
Hak Cipta 2020 The TF-Agents Authors.
Memulai
| | |  Lihat sumber di GitHub Lihat sumber di GitHub | |
Mempersiapkan
Jika Anda belum menginstal dependensi berikut, jalankan:
pip install tf-agents
Impor
import abc
import numpy as np
import tensorflow as tf
from tf_agents.agents import tf_agent
from tf_agents.drivers import driver
from tf_agents.environments import py_environment
from tf_agents.environments import tf_environment
from tf_agents.environments import tf_py_environment
from tf_agents.policies import tf_policy
from tf_agents.specs import array_spec
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import time_step as ts
from tf_agents.trajectories import trajectory
from tf_agents.trajectories import policy_step
nest = tf.nest
pengantar
Masalah Multi-Armed Bandit (MAB) adalah kasus khusus dari Pembelajaran Penguatan: agen mengumpulkan hadiah di lingkungan dengan mengambil beberapa tindakan setelah mengamati beberapa keadaan lingkungan. Perbedaan utama antara RL umum dan MAB adalah bahwa dalam MAB, kami berasumsi bahwa tindakan yang diambil oleh agen tidak mempengaruhi keadaan lingkungan berikutnya. Oleh karena itu, agen tidak memodelkan transisi status, penghargaan kredit untuk tindakan masa lalu, atau "merencanakan ke depan" untuk mencapai status kaya penghargaan.
Seperti dalam domain RL lain, tujuan dari agen MAB adalah untuk menemukan kebijakan yang mengumpulkan sebanyak hadiah mungkin. Akan tetapi, adalah suatu kesalahan untuk selalu mencoba mengeksploitasi tindakan yang menjanjikan imbalan tertinggi, karena dengan demikian ada kemungkinan kita kehilangan tindakan yang lebih baik jika kita tidak cukup mengeksplorasi. Ini adalah masalah utama yang harus diselesaikan dalam (MAB), sering disebut eksplorasi-eksploitasi dilema.
Lingkungan Bandit, kebijakan, dan agen untuk MAB dapat ditemukan dalam subdirektori dari tf_agents / bandit .
Lingkungan
Dalam TF-Agen, kelas lingkungan menyajikan peran memberikan informasi tentang kondisi saat ini (ini disebut observasi atau konteks), menerima tindakan sebagai masukan, melakukan transisi negara, dan keluaran hadiah. Kelas ini juga mengatur ulang saat episode berakhir, sehingga episode baru dapat dimulai. Hal ini diwujudkan dengan memanggil reset fungsi ketika keadaan diberi label sebagai "terakhir" episode.
Untuk lebih jelasnya, lihat TF-Agen lingkungan tutorial .
Seperti disebutkan di atas, MAB berbeda dari RL umum dalam hal tindakan tidak mempengaruhi pengamatan berikutnya. Perbedaan lainnya adalah bahwa di Bandit, tidak ada "episode": setiap langkah waktu dimulai dengan pengamatan baru, terlepas dari langkah waktu sebelumnya.
Untuk memastikan pengamatan independen dan untuk pergi abstrak konsep episode RL, kami memperkenalkan subclass dari PyEnvironment dan TFEnvironment : BanditPyEnvironment dan BanditTFEnvironment . Kelas-kelas ini mengekspos dua fungsi anggota pribadi yang tetap diimplementasikan oleh pengguna:
@abc.abstractmethod
def _observe(self):
dan
@abc.abstractmethod
def _apply_action(self, action):
The _observe mengembalikan fungsi pengamatan. Kemudian, kebijakan memilih tindakan berdasarkan pengamatan ini. The _apply_action menerima bahwa tindakan sebagai masukan, dan mengembalikan sesuai reward. Fungsi anggota pribadi ini disebut dengan fungsi reset dan step , masing-masing.
class BanditPyEnvironment(py_environment.PyEnvironment):
def __init__(self, observation_spec, action_spec):
self._observation_spec = observation_spec
self._action_spec = action_spec
super(BanditPyEnvironment, self).__init__()
# Helper functions.
def action_spec(self):
return self._action_spec
def observation_spec(self):
return self._observation_spec
def _empty_observation(self):
return tf.nest.map_structure(lambda x: np.zeros(x.shape, x.dtype),
self.observation_spec())
# These two functions below should not be overridden by subclasses.
def _reset(self):
"""Returns a time step containing an observation."""
return ts.restart(self._observe(), batch_size=self.batch_size)
def _step(self, action):
"""Returns a time step containing the reward for the action taken."""
reward = self._apply_action(action)
return ts.termination(self._observe(), reward)
# These two functions below are to be implemented in subclasses.
@abc.abstractmethod
def _observe(self):
"""Returns an observation."""
