

Задача определения того, что представляет собой аудио, называется классификацией звука . Модель классификации аудио обучена распознавать различные аудиособытия. Например, вы можете научить модель распознавать события, представляющие три разных события: хлопок, щелчок пальцами и набор текста. TensorFlow Lite предоставляет оптимизированные предварительно обученные модели, которые вы можете развернуть в своих мобильных приложениях. Подробнее о классификации аудио с помощью TensorFlow можно узнать здесь .
На следующем изображении показаны выходные данные модели классификации аудио на Android.
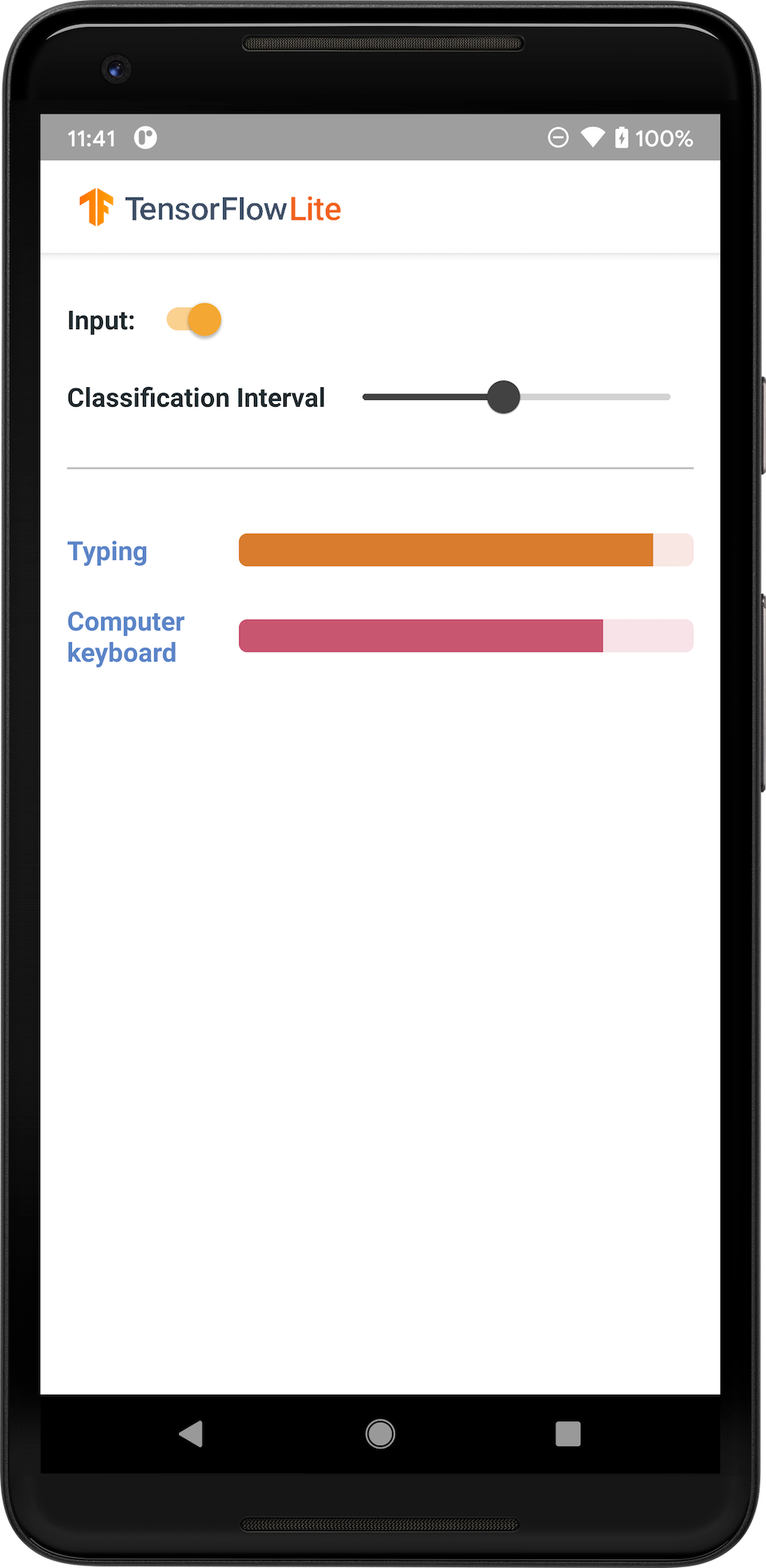
Начать
Если вы новичок в TensorFlow Lite и работаете с Android, мы рекомендуем изучить следующие примеры приложений, которые помогут вам начать работу.
Вы можете использовать готовый API из библиотеки задач TensorFlow Lite для интеграции моделей классификации аудио всего в несколько строк кода. Вы также можете создать свой собственный конвейер вывода, используя библиотеку поддержки TensorFlow Lite .
Пример Android ниже демонстрирует реализацию с использованием библиотеки задач TFLite.
Если вы используете платформу, отличную от Android/iOS, или если вы уже знакомы с API-интерфейсами TensorFlow Lite , загрузите начальную модель и вспомогательные файлы (если применимо).
Загрузите стартовую модель из TensorFlow Hub.
Описание модели
YAMNet — это классификатор аудиособытий, который принимает форму аудиосигнала в качестве входных данных и делает независимые прогнозы для каждого из 521 аудиособытия из онтологии AudioSet . Модель использует архитектуру MobileNet v1 и обучена с использованием корпуса AudioSet. Эта модель изначально была выпущена в TensorFlow Model Garden, где находится исходный код модели, исходная контрольная точка модели и более подробная документация.
Как это работает
Существует две версии модели YAMNet, преобразованной в TFLite:
YAMNet — это оригинальная модель классификации аудио с динамическим размером входных данных, подходящая для трансферного обучения, развертывания в Интернете и на мобильных устройствах. Он также имеет более сложный результат.
YAMNet/classification — это квантованная версия с более простым вводом кадров фиксированной длины (15 600 выборок) и возвратом одного вектора оценок для 521 класса аудиособытий.
Входы
Модель принимает одномерный массив float32 Tensor или NumPy длиной 15600, содержащий форму сигнала длительностью 0,975 секунды, представленную в виде монофонических выборок с частотой 16 кГц в диапазоне [-1.0, +1.0] .
Выходы
Модель возвращает двумерный тензор float32 формы (1, 521), содержащий прогнозируемые оценки для каждого из 521 класса в онтологии AudioSet, поддерживаемых YAMNet. Индекс столбца (0–520) тензора оценок сопоставляется с соответствующим именем класса AudioSet с использованием карты классов YAMNet, которая доступна в виде связанного файла yamnet_label_list.txt упакованного в файл модели. См. ниже использование.
Подходящее использование
YAMNet можно использовать
- в качестве автономного классификатора аудиособытий, который обеспечивает разумную основу для широкого спектра аудиособытий.
- в качестве экстрактора функций высокого уровня: выходные данные YAMNet для внедрения 1024-D можно использовать в качестве входных функций другой модели, которую затем можно обучить на небольшом объеме данных для конкретной задачи. Это позволяет быстро создавать специализированные классификаторы аудио, не требуя большого количества размеченных данных и без необходимости сквозного обучения большой модели.
- в качестве «теплого старта»: параметры модели YAMNet можно использовать для инициализации части более крупной модели, что позволяет ускорить тонкую настройку и исследование модели.
Ограничения
- Выходные данные классификатора YAMNet не были откалиброваны по классам, поэтому вы не можете напрямую рассматривать выходные данные как вероятности. Для любой конкретной задачи вам, скорее всего, потребуется выполнить калибровку с использованием данных для конкретной задачи, что позволит вам назначить правильные пороговые значения и масштабирование для каждого класса.
- YAMNet был обучен на миллионах видеороликов YouTube, и хотя они очень разнообразны, между средним видео YouTube и аудиовходами, ожидаемыми для любой конкретной задачи, все же может быть несоответствие домена. Вам следует ожидать выполнения некоторой тонкой настройки и калибровки, чтобы сделать YAMNet пригодным для использования в любой создаваемой вами системе.
Настройка модели
Предоставленные предварительно обученные модели обучены обнаруживать 521 различный класс звука. Полный список классов смотрите в файле labels в репозитории модели .
Вы можете использовать метод, известный как трансферное обучение, чтобы переобучить модель для распознавания классов, отсутствующих в исходном наборе. Например, вы можете переобучить модель для обнаружения нескольких песен птиц. Для этого вам понадобится набор обучающих аудиозаписей для каждого нового лейбла, который вы хотите обучить. Рекомендуемый способ — использовать библиотеку TensorFlow Lite Model Maker , которая упрощает процесс обучения модели TensorFlow Lite с использованием пользовательского набора данных за несколько строк кода. Он использует трансферное обучение, чтобы уменьшить объем необходимых обучающих данных и времени. Вы также можете изучить Трансферное обучение для распознавания аудио в качестве примера трансферного обучения.
Дальнейшее чтение и ресурсы
Используйте следующие ресурсы, чтобы узнать больше о концепциях, связанных с классификацией аудио: