
| | |
Perkenalan
Model bahasa besar (LLM) adalah kelas model pembelajaran mesin yang dilatih untuk menghasilkan teks berdasarkan kumpulan data besar. Mereka dapat digunakan untuk tugas pemrosesan bahasa alami (NLP), termasuk pembuatan teks, menjawab pertanyaan, dan terjemahan mesin. Mereka didasarkan pada arsitektur Transformer dan dilatih pada data teks dalam jumlah besar, seringkali melibatkan miliaran kata. Bahkan LLM dengan skala yang lebih kecil, seperti GPT-2, dapat memberikan kinerja yang mengesankan. Mengonversi model TensorFlow menjadi model yang lebih ringan, cepat, dan berdaya rendah memungkinkan kami menjalankan model AI generatif di perangkat, dengan manfaat keamanan pengguna yang lebih baik karena data tidak akan pernah keluar dari perangkat Anda.
Runbook ini menunjukkan kepada Anda cara membuat aplikasi Android dengan TensorFlow Lite untuk menjalankan Keras LLM dan memberikan saran untuk pengoptimalan model menggunakan teknik kuantisasi, yang jika tidak, akan memerlukan jumlah memori yang jauh lebih besar dan daya komputasi yang lebih besar untuk menjalankannya.
Kami telah membuat kerangka aplikasi Android kami menjadi sumber terbuka sehingga LLM TFLite mana pun yang kompatibel dapat menyambungkannya. Berikut adalah dua demo:
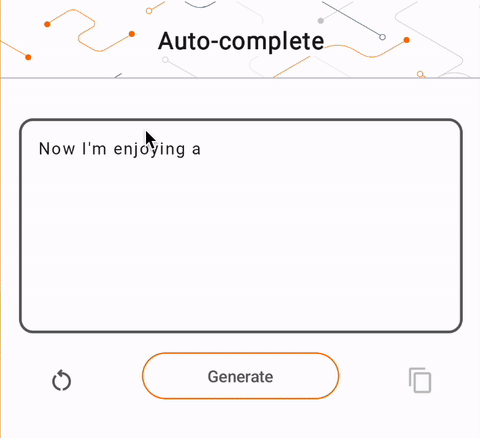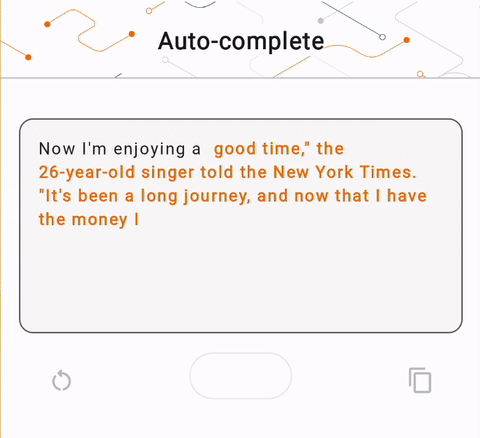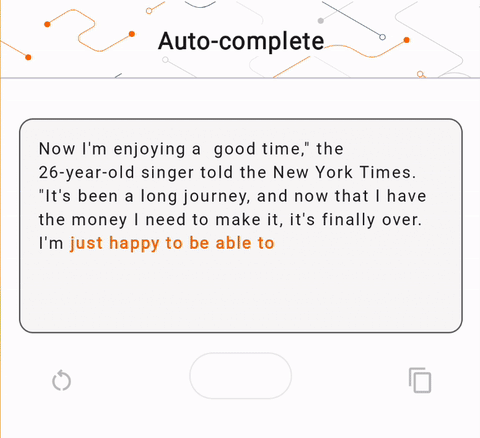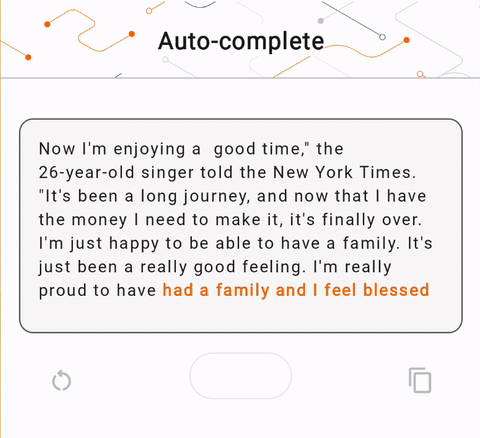
- Pada Gambar 1, kami menggunakan model Keras GPT-2 untuk melakukan tugas penyelesaian teks pada perangkat.
- Pada Gambar 2, kami mengonversi versi model PaLM yang disesuaikan dengan instruksi (1,5 miliar parameter) menjadi TFLite dan dieksekusi melalui runtime TFLite.
