
|
|
|
 View source on GitHub View source on GitHub
|
|
This notebook demonstrates unpaired image to image translation using conditional GAN's, as described in Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks, also known as CycleGAN. The paper proposes a method that can capture the characteristics of one image domain and figure out how these characteristics could be translated into another image domain, all in the absence of any paired training examples.
This notebook assumes you are familiar with Pix2Pix, which you can learn about in the Pix2Pix tutorial. The code for CycleGAN is similar, the main difference is an additional loss function, and the use of unpaired training data.
CycleGAN uses a cycle consistency loss to enable training without the need for paired data. In other words, it can translate from one domain to another without a one-to-one mapping between the source and target domain.
This opens up the possibility to do a lot of interesting tasks like photo-enhancement, image colorization, style transfer, etc. All you need is the source and the target dataset (which is simply a directory of images).


Set up the input pipeline
Install the tensorflow_examples package that enables importing of the generator and the discriminator.
pip install git+https://github.com/tensorflow/examples.gitimport tensorflow as tf
2024-08-16 03:32:53.504656: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:485] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered 2024-08-16 03:32:53.526121: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:8454] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered 2024-08-16 03:32:53.532471: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1452] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
import tensorflow_datasets as tfds
from tensorflow_examples.models.pix2pix import pix2pix
import os
import time
import matplotlib.pyplot as plt
from IPython.display import clear_output
AUTOTUNE = tf.data.AUTOTUNE
Input Pipeline
This tutorial trains a model to translate from images of horses, to images of zebras. You can find this dataset and similar ones here.
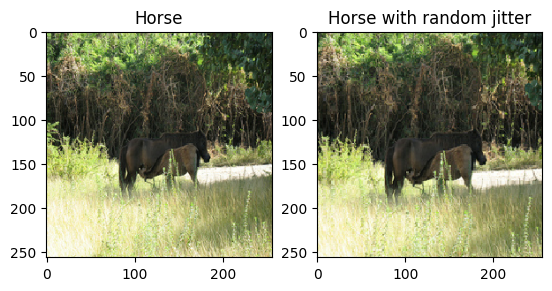
As mentioned in the paper, apply random jittering and mirroring to the training dataset. These are some of the image augmentation techniques that avoids overfitting.
This is similar to what was done in pix2pix
- In random jittering, the image is resized to
286 x 286and then randomly cropped to256 x 256. - In random mirroring, the image is randomly flipped horizontally i.e., left to right.
dataset, metadata = tfds.load('cycle_gan/horse2zebra',
with_info=True, as_supervised=True)
train_horses, train_zebras = dataset['trainA'], dataset['trainB']
test_horses, test_zebras = dataset['testA'], dataset['testB']
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR I0000 00:00:1723779177.668385 151656 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723779177.672215 151656 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723779177.675938 151656 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723779177.679665 151656 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723779177.690837 151656 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723779177.694307 151656 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723779177.697747 151656 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723779177.701202 151656 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723779177.704645 151656 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723779177.708210 151656 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723779177.711701 151656 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723779177.715154 151656 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723779178.941133 151656 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723779178.943273 151656 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723779178.945340 151656 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723779178.947311 151656 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723779178.949287 151656 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723779178.951242 151656 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723779178.953200 151656 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723779178.955081 151656 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723779178.956977 151656 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723779178.958957 151656 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723779178.960927 151656 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723779178.962807 151656 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723779179.000753 151656 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723779179.002808 151656 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723779179.004815 151656 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723779179.006733 151656 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723779179.008636 151656 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723779179.010602 151656 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723779179.012568 151656 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723779179.014451 151656 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723779179.016372 151656 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723779179.018790 151656 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723779179.021194 151656 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355 I0000 00:00:1723779179.023542 151656 cuda_executor.cc:1015] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero. See more at https://github.com/torvalds/linux/blob/v6.0/Documentation/ABI/testing/sysfs-bus-pci#L344-L355
BUFFER_SIZE = 1000
BATCH_SIZE = 1
IMG_WIDTH = 256
IMG_HEIGHT = 256
def random_crop(image):
cropped_image = tf.image.random_crop(
image, size=[IMG_HEIGHT, IMG_WIDTH, 3])
return cropped_image
# normalizing the images to [-1, 1]
def normalize(image):
image = tf.cast(image, tf.float32)
image = (image / 127.5) - 1
return image
def random_jitter(image):
# resizing to 286 x 286 x 3
image = tf.image.resize(image, [286, 286],
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
# randomly cropping to 256 x 256 x 3
image = random_crop(image)
# random mirroring
image = tf.image.random_flip_left_right(image)
return image
def preprocess_image_train(image, label):
image = random_jitter(image)
image = normalize(image)
return image
def preprocess_image_test(image, label):
image = normalize(image)
return image
train_horses = train_horses.cache().map(
preprocess_image_train, num_parallel_calls=AUTOTUNE).shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
train_zebras = train_zebras.cache().map(
preprocess_image_train, num_parallel_calls=AUTOTUNE).shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
test_horses = test_horses.map(
preprocess_image_test, num_parallel_calls=AUTOTUNE).cache().shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
test_zebras = test_zebras.map(
preprocess_image_test, num_parallel_calls=AUTOTUNE).cache().shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
sample_horse = next(iter(train_horses))
sample_zebra = next(iter(train_zebras))
2024-08-16 03:33:01.492073: W tensorflow/core/kernels/data/cache_dataset_ops.cc:913] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead. 2024-08-16 03:33:02.838179: W tensorflow/core/kernels/data/cache_dataset_ops.cc:913] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
plt.subplot(121)
plt.title('Horse')
plt.imshow(sample_horse[0] * 0.5 + 0.5)
plt.subplot(122)
plt.title('Horse with random jitter')
plt.imshow(random_jitter(sample_horse[0]) * 0.5 + 0.5)
<matplotlib.image.AxesImage at 0x7f2940126cd0>
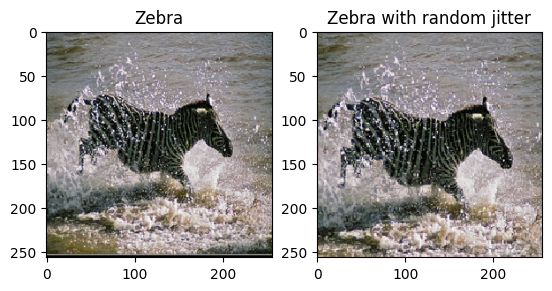
plt.subplot(121)
plt.title('Zebra')
plt.imshow(sample_zebra[0] * 0.5 + 0.5)
plt.subplot(122)
plt.title('Zebra with random jitter')
plt.imshow(random_jitter(sample_zebra[0]) * 0.5 + 0.5)
<matplotlib.image.AxesImage at 0x7f29047c8280>
Import and reuse the Pix2Pix models
Import the generator and the discriminator used in Pix2Pix via the installed tensorflow_examples package.
The model architecture used in this tutorial is very similar to what was used in pix2pix. Some of the differences are:
- Cyclegan uses instance normalization instead of batch normalization.
- The CycleGAN paper uses a modified
resnetbased generator. This tutorial is using a modifiedunetgenerator for simplicity.
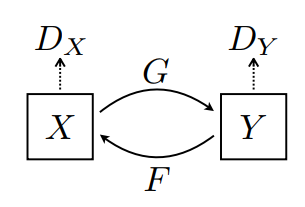
There are 2 generators (G and F) and 2 discriminators (X and Y) being trained here.
- Generator
Glearns to transform imageXto imageY. \((G: X -> Y)\) - Generator
Flearns to transform imageYto imageX. \((F: Y -> X)\) - Discriminator
D_Xlearns to differentiate between imageXand generated imageX(F(Y)). - Discriminator
D_Ylearns to differentiate between imageYand generated imageY(G(X)).
OUTPUT_CHANNELS = 3
generator_g = pix2pix.unet_generator(OUTPUT_CHANNELS, norm_type='instancenorm')
generator_f = pix2pix.unet_generator(OUTPUT_CHANNELS, norm_type='instancenorm')
discriminator_x = pix2pix.discriminator(norm_type='instancenorm', target=False)
discriminator_y = pix2pix.discriminator(norm_type='instancenorm', target=False)
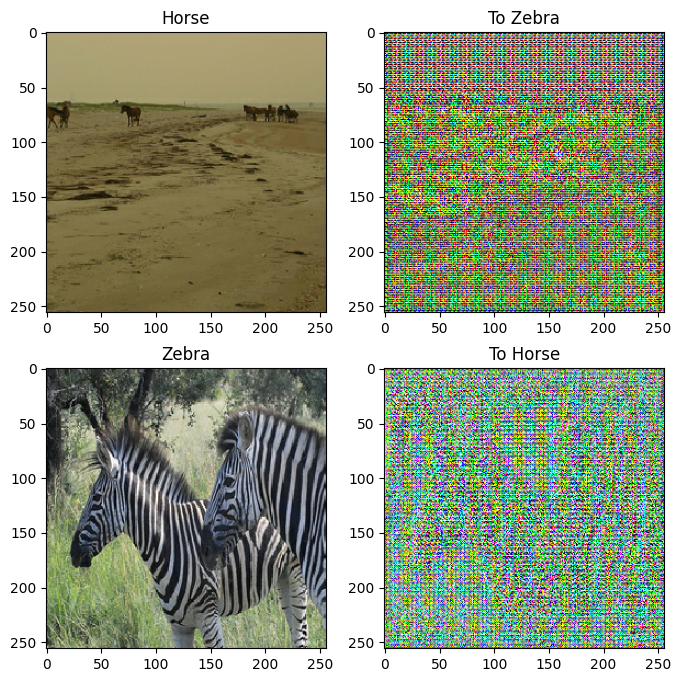
to_zebra = generator_g(sample_horse)
to_horse = generator_f(sample_zebra)
plt.figure(figsize=(8, 8))
contrast = 8
imgs = [sample_horse, to_zebra, sample_zebra, to_horse]
title = ['Horse', 'To Zebra', 'Zebra', 'To Horse']
for i in range(len(imgs)):
plt.subplot(2, 2, i+1)
plt.title(title[i])
if i % 2 == 0:
plt.imshow(imgs[i][0] * 0.5 + 0.5)
else:
plt.imshow(imgs[i][0] * 0.5 * contrast + 0.5)
plt.show()
W0000 00:00:1723779184.437249 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779184.466763 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779184.506117 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779184.507322 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779184.508517 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779184.509696 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779184.510906 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779184.512126 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779184.513441 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779184.514721 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779184.515961 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779184.517223 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779184.520385 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779184.536257 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779184.537872 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779184.539492 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779184.541150 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779184.542793 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779184.544534 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779184.546254 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779184.548027 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779184.549805 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779184.551609 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779184.569168 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779184.571150 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779184.573281 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779184.575496 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779184.990729 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779184.992506 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779184.994196 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779184.995945 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779184.997646 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779184.999463 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.001275 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.003112 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.005300 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.007315 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.009506 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.011540 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.013693 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.015837 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.029958 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.031732 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.037891 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.040131 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.042231 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.044481 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.046809 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.049124 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.051461 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.053662 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.056064 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.058409 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.060744 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.063518 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.066432 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.100344 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.102455 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.104644 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.106940 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.118215 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.121231 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.124505 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.128030 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.131565 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.135052 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.138638 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.142196 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.145755 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.150175 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.154913 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.169056 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.171147 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.173311 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.175605 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.178499 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.181762 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.188496 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.191900 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.195319 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.198940 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.202581 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.206124 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.209678 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.214110 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.218838 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.230055 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.231559 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.232959 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.234434 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.236205 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.238093 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.239502 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.241438 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.243395 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.245391 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.247390 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.249515 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.251646 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.254239 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.261939 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.263313 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.264710 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.267359 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.296338 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.304455 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.306165 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.307325 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.308724 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.337634 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.356231 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.417622 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.535960 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.537371 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.538352 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.539816 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.541665 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.548661 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.578404 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.579898 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.580867 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.582324 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.584179 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.590992 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.620889 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.622193 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.623346 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.624833 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.626713 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.648515 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.669128 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.694104 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.724493 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.725754 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.727120 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.728447 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.729909 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.754089 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.801041 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.802356 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.803664 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.804992 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.806556 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.818530 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.847804 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.849183 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.850472 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.851775 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.860285 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.862969 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.881190 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.881995 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.882830 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.883608 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.885799 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.887675 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.890741 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779185.897197 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-3.1926382..4.208702]. WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-2.6840363..3.8377764].
plt.figure(figsize=(8, 8))
plt.subplot(121)
plt.title('Is a real zebra?')
plt.imshow(discriminator_y(sample_zebra)[0, ..., -1], cmap='RdBu_r')
plt.subplot(122)
plt.title('Is a real horse?')
