
L'uso di processori specializzati come GPU, NPU o DSP per l'accelerazione hardware può migliorare notevolmente le prestazioni di inferenza (in alcuni casi fino a 10 volte più veloci) e l'esperienza utente della tua applicazione Android abilitata per ML. Tuttavia, data la varietà di hardware e driver che i tuoi utenti potrebbero avere, scegliere la configurazione di accelerazione hardware ottimale per il dispositivo di ciascun utente può essere difficile. Inoltre, abilitare la configurazione errata su un dispositivo può creare un'esperienza utente insoddisfacente a causa dell'elevata latenza o, in alcuni rari casi, errori di runtime o problemi di precisione causati da incompatibilità hardware.
Il servizio di accelerazione per Android è un'API che ti aiuta a scegliere la configurazione di accelerazione hardware ottimale per un determinato dispositivo utente e il tuo modello .tflite , riducendo al minimo il rischio di errori di runtime o problemi di precisione.
Il servizio di accelerazione valuta diverse configurazioni di accelerazione sui dispositivi degli utenti eseguendo benchmark di inferenza interni con il tuo modello TensorFlow Lite. Queste esecuzioni di test vengono generalmente completate in pochi secondi, a seconda del modello. Puoi eseguire i benchmark una volta su ogni dispositivo utente prima dell'inferenza, memorizzare nella cache il risultato e utilizzarlo durante l'inferenza. Questi benchmark sono fuori processo; che riduce al minimo il rischio di arresti anomali della tua app.
Fornisci il tuo modello, campioni di dati e risultati attesi (input e output "golden") e il servizio di accelerazione eseguirà un benchmark di inferenza TFLite interno per fornirti consigli sull'hardware.
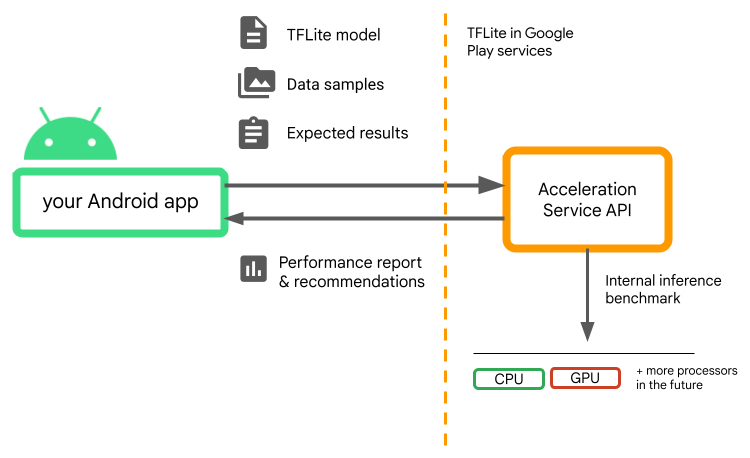
Il servizio di accelerazione fa parte dello stack ML personalizzato di Android e funziona con TensorFlow Lite nei servizi Google Play .
Aggiungi le dipendenze al tuo progetto
Aggiungi le seguenti dipendenze al file build.gradle della tua applicazione:
implementation "com.google.android.gms:play-services-tflite-
acceleration-service:16.0.0-beta01"
L'API del servizio di accelerazione funziona con TensorFlow Lite in Google Play Services . Se non utilizzi ancora il runtime TensorFlow Lite fornito tramite Play Services, dovrai aggiornare le tue dipendenze .
Come utilizzare l'API del servizio di accelerazione
Per utilizzare il servizio di accelerazione, inizia creando la configurazione di accelerazione che desideri valutare per il tuo modello (ad esempio GPU con OpenGL). Quindi crea una configurazione di convalida con il tuo modello, alcuni dati di esempio e l'output del modello previsto. Infine chiama validateConfig() passando sia la configurazione di accelerazione che quella di convalida.

Creare configurazioni di accelerazione
Le configurazioni di accelerazione sono rappresentazioni delle configurazioni hardware che vengono tradotte in delegati durante il tempo di esecuzione. Il servizio di accelerazione utilizzerà quindi queste configurazioni internamente per eseguire inferenze di test.
Al momento il servizio di accelerazione consente di valutare le configurazioni della GPU (convertite in delegato GPU durante il tempo di esecuzione) con GpuAccelerationConfig e l'inferenza della CPU (con CpuAccelerationConfig ). Stiamo lavorando per supportare più delegati nell'accesso ad altro hardware in futuro.
Configurazione dell'accelerazione GPU
Crea una configurazione di accelerazione GPU come segue:
AccelerationConfig accelerationConfig = new GpuAccelerationConfig.Builder()
.setEnableQuantizedInference(false)
.build();
È necessario specificare se il modello utilizza o meno la quantizzazione con setEnableQuantizedInference() .
Configurazione dell'accelerazione della CPU
Crea l'accelerazione della CPU come segue:
AccelerationConfig accelerationConfig = new CpuAccelerationConfig.Builder()
.setNumThreads(2)
.build();
Utilizza il metodo setNumThreads() per definire il numero di thread che desideri utilizzare per valutare l'inferenza della CPU.
Creare configurazioni di convalida
Le configurazioni di convalida consentono di definire il modo in cui si desidera che il servizio di accelerazione valuti le inferenze. Li utilizzerai per passare:
- campioni di ingresso,
- risultati attesi,
- logica di validazione dell'accuratezza.
Assicurati di fornire campioni di input per i quali ti aspetti una buona prestazione del tuo modello (noti anche come campioni "d'oro").
Crea un ValidationConfig con CustomValidationConfig.Builder come segue:
ValidationConfig validationConfig = new CustomValidationConfig.Builder()
.setBatchSize(5)
.setGoldenInputs(inputs)
.setGoldenOutputs(outputBuffer)
.setAccuracyValidator(new MyCustomAccuracyValidator())
.build();
Specificare il numero dei campioni dorati con setBatchSize() . Passa gli input dei tuoi campioni dorati utilizzando setGoldenInputs() . Fornire l'output previsto per l'input passato con setGoldenOutputs() .
È possibile definire un tempo di inferenza massimo con setInferenceTimeoutMillis() (5000 ms per impostazione predefinita). Se l'inferenza richiede più tempo del tempo definito, la configurazione verrà rifiutata.
Facoltativamente, puoi anche creare un AccuracyValidator personalizzato come segue:
class MyCustomAccuracyValidator implements AccuracyValidator {
boolean validate(
BenchmarkResult benchmarkResult,
ByteBuffer[] goldenOutput) {
for (int i = 0; i < benchmarkResult.actualOutput().size(); i++) {
if (!goldenOutputs[i]
.equals(benchmarkResult.actualOutput().get(i).getValue())) {
return false;
}
}
return true;
}
}
Assicurati di definire una logica di convalida che funzioni per il tuo caso d'uso.
Tieni presente che se i dati di convalida sono già incorporati nel tuo modello, puoi utilizzare EmbeddedValidationConfig .
Genera output di convalida
Gli output dorati sono facoltativi e finché fornisci input dorati, il servizio di accelerazione può generare internamente gli output dorati. Puoi anche definire la configurazione di accelerazione utilizzata per generare questi output dorati chiamando setGoldenConfig() :
ValidationConfig validationConfig = new CustomValidationConfig.Builder()
.setBatchSize(5)
.setGoldenInputs(inputs)
.setGoldenConfig(customCpuAccelerationConfig)
[...]
.build();
Convalidare la configurazione dell'accelerazione
Dopo aver creato una configurazione di accelerazione e una configurazione di convalida, puoi valutarle per il tuo modello.
Assicurati che il runtime TensorFlow Lite con Play Services sia inizializzato correttamente e che il delegato GPU sia disponibile per il dispositivo eseguendo:
TfLiteGpu.isGpuDelegateAvailable(context)
.onSuccessTask(gpuAvailable -> TfLite.initialize(context,
TfLiteInitializationOptions.builder()
.setEnableGpuDelegateSupport(gpuAvailable)
.build()
)
);
Crea un'istanza di AccelerationService chiamando AccelerationService.create() .
Puoi quindi convalidare la configurazione dell'accelerazione per il tuo modello chiamando validateConfig() :
InterpreterApi interpreter;
InterpreterOptions interpreterOptions = InterpreterApi.Options();
AccelerationService.create(context)
.validateConfig(model, accelerationConfig, validationConfig)
.addOnSuccessListener(validatedConfig -> {
if (validatedConfig.isValid() && validatedConfig.benchmarkResult().hasPassedAccuracyTest()) {
interpreterOptions.setAccelerationConfig(validatedConfig);
interpreter = InterpreterApi.create(model, interpreterOptions);
});
È inoltre possibile convalidare più configurazioni chiamando validateConfigs() e passando un oggetto Iterable<AccelerationConfig> come parametro.
validateConfig() restituirà un Task< ValidatedAccelerationConfigResult > dall'API Task di Google Play Services che abilita attività asincrone.
Per ottenere il risultato dalla chiamata di convalida, aggiungere una richiamata addOnSuccessListener() .
Utilizza la configurazione convalidata nel tuo interprete
Dopo aver verificato se ValidatedAccelerationConfigResult restituito nel callback è valido, puoi impostare la configurazione convalidata come configurazione di accelerazione per il tuo interprete che chiama interpreterOptions.setAccelerationConfig() .
Cache della configurazione
È improbabile che la configurazione di accelerazione ottimale per il tuo modello cambi sul dispositivo. Pertanto, una volta ricevuta una configurazione di accelerazione soddisfacente, dovresti archiviarla sul dispositivo e lasciare che l'applicazione la recuperi e la utilizzi per creare le tue InterpreterOptions durante le sessioni successive invece di eseguire un'altra convalida. I metodi serialize() e deserialize() in ValidatedAccelerationConfigResult semplificano il processo di archiviazione e recupero.