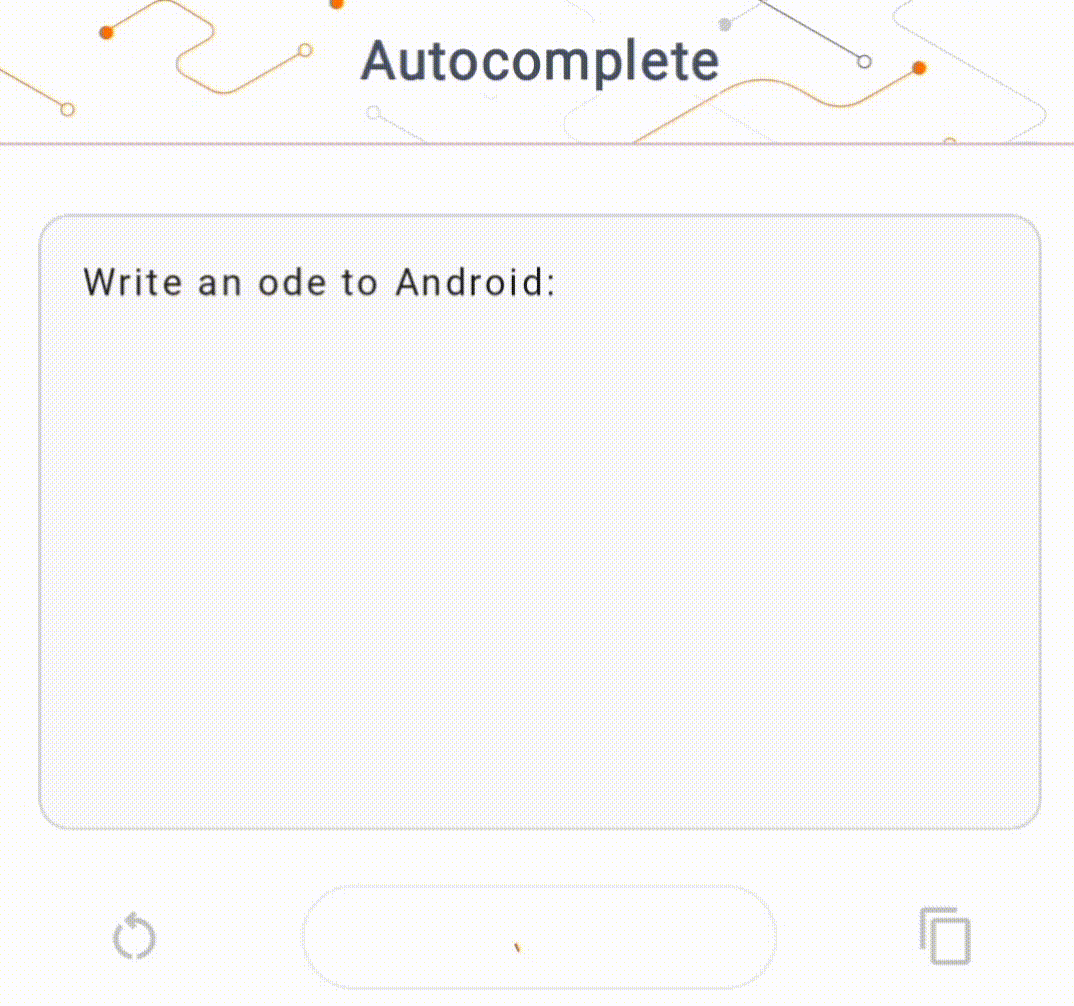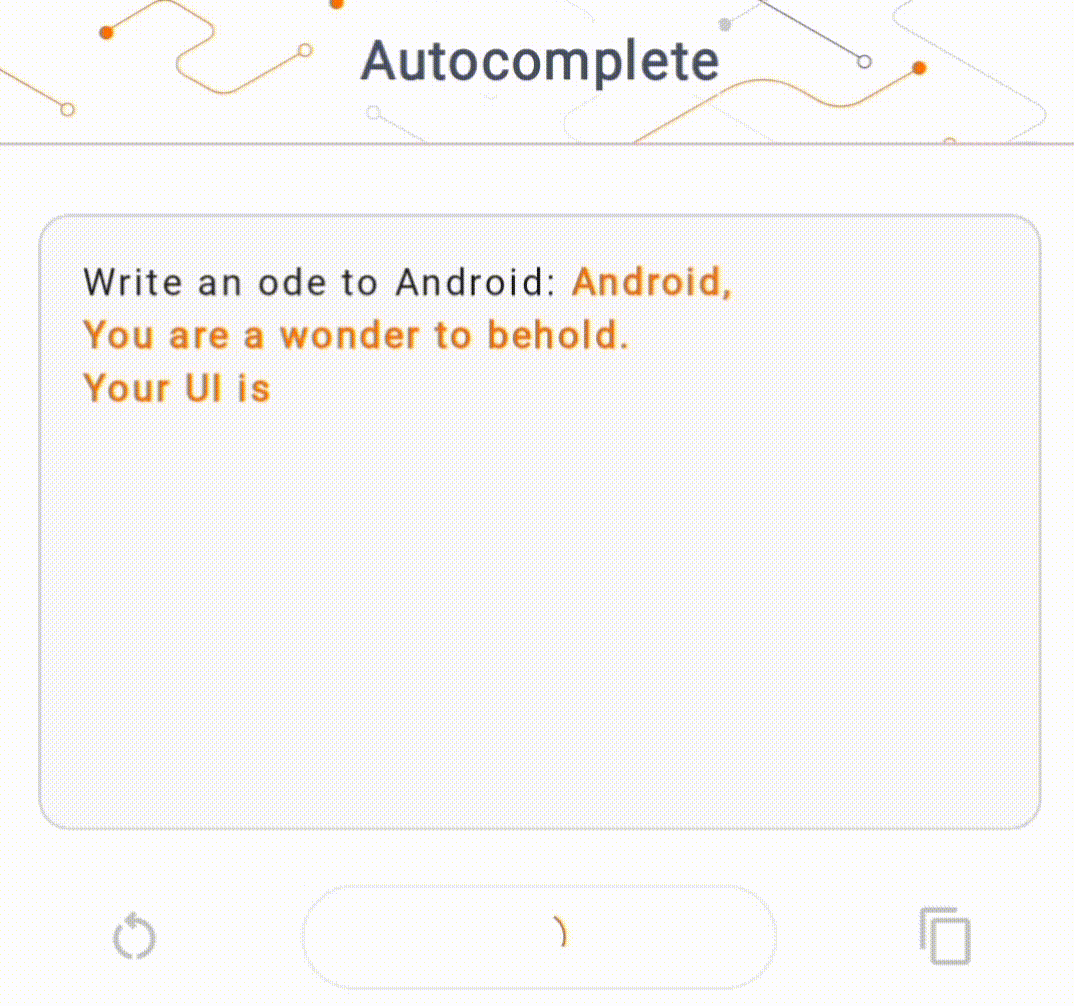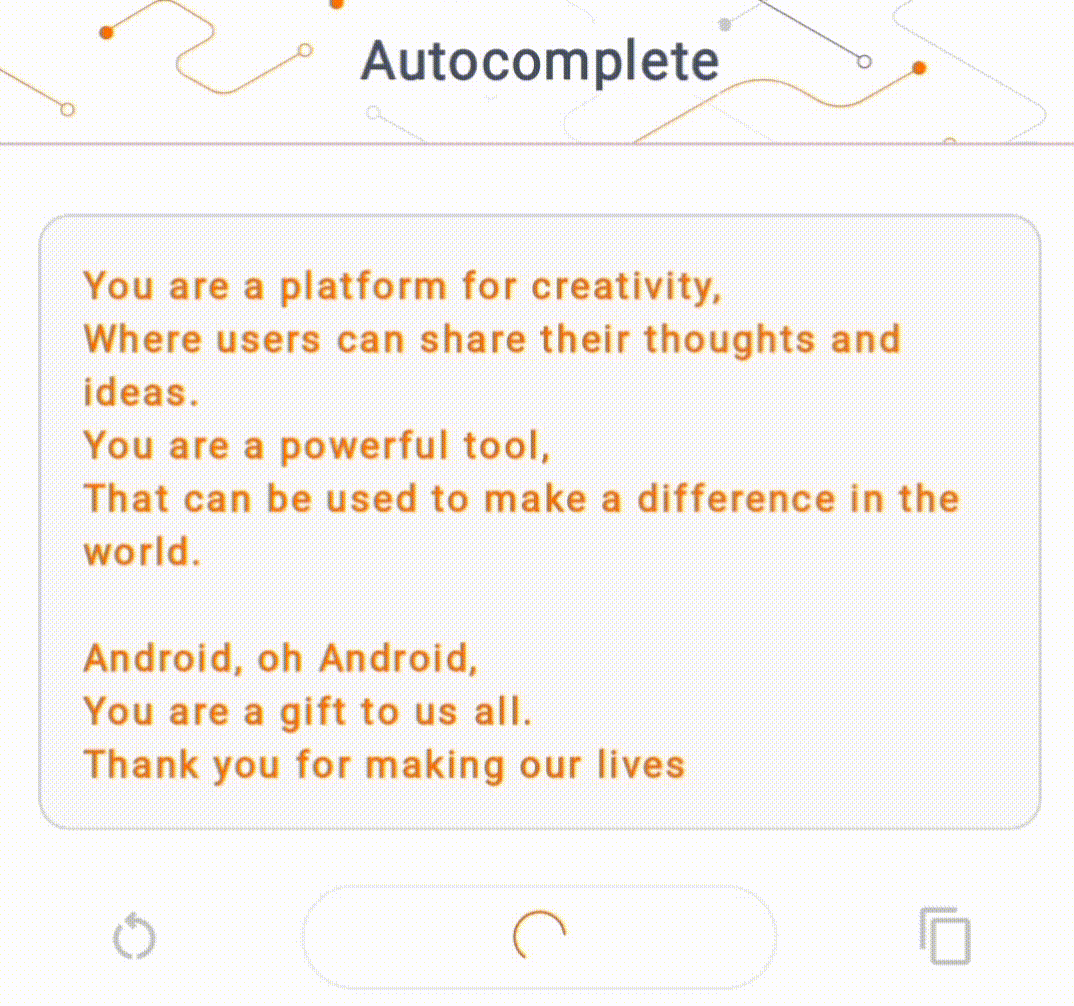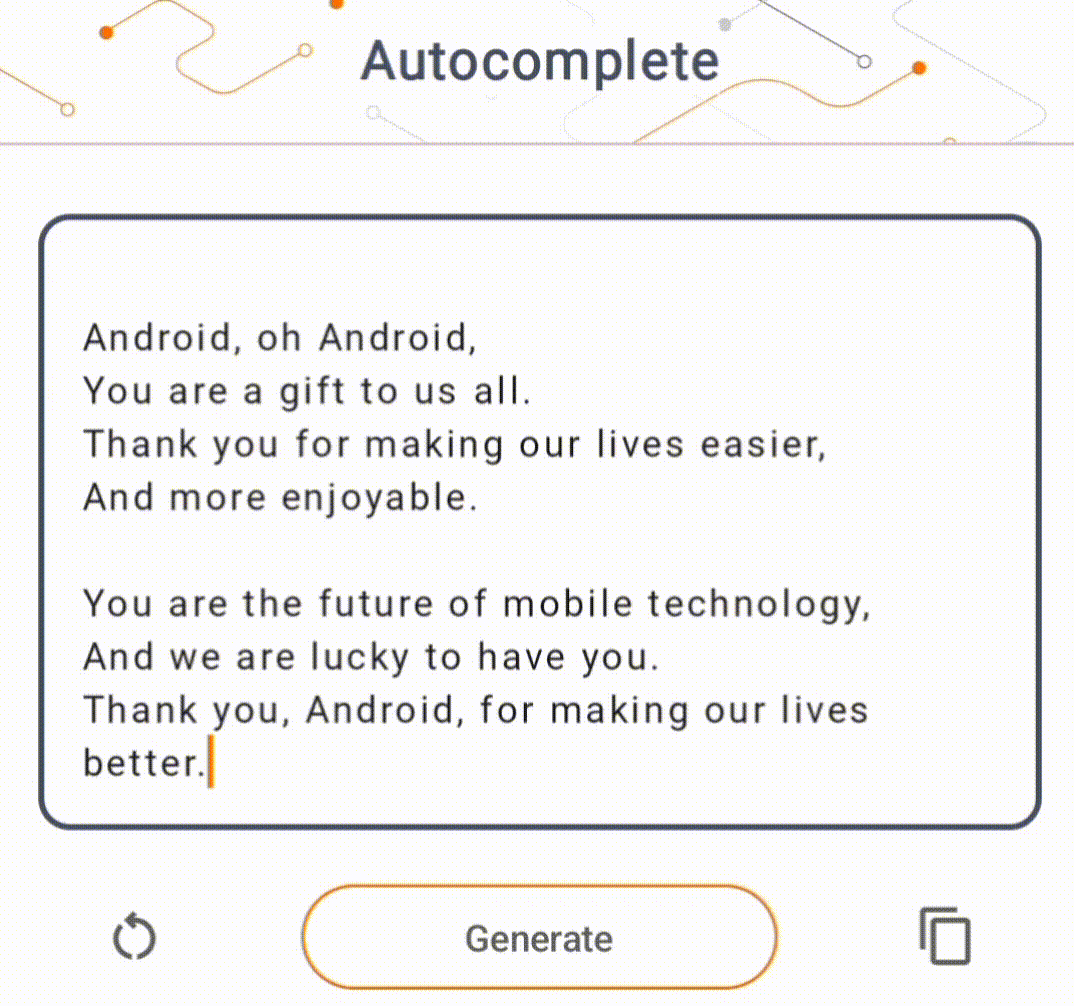
Panduan
Penulisan model
Untuk demonstrasi ini, kami akan menggunakan KerasNLP untuk mendapatkan model GPT-2. KerasNLP adalah perpustakaan yang berisi model terlatih canggih untuk tugas pemrosesan bahasa alami, dan dapat mendukung pengguna melalui seluruh siklus pengembangan mereka. Anda dapat melihat daftar model yang tersedia di repositori KerasNLP . Alur kerja dibangun dari komponen modular yang memiliki bobot dan arsitektur prasetel yang canggih saat digunakan langsung dan mudah disesuaikan saat diperlukan lebih banyak kontrol. Membuat model GPT-2 dapat dilakukan dengan langkah-langkah berikut:
gpt2_tokenizer = keras_nlp.models.GPT2Tokenizer.from_preset("gpt2_base_en")
gpt2_preprocessor = keras_nlp.models.GPT2CausalLMPreprocessor.from_preset(
"gpt2_base_en",
sequence_length=256,
add_end_token=True,
)
gpt2_lm =
keras_nlp.models.GPT2CausalLM.from_preset(
"gpt2_base_en",
preprocessor=gpt2_preprocessor
)
Salah satu kesamaan di antara ketiga baris kode ini adalah metode from_preset() , yang akan membuat instance bagian Keras API dari arsitektur dan/atau bobot yang telah ditetapkan sebelumnya, sehingga memuat model yang telah dilatih sebelumnya. Dari cuplikan kode ini, Anda juga akan melihat tiga komponen modular:
Tokenizer : mengubah input string mentah menjadi ID token integer yang cocok untuk lapisan Keras Embedding. GPT-2 menggunakan tokenizer byte-pair coding (BPE) secara khusus.
Preprocessor : lapisan untuk tokenisasi dan pengemasan input untuk dimasukkan ke dalam model Keras. Di sini, praprosesor akan memasukkan tensor ID token ke panjang tertentu (256) setelah tokenisasi.
Backbone : Model Keras yang mengikuti arsitektur tulang punggung transformator SoTA dan memiliki bobot yang telah ditentukan sebelumnya.
Selain itu, Anda dapat melihat implementasi model GPT-2 secara lengkap di GitHub .
Konversi model
TensorFlow Lite adalah perpustakaan seluler untuk menerapkan metode pada perangkat seluler, mikrokontroler, dan perangkat edge lainnya. Langkah pertama adalah mengonversi model Keras ke format TensorFlow Lite yang lebih ringkas menggunakan konverter TensorFlow Lite , lalu menggunakan juru bahasa TensorFlow Lite , yang sangat dioptimalkan untuk perangkat seluler, untuk menjalankan model yang dikonversi.
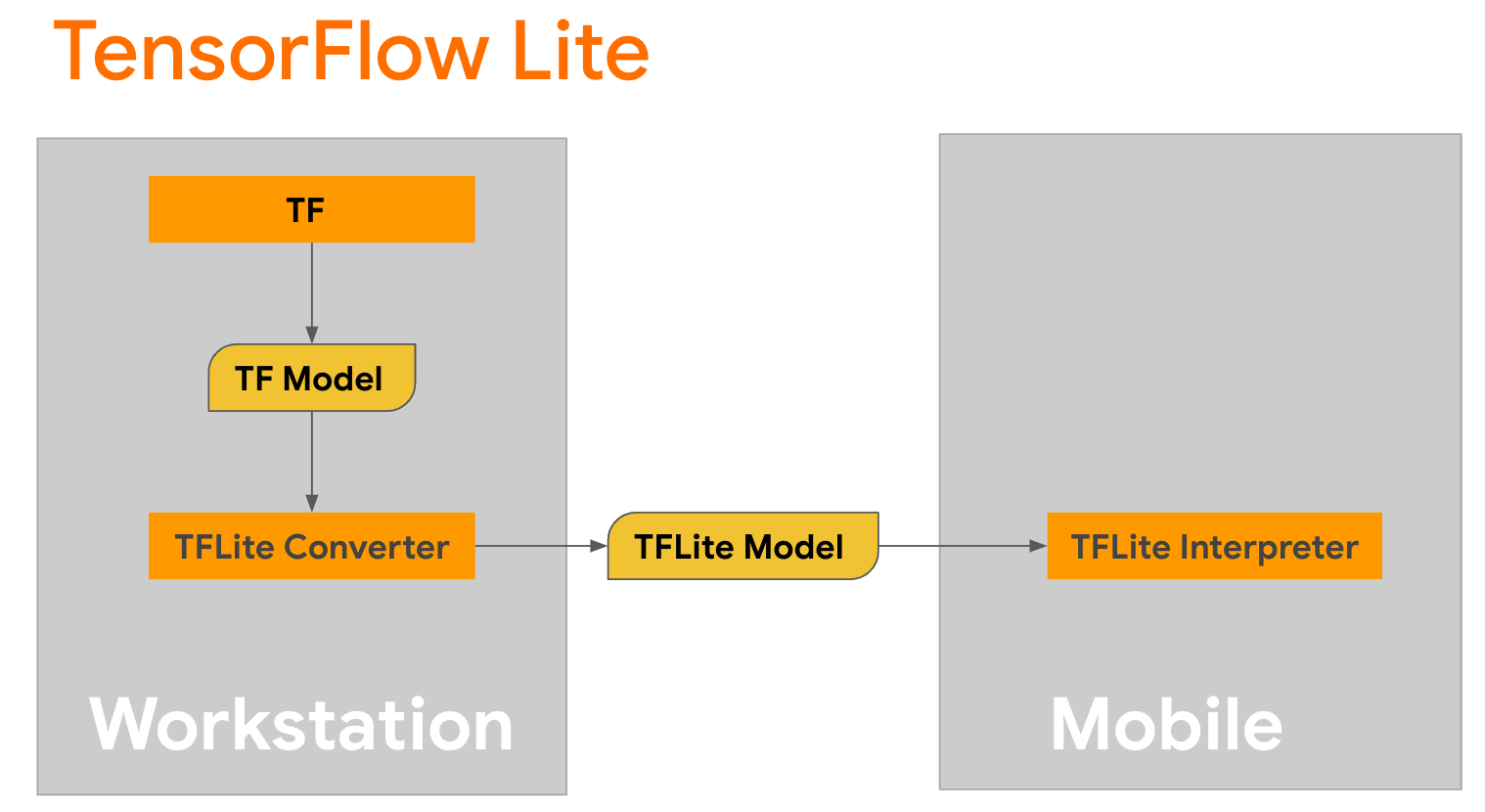 Mulailah dengan fungsi
Mulailah dengan fungsi generate() dari GPT2CausalLM yang melakukan konversi. Gabungkan fungsi generate() untuk membuat fungsi TensorFlow yang konkret:
@tf.function
def generate(prompt, max_length):
"""
Args:
prompt: input prompt to the LLM in string format
max_length: the max length of the generated tokens
"""
return gpt2_lm.generate(prompt, max_length)
concrete_func = generate.get_concrete_function(tf.TensorSpec([], tf.string), 100)
Perhatikan bahwa Anda juga dapat menggunakan from_keras_model() dari TFLiteConverter untuk melakukan konversi.
Sekarang tentukan fungsi pembantu yang akan menjalankan inferensi dengan input dan model TFLite. Operasi teks TensorFlow bukanlah operasi bawaan dalam runtime TFLite, jadi Anda perlu menambahkan operasi khusus ini agar penerjemah dapat membuat inferensi pada model ini. Fungsi pembantu ini menerima masukan dan fungsi yang melakukan konversi, yaitu fungsi generator() yang didefinisikan di atas.
def run_inference(input, generate_tflite):
interp = interpreter.InterpreterWithCustomOps(
model_content=generate_tflite,
custom_op_registerers=
tf_text.tflite_registrar.SELECT_TFTEXT_OPS
)
interp.get_signature_list()
generator = interp.get_signature_runner('serving_default')
output = generator(prompt=np.array([input]))
Anda dapat mengonversi model sekarang:
gpt2_lm.jit_compile = False
converter = tf.lite.TFLiteConverter.from_concrete_functions(
[concrete_func],
gpt2_lm)
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # enable TFLite ops
tf.lite.OpsSet.SELECT_TF_OPS, # enable TF ops
]
converter.allow_custom_ops = True
converter.target_spec.experimental_select_user_tf_ops = [
"UnsortedSegmentJoin",
"UpperBound"
]
converter._experimental_guarantee_all_funcs_one_use = True
generate_tflite = converter.convert()
run_inference("I'm enjoying a", generate_tflite)
Kuantisasi
TensorFlow Lite telah menerapkan teknik pengoptimalan yang disebut kuantisasi yang dapat mengurangi ukuran model dan mempercepat inferensi. Melalui proses kuantisasi, float 32-bit dipetakan ke bilangan bulat 8-bit yang lebih kecil, sehingga mengurangi ukuran model sebanyak 4 kali lipat untuk eksekusi yang lebih efisien pada perangkat keras modern. Ada beberapa cara untuk melakukan kuantisasi di TensorFlow. Anda dapat mengunjungi halaman Pengoptimalan Model TFLite dan Alat Pengoptimalan Model TensorFlow untuk informasi selengkapnya. Jenis kuantisasi dijelaskan secara singkat di bawah ini.
Di sini, Anda akan menggunakan kuantisasi rentang dinamis pasca-pelatihan pada model GPT-2 dengan menyetel tanda pengoptimalan konverter ke tf.lite.Optimize.DEFAULT , dan proses konversi selanjutnya sama seperti yang dijelaskan sebelumnya. Kami menguji bahwa dengan teknik kuantisasi ini, latensinya sekitar 6,7 detik pada Pixel 7 dengan panjang keluaran maksimal disetel ke 100.
gpt2_lm.jit_compile = False
converter = tf.lite.TFLiteConverter.from_concrete_functions(
[concrete_func],
gpt2_lm)
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # enable TFLite ops
tf.lite.OpsSet.SELECT_TF_OPS, # enable TF ops
]
converter.allow_custom_ops = True
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.experimental_select_user_tf_ops = [
"UnsortedSegmentJoin",
"UpperBound"
]
converter._experimental_guarantee_all_funcs_one_use = True
quant_generate_tflite = converter.convert()
run_inference("I'm enjoying a", quant_generate_tflite)
Rentang Dinamis
Kuantisasi rentang dinamis adalah titik awal yang disarankan untuk mengoptimalkan model pada perangkat. Hal ini dapat mencapai pengurangan ukuran model sekitar 4x, dan merupakan titik awal yang direkomendasikan karena memberikan pengurangan penggunaan memori dan komputasi yang lebih cepat tanpa Anda harus menyediakan kumpulan data yang representatif untuk kalibrasi. Jenis kuantisasi ini secara statis hanya mengkuantisasi bobot dari floating point ke integer 8-bit pada waktu konversi.
FP16
Model floating point juga dapat dioptimalkan dengan mengkuantisasi bobot ke tipe float16. Keuntungan kuantisasi float16 adalah mengurangi ukuran model hingga setengahnya (karena semua bobot menjadi setengah ukurannya), menyebabkan hilangnya akurasi yang minimal, dan mendukung delegasi GPU yang dapat beroperasi secara langsung pada data float16 (yang menghasilkan komputasi lebih cepat dibandingkan pada float32 data). Model yang dikonversi ke bobot float16 masih dapat berjalan di CPU tanpa modifikasi tambahan. Bobot float16 ditingkatkan sampelnya menjadi float32 sebelum inferensi pertama, yang memungkinkan pengurangan ukuran model dengan imbalan dampak minimal terhadap latensi dan akurasi.
Kuantisasi Integer Penuh
Kuantisasi bilangan bulat penuh mengubah bilangan floating point 32 bit, termasuk bobot dan aktivasi, menjadi bilangan bulat 8 bit terdekat. Jenis kuantisasi ini menghasilkan model yang lebih kecil dengan peningkatan kecepatan inferensi, yang sangat berharga saat menggunakan mikrokontroler. Mode ini direkomendasikan ketika aktivasi sensitif terhadap kuantisasi.
Integrasi Aplikasi Android
Anda dapat mengikuti contoh Android ini untuk mengintegrasikan model TFLite Anda ke dalam Aplikasi Android.
Prasyarat
Jika Anda belum melakukannya, instal Android Studio , ikuti petunjuk di situs web.
- Android Studio 2022.2.1 atau lebih tinggi.
- Perangkat Android atau emulator Android dengan memori lebih dari 4G
Membangun dan Menjalankan dengan Android Studio
- Buka Android Studio, dan dari layar Selamat Datang, pilih Buka proyek Android Studio yang ada .
- Dari jendela Open File atau Project yang muncul, navigasikan ke dan pilih direktori
lite/examples/generative_ai/androiddari mana pun Anda mengkloning sampel repo GitHub TensorFlow Lite. - Anda mungkin juga perlu menginstal berbagai platform dan alat sesuai dengan pesan kesalahan.
- Ganti nama model .tflite yang dikonversi menjadi
autocomplete.tflitedan salin ke folderapp/src/main/assets/. - Pilih menu Build -> Make Project untuk membangun aplikasi. (Ctrl+F9, tergantung versi Anda).
- Klik menu Jalankan -> Jalankan 'aplikasi' . (Shift+F10, tergantung versi Anda)
Alternatifnya, Anda juga dapat menggunakan gradle wrapper untuk membuatnya di baris perintah. Silakan merujuk ke dokumentasi Gradle untuk informasi lebih lanjut.
(Opsional) Membangun file .aar
Secara default, aplikasi secara otomatis mengunduh file .aar yang diperlukan. Tetapi jika Anda ingin membuatnya sendiri, alihkan ke folder app/libs/build_aar/ jalankan ./build_aar.sh . Skrip ini akan mengambil operasi yang diperlukan dari TensorFlow Text dan membuat aar untuk operator TF Pilihan.
Setelah kompilasi, file baru tftext_tflite_flex.aar dibuat. Ganti file .aar di folder app/libs/ dan buat ulang aplikasi.
Perhatikan bahwa Anda masih perlu menyertakan tensorflow-lite aar standar dalam file gradle Anda.
Ukuran jendela konteks
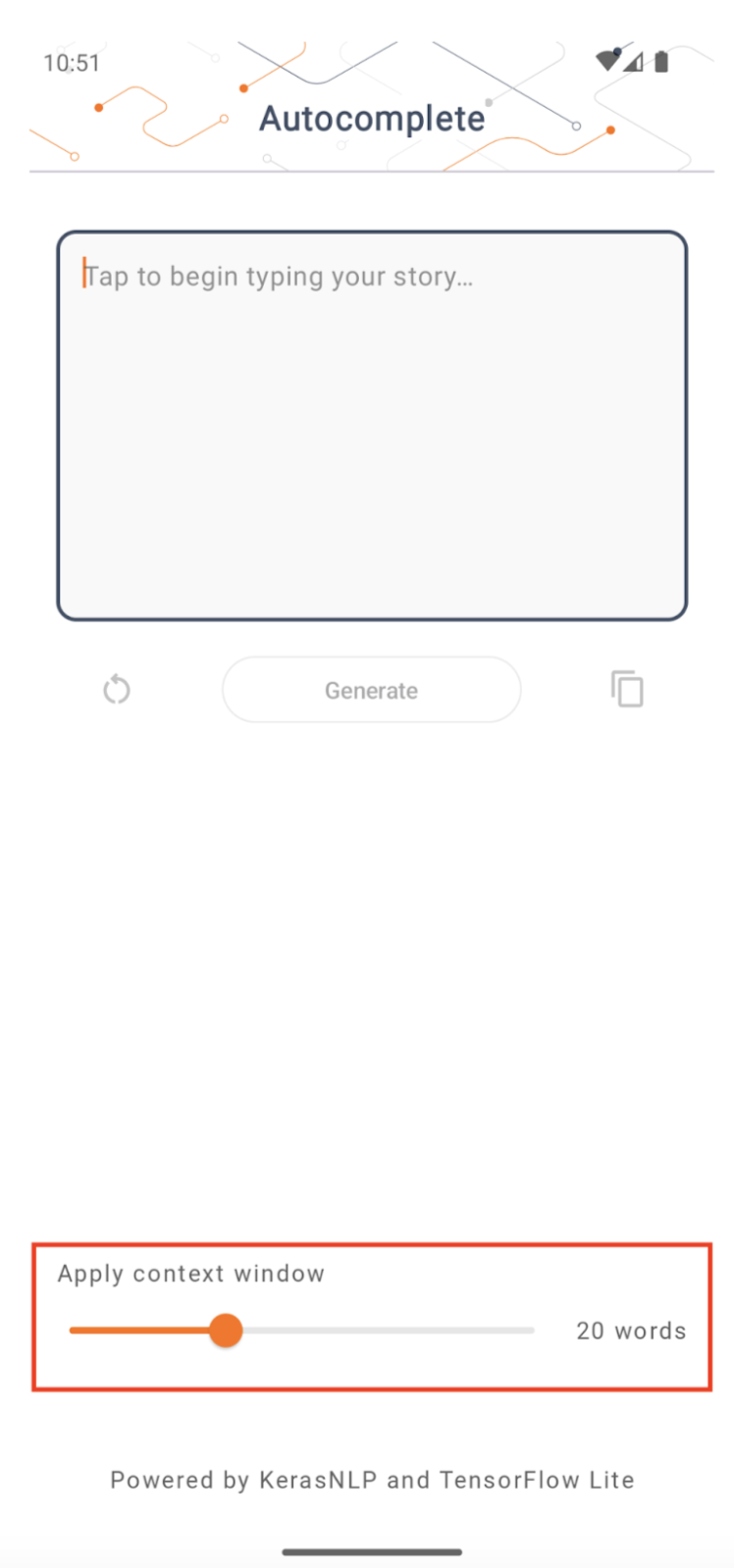
Aplikasi ini memiliki parameter 'ukuran jendela konteks' yang dapat diubah, yang diperlukan karena LLM saat ini umumnya memiliki ukuran konteks tetap yang membatasi berapa banyak kata/token yang dapat dimasukkan ke dalam model sebagai 'prompt' (perhatikan bahwa 'kata' belum tentu setara dengan 'token' dalam hal ini, karena metode tokenisasi yang berbeda). Angka ini penting karena:
- Jika terlalu kecil, model tidak akan memiliki konteks yang cukup untuk menghasilkan keluaran yang berarti
- Menyetelnya terlalu besar, model tidak akan memiliki cukup ruang untuk dikerjakan (karena urutan keluaran sudah termasuk prompt)
Anda dapat bereksperimen dengannya, tetapi menyetelnya ke ~50% dari panjang urutan keluaran adalah awal yang baik.
AI yang Aman dan Bertanggung Jawab
Seperti yang tercantum dalam pengumuman awal OpenAI GPT-2 , terdapat peringatan dan batasan penting pada model GPT-2. Faktanya, LLM saat ini umumnya memiliki beberapa tantangