
| | |
ভূমিকা
লার্জ ল্যাঙ্গুয়েজ মডেল (LLMs) হল মেশিন লার্নিং মডেলের একটি ক্লাস যেগুলিকে বড় ডেটাসেটের উপর ভিত্তি করে টেক্সট তৈরি করতে প্রশিক্ষিত করা হয়। এগুলি পাঠ্য তৈরি, প্রশ্নের উত্তর এবং মেশিন অনুবাদ সহ প্রাকৃতিক ভাষা প্রক্রিয়াকরণ (NLP) কাজের জন্য ব্যবহার করা যেতে পারে। এগুলি ট্রান্সফরমার আর্কিটেকচারের উপর ভিত্তি করে এবং প্রচুর পরিমাণে পাঠ্য ডেটার উপর প্রশিক্ষিত হয়, প্রায়শই কোটি কোটি শব্দ জড়িত থাকে। এমনকি ছোট স্কেলের এলএলএম, যেমন GPT-2, চিত্তাকর্ষকভাবে পারফর্ম করতে পারে। টেনসরফ্লো মডেলগুলিকে একটি হালকা, দ্রুত এবং কম-পাওয়ার মডেলে রূপান্তর করা আমাদেরকে আরও ভাল ব্যবহারকারীর সুরক্ষার সুবিধা সহ ডিভাইসে জেনারেটিভ AI মডেলগুলি চালানোর অনুমতি দেয় কারণ ডেটা কখনই আপনার ডিভাইস ছেড়ে যাবে না।
এই রানবুকটি আপনাকে দেখায় কিভাবে একটি কেরাস এলএলএম চালানোর জন্য টেনসরফ্লো লাইট দিয়ে একটি অ্যান্ড্রয়েড অ্যাপ তৈরি করতে হয় এবং কোয়ান্টাইজিং কৌশল ব্যবহার করে মডেল অপ্টিমাইজেশানের জন্য পরামর্শ প্রদান করে, যা অন্যথায় চালানোর জন্য অনেক বেশি মেমরি এবং বৃহত্তর গণনা শক্তির প্রয়োজন হবে।
আমরা আমাদের অ্যান্ড্রয়েড অ্যাপ ফ্রেমওয়ার্ক ওপেন সোর্স করেছি যা যেকোনো সামঞ্জস্যপূর্ণ TFLite LLM প্লাগ ইন করতে পারে। এখানে দুটি ডেমো আছে:
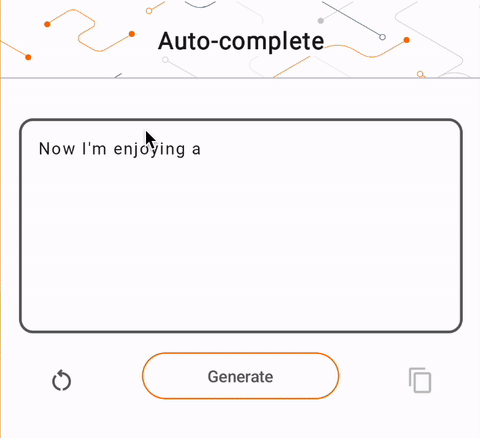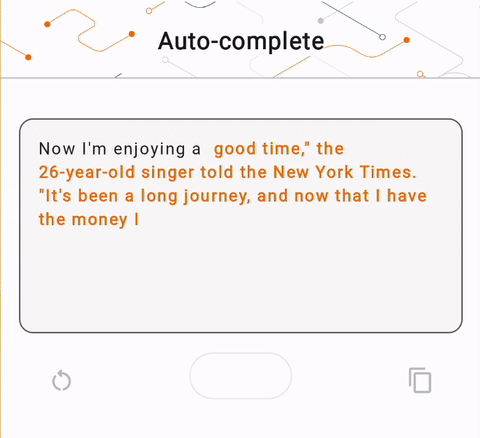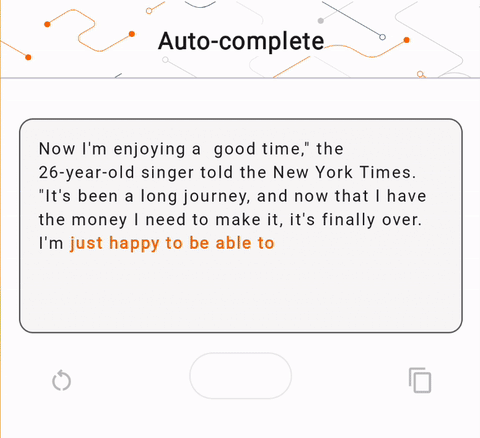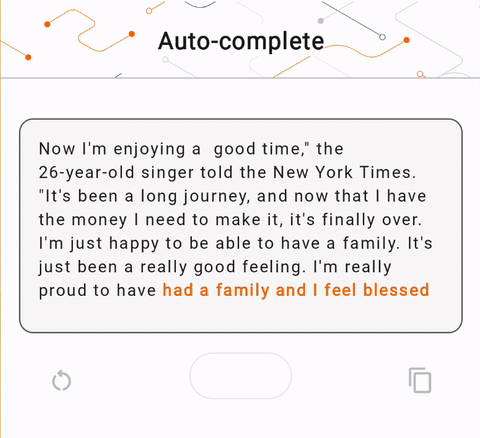
- চিত্র 1-এ, আমরা ডিভাইসে পাঠ্য সমাপ্তির কাজগুলি সম্পাদন করতে একটি কেরাস GPT-2 মডেল ব্যবহার করেছি।
- চিত্র 2-এ, আমরা নির্দেশ-টিউনড PaLM মডেলের একটি সংস্করণ (1.5 বিলিয়ন প্যারামিটার) TFLite-এ রূপান্তরিত করেছি এবং TFLite রানটাইমের মাধ্যমে কার্যকর করেছি।