plt.imshow(discriminator_x(sample_horse)[0, ..., -1], cmap='RdBu_r')
plt.show()
W0000 00:00:1723779186.545702 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779186.547874 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779186.549983 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779186.552228 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779186.553755 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779186.555390 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779186.557002 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779186.558614 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779186.560021 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779186.561384 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779186.562827 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779186.564386 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779186.565923 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779186.567858 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779186.569218 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779186.610428 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779186.632893 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779186.634128 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779186.635381 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779186.636901 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779186.638737 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779186.640663 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779186.642349 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779186.644049 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779186.645776 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779186.647731 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779186.649643 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779186.651339 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced W0000 00:00:1723779186.652346 151656 gpu_timer.cc:114] Skipping the delay kernel, measurement accuracy will be reduced

Loss functions
In CycleGAN, there is no paired data to train on, hence there is no guarantee that the input x and the target y pair are meaningful during training. Thus in order to enforce that the network learns the correct mapping, the authors propose the cycle consistency loss.
The discriminator loss and the generator loss are similar to the ones used in pix2pix.
LAMBDA = 10
loss_obj = tf.keras.losses.BinaryCrossentropy(from_logits=True)
def discriminator_loss(real, generated):
real_loss = loss_obj(tf.ones_like(real), real)
generated_loss = loss_obj(tf.zeros_like(generated), generated)
total_disc_loss = real_loss + generated_loss
return total_disc_loss * 0.5
def generator_loss(generated):
return loss_obj(tf.ones_like(generated), generated)
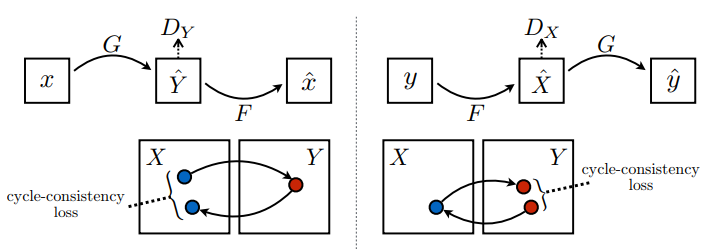
Cycle consistency means the result should be close to the original input. For example, if one translates a sentence from English to French, and then translates it back from French to English, then the resulting sentence should be the same as the original sentence.
In cycle consistency loss,
- Image \(X\) is passed via generator \(G\) that yields generated image \(\hat{Y}\).
- Generated image \(\hat{Y}\) is passed via generator \(F\) that yields cycled image \(\hat{X}\).
- Mean absolute error is calculated between \(X\) and \(\hat{X}\).
\[forward\ cycle\ consistency\ loss: X -> G(X) -> F(G(X)) \sim \hat{X}\]
\[backward\ cycle\ consistency\ loss: Y -> F(Y) -> G(F(Y)) \sim \hat{Y}\]
def calc_cycle_loss(real_image, cycled_image):
loss1 = tf.reduce_mean(tf.abs(real_image - cycled_image))
return LAMBDA * loss1
As shown above, generator \(G\) is responsible for translating image \(X\) to image \(Y\). Identity loss says that, if you fed image \(Y\) to generator \(G\), it should yield the real image \(Y\) or something close to image \(Y\).
If you run the zebra-to-horse model on a horse or the horse-to-zebra model on a zebra, it should not modify the image much since the image already contains the target class.
\[Identity\ loss = |G(Y) - Y| + |F(X) - X|\]
def identity_loss(real_image, same_image):
loss = tf.reduce_mean(tf.abs(real_image - same_image))
return LAMBDA * 0.5 * loss
Initialize the optimizers for all the generators and the discriminators.
generator_g_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
generator_f_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_x_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_y_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
Checkpoints
checkpoint_path = "./checkpoints/train"
ckpt = tf.train.Checkpoint(generator_g=generator_g,
generator_f=generator_f,
discriminator_x=discriminator_x,
discriminator_y=discriminator_y,
generator_g_optimizer=generator_g_optimizer,
generator_f_optimizer=generator_f_optimizer,
discriminator_x_optimizer=discriminator_x_optimizer,
discriminator_y_optimizer=discriminator_y_optimizer)
ckpt_manager = tf.train.CheckpointManager(ckpt, checkpoint_path, max_to_keep=5)
# if a checkpoint exists, restore the latest checkpoint.
if ckpt_manager.latest_checkpoint:
ckpt.restore(ckpt_manager.latest_checkpoint)
print ('Latest checkpoint restored!!')
