
| | |  Посмотреть на GitHub Посмотреть на GitHub | | |
YAMNet — это предварительно обученная глубокая нейронная сеть, которая может предсказывать звуковые события из 521 класса , такие как смех, лай или сирена.
В этом уроке вы узнаете, как:
- Загрузите и используйте модель YAMNet для логического вывода.
- Создайте новую модель, используя вложения YAMNet, чтобы классифицировать звуки кошек и собак.
- Оцените и экспортируйте свою модель.
Импорт TensorFlow и других библиотек
Начните с установки TensorFlow I/O , что облегчит вам загрузку аудиофайлов с диска.
pip install tensorflow_io
import os
from IPython import display
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_io as tfio
О YAMNet
YAMNet — это предварительно обученная нейронная сеть, использующая архитектуру свертки MobileNetV1 с разделением по глубине. Он может использовать форму аудиосигнала в качестве входных данных и делать независимые прогнозы для каждого из 521 аудиособытия из корпуса AudioSet .
Внутри модель извлекает «кадры» из звукового сигнала и обрабатывает пакеты этих кадров. Эта версия модели использует кадры продолжительностью 0,96 секунды и извлекает один кадр каждые 0,48 секунды.
Модель принимает одномерный массив float32 Tensor или NumPy, содержащий сигнал произвольной длины, представленный в виде одноканальных (моно) выборок 16 кГц в диапазоне [-1.0, +1.0] . Это руководство содержит код, который поможет вам преобразовать файлы WAV в поддерживаемый формат.
Модель возвращает 3 вывода, включая баллы класса, вложения (которые вы будете использовать для трансферного обучения) и спектрограмму log mel. Вы можете найти более подробную информацию здесь .
Одно из конкретных применений YAMNet — это высокоуровневый экстрактор функций — вывод 1024-мерного встраивания. Вы будете использовать входные функции базовой (YAMNet) модели и передавать их в более мелкую модель, состоящую из одного скрытого слоя tf.keras.layers.Dense . Затем вы будете обучать сеть на небольшом количестве данных для классификации звука, не требуя большого количества размеченных данных и сквозного обучения. (Это похоже на перенос обучения для классификации изображений с помощью TensorFlow Hub для получения дополнительной информации.)
Сначала вы протестируете модель и увидите результаты классификации звука. Затем вы создадите конвейер предварительной обработки данных.
Загрузка YAMNet из TensorFlow Hub
Вы собираетесь использовать предварительно обученный YAMNet из Tensorflow Hub для извлечения вложений из звуковых файлов.
Загрузить модель из TensorFlow Hub очень просто: выберите модель, скопируйте ее URL-адрес и используйте функцию load .
yamnet_model_handle = 'https://tfhub.dev/google/yamnet/1'
yamnet_model = hub.load(yamnet_model_handle)
Загрузив модель, вы можете следовать основному руководству по использованию YAMNet и загрузить образец WAV-файла, чтобы выполнить вывод.
testing_wav_file_name = tf.keras.utils.get_file('miaow_16k.wav',
'https://storage.googleapis.com/audioset/miaow_16k.wav',
cache_dir='./',
cache_subdir='test_data')
print(testing_wav_file_name)
Downloading data from https://storage.googleapis.com/audioset/miaow_16k.wav 221184/215546 [==============================] - 0s 0us/step 229376/215546 [===============================] - 0s 0us/step ./test_data/miaow_16k.wav
Вам понадобится функция для загрузки аудиофайлов, которая также будет использоваться в дальнейшем при работе с обучающими данными. (Узнайте больше о чтении аудиофайлов и их меток в разделе Простое распознавание аудио .
# Utility functions for loading audio files and making sure the sample rate is correct.
@tf.function
def load_wav_16k_mono(filename):
""" Load a WAV file, convert it to a float tensor, resample to 16 kHz single-channel audio. """
file_contents = tf.io.read_file(filename)
wav, sample_rate = tf.audio.decode_wav(
file_contents,
desired_channels=1)
wav = tf.squeeze(wav, axis=-1)
sample_rate = tf.cast(sample_rate, dtype=tf.int64)
wav = tfio.audio.resample(wav, rate_in=sample_rate, rate_out=16000)
return wav
testing_wav_data = load_wav_16k_mono(testing_wav_file_name)
_ = plt.plot(testing_wav_data)
# Play the audio file.
display.Audio(testing_wav_data,rate=16000)
2022-01-26 08:07:19.084427: W tensorflow_io/core/kernels/audio_video_mp3_kernels.cc:271] libmp3lame.so.0 or lame functions are not available WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample

Загрузите сопоставление классов
Важно загружать имена классов, которые YAMNet может распознать. Файл сопоставления находится в yamnet_model.class_map_path() в формате CSV.
class_map_path = yamnet_model.class_map_path().numpy().decode('utf-8')
class_names =list(pd.read_csv(class_map_path)['display_name'])
for name in class_names[:20]:
print(name)
print('...')
Speech Child speech, kid speaking Conversation Narration, monologue Babbling Speech synthesizer Shout Bellow Whoop Yell Children shouting Screaming Whispering Laughter Baby laughter Giggle Snicker Belly laugh Chuckle, chortle Crying, sobbing ...
Запустить вывод
YAMNet предоставляет оценки классов на уровне кадров (т. е. 521 оценка для каждого кадра). Чтобы определить прогнозы на уровне клипа, оценки могут быть агрегированы для каждого класса по кадрам (например, с использованием среднего или максимального агрегирования). Это делается ниже с помощью scores_np.mean(axis=0) . Наконец, чтобы найти класс с наивысшим баллом на уровне клипа, вы берете максимум из 521 агрегированного балла.
scores, embeddings, spectrogram = yamnet_model(testing_wav_data)
class_scores = tf.reduce_mean(scores, axis=0)
top_class = tf.argmax(class_scores)
inferred_class = class_names[top_class]
print(f'The main sound is: {inferred_class}')
print(f'The embeddings shape: {embeddings.shape}')
The main sound is: Animal The embeddings shape: (13, 1024)
Набор данных ESC-50
Набор данных ESC-50 ( Piczak, 2015 ) представляет собой помеченную коллекцию из 2000 пятисекундных аудиозаписей окружающей среды. Набор данных состоит из 50 классов, по 40 примеров в каждом классе.
Загрузите набор данных и извлеките его.
_ = tf.keras.utils.get_file('esc-50.zip',
'https://github.com/karoldvl/ESC-50/archive/master.zip',
cache_dir='./',
cache_subdir='datasets',
extract=True)
Downloading data from https://github.com/karoldvl/ESC-50/archive/master.zip 645103616/Unknown - 47s 0us/step
Исследуйте данные
Метаданные для каждого файла указаны в CSV-файле по адресу ./datasets/ESC-50-master/meta/esc50.csv
и все аудиофайлы находятся в ./datasets/ESC-50-master/audio/
Вы создадите DataFrame с отображением и будете использовать его для более четкого представления данных.
esc50_csv = './datasets/ESC-50-master/meta/esc50.csv'
base_data_path = './datasets/ESC-50-master/audio/'
pd_data = pd.read_csv(esc50_csv)
pd_data.head()
Фильтровать данные
Теперь, когда данные хранятся в DataFrame , примените некоторые преобразования:
- Отфильтруйте строки и используйте только выбранные классы —
dogиcat. Если вы хотите использовать какие-либо другие классы, вы можете выбрать их здесь. - Измените имя файла, чтобы он содержал полный путь. Это облегчит загрузку позже.
- Измените цели, чтобы они находились в определенном диапазоне. В этом примере
dogостанется равным0, аcatстанет равным1вместо исходного значения5.
my_classes = ['dog', 'cat']
map_class_to_id = {'dog':0, 'cat':1}
filtered_pd = pd_data[pd_data.category.isin(my_classes)]
class_id = filtered_pd['category'].apply(lambda name: map_class_to_id[name])
filtered_pd = filtered_pd.assign(target=class_id)
full_path = filtered_pd['filename'].apply(lambda row: os.path.join(base_data_path, row))
filtered_pd = filtered_pd.assign(filename=full_path)
filtered_pd.head(10)
Загрузите аудиофайлы и извлеките вложения
Здесь вы примените load_wav_16k_mono и подготовите данные WAV для модели.
При извлечении вложений из данных WAV вы получаете массив формы (N, 1024) где N — количество кадров, найденных YAMNet (по одному на каждые 0,48 секунды звука).
Ваша модель будет использовать каждый кадр как один вход. Поэтому вам нужно создать новый столбец с одним кадром в строке. Вам также необходимо расширить метки и столбец fold , чтобы правильно отразить эти новые строки.
Расширенный столбец fold сохраняет исходные значения. Вы не можете смешивать кадры, потому что при выполнении разделения вы можете получить части одного и того же звука в разных разделениях, что сделает ваши шаги проверки и тестирования менее эффективными.
filenames = filtered_pd['filename']
targets = filtered_pd['target']
folds = filtered_pd['fold']
main_ds = tf.data.Dataset.from_tensor_slices((filenames, targets, folds))
main_ds.element_spec
(TensorSpec(shape=(), dtype=tf.string, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
def load_wav_for_map(filename, label, fold):
return load_wav_16k_mono(filename), label, fold
main_ds = main_ds.map(load_wav_for_map)
main_ds.element_spec
WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample (TensorSpec(shape=<unknown>, dtype=tf.float32, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
# applies the embedding extraction model to a wav data
def extract_embedding(wav_data, label, fold):
''' run YAMNet to extract embedding from the wav data '''
scores, embeddings, spectrogram = yamnet_model(wav_data)
num_embeddings = tf.shape(embeddings)[0]
return (embeddings,
tf.repeat(label, num_embeddings),
tf.repeat(fold, num_embeddings))
# extract embedding
main_ds = main_ds.map(extract_embedding).unbatch()
main_ds.element_spec
(TensorSpec(shape=(1024,), dtype=tf.float32, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))
Разделить данные
Вы будете использовать столбец fold , чтобы разделить набор данных на обучающие, проверочные и тестовые наборы.
ESC-50 организован в пять одинаковых по размеру fold перекрестной проверки, так что клипы из одного и того же исходного источника всегда находятся в одном и том же fold — узнайте больше в документе ESC: Dataset for Environmental Sound Classification .
Последний шаг — удалить столбец fold из набора данных, поскольку вы не собираетесь использовать его во время обучения.
cached_ds = main_ds.cache()
train_ds = cached_ds.filter(lambda embedding, label, fold: fold < 4)
val_ds = cached_ds.filter(lambda embedding, label, fold: fold == 4)
test_ds = cached_ds.filter(lambda embedding, label, fold: fold == 5)
# remove the folds column now that it's not needed anymore
remove_fold_column = lambda embedding, label, fold: (embedding, label)
train_ds = train_ds.map(remove_fold_column)
val_ds = val_ds.map(remove_fold_column)
test_ds = test_ds.map(remove_fold_column)
train_ds = train_ds.cache().shuffle(1000).batch(32).prefetch(tf.data.AUTOTUNE)
val_ds = val_ds.cache().batch(32).prefetch(tf.data.AUTOTUNE)
test_ds = test_ds.cache().batch(32).prefetch(tf.data.AUTOTUNE)
Создайте свою модель
Вы сделали большую часть работы! Затем определите очень простую модель Sequential с одним скрытым слоем и двумя выходными данными для распознавания кошек и собак по звукам.
my_model = tf.keras.Sequential([
tf.keras.layers.Input(shape=(1024), dtype=tf.float32,
name='input_embedding'),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(len(my_classes))
], name='my_model')
my_model.summary()
Model: "my_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 512) 524800
dense_1 (Dense) (None, 2) 1026
=================================================================
Total params: 525,826
Trainable params: 525,826
Non-trainable params: 0
_________________________________________________________________
my_model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer="adam",
metrics=['accuracy'])
callback = tf.keras.callbacks.EarlyStopping(monitor='loss',
patience=3,
restore_best_weights=True)
history = my_model.fit(train_ds,
epochs=20,
validation_data=val_ds,
callbacks=callback)
Epoch 1/20 15/15 [==============================] - 6s 49ms/step - loss: 0.7811 - accuracy: 0.8229 - val_loss: 0.4866 - val_accuracy: 0.9125 Epoch 2/20 15/15 [==============================] - 0s 18ms/step - loss: 0.3385 - accuracy: 0.8938 - val_loss: 0.2185 - val_accuracy: 0.8813 Epoch 3/20 15/15 [==============================] - 0s 18ms/step - loss: 0.3091 - accuracy: 0.9021 - val_loss: 0.4290 - val_accuracy: 0.8813 Epoch 4/20 15/15 [==============================] - 0s 18ms/step - loss: 0.5354 - accuracy: 0.9062 - val_loss: 0.2074 - val_accuracy: 0.9125 Epoch 5/20 15/15 [==============================] - 0s 18ms/step - loss: 0.4651 - accuracy: 0.9333 - val_loss: 0.6857 - val_accuracy: 0.8813 Epoch 6/20 15/15 [==============================] - 0s 18ms/step - loss: 0.2489 - accuracy: 0.9167 - val_loss: 0.3640 - val_accuracy: 0.8750 Epoch 7/20 15/15 [==============================] - 0s 17ms/step - loss: 0.2020 - accuracy: 0.9292 - val_loss: 0.2158 - val_accuracy: 0.9125 Epoch 8/20 15/15 [==============================] - 0s 16ms/step - loss: 0.4550 - accuracy: 0.9208 - val_loss: 0.9893 - val_accuracy: 0.8750 Epoch 9/20 15/15 [==============================] - 0s 17ms/step - loss: 0.3434 - accuracy: 0.9354 - val_loss: 0.2670 - val_accuracy: 0.8813 Epoch 10/20 15/15 [==============================] - 0s 17ms/step - loss: 0.2864 - accuracy: 0.9208 - val_loss: 0.5122 - val_accuracy: 0.8813
Давайте запустим метод evaluate на тестовых данных, чтобы убедиться, что нет переобучения.
loss, accuracy = my_model.evaluate(test_ds)
print("Loss: ", loss)
print("Accuracy: ", accuracy)
5/5 [==============================] - 0s 9ms/step - loss: 0.2526 - accuracy: 0.9000 Loss: 0.25257644057273865 Accuracy: 0.8999999761581421
Ты сделал это!
Протестируйте свою модель
Затем попробуйте свою модель на встраивании из предыдущего теста, используя только YAMNet.
scores, embeddings, spectrogram = yamnet_model(testing_wav_data)
result = my_model(embeddings).numpy()
inferred_class = my_classes[result.mean(axis=0).argmax()]
print(f'The main sound is: {inferred_class}')
The main sound is: cat
Сохраните модель, которая может напрямую принимать WAV-файл в качестве входных данных.
Ваша модель работает, когда вы даете ей вложения в качестве входных данных.
В реальном сценарии вы захотите использовать аудиоданные в качестве прямого ввода.
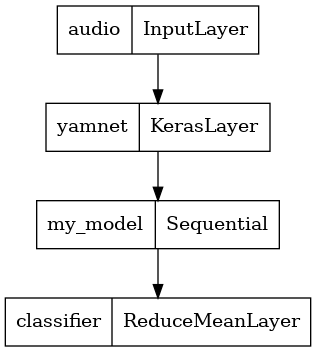
Для этого вы объедините YAMNet со своей моделью в единую модель, которую сможете экспортировать для других приложений.
Чтобы было проще использовать результат модели, последним слоем будет операция reduce_mean . При использовании этой модели для сервировки (о которой вы узнаете позже в этом уроке) вам понадобится имя финального слоя. Если вы не определите его, TensorFlow автоматически определит добавочный, что затруднит тестирование, поскольку он будет меняться каждый раз, когда вы обучаете модель. При использовании необработанной операции TensorFlow вы не можете присвоить ей имя. Чтобы решить эту проблему, вы создадите пользовательский слой, который применяет reduce_mean , и назовете его 'classifier' .
class ReduceMeanLayer(tf.keras.layers.Layer):
def __init__(self, axis=0, **kwargs):
super(ReduceMeanLayer, self).__init__(**kwargs)
self.axis = axis
def call(self, input):
return tf.math.reduce_mean(input, axis=self.axis)
saved_model_path = './dogs_and_cats_yamnet'
input_segment = tf.keras.layers.Input(shape=(), dtype=tf.float32, name='audio')
embedding_extraction_layer = hub.KerasLayer(yamnet_model_handle,
trainable=False, name='yamnet')
_, embeddings_output, _ = embedding_extraction_layer(input_segment)
serving_outputs = my_model(embeddings_output)
serving_outputs = ReduceMeanLayer(axis=0, name='classifier')(serving_outputs)
serving_model = tf.keras.Model(input_segment, serving_outputs)
serving_model.save(saved_model_path, include_optimizer=False)
WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model. 2022-01-26 08:08:33.807036: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: ./dogs_and_cats_yamnet/assets INFO:tensorflow:Assets written to: ./dogs_and_cats_yamnet/assets
tf.keras.utils.plot_model(serving_model)
Загрузите сохраненную модель, чтобы убедиться, что она работает должным образом.
reloaded_model = tf.saved_model.load(saved_model_path)
И последний тест: учитывая некоторые звуковые данные, возвращает ли ваша модель правильный результат?
reloaded_results = reloaded_model(testing_wav_data)
cat_or_dog = my_classes[tf.argmax(reloaded_results)]
print(f'The main sound is: {cat_or_dog}')
The main sound is: cat
Если вы хотите попробовать свою новую модель в настройке обслуживания, вы можете использовать сигнатуру serving_default.
serving_results = reloaded_model.signatures['serving_default'](testing_wav_data)
cat_or_dog = my_classes[tf.argmax(serving_results['classifier'])]
print(f'The main sound is: {cat_or_dog}')
The main sound is: cat
(Необязательно) Еще несколько тестов
Модель готова.
Давайте сравним его с YAMNet в тестовом наборе данных.
test_pd = filtered_pd.loc[filtered_pd['fold'] == 5]
row = test_pd.sample(1)
filename = row['filename'].item()
print(filename)
waveform = load_wav_16k_mono(filename)
print(f'Waveform values: {waveform}')
_ = plt.plot(waveform)
display.Audio(waveform, rate=16000)
./datasets/ESC-50-master/audio/5-214759-A-5.wav WARNING:tensorflow:Using a while_loop for converting IO>AudioResample WARNING:tensorflow:Using a while_loop for converting IO>AudioResample Waveform values: [ 3.2084468e-09 -7.7704687e-09 -1.2222010e-08 ... 2.2788899e-02 1.0315948e-02 -3.4766860e-02]
# Run the model, check the output.
scores, embeddings, spectrogram = yamnet_model(waveform)
class_scores = tf.reduce_mean(scores, axis=0)
top_class = tf.argmax(class_scores)
inferred_class = class_names[top_class]
top_score = class_scores[top_class]
print(f'[YAMNet] The main sound is: {inferred_class} ({top_score})')
reloaded_results = reloaded_model(waveform)
your_top_class = tf.argmax(reloaded_results)
your_inferred_class = my_classes[your_top_class]
class_probabilities = tf.nn.softmax(reloaded_results, axis=-1)
your_top_score = class_probabilities[your_top_class]
print(f'[Your model] The main sound is: {your_inferred_class} ({your_top_score})')
[YAMNet] The main sound is: Silence (0.500638484954834) [Your model] The main sound is: cat (0.9981643557548523)
Следующие шаги
Вы создали модель, которая может классифицировать звуки собак или кошек. С той же идеей и другим набором данных вы можете попробовать, например, построить акустический идентификатор птиц на основе их пения.
Поделитесь своим проектом с командой TensorFlow в социальных сетях!