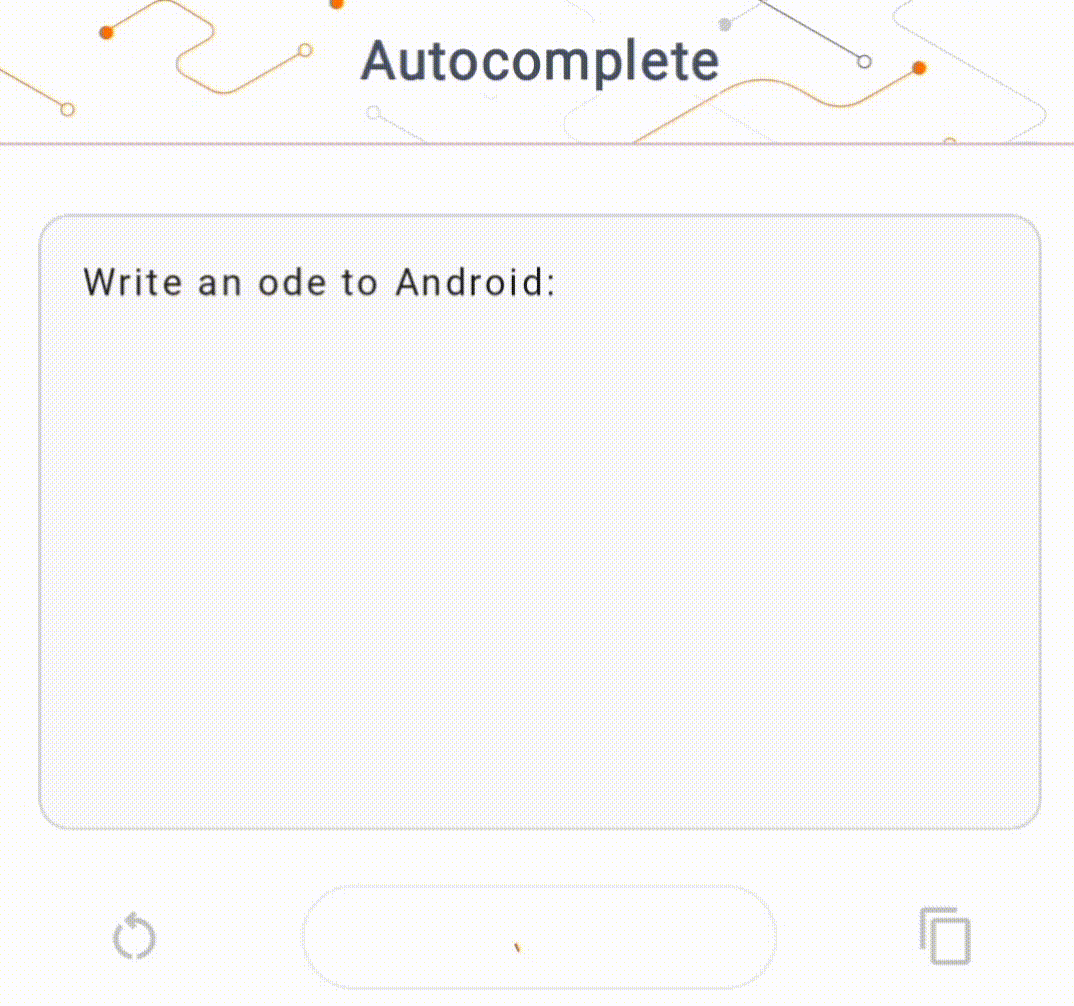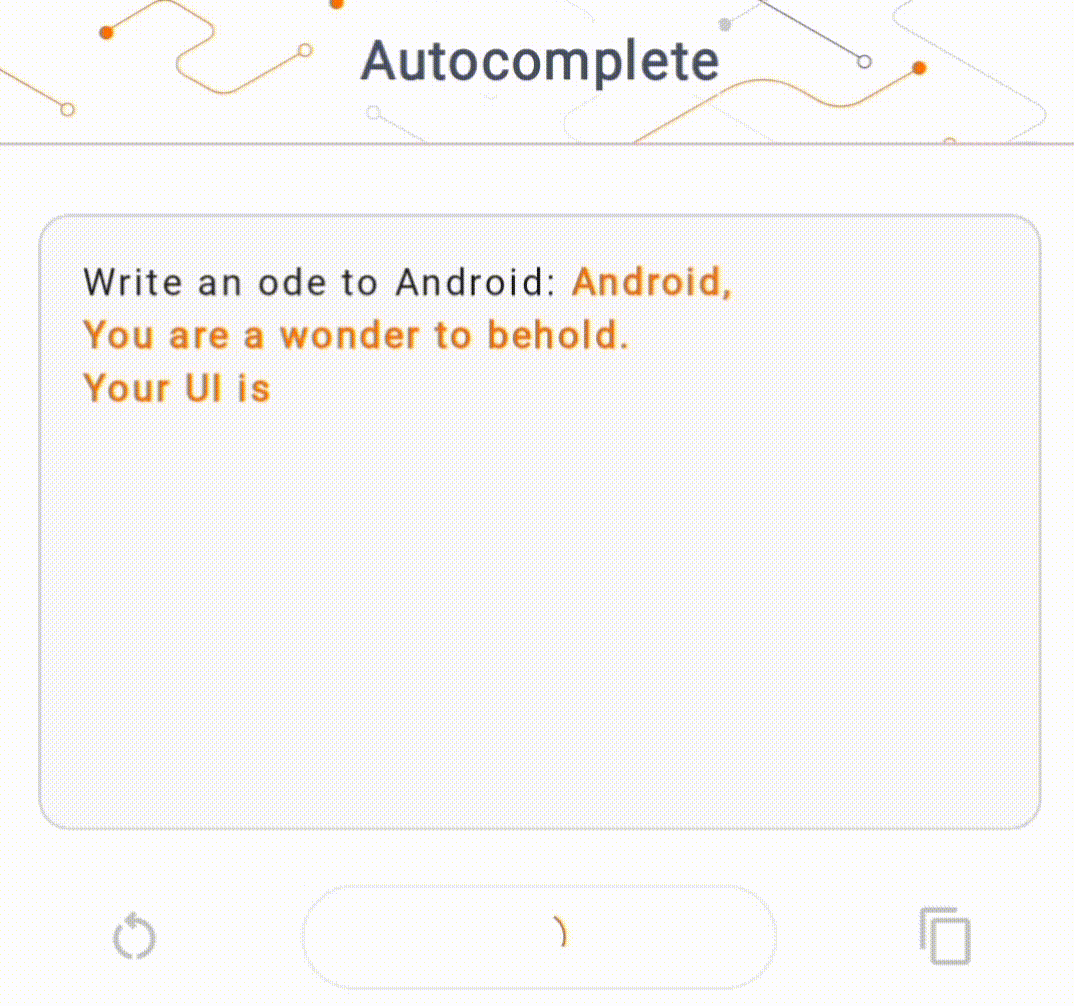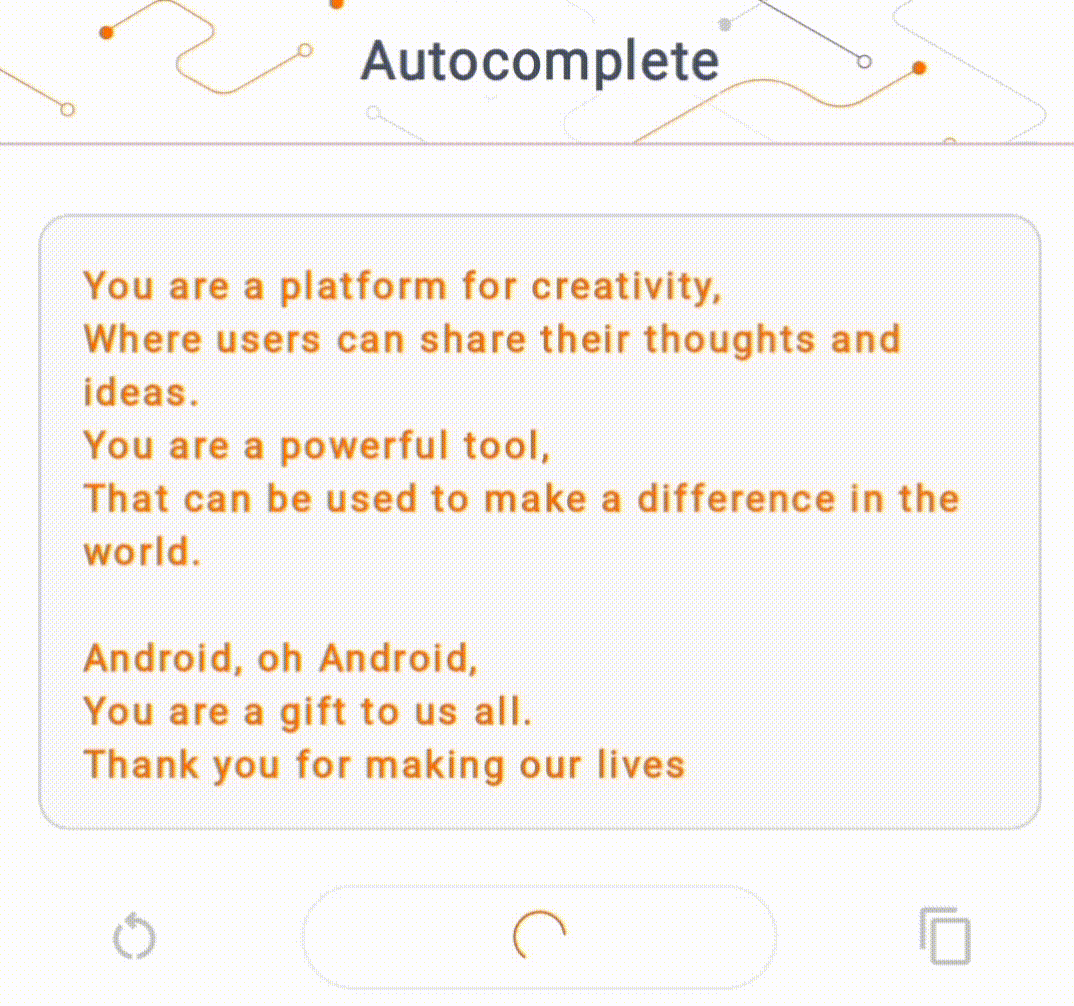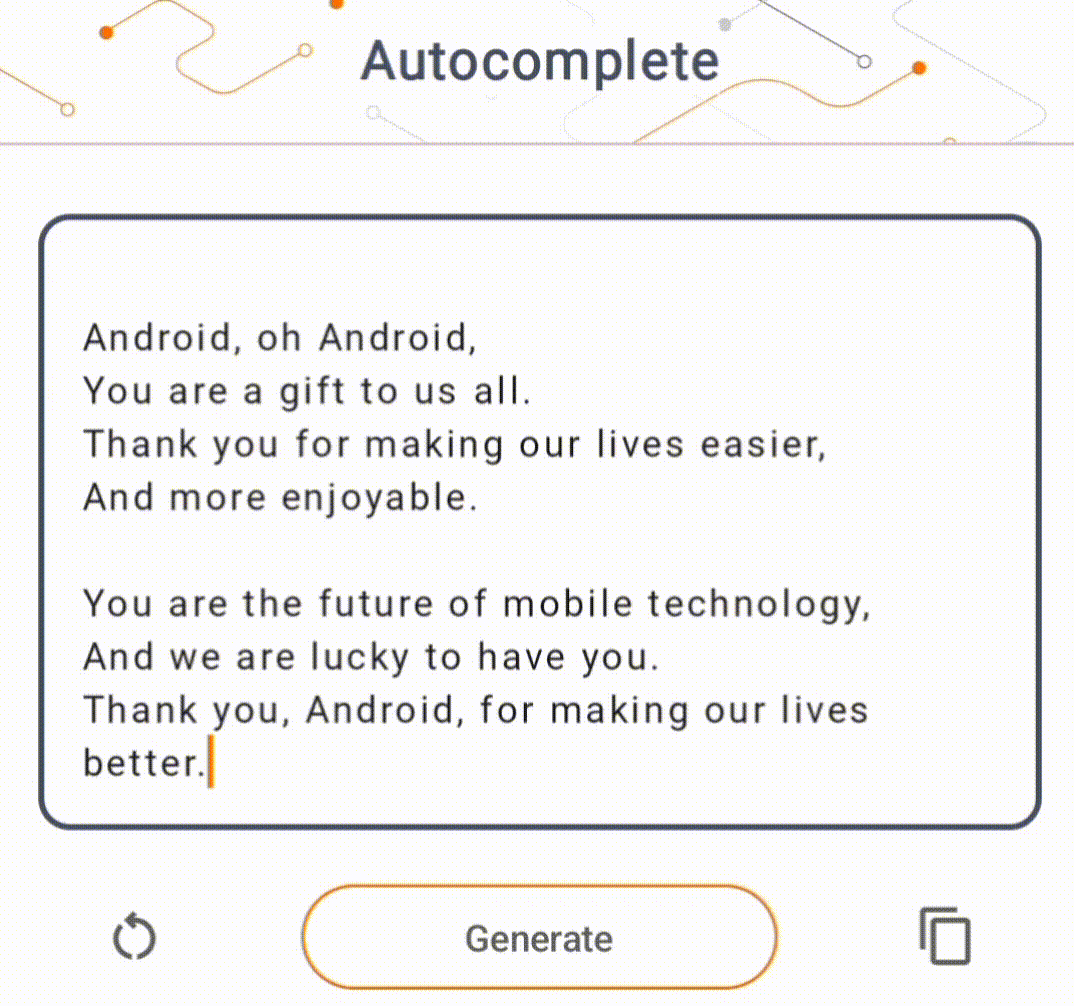
গাইড
মডেল রচনা
এই প্রদর্শনের জন্য, আমরা GPT-2 মডেল পেতে KerasNLP ব্যবহার করব। কেরাসএনএলপি একটি লাইব্রেরি যা প্রাকৃতিক ভাষা প্রক্রিয়াকরণ কাজের জন্য অত্যাধুনিক প্রশিক্ষিত মডেল ধারণ করে এবং ব্যবহারকারীদের তাদের সম্পূর্ণ বিকাশ চক্রের মাধ্যমে সহায়তা করতে পারে। আপনি KerasNLP সংগ্রহস্থলে উপলব্ধ মডেলের তালিকা দেখতে পারেন। ওয়ার্কফ্লোগুলি মডুলার উপাদানগুলি থেকে তৈরি করা হয়েছে যেগুলিতে অত্যাধুনিক প্রিসেট ওজন এবং আর্কিটেকচার রয়েছে যখন বাক্সের বাইরে ব্যবহার করা হয় এবং আরও নিয়ন্ত্রণের প্রয়োজন হলে সহজেই কাস্টমাইজ করা যায়৷ GPT-2 মডেল তৈরি করা নিম্নলিখিত পদক্ষেপগুলি দিয়ে করা যেতে পারে:
gpt2_tokenizer = keras_nlp.models.GPT2Tokenizer.from_preset("gpt2_base_en")
gpt2_preprocessor = keras_nlp.models.GPT2CausalLMPreprocessor.from_preset(
"gpt2_base_en",
sequence_length=256,
add_end_token=True,
)
gpt2_lm =
keras_nlp.models.GPT2CausalLM.from_preset(
"gpt2_base_en",
preprocessor=gpt2_preprocessor
)
কোডের এই তিনটি লাইনের মধ্যে একটি সাধারণতা হল from_preset() পদ্ধতি, যা একটি প্রিসেট আর্কিটেকচার এবং/অথবা ওজন থেকে কেরাস API-এর অংশকে ইনস্ট্যান্টিয়েট করবে, তাই প্রাক-প্রশিক্ষিত মডেল লোড হচ্ছে। এই কোড স্নিপেট থেকে, আপনি তিনটি মডুলার উপাদানও লক্ষ্য করবেন:
টোকেনাইজার : একটি কেরাস এম্বেডিং স্তরের জন্য উপযুক্ত পূর্ণসংখ্যা টোকেন আইডিতে একটি কাঁচা স্ট্রিং ইনপুটকে রূপান্তর করে। GPT-2 বিশেষভাবে বাইট-পেয়ার এনকোডিং (BPE) টোকেনাইজার ব্যবহার করে।
