
| | |  Voir la source sur GitHub Voir la source sur GitHub | |
Ce didacticiel présentera les meilleures pratiques recommandées pour les modèles d'entraînement avec confidentialité différentielle au niveau de l'utilisateur à l'aide de Tensorflow Federated. Nous utiliserons l'algorithme DP-SGD de Abadi et al., « Deep apprentissage avec différentiel vie privée » modifiée pour DP-niveau utilisateur dans un contexte fédéré dans McMahan et al., « Récurrente d' apprentissage différentiellement privé langue modèles » .
La confidentialité différentielle (DP) est une méthode largement utilisée pour délimiter et quantifier les fuites de confidentialité des données sensibles lors de l'exécution de tâches d'apprentissage. La formation d'un modèle avec un DP au niveau de l'utilisateur garantit qu'il est peu probable que le modèle apprenne quoi que ce soit d'important sur les données d'un individu, mais peut toujours (espérons-le !) apprendre des modèles qui existent dans les données de nombreux clients.
Nous entraînerons un modèle sur l'ensemble de données EMNIST fédéré. Il existe un compromis inhérent entre l'utilité et la confidentialité, et il peut être difficile de former un modèle avec une confidentialité élevée qui fonctionne aussi bien qu'un modèle non privé de pointe. Par souci d'opportunité dans ce didacticiel, nous nous entraînerons pour seulement 100 tours, sacrifiant une certaine qualité afin de montrer comment s'entraîner avec une grande confidentialité. Si nous utilisions plus de cycles de formation, nous pourrions certainement avoir un modèle privé un peu plus précis, mais pas aussi élevé qu'un modèle formé sans DP.
Avant que nous commencions
Tout d'abord, assurons-nous que le notebook est connecté à un backend qui a compilé les composants pertinents.
!pip install --quiet --upgrade tensorflow_federated_nightly
!pip install --quiet --upgrade nest-asyncio
import nest_asyncio
nest_asyncio.apply()
Certaines importations dont nous aurons besoin pour le tutoriel. Nous utiliserons tensorflow_federated , le cadre open-source pour l' apprentissage de la machine et d' autres calculs sur les données décentralisées, ainsi que tensorflow_privacy , la bibliothèque open source pour la mise en œuvre et l' analyse des algorithmes différentiellement privés tensorflow.
import collections
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_federated as tff
import tensorflow_privacy as tfp
Exécutez l'exemple "Hello World" suivant pour vous assurer que l'environnement TFF est correctement configuré. Si cela ne fonctionne pas, s'il vous plaît se référer à l' installation guide pour les instructions.
@tff.federated_computation
def hello_world():
return 'Hello, World!'
hello_world()
b'Hello, World!'
Téléchargez et prétraitez l'ensemble de données EMNIST fédéré.
def get_emnist_dataset():
emnist_train, emnist_test = tff.simulation.datasets.emnist.load_data(
only_digits=True)
def element_fn(element):
return collections.OrderedDict(
x=tf.expand_dims(element['pixels'], -1), y=element['label'])
def preprocess_train_dataset(dataset):
# Use buffer_size same as the maximum client dataset size,
# 418 for Federated EMNIST
return (dataset.map(element_fn)
.shuffle(buffer_size=418)
.repeat(1)
.batch(32, drop_remainder=False))
def preprocess_test_dataset(dataset):
return dataset.map(element_fn).batch(128, drop_remainder=False)
emnist_train = emnist_train.preprocess(preprocess_train_dataset)
emnist_test = preprocess_test_dataset(
emnist_test.create_tf_dataset_from_all_clients())
return emnist_train, emnist_test
train_data, test_data = get_emnist_dataset()
Définir notre modèle.
def my_model_fn():
model = tf.keras.models.Sequential([
tf.keras.layers.Reshape(input_shape=(28, 28, 1), target_shape=(28 * 28,)),
tf.keras.layers.Dense(200, activation=tf.nn.relu),
tf.keras.layers.Dense(200, activation=tf.nn.relu),
tf.keras.layers.Dense(10)])
return tff.learning.from_keras_model(
keras_model=model,
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
input_spec=test_data.element_spec,
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()])
Déterminer la sensibilité au bruit du modèle.
