
| | |  Ver fonte no GitHub Ver fonte no GitHub | |
Este tutorial explora aprendizagem federado parcialmente local, onde alguns parâmetros cliente nunca são agregadas no servidor. Isso é útil para modelos com parâmetros específicos do usuário (por exemplo, modelos de fatoração de matriz) e para treinamento em configurações de comunicação limitada. Nós construímos em conceitos introduzidos no Federated Aprendizagem para Imagem Classification tutorial; como no tutorial, vamos introduzir APIs de alto nível em tff.learning para treinamento e avaliação federado.
Começamos por motivar a aprendizagem federado parcialmente local para fatoração de matriz . Descrevemos Federated Reconstrução , um algoritmo prático para a aprendizagem federado parcialmente local em escala. Preparamos o conjunto de dados MovieLens 1M, construímos um modelo parcialmente local e o treinamos e avaliamos.
!pip install --quiet --upgrade tensorflow-federated-nightly
!pip install --quiet --upgrade nest-asyncio
import nest_asyncio
nest_asyncio.apply()
import collections
import functools
import io
import os
import requests
import zipfile
from typing import List, Optional, Tuple
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_federated as tff
np.random.seed(42)
Antecedentes: Fatoração de Matriz
Matrix fatoração tem sido uma técnica historicamente popular para aprender recomendações e incorporação de representações itens com base nas interações do usuário. O exemplo canônico é recomendação de filmes, onde há \(n\) usuários e \(m\) filmes, e os usuários avaliaram alguns filmes. Dado um usuário, usamos seu histórico de classificação e as classificações de usuários semelhantes para prever as classificações do usuário para filmes que não viram. Se tivermos um modelo que pode prever as classificações, é fácil recomendar aos usuários novos filmes que eles vão gostar.
Para esta tarefa, é útil para representar classificações dos usuários como um \(n \times m\) matriz \(R\):

Essa matriz geralmente é esparsa, já que os usuários geralmente veem apenas uma pequena fração dos filmes no conjunto de dados. A saída da matriz é fatoração duas matrizes: um \(n \times k\) matriz \(U\) representando \(k\)embeddings usuário -dimensional para cada utilizador, e um \(m \times k\) matriz \(I\) representando \(k\)embeddings item de -dimensional para cada item. O objetivo do treinamento mais simples é para garantir que o produto escalar de embeddings usuário e item são preditivos de classificações observados \(O\):
\[argmin_{U,I} \sum_{(u, i) \in O} (R_{ui} - U_u I_i^T)^2\]
Isso é equivalente a minimizar o erro quadrático médio entre as classificações observadas e as classificações previstas, pegando o produto escalar do usuário correspondente e os embeddings de itens. Outra maneira para interpretar este é que isto assegura que \(R \approx UI^T\) para classificações conhecidos, portanto, "fatoração matriz". Se isso for confuso, não se preocupe - não precisaremos saber os detalhes da fatoração de matrizes no restante do tutorial.
Explorando Dados do MovieLens
Vamos começar por carregar os MovieLens 1M de dados, que consiste em 1,000,209 classificação dos filmes de 6040 usuários em 3706 filmes.
def download_movielens_data(dataset_path):
"""Downloads and copies MovieLens data to local /tmp directory."""
if dataset_path.startswith('http'):
r = requests.get(dataset_path)
z = zipfile.ZipFile(io.BytesIO(r.content))
z.extractall(path='/tmp')
else:
tf.io.gfile.makedirs('/tmp/ml-1m/')
for filename in ['ratings.dat', 'movies.dat', 'users.dat']:
tf.io.gfile.copy(
os.path.join(dataset_path, filename),
os.path.join('/tmp/ml-1m/', filename),
overwrite=True)
download_movielens_data('http://files.grouplens.org/datasets/movielens/ml-1m.zip')
def load_movielens_data(
data_directory: str = "/tmp",
) -> Tuple[pd.DataFrame, pd.DataFrame]:
"""Loads pandas DataFrames for ratings, movies, users from data directory."""
# Load pandas DataFrames from data directory. Assuming data is formatted as
# specified in http://files.grouplens.org/datasets/movielens/ml-1m-README.txt.
ratings_df = pd.read_csv(
os.path.join(data_directory, "ml-1m", "ratings.dat"),
sep="::",
names=["UserID", "MovieID", "Rating", "Timestamp"], engine="python")
movies_df = pd.read_csv(
os.path.join(data_directory, "ml-1m", "movies.dat"),
sep="::",
names=["MovieID", "Title", "Genres"], engine="python")
# Create dictionaries mapping from old IDs to new (remapped) IDs for both
# MovieID and UserID. Use the movies and users present in ratings_df to
# determine the mapping, since movies and users without ratings are unneeded.
movie_mapping = {
old_movie: new_movie for new_movie, old_movie in enumerate(
ratings_df.MovieID.astype("category").cat.categories)
}
user_mapping = {
old_user: new_user for new_user, old_user in enumerate(
ratings_df.UserID.astype("category").cat.categories)
}
# Map each DataFrame consistently using the now-fixed mapping.
ratings_df.MovieID = ratings_df.MovieID.map(movie_mapping)
ratings_df.UserID = ratings_df.UserID.map(user_mapping)
movies_df.MovieID = movies_df.MovieID.map(movie_mapping)
# Remove nulls resulting from some movies being in movies_df but not
# ratings_df.
movies_df = movies_df[pd.notnull(movies_df.MovieID)]
return ratings_df, movies_df
Vamos carregar e explorar alguns DataFrames do Pandas contendo a classificação e os dados do filme.
ratings_df, movies_df = load_movielens_data()
Podemos ver que cada exemplo de classificação tem uma classificação de 1 a 5, um UserID correspondente, um MovieID correspondente e um carimbo de data / hora.
ratings_df.head()
Cada filme tem um título e potencialmente vários gêneros.
movies_df.head()
É sempre uma boa ideia entender as estatísticas básicas do conjunto de dados:
print('Num users:', len(set(ratings_df.UserID)))
print('Num movies:', len(set(ratings_df.MovieID)))
Num users: 6040 Num movies: 3706
ratings = ratings_df.Rating.tolist()
plt.hist(ratings, bins=5)
plt.xticks([1, 2, 3, 4, 5])
plt.ylabel('Count')
plt.xlabel('Rating')
plt.show()
print('Average rating:', np.mean(ratings))
print('Median rating:', np.median(ratings))
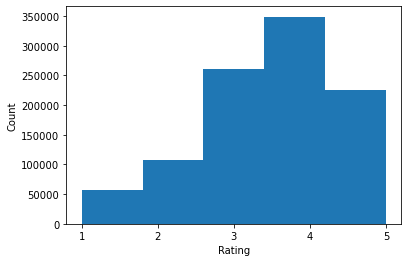
Average rating: 3.581564453029317 Median rating: 4.0
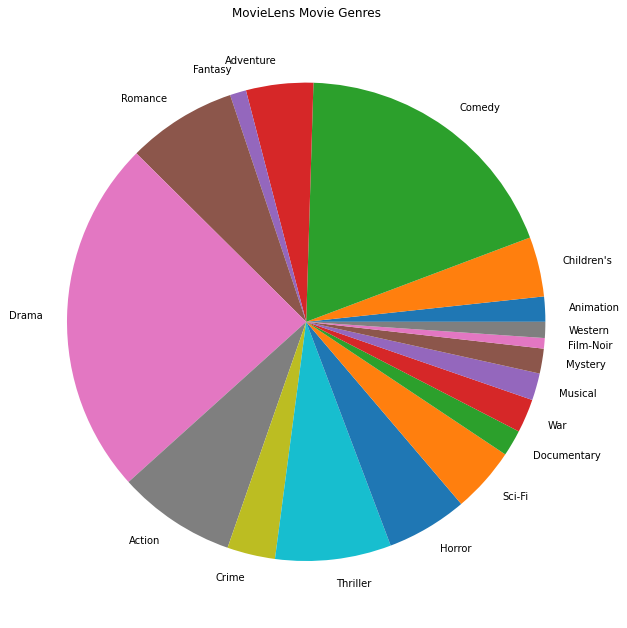
Também podemos traçar os gêneros de filmes mais populares.
movie_genres_list = movies_df.Genres.tolist()
# Count the number of times each genre describes a movie.
genre_count = collections.defaultdict(int)
for genres in movie_genres_list:
curr_genres_list = genres.split('|')
for genre in curr_genres_list:
genre_count[genre] += 1
genre_name_list, genre_count_list = zip(*genre_count.items())
plt.figure(figsize=(11, 11))
plt.pie(genre_count_list, labels=genre_name_list)
plt.title('MovieLens Movie Genres')
plt.show()
Esses dados são naturalmente particionados em classificações de diferentes usuários, portanto, esperamos alguma heterogeneidade nos dados entre os clientes. Abaixo, exibimos os gêneros de filmes mais comumente avaliados para diferentes usuários. Podemos observar diferenças significativas entre os usuários.
def print_top_genres_for_user(ratings_df, movies_df, user_id):
"""Prints top movie genres for user with ID user_id."""