@abc.abstractmethod
def _apply_action(self, action):
"""Applies `action` to the Environment and returns the corresponding reward.
"""
Di atas mengimplementasikan kelas abstrak interim PyEnvironment 's _reset dan _step fungsi dan memperlihatkan fungsi abstrak _observe dan _apply_action harus dilaksanakan oleh subclass.
Contoh Kelas Lingkungan Sederhana
Kelas berikut memberikan lingkungan yang sangat sederhana yang pengamatannya adalah bilangan bulat acak antara -2 dan 2, ada 3 kemungkinan tindakan (0, 1, 2), dan hadiahnya adalah produk dari tindakan dan pengamatan.
class SimplePyEnvironment(BanditPyEnvironment):
def __init__(self):
action_spec = array_spec.BoundedArraySpec(
shape=(), dtype=np.int32, minimum=0, maximum=2, name='action')
observation_spec = array_spec.BoundedArraySpec(
shape=(1,), dtype=np.int32, minimum=-2, maximum=2, name='observation')
super(SimplePyEnvironment, self).__init__(observation_spec, action_spec)
def _observe(self):
self._observation = np.random.randint(-2, 3, (1,), dtype='int32')
return self._observation
def _apply_action(self, action):
return action * self._observation
Sekarang kita dapat menggunakan lingkungan ini untuk mendapatkan pengamatan, dan menerima hadiah atas tindakan kita.
environment = SimplePyEnvironment()
observation = environment.reset().observation
print("observation: %d" % observation)
action = 2
print("action: %d" % action)
reward = environment.step(action).reward
print("reward: %f" % reward)
observation: -1 action: 2 reward: -2.000000
Lingkungan TF
Satu dapat menentukan lingkungan Bandit oleh subclassing BanditTFEnvironment , atau, mirip dengan lingkungan RL, satu dapat menentukan BanditPyEnvironment dan bungkus dengan TFPyEnvironment . Demi kesederhanaan, kami menggunakan opsi terakhir dalam tutorial ini.
tf_environment = tf_py_environment.TFPyEnvironment(environment)
Kebijakan
Sebuah kebijakan dalam masalah bandit yang bekerja dengan cara yang sama seperti pada masalah RL: menyediakan suatu tindakan (atau distribusi tindakan), diberikan sebuah pengamatan sebagai masukan.
Untuk lebih jelasnya, lihat tutorial TF-Agen Kebijakan .
Seperti lingkungan, ada dua cara untuk membangun kebijakan: Satu dapat membuat PyPolicy dan bungkus dengan TFPyPolicy , atau langsung membuat TFPolicy . Di sini kami memilih untuk menggunakan metode langsung.
Karena contoh ini cukup sederhana, kita dapat menentukan kebijakan optimal secara manual. Tindakan hanya tergantung pada tanda pengamatan, 0 ketika negatif dan 2 ketika positif.
class SignPolicy(tf_policy.TFPolicy):
def __init__(self):
observation_spec = tensor_spec.BoundedTensorSpec(
shape=(1,), dtype=tf.int32, minimum=-2, maximum=2)
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
shape=(), dtype=tf.int32, minimum=0, maximum=2)
super(SignPolicy, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec)
def _distribution(self, time_step):
pass
def _variables(self):
return ()
def _action(self, time_step, policy_state, seed):
observation_sign = tf.cast(tf.sign(time_step.observation[0]), dtype=tf.int32)
action = observation_sign + 1
return policy_step.PolicyStep(action, policy_state)
Sekarang kita dapat meminta pengamatan dari lingkungan, memanggil kebijakan untuk memilih tindakan, maka lingkungan akan menampilkan hadiah:
sign_policy = SignPolicy()
current_time_step = tf_environment.reset()
print('Observation:')
print (current_time_step.observation)
action = sign_policy.action(current_time_step).action
print('Action:')
print (action)
reward = tf_environment.step(action).reward
print('Reward:')
print(reward)
Observation: tf.Tensor([[2]], shape=(1, 1), dtype=int32) Action: tf.Tensor([2], shape=(1,), dtype=int32) Reward: tf.Tensor([[4.]], shape=(1, 1), dtype=float32)
Cara lingkungan bandit diterapkan memastikan bahwa setiap kali kita mengambil langkah, kita tidak hanya menerima hadiah untuk tindakan yang kita lakukan, tetapi juga pengamatan berikutnya.
step = tf_environment.reset()
action = 1
next_step = tf_environment.step(action)
reward = next_step.reward
next_observation = next_step.observation
print("Reward: ")
print(reward)
print("Next observation:")
print(next_observation)
Reward: tf.Tensor([[-2.]], shape=(1, 1), dtype=float32) Next observation: tf.Tensor([[0]], shape=(1, 1), dtype=int32)
Agen
Sekarang kita memiliki lingkungan bandit dan kebijakan bandit, sekarang saatnya untuk mendefinisikan agen bandit, yang menangani perubahan kebijakan berdasarkan sampel pelatihan.
API untuk agen bandit yang tidak berbeda dari yang agen RL: agen hanya perlu menerapkan _initialize dan _train metode, dan menetapkan policy dan collect_policy .
Lingkungan yang Lebih Rumit
Sebelum kita menulis agen bandit kita, kita perlu memiliki lingkungan yang sedikit lebih sulit untuk dipahami. Untuk membumbui hal-hal hanya sedikit, lingkungan berikutnya akan baik selalu memberikan reward = observation * action atau reward = -observation * action . Ini akan diputuskan ketika lingkungan diinisialisasi.
class TwoWayPyEnvironment(BanditPyEnvironment):
def __init__(self):
action_spec = array_spec.BoundedArraySpec(
shape=(), dtype=np.int32, minimum=0, maximum=2, name='action')
observation_spec = array_spec.BoundedArraySpec(
shape=(1,), dtype=np.int32, minimum=-2, maximum=2, name='observation')
# Flipping the sign with probability 1/2.
self._reward_sign = 2 * np.random.randint(2) - 1
print("reward sign:")
print(self._reward_sign)
super(TwoWayPyEnvironment, self).__init__(observation_spec, action_spec)
def _observe(self):
self._observation = np.random.randint(-2, 3, (1,), dtype='int32')
return self._observation
def _apply_action(self, action):
return self._reward_sign * action * self._observation[0]
two_way_tf_environment = tf_py_environment.TFPyEnvironment(TwoWayPyEnvironment())
reward sign: -1
Kebijakan yang Lebih Rumit
Lingkungan yang lebih rumit membutuhkan kebijakan yang lebih rumit. Kami membutuhkan kebijakan yang mendeteksi perilaku lingkungan yang mendasarinya. Ada tiga situasi yang perlu ditangani oleh kebijakan:
- Agen belum mendeteksi tahu versi lingkungan mana yang sedang berjalan.
- Agen mendeteksi bahwa versi asli lingkungan sedang berjalan.
- Agen mendeteksi bahwa versi lingkungan yang dibalik sedang berjalan.
Kami mendefinisikan tf_variable bernama _situation untuk menyimpan informasi ini dikodekan sebagai nilai dalam [0, 2] , kemudian membuat berperilaku kebijakan sesuai.
