
|
|
|
 View source on GitHub
View source on GitHub
|
|
This tutorial demonstrates how to classify structured data, such as tabular data, using a simplified version of the PetFinder dataset from a Kaggle competition stored in a CSV file.
You will use Keras to define the model, and Keras preprocessing layers as a bridge to map from columns in a CSV file to features used to train the model. The goal is to predict if a pet will be adopted.
This tutorial contains complete code for:
- Loading a CSV file into a DataFrame using pandas.
- Building an input pipeline to batch and shuffle the rows using
tf.data. (Visit tf.data: Build TensorFlow input pipelines for more details.) - Mapping from columns in the CSV file to features used to train the model with the Keras preprocessing layers.
- Building, training, and evaluating a model using the Keras built-in methods.
The PetFinder.my mini dataset
There are several thousand rows in the PetFinder.my mini's CSV dataset file, where each row describes a pet (a dog or a cat) and each column describes an attribute, such as age, breed, color, and so on.
In the dataset's summary below, notice there are mostly numerical and categorical columns. In this tutorial, you will only be dealing with those two feature types, dropping Description (a free text feature) and AdoptionSpeed (a classification feature) during data preprocessing.
| Column | Pet description | Feature type | Data type |
|---|---|---|---|
Type |
Type of animal (Dog, Cat) |
Categorical | String |
Age |
Age | Numerical | Integer |
Breed1 |
Primary breed | Categorical | String |
Color1 |
Color 1 | Categorical | String |
Color2 |
Color 2 | Categorical | String |
MaturitySize |
Size at maturity | Categorical | String |
FurLength |
Fur length | Categorical | String |
Vaccinated |
Pet has been vaccinated | Categorical | String |
Sterilized |
Pet has been sterilized | Categorical | String |
Health |
Health condition | Categorical | String |
Fee |
Adoption fee | Numerical | Integer |
Description |
Profile write-up | Text | String |
PhotoAmt |
Total uploaded photos | Numerical | Integer |
AdoptionSpeed |
Categorical speed of adoption | Classification | Integer |
Import TensorFlow and other libraries
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow.keras import layers
2024-09-05 01:20:38.599507: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:485] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered 2024-09-05 01:20:38.620596: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:8454] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered 2024-09-05 01:20:38.626833: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1452] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
tf.__version__
'2.17.0'
Load the dataset and read it into a pandas DataFrame
pandas is a Python library with many helpful utilities for loading and working with structured data. Use tf.keras.utils.get_file to download and extract the CSV file with the PetFinder.my mini dataset, and load it into a DataFrame with pandas.read_csv:
dataset_url = 'http://storage.googleapis.com/download.tensorflow.org/data/petfinder-mini.zip'
csv_file = 'datasets/petfinder-mini/petfinder-mini.csv'
tf.keras.utils.get_file('petfinder_mini.zip', dataset_url,
extract=True, cache_dir='.')
dataframe = pd.read_csv(csv_file)
Downloading data from http://storage.googleapis.com/download.tensorflow.org/data/petfinder-mini.zip 1668792/1668792 ━━━━━━━━━━━━━━━━━━━━ 0s 0us/step
Inspect the dataset by checking the first five rows of the DataFrame:
dataframe.head()
Create a target variable
The original task in Kaggle's PetFinder.my Adoption Prediction competition was to predict the speed at which a pet will be adopted (e.g. in the first week, the first month, the first three months, and so on).
In this tutorial, you will simplify the task by transforming it into a binary classification problem, where you simply have to predict whether a pet was adopted or not.
After modifying the AdoptionSpeed column, 0 will indicate the pet was not adopted, and 1 will indicate it was.