Pour obtenir des garanties DP au niveau de l'utilisateur, nous devons modifier l'algorithme de base de la moyenne fédérée de deux manières. Premièrement, les mises à jour du modèle des clients doivent être coupées avant la transmission au serveur, limitant l'influence maximale d'un client. Deuxièmement, le serveur doit ajouter suffisamment de bruit à la somme des mises à jour des utilisateurs avant de faire la moyenne pour masquer l'influence du client dans le pire des cas.
Pour écrêtage, nous utilisons la méthode de découpage adaptatif d' Andrew et al. 2021, Différentiellement Apprentissage privé avec Adaptive Clipping , donc pas de norme de découpage doit être explicitement défini.
L'ajout de bruit dégradera en général l'utilité du modèle, mais nous pouvons contrôler la quantité de bruit dans la mise à jour moyenne à chaque tour avec deux boutons : l'écart type du bruit gaussien ajouté à la somme, et le nombre de clients dans le moyenne. Notre stratégie sera d'abord de déterminer la quantité de bruit que le modèle peut tolérer avec un nombre relativement petit de clients par tour avec une perte acceptable pour l'utilité du modèle. Ensuite, pour entraîner le modèle final, nous pouvons augmenter la quantité de bruit dans la somme, tout en augmentant proportionnellement le nombre de clients par tour (en supposant que l'ensemble de données est suffisamment grand pour prendre en charge autant de clients par tour). Il est peu probable que cela affecte significativement la qualité du modèle, puisque le seul effet est de diminuer la variance due à l'échantillonnage des clients (en effet, nous vérifierons que ce n'est pas le cas dans notre cas).
À cette fin, nous formons d'abord une série de modèles avec 50 clients par tour, avec des niveaux de bruit croissants. Plus précisément, nous augmentons le "noise_multiplier" qui est le rapport de l'écart type du bruit à la norme d'écrêtage. Puisque nous utilisons l'écrêtage adaptatif, cela signifie que l'amplitude réelle du bruit change d'un tour à l'autre.
# Run five clients per thread. Increase this if your runtime is running out of
# memory. Decrease it if you have the resources and want to speed up execution.
tff.backends.native.set_local_python_execution_context(clients_per_thread=5)
total_clients = len(train_data.client_ids)
def train(rounds, noise_multiplier, clients_per_round, data_frame):
# Using the `dp_aggregator` here turns on differential privacy with adaptive
# clipping.
aggregation_factory = tff.learning.model_update_aggregator.dp_aggregator(
noise_multiplier, clients_per_round)
# We use Poisson subsampling which gives slightly tighter privacy guarantees
# compared to having a fixed number of clients per round. The actual number of
# clients per round is stochastic with mean clients_per_round.
sampling_prob = clients_per_round / total_clients
# Build a federated averaging process.
# Typically a non-adaptive server optimizer is used because the noise in the
# updates can cause the second moment accumulators to become very large
# prematurely.
learning_process = tff.learning.build_federated_averaging_process(
my_model_fn,
client_optimizer_fn=lambda: tf.keras.optimizers.SGD(0.01),
server_optimizer_fn=lambda: tf.keras.optimizers.SGD(1.0, momentum=0.9),
model_update_aggregation_factory=aggregation_factory)
eval_process = tff.learning.build_federated_evaluation(my_model_fn)
# Training loop.
state = learning_process.initialize()
for round in range(rounds):
if round % 5 == 0:
metrics = eval_process(state.model, [test_data])['eval']
if round < 25 or round % 25 == 0:
print(f'Round {round:3d}: {metrics}')
data_frame = data_frame.append({'Round': round,
'NoiseMultiplier': noise_multiplier,
**metrics}, ignore_index=True)
# Sample clients for a round. Note that if your dataset is large and
# sampling_prob is small, it would be faster to use gap sampling.
x = np.random.uniform(size=total_clients)
sampled_clients = [
train_data.client_ids[i] for i in range(total_clients)
if x[i] < sampling_prob]
sampled_train_data = [
train_data.create_tf_dataset_for_client(client)
for client in sampled_clients]