class TwoWaySignPolicy(tf_policy.TFPolicy):
def __init__(self, situation):
observation_spec = tensor_spec.BoundedTensorSpec(
shape=(1,), dtype=tf.int32, minimum=-2, maximum=2)
action_spec = tensor_spec.BoundedTensorSpec(
shape=(), dtype=tf.int32, minimum=0, maximum=2)
time_step_spec = ts.time_step_spec(observation_spec)
self._situation = situation
super(TwoWaySignPolicy, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec)
def _distribution(self, time_step):
pass
def _variables(self):
return [self._situation]
def _action(self, time_step, policy_state, seed):
sign = tf.cast(tf.sign(time_step.observation[0, 0]), dtype=tf.int32)
def case_unknown_fn():
# Choose 1 so that we get information on the sign.
return tf.constant(1, shape=(1,))
# Choose 0 or 2, depending on the situation and the sign of the observation.
def case_normal_fn():
return tf.constant(sign + 1, shape=(1,))
def case_flipped_fn():
return tf.constant(1 - sign, shape=(1,))
cases = [(tf.equal(self._situation, 0), case_unknown_fn),
(tf.equal(self._situation, 1), case_normal_fn),
(tf.equal(self._situation, 2), case_flipped_fn)]
action = tf.case(cases, exclusive=True)
return policy_step.PolicyStep(action, policy_state)
Agen
Sekarang saatnya untuk menentukan agen yang mendeteksi tanda lingkungan dan menetapkan kebijakan dengan tepat.
class SignAgent(tf_agent.TFAgent):
def __init__(self):
self._situation = tf.Variable(0, dtype=tf.int32)
policy = TwoWaySignPolicy(self._situation)
time_step_spec = policy.time_step_spec
action_spec = policy.action_spec
super(SignAgent, self).__init__(time_step_spec=time_step_spec,
action_spec=action_spec,
policy=policy,
collect_policy=policy,
train_sequence_length=None)
def _initialize(self):
return tf.compat.v1.variables_initializer(self.variables)
def _train(self, experience, weights=None):
observation = experience.observation
action = experience.action
reward = experience.reward
# We only need to change the value of the situation variable if it is
# unknown (0) right now, and we can infer the situation only if the
# observation is not 0.
needs_action = tf.logical_and(tf.equal(self._situation, 0),
tf.not_equal(reward, 0))
def new_situation_fn():
"""This returns either 1 or 2, depending on the signs."""
return (3 - tf.sign(tf.cast(observation[0, 0, 0], dtype=tf.int32) *
tf.cast(action[0, 0], dtype=tf.int32) *
tf.cast(reward[0, 0], dtype=tf.int32))) / 2
new_situation = tf.cond(needs_action,
new_situation_fn,
lambda: self._situation)
new_situation = tf.cast(new_situation, tf.int32)
tf.compat.v1.assign(self._situation, new_situation)
return tf_agent.LossInfo((), ())
sign_agent = SignAgent()
Pada kode di atas, agen mendefinisikan kebijakan, dan variabel situation dibagi oleh agen dan kebijakan.
Juga, parameter experience dari _train fungsi lintasan:
lintasan
Dalam TF-Agen, trajectories bernama tupel yang berisi sampel dari langkah sebelumnya diambil. Sampel ini kemudian digunakan oleh agen untuk melatih dan memperbarui kebijakan. Di RL, lintasan harus berisi informasi tentang keadaan saat ini, keadaan selanjutnya, dan apakah episode saat ini telah berakhir. Karena di dunia Bandit kami tidak membutuhkan hal-hal ini, kami menyiapkan fungsi pembantu untuk membuat lintasan:
# We need to add another dimension here because the agent expects the
# trajectory of shape [batch_size, time, ...], but in this tutorial we assume
# that both batch size and time are 1. Hence all the expand_dims.
def trajectory_for_bandit(initial_step, action_step, final_step):
return trajectory.Trajectory(observation=tf.expand_dims(initial_step.observation, 0),
action=tf.expand_dims(action_step.action, 0),
policy_info=action_step.info,
reward=tf.expand_dims(final_step.reward, 0),
discount=tf.expand_dims(final_step.discount, 0),
step_type=tf.expand_dims(initial_step.step_type, 0),
next_step_type=tf.expand_dims(final_step.step_type, 0))
Melatih Agen
Sekarang semua potongan siap untuk melatih agen bandit kami.
