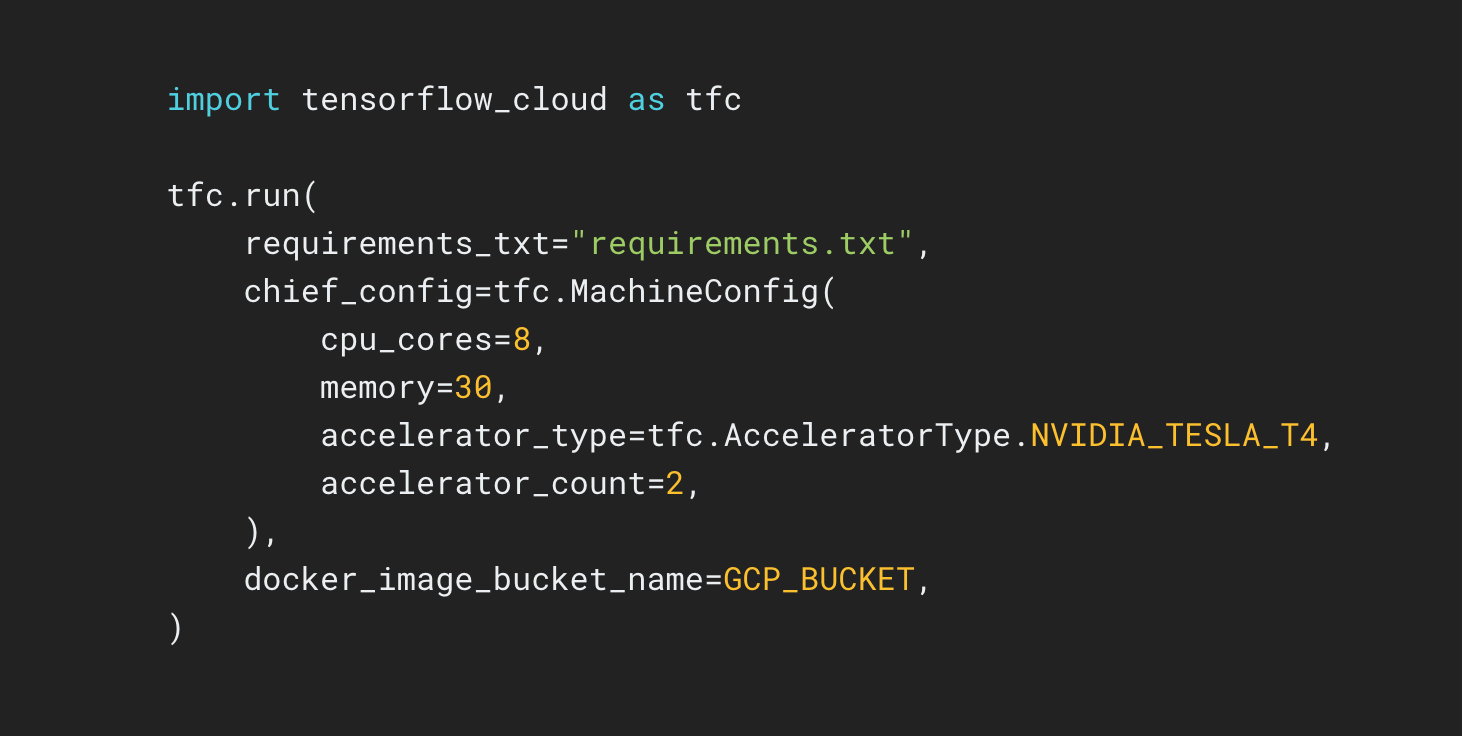
TensorFlow Cloud est une bibliothèque permettant de connecter votre environnement local à Google Cloud.
import tensorflow_cloud as tfc TF_GPU_IMAGE= "tensorflow/tensorflow:latest-gpu" run_parameters = [ distribution_strategy='auto', requirements_txt='requirements.txt', docker_config=tfc.DockerConfig( parent_image=TF_GPU_IMAGE, image_build_bucket=GCS_BUCKET ), chief_config=tfc.COMMON_MACHINE_CONFIGS['K80_1X'], worker_config=tfc.COMMON_MACHINE_CONFIGS['K80_1X'], worker_count=3, job_labels={'job': "my_job"} ] run(**run_parameters) # Runs your training on Google Cloud!
Le dépôt TensorFlow Cloud fournit des API qui facilitent la transition des opérations locales de création et de débogage des modèles vers un entraînement et un réglage des hyperparamètres distribués sur Google Cloud. Vous pouvez envoyer votre modèle depuis un notebook Colab ou Kaggle ou un fichier de script local pour l'entraîner ou le paramétrer directement sur Google Cloud, sans avoir à utiliser Cloud Console.