# In the original dataset, `'AdoptionSpeed'` of `4` indicates
# a pet was not adopted.
dataframe['target'] = np.where(dataframe['AdoptionSpeed']==4, 0, 1)
# Drop unused features.
dataframe = dataframe.drop(columns=['AdoptionSpeed', 'Description'])
Split the DataFrame into training, validation, and test sets
The dataset is in a single pandas DataFrame. Split it into training, validation, and test sets using a, for example, 80:10:10 ratio, respectively:
train, val, test = np.split(dataframe.sample(frac=1), [int(0.8*len(dataframe)), int(0.9*len(dataframe))])
/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/numpy/core/fromnumeric.py:59: FutureWarning: 'DataFrame.swapaxes' is deprecated and will be removed in a future version. Please use 'DataFrame.transpose' instead. return bound(*args, **kwds)
print(len(train), 'training examples')
print(len(val), 'validation examples')
print(len(test), 'test examples')
9229 training examples 1154 validation examples 1154 test examples
Create an input pipeline using tf.data
Next, create a utility function that converts each training, validation, and test set DataFrame into a tf.data.Dataset, then shuffles and batches the data.
def df_to_dataset(dataframe, shuffle=True, batch_size=32):
df = dataframe.copy()
labels = df.pop('target')
df = {key: value.to_numpy()[:,tf.newaxis] for key, value in dataframe.items()}
ds = tf.data.Dataset.from_tensor_slices((dict(df), labels))
if shuffle:
ds = ds.shuffle(buffer_size=len(dataframe))
ds = ds.batch(batch_size)
ds = ds.prefetch(batch_size)
return ds
Now, use the newly created function (df_to_dataset) to check the format of the data the input pipeline helper function returns by calling it on the training data, and use a small batch size to keep the output readable:
batch_size = 5
train_ds = df_to_dataset(train, batch_size=batch_size)
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR I0000 00:00:1725499241.160728 9812 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1725499241.164528 9812 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1725499241.168293 9812 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1725499241.172081 9812 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1725499241.183202 9812 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1725499241.186712 9812 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1725499241.190256 9812 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1725499241.193740 9812 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1725499241.197250 9812 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1725499241.200723 9812 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1725499241.204294 9812 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1725499241.207818 9812 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1725499242.457392 9812 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1725499242.459472 9812 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1725499242.461579 9812 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1725499242.463650 9812 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1725499242.465730 9812 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1725499242.467675 9812 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1725499242.469695 9812 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1725499242.471876 9812 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1725499242.473835 9812 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1725499242.475755 9812 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1725499242.477755 9812 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1725499242.480239 9812 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1725499242.522691 9812 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1725499242.524681 9812 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1725499242.526832 9812 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1725499242.528865 9812 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1725499242.530735 9812 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1725499242.532710 9812 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1725499242.534711 9812 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1725499242.536716 9812 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1725499242.538582 9812 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1725499242.542138 9812 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1725499242.544598 9812 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1725499242.547054 9812 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
[(train_features, label_batch)] = train_ds.take(1)
print('Every feature:', list(train_features.keys()))
print('A batch of ages:', train_features['Age'])
print('A batch of targets:', label_batch )
Every feature: ['Type', 'Age', 'Breed1', 'Gender', 'Color1', 'Color2', 'MaturitySize', 'FurLength', 'Vaccinated', 'Sterilized', 'Health', 'Fee', 'PhotoAmt', 'target'] A batch of ages: tf.Tensor( [[5] [2] [2] [3] [3]], shape=(5, 1), dtype=int64) A batch of targets: tf.Tensor([1 1 1 1 1], shape=(5,), dtype=int64)
As the output demonstrates, the training set returns a dictionary of column names (from the DataFrame) that map to column values from rows.
Apply the Keras preprocessing layers
The Keras preprocessing layers allow you to build Keras-native input processing pipelines, which can be used as independent preprocessing code in non-Keras workflows, combined directly with Keras models, and exported as part of a Keras SavedModel.
In this tutorial, you will use the following four preprocessing layers to demonstrate how to perform preprocessing, structured data encoding, and feature engineering:
tf.keras.layers.Normalization: Performs feature-wise normalization of input features.tf.keras.layers.CategoryEncoding: Turns integer categorical features into one-hot, multi-hot, or tf-idf dense representations.tf.keras.layers.StringLookup: Turns string categorical values into integer indices.tf.keras.layers.IntegerLookup: Turns integer categorical values into integer indices.
You can learn more about the available layers in the Working with preprocessing layers guide.
- For numerical features of the PetFinder.my mini dataset, you will use a
tf.keras.layers.Normalizationlayer to standardize the distribution of the data. - For categorical features, such as pet
Types (DogandCatstrings), you will transform them to multi-hot encoded tensors withtf.keras.layers.CategoryEncoding.
Numerical columns
For each numeric feature in the PetFinder.my mini dataset, you will use a tf.keras.layers.Normalization layer to standardize the distribution of the data.
Define a new utility function that returns a layer which applies feature-wise normalization to numerical features using that Keras preprocessing layer:
def get_normalization_layer(name, dataset):
# Create a Normalization layer for the feature.
normalizer = layers.Normalization(axis=None)
# Prepare a Dataset that only yields the feature.
feature_ds = dataset.map(lambda x, y: x[name])
# Learn the statistics of the data.
normalizer.adapt(feature_ds)
return normalizer
Next, test the new function by calling it on the total uploaded pet photo features to normalize 'PhotoAmt':
photo_count_col = train_features['PhotoAmt']
layer = get_normalization_layer('PhotoAmt', train_ds)
layer(photo_count_col)
<tf.Tensor: shape=(5, 1), dtype=float32, numpy=
array([[-0.19791041],
[-0.82850194],
[-0.5132062 ],
[-0.5132062 ],
[-0.82850194]], dtype=float32)>
Categorical columns
Pet Types in the dataset are represented as strings—Dogs and Cats—which need to be multi-hot encoded before being fed into the model. The Age feature
Define another new utility function that returns a layer which maps values from a vocabulary to integer indices and multi-hot encodes the features using the tf.keras.layers.StringLookup, tf.keras.layers.IntegerLookup, and tf.keras.CategoryEncoding preprocessing layers:
def get_category_encoding_layer(name, dataset, dtype, max_tokens=None):
# Create a layer that turns strings into integer indices.
if dtype == 'string':
index = layers.StringLookup(max_tokens=max_tokens)
# Otherwise, create a layer that turns integer values into integer indices.
else:
index = layers.IntegerLookup(max_tokens=max_tokens)
# Prepare a `tf.data.Dataset` that only yields the feature.
feature_ds = dataset.map(lambda x, y: x[name])
# Learn the set of possible values and assign them a fixed integer index.
index.adapt(feature_ds)
# Encode the integer indices.
encoder = layers.CategoryEncoding(num_tokens=index.vocabulary_size())
# Apply multi-hot encoding to the indices. The lambda function captures the
# layer, so you can use them, or include them in the Keras Functional model later.
return lambda feature: encoder(index(feature))
Test the get_category_encoding_layer function by calling it on pet 'Type' features to turn them into multi-hot encoded tensors:
test_type_col = train_features['Type']
test_type_layer = get_category_encoding_layer(name='Type',
dataset=train_ds,
dtype='string')
test_type_layer(test_type_col)
<tf.Tensor: shape=(5, 3), dtype=float32, numpy=
array([[0., 1., 0.],
[0., 1., 0.],
[0., 1., 0.],
[0., 0., 1.],
[0., 0., 1.]], dtype=float32)>
Repeat the process on the pet 'Age' features:
test_age_col = train_features['Age']
test_age_layer = get_category_encoding_layer(name='Age',
dataset=train_ds,
dtype='int64',
max_tokens=5)
test_age_layer(test_age_col)
<tf.Tensor: shape=(5, 5), dtype=float32, numpy=
array([[1., 0., 0., 0., 0.],
[0., 1., 0., 0., 0.],
[0., 1., 0., 0., 0.],
[0., 0., 1., 0., 0.],
[0., 0., 1., 0., 0.]], dtype=float32)>
Preprocess selected features to train the model on
You have learned how to use several types of Keras preprocessing layers. Next, you will:
- Apply the preprocessing utility functions defined earlier on 13 numerical and categorical features from the PetFinder.my mini dataset.
- Add all the feature inputs to a list.
As mentioned in the beginning, to train the model, you will use the PetFinder.my mini dataset's numerical ('PhotoAmt', 'Fee') and categorical ('Age', 'Type', 'Color1', 'Color2', 'Gender', 'MaturitySize', 'FurLength', 'Vaccinated', 'Sterilized', 'Health', 'Breed1') features.
Earlier, you used a small batch size to demonstrate the input pipeline. Let's now create a new input pipeline with a larger batch size of 256:
batch_size = 256
train_ds = df_to_dataset(train, batch_size=batch_size)
val_ds = df_to_dataset(val, shuffle=False, batch_size=batch_size)
test_ds = df_to_dataset(test, shuffle=False, batch_size=batch_size)
Normalize the numerical features (the number of pet photos and the adoption fee), and add them to one list of inputs called encoded_features:
all_inputs = {}
encoded_features = []
# Numerical features.
for header in ['PhotoAmt', 'Fee']:
numeric_col = tf.keras.Input(shape=(1,), name=header)
normalization_layer = get_normalization_layer(header, train_ds)
encoded_numeric_col = normalization_layer(numeric_col)
all_inputs[header] = numeric_col
encoded_features.append(encoded_numeric_col)
Turn the integer categorical values from the dataset (the pet age) into integer indices, perform multi-hot encoding, and add the resulting feature inputs to encoded_features:
age_col = tf.keras.Input(shape=(1,), name='Age', dtype='int64')
encoding_layer = get_category_encoding_layer(name='Age',
dataset=train_ds,
dtype='int64',
max_tokens=5)
encoded_age_col = encoding_layer(age_col)
all_inputs['Age'] = age_col
encoded_features.append(encoded_age_col)
Repeat the same step for the string categorical values:
categorical_cols = ['Type', 'Color1', 'Color2', 'Gender', 'MaturitySize',
'FurLength', 'Vaccinated', 'Sterilized', 'Health', 'Breed1']
for header in categorical_cols:
categorical_col = tf.keras.Input(shape=(1,), name=header, dtype='string')
encoding_layer = get_category_encoding_layer(name=header,
dataset=train_ds,
dtype='string',
max_tokens=5)
encoded_categorical_col = encoding_layer(categorical_col)
all_inputs[header] = categorical_col
encoded_features.append(encoded_categorical_col)
Create, compile, and train the model
The next step is to create a model using the Keras Functional API. For the first layer in your model, merge the list of feature inputs—encoded_features—into one vector via concatenation with tf.keras.layers.concatenate.
encoded_features
[<KerasTensor shape=(None, 1), dtype=float32, sparse=False, name=keras_tensor>, <KerasTensor shape=(None, 1), dtype=float32, sparse=False, name=keras_tensor_1>, <KerasTensor shape=(None, 5), dtype=float32, sparse=False, name=keras_tensor_3>, <KerasTensor shape=(None, 3), dtype=float32, sparse=False, name=keras_tensor_5>, <KerasTensor shape=(None, 5), dtype=float32, sparse=False, name=keras_tensor_7>, <KerasTensor shape=(None, 5), dtype=float32, sparse=False, name=keras_tensor_9>, <KerasTensor shape=(None, 3), dtype=float32, sparse=False, name=keras_tensor_11>, <KerasTensor shape=(None, 4), dtype=float32, sparse=False, name=keras_tensor_13>, <KerasTensor shape=(None, 4), dtype=float32, sparse=False, name=keras_tensor_15>, <KerasTensor shape=(None, 4), dtype=float32, sparse=False, name=keras_tensor_17>, <KerasTensor shape=(None, 4), dtype=float32, sparse=False, name=keras_tensor_19>, <KerasTensor shape=(None, 4), dtype=float32, sparse=False, name=keras_tensor_21>, <KerasTensor shape=(None, 5), dtype=float32, sparse=False, name=keras_tensor_23>]
all_features = tf.keras.layers.concatenate(encoded_features)
x = tf.keras.layers.Dense(32, activation="relu")(all_features)
x = tf.keras.layers.Dropout(0.5)(x)
output = tf.keras.layers.Dense(1)(x)
model = tf.keras.Model(all_inputs, output)
Configure the model with Keras Model.compile:
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=["accuracy"],
run_eagerly=True)
Let's visualize the connectivity graph:
# Use `rankdir='LR'` to make the graph horizontal.
tf.keras.utils.plot_model(model, show_shapes=True, show_layer_names=True, rankdir="LR")
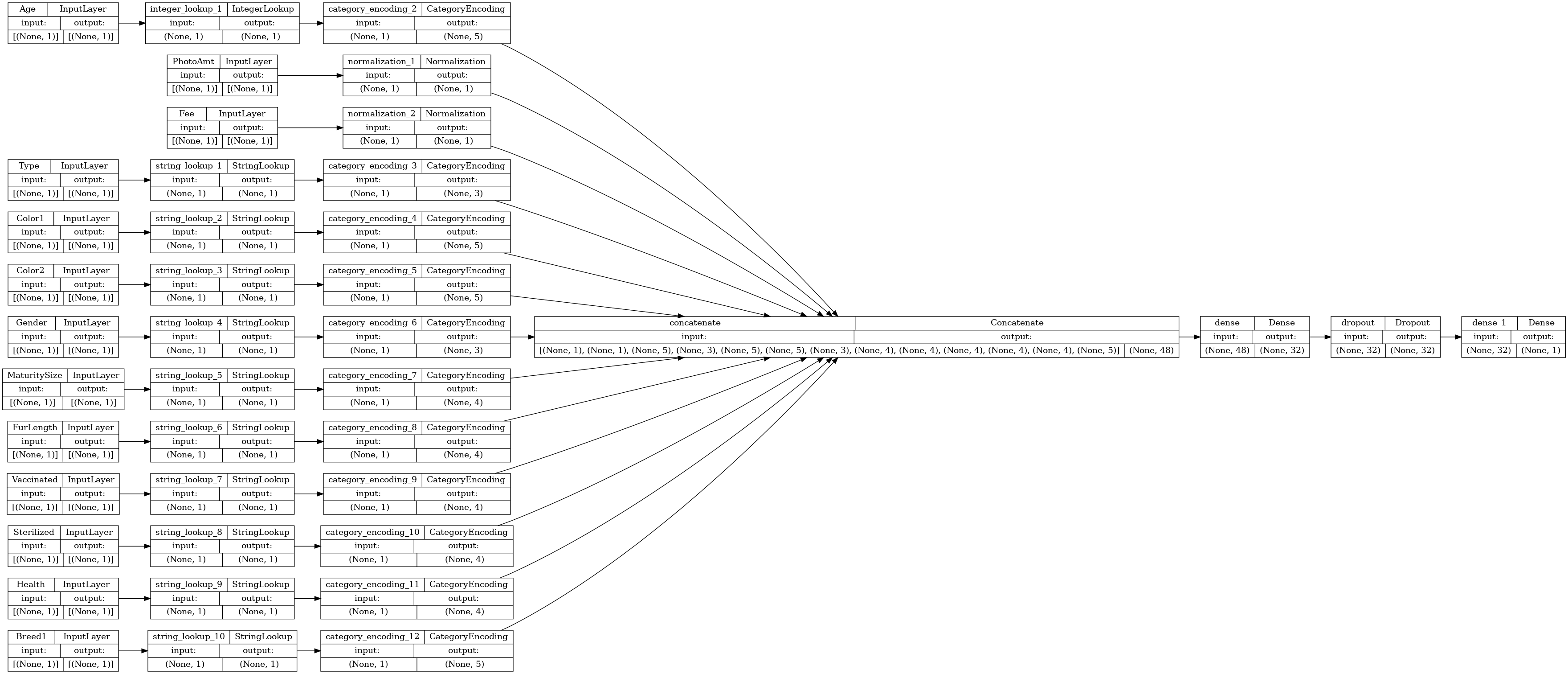
Next, train and test the model:
model.fit(train_ds, epochs=10, validation_data=val_ds)
Epoch 1/10 37/37 ━━━━━━━━━━━━━━━━━━━━ 3s 56ms/step - accuracy: 0.5514 - loss: 0.6413 - val_accuracy: 0.7504 - val_loss: 0.5363 Epoch 2/10 37/37 ━━━━━━━━━━━━━━━━━━━━ 2s 54ms/step - accuracy: 0.6406 - loss: 0.5972 - val_accuracy: 0.7470 - val_loss: 0.5207 Epoch 3/10 37/37 ━━━━━━━━━━━━━━━━━━━━ 2s 54ms/step - accuracy: 0.6941 - loss: 0.5595 - val_accuracy: 0.7470 - val_loss: 0.5103 Epoch 4/10 37/37 ━━━━━━━━━━━━━━━━━━━━ 2s 54ms/step - accuracy: 0.6888 - loss: 0.5586 - val_accuracy: 0.7539 - val_loss: 0.5042 Epoch 5/10 37/37 ━━━━━━━━━━━━━━━━━━━━ 2s 53ms/step - accuracy: 0.7079 - loss: 0.5410 - val_accuracy: 0.7530 - val_loss: 0.4996 Epoch 6/10 37/37 ━━━━━━━━━━━━━━━━━━━━ 2s 53ms/step - accuracy: 0.7065 - loss: 0.5407 - val_accuracy: 0.7504 - val_loss: 0.4959 Epoch 7/10 37/37 ━━━━━━━━━━━━━━━━━━━━ 2s 52ms/step - accuracy: 0.7106 - loss: 0.5370 - val_accuracy: 0.7556 - val_loss: 0.4941 Epoch 8/10 37/37 ━━━━━━━━━━━━━━━━━━━━ 2s 54ms/step - accuracy: 0.7131 - loss: 0.5302 - val_accuracy: 0.7591 - val_loss: 0.4922 Epoch 9/10 37/37 ━━━━━━━━━━━━━━━━━━━━ 2s 53ms/step - accuracy: 0.7216 - loss: 0.5289 - val_accuracy: 0.7582 - val_loss: 0.4908 Epoch 10/10 37/37 ━━━━━━━━━━━━━━━━━━━━ 2s 53ms/step - accuracy: 0.7211 - loss: 0.5266 - val_accuracy: 0.7574 - val_loss: 0.4899 <keras.src.callbacks.history.History at 0x7f2b280947f0>
result = model.evaluate(test_ds, return_dict=True)
print(result)
5/5 ━━━━━━━━━━━━━━━━━━━━ 0s 25ms/step - accuracy: 0.7408 - loss: 0.5098
{'accuracy': 0.737434983253479, 'loss': 0.5158435702323914}
Perform inference
The model you have developed can now classify a row from a CSV file directly after you've included the preprocessing layers inside the model itself.
You can now save and reload the Keras model with Model.save and Model.load_model before performing inference on new data:
model.save('my_pet_classifier.keras')
reloaded_model = tf.keras.models.load_model('my_pet_classifier.keras')
To get a prediction for a new sample, you can simply call the Keras Model.predict method. There are just two things you need to do:
- Wrap scalars into a list so as to have a batch dimension (
Models only process batches of data, not single samples). - Call
tf.convert_to_tensoron each feature.
sample = {
'Type': 'Cat',
'Age': 3,
'Breed1': 'Tabby',
'Gender': 'Male',
'Color1': 'Black',
'Color2': 'White',
'MaturitySize': 'Small',
'FurLength': 'Short',
'Vaccinated': 'No',
'Sterilized': 'No',
'Health': 'Healthy',
'Fee': 100,
'PhotoAmt': 2,
}
input_dict = {name: tf.convert_to_tensor([value]) for name, value in sample.items()}
predictions = reloaded_model.predict(input_dict)
prob = tf.nn.sigmoid(predictions[0])
print(
"This particular pet had a %.1f percent probability "
"of getting adopted." % (100 * prob)
)
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 73ms/step This particular pet had a 81.0 percent probability of getting adopted.
Next steps
To learn more about classifying structured data, try working with other datasets. To improve accuracy during training and testing your models, think carefully about which features to include in your model and how they should be represented.
Below are some suggestions for datasets:
- TensorFlow Datasets: MovieLens: A set of movie ratings from a movie recommendation service.
- TensorFlow Datasets: Wine Quality: Two datasets related to red and white variants of the Portuguese "Vinho Verde" wine. You can also find the Red Wine Quality dataset on Kaggle.
- Kaggle: arXiv Dataset: A corpus of 1.7 million scholarly articles from arXiv, covering physics, computer science, math, statistics, electrical engineering, quantitative biology, and economics.