
| |  GitHubでソースを表示 GitHubでソースを表示 | |
このチュートリアルでは、TensorflowFederatedを使用してユーザーレベルの差分プライバシーを使用してモデルをトレーニングするための推奨されるベストプラクティスを示します。我々は、DP-SGDアルゴリズムを使用しますアバディら、「差動プライバシーと深い学習」で連合文脈でユーザレベルDP用に変更McMahanら、「学習の差分プライバシー再発言語モデル」 。
差分プライバシー(DP)は、学習タスクを実行するときに機密データのプライバシー漏洩を制限および定量化するために広く使用されている方法です。ユーザーレベルのDPを使用してモデルをトレーニングすると、モデルが個人のデータについて重要なことを学習する可能性は低くなりますが、多くのクライアントのデータに存在するパターンを学習できます(願わくば!)。
フェデレーションEMNISTデータセットでモデルをトレーニングします。効用とプライバシーの間には固有のトレードオフがあり、最新の非プライベートモデルと同様に機能する高いプライバシーを備えたモデルをトレーニングすることは難しい場合があります。このチュートリアルの便宜のために、高いプライバシーでトレーニングする方法を示すために、品質をいくらか犠牲にして、100ラウンドだけトレーニングします。より多くのトレーニングラウンドを使用した場合、確かに多少精度の高いプライベートモデルを使用できますが、DPなしでトレーニングされたモデルほど高くはありません。
始める前に
まず、関連するコンポーネントがコンパイルされたバックエンドにノートブックが接続されていることを確認しましょう。
!pip install --quiet --upgrade tensorflow_federated_nightly
!pip install --quiet --upgrade nest-asyncio
import nest_asyncio
nest_asyncio.apply()
チュートリアルに必要ないくつかのインポート。私たちは、使用するtensorflow_federated 、機械学習と分散型データ上の他の計算だけでなく、ためのオープンソースのフレームワークtensorflow_privacy 、tensorflowに差分プライバシーアルゴリズムを実装し、分析するためのオープンソースのライブラリを。
import collections
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_federated as tff
import tensorflow_privacy as tfp
次の「HelloWorld」の例を実行して、TFF環境が正しくセットアップされていることを確認します。それが動作しない場合は、を参照してください。インストールの手順についてのガイド。
@tff.federated_computation
def hello_world():
return 'Hello, World!'
hello_world()
b'Hello, World!'
フェデレーションEMNISTデータセットをダウンロードして前処理します。
def get_emnist_dataset():
emnist_train, emnist_test = tff.simulation.datasets.emnist.load_data(
only_digits=True)
def element_fn(element):
return collections.OrderedDict(
x=tf.expand_dims(element['pixels'], -1), y=element['label'])
def preprocess_train_dataset(dataset):
# Use buffer_size same as the maximum client dataset size,
# 418 for Federated EMNIST
return (dataset.map(element_fn)
.shuffle(buffer_size=418)
.repeat(1)
.batch(32, drop_remainder=False))
def preprocess_test_dataset(dataset):
return dataset.map(element_fn).batch(128, drop_remainder=False)
emnist_train = emnist_train.preprocess(preprocess_train_dataset)
emnist_test = preprocess_test_dataset(
emnist_test.create_tf_dataset_from_all_clients())
return emnist_train, emnist_test
train_data, test_data = get_emnist_dataset()
モデルを定義します。
def my_model_fn():
model = tf.keras.models.Sequential([
tf.keras.layers.Reshape(input_shape=(28, 28, 1), target_shape=(28 * 28,)),
tf.keras.layers.Dense(200, activation=tf.nn.relu),
tf.keras.layers.Dense(200, activation=tf.nn.relu),
tf.keras.layers.Dense(10)])
return tff.learning.from_keras_model(
keras_model=model,
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
input_spec=test_data.element_spec,
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()])
モデルのノイズ感度を決定します。
ユーザーレベルのDP保証を取得するには、基本的なFederatedAveragingアルゴリズムを2つの方法で変更する必要があります。まず、クライアントのモデルの更新は、サーバーに送信する前にクリップする必要があり、1つのクライアントの最大の影響を制限します。次に、サーバーは、最悪の場合のクライアントの影響を不明瞭にするために、平均化する前にユーザー更新の合計に十分なノイズを追加する必要があります。
クリッピングのために、私たちはの適応クリッピング方法を使用アンドリューら。 2021年、適応クリッピングとの差分プライバシー学習、クリッピングノルムが明示的に設定する必要はありませんので。
ノイズを追加すると、一般にモデルの有用性が低下しますが、合計に追加されたガウスノイズの標準偏差と、平均。私たちの戦略は、最初に、モデルの有用性を許容できる損失で、ラウンドごとに比較的少数のクライアントでモデルが許容できるノイズの量を決定することです。次に、最終モデルをトレーニングするために、ラウンドごとのクライアント数を比例的にスケールアップしながら、合計のノイズ量を増やすことができます(データセットがラウンドごとにその数のクライアントをサポートするのに十分な大きさであると仮定します)。唯一の効果はクライアントのサンプリングによる分散を減らすことであるため、これがモデルの品質に大きな影響を与える可能性は低いです(実際、この場合はそうではないことを確認します)。
そのために、まず、ノイズの量を増やしながら、ラウンドごとに50のクライアントを使用して一連のモデルをトレーニングします。具体的には、クリッピング基準に対するノイズ標準偏差の比率である「noise_multiplier」を増やします。アダプティブクリッピングを使用しているため、これはノイズの実際の大きさがラウンドごとに変化することを意味します。
# Run five clients per thread. Increase this if your runtime is running out of
# memory. Decrease it if you have the resources and want to speed up execution.
tff.backends.native.set_local_python_execution_context(clients_per_thread=5)
total_clients = len(train_data.client_ids)
def train(rounds, noise_multiplier, clients_per_round, data_frame):
# Using the `dp_aggregator` here turns on differential privacy with adaptive
# clipping.
aggregation_factory = tff.learning.model_update_aggregator.dp_aggregator(
noise_multiplier, clients_per_round)
# We use Poisson subsampling which gives slightly tighter privacy guarantees
# compared to having a fixed number of clients per round. The actual number of
# clients per round is stochastic with mean clients_per_round.
sampling_prob = clients_per_round / total_clients
# Build a federated averaging process.
# Typically a non-adaptive server optimizer is used because the noise in the
# updates can cause the second moment accumulators to become very large
# prematurely.
learning_process = tff.learning.build_federated_averaging_process(
my_model_fn,
client_optimizer_fn=lambda: tf.keras.optimizers.SGD(0.01),
server_optimizer_fn=lambda: tf.keras.optimizers.SGD(1.0, momentum=0.9),
model_update_aggregation_factory=aggregation_factory)
eval_process = tff.learning.build_federated_evaluation(my_model_fn)
# Training loop.
state = learning_process.initialize()
for round in range(rounds):
if round % 5 == 0:
metrics = eval_process(state.model, [test_data])['eval']
if round < 25 or round % 25 == 0:
print(f'Round {round:3d}: {metrics}')
data_frame = data_frame.append({'Round': round,
'NoiseMultiplier': noise_multiplier,
**metrics}, ignore_index=True)
# Sample clients for a round. Note that if your dataset is large and
# sampling_prob is small, it would be faster to use gap sampling.
x = np.random.uniform(size=total_clients)
sampled_clients = [
train_data.client_ids[i] for i in range(total_clients)
if x[i] < sampling_prob]
sampled_train_data = [
train_data.create_tf_dataset_for_client(client)
for client in sampled_clients]
# Use selected clients for update.
state, metrics = learning_process.next(state, sampled_train_data)
metrics = eval_process(state.model, [test_data])['eval']
print(f'Round {rounds:3d}: {metrics}')
data_frame = data_frame.append({'Round': rounds,
'NoiseMultiplier': noise_multiplier,
**metrics}, ignore_index=True)
return data_frame
data_frame = pd.DataFrame()
rounds = 100
clients_per_round = 50
for noise_multiplier in [0.0, 0.5, 0.75, 1.0]:
print(f'Starting training with noise multiplier: {noise_multiplier}')
data_frame = train(rounds, noise_multiplier, clients_per_round, data_frame)
print()
Starting training with noise multiplier: 0.0
Round 0: OrderedDict([('sparse_categorical_accuracy', 0.112289384), ('loss', 2.5190482)])
Round 5: OrderedDict([('sparse_categorical_accuracy', 0.19075724), ('loss', 2.2449977)])
Round 10: OrderedDict([('sparse_categorical_accuracy', 0.18115693), ('loss', 2.163907)])
Round 15: OrderedDict([('sparse_categorical_accuracy', 0.49970612), ('loss', 2.01017)])
Round 20: OrderedDict([('sparse_categorical_accuracy', 0.5333317), ('loss', 1.8350543)])
Round 25: OrderedDict([('sparse_categorical_accuracy', 0.5828517), ('loss', 1.6551636)])
Round 50: OrderedDict([('sparse_categorical_accuracy', 0.7352077), ('loss', 0.8700141)])
Round 75: OrderedDict([('sparse_categorical_accuracy', 0.7769152), ('loss', 0.6992781)])
Round 100: OrderedDict([('sparse_categorical_accuracy', 0.8049814), ('loss', 0.62453026)])
Starting training with noise multiplier: 0.5
Round 0: OrderedDict([('sparse_categorical_accuracy', 0.09526841), ('loss', 2.4332638)])
Round 5: OrderedDict([('sparse_categorical_accuracy', 0.20128821), ('loss', 2.2664592)])
Round 10: OrderedDict([('sparse_categorical_accuracy', 0.35472178), ('loss', 2.130336)])
Round 15: OrderedDict([('sparse_categorical_accuracy', 0.5480995), ('loss', 1.9713942)])
Round 20: OrderedDict([('sparse_categorical_accuracy', 0.42246276), ('loss', 1.8045483)])
Round 25: OrderedDict([('sparse_categorical_accuracy', 0.624902), ('loss', 1.4785467)])
Round 50: OrderedDict([('sparse_categorical_accuracy', 0.7265625), ('loss', 0.85801566)])
Round 75: OrderedDict([('sparse_categorical_accuracy', 0.77720904), ('loss', 0.70615387)])
Round 100: OrderedDict([('sparse_categorical_accuracy', 0.7702537), ('loss', 0.72331005)])
Starting training with noise multiplier: 0.75
Round 0: OrderedDict([('sparse_categorical_accuracy', 0.098672606), ('loss', 2.422002)])
Round 5: OrderedDict([('sparse_categorical_accuracy', 0.11794671), ('loss', 2.2227976)])
Round 10: OrderedDict([('sparse_categorical_accuracy', 0.3208513), ('loss', 2.083766)])
Round 15: OrderedDict([('sparse_categorical_accuracy', 0.49752644), ('loss', 1.8728142)])
Round 20: OrderedDict([('sparse_categorical_accuracy', 0.5816761), ('loss', 1.6084186)])
Round 25: OrderedDict([('sparse_categorical_accuracy', 0.62896746), ('loss', 1.378527)])
Round 50: OrderedDict([('sparse_categorical_accuracy', 0.73153406), ('loss', 0.8705139)])
Round 75: OrderedDict([('sparse_categorical_accuracy', 0.7789724), ('loss', 0.7113147)])
Round 100: OrderedDict([('sparse_categorical_accuracy', 0.70944357), ('loss', 0.89495045)])
Starting training with noise multiplier: 1.0
Round 0: OrderedDict([('sparse_categorical_accuracy', 0.12002841), ('loss', 2.60482)])
Round 5: OrderedDict([('sparse_categorical_accuracy', 0.104574844), ('loss', 2.3388205)])
Round 10: OrderedDict([('sparse_categorical_accuracy', 0.29966694), ('loss', 2.089262)])
Round 15: OrderedDict([('sparse_categorical_accuracy', 0.4067398), ('loss', 1.9109797)])
Round 20: OrderedDict([('sparse_categorical_accuracy', 0.5123677), ('loss', 1.6472703)])
Round 25: OrderedDict([('sparse_categorical_accuracy', 0.56416535), ('loss', 1.4362282)])
Round 50: OrderedDict([('sparse_categorical_accuracy', 0.62323666), ('loss', 1.1682972)])
Round 75: OrderedDict([('sparse_categorical_accuracy', 0.55968356), ('loss', 1.4779186)])
Round 100: OrderedDict([('sparse_categorical_accuracy', 0.382837), ('loss', 1.9680436)])
これで、評価セットの精度とそれらの実行の損失を視覚化できます。
import matplotlib.pyplot as plt
import seaborn as sns
def make_plot(data_frame):
plt.figure(figsize=(15, 5))
dff = data_frame.rename(
columns={'sparse_categorical_accuracy': 'Accuracy', 'loss': 'Loss'})
plt.subplot(121)
sns.lineplot(data=dff, x='Round', y='Accuracy', hue='NoiseMultiplier', palette='dark')
plt.subplot(122)
sns.lineplot(data=dff, x='Round', y='Loss', hue='NoiseMultiplier', palette='dark')
make_plot(data_frame)
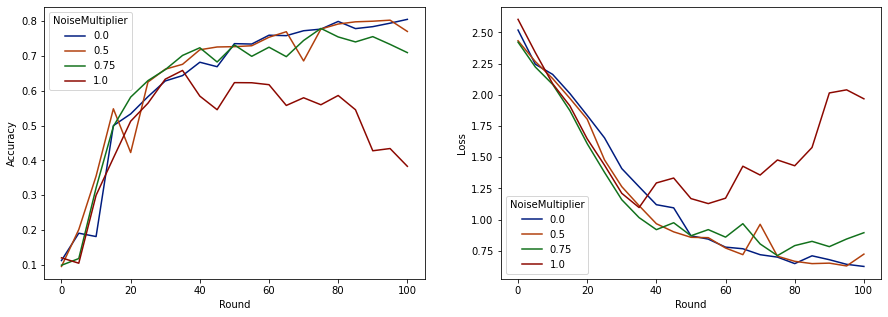
ラウンドごとに50のクライアントが予想されるため、このモデルはモデルの品質を低下させることなく、最大0.5のノイズ乗数を許容できるようです。ノイズ乗数が0.75の場合、モデルが少し劣化するようで、1.0の場合はモデルが発散します。
通常、モデルの品質とプライバシーの間にはトレードオフがあります。使用するノイズが高いほど、同じトレーニング時間とクライアント数でプライバシーを確保できます。逆に、ノイズが少ないほど、より正確なモデルが得られる可能性がありますが、目標のプライバシーレベルに到達するには、ラウンドごとにより多くのクライアントでトレーニングする必要があります。
上記の実験では、最終モデルをより速くトレーニングするために、0.75での少量のモデル劣化が許容できると判断する可能性がありますが、0.5ノイズ乗数モデルのパフォーマンスと一致させたいと仮定します。
これで、tensorflow_privacy関数を使用して、許容可能なプライバシーを取得するために必要な、ラウンドごとに予想されるクライアントの数を決定できます。標準的な方法は、データセット内のレコード数よりもいくらか小さいデルタを選択することです。このデータセットには合計3383人のトレーニングユーザーがいるので、(2、1e-5)-DPを目指しましょう。
ラウンドごとのクライアント数に対して単純な二分探索を使用します。我々はイプシロンを推定するために使用tensorflow_privacy機能が基づいているWangら。 (2018)とミロノフら。 (2019年) 。
rdp_orders = ([1.25, 1.5, 1.75, 2., 2.25, 2.5, 3., 3.5, 4., 4.5] +
list(range(5, 64)) + [128, 256, 512])
total_clients = 3383
base_noise_multiplier = 0.5
base_clients_per_round = 50
target_delta = 1e-5
target_eps = 2
def get_epsilon(clients_per_round):
# If we use this number of clients per round and proportionally
# scale up the noise multiplier, what epsilon do we achieve?
q = clients_per_round / total_clients
noise_multiplier = base_noise_multiplier
noise_multiplier *= clients_per_round / base_clients_per_round
rdp = tfp.compute_rdp(
q, noise_multiplier=noise_multiplier, steps=rounds, orders=rdp_orders)
eps, _, _ = tfp.get_privacy_spent(rdp_orders, rdp, target_delta=target_delta)
return clients_per_round, eps, noise_multiplier
def find_needed_clients_per_round():
hi = get_epsilon(base_clients_per_round)
if hi[1] < target_eps:
return hi
# Grow interval exponentially until target_eps is exceeded.
while True:
lo = hi
hi = get_epsilon(2 * lo[0])
if hi[1] < target_eps:
break
# Binary search.
while hi[0] - lo[0] > 1:
mid = get_epsilon((lo[0] + hi[0]) // 2)
if mid[1] > target_eps:
lo = mid
else:
hi = mid
return hi
clients_per_round, _, noise_multiplier = find_needed_clients_per_round()
print(f'To get ({target_eps}, {target_delta})-DP, use {clients_per_round} '
f'clients with noise multiplier {noise_multiplier}.')
To get (2, 1e-05)-DP, use 120 clients with noise multiplier 1.2.
これで、リリース用に最終的なプライベートモデルをトレーニングできます。
rounds = 100
noise_multiplier = 1.2
clients_per_round = 120
data_frame = pd.DataFrame()
data_frame = train(rounds, noise_multiplier, clients_per_round, data_frame)
make_plot(data_frame)
Round 0: OrderedDict([('sparse_categorical_accuracy', 0.08260678), ('loss', 2.6334999)])
Round 5: OrderedDict([('sparse_categorical_accuracy', 0.1492212), ('loss', 2.259542)])
Round 10: OrderedDict([('sparse_categorical_accuracy', 0.28847474), ('loss', 2.155699)])
Round 15: OrderedDict([('sparse_categorical_accuracy', 0.3989518), ('loss', 2.0156953)])
Round 20: OrderedDict([('sparse_categorical_accuracy', 0.5086697), ('loss', 1.8261365)])
Round 25: OrderedDict([('sparse_categorical_accuracy', 0.6204692), ('loss', 1.5602393)])
Round 50: OrderedDict([('sparse_categorical_accuracy', 0.70008814), ('loss', 0.91155165)])
Round 75: OrderedDict([('sparse_categorical_accuracy', 0.78421336), ('loss', 0.6820159)])
Round 100: OrderedDict([('sparse_categorical_accuracy', 0.7955525), ('loss', 0.6585961)])
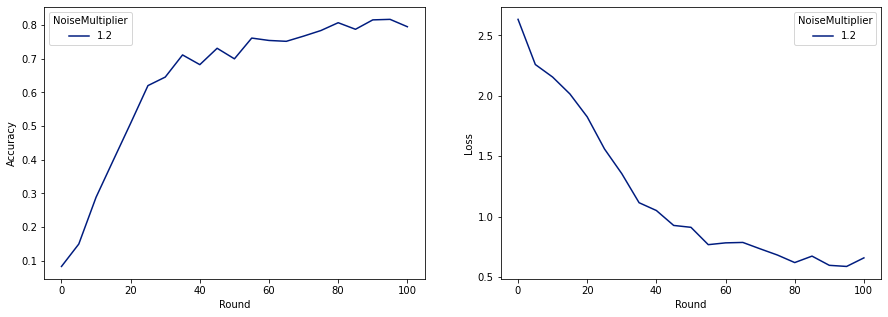
ご覧のとおり、最終モデルの損失と精度は、ノイズなしでトレーニングされたモデルと同様ですが、これは(2、1e-5)-DPを満たしています。