step = two_way_tf_environment.reset()
for _ in range(10):
action_step = sign_agent.collect_policy.action(step)
next_step = two_way_tf_environment.step(action_step.action)
experience = trajectory_for_bandit(step, action_step, next_step)
print(experience)
sign_agent.train(experience)
step = next_step
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[1]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[0]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[1]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[1.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[2.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[-2]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[4.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[2]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Trajectory(
{'action': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[0]], dtype=int32)>,
'discount': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'next_step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>,
'observation': <tf.Tensor: shape=(1, 1, 1), dtype=int32, numpy=array([[[1]]], dtype=int32)>,
'policy_info': (),
'reward': <tf.Tensor: shape=(1, 1), dtype=float32, numpy=array([[0.]], dtype=float32)>,
'step_type': <tf.Tensor: shape=(1, 1), dtype=int32, numpy=array([[2]], dtype=int32)>})
Dari output dapat dilihat bahwa setelah langkah kedua (kecuali pengamatan adalah 0 pada langkah pertama), kebijakan memilih tindakan dengan cara yang benar dan dengan demikian imbalan yang dikumpulkan selalu non-negatif.
Contoh Bandit Kontekstual Nyata
Dalam sisa tutorial ini, kita menggunakan pra-diterapkan lingkungan dan agen perpustakaan TF-Agen Bandits.
# Imports for example.
from tf_agents.bandits.agents import lin_ucb_agent
from tf_agents.bandits.environments import stationary_stochastic_py_environment as sspe
from tf_agents.bandits.metrics import tf_metrics
from tf_agents.drivers import dynamic_step_driver
from tf_agents.replay_buffers import tf_uniform_replay_buffer
import matplotlib.pyplot as plt
Lingkungan Stochastic Stasioner dengan Fungsi Linier Payoff
Lingkungan yang digunakan dalam contoh ini adalah StationaryStochasticPyEnvironment . Lingkungan ini mengambil parameter a (biasanya berisik) fungsi untuk memberikan pengamatan (konteks), dan untuk setiap lengan mengambil fungsi (juga berisik) yang menghitung hadiah berdasarkan pengamatan yang diberikan. Dalam contoh kami, kami mengambil sampel konteks secara seragam dari kubus d-dimensi, dan fungsi hadiah adalah fungsi linier dari konteks, ditambah beberapa kebisingan Gaussian.
batch_size = 2 # @param
arm0_param = [-3, 0, 1, -2] # @param
arm1_param = [1, -2, 3, 0] # @param
arm2_param = [0, 0, 1, 1] # @param
def context_sampling_fn(batch_size):
"""Contexts from [-10, 10]^4."""
def _context_sampling_fn():
return np.random.randint(-10, 10, [batch_size, 4]).astype(np.float32)
return _context_sampling_fn
class LinearNormalReward(object):
"""A class that acts as linear reward function when called."""
def __init__(self, theta, sigma):
self.theta = theta
self.sigma = sigma
def __call__(self, x):
mu = np.dot(x, self.theta)
return np.random.normal(mu, self.sigma)
arm0_reward_fn = LinearNormalReward(arm0_param, 1)
arm1_reward_fn = LinearNormalReward(arm1_param, 1)
arm2_reward_fn = LinearNormalReward(arm2_param, 1)
environment = tf_py_environment.TFPyEnvironment(
sspe.StationaryStochasticPyEnvironment(
context_sampling_fn(batch_size),
[arm0_reward_fn, arm1_reward_fn, arm2_reward_fn],
batch_size=batch_size))
Agen LinUCB
Agen bawah alat yang LinUCB algoritma.
observation_spec = tensor_spec.TensorSpec([4], tf.float32)
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
dtype=tf.int32, shape=(), minimum=0, maximum=2)
agent = lin_ucb_agent.LinearUCBAgent(time_step_spec=time_step_spec,
action_spec=action_spec)
Metrik Penyesalan
Metrik bandit yang paling penting adalah penyesalan, dihitung sebagai perbedaan antara reward yang dikumpulkan oleh agen dan pahala yang diharapkan dari kebijakan oracle yang memiliki akses ke fungsi reward dari lingkungan. The RegretMetric sehingga membutuhkan fungsi baseline_reward_fn yang menghitung terbaik reward yang diharapkan dapat dicapai diberi observasi. Untuk contoh kita, kita perlu mengambil nilai maksimum dari fungsi penghargaan yang telah kita definisikan untuk lingkungan.
def compute_optimal_reward(observation):
expected_reward_for_arms = [
tf.linalg.matvec(observation, tf.cast(arm0_param, dtype=tf.float32)),
tf.linalg.matvec(observation, tf.cast(arm1_param, dtype=tf.float32)),
tf.linalg.matvec(observation, tf.cast(arm2_param, dtype=tf.float32))]
optimal_action_reward = tf.reduce_max(expected_reward_for_arms, axis=0)
return optimal_action_reward
regret_metric = tf_metrics.RegretMetric(compute_optimal_reward)
Pelatihan
Sekarang kami mengumpulkan semua komponen yang kami perkenalkan di atas: lingkungan, kebijakan, dan agen. Kami menjalankan kebijakan lingkungan dan pelatihan data output dengan bantuan sopir, dan melatih agen pada data.
Perhatikan bahwa ada dua parameter yang bersama-sama menentukan jumlah langkah yang diambil. num_iterations menetapkan berapa kali kita menjalankan loop pelatih, sementara pengemudi akan mengambil steps_per_loop langkah per iterasi. Alasan utama di balik menjaga kedua parameter ini adalah bahwa beberapa operasi dilakukan per iterasi, sementara beberapa dilakukan oleh driver di setiap langkah. Misalnya, agen train fungsi hanya dipanggil sekali per iterasi. Trade-off di sini adalah jika kita berlatih lebih sering maka kebijakan kita "lebih segar", di sisi lain, pelatihan dalam batch yang lebih besar mungkin lebih efisien waktu.
num_iterations = 90 # @param
steps_per_loop = 1 # @param
replay_buffer = tf_uniform_replay_buffer.TFUniformReplayBuffer(
data_spec=agent.policy.trajectory_spec,
batch_size=batch_size,
max_length=steps_per_loop)
observers = [replay_buffer.add_batch, regret_metric]
driver = dynamic_step_driver.DynamicStepDriver(
env=environment,
policy=agent.collect_policy,
num_steps=steps_per_loop * batch_size,
observers=observers)
regret_values = []
for _ in range(num_iterations):
driver.run()
loss_info = agent.train(replay_buffer.gather_all())
replay_buffer.clear()
regret_values.append(regret_metric.result())
plt.plot(regret_values)
plt.ylabel('Average Regret')
plt.xlabel('Number of Iterations')
WARNING:tensorflow:From /tmp/ipykernel_11392/3138849230.py:21: ReplayBuffer.gather_all (from tf_agents.replay_buffers.replay_buffer) is deprecated and will be removed in a future version. Instructions for updating: Use `as_dataset(..., single_deterministic_pass=True)` instead. Text(0.5, 0, 'Number of Iterations')
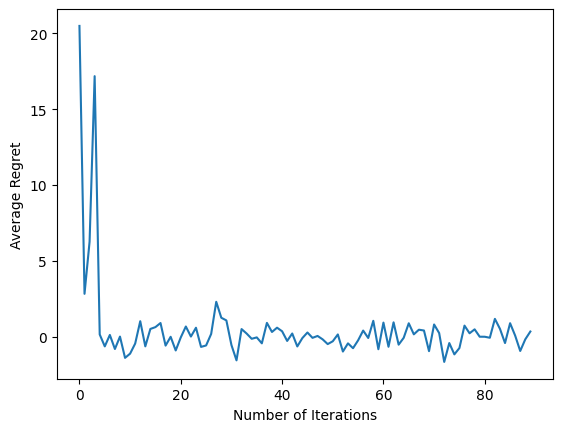
Setelah menjalankan cuplikan kode terakhir, plot yang dihasilkan (semoga) menunjukkan bahwa rata-rata penyesalan menurun saat agen dilatih dan kebijakan menjadi lebih baik dalam menentukan tindakan yang tepat, berdasarkan pengamatan.
Apa berikutnya?
Untuk melihat lebih banyak contoh bekerja, silakan lihat bandit / agen / contoh direktori yang memiliki contoh siap menjalankan untuk agen dan lingkungan.
Library TF-Agents juga mampu menangani Multi-Armed Bandit dengan fitur per-arm. Untuk itu, kita merujuk pembaca untuk per-lengan bandit yang tutorial .