
| | |  Voir la source sur GitHub Voir la source sur GitHub | |
Aperçu
Ce tutoriel est un aperçu des contraintes et des régularisations fournies par la bibliothèque TensorFlow Lattice (TFL). Ici, nous utilisons des estimateurs prédéfinis TFL sur des ensembles de données synthétiques, mais notez que tout dans ce didacticiel peut également être fait avec des modèles construits à partir de couches TFL Keras.
Avant de continuer, assurez-vous que votre environnement d'exécution a tous les packages requis installés (tels qu'importés dans les cellules de code ci-dessous).
Installer
Installation du package TF Lattice :
pip install -q tensorflow-lattice
Importation des packages requis :
import tensorflow as tf
from IPython.core.pylabtools import figsize
import itertools
import logging
import matplotlib
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
import sys
import tensorflow_lattice as tfl
logging.disable(sys.maxsize)
Valeurs par défaut utilisées dans ce guide :
NUM_EPOCHS = 1000
BATCH_SIZE = 64
LEARNING_RATE=0.01
Ensemble de données d'entraînement pour le classement des restaurants
Imaginez un scénario simplifié où nous voulons déterminer si les utilisateurs cliqueront ou non sur un résultat de recherche de restaurant. La tâche consiste à prédire le taux de clics (CTR) en fonction des caractéristiques d'entrée :
- Note moyenne (
avg_rating): une fonction numérique avec des valeurs dans l'intervalle [1,5]. - Nombre d'évaluations (
num_reviews): une fonction numérique avec des valeurs plafonnées à 200, que nous utilisons comme mesure de branchitude. - Évaluation du dollar (
dollar_rating): une caractéristique catégorique avec les valeurs de chaîne dans l'ensemble { "D", "DD", "DDD", "DDDD"}.
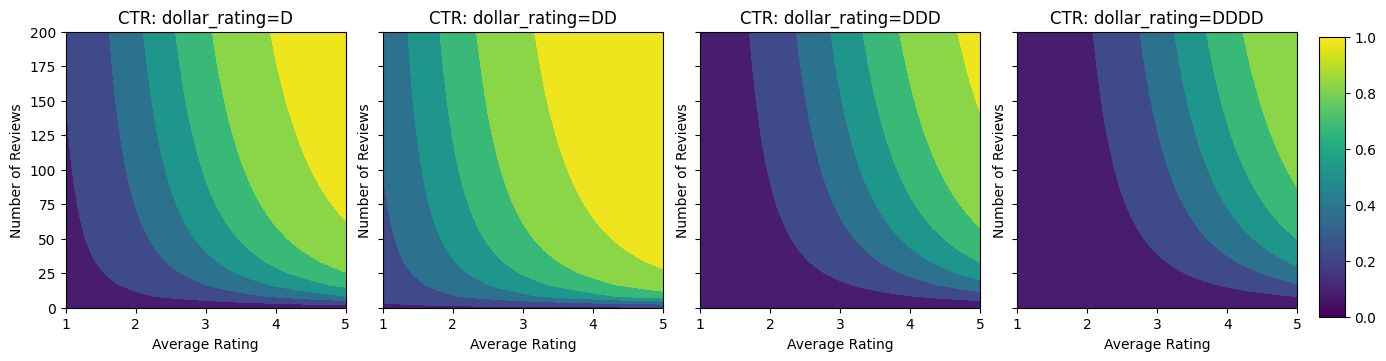
Ici, nous créons un ensemble de données synthétiques où le vrai CTR est donné par la formule :
\[ CTR = 1 / (1 + exp\{\mbox{b(dollar_rating)}-\mbox{avg_rating}\times log(\mbox{num_reviews}) /4 \}) \]
où \(b(\cdot)\) se traduit par dollar_rating à une valeur de référence:
\[ \mbox{D}\to 3,\ \mbox{DD}\to 2,\ \mbox{DDD}\to 4,\ \mbox{DDDD}\to 4.5. \]
Cette formule reflète les modèles d'utilisateurs typiques. par exemple, étant donné que tout le reste est corrigé, les utilisateurs préfèrent les restaurants avec un nombre d'étoiles plus élevé et les restaurants "\$\$" recevront plus de clics que "\$", suivis de "\$\$\$" et "\$\$\$ \$".
def click_through_rate(avg_ratings, num_reviews, dollar_ratings):
dollar_rating_baseline = {"D": 3, "DD": 2, "DDD": 4, "DDDD": 4.5}
return 1 / (1 + np.exp(
np.array([dollar_rating_baseline[d] for d in dollar_ratings]) -
avg_ratings * np.log1p(num_reviews) / 4))
Jetons un coup d'œil aux tracés de contour de cette fonction CTR.
def color_bar():
bar = matplotlib.cm.ScalarMappable(
norm=matplotlib.colors.Normalize(0, 1, True),
cmap="viridis",
)
bar.set_array([0, 1])
return bar
def plot_fns(fns, split_by_dollar=False, res=25):
"""Generates contour plots for a list of (name, fn) functions."""
num_reviews, avg_ratings = np.meshgrid(
np.linspace(0, 200, num=res),
np.linspace(1, 5, num=res),
)
if split_by_dollar:
dollar_rating_splits = ["D", "DD", "DDD", "DDDD"]
else:
dollar_rating_splits = [None]
if len(fns) == 1:
fig, axes = plt.subplots(2, 2, sharey=True, tight_layout=False)
else:
fig, axes = plt.subplots(
len(dollar_rating_splits), len(fns), sharey=True, tight_layout=False)
axes = axes.flatten()
axes_index = 0
for dollar_rating_split in dollar_rating_splits:
for title, fn in fns:
if dollar_rating_split is not None:
dollar_ratings = np.repeat(dollar_rating_split, res**2)
values = fn(avg_ratings.flatten(), num_reviews.flatten(),
dollar_ratings)
title = "{}: dollar_rating={}".format(title, dollar_rating_split)
else:
values = fn(avg_ratings.flatten(), num_reviews.flatten())
subplot = axes[axes_index]
axes_index += 1
subplot.contourf(
avg_ratings,
num_reviews,
np.reshape(values, (res, res)),
vmin=0,
vmax=1)
subplot.title.set_text(title)
subplot.set(xlabel="Average Rating")
subplot.set(ylabel="Number of Reviews")
subplot.set(xlim=(1, 5))
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
figsize(11, 11)
plot_fns([("CTR", click_through_rate)], split_by_dollar=True)
Préparation des données
Nous devons maintenant créer nos jeux de données synthétiques. Nous commençons par générer un jeu de données simulé de restaurants et de leurs caractéristiques.
def sample_restaurants(n):
avg_ratings = np.random.uniform(1.0, 5.0, n)
num_reviews = np.round(np.exp(np.random.uniform(0.0, np.log(200), n)))
dollar_ratings = np.random.choice(["D", "DD", "DDD", "DDDD"], n)
ctr_labels = click_through_rate(avg_ratings, num_reviews, dollar_ratings)
return avg_ratings, num_reviews, dollar_ratings, ctr_labels
np.random.seed(42)
avg_ratings, num_reviews, dollar_ratings, ctr_labels = sample_restaurants(2000)
figsize(5, 5)
fig, axs = plt.subplots(1, 1, sharey=False, tight_layout=False)
for rating, marker in [("D", "o"), ("DD", "^"), ("DDD", "+"), ("DDDD", "x")]:
plt.scatter(
x=avg_ratings[np.where(dollar_ratings == rating)],
y=num_reviews[np.where(dollar_ratings == rating)],
c=ctr_labels[np.where(dollar_ratings == rating)],
vmin=0,
vmax=1,
marker=marker,
label=rating)
plt.xlabel("Average Rating")
plt.ylabel("Number of Reviews")
plt.legend()
plt.xlim((1, 5))
plt.title("Distribution of restaurants")
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
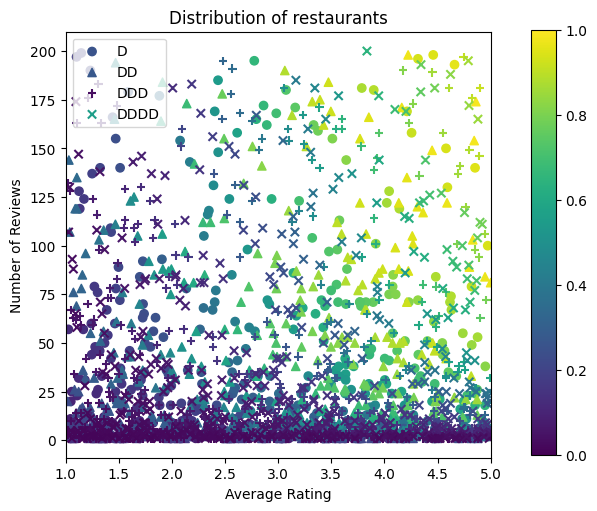
Produisons les ensembles de données d'entraînement, de validation et de test. Lorsqu'un restaurant est affiché dans les résultats de la recherche, nous pouvons enregistrer l'engagement de l'utilisateur (clic ou pas de clic) en tant que point d'échantillon.
Dans la pratique, les utilisateurs ne parcourent souvent pas tous les résultats de recherche. Cela signifie que les utilisateurs ne verront probablement que les restaurants déjà considérés comme « bons » par le modèle de classement actuellement utilisé. En conséquence, les « bons » restaurants sont plus fréquemment impressionnés et surreprésentés dans les ensembles de données d'apprentissage. Lorsque vous utilisez plus de fonctionnalités, l'ensemble de données d'apprentissage peut présenter des lacunes importantes dans les « mauvaises » parties de l'espace des fonctionnalités.
Lorsque le modèle est utilisé pour le classement, il est souvent évalué sur tous les résultats pertinents avec une distribution plus uniforme qui n'est pas bien représentée par l'ensemble de données d'apprentissage. Un modèle flexible et compliqué pourrait échouer dans ce cas en raison du surajustement des points de données surreprésentés et donc manquer de généralisabilité. Nous traitons ce problème en appliquant les connaissances de domaine pour ajouter des contraintes de forme qui guident le modèle pour faire des prévisions raisonnables quand il ne peut pas les chercher à l'ensemble de données de formation.
Dans cet exemple, l'ensemble de données de formation se compose principalement d'interactions d'utilisateurs avec de bons restaurants populaires. L'ensemble de données de test a une distribution uniforme pour simuler le paramètre d'évaluation discuté ci-dessus. Notez qu'un tel ensemble de données de test ne sera pas disponible dans un contexte de problème réel.
def sample_dataset(n, testing_set):
(avg_ratings, num_reviews, dollar_ratings, ctr_labels) = sample_restaurants(n)
if testing_set:
# Testing has a more uniform distribution over all restaurants.
num_views = np.random.poisson(lam=3, size=n)
else:
# Training/validation datasets have more views on popular restaurants.
num_views = np.random.poisson(lam=ctr_labels * num_reviews / 50.0, size=n)
return pd.DataFrame({
"avg_rating": np.repeat(avg_ratings, num_views),
"num_reviews": np.repeat(num_reviews, num_views),
"dollar_rating": np.repeat(dollar_ratings, num_views),
"clicked": np.random.binomial(n=1, p=np.repeat(ctr_labels, num_views))
})
# Generate datasets.
np.random.seed(42)
data_train = sample_dataset(500, testing_set=False)
data_val = sample_dataset(500, testing_set=False)
data_test = sample_dataset(500, testing_set=True)
# Plotting dataset densities.
figsize(12, 5)
fig, axs = plt.subplots(1, 2, sharey=False, tight_layout=False)
for ax, data, title in [(axs[0], data_train, "training"),
(axs[1], data_test, "testing")]:
_, _, _, density = ax.hist2d(
x=data["avg_rating"],
y=data["num_reviews"],
bins=(np.linspace(1, 5, num=21), np.linspace(0, 200, num=21)),
density=True,
cmap="Blues",
)
ax.set(xlim=(1, 5))
ax.set(ylim=(0, 200))
ax.set(xlabel="Average Rating")
ax.set(ylabel="Number of Reviews")
ax.title.set_text("Density of {} examples".format(title))
_ = fig.colorbar(density, ax=ax)

Définition de input_fns utilisé pour la formation et l'évaluation :
train_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
shuffle=False,
)
# feature_analysis_input_fn is used for TF Lattice estimators.
feature_analysis_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
val_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_val,
y=data_val["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
test_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_test,
y=data_test["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
Ajustement d'arbres améliorés par gradient
Commençons avec seulement deux caractéristiques: avg_rating et num_reviews .
Nous créons quelques fonctions auxiliaires pour tracer et calculer les métriques de validation et de test.
def analyze_two_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def two_d_pred(avg_ratings, num_reviews):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
def two_d_click_through_rate(avg_ratings, num_reviews):
return np.mean([
click_through_rate(avg_ratings, num_reviews,
np.repeat(d, len(avg_ratings)))
for d in ["D", "DD", "DDD", "DDDD"]
],
axis=0)
figsize(11, 5)
plot_fns([("{} Estimated CTR".format(name), two_d_pred),
("CTR", two_d_click_through_rate)],
split_by_dollar=False)
Nous pouvons insérer des arbres de décision TensorFlow boostés par gradient sur l'ensemble de données :
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
gbt_estimator = tf.estimator.BoostedTreesClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
n_batches_per_layer=1,
max_depth=2,
n_trees=50,
learning_rate=0.05,
config=tf.estimator.RunConfig(tf_random_seed=42),
)
gbt_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(gbt_estimator, "GBT")
Validation AUC: 0.6333084106445312 Testing AUC: 0.774649977684021

Même si le modèle a capturé la forme générale du vrai CTR et a des métriques de validation décentes, il a un comportement contre-intuitif dans plusieurs parties de l'espace d'entrée : le CTR estimé diminue à mesure que la note moyenne ou le nombre d'avis augmente. Cela est dû à un manque de points d'échantillonnage dans les zones non bien couvertes par l'ensemble de données d'apprentissage. Le modèle n'a tout simplement aucun moyen de déduire le comportement correct uniquement à partir des données.
Pour résoudre ce problème, nous appliquons la contrainte de forme selon laquelle le modèle doit produire des valeurs augmentant de manière monotone en ce qui concerne à la fois la note moyenne et le nombre d'avis. Nous verrons plus tard comment implémenter cela dans TFL.
Installer un DNN
Nous pouvons répéter les mêmes étapes avec un classificateur DNN. Nous pouvons observer un schéma similaire : ne pas avoir suffisamment de points d'échantillonnage avec un petit nombre d'examens entraîne une extrapolation absurde. Notez que même si la métrique de validation est meilleure que la solution arborescente, la métrique de test est bien pire.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
dnn_estimator = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
hidden_units=[16, 8, 8],
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
dnn_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(dnn_estimator, "DNN")
Validation AUC: 0.6696228981018066 Testing AUC: 0.750156044960022

Contraintes de forme
TensorFlow Lattice (TFL) se concentre sur l'application de contraintes de forme pour protéger le comportement du modèle au-delà des données d'apprentissage. Ces contraintes de forme sont appliquées aux couches TFL Keras. Leurs coordonnées se trouvent dans notre papier JMLR .
Dans ce didacticiel, nous utilisons des estimateurs prédéfinis TF pour couvrir diverses contraintes de forme, mais notez que toutes ces étapes peuvent être effectuées avec des modèles créés à partir de couches TFL Keras.
Comme avec tout autre estimateur de tensorflow, estimateurs utilisent TFL mis en conserve des colonnes de fonction pour définir le format d'entrée et d' utiliser un input_fn de formation pour passer dans les données. L'utilisation d'estimateurs pré-programmés TFL nécessite également :
- une configuration de modèle: définir l'architecture du modèle et des contraintes de forme et par-fonction régularisations.
- une analyse de la fonction input_fn: une TF input_fn transmettre des données d'initialisation TFL.
Pour une description plus détaillée, veuillez vous référer au didacticiel des estimateurs en conserve ou à la documentation de l'API.
Monotonie
Nous abordons d'abord les problèmes de monotonie en ajoutant des contraintes de forme de monotonie aux deux caractéristiques.
De charger TFL de faire respecter les contraintes de forme, nous précisons les contraintes dans les caractéristiques configs. Le code suivant montre comment nous pouvons exiger la production d'augmenter de façon monotone par rapport aux deux num_reviews et avg_rating en réglant monotonicity="increasing" .
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
Validation AUC: 0.6565533876419067 Testing AUC: 0.7784258723258972

L' utilisation d' un CalibratedLatticeConfig crée un classificateur en conserve qui applique d' abord un calibreur à chaque entrée (une fonction linéaire par morceaux pour les fonctions numériques) suivie d'une couche de réseau de façon non linéaire les éléments fusibles calibrés. Nous pouvons utiliser tfl.visualization pour visualiser le modèle. En particulier, le graphique suivant montre les deux calibrateurs entraînés inclus dans le classificateur en conserve.
def save_and_visualize_lattice(tfl_estimator):
saved_model_path = tfl_estimator.export_saved_model(
"/tmp/TensorFlow_Lattice_101/",
tf.estimator.export.build_parsing_serving_input_receiver_fn(
feature_spec=tf.feature_column.make_parse_example_spec(
feature_columns)))
model_graph = tfl.estimators.get_model_graph(saved_model_path)
figsize(8, 8)
tfl.visualization.draw_model_graph(model_graph)
return model_graph
_ = save_and_visualize_lattice(tfl_estimator)

Avec les contraintes ajoutées, le CTR estimé augmentera toujours à mesure que la note moyenne augmente ou que le nombre d'avis augmente. Ceci est fait en s'assurant que les calibrateurs et le réseau sont monotones.
Rendements décroissants
Les rendements décroissants signifie que le gain marginal de plus en plus une certaine valeur de caractéristique diminue à mesure que l' on augmente la valeur. Dans notre cas , nous attendons à ce que la num_reviews fonction suit ce modèle, afin que nous puissions configurer en conséquence son calibrateur. Notez que nous pouvons décomposer les rendements décroissants en deux conditions suffisantes :
- le calibrateur augmente de façon monotone, et
- le calibreur est concave.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891247272491455
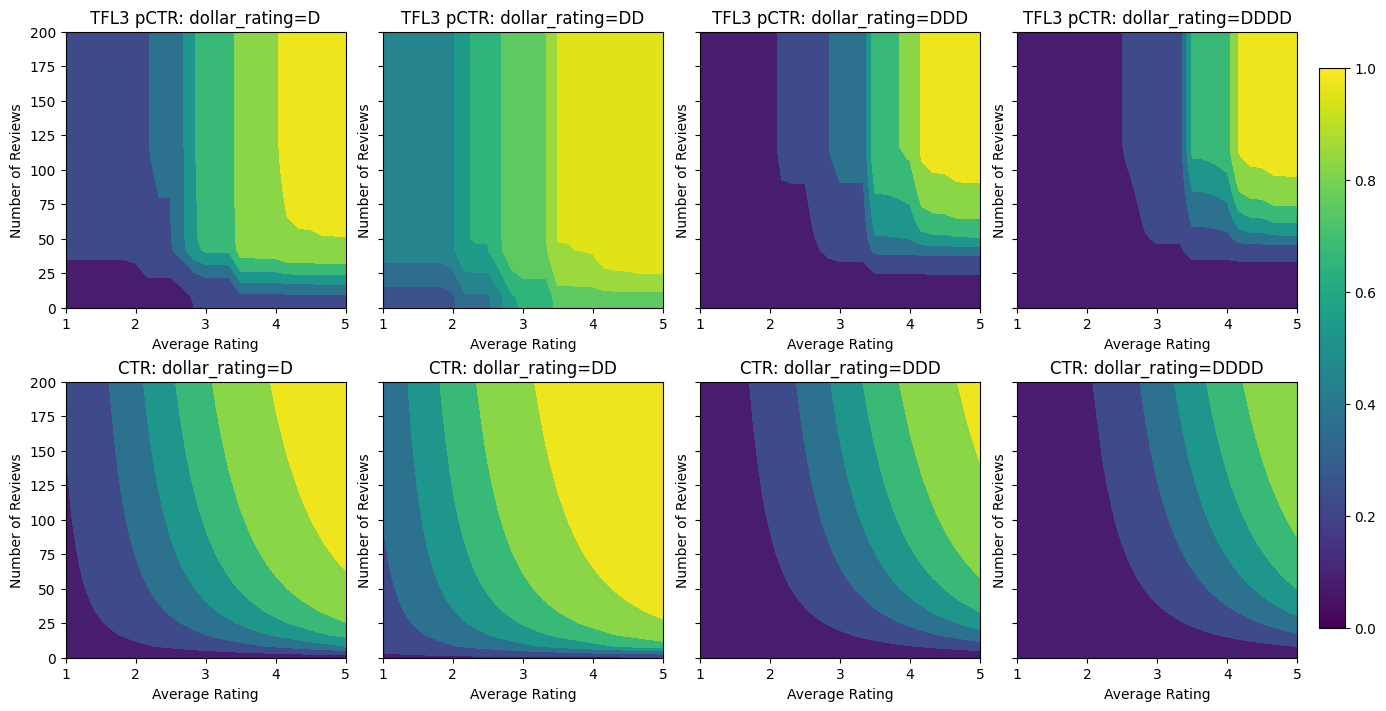

Remarquez comment la métrique de test s'améliore en ajoutant la contrainte de concavité. Le tracé de prédiction ressemble également mieux à la vérité terrain.
Contrainte de forme 2D : confiance
Une note de 5 étoiles pour un restaurant avec seulement une ou deux critiques est probablement une note peu fiable (le restaurant peut ne pas être bon), alors qu'une note de 4 étoiles pour un restaurant avec des centaines de critiques est beaucoup plus fiable (le restaurant est probablement bon dans ce cas). Nous pouvons voir que le nombre de critiques d'un restaurant affecte la confiance que nous accordons à sa note moyenne.
Nous pouvons exercer des contraintes de confiance TFL pour informer le modèle que la valeur plus grande (ou plus petite) d'une caractéristique indique plus de confiance ou de confiance envers une autre caractéristique. Cela se fait par la mise en reflects_trust_in configuration dans la configuration de la fonction.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
# Larger num_reviews indicating more trust in avg_rating.
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
model_graph = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891043424606323
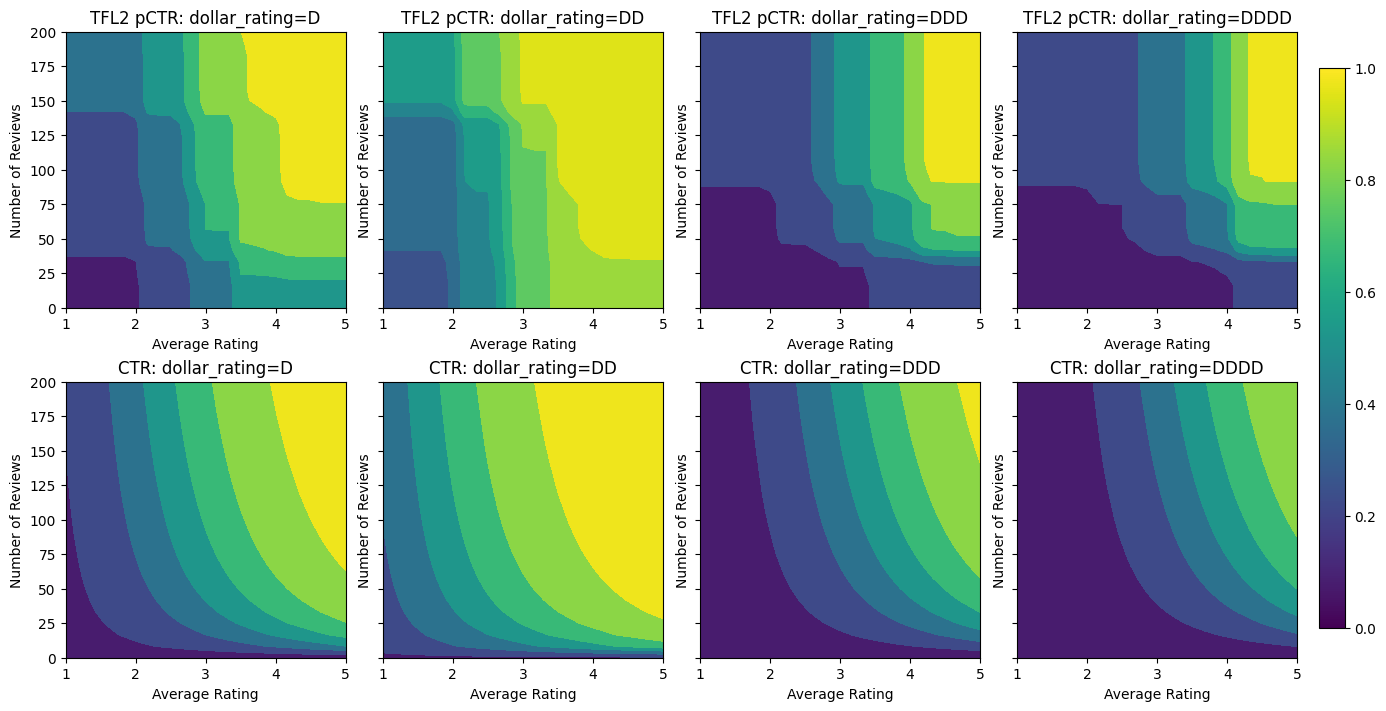

Le graphique suivant présente la fonction de réseau entraînée. En raison de la contrainte de confiance, nous nous attendons à ce que les plus grandes valeurs calibrées num_reviews forceraient pente supérieure par rapport à étalonnée avg_rating , entraînant un mouvement plus important dans la sortie réseau.