প্রিপ্রসেসর : কেরাস মডেলে টোকেনাইজিং এবং প্যাকিং ইনপুট খাওয়ানোর জন্য স্তর। এখানে, প্রিপ্রসেসর টোকেনাইজেশনের পরে টোকেন আইডিগুলির টেনসরকে একটি নির্দিষ্ট দৈর্ঘ্যে (256) প্যাড করবে।
ব্যাকবোন : কেরাস মডেল যা SoTA ট্রান্সফরমার ব্যাকবোন আর্কিটেকচার অনুসরণ করে এবং এর প্রিসেট ওজন রয়েছে।
উপরন্তু, আপনি GitHub- এ সম্পূর্ণ GPT-2 মডেল বাস্তবায়ন পরীক্ষা করে দেখতে পারেন।
মডেল রূপান্তর
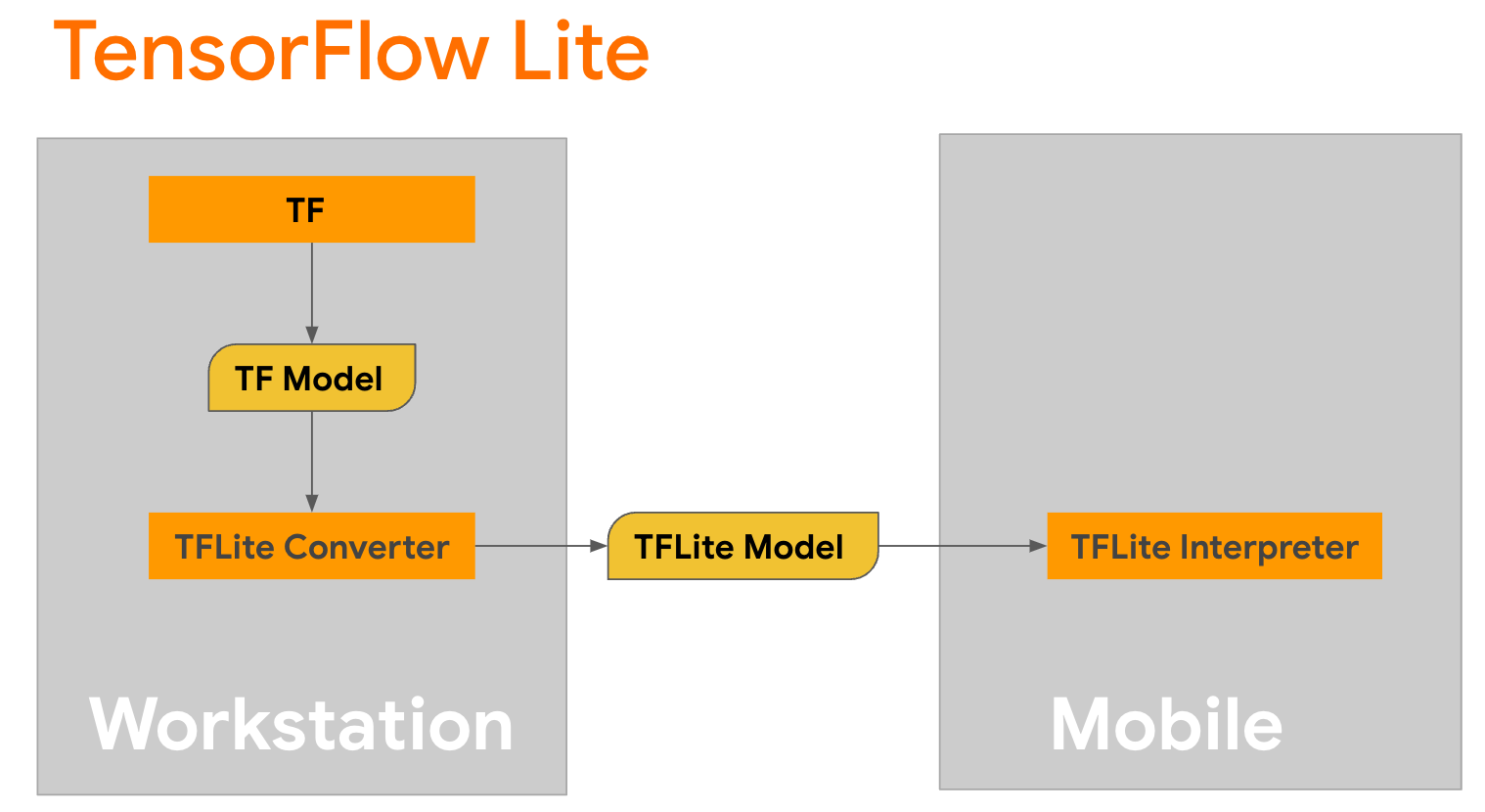
TensorFlow Lite হল মোবাইল, মাইক্রোকন্ট্রোলার এবং অন্যান্য এজ ডিভাইসে পদ্ধতি স্থাপনের জন্য একটি মোবাইল লাইব্রেরি। প্রথম ধাপ হল টেনসরফ্লো লাইট কনভার্টার ব্যবহার করে কেরাস মডেলটিকে আরও কমপ্যাক্ট টেনসরফ্লো লাইট ফর্ম্যাটে রূপান্তর করা এবং তারপরে রূপান্তরিত মডেল চালানোর জন্য টেনসরফ্লো লাইট ইন্টারপ্রেটার ব্যবহার করা, যা মোবাইল ডিভাইসের জন্য অত্যন্ত অপ্টিমাইজ করা হয়েছে।
GPT2CausalLM থেকে generate() ফাংশন দিয়ে শুরু করুন যা রূপান্তর সম্পাদন করে। একটি কংক্রিট টেনসরফ্লো ফাংশন তৈরি করতে generate() ফাংশনটি মোড়ানো:
@tf.function
def generate(prompt, max_length):
"""
Args:
prompt: input prompt to the LLM in string format
max_length: the max length of the generated tokens
"""
return gpt2_lm.generate(prompt, max_length)
concrete_func = generate.get_concrete_function(tf.TensorSpec([], tf.string), 100)
মনে রাখবেন যে আপনি রূপান্তরটি সম্পাদন করার জন্য TFLiteConverter থেকে from_keras_model() ব্যবহার করতে পারেন।
এখন একটি সহায়ক ফাংশন সংজ্ঞায়িত করুন যা একটি ইনপুট এবং একটি TFLite মডেলের সাথে অনুমান চালাবে। TFLite রানটাইমে TensorFlow টেক্সট অপ্স বিল্ট-ইন অপ্স নয়, তাই আপনাকে এই কাস্টম অপস যোগ করতে হবে যাতে দোভাষী এই মডেলে অনুমান করতে পারে। এই সাহায্যকারী ফাংশনটি একটি ইনপুট এবং একটি ফাংশন গ্রহণ করে যা রূপান্তর সম্পাদন করে, যেমন উপরে সংজ্ঞায়িত generator() ফাংশন।
def run_inference(input, generate_tflite):
interp = interpreter.InterpreterWithCustomOps(
model_content=generate_tflite,
custom_op_registerers=
tf_text.tflite_registrar.SELECT_TFTEXT_OPS
)
interp.get_signature_list()
generator = interp.get_signature_runner('serving_default')
output = generator(prompt=np.array([input]))
আপনি এখন মডেল রূপান্তর করতে পারেন:
gpt2_lm.jit_compile = False
converter = tf.lite.TFLiteConverter.from_concrete_functions(
[concrete_func],
gpt2_lm)
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # enable TFLite ops
tf.lite.OpsSet.SELECT_TF_OPS, # enable TF ops
]
converter.allow_custom_ops = True
converter.target_spec.experimental_select_user_tf_ops = [
"UnsortedSegmentJoin",
"UpperBound"
]
converter._experimental_guarantee_all_funcs_one_use = True
generate_tflite = converter.convert()
run_inference("I'm enjoying a", generate_tflite)
কোয়ান্টাইজেশন
টেনসরফ্লো লাইট কোয়ান্টাইজেশন নামে একটি অপ্টিমাইজেশন কৌশল প্রয়োগ করেছে যা মডেলের আকার কমাতে পারে এবং অনুমানকে ত্বরান্বিত করতে পারে। কোয়ান্টাইজেশন প্রক্রিয়ার মাধ্যমে, 32-বিট ফ্লোটগুলিকে ছোট 8-বিট পূর্ণসংখ্যাতে ম্যাপ করা হয়, তাই আধুনিক হার্ডওয়্যারগুলিতে আরও কার্যকরী সম্পাদনের জন্য মডেলের আকার 4 এর ফ্যাক্টর দ্বারা হ্রাস করা হয়। TensorFlow এ কোয়ান্টাইজেশন করার বিভিন্ন উপায় আছে। আপনি আরও তথ্যের জন্য TFLite মডেল অপ্টিমাইজেশান এবং TensorFlow মডেল অপ্টিমাইজেশান টুলকিট পৃষ্ঠাগুলি দেখতে পারেন৷ কোয়ান্টাইজেশনের প্রকারগুলি নীচে সংক্ষেপে ব্যাখ্যা করা হয়েছে।
এখানে, আপনি কনভার্টার অপ্টিমাইজেশান ফ্ল্যাগটিকে tf.lite.Optimize.DEFAULT এ সেট করে GPT-2 মডেলে প্রশিক্ষণ-পরবর্তী গতিশীল পরিসরের পরিমাপ ব্যবহার করবেন এবং বাকি রূপান্তর প্রক্রিয়াটি পূর্বে বিশদ বিবরণের মতোই। আমরা পরীক্ষা করেছি যে এই কোয়ান্টাইজেশন কৌশলটি দিয়ে Pixel 7-এ লেটেন্সি প্রায় 6.7 সেকেন্ড এবং সর্বোচ্চ আউটপুট দৈর্ঘ্য 100 এ সেট করা হয়েছে।
gpt2_lm.jit_compile = False
converter = tf.lite.TFLiteConverter.from_concrete_functions(
[concrete_func],
gpt2_lm)
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # enable TFLite ops
tf.lite.OpsSet.SELECT_TF_OPS, # enable TF ops
]
converter.allow_custom_ops = True
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.experimental_select_user_tf_ops = [
"UnsortedSegmentJoin",
"UpperBound"
]
converter._experimental_guarantee_all_funcs_one_use = True
quant_generate_tflite = converter.convert()
run_inference("I'm enjoying a", quant_generate_tflite)
গতিশীল পরিসীমা
ডাইনামিক রেঞ্জ কোয়ান্টাইজেশন হল অন-ডিভাইস মডেল অপ্টিমাইজ করার জন্য প্রস্তাবিত সূচনা পয়েন্ট। এটি মডেলের আকারে প্রায় 4x হ্রাস অর্জন করতে পারে এবং এটি একটি প্রস্তাবিত শুরুর পয়েন্ট কারণ এটি আপনাকে ক্রমাঙ্কনের জন্য একটি প্রতিনিধি ডেটাসেট প্রদান না করেই মেমরির ব্যবহার হ্রাস এবং দ্রুত গণনা প্রদান করে। এই ধরনের কোয়ান্টাইজেশন স্থিরভাবে রূপান্তরের সময় ফ্লোটিং পয়েন্ট থেকে 8-বিট পূর্ণসংখ্যা পর্যন্ত ওজনের পরিমাণ নির্ধারণ করে।
FP16
ফ্লোটিং পয়েন্ট মডেলগুলিকে ফ্লোট১৬ টাইপের ওজনের পরিমাণ নির্ধারণ করেও অপ্টিমাইজ করা যেতে পারে। float16 কোয়ান্টাইজেশনের সুবিধাগুলি হল মডেলের আকারকে অর্ধেক পর্যন্ত হ্রাস করা (যেহেতু সমস্ত ওজন তাদের আকারের অর্ধেক হয়ে যায়), নির্ভুলতার ন্যূনতম ক্ষতি ঘটায় এবং GPU প্রতিনিধিদের সমর্থন করে যা সরাসরি float16 ডেটাতে কাজ করতে পারে (যার ফলে float32 এর তুলনায় দ্রুত গণনা করা হয় ডেটা)। float16 ওজনে রূপান্তরিত একটি মডেল এখনও অতিরিক্ত পরিবর্তন ছাড়াই CPU-তে চলতে পারে। প্রথম অনুমানের আগে float16 ওজনগুলিকে float32-এ আপস্যাম্পল করা হয়, যা বিলম্ব এবং নির্ভুলতার ন্যূনতম প্রভাবের বিনিময়ে মডেলের আকার হ্রাস করার অনুমতি দেয়।
সম্পূর্ণ পূর্ণসংখ্যা পরিমাপ
সম্পূর্ণ পূর্ণসংখ্যার পরিমাপ উভয়ই 32 বিট ফ্লোটিং পয়েন্ট সংখ্যাকে, ওজন এবং সক্রিয়করণ সহ নিকটতম 8 বিট পূর্ণসংখ্যাতে রূপান্তরিত করে। এই ধরনের কোয়ান্টাইজেশনের ফলে অনুমান গতি বৃদ্ধি সহ একটি ছোট মডেল তৈরি হয়, যা মাইক্রোকন্ট্রোলার ব্যবহার করার সময় অবিশ্বাস্যভাবে মূল্যবান। এই মোডটি সুপারিশ করা হয় যখন অ্যাক্টিভেশনগুলি পরিমাপের প্রতি সংবেদনশীল হয়।
অ্যান্ড্রয়েড অ্যাপ ইন্টিগ্রেশন
আপনি একটি Android অ্যাপে আপনার TFLite মডেলকে সংহত করতে এই Android উদাহরণ অনুসরণ করতে পারেন।
পূর্বশর্ত
আপনি যদি ইতিমধ্যেই না করে থাকেন তবে ওয়েবসাইটের নির্দেশাবলী অনুসরণ করে অ্যান্ড্রয়েড স্টুডিও ইনস্টল করুন।
- অ্যান্ড্রয়েড স্টুডিও 2022.2.1 বা তার বেশি।
- 4G এর বেশি মেমরি সহ একটি Android ডিভাইস বা Android এমুলেটর
অ্যান্ড্রয়েড স্টুডিওর সাথে নির্মাণ এবং চলমান
- অ্যান্ড্রয়েড স্টুডিও খুলুন, এবং স্বাগতম স্ক্রীন থেকে, একটি বিদ্যমান অ্যান্ড্রয়েড স্টুডিও প্রকল্প খুলুন নির্বাচন করুন।
- যে ওপেন ফাইল বা প্রজেক্ট উইন্ডোটি প্রদর্শিত হবে সেখান থেকে, যেখানেই আপনি টেনসরফ্লো লাইট নমুনা গিটহাব রেপো ক্লোন করেছেন সেখান থেকে
lite/examples/generative_ai/androidডিরেক্টরিতে নেভিগেট করুন এবং নির্বাচন করুন। - ত্রুটি বার্তা অনুসারে আপনাকে বিভিন্ন প্ল্যাটফর্ম এবং সরঞ্জাম ইনস্টল করতে হতে পারে।
- রূপান্তরিত .tflite মডেলটিকে
autocomplete.tfliteএ পুনঃনামকরণ করুন এবং এটিকেapp/src/main/assets/ফোল্ডারে অনুলিপি করুন৷ - মেনু বিল্ড নির্বাচন করুন -> অ্যাপ তৈরি করতে প্রজেক্ট তৈরি করুন । (Ctrl+F9, আপনার সংস্করণের উপর নির্ভর করে)।
- মেনু রান -> রান 'অ্যাপ' এ ক্লিক করুন। (Shift+F10, আপনার সংস্করণের উপর নির্ভর করে)
বিকল্পভাবে, আপনি কমান্ড লাইনে এটি তৈরি করতে gradle wrapper ব্যবহার করতে পারেন। আরও তথ্যের জন্য অনুগ্রহ করে গ্রেডল ডকুমেন্টেশন পড়ুন।
(ঐচ্ছিক) .aar ফাইল তৈরি করা
ডিফল্টরূপে অ্যাপ স্বয়ংক্রিয়ভাবে প্রয়োজনীয় .aar ফাইল ডাউনলোড করে। কিন্তু আপনি যদি নিজের তৈরি করতে চান, তাহলে app/libs/build_aar/ ফোল্ডার রান ./build_aar.sh এ স্যুইচ করুন। এই স্ক্রিপ্টটি টেনসরফ্লো টেক্সট থেকে প্রয়োজনীয় অপস টেনে আনবে এবং সিলেক্ট টিএফ অপারেটরদের জন্য aar তৈরি করবে।
সংকলনের পরে, একটি নতুন ফাইল tftext_tflite_flex.aar তৈরি হয়। app/libs/ ফোল্ডারে .aar ফাইলটি প্রতিস্থাপন করুন এবং অ্যাপটি পুনরায় তৈরি করুন।
মনে রাখবেন যে আপনাকে এখনও আপনার গ্রেডল ফাইলে স্ট্যান্ডার্ড tensorflow-lite এআর অন্তর্ভুক্ত করতে হবে।
প্রসঙ্গ উইন্ডোর আকার
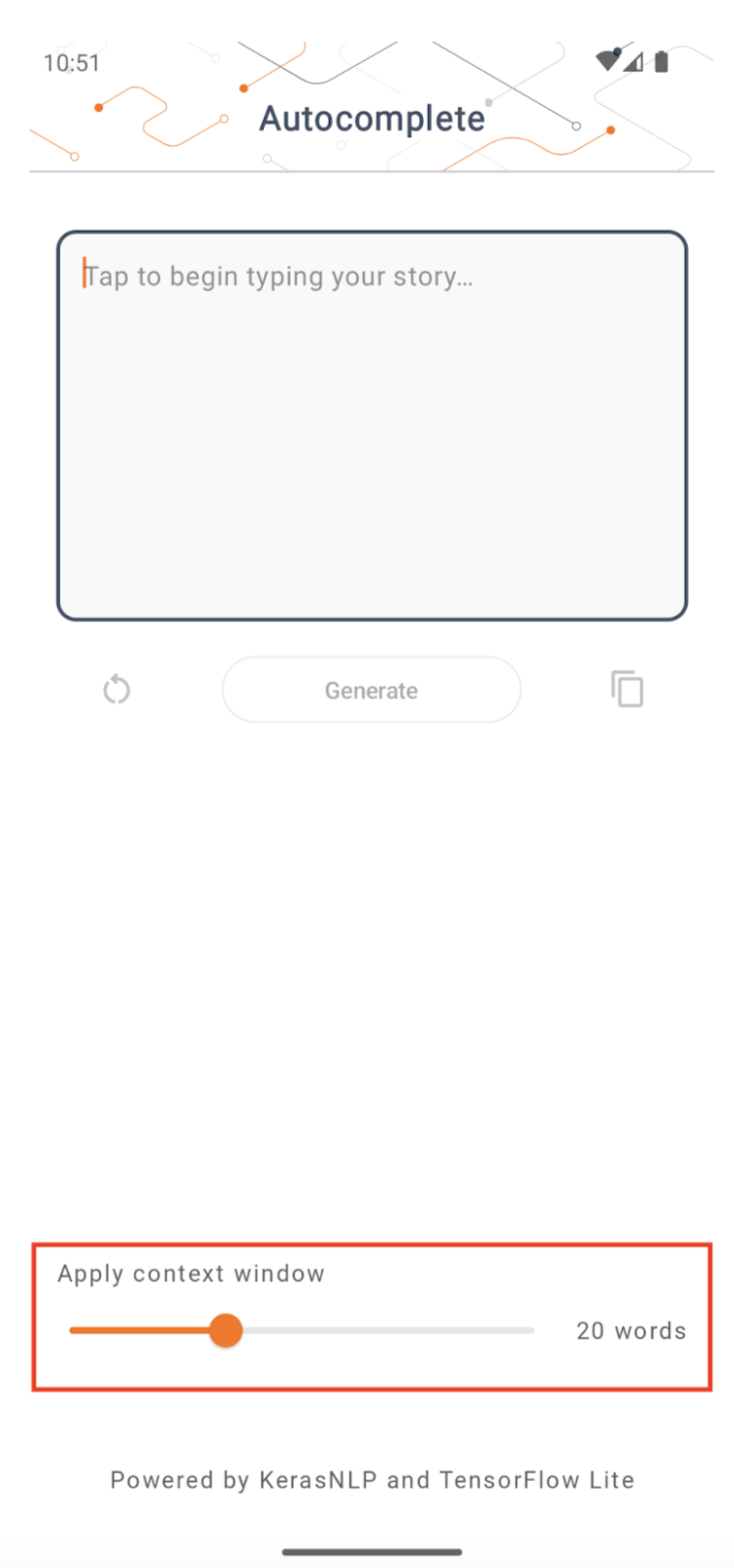
অ্যাপটির একটি পরিবর্তনযোগ্য প্যারামিটার 'প্রসঙ্গ উইন্ডোর আকার' রয়েছে, যা প্রয়োজন কারণ LLM-এর সাধারণত একটি নির্দিষ্ট প্রসঙ্গ আকার থাকে যা 'প্রম্পট' হিসাবে মডেলটিতে কতগুলি শব্দ/টোকেন দেওয়া যেতে পারে তা সীমাবদ্ধ করে (মনে রাখবেন যে 'শব্দ' অগত্যা নয় এই ক্ষেত্রে 'টোকেন' এর সমতুল্য, বিভিন্ন টোকেনাইজেশন পদ্ধতির কারণে)। এই সংখ্যাটি গুরুত্বপূর্ণ কারণ:
- এটিকে খুব ছোট করে সেট করা, অর্থপূর্ণ আউটপুট তৈরি করার জন্য মডেলটির যথেষ্ট প্রসঙ্গ থাকবে না
- এটি খুব বড় সেট করা, মডেলটির সাথে কাজ করার জন্য পর্যাপ্ত জায়গা থাকবে না (যেহেতু আউটপুট ক্রমটি প্রম্পটের অন্তর্ভুক্ত)
আপনি এটি নিয়ে পরীক্ষা করতে পারেন, তবে এটিকে আউটপুট ক্রম দৈর্ঘ্যের ~50% এ সেট করা একটি ভাল শুরু।
নিরাপত্তা এবং দায়িত্বশীল এআই
মূল OpenAI GPT-2 ঘোষণায় উল্লিখিত হিসাবে, GPT-2 মডেলের সাথে উল্লেখযোগ্য সতর্কতা এবং সীমাবদ্ধতা রয়েছে। প্রকৃতপক্ষে, এলএলএম-এর আজ সাধারণত কিছু সুপরিচিত চ্যালেঞ্জ রয়েছে যেমন হ্যালুসিনেশন, ন্যায্যতা এবং পক্ষপাত; কারণ এই মডেলগুলি বাস্তব-বিশ্বের ডেটার উপর প্রশিক্ষিত, যা তাদের বাস্তব বিশ্বের সমস্যাগুলিকে প্রতিফলিত করে।
এই কোডল্যাবটি শুধুমাত্র টেনসরফ্লো টুলিং এর সাহায্যে এলএলএম দ্বারা চালিত একটি অ্যাপ কীভাবে তৈরি করা যায় তা প্রদর্শন করার জন্য তৈরি করা হয়েছে। এই কোডল্যাবে উত্পাদিত মডেল শুধুমাত্র শিক্ষাগত উদ্দেশ্যে এবং উৎপাদন ব্যবহারের উদ্দেশ্যে নয়।
এলএলএম উত্পাদন ব্যবহারের জন্য প্রশিক্ষণ ডেটাসেটগুলির চিন্তাশীল নির্বাচন এবং ব্যাপক নিরাপত্তা প্রশমন প্রয়োজন। এই অ্যান্ড্রয়েড অ্যাপে দেওয়া এই ধরনের একটি কার্যকারিতা হল অশ্লীলতা ফিল্টার, যা খারাপ ব্যবহারকারীর ইনপুট বা মডেল আউটপুট প্রত্যাখ্যান করে। কোনো অনুপযুক্ত ভাষা শনাক্ত হলে, অ্যাপটি সেই ক্রিয়াকে প্রত্যাখ্যান করবে। LLM-এর প্রসঙ্গে দায়বদ্ধ AI সম্পর্কে আরও জানতে, Google I/O 2023-এ জেনারেটিভ ল্যাঙ্গুয়েজ মডেলের প্রযুক্তিগত সেশনের সাথে নিরাপদ এবং দায়িত্বশীল বিকাশ দেখতে ভুলবেন না এবং দায়বদ্ধ AI টুলকিটটি দেখুন।