user_ratings_df = ratings_df[ratings_df.UserID == user_id]
movie_ids = user_ratings_df.MovieID
genre_count = collections.Counter()
for movie_id in movie_ids:
genres_string = movies_df[movies_df.MovieID == movie_id].Genres.tolist()[0]
for genre in genres_string.split('|'):
genre_count[genre] += 1
print(f'\nFor user {user_id}:')
for (genre, freq) in genre_count.most_common(5):
print(f'{genre} was rated {freq} times')
print_top_genres_for_user(ratings_df, movies_df, user_id=0)
print_top_genres_for_user(ratings_df, movies_df, user_id=10)
print_top_genres_for_user(ratings_df, movies_df, user_id=19)
For user 0: Drama was rated 21 times Children's was rated 20 times Animation was rated 18 times Musical was rated 14 times Comedy was rated 14 times For user 10: Comedy was rated 84 times Drama was rated 54 times Romance was rated 22 times Thriller was rated 18 times Action was rated 9 times For user 19: Action was rated 17 times Sci-Fi was rated 9 times Thriller was rated 9 times Drama was rated 6 times Crime was rated 5 times
Pré-processamento de dados MovieLens
Vamos agora preparar o conjunto de dados MovieLens como uma lista de tf.data.Dataset s representando os dados de cada usuário para uso com TFF.
Implementamos duas funções:
-
create_tf_datasets: leva nossos ratings trama de dados e produz uma lista de user-splittf.data.Datasets. -
split_tf_datasets: pega uma lista de conjuntos de dados e divide em trem / val / teste por usuário, de modo que os / conjuntos de teste val conter apenas as classificações de usuários invisíveis durante o treinamento. Normalmente na fatoração de matriz centralizado padrão que realmente dividida de modo que os conjuntos val / teste contêm avaliações realizadas-out de usuários atendidos, desde que os usuários invisíveis não têm embeddings usuário. Em nosso caso, veremos mais tarde que a abordagem que usamos para habilitar a fatoração de matriz em FL também permite reconstruir rapidamente embeddings de usuário para usuários invisíveis.
def create_tf_datasets(ratings_df: pd.DataFrame,
batch_size: int = 1,
max_examples_per_user: Optional[int] = None,
max_clients: Optional[int] = None) -> List[tf.data.Dataset]:
"""Creates TF Datasets containing the movies and ratings for all users."""
num_users = len(set(ratings_df.UserID))
# Optionally limit to `max_clients` to speed up data loading.
if max_clients is not None:
num_users = min(num_users, max_clients)
def rating_batch_map_fn(rating_batch):
"""Maps a rating batch to an OrderedDict with tensor values."""
# Each example looks like: {x: movie_id, y: rating}.
# We won't need the UserID since each client will only look at their own
# data.
return collections.OrderedDict([
("x", tf.cast(rating_batch[:, 1:2], tf.int64)),
("y", tf.cast(rating_batch[:, 2:3], tf.float32))
])
tf_datasets = []
for user_id in range(num_users):
# Get subset of ratings_df belonging to a particular user.
user_ratings_df = ratings_df[ratings_df.UserID == user_id]
tf_dataset = tf.data.Dataset.from_tensor_slices(user_ratings_df)
# Define preprocessing operations.
tf_dataset = tf_dataset.take(max_examples_per_user).shuffle(
buffer_size=max_examples_per_user, seed=42).batch(batch_size).map(
rating_batch_map_fn,
num_parallel_calls=tf.data.experimental.AUTOTUNE)
tf_datasets.append(tf_dataset)
return tf_datasets
def split_tf_datasets(
tf_datasets: List[tf.data.Dataset],
train_fraction: float = 0.8,
val_fraction: float = 0.1,
) -> Tuple[List[tf.data.Dataset], List[tf.data.Dataset], List[tf.data.Dataset]]:
"""Splits a list of user TF datasets into train/val/test by user.
"""
np.random.seed(42)
np.random.shuffle(tf_datasets)
train_idx = int(len(tf_datasets) * train_fraction)
val_idx = int(len(tf_datasets) * (train_fraction + val_fraction))
# Note that the val and test data contains completely different users, not
# just unseen ratings from train users.
return (tf_datasets[:train_idx], tf_datasets[train_idx:val_idx],
tf_datasets[val_idx:])
# We limit the number of clients to speed up dataset creation. Feel free to pass
# max_clients=None to load all clients' data.
tf_datasets = create_tf_datasets(
ratings_df=ratings_df,
batch_size=5,
max_examples_per_user=300,
max_clients=2000)
# Split the ratings into training/val/test by client.
tf_train_datasets, tf_val_datasets, tf_test_datasets = split_tf_datasets(
tf_datasets,
train_fraction=0.8,
val_fraction=0.1)
Para uma verificação rápida, podemos imprimir um lote de dados de treinamento. Podemos ver que cada exemplo individual contém um MovieID na tecla "x" e uma classificação na tecla "y". Observe que não precisaremos do UserID, pois cada usuário vê apenas seus próprios dados.
print(next(iter(tf_train_datasets[0])))
OrderedDict([('x', <tf.Tensor: shape=(5, 1), dtype=int64, numpy=
array([[1907],
[2891],
[1574],
[2785],
[2775]])>), ('y', <tf.Tensor: shape=(5, 1), dtype=float32, numpy=
array([[3.],
[3.],
[3.],
[4.],
[3.]], dtype=float32)>)])
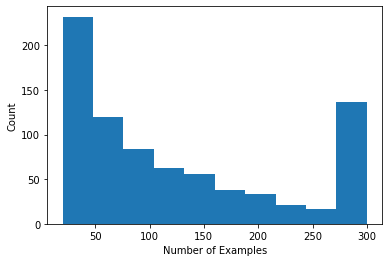
Podemos traçar um histograma mostrando o número de avaliações por usuário.
def count_examples(curr_count, batch):
return curr_count + tf.size(batch['x'])
num_examples_list = []
# Compute number of examples for every other user.
for i in range(0, len(tf_train_datasets), 2):
num_examples = tf_train_datasets[i].reduce(tf.constant(0), count_examples).numpy()
num_examples_list.append(num_examples)
plt.hist(num_examples_list, bins=10)
plt.ylabel('Count')
plt.xlabel('Number of Examples')
plt.show()
Agora que carregamos e exploramos os dados, discutiremos como trazer a fatoração de matrizes para o aprendizado federado. Ao longo do caminho, vamos motivar o aprendizado federado parcialmente local.
Trazendo a Fatoração de Matriz para FL
Embora a fatoração de matriz tenha sido tradicionalmente usada em configurações centralizadas, é especialmente relevante no aprendizado federado: as classificações do usuário podem residir em dispositivos de cliente separados e podemos querer aprender embeddings e recomendações para usuários e itens sem centralizar os dados. Uma vez que cada usuário tem uma incorporação de usuário correspondente, é natural que cada cliente armazene sua incorporação de usuário - isso é muito melhor escalável do que um servidor central que armazena todas as incorporação de usuário.
Uma proposta para trazer a fatoração de matriz para FL é a seguinte:
- O servidor armazena e envia a matriz item de \(I\) aos clientes amostrados cada rodada
- Clientes atualizar a matriz item e seu utilizador pessoal incorporando \(U_u\) usando SGD no objectivo acima
- Atualizações para \(I\) são agregados no servidor, atualizando a cópia do servidor do \(I\) para a próxima rodada
Esta abordagem é parcialmente local, isto é, alguns parâmetros cliente nunca são agregadas pelo servidor. Embora essa abordagem seja atraente, ela requer que os clientes mantenham o estado em todas as rodadas, ou seja, seus embeddings de usuário. Algoritmos federados com monitoração de estado são menos apropriados para configurações FL entre dispositivos: nessas configurações, o tamanho da população costuma ser muito maior do que o número de clientes que participam de cada rodada, e um cliente geralmente participa no máximo uma vez durante o processo de treinamento. Além de depender de estado que não pode ser inicializado, algoritmos stateful pode resultar em degradação do desempenho em ambientes de vários dispositivos devido ao estado ficando obsoleto quando os clientes raramente são amostrados. É importante ressaltar que na configuração de fatoração de matriz, um algoritmo stateful leva a todos os clientes invisíveis perdendo embeddings de usuários treinados e, em treinamento em grande escala, a maioria dos usuários pode ser invisível. Para mais informações sobre a motivação para algoritmos sem estado em corte dispositivo FL, ver Wang et al. 2021 Sec. 3.1.1 e Reddi et al. 2020 seg. 5.1 .
Federados Reconstrução ( Singhal et al. 2021 ) é uma alternativa sem estado para a abordagem acima mencionada. A ideia principal é que, em vez de armazenar os embeddings do usuário em rodadas, os clientes reconstroem os embeddings do usuário quando necessário. Quando o FedRecon é aplicado à fatoração da matriz, o treinamento prossegue da seguinte forma:
- O servidor armazena e envia a matriz item de \(I\) aos clientes amostrados cada rodada
- Cada cliente congela \(I\) e treina o seu utilizador incorporação \(U_u\) utilizando um ou mais passos de SGD (reconstrução)
- Cada cliente congela \(U_u\) e trens \(I\) usando uma ou mais etapas de SGD
- Atualizações para \(I\) são agregados entre os usuários, atualizar a cópia do servidor do \(I\) para a próxima rodada
Essa abordagem não exige que os clientes mantenham o estado entre as rodadas. Os autores também mostram no artigo que este método leva à reconstrução rápida de embeddings de usuário para clientes invisíveis (Seção 4.2, Fig. 3 e Tabela 1), permitindo que a maioria dos clientes que não participam do treinamento tenham um modelo treinado , permitindo recomendações para esses clientes.
Definindo o modelo
A seguir, definiremos o modelo de fatoração de matriz local a ser treinado em dispositivos clientes. Este modelo irá incluir a matriz artigo completo \(I\) e um usuário de incorporação único \(U_u\) para o cliente \(u\). Note-se que os clientes não vai precisar para armazenar a matriz de usuário completa \(U\).
Vamos definir o seguinte:
-
UserEmbedding: uma camada simples Keras representando um úniconum_latent_factorsincorporação utilizador -dimensional. -
get_matrix_factorization_model: uma função que retorna umtff.learning.reconstruction.Modelcontendo a lógica do modelo, incluindo as camadas a serem globalmente agregadas no servidor e quais camadas permanecem local. Precisamos dessas informações adicionais para inicializar o processo de treinamento de Reconstrução Federada. Aqui nós produzimos otff.learning.reconstruction.Modelde um modelo Keras usandotff.learning.reconstruction.from_keras_model. Semelhante aotff.learning.Model, também podemos implementar um costumetff.learning.reconstruction.Modelimplementando a interface de classe.
class UserEmbedding(tf.keras.layers.Layer):
"""Keras layer representing an embedding for a single user, used below."""
def __init__(self, num_latent_factors, **kwargs):
super().__init__(**kwargs)
self.num_latent_factors = num_latent_factors
def build(self, input_shape):
self.embedding = self.add_weight(
shape=(1, self.num_latent_factors),
initializer='uniform',
dtype=tf.float32,
name='UserEmbeddingKernel')
super().build(input_shape)
def call(self, inputs):
return self.embedding
def compute_output_shape(self):
return (1, self.num_latent_factors)
def get_matrix_factorization_model(
num_items: int,
num_latent_factors: int) -> tff.learning.reconstruction.Model:
"""Defines a Keras matrix factorization model."""
# Layers with variables will be partitioned into global and local layers.
# We'll pass this to `tff.learning.reconstruction.from_keras_model`.
global_layers = []
local_layers = []
# Extract the item embedding.
item_input = tf.keras.layers.Input(shape=[1], name='Item')
item_embedding_layer = tf.keras.layers.Embedding(
num_items,
num_latent_factors,
name='ItemEmbedding')
global_layers.append(item_embedding_layer)
flat_item_vec = tf.keras.layers.Flatten(name='FlattenItems')(
item_embedding_layer(item_input))
# Extract the user embedding.
user_embedding_layer = UserEmbedding(
num_latent_factors,
name='UserEmbedding')
local_layers.append(user_embedding_layer)
# The item_input never gets used by the user embedding layer,
# but this allows the model to directly use the user embedding.
flat_user_vec = user_embedding_layer(item_input)
# Compute the dot product between the user embedding, and the item one.
pred = tf.keras.layers.Dot(
1, normalize=False, name='Dot')([flat_user_vec, flat_item_vec])
input_spec = collections.OrderedDict(
x=tf.TensorSpec(shape=[None, 1], dtype=tf.int64),
y=tf.TensorSpec(shape=[None, 1], dtype=tf.float32))
model = tf.keras.Model(inputs=item_input, outputs=pred)
return tff.learning.reconstruction.from_keras_model(
keras_model=model,
global_layers=global_layers,
local_layers=local_layers,
input_spec=input_spec)
Análogo à interface para Federated Média, a interface para Federated Reconstrução espera um model_fn sem argumentos que retorna um tff.learning.reconstruction.Model .
# This will be used to produce our training process.
# User and item embeddings will be 50-dimensional.
model_fn = functools.partial(
get_matrix_factorization_model,
num_items=3706,
num_latent_factors=50)
Vamos próxima definir loss_fn e metrics_fn , onde loss_fn é uma função sem argumentos retornando uma perda Keras usar para treinar o modelo, e metrics_fn é uma função sem argumentos retornar uma lista de métricas Keras para avaliação. Eles são necessários para construir os cálculos de treinamento e avaliação.
Usaremos o erro médio quadrático como a perda, conforme mencionado acima. Para avaliação, usaremos a precisão da classificação (quando o produto escalar previsto do modelo é arredondado para o número inteiro mais próximo, com que frequência ele corresponde à classificação do rótulo?).
class RatingAccuracy(tf.keras.metrics.Mean):
"""Keras metric computing accuracy of reconstructed ratings."""
def __init__(self,
name: str = 'rating_accuracy',
**kwargs):
super().__init__(name=name, **kwargs)
def update_state(self,
y_true: tf.Tensor,
y_pred: tf.Tensor,
sample_weight: Optional[tf.Tensor] = None):
absolute_diffs = tf.abs(y_true - y_pred)
# A [batch_size, 1] tf.bool tensor indicating correctness within the
# threshold for each example in a batch. A 0.5 threshold corresponds
# to correctness when predictions are rounded to the nearest whole
# number.
example_accuracies = tf.less_equal(absolute_diffs, 0.5)
super().update_state(example_accuracies, sample_weight=sample_weight)
loss_fn = lambda: tf.keras.losses.MeanSquaredError()
metrics_fn = lambda: [RatingAccuracy()]
Treinamento e Avaliação
Agora temos tudo o que precisamos para definir o processo de treinamento. Uma diferença importante entre a interface para Federated Média é que agora passar em um reconstruction_optimizer_fn , que será usado para a reconstrução parâmetros locais (no nosso caso, embeddings usuário). Em geral, é razoável usar SGD aqui, com um similar ou ligeiramente menor taxa de aprendizagem do que o cliente otimizador de taxa de aprendizagem. Fornecemos uma configuração de trabalho abaixo. Isso não foi ajustado cuidadosamente, então sinta-se à vontade para brincar com valores diferentes.
Confira a documentação para mais detalhes e opções.
# We'll use this by doing:
# state = training_process.initialize()
# state, metrics = training_process.next(state, federated_train_data)
training_process = tff.learning.reconstruction.build_training_process(
model_fn=model_fn,
loss_fn=loss_fn,
metrics_fn=metrics_fn,
server_optimizer_fn=lambda: tf.keras.optimizers.SGD(1.0),
client_optimizer_fn=lambda: tf.keras.optimizers.SGD(0.5),
reconstruction_optimizer_fn=lambda: tf.keras.optimizers.SGD(0.1))
Também podemos definir um cálculo para avaliar nosso modelo global treinado.
# We'll use this by doing:
# eval_metrics = evaluation_computation(state.model, tf_val_datasets)
# where `state` is the state from the training process above.
evaluation_computation = tff.learning.reconstruction.build_federated_evaluation(
model_fn,
loss_fn=loss_fn,
metrics_fn=metrics_fn,
reconstruction_optimizer_fn=functools.partial(
tf.keras.optimizers.SGD, 0.1))
Podemos inicializar o estado do processo de treinamento e examiná-lo. Mais importante, podemos ver que este estado do servidor armazena apenas variáveis de item (atualmente inicializadas aleatoriamente) e não quaisquer embeddings de usuário.
state = training_process.initialize()
print(state.model)
print('Item variables shape:', state.model.trainable[0].shape)
ModelWeights(trainable=[array([[-0.02840446, 0.01196523, -0.01864688, ..., 0.03020107,
0.00121176, 0.00146852],
[ 0.01330637, 0.04741272, -0.01487445, ..., -0.03352419,
0.0104811 , 0.03506917],
[-0.04132779, 0.04883525, -0.04799002, ..., 0.00246904,
0.00586842, 0.01506213],
...,
[ 0.0216659 , 0.00734354, 0.00471039, ..., 0.01596491,
-0.00220431, -0.01559857],
[-0.00319657, -0.01740328, 0.02808609, ..., -0.00501985,
-0.03850871, -0.03844522],
[ 0.03791947, -0.00035037, 0.04217024, ..., 0.00365371,
0.00283421, 0.00897921]], dtype=float32)], non_trainable=[])
Item variables shape: (3706, 50)
Também podemos tentar avaliar nosso modelo inicializado aleatoriamente em clientes de validação. A avaliação da reconstrução federada aqui envolve o seguinte:
- O servidor envia a matriz item de \(I\) para clientes de avaliação amostrados
- Cada cliente congela \(I\) e treina o seu utilizador incorporação \(U_u\) utilizando um ou mais passos de SGD (reconstrução)
- Cada perda e métricas calcula cliente usando o servidor \(I\) e reconstruído \(U_u\) em uma parte invisível de seus dados locais
- As perdas e métricas são calculadas entre os usuários para calcular a perda geral e métricas
Observe que as etapas 1 e 2 são iguais às do treinamento. Esta ligação é importante, pois a formação da mesma forma que avaliar leva a uma forma de meta-aprendizagem, ou aprender a aprender. Neste caso, o modelo está aprendendo como aprender variáveis globais (matriz de item) que levam à reconstrução de desempenho de variáveis locais (embeddings de usuário). Para saber mais sobre isso, ver Sec. 4.2 do papel.
Também é importante que as etapas 2 e 3 sejam realizadas usando partes separadas dos dados locais dos clientes, para garantir uma avaliação justa. Por padrão, tanto o processo de treinamento quanto o cálculo de avaliação usam todos os outros exemplos para reconstrução e usam a outra metade após a reconstrução. Este comportamento pode ser personalizado usando o dataset_split_fn argumento (vamos explorar isso mais adiante).
# We shouldn't expect good evaluation results here, since we haven't trained
# yet!
eval_metrics = evaluation_computation(state.model, tf_val_datasets)
print('Initial Eval:', eval_metrics['eval'])
Initial Eval: OrderedDict([('loss', 14.340279), ('rating_accuracy', 0.0)])
Em seguida, podemos tentar uma rodada de treinamento. Para tornar as coisas mais realistas, vamos amostrar 50 clientes por rodada aleatoriamente, sem reposição. Ainda devemos esperar que as métricas de treinamento sejam ruins, já que estamos fazendo apenas uma rodada de treinamento.
federated_train_data = np.random.choice(tf_train_datasets, size=50, replace=False).tolist()
state, metrics = training_process.next(state, federated_train_data)
print(f'Train metrics:', metrics['train'])
Train metrics: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.317455)])
Agora vamos configurar um loop de treinamento para treinar em várias rodadas.
NUM_ROUNDS = 20
train_losses = []
train_accs = []
state = training_process.initialize()
# This may take a couple minutes to run.
for i in range(NUM_ROUNDS):
federated_train_data = np.random.choice(tf_train_datasets, size=50, replace=False).tolist()
state, metrics = training_process.next(state, federated_train_data)
print(f'Train round {i}:', metrics['train'])
train_losses.append(metrics['train']['loss'])
train_accs.append(metrics['train']['rating_accuracy'])
eval_metrics = evaluation_computation(state.model, tf_val_datasets)
print('Final Eval:', eval_metrics['eval'])
Train round 0: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.7013445)])
Train round 1: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.459233)])
Train round 2: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.52466)])
Train round 3: OrderedDict([('rating_accuracy', 0.0), ('loss', 14.087793)])
Train round 4: OrderedDict([('rating_accuracy', 0.011243612), ('loss', 11.110232)])
Train round 5: OrderedDict([('rating_accuracy', 0.06366048), ('loss', 8.267054)])
Train round 6: OrderedDict([('rating_accuracy', 0.12331288), ('loss', 5.2693872)])
Train round 7: OrderedDict([('rating_accuracy', 0.14264487), ('loss', 5.1511016)])
Train round 8: OrderedDict([('rating_accuracy', 0.21046545), ('loss', 3.8246362)])
Train round 9: OrderedDict([('rating_accuracy', 0.21320973), ('loss', 3.303812)])
Train round 10: OrderedDict([('rating_accuracy', 0.21651311), ('loss', 3.4864292)])
Train round 11: OrderedDict([('rating_accuracy', 0.23476052), ('loss', 3.0105433)])
Train round 12: OrderedDict([('rating_accuracy', 0.21981856), ('loss', 3.1807854)])
Train round 13: OrderedDict([('rating_accuracy', 0.27683082), ('loss', 2.3382564)])
Train round 14: OrderedDict([('rating_accuracy', 0.26080742), ('loss', 2.7009728)])
Train round 15: OrderedDict([('rating_accuracy', 0.2733109), ('loss', 2.2993557)])
Train round 16: OrderedDict([('rating_accuracy', 0.29282996), ('loss', 2.5278995)])
Train round 17: OrderedDict([('rating_accuracy', 0.30204678), ('loss', 2.060092)])
Train round 18: OrderedDict([('rating_accuracy', 0.2940266), ('loss', 2.0976772)])
Train round 19: OrderedDict([('rating_accuracy', 0.3086304), ('loss', 2.0626144)])
Final Eval: OrderedDict([('loss', 1.9961331), ('rating_accuracy', 0.30322924)])
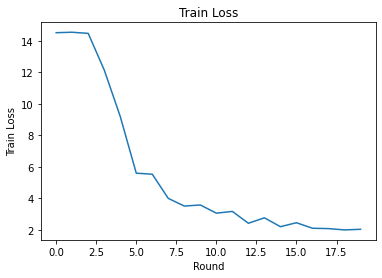
Podemos traçar a perda e a precisão do treinamento ao longo das rodadas. Os hiperparâmetros neste bloco de notas não foram ajustados cuidadosamente, então sinta-se à vontade para experimentar diferentes clientes por rodada, taxas de aprendizagem, número de rodadas e número total de clientes para melhorar esses resultados.