# Use selected clients for update.
state, metrics = learning_process.next(state, sampled_train_data)
metrics = eval_process(state.model, [test_data])['eval']
print(f'Round {rounds:3d}: {metrics}')
data_frame = data_frame.append({'Round': rounds,
'NoiseMultiplier': noise_multiplier,
**metrics}, ignore_index=True)
return data_frame
data_frame = pd.DataFrame()
rounds = 100
clients_per_round = 50
for noise_multiplier in [0.0, 0.5, 0.75, 1.0]:
print(f'Starting training with noise multiplier: {noise_multiplier}')
data_frame = train(rounds, noise_multiplier, clients_per_round, data_frame)
print()
Starting training with noise multiplier: 0.0
Round 0: OrderedDict([('sparse_categorical_accuracy', 0.112289384), ('loss', 2.5190482)])
Round 5: OrderedDict([('sparse_categorical_accuracy', 0.19075724), ('loss', 2.2449977)])
Round 10: OrderedDict([('sparse_categorical_accuracy', 0.18115693), ('loss', 2.163907)])
Round 15: OrderedDict([('sparse_categorical_accuracy', 0.49970612), ('loss', 2.01017)])
Round 20: OrderedDict([('sparse_categorical_accuracy', 0.5333317), ('loss', 1.8350543)])
Round 25: OrderedDict([('sparse_categorical_accuracy', 0.5828517), ('loss', 1.6551636)])
Round 50: OrderedDict([('sparse_categorical_accuracy', 0.7352077), ('loss', 0.8700141)])
Round 75: OrderedDict([('sparse_categorical_accuracy', 0.7769152), ('loss', 0.6992781)])
Round 100: OrderedDict([('sparse_categorical_accuracy', 0.8049814), ('loss', 0.62453026)])
Starting training with noise multiplier: 0.5
Round 0: OrderedDict([('sparse_categorical_accuracy', 0.09526841), ('loss', 2.4332638)])
Round 5: OrderedDict([('sparse_categorical_accuracy', 0.20128821), ('loss', 2.2664592)])
Round 10: OrderedDict([('sparse_categorical_accuracy', 0.35472178), ('loss', 2.130336)])
Round 15: OrderedDict([('sparse_categorical_accuracy', 0.5480995), ('loss', 1.9713942)])
Round 20: OrderedDict([('sparse_categorical_accuracy', 0.42246276), ('loss', 1.8045483)])
Round 25: OrderedDict([('sparse_categorical_accuracy', 0.624902), ('loss', 1.4785467)])
Round 50: OrderedDict([('sparse_categorical_accuracy', 0.7265625), ('loss', 0.85801566)])
Round 75: OrderedDict([('sparse_categorical_accuracy', 0.77720904), ('loss', 0.70615387)])
Round 100: OrderedDict([('sparse_categorical_accuracy', 0.7702537), ('loss', 0.72331005)])
Starting training with noise multiplier: 0.75
Round 0: OrderedDict([('sparse_categorical_accuracy', 0.098672606), ('loss', 2.422002)])
Round 5: OrderedDict([('sparse_categorical_accuracy', 0.11794671), ('loss', 2.2227976)])
Round 10: OrderedDict([('sparse_categorical_accuracy', 0.3208513), ('loss', 2.083766)])
Round 15: OrderedDict([('sparse_categorical_accuracy', 0.49752644), ('loss', 1.8728142)])
Round 20: OrderedDict([('sparse_categorical_accuracy', 0.5816761), ('loss', 1.6084186)])
Round 25: OrderedDict([('sparse_categorical_accuracy', 0.62896746), ('loss', 1.378527)])
Round 50: OrderedDict([('sparse_categorical_accuracy', 0.73153406), ('loss', 0.8705139)])
Round 75: OrderedDict([('sparse_categorical_accuracy', 0.7789724), ('loss', 0.7113147)])
Round 100: OrderedDict([('sparse_categorical_accuracy', 0.70944357), ('loss', 0.89495045)])
Starting training with noise multiplier: 1.0
Round 0: OrderedDict([('sparse_categorical_accuracy', 0.12002841), ('loss', 2.60482)])
Round 5: OrderedDict([('sparse_categorical_accuracy', 0.104574844), ('loss', 2.3388205)])
Round 10: OrderedDict([('sparse_categorical_accuracy', 0.29966694), ('loss', 2.089262)])
Round 15: OrderedDict([('sparse_categorical_accuracy', 0.4067398), ('loss', 1.9109797)])
Round 20: OrderedDict([('sparse_categorical_accuracy', 0.5123677), ('loss', 1.6472703)])
Round 25: OrderedDict([('sparse_categorical_accuracy', 0.56416535), ('loss', 1.4362282)])
Round 50: OrderedDict([('sparse_categorical_accuracy', 0.62323666), ('loss', 1.1682972)])
Round 75: OrderedDict([('sparse_categorical_accuracy', 0.55968356), ('loss', 1.4779186)])
Round 100: OrderedDict([('sparse_categorical_accuracy', 0.382837), ('loss', 1.9680436)])
Nous pouvons maintenant visualiser la précision de l'ensemble d'évaluation et la perte de ces analyses.
import matplotlib.pyplot as plt
import seaborn as sns
def make_plot(data_frame):
plt.figure(figsize=(15, 5))
dff = data_frame.rename(
columns={'sparse_categorical_accuracy': 'Accuracy', 'loss': 'Loss'})
plt.subplot(121)
sns.lineplot(data=dff, x='Round', y='Accuracy', hue='NoiseMultiplier', palette='dark')
plt.subplot(122)
sns.lineplot(data=dff, x='Round', y='Loss', hue='NoiseMultiplier', palette='dark')
make_plot(data_frame)
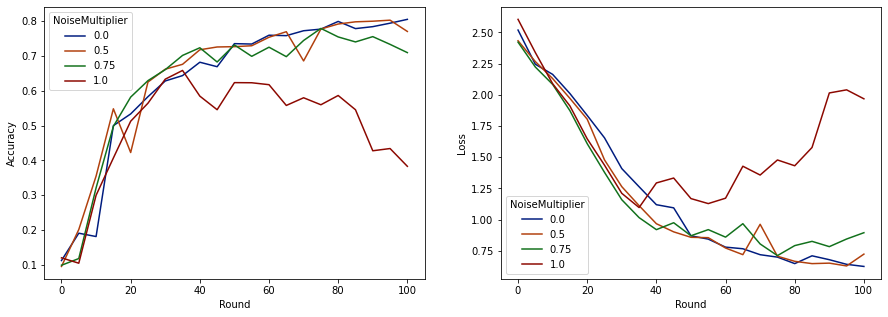
Il apparaît qu'avec 50 clients attendus par tour, ce modèle peut tolérer un multiplicateur de bruit allant jusqu'à 0,5 sans dégrader la qualité du modèle. Un multiplicateur de bruit de 0,75 semble provoquer une légère dégradation du modèle et 1,0 fait diverger le modèle.
Il y a généralement un compromis entre la qualité du modèle et la confidentialité. Plus nous utilisons de bruit, plus nous pouvons obtenir d'intimité pour le même temps d'entraînement et le même nombre de clients. À l'inverse, avec moins de bruit, nous pouvons avoir un modèle plus précis, mais nous devrons nous entraîner avec plus de clients par tour pour atteindre notre niveau de confidentialité cible.
Avec l'expérience ci-dessus, nous pourrions décider que la faible détérioration du modèle à 0,75 est acceptable afin d'entraîner le modèle final plus rapidement, mais supposons que nous voulons égaler les performances du modèle multiplicateur de bruit à 0,5.
Nous pouvons maintenant utiliser les fonctions tensorflow_privacy pour déterminer le nombre de clients attendus par tour dont nous aurions besoin pour obtenir une confidentialité acceptable. La pratique standard consiste à choisir un delta légèrement inférieur à un par rapport au nombre d'enregistrements dans l'ensemble de données. Cet ensemble de données compte 3383 utilisateurs en formation au total, visons donc (2, 1e-5)-DP.