Applicazione di esempio
Per esaminare un'integrazione in situ del servizio di accelerazione, dai un'occhiata all'app di esempio .
Limitazioni
Il servizio di accelerazione presenta le seguenti limitazioni attuali:
- Al momento sono supportate solo le configurazioni di accelerazione CPU e GPU,
- Supporta TensorFlow Lite solo nei servizi Google Play e non puoi utilizzarlo se utilizzi la versione in bundle di TensorFlow Lite,
- Non supporta la libreria di attività TensorFlow Lite poiché non è possibile inizializzare direttamente
BaseOptionscon l'oggettoValidatedAccelerationConfigResult. - L'SDK del servizio di accelerazione supporta solo il livello API 22 e versioni successive.
Avvertenze
Ti invitiamo a leggere attentamente le seguenti avvertenze, soprattutto se prevedi di utilizzare questo SDK in produzione:
Prima di uscire dalla Beta e rilasciare la versione stabile per l'API del servizio di accelerazione, pubblicheremo un nuovo SDK che potrebbe presentare alcune differenze rispetto all'attuale Beta. Per continuare a utilizzare il servizio di accelerazione, dovrai eseguire la migrazione a questo nuovo SDK e inviare tempestivamente un aggiornamento alla tua app. In caso contrario, potrebbero verificarsi guasti poiché l'SDK Beta potrebbe non essere più compatibile con i servizi Google Play dopo un po' di tempo.
Non vi è alcuna garanzia che una funzionalità specifica all'interno dell'API del servizio di accelerazione o dell'API nel suo complesso diventi mai disponibile a livello generale. Potrebbe rimanere in versione Beta a tempo indeterminato, essere chiuso o essere combinato con altre funzionalità in pacchetti progettati per un pubblico di sviluppatori specifico. Alcune funzionalità dell'API del servizio di accelerazione o dell'intera API stessa potrebbero eventualmente diventare disponibili a tutti, ma non esiste un programma fisso per questo.
Termini e privacy
Termini di servizio
L'utilizzo delle API del servizio di accelerazione è soggetto ai Termini di servizio delle API di Google .
Inoltre, le API del servizio di accelerazione sono attualmente in versione beta e, come tale, utilizzandole riconosci i potenziali problemi delineati nella sezione Avvertenze sopra e riconosci che il servizio di accelerazione potrebbe non funzionare sempre come specificato.
Privacy
Quando utilizzi le API del servizio di accelerazione, l'elaborazione dei dati di input (ad esempio immagini, video, testo) avviene interamente sul dispositivo e il servizio di accelerazione non invia tali dati ai server di Google . Di conseguenza, puoi utilizzare le nostre API per elaborare i dati di input che non devono lasciare il dispositivo.
Le API del servizio di accelerazione possono contattare di tanto in tanto i server di Google per ricevere elementi quali correzioni di bug, modelli aggiornati e informazioni sulla compatibilità dell'acceleratore hardware. Le API del servizio di accelerazione inviano a Google anche metriche sulle prestazioni e sull'utilizzo delle API nella tua app. Google utilizza questi dati di metrica per misurare le prestazioni, eseguire il debug, mantenere e migliorare le API e rilevare usi impropri o abusi, come ulteriormente descritto nelle nostre Norme sulla privacy .
Sei responsabile di informare gli utenti della tua app sull'elaborazione da parte di Google dei dati delle metriche del servizio di accelerazione come richiesto dalla legge applicabile.
I dati che raccogliamo includono quanto segue:
- Informazioni sul dispositivo (come produttore, modello, versione e build del sistema operativo) e acceleratori hardware ML disponibili (GPU e DSP). Utilizzato per la diagnostica e l'analisi dell'utilizzo.
- Informazioni sull'app (nome pacchetto/ID bundle, versione dell'app). Utilizzato per la diagnostica e l'analisi dell'utilizzo.
- Configurazione API (come formato immagine e risoluzione). Utilizzato per la diagnostica e l'analisi dell'utilizzo.
- Tipo di evento (ad esempio inizializzazione, download modello, aggiornamento, esecuzione, rilevamento). Utilizzato per la diagnostica e l'analisi dell'utilizzo.
- Codici di errore. Utilizzato per la diagnostica.
- Metriche delle prestazioni. Utilizzato per la diagnostica.
- Identificatori per installazione che non identificano in modo univoco un utente o un dispositivo fisico. Utilizzato per il funzionamento della configurazione remota e dell'analisi dell'utilizzo.
- Indirizzi IP del mittente della richiesta di rete. Utilizzato per la diagnostica della configurazione remota. Gli indirizzi IP raccolti vengono conservati temporaneamente.
Supporto e feedback
Puoi fornire feedback e ottenere supporto tramite TensorFlow Issue Tracker. Segnala problemi e richieste di supporto utilizzando il modello di problema per TensorFlow Lite nei servizi Google Play.