
rewardはスカラーの浮動小数点値ですactionは可能な値が 2 つだけのスカラー整数です。0— 「左に移動」1— 「右に移動」
time_step = env.reset()
print('Time step:')
print(time_step)
action = np.array(1, dtype=np.int32)
next_time_step = env.step(action)
print('Next time step:')
print(next_time_step)
Time step: TimeStep(step_type=array(0, dtype=int32), reward=array(0., dtype=float32), discount=array(1., dtype=float32), observation=array([-0.0282033 , -0.04788824, -0.02078666, 0.04272398], dtype=float32)) Next time step: TimeStep(step_type=array(1, dtype=int32), reward=array(1., dtype=float32), discount=array(1., dtype=float32), observation=array([-0.02916106, 0.14752552, -0.01993218, -0.2564442 ], dtype=float32))
通常、2 つの環境(トレーニング用、評価用)のみがインスタンス化されます。
train_py_env = suite_gym.load(env_name)
eval_py_env = suite_gym.load(env_name)
CartPole 環境は、ほとんどの環境と同様に純粋な Python で記述されています。これは、TFPyEnvironmentラッパーを使用して TensorFlow に変換されます。
従来の環境の API は Numpy 配列を使用します。TFPyEnvironmentは、これらをTensorsに変換して、Tensorflow エージェントおよびポリシーとの互換性を確保します。
train_env = tf_py_environment.TFPyEnvironment(train_py_env)
eval_env = tf_py_environment.TFPyEnvironment(eval_py_env)
エージェント
RL問題の解決に使用されるアルゴリズムは、Agentで表されます。TF-Agent は、以下を含むさまざまなAgentsの標準実装を提供します。
DQN エージェントは、個別の行動領域がある任意の環境で使用できます。
DQN エージェントの中心にあるのがQNetworkです。これは、環境から観察を得て、すべての行動のQValues(予期される戻り値)を予測する方法を学習するニューラルネットワークモデルです。
tf_agents.networks.q_networkを使用してQNetworkを作成し、observation_spec、action_spec、およびモデルの非表示レイヤーの数とサイズを表すタプルを渡します。
fc_layer_params = (100,)
q_net = q_network.QNetwork(
train_env.observation_spec(),
train_env.action_spec(),
fc_layer_params=fc_layer_params)
tf_agents.agents.dqn.dqn_agentを使用してDqnAgentをインスタンス化します。time_step_spec、action_spec、および QNetwork に加えて、エージェントコンストラクタにもオプティマイザ(この場合、AdamOptimizer)、損失関数、および整数ステップカウンタが必要です。
optimizer = tf.compat.v1.train.AdamOptimizer(learning_rate=learning_rate)
train_step_counter = tf.Variable(0)
agent = dqn_agent.DqnAgent(
train_env.time_step_spec(),
train_env.action_spec(),
q_network=q_net,
optimizer=optimizer,
td_errors_loss_fn=common.element_wise_squared_loss,
train_step_counter=train_step_counter)
agent.initialize()
ポリシー
ポリシーは、エージェントが環境で行動する方法を定義します。通常、強化学習の目標は、ポリシーが望ましい結果を生成するまで、基礎となるモデルをトレーニングすることです。
このチュートリアルでは
- 望ましい結果は、台車の上の棒が倒れないようにバランスを保つことです。
- ポリシーは、
time_step観測ごとに行動(左または右)を返します。
エージェントには 2 つのポリシーが含まれています。
agent.policy— 評価とデプロイに使用される主なポリシー。agent.collect_policy— データ収集に使用される補助的なポリシー。
eval_policy = agent.policy
collect_policy = agent.collect_policy
ポリシーはエージェントとは無関係に作成できます。たとえば、tf_agents.policies.random_tf_policyを使用して、各time_stepの行動をランダムに選択するポリシーを作成できます。
random_policy = random_tf_policy.RandomTFPolicy(train_env.time_step_spec(),
train_env.action_spec())
ポリシーから行動を取得するには、policy.action(time_step)メソッドを呼び出します。time_stepには、環境からの観測が含まれています。このメソッドは、3 つのコンポーネントを持つ名前付きタプルであるPolicyStepを返します。
action— 実行する行動(ここでは0または1)state— ステートフルポリシー(RNNベース)に使用info— 行動のログ確率などの補助データ
example_environment = tf_py_environment.TFPyEnvironment(
suite_gym.load('CartPole-v0'))
time_step = example_environment.reset()
random_policy.action(time_step)
PolicyStep(action=<tf.Tensor: shape=(1,), dtype=int64, numpy=array([0])>, state=(), info=())
指標と評価
ポリシーの評価に使用される最も一般的な指標は、平均リターンです。リターンは、エピソードの環境でポリシーを実行中に取得した報酬の合計です。エピソードは何回か実行され、平均リターンが生成されます。
次の関数は、ポリシー、環境、およびエピソードの数を指定して、ポリシーの平均リターンを計算します。
def compute_avg_return(environment, policy, num_episodes=10):
total_return = 0.0
for _ in range(num_episodes):
time_step = environment.reset()
episode_return = 0.0
while not time_step.is_last():
action_step = policy.action(time_step)
time_step = environment.step(action_step.action)
episode_return += time_step.reward
total_return += episode_return
avg_return = total_return / num_episodes
return avg_return.numpy()[0]