Nous utilisons une simple recherche binaire sur le nombre de clients par tour. La fonction tensorflow_privacy que nous utilisons pour estimer epsilon est basé sur Wang et al. (2018) et Mironov et al. (2019) .
rdp_orders = ([1.25, 1.5, 1.75, 2., 2.25, 2.5, 3., 3.5, 4., 4.5] +
list(range(5, 64)) + [128, 256, 512])
total_clients = 3383
base_noise_multiplier = 0.5
base_clients_per_round = 50
target_delta = 1e-5
target_eps = 2
def get_epsilon(clients_per_round):
# If we use this number of clients per round and proportionally
# scale up the noise multiplier, what epsilon do we achieve?
q = clients_per_round / total_clients
noise_multiplier = base_noise_multiplier
noise_multiplier *= clients_per_round / base_clients_per_round
rdp = tfp.compute_rdp(
q, noise_multiplier=noise_multiplier, steps=rounds, orders=rdp_orders)
eps, _, _ = tfp.get_privacy_spent(rdp_orders, rdp, target_delta=target_delta)
return clients_per_round, eps, noise_multiplier
def find_needed_clients_per_round():
hi = get_epsilon(base_clients_per_round)
if hi[1] < target_eps:
return hi
# Grow interval exponentially until target_eps is exceeded.
while True:
lo = hi
hi = get_epsilon(2 * lo[0])
if hi[1] < target_eps:
break
# Binary search.
while hi[0] - lo[0] > 1:
mid = get_epsilon((lo[0] + hi[0]) // 2)
if mid[1] > target_eps:
lo = mid
else:
hi = mid
return hi
clients_per_round, _, noise_multiplier = find_needed_clients_per_round()
print(f'To get ({target_eps}, {target_delta})-DP, use {clients_per_round} '
f'clients with noise multiplier {noise_multiplier}.')
To get (2, 1e-05)-DP, use 120 clients with noise multiplier 1.2.
Nous pouvons maintenant entraîner notre modèle privé final pour sa sortie.
rounds = 100
noise_multiplier = 1.2
clients_per_round = 120
data_frame = pd.DataFrame()
data_frame = train(rounds, noise_multiplier, clients_per_round, data_frame)
make_plot(data_frame)
Round 0: OrderedDict([('sparse_categorical_accuracy', 0.08260678), ('loss', 2.6334999)])
Round 5: OrderedDict([('sparse_categorical_accuracy', 0.1492212), ('loss', 2.259542)])
Round 10: OrderedDict([('sparse_categorical_accuracy', 0.28847474), ('loss', 2.155699)])
Round 15: OrderedDict([('sparse_categorical_accuracy', 0.3989518), ('loss', 2.0156953)])
Round 20: OrderedDict([('sparse_categorical_accuracy', 0.5086697), ('loss', 1.8261365)])
Round 25: OrderedDict([('sparse_categorical_accuracy', 0.6204692), ('loss', 1.5602393)])
Round 50: OrderedDict([('sparse_categorical_accuracy', 0.70008814), ('loss', 0.91155165)])
Round 75: OrderedDict([('sparse_categorical_accuracy', 0.78421336), ('loss', 0.6820159)])
Round 100: OrderedDict([('sparse_categorical_accuracy', 0.7955525), ('loss', 0.6585961)])
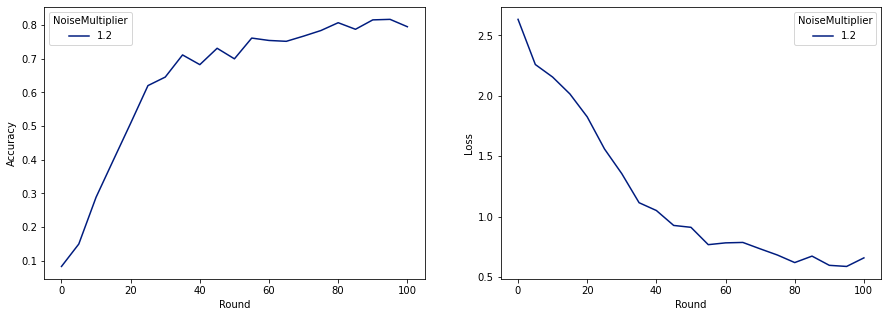
Comme nous pouvons le voir, le modèle final a une perte et une précision similaires au modèle entraîné sans bruit, mais celui-ci satisfait (2, 1e-5)-DP.