
| | |
Введение
Большие языковые модели (LLM) — это класс моделей машинного обучения, которые обучены генерировать текст на основе больших наборов данных. Их можно использовать для задач обработки естественного языка (НЛП), включая генерацию текста, ответы на вопросы и машинный перевод. Они основаны на архитектуре Transformer и обучаются на огромных объемах текстовых данных, часто состоящих из миллиардов слов. Даже LLM меньшего масштаба, такие как GPT-2, могут работать впечатляюще. Преобразование моделей TensorFlow в более легкие, быстрые и маломощные модели позволяет нам запускать генеративные модели искусственного интеллекта на устройстве, обеспечивая при этом повышенную безопасность пользователей, поскольку данные никогда не покинут ваше устройство.
В этом модуле Runbook показано, как создать приложение Android с помощью TensorFlow Lite для запуска Keras LLM, а также представлены предложения по оптимизации модели с использованием методов квантования, которые в противном случае потребовали бы гораздо большего объема памяти и большей вычислительной мощности для запуска.
Мы открыли исходный код нашей платформы приложений для Android , к которой могут подключиться любые совместимые LLM TFLite. Вот две демоверсии:
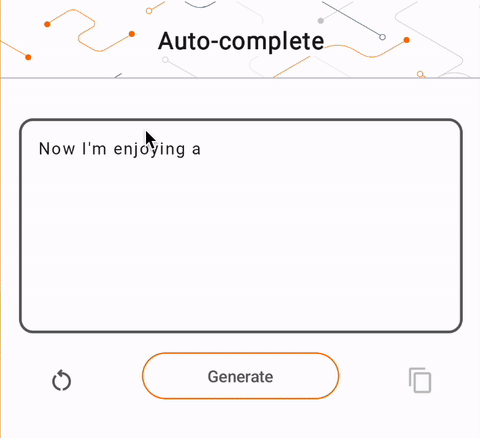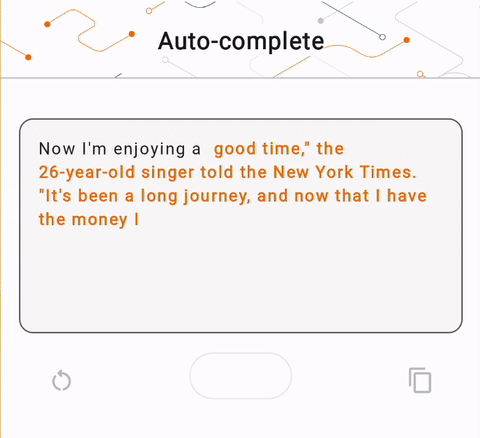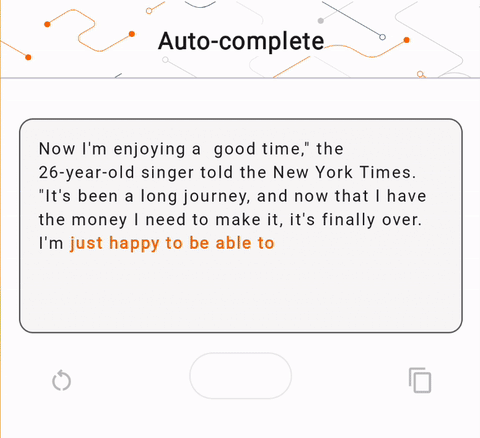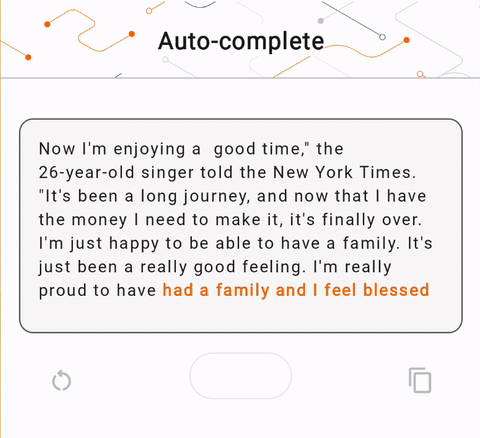
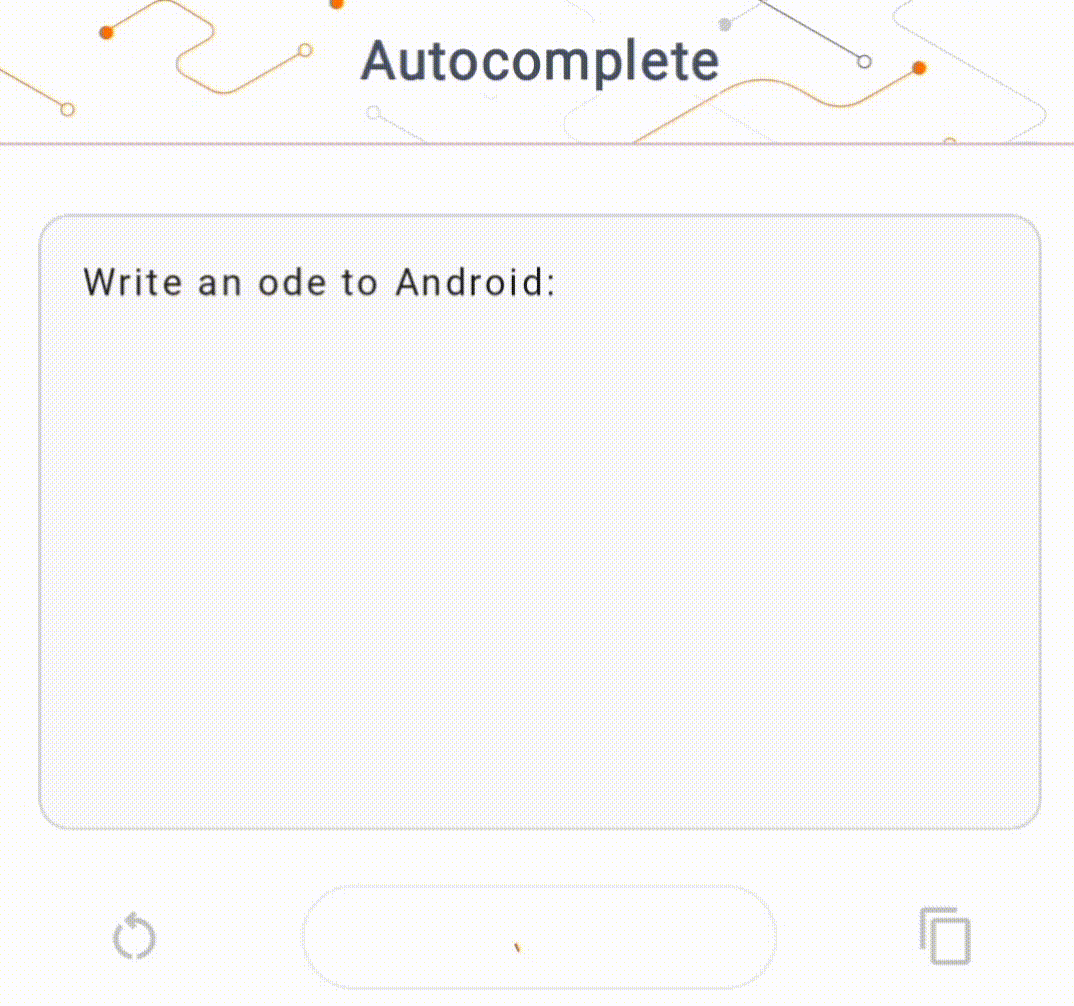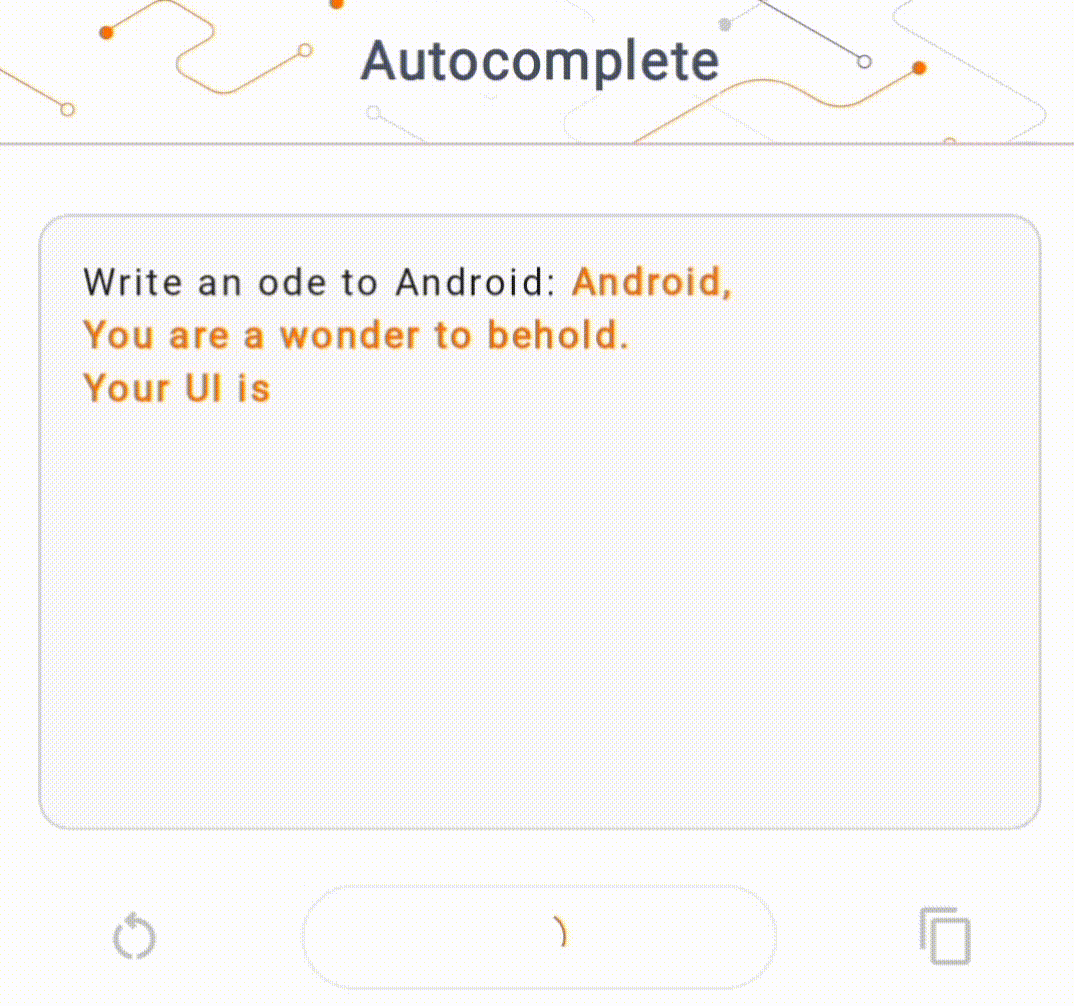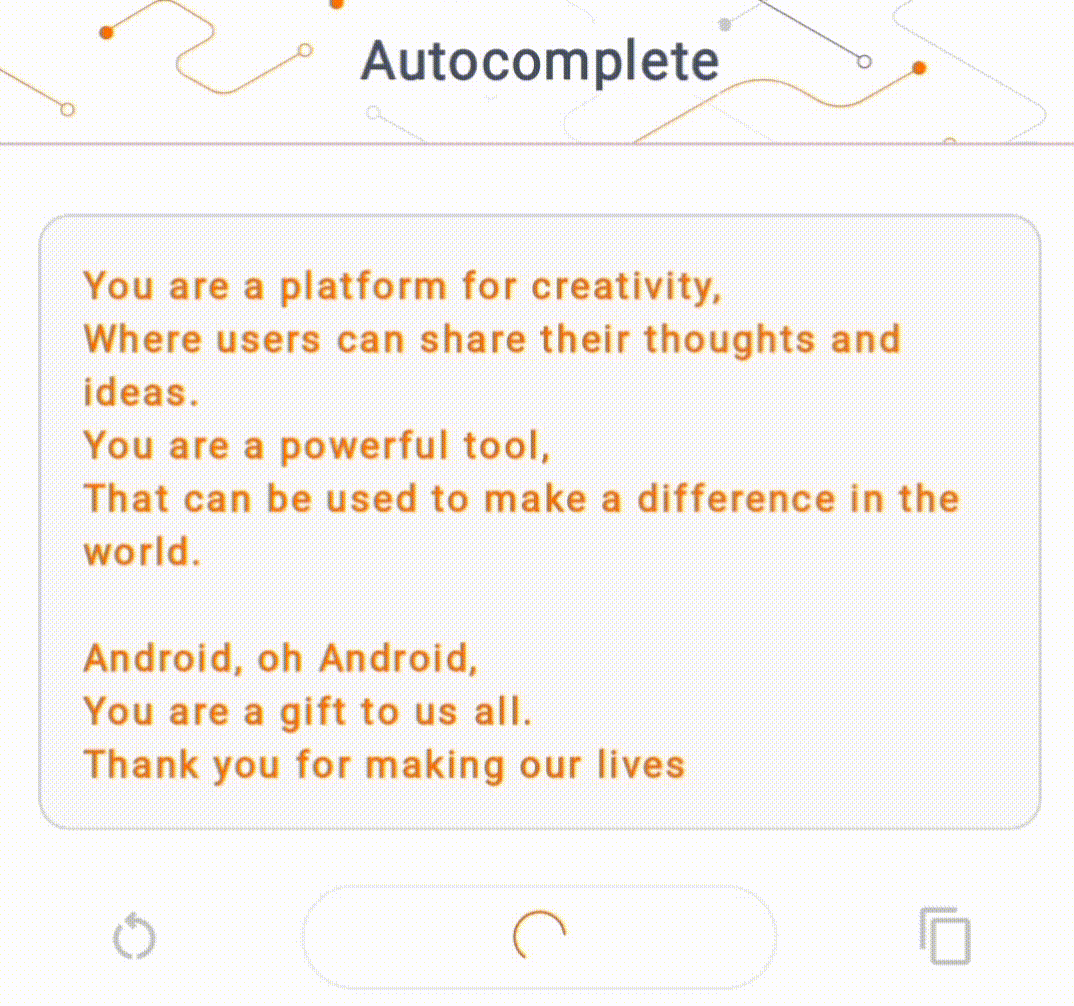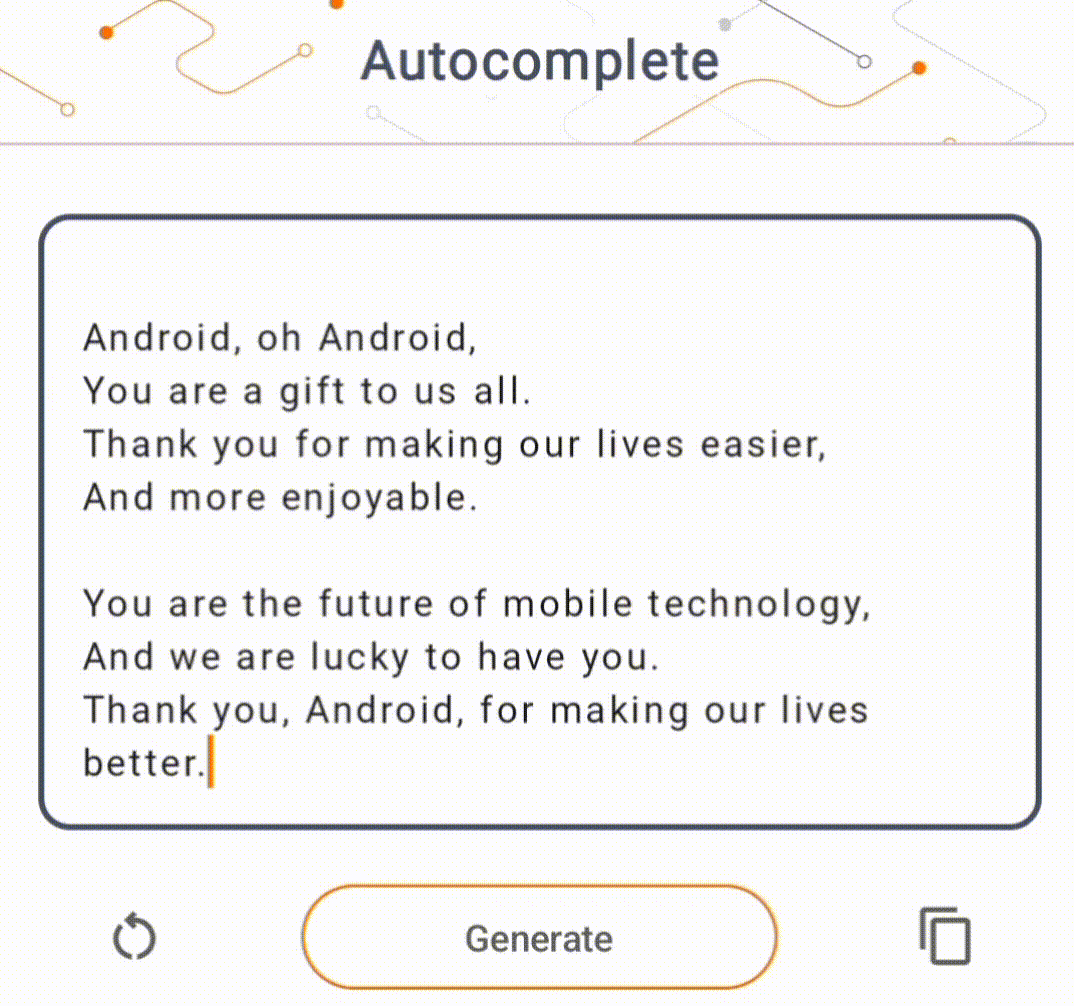
- На рисунке 1 мы использовали модель Keras GPT-2 для выполнения задач по дополнению текста на устройстве.
- На рисунке 2 мы преобразовали версию модели PaLM с настройкой инструкций (1,5 миллиарда параметров) в TFLite и выполнили ее во время выполнения TFLite.
Путеводители
Создание модели
Для этой демонстрации мы будем использовать KerasNLP для получения модели GPT-2. KerasNLP — это библиотека, которая содержит современные предварительно обученные модели для задач обработки естественного языка и может поддерживать пользователей на протяжении всего цикла разработки. Список доступных моделей вы можете посмотреть в репозитории KerasNLP . Рабочие процессы построены на основе модульных компонентов, которые имеют самые современные предустановленные веса и архитектуру при использовании «из коробки» и легко настраиваются, когда требуется больший контроль. Создание модели GPT-2 можно выполнить, выполнив следующие шаги:
gpt2_tokenizer = keras_nlp.models.GPT2Tokenizer.from_preset("gpt2_base_en")
gpt2_preprocessor = keras_nlp.models.GPT2CausalLMPreprocessor.from_preset(
"gpt2_base_en",
sequence_length=256,
add_end_token=True,
)
gpt2_lm =
keras_nlp.models.GPT2CausalLM.from_preset(
"gpt2_base_en",
preprocessor=gpt2_preprocessor
)
Одной из общих черт этих трех строк кода является метод from_preset() , который создает экземпляр части Keras API на основе предустановленной архитектуры и/или весов, тем самым загружая предварительно обученную модель. В этом фрагменте кода вы также заметите три модульных компонента:
Tokenizer : преобразует входную необработанную строку в целочисленные идентификаторы токенов, подходящие для слоя внедрения Keras. GPT-2 специально использует токенизатор кодирования пар байтов (BPE).
Препроцессор : слой для токенизации и упаковки входных данных для подачи в модель Keras. Здесь препроцессор дополняет тензор идентификаторов токенов до указанной длины (256) после токенизации.
Backbone : модель Keras, которая соответствует архитектуре магистральной сети трансформатора SoTA и имеет предустановленные веса.
Кроме того, вы можете ознакомиться с полной реализацией модели GPT-2 на GitHub .
Преобразование модели
TensorFlow Lite — это мобильная библиотека для развертывания методов на мобильных устройствах, микроконтроллерах и других периферийных устройствах. Первым шагом является преобразование модели Keras в более компактный формат TensorFlow Lite с помощью конвертера TensorFlow Lite, а затем использование интерпретатора TensorFlow Lite, который сильно оптимизирован для мобильных устройств, для запуска преобразованной модели.
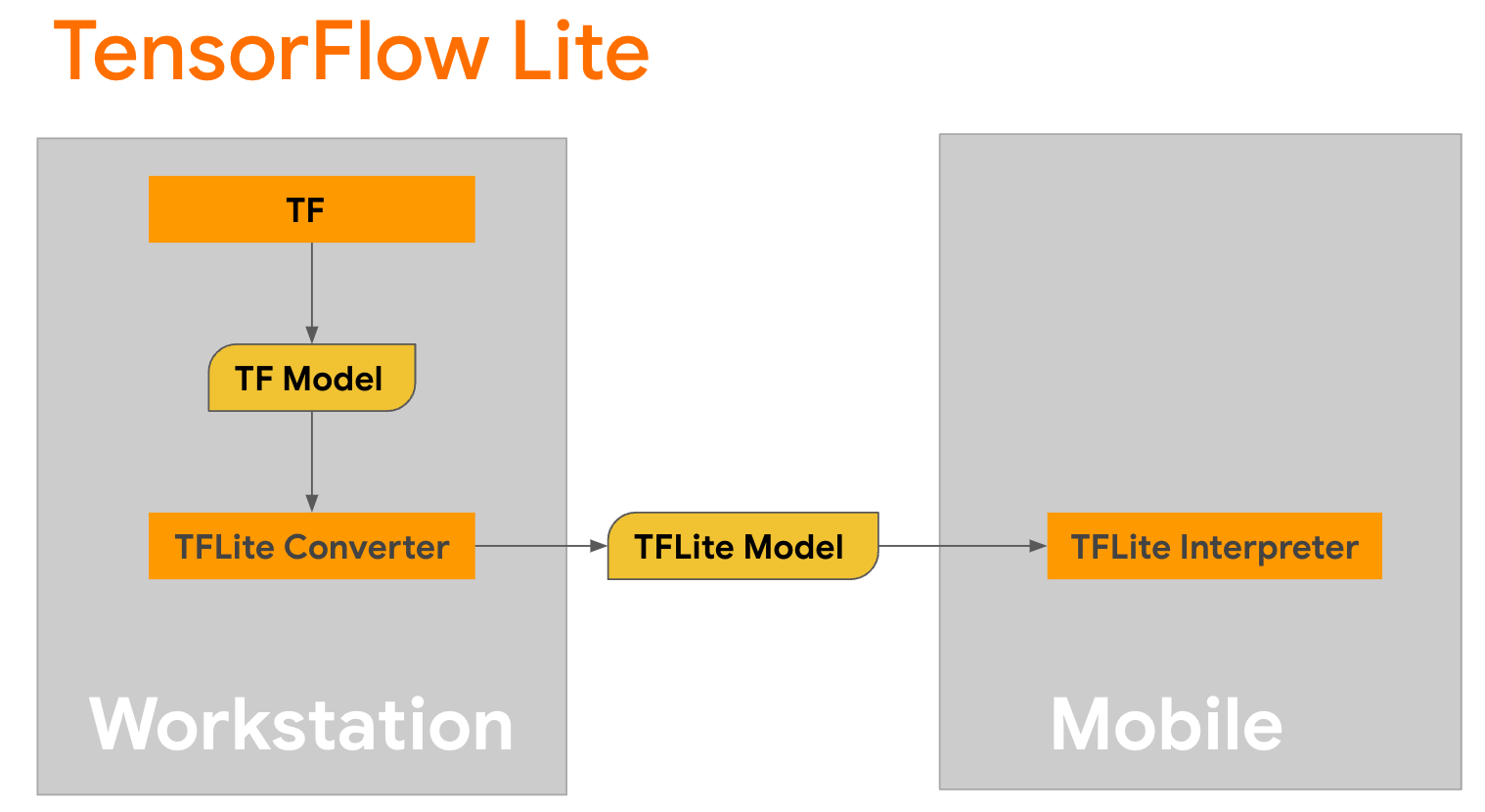 Начните с
Начните с generate() из GPT2CausalLM , которая выполняет преобразование. Оберните generate() , чтобы создать конкретную функцию TensorFlow:
@tf.function
def generate(prompt, max_length):
"""
Args:
prompt: input prompt to the LLM in string format
max_length: the max length of the generated tokens
"""
return gpt2_lm.generate(prompt, max_length)
concrete_func = generate.get_concrete_function(tf.TensorSpec([], tf.string), 100)
Обратите внимание, что вы также можете использовать from_keras_model() из TFLiteConverter для выполнения преобразования.
Теперь определите вспомогательную функцию, которая будет выполнять вывод на основе входных данных и модели TFLite. Текстовые операции TensorFlow не являются встроенными операциями во время выполнения TFLite, поэтому вам нужно будет добавить эти пользовательские операции, чтобы интерпретатор мог сделать вывод по этой модели. Эта вспомогательная функция принимает входные данные и функцию, выполняющую преобразование, а именно функцию generator() , определенную выше.
def run_inference(input, generate_tflite):
interp = interpreter.InterpreterWithCustomOps(
model_content=generate_tflite,
custom_op_registerers=
tf_text.tflite_registrar.SELECT_TFTEXT_OPS
)
interp.get_signature_list()
generator = interp.get_signature_runner('serving_default')
output = generator(prompt=np.array([input]))
Вы можете конвертировать модель сейчас:
gpt2_lm.jit_compile = False
converter = tf.lite.TFLiteConverter.from_concrete_functions(
[concrete_func],
gpt2_lm)
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # enable TFLite ops
tf.lite.OpsSet.SELECT_TF_OPS, # enable TF ops
]
converter.allow_custom_ops = True
converter.target_spec.experimental_select_user_tf_ops = [
"UnsortedSegmentJoin",
"UpperBound"
]
converter._experimental_guarantee_all_funcs_one_use = True
generate_tflite = converter.convert()
run_inference("I'm enjoying a", generate_tflite)
Квантование
В TensorFlow Lite реализован метод оптимизации, называемый квантованием , который может уменьшить размер модели и ускорить вывод. В процессе квантования 32-битные числа с плавающей запятой преобразуются в меньшие 8-битные целые числа, что уменьшает размер модели в 4 раза для более эффективного выполнения на современном оборудовании. В TensorFlow есть несколько способов выполнить квантование. Вы можете посетить страницы «Оптимизация модели TFLite» и «Инструментарий для оптимизации модели TensorFlow» для получения дополнительной информации. Типы квантования кратко объясняются ниже.
Здесь вы будете использовать квантование динамического диапазона после обучения в модели GPT-2, установив для флага оптимизации преобразователя значение tf.lite.Optimize.DEFAULT , а остальная часть процесса преобразования аналогична описанной ранее. Мы протестировали, что при использовании этого метода квантования задержка составляет около 6,7 секунды на Pixel 7 с максимальной длиной вывода, установленной на 100.
gpt2_lm.jit_compile = False
converter = tf.lite.TFLiteConverter.from_concrete_functions(
[concrete_func],
gpt2_lm)
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # enable TFLite ops
tf.lite.OpsSet.SELECT_TF_OPS, # enable TF ops
]
converter.allow_custom_ops = True
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.experimental_select_user_tf_ops = [
"UnsortedSegmentJoin",
"UpperBound"
]
converter._experimental_guarantee_all_funcs_one_use = True
quant_generate_tflite = converter.convert()
run_inference("I'm enjoying a", quant_generate_tflite)
Динамический диапазон
Квантование динамического диапазона — рекомендуемая отправная точка для оптимизации моделей на устройстве. Он позволяет уменьшить размер модели примерно в 4 раза и является рекомендуемой отправной точкой, поскольку обеспечивает сокращение использования памяти и более быстрые вычисления без необходимости предоставления репрезентативного набора данных для калибровки. Этот тип квантования статически квантует только веса от плавающей запятой до 8-битного целого числа во время преобразования.
РП16
Модели с плавающей запятой также можно оптимизировать путем квантования весов до типа float16. Преимущества квантования float16 заключаются в уменьшении размера модели почти вдвое (поскольку все веса уменьшаются вдвое), что приводит к минимальной потере точности и поддержке делегатов графического процессора, которые могут работать непосредственно с данными float16 (что приводит к более быстрым вычислениям, чем при использовании float32). данные). Модель, преобразованная в веса float16, по-прежнему может работать на ЦП без дополнительных модификаций. Перед первым выводом веса float16 повышаются до float32, что позволяет уменьшить размер модели в обмен на минимальное влияние на задержку и точность.
Полное целочисленное квантование
Полное целочисленное квантование преобразует 32-битные числа с плавающей запятой, включая веса и активации, в ближайшие 8-битные целые числа. Этот тип квантования приводит к уменьшению модели с увеличенной скоростью вывода, что невероятно ценно при использовании микроконтроллеров. Этот режим рекомендуется использовать, когда активации чувствительны к квантованию.
Интеграция приложений Android
Вы можете следовать этому примеру для Android , чтобы интегрировать свою модель TFLite в приложение для Android.
Предварительные условия
Если вы еще этого не сделали, установите Android Studio , следуя инструкциям на сайте.
- Android Studio 2022.2.1 или более поздней версии.
- Устройство Android или эмулятор Android с памятью более 4G.
Сборка и запуск с помощью Android Studio
- Откройте Android Studio и на экране приветствия выберите «Открыть существующий проект Android Studio» .
- В появившемся окне «Открыть файл» или «Проект» перейдите и выберите каталог
lite/examples/generative_ai/androidоткуда вы клонировали образец репозитория GitHub TensorFlow Lite. - Вам также может потребоваться установить различные платформы и инструменты в соответствии с сообщениями об ошибках.
- Переименуйте преобразованную модель .tflite в
autocomplete.tfliteи скопируйте ее в папкуapp/src/main/assets/. - Выберите меню «Сборка» -> «Создать проект» , чтобы создать приложение. (Ctrl+F9, в зависимости от вашей версии).
- Нажмите меню «Выполнить» -> «Запустить приложение» . (Shift+F10, в зависимости от вашей версии)
Альтернативно вы также можете использовать оболочку gradle для ее сборки в командной строке. Пожалуйста, обратитесь к документации Gradle для получения дополнительной информации.
(Необязательно) Создание файла .aar
По умолчанию приложение автоматически загружает необходимые файлы .aar . Но если вы хотите создать свой собственный, переключитесь на папку app/libs/build_aar/ run ./build_aar.sh . Этот скрипт извлечет необходимые операции из TensorFlow Text и создаст aar для операторов Select TF.
После компиляции создается новый файл tftext_tflite_flex.aar . Замените файл .aar в папке app/libs/ и пересоберите приложение.
Обратите внимание, что вам все равно необходимо включить стандартный aar tensorflow-lite в файл Gradle.
Размер контекстного окна
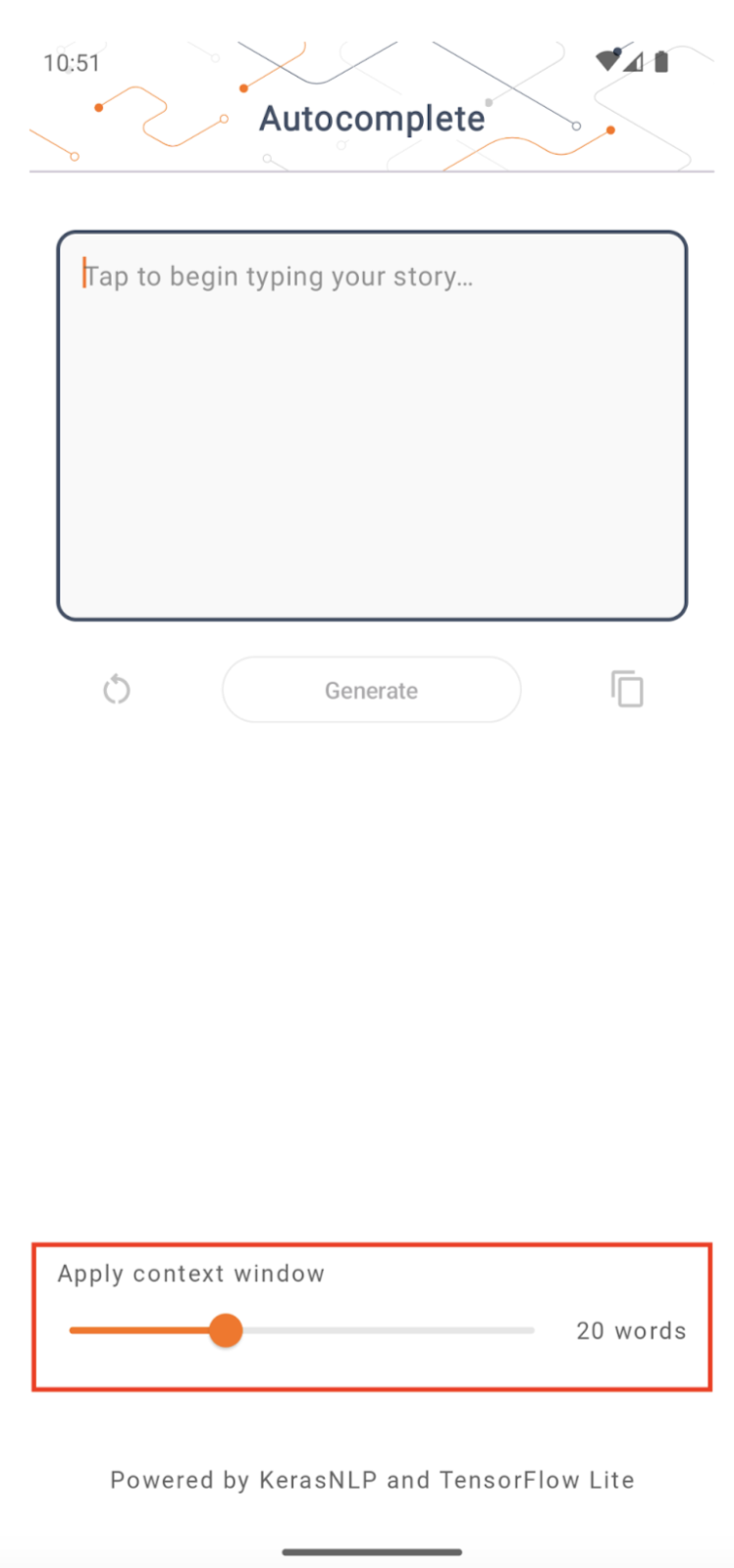
В приложении есть изменяемый параметр «размер окна контекста», который необходим, поскольку сегодня LLM обычно имеют фиксированный размер контекста, который ограничивает количество слов/токенов, которые можно ввести в модель в качестве «подсказки» (обратите внимание, что «слово» не обязательно в данном случае эквивалентно «токену» из-за разных методов токенизации). Это число важно, потому что:
- Если установить слишком маленькое значение, у модели не будет достаточно контекста для создания значимого вывода.
- Если установить слишком большое значение, в модели не будет достаточно места для работы (поскольку последовательность вывода включает подсказку)
Вы можете поэкспериментировать с этим, но установка значения ~50% от длины выходной последовательности — хорошее начало.
Безопасность и ответственный ИИ
Как отмечалось в исходном объявлении OpenAI GPT-2 , модель GPT-2 имеет заметные предостережения и ограничения . Фактически, сегодня у студентов LLM обычно есть некоторые хорошо известные проблемы, такие как галлюцинации, справедливость и предвзятость; это связано с тем, что эти модели обучаются на реальных данных, что позволяет им отражать проблемы реального мира.
Эта лаборатория кода создана только для того, чтобы продемонстрировать, как создать приложение на базе LLM с помощью инструментов TensorFlow. Модель, созданная в этой лаборатории, предназначена только для образовательных целей и не предназначена для промышленного использования.
Использование LLM в производстве требует продуманного выбора наборов обучающих данных и комплексных мер по снижению безопасности. Одной из таких функций, предлагаемых в этом приложении для Android, является фильтр ненормативной лексики, который отклоняет неправильные вводимые пользователем данные или выходные данные модели. Если будет обнаружен какой-либо недопустимый язык, приложение в ответ отклонит это действие. Чтобы узнать больше об ответственном искусственном интеллекте в контексте программ LLM, обязательно посмотрите техническую сессию «Безопасная и ответственная разработка с использованием генеративных языковых моделей» на конференции Google I/O 2023 и ознакомьтесь с набором инструментов для ответственного искусственного интеллекта .