lat_mesh_n = 12
lat_mesh_x, lat_mesh_y = tfl.test_utils.two_dim_mesh_grid(
lat_mesh_n**2, 0, 0, 1, 1)
lat_mesh_fn = tfl.test_utils.get_hypercube_interpolation_fn(
model_graph.output_node.weights.flatten())
lat_mesh_z = [
lat_mesh_fn([lat_mesh_x.flatten()[i],
lat_mesh_y.flatten()[i]]) for i in range(lat_mesh_n**2)
]
trust_plt = tfl.visualization.plot_outputs(
(lat_mesh_x, lat_mesh_y),
{"Lattice Lookup": lat_mesh_z},
figsize=(6, 6),
)
trust_plt.title("Trust")
trust_plt.xlabel("Calibrated avg_rating")
trust_plt.ylabel("Calibrated num_reviews")
trust_plt.show()
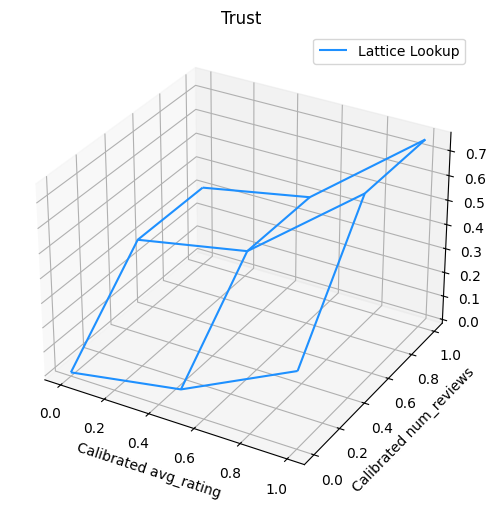
Calibrateurs de lissage
Jetons maintenant un coup d' oeil au calibrateur de avg_rating . Bien qu'il augmente de façon monotone, les changements de ses pentes sont abrupts et difficiles à interpréter. Cela donne à penser que nous pourrions envisager de lissage ce calibrateur en utilisant une configuration de régularisateur dans les regularizer_configs .
Ici , nous appliquons une wrinkle régularisateur pour réduire les changements de la courbure. Vous pouvez également utiliser la laplacian régularisateur pour aplatir le calibrateur et la hessian de hessian régularisateur pour le rendre plus linéaire.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6465646028518677 Testing AUC: 0.7948372960090637


Les calibrateurs sont maintenant fluides et le CTR estimé global correspond mieux à la vérité terrain. Cela se reflète à la fois dans la métrique de test et dans les tracés de contour.
Monotonie partielle pour l'étalonnage catégoriel
Jusqu'à présent, nous n'avons utilisé que deux des caractéristiques numériques du modèle. Ici, nous allons ajouter une troisième fonctionnalité à l'aide d'une couche de calibration catégorielle. Encore une fois, nous commençons par configurer des fonctions d'aide pour le traçage et le calcul métrique.
def analyze_three_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def three_d_pred(avg_ratings, num_reviews, dollar_rating):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
"dollar_rating": dollar_rating,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
figsize(11, 22)
plot_fns([("{} Estimated CTR".format(name), three_d_pred),
("CTR", click_through_rate)],
split_by_dollar=True)
Pour impliquer le troisième long métrage, dollar_rating , il convient de rappeler que les caractéristiques catégoriques nécessitent un traitement légèrement différent dans TFL, à la fois en tant que colonne de fonction et une configuration caractéristique. Ici, nous appliquons la contrainte de monotonie partielle selon laquelle les sorties des restaurants « DD » doivent être plus grandes que les restaurants « D » lorsque toutes les autres entrées sont fixes. Cela se fait à l' aide du monotonicity paramètre dans la config de fonction.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7699775695800781 Testing AUC: 0.8594040274620056


Ce calibrateur catégoriel montre la préférence de la sortie du modèle : DD > D > DDD > DDDD, ce qui est cohérent avec notre configuration. Notez qu'il y a aussi une colonne pour les valeurs manquantes. Bien qu'il n'y ait aucune fonctionnalité manquante dans nos données d'entraînement et de test, le modèle nous fournit une imputation pour la valeur manquante si cela se produit pendant la diffusion du modèle en aval.
Ici , nous traçons aussi le CTR prévu de ce modèle conditionné sur dollar_rating . Notez que toutes les contraintes dont nous avons besoin sont remplies dans chacune des tranches.
Étalonnage de la sortie
Pour tous les modèles TFL que nous avons entraînés jusqu'à présent, la couche de réseau (indiquée par « Lattice » dans le graphique du modèle) génère directement la prédiction du modèle. Parfois, nous ne savons pas si la sortie du réseau doit être redimensionnée pour émettre des sorties de modèle :
- les caractéristiques sont \(log\) compte alors que les étiquettes sont des comptes.
- le réseau est configuré pour avoir très peu de sommets mais la distribution des étiquettes est relativement compliquée.
Dans ces cas, nous pouvons ajouter un autre calibrateur entre la sortie du réseau et la sortie du modèle pour augmenter la flexibilité du modèle. Ajoutons ici une couche de calibrage avec 5 points clés au modèle que nous venons de construire. Nous ajoutons également un régularisateur pour le calibrateur de sortie afin de maintenir la fonction fluide.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
output_calibration=True,
output_calibration_num_keypoints=5,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="output_calib_wrinkle", l2=0.1),
],
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7697908878326416 Testing AUC: 0.861327052116394


La métrique de test finale et les graphiques montrent comment l'utilisation de contraintes de bon sens peut aider le modèle à éviter un comportement inattendu et à mieux extrapoler à l'ensemble de l'espace d'entrée.
,| | | Voir la source sur GitHub | |
Aperçu
Ce tutoriel est un aperçu des contraintes et des régularisations fournies par la bibliothèque TensorFlow Lattice (TFL). Ici, nous utilisons des estimateurs prédéfinis TFL sur des ensembles de données synthétiques, mais notez que tout dans ce didacticiel peut également être fait avec des modèles construits à partir de couches TFL Keras.
Avant de continuer, assurez-vous que votre environnement d'exécution a tous les packages requis installés (tels qu'importés dans les cellules de code ci-dessous).
Installer
Installation du package TF Lattice :
pip install -q tensorflow-lattice
Importation des packages requis :
import tensorflow as tf
from IPython.core.pylabtools import figsize
import itertools
import logging
import matplotlib
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
import sys
import tensorflow_lattice as tfl
logging.disable(sys.maxsize)
Valeurs par défaut utilisées dans ce guide :
NUM_EPOCHS = 1000
BATCH_SIZE = 64
LEARNING_RATE=0.01
Ensemble de données d'entraînement pour le classement des restaurants
Imaginez un scénario simplifié où nous voulons déterminer si les utilisateurs cliqueront ou non sur un résultat de recherche de restaurant. La tâche consiste à prédire le taux de clics (CTR) en fonction des caractéristiques d'entrée :
- Note moyenne (
avg_rating): une fonction numérique avec des valeurs dans l'intervalle [1,5]. - Nombre d'évaluations (
num_reviews): une fonction numérique avec des valeurs plafonnées à 200, que nous utilisons comme mesure de branchitude. - Évaluation du dollar (
dollar_rating): une caractéristique catégorique avec les valeurs de chaîne dans l'ensemble { "D", "DD", "DDD", "DDDD"}.
Ici, nous créons un ensemble de données synthétiques où le vrai CTR est donné par la formule :
\[ CTR = 1 / (1 + exp\{\mbox{b(dollar_rating)}-\mbox{avg_rating}\times log(\mbox{num_reviews}) /4 \}) \]
où \(b(\cdot)\) se traduit par dollar_rating à une valeur de référence:
\[ \mbox{D}\to 3,\ \mbox{DD}\to 2,\ \mbox{DDD}\to 4,\ \mbox{DDDD}\to 4.5. \]
Cette formule reflète les modèles d'utilisateurs typiques. par exemple, étant donné que tout le reste est corrigé, les utilisateurs préfèrent les restaurants avec un nombre d'étoiles plus élevé et les restaurants "\$\$" recevront plus de clics que "\$", suivis de "\$\$\$" et "\$\$\$ \$".
def click_through_rate(avg_ratings, num_reviews, dollar_ratings):
dollar_rating_baseline = {"D": 3, "DD": 2, "DDD": 4, "DDDD": 4.5}
return 1 / (1 + np.exp(
np.array([dollar_rating_baseline[d] for d in dollar_ratings]) -
avg_ratings * np.log1p(num_reviews) / 4))
Jetons un coup d'œil aux tracés de contour de cette fonction CTR.
def color_bar():
bar = matplotlib.cm.ScalarMappable(
norm=matplotlib.colors.Normalize(0, 1, True),
cmap="viridis",
)
bar.set_array([0, 1])
return bar
def plot_fns(fns, split_by_dollar=False, res=25):
"""Generates contour plots for a list of (name, fn) functions."""
num_reviews, avg_ratings = np.meshgrid(
np.linspace(0, 200, num=res),
np.linspace(1, 5, num=res),
)
if split_by_dollar:
dollar_rating_splits = ["D", "DD", "DDD", "DDDD"]
else:
dollar_rating_splits = [None]
if len(fns) == 1:
fig, axes = plt.subplots(2, 2, sharey=True, tight_layout=False)
else:
fig, axes = plt.subplots(
len(dollar_rating_splits), len(fns), sharey=True, tight_layout=False)
axes = axes.flatten()
axes_index = 0
for dollar_rating_split in dollar_rating_splits:
for title, fn in fns:
if dollar_rating_split is not None:
dollar_ratings = np.repeat(dollar_rating_split, res**2)
values = fn(avg_ratings.flatten(), num_reviews.flatten(),
dollar_ratings)
title = "{}: dollar_rating={}".format(title, dollar_rating_split)
else:
values = fn(avg_ratings.flatten(), num_reviews.flatten())
subplot = axes[axes_index]
axes_index += 1
subplot.contourf(
avg_ratings,
num_reviews,
np.reshape(values, (res, res)),
vmin=0,
vmax=1)
subplot.title.set_text(title)
subplot.set(xlabel="Average Rating")
subplot.set(ylabel="Number of Reviews")
subplot.set(xlim=(1, 5))
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
figsize(11, 11)
plot_fns([("CTR", click_through_rate)], split_by_dollar=True)
Préparation des données
Nous devons maintenant créer nos jeux de données synthétiques. Nous commençons par générer un jeu de données simulé de restaurants et de leurs caractéristiques.
def sample_restaurants(n):
avg_ratings = np.random.uniform(1.0, 5.0, n)
num_reviews = np.round(np.exp(np.random.uniform(0.0, np.log(200), n)))
dollar_ratings = np.random.choice(["D", "DD", "DDD", "DDDD"], n)
ctr_labels = click_through_rate(avg_ratings, num_reviews, dollar_ratings)
return avg_ratings, num_reviews, dollar_ratings, ctr_labels
np.random.seed(42)
avg_ratings, num_reviews, dollar_ratings, ctr_labels = sample_restaurants(2000)
figsize(5, 5)
fig, axs = plt.subplots(1, 1, sharey=False, tight_layout=False)
for rating, marker in [("D", "o"), ("DD", "^"), ("DDD", "+"), ("DDDD", "x")]:
plt.scatter(
x=avg_ratings[np.where(dollar_ratings == rating)],
y=num_reviews[np.where(dollar_ratings == rating)],
c=ctr_labels[np.where(dollar_ratings == rating)],
vmin=0,
vmax=1,
marker=marker,
label=rating)
plt.xlabel("Average Rating")
plt.ylabel("Number of Reviews")
plt.legend()
plt.xlim((1, 5))
plt.title("Distribution of restaurants")
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
Produisons les ensembles de données d'entraînement, de validation et de test. Lorsqu'un restaurant est affiché dans les résultats de la recherche, nous pouvons enregistrer l'engagement de l'utilisateur (clic ou pas de clic) en tant que point d'échantillon.
Dans la pratique, les utilisateurs ne parcourent souvent pas tous les résultats de recherche. Cela signifie que les utilisateurs ne verront probablement que les restaurants déjà considérés comme « bons » par le modèle de classement actuellement utilisé. En conséquence, les « bons » restaurants sont plus fréquemment impressionnés et surreprésentés dans les ensembles de données d'apprentissage. Lorsque vous utilisez plus de fonctionnalités, l'ensemble de données d'apprentissage peut présenter des lacunes importantes dans les « mauvaises » parties de l'espace des fonctionnalités.
Lorsque le modèle est utilisé pour le classement, il est souvent évalué sur tous les résultats pertinents avec une distribution plus uniforme qui n'est pas bien représentée par l'ensemble de données d'apprentissage. Un modèle flexible et compliqué pourrait échouer dans ce cas en raison du surajustement des points de données surreprésentés et donc manquer de généralisabilité. Nous traitons ce problème en appliquant les connaissances de domaine pour ajouter des contraintes de forme qui guident le modèle pour faire des prévisions raisonnables quand il ne peut pas les chercher à l'ensemble de données de formation.
Dans cet exemple, l'ensemble de données de formation se compose principalement d'interactions d'utilisateurs avec de bons restaurants populaires. L'ensemble de données de test a une distribution uniforme pour simuler le paramètre d'évaluation discuté ci-dessus. Notez qu'un tel ensemble de données de test ne sera pas disponible dans un contexte de problème réel.
def sample_dataset(n, testing_set):
(avg_ratings, num_reviews, dollar_ratings, ctr_labels) = sample_restaurants(n)
if testing_set:
# Testing has a more uniform distribution over all restaurants.
num_views = np.random.poisson(lam=3, size=n)
else:
# Training/validation datasets have more views on popular restaurants.
num_views = np.random.poisson(lam=ctr_labels * num_reviews / 50.0, size=n)
return pd.DataFrame({
"avg_rating": np.repeat(avg_ratings, num_views),
"num_reviews": np.repeat(num_reviews, num_views),
"dollar_rating": np.repeat(dollar_ratings, num_views),
"clicked": np.random.binomial(n=1, p=np.repeat(ctr_labels, num_views))
})
# Generate datasets.
np.random.seed(42)
data_train = sample_dataset(500, testing_set=False)
data_val = sample_dataset(500, testing_set=False)
data_test = sample_dataset(500, testing_set=True)
# Plotting dataset densities.
figsize(12, 5)
fig, axs = plt.subplots(1, 2, sharey=False, tight_layout=False)
for ax, data, title in [(axs[0], data_train, "training"),
(axs[1], data_test, "testing")]:
_, _, _, density = ax.hist2d(
x=data["avg_rating"],
y=data["num_reviews"],
bins=(np.linspace(1, 5, num=21), np.linspace(0, 200, num=21)),
density=True,
cmap="Blues",
)
ax.set(xlim=(1, 5))
ax.set(ylim=(0, 200))
ax.set(xlabel="Average Rating")
ax.set(ylabel="Number of Reviews")
ax.title.set_text("Density of {} examples".format(title))
_ = fig.colorbar(density, ax=ax)
Définition de input_fns utilisé pour la formation et l'évaluation :
train_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
shuffle=False,
)
# feature_analysis_input_fn is used for TF Lattice estimators.
feature_analysis_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
val_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_val,
y=data_val["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
test_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_test,
y=data_test["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
Ajustement d'arbres améliorés par gradient
Commençons avec seulement deux caractéristiques: avg_rating et num_reviews .
Nous créons quelques fonctions auxiliaires pour tracer et calculer les métriques de validation et de test.
def analyze_two_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def two_d_pred(avg_ratings, num_reviews):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
def two_d_click_through_rate(avg_ratings, num_reviews):
return np.mean([
click_through_rate(avg_ratings, num_reviews,
np.repeat(d, len(avg_ratings)))
for d in ["D", "DD", "DDD", "DDDD"]
],
axis=0)
figsize(11, 5)
plot_fns([("{} Estimated CTR".format(name), two_d_pred),
("CTR", two_d_click_through_rate)],
split_by_dollar=False)
Nous pouvons insérer des arbres de décision TensorFlow boostés par gradient sur l'ensemble de données :
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
gbt_estimator = tf.estimator.BoostedTreesClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
n_batches_per_layer=1,
max_depth=2,
n_trees=50,
learning_rate=0.05,
config=tf.estimator.RunConfig(tf_random_seed=42),
)
gbt_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(gbt_estimator, "GBT")
Validation AUC: 0.6333084106445312 Testing AUC: 0.774649977684021
Même si le modèle a capturé la forme générale du vrai CTR et a des métriques de validation décentes, il a un comportement contre-intuitif dans plusieurs parties de l'espace d'entrée : le CTR estimé diminue à mesure que la note moyenne ou le nombre d'avis augmente. Cela est dû à un manque de points d'échantillonnage dans les zones non bien couvertes par l'ensemble de données d'apprentissage. Le modèle n'a tout simplement aucun moyen de déduire le comportement correct uniquement à partir des données.
Pour résoudre ce problème, nous appliquons la contrainte de forme selon laquelle le modèle doit produire des valeurs augmentant de manière monotone en ce qui concerne à la fois la note moyenne et le nombre d'avis. Nous verrons plus tard comment implémenter cela dans TFL.
Installer un DNN
Nous pouvons répéter les mêmes étapes avec un classificateur DNN. Nous pouvons observer un schéma similaire : ne pas avoir suffisamment de points d'échantillonnage avec un petit nombre d'examens entraîne une extrapolation absurde. Notez que même si la métrique de validation est meilleure que la solution arborescente, la métrique de test est bien pire.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
dnn_estimator = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
hidden_units=[16, 8, 8],
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
dnn_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(dnn_estimator, "DNN")
Validation AUC: 0.6696228981018066 Testing AUC: 0.750156044960022
Contraintes de forme
TensorFlow Lattice (TFL) se concentre sur l'application de contraintes de forme pour protéger le comportement du modèle au-delà des données d'apprentissage. Ces contraintes de forme sont appliquées aux couches TFL Keras. Leurs coordonnées se trouvent dans notre papier JMLR .
Dans ce didacticiel, nous utilisons des estimateurs prédéfinis TF pour couvrir diverses contraintes de forme, mais notez que toutes ces étapes peuvent être effectuées avec des modèles créés à partir de couches TFL Keras.
Comme avec tout autre estimateur de tensorflow, estimateurs utilisent TFL mis en conserve des colonnes de fonction pour définir le format d'entrée et d' utiliser un input_fn de formation pour passer dans les données. L'utilisation d'estimateurs pré-programmés TFL nécessite également :
- une configuration de modèle: définir l'architecture du modèle et des contraintes de forme et par-fonction régularisations.
- une analyse de la fonction input_fn: une TF input_fn transmettre des données d'initialisation TFL.
Pour une description plus détaillée, veuillez vous référer au didacticiel des estimateurs en conserve ou à la documentation de l'API.
Monotonie
Nous abordons d'abord les problèmes de monotonie en ajoutant des contraintes de forme de monotonie aux deux caractéristiques.
De charger TFL de faire respecter les contraintes de forme, nous précisons les contraintes dans les caractéristiques configs. Le code suivant montre comment nous pouvons exiger la production d'augmenter de façon monotone par rapport aux deux num_reviews et avg_rating en réglant monotonicity="increasing" .
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
Validation AUC: 0.6565533876419067 Testing AUC: 0.7784258723258972
L' utilisation d' un CalibratedLatticeConfig crée un classificateur en conserve qui applique d' abord un calibreur à chaque entrée (une fonction linéaire par morceaux pour les fonctions numériques) suivie d'une couche de réseau de façon non linéaire les éléments fusibles calibrés. Nous pouvons utiliser tfl.visualization pour visualiser le modèle. En particulier, le graphique suivant montre les deux calibrateurs entraînés inclus dans le classificateur en conserve.
def save_and_visualize_lattice(tfl_estimator):
saved_model_path = tfl_estimator.export_saved_model(
"/tmp/TensorFlow_Lattice_101/",
tf.estimator.export.build_parsing_serving_input_receiver_fn(
feature_spec=tf.feature_column.make_parse_example_spec(
feature_columns)))
model_graph = tfl.estimators.get_model_graph(saved_model_path)
figsize(8, 8)
tfl.visualization.draw_model_graph(model_graph)
return model_graph
_ = save_and_visualize_lattice(tfl_estimator)
Avec les contraintes ajoutées, le CTR estimé augmentera toujours à mesure que la note moyenne augmente ou que le nombre d'avis augmente. Ceci est fait en s'assurant que les calibrateurs et le réseau sont monotones.
Rendements décroissants
Les rendements décroissants signifie que le gain marginal de plus en plus une certaine valeur de caractéristique diminue à mesure que l' on augmente la valeur. Dans notre cas , nous attendons à ce que la num_reviews fonction suit ce modèle, afin que nous puissions configurer en conséquence son calibrateur. Notez que nous pouvons décomposer les rendements décroissants en deux conditions suffisantes :
- le calibrateur augmente de façon monotone, et
- le calibreur est concave.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891247272491455
Remarquez comment la métrique de test s'améliore en ajoutant la contrainte de concavité. Le tracé de prédiction ressemble également mieux à la vérité terrain.
Contrainte de forme 2D : confiance
Une note de 5 étoiles pour un restaurant avec seulement une ou deux critiques est probablement une note peu fiable (le restaurant peut ne pas être bon), alors qu'une note de 4 étoiles pour un restaurant avec des centaines de critiques est beaucoup plus fiable (le restaurant est probablement bon dans ce cas). Nous pouvons voir que le nombre de critiques d'un restaurant affecte la confiance que nous accordons à sa note moyenne.
Nous pouvons exercer des contraintes de confiance TFL pour informer le modèle que la valeur plus grande (ou plus petite) d'une caractéristique indique plus de confiance ou de confiance envers une autre caractéristique. Cela se fait par la mise en reflects_trust_in configuration dans la configuration de la fonction.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
# Larger num_reviews indicating more trust in avg_rating.
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
model_graph = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891043424606323
Le graphique suivant présente la fonction de réseau entraînée. En raison de la contrainte de confiance, nous nous attendons à ce que les plus grandes valeurs calibrées num_reviews forceraient pente supérieure par rapport à étalonnée avg_rating , entraînant un mouvement plus important dans la sortie réseau.
lat_mesh_n = 12
lat_mesh_x, lat_mesh_y = tfl.test_utils.two_dim_mesh_grid(
lat_mesh_n**2, 0, 0, 1, 1)
lat_mesh_fn = tfl.test_utils.get_hypercube_interpolation_fn(
model_graph.output_node.weights.flatten())
lat_mesh_z = [
lat_mesh_fn([lat_mesh_x.flatten()[i],
lat_mesh_y.flatten()[i]]) for i in range(lat_mesh_n**2)
]
trust_plt = tfl.visualization.plot_outputs(
(lat_mesh_x, lat_mesh_y),
{"Lattice Lookup": lat_mesh_z},
figsize=(6, 6),
)
trust_plt.title("Trust")
trust_plt.xlabel("Calibrated avg_rating")
trust_plt.ylabel("Calibrated num_reviews")
trust_plt.show()
Calibrateurs de lissage
Jetons maintenant un coup d' oeil au calibrateur de avg_rating . Bien qu'il augmente de façon monotone, les changements de ses pentes sont abrupts et difficiles à interpréter. Cela donne à penser que nous pourrions envisager de lissage ce calibrateur en utilisant une configuration de régularisateur dans les regularizer_configs .
Ici , nous appliquons une wrinkle régularisateur pour réduire les changements de la courbure. Vous pouvez également utiliser la laplacian régularisateur pour aplatir le calibrateur et la hessian de hessian régularisateur pour le rendre plus linéaire.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6465646028518677 Testing AUC: 0.7948372960090637
Les calibrateurs sont maintenant fluides et le CTR estimé global correspond mieux à la vérité terrain. Cela se reflète à la fois dans la métrique de test et dans les tracés de contour.
Monotonie partielle pour l'étalonnage catégoriel
Jusqu'à présent, nous n'avons utilisé que deux des caractéristiques numériques du modèle. Ici, nous allons ajouter une troisième fonctionnalité à l'aide d'une couche de calibration catégorielle. Encore une fois, nous commençons par configurer des fonctions d'aide pour le traçage et le calcul métrique.
def analyze_three_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def three_d_pred(avg_ratings, num_reviews, dollar_rating):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
"dollar_rating": dollar_rating,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
figsize(11, 22)
plot_fns([("{} Estimated CTR".format(name), three_d_pred),
("CTR", click_through_rate)],
split_by_dollar=True)
Pour impliquer le troisième long métrage, dollar_rating , il convient de rappeler que les caractéristiques catégoriques nécessitent un traitement légèrement différent dans TFL, à la fois en tant que colonne de fonction et une configuration caractéristique. Ici, nous appliquons la contrainte de monotonie partielle selon laquelle les sorties des restaurants « DD » doivent être plus grandes que les restaurants « D » lorsque toutes les autres entrées sont fixes. Cela se fait à l' aide du monotonicity paramètre dans la config de fonction.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7699775695800781 Testing AUC: 0.8594040274620056
Ce calibrateur catégoriel montre la préférence de la sortie du modèle : DD > D > DDD > DDDD, ce qui est cohérent avec notre configuration. Notez qu'il y a aussi une colonne pour les valeurs manquantes. Bien qu'il n'y ait aucune fonctionnalité manquante dans nos données d'entraînement et de test, le modèle nous fournit une imputation pour la valeur manquante si cela se produit pendant la diffusion du modèle en aval.
Ici , nous traçons aussi le CTR prévu de ce modèle conditionné sur dollar_rating . Notez que toutes les contraintes dont nous avons besoin sont remplies dans chacune des tranches.
Étalonnage de sortie
Pour tous les modèles TFL que nous avons entraînés jusqu'à présent, la couche de réseau (indiquée par « Lattice » dans le graphique du modèle) génère directement la prédiction du modèle. Parfois, nous ne savons pas si la sortie du réseau doit être redimensionnée pour émettre des sorties de modèle :
- les caractéristiques sont \(log\) compte alors que les étiquettes sont des comptes.
- le réseau est configuré pour avoir très peu de sommets mais la distribution des étiquettes est relativement compliquée.
Dans ces cas, nous pouvons ajouter un autre calibrateur entre la sortie du réseau et la sortie du modèle pour augmenter la flexibilité du modèle. Ajoutons ici une couche de calibrage avec 5 points clés au modèle que nous venons de construire. Nous ajoutons également un régularisateur pour le calibrateur de sortie afin de maintenir la fonction fluide.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
output_calibration=True,
output_calibration_num_keypoints=5,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="output_calib_wrinkle", l2=0.1),
],
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7697908878326416 Testing AUC: 0.861327052116394
La métrique de test finale et les graphiques montrent comment l'utilisation de contraintes de bon sens peut aider le modèle à éviter un comportement inattendu et à mieux extrapoler à l'ensemble de l'espace d'entrée.