# See also the metrics module for standard implementations of different metrics.
# https://github.com/tensorflow/agents/tree/master/tf_agents/metrics
この計算をrandom_policyで実行すると、環境のベースラインパフォーマンスが示されます。
compute_avg_return(eval_env, random_policy, num_eval_episodes)
18.8
再生バッファ
再生バッファは、環境から収集されたデータを追跡します。このチュートリアルでは最も一般的なtf_agents.replay_buffers.tf_uniform_replay_buffer.TFUniformReplayBufferを使用します。
コンストラクタは、収集するデータの仕様を必要とします。これは、collect_data_specメソッドを使用してエージェントから入手できます。バッチサイズと最大バッファ長も必要です。
replay_buffer = tf_uniform_replay_buffer.TFUniformReplayBuffer(
data_spec=agent.collect_data_spec,
batch_size=train_env.batch_size,
max_length=replay_buffer_max_length)
ほとんどのエージェントの場合、collect_data_specは、Trajectoryと呼ばれる名前付きタプルであり、観測、行動、報酬、およびその他の要素の仕様が含まれています。
agent.collect_data_spec
Trajectory(step_type=TensorSpec(shape=(), dtype=tf.int32, name='step_type'), observation=BoundedTensorSpec(shape=(4,), dtype=tf.float32, name='observation', minimum=array([-4.8000002e+00, -3.4028235e+38, -4.1887903e-01, -3.4028235e+38],
dtype=float32), maximum=array([4.8000002e+00, 3.4028235e+38, 4.1887903e-01, 3.4028235e+38],
dtype=float32)), action=BoundedTensorSpec(shape=(), dtype=tf.int64, name='action', minimum=array(0), maximum=array(1)), policy_info=(), next_step_type=TensorSpec(shape=(), dtype=tf.int32, name='step_type'), reward=TensorSpec(shape=(), dtype=tf.float32, name='reward'), discount=BoundedTensorSpec(shape=(), dtype=tf.float32, name='discount', minimum=array(0., dtype=float32), maximum=array(1., dtype=float32)))
agent.collect_data_spec._fields
('step_type',
'observation',
'action',
'policy_info',
'next_step_type',
'reward',
'discount')
データ収集
次に、環境でランダムポリシーを数ステップ実行し、データを再生バッファに記録します。
def collect_step(environment, policy, buffer):
time_step = environment.current_time_step()
action_step = policy.action(time_step)
next_time_step = environment.step(action_step.action)
traj = trajectory.from_transition(time_step, action_step, next_time_step)
# Add trajectory to the replay buffer
buffer.add_batch(traj)
def collect_data(env, policy, buffer, steps):
for _ in range(steps):
collect_step(env, policy, buffer)
collect_data(train_env, random_policy, replay_buffer, steps=100)
# This loop is so common in RL, that we provide standard implementations.
# For more details see the drivers module.
# https://www.tensorflow.org/agents/api_docs/python/tf_agents/drivers
再生バッファは Trajectory のコレクションではありません。
# For the curious:
# Uncomment to peel one of these off and inspect it.
# iter(replay_buffer.as_dataset()).next()
エージェントは再生バッファにアクセスする必要があります。これは、エージェントにデータをフィードするイテレーション可能なtf.data.Datasetパイプラインを作成することにより提供されます。
再生バッファの各行には、1 つの観測ステップのみが格納されます。しかし、DQN エージェントは損失を計算するためにその時点の観測と次の観測を両方必要とするので、データセットパイプラインは、バッチ内の要素ごとに2つの隣接する行をサンプリングします(num_steps=2)。
また、このデータセットは、並列呼び出しを実行してデータをプリフェッチすることにより最適化されます。
# Dataset generates trajectories with shape [Bx2x...]
dataset = replay_buffer.as_dataset(
num_parallel_calls=3,
sample_batch_size=batch_size,
num_steps=2).prefetch(3)
dataset
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.6/site-packages/tensorflow/python/autograph/operators/control_flow.py:1218: ReplayBuffer.get_next (from tf_agents.replay_buffers.replay_buffer) is deprecated and will be removed in a future version. Instructions for updating: Use `as_dataset(..., single_deterministic_pass=False) instead. <PrefetchDataset shapes: (Trajectory(step_type=(64, 2), observation=(64, 2, 4), action=(64, 2), policy_info=(), next_step_type=(64, 2), reward=(64, 2), discount=(64, 2)), BufferInfo(ids=(64, 2), probabilities=(64,))), types: (Trajectory(step_type=tf.int32, observation=tf.float32, action=tf.int64, policy_info=(), next_step_type=tf.int32, reward=tf.float32, discount=tf.float32), BufferInfo(ids=tf.int64, probabilities=tf.float32))>
iterator = iter(dataset)
print(iterator)
<tensorflow.python.data.ops.iterator_ops.OwnedIterator object at 0x7f84cc723160>
# For the curious:
# Uncomment to see what the dataset iterator is feeding to the agent.
# Compare this representation of replay data
# to the collection of individual trajectories shown earlier.
# iterator.next()
エージェントのトレーニング
トレーニングループ時には、以下の 2 つが行われる必要があります。
- 環境からデータを収集する
- そのデータを使用してエージェントのニューラルネットワークをトレーニングする
この例では、定期的にポリシーを評価し、その時点のスコアを出力します。
以下の実行には 5 分ほどかかります。
try:
%%time
except:
pass
# (Optional) Optimize by wrapping some of the code in a graph using TF function.
agent.train = common.function(agent.train)
# Reset the train step
agent.train_step_counter.assign(0)
# Evaluate the agent's policy once before training.
avg_return = compute_avg_return(eval_env, agent.policy, num_eval_episodes)
returns = [avg_return]
for _ in range(num_iterations):
# Collect a few steps using collect_policy and save to the replay buffer.
for _ in range(collect_steps_per_iteration):
collect_step(train_env, agent.collect_policy, replay_buffer)
# Sample a batch of data from the buffer and update the agent's network.
experience, unused_info = next(iterator)
train_loss = agent.train(experience).loss
step = agent.train_step_counter.numpy()
if step % log_interval == 0:
print('step = {0}: loss = {1}'.format(step, train_loss))
if step % eval_interval == 0:
avg_return = compute_avg_return(eval_env, agent.policy, num_eval_episodes)
print('step = {0}: Average Return = {1}'.format(step, avg_return))
returns.append(avg_return)
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.6/site-packages/tensorflow/python/util/dispatch.py:201: calling foldr_v2 (from tensorflow.python.ops.functional_ops) with back_prop=False is deprecated and will be removed in a future version. Instructions for updating: back_prop=False is deprecated. Consider using tf.stop_gradient instead. Instead of: results = tf.foldr(fn, elems, back_prop=False) Use: results = tf.nest.map_structure(tf.stop_gradient, tf.foldr(fn, elems)) step = 200: loss = 26.031688690185547 step = 400: loss = 5.314972400665283 step = 600: loss = 5.50214147567749 step = 800: loss = 16.61824607849121 step = 1000: loss = 29.10118293762207 step = 1000: Average Return = 151.6999969482422 step = 1200: loss = 57.56373596191406 step = 1400: loss = 61.819091796875 step = 1600: loss = 5.503599166870117 step = 1800: loss = 59.7533073425293 step = 2000: loss = 81.48899841308594 step = 2000: Average Return = 149.5 step = 2200: loss = 14.238945007324219 step = 2400: loss = 21.271509170532227 step = 2600: loss = 714.9962768554688 step = 2800: loss = 432.18438720703125 step = 3000: loss = 31.756074905395508 step = 3000: Average Return = 68.69999694824219 step = 3200: loss = 245.41600036621094 step = 3400: loss = 49.524330139160156 step = 3600: loss = 854.413818359375 step = 3800: loss = 642.3952026367188 step = 4000: loss = 340.8377990722656 step = 4000: Average Return = 74.5 step = 4200: loss = 740.2651977539062 step = 4400: loss = 1225.3353271484375 step = 4600: loss = 457.6378479003906 step = 4800: loss = 1717.94091796875 step = 5000: loss = 208.09521484375 step = 5000: Average Return = 54.599998474121094 step = 5200: loss = 396.01123046875 step = 5400: loss = 1565.9281005859375 step = 5600: loss = 89.62256622314453 step = 5800: loss = 266.5655212402344 step = 6000: loss = 231.2029266357422 step = 6000: Average Return = 86.80000305175781 step = 6200: loss = 243.82525634765625 step = 6400: loss = 151.86875915527344 step = 6600: loss = 139.1936798095703 step = 6800: loss = 281.7527160644531 step = 7000: loss = 112.37540435791016 step = 7000: Average Return = 143.1999969482422 step = 7200: loss = 108.10910034179688 step = 7400: loss = 18.46331787109375 step = 7600: loss = 1931.9803466796875 step = 7800: loss = 1408.3668212890625 step = 8000: loss = 279.8353576660156 step = 8000: Average Return = 156.60000610351562 step = 8200: loss = 17.501930236816406 step = 8400: loss = 19.664348602294922 step = 8600: loss = 17.774032592773438 step = 8800: loss = 190.37933349609375 step = 9000: loss = 456.5616455078125 step = 9000: Average Return = 195.3000030517578 step = 9200: loss = 1339.147705078125 step = 9400: loss = 305.4017028808594 step = 9600: loss = 85.6674575805664 step = 9800: loss = 145.49986267089844 step = 10000: loss = 45.751380920410156 step = 10000: Average Return = 200.0 step = 10200: loss = 111.9870834350586 step = 10400: loss = 244.15025329589844 step = 10600: loss = 171.58120727539062 step = 10800: loss = 13.996395111083984 step = 11000: loss = 140.0017852783203 step = 11000: Average Return = 200.0 step = 11200: loss = 23.76217269897461 step = 11400: loss = 1000.08935546875 step = 11600: loss = 458.71331787109375 step = 11800: loss = 38.53162384033203 step = 12000: loss = 13.367055892944336 step = 12000: Average Return = 200.0 step = 12200: loss = 27.199668884277344 step = 12400: loss = 22.037113189697266 step = 12600: loss = 14.54778003692627 step = 12800: loss = 13.551041603088379 step = 13000: loss = 24.765060424804688 step = 13000: Average Return = 196.39999389648438 step = 13200: loss = 13.768646240234375 step = 13400: loss = 42.01901626586914 step = 13600: loss = 708.3466796875 step = 13800: loss = 27.82616424560547 step = 14000: loss = 2113.056640625 step = 14000: Average Return = 200.0 step = 14200: loss = 23.315961837768555 step = 14400: loss = 778.3829345703125 step = 14600: loss = 794.56689453125 step = 14800: loss = 32.738624572753906 step = 15000: loss = 33.288021087646484 step = 15000: Average Return = 200.0 step = 15200: loss = 52.65998077392578 step = 15400: loss = 1230.9066162109375 step = 15600: loss = 49.63909912109375 step = 15800: loss = 2566.757080078125 step = 16000: loss = 33.33224868774414 step = 16000: Average Return = 200.0 step = 16200: loss = 42.63489532470703 step = 16400: loss = 45.52163314819336 step = 16600: loss = 1360.7489013671875 step = 16800: loss = 40.121482849121094 step = 17000: loss = 88.85276794433594 step = 17000: Average Return = 200.0 step = 17200: loss = 37.30867004394531 step = 17400: loss = 1714.3226318359375 step = 17600: loss = 3302.299560546875 step = 17800: loss = 48.68688201904297 step = 18000: loss = 3574.722900390625 step = 18000: Average Return = 200.0 step = 18200: loss = 68.59884643554688 step = 18400: loss = 49.48236083984375 step = 18600: loss = 131.61178588867188 step = 18800: loss = 6955.58349609375 step = 19000: loss = 80.3465576171875 step = 19000: Average Return = 200.0 step = 19200: loss = 2100.316650390625 step = 19400: loss = 4835.74267578125 step = 19600: loss = 49.40709686279297 step = 19800: loss = 104.12965393066406 step = 20000: loss = 3127.011962890625 step = 20000: Average Return = 200.0
可視化
プロット
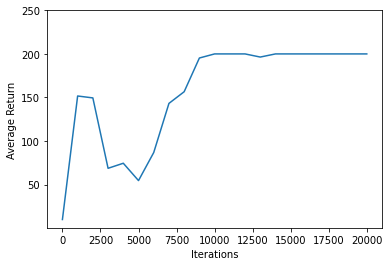
matplotlib.pyplotを使用して、トレーニング中にポリシーがどのように改善されたかをグラフ化します。
Cartpole-v0の 1 回のイテレーションには、200のタイムステップがあります。環境は、棒が立ったままでいる各ステップに対して+1の報酬を与えるので、1 つのエピソードの最大リターンは 200 です。グラフは、トレーニング中に評価されるたびに、最大値に向かって増加するリターンを示しています。(多少不安定になり、毎回単調に増加しないこともあります。)
iterations = range(0, num_iterations + 1, eval_interval)
plt.plot(iterations, returns)
plt.ylabel('Average Return')
plt.xlabel('Iterations')
plt.ylim(top=250)
(0.39499959945678675, 250.0)
動画
グラフは便利ですが、エージェントが環境内で実際にタスクを実行している様子を動画で視覚化するとさらに分かりやすくなります。
まず、ノートブックに動画を埋め込む関数を作成します。
def embed_mp4(filename):
"""Embeds an mp4 file in the notebook."""
video = open(filename,'rb').read()
b64 = base64.b64encode(video)
tag = '''
<video width="640" height="480" controls>
<source src="data:video/mp4;base64,{0}" type="video/mp4">
Your browser does not support the video tag.
</video>'''.format(b64.decode())
return IPython.display.HTML(tag)
CartPole ゲームのいくつかのエピソードをエージェントで繰り返します。基礎となる Python 環境(TensorFlow 環境ラッパーの「内部」のもの)は、環境の状態のイメージを出力するrender()メソッドを提供します。これらは動画に収集できます。
def create_policy_eval_video(policy, filename, num_episodes=5, fps=30):
filename = filename + ".mp4"
with imageio.get_writer(filename, fps=fps) as video:
for _ in range(num_episodes):
time_step = eval_env.reset()
video.append_data(eval_py_env.render())
while not time_step.is_last():
action_step = policy.action(time_step)
time_step = eval_env.step(action_step.action)
video.append_data(eval_py_env.render())
return embed_mp4(filename)
create_policy_eval_video(agent.policy, "trained-agent")
WARNING:root:IMAGEIO FFMPEG_WRITER WARNING: input image is not divisible by macro_block_size=16, resizing from (400, 600) to (400, 608) to ensure video compatibility with most codecs and players. To prevent resizing, make your input image divisible by the macro_block_size or set the macro_block_size to None (risking incompatibility). You may also see a FFMPEG warning concerning speedloss due to data not being aligned.
トレーニングされたエージェント(上記)をランダムに移動するエージェントと比較してみてください。(ランダムに移動するエージェントは、トレーニングされたエージェントと比べて上手くできません。)
create_policy_eval_video(random_policy, "random-agent")
WARNING:root:IMAGEIO FFMPEG_WRITER WARNING: input image is not divisible by macro_block_size=16, resizing from (400, 600) to (400, 608) to ensure video compatibility with most codecs and players. To prevent resizing, make your input image divisible by the macro_block_size or set the macro_block_size to None (risking incompatibility). You may also see a FFMPEG warning concerning speedloss due to data not being aligned.