plt.plot(range(NUM_ROUNDS), train_losses)
plt.ylabel('Train Loss')
plt.xlabel('Round')
plt.title('Train Loss')
plt.show()
plt.plot(range(NUM_ROUNDS), train_accs)
plt.ylabel('Train Accuracy')
plt.xlabel('Round')
plt.title('Train Accuracy')
plt.show()
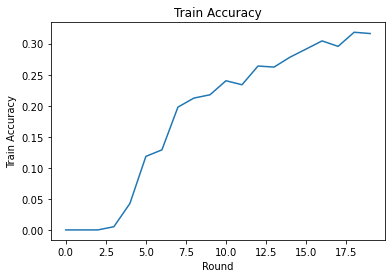
Finalmente, podemos calcular as métricas em um conjunto de teste invisível quando terminarmos de ajustar.
eval_metrics = evaluation_computation(state.model, tf_test_datasets)
print('Final Test:', eval_metrics['eval'])
Final Test: OrderedDict([('loss', 1.9566978), ('rating_accuracy', 0.30792442)])
Explorações Adicionais
Bom trabalho ao completar este bloco de notas. Sugerimos os seguintes exercícios para explorar mais a aprendizagem federada localmente, aproximadamente ordenada por dificuldade crescente:
Implementações típicas de Federated Averaging levam várias passagens locais (épocas) sobre os dados (além de fazer uma passagem sobre os dados em vários lotes). Para a reconstrução federada, podemos controlar o número de etapas separadamente para a reconstrução e o treinamento pós-reconstrução. Passando o
dataset_split_fnargumento para a formação e avaliação construtores de computação permite controlar o número de passos e épocas mais de dois reconstrução e pós-reconstrução conjuntos de dados. Como exercício, tente realizar 3 épocas locais de treinamento de reconstrução, com limite de 50 etapas e 1 época local de treinamento pós-reconstrução, com limite de 50 etapas. DICA: Você vai encontrartff.learning.reconstruction.build_dataset_split_fnútil. Depois de fazer isso, tente ajustar esses hiperparâmetros e outros relacionados, como taxas de aprendizagem e tamanho do lote, para obter melhores resultados.O comportamento padrão do treinamento e avaliação da Reconstrução Federada é dividir os dados locais dos clientes pela metade para cada reconstrução e pós-reconstrução. Nos casos em que os clientes têm muito poucos dados locais, pode ser razoável reutilizar os dados para reconstrução e pós-reconstrução apenas para o processo de treinamento (não para avaliação, isso levará a uma avaliação injusta). Tente fazer esta mudança para o processo de formação, garantindo a
dataset_split_fnpara avaliação ainda mantém reconstrução e pós-reconstrução disjuntos dados. Dica:tff.learning.reconstruction.simple_dataset_split_fnpode ser útil.Acima, produziu um
tff.learning.Modelde um modelo Keras usandotff.learning.reconstruction.from_keras_model. Nós também pode implementar um modelo personalizado usando puro TensorFlow 2,0 por implementar a interface modelo . Tente modificarget_matrix_factorization_modelpara construir e retornar uma classe que estendetff.learning.reconstruction.Model, a implementação de seus métodos. Dica: o código fonte detff.learning.reconstruction.from_keras_modelfornece um exemplo de estender otff.learning.reconstruction.Modelclasse. Consulte também a implementação do modelo personalizado na classificação de imagens EMNIST tutorial para um exercício semelhante em estender umtff.learning.Model.Neste tutorial, motivamos o aprendizado federado parcialmente local no contexto da fatoração de matriz, em que o envio de embeddings do usuário para o servidor vazaria trivialmente as preferências do usuário. Também podemos aplicar a Reconstrução Federada em outras configurações como uma forma de treinar modelos mais pessoais (já que parte do modelo é totalmente local para cada usuário) enquanto reduz a comunicação (já que os parâmetros locais não são enviados ao servidor). Em geral, usando a interface apresentada aqui, podemos pegar qualquer modelo federado que normalmente seria totalmente treinado globalmente e, em vez disso, particionar suas variáveis em variáveis globais e variáveis locais. O exemplo explorado no papel Federated Reconstrução é a previsão da próxima palavra pessoal: aqui, cada usuário tem seu próprio conjunto local de embeddings palavra para palavras fora do vocabulário, permitindo que o modelo a gíria dos usuários de captura e alcançar personalização sem comunicação adicional. Como exercício, tente implementar (como um modelo Keras ou um modelo personalizado do TensorFlow 2.0) um modelo diferente para usar com a reconstrução federada. Uma sugestão: implemente um modelo de classificação EMNIST com uma incorporação de usuário pessoal, onde a incorporação de usuário pessoal é concatenada aos recursos de imagem CNN antes da última camada Densa do modelo. Você pode reutilizar grande parte do código deste tutorial (por exemplo, o
UserEmbeddingclasse) ea imagem de classificação tutorial .
Se você ainda está procurando mais na aprendizagem federado parcialmente local, verificar o papel Federated Reconstrução e open-source código da experiência .