Training
EPOCHS = 10
def generate_images(model, test_input):
prediction = model(test_input)
plt.figure(figsize=(12, 12))
display_list = [test_input[0], prediction[0]]
title = ['Input Image', 'Predicted Image']
for i in range(2):
plt.subplot(1, 2, i+1)
plt.title(title[i])
# getting the pixel values between [0, 1] to plot it.
plt.imshow(display_list[i] * 0.5 + 0.5)
plt.axis('off')
plt.show()
Even though the training loop looks complicated, it consists of four basic steps:
- Get the predictions.
- Calculate the loss.
- Calculate the gradients using backpropagation.
- Apply the gradients to the optimizer.
@tf.function
def train_step(real_x, real_y):
# persistent is set to True because the tape is used more than
# once to calculate the gradients.
with tf.GradientTape(persistent=True) as tape:
# Generator G translates X -> Y
# Generator F translates Y -> X.
fake_y = generator_g(real_x, training=True)
cycled_x = generator_f(fake_y, training=True)
fake_x = generator_f(real_y, training=True)
cycled_y = generator_g(fake_x, training=True)
# same_x and same_y are used for identity loss.
same_x = generator_f(real_x, training=True)
same_y = generator_g(real_y, training=True)
disc_real_x = discriminator_x(real_x, training=True)
disc_real_y = discriminator_y(real_y, training=True)
disc_fake_x = discriminator_x(fake_x, training=True)
disc_fake_y = discriminator_y(fake_y, training=True)
# calculate the loss
gen_g_loss = generator_loss(disc_fake_y)
gen_f_loss = generator_loss(disc_fake_x)
total_cycle_loss = calc_cycle_loss(real_x, cycled_x) + calc_cycle_loss(real_y, cycled_y)
# Total generator loss = adversarial loss + cycle loss
total_gen_g_loss = gen_g_loss + total_cycle_loss + identity_loss(real_y, same_y)
total_gen_f_loss = gen_f_loss + total_cycle_loss + identity_loss(real_x, same_x)
disc_x_loss = discriminator_loss(disc_real_x, disc_fake_x)
disc_y_loss = discriminator_loss(disc_real_y, disc_fake_y)
# Calculate the gradients for generator and discriminator
generator_g_gradients = tape.gradient(total_gen_g_loss,
generator_g.trainable_variables)
generator_f_gradients = tape.gradient(total_gen_f_loss,
generator_f.trainable_variables)
discriminator_x_gradients = tape.gradient(disc_x_loss,
discriminator_x.trainable_variables)
discriminator_y_gradients = tape.gradient(disc_y_loss,
discriminator_y.trainable_variables)
# Apply the gradients to the optimizer
generator_g_optimizer.apply_gradients(zip(generator_g_gradients,
generator_g.trainable_variables))
generator_f_optimizer.apply_gradients(zip(generator_f_gradients,
generator_f.trainable_variables))
discriminator_x_optimizer.apply_gradients(zip(discriminator_x_gradients,
discriminator_x.trainable_variables))
discriminator_y_optimizer.apply_gradients(zip(discriminator_y_gradients,
discriminator_y.trainable_variables))
for epoch in range(EPOCHS):
start = time.time()
n = 0
for image_x, image_y in tf.data.Dataset.zip((train_horses, train_zebras)):
train_step(image_x, image_y)
if n % 10 == 0:
print ('.', end='')
n += 1
clear_output(wait=True)
# Using a consistent image (sample_horse) so that the progress of the model
# is clearly visible.
generate_images(generator_g, sample_horse)
if (epoch + 1) % 5 == 0:
ckpt_save_path = ckpt_manager.save()
print ('Saving checkpoint for epoch {} at {}'.format(epoch+1,
ckpt_save_path))
print ('Time taken for epoch {} is {} sec\n'.format(epoch + 1,
time.time()-start))

Saving checkpoint for epoch 10 at ./checkpoints/train/ckpt-2 Time taken for epoch 10 is 529.7002165317535 sec
Generate using test dataset
# Run the trained model on the test dataset
for inp in test_horses.take(5):
generate_images(generator_g, inp)





Next steps
This tutorial has shown how to implement CycleGAN starting from the generator and discriminator implemented in the Pix2Pix tutorial. As a next step, you could try using a different dataset from TensorFlow Datasets.
You could also train for a larger number of epochs to improve the results, or you could implement the modified ResNet generator used in the paper instead of the U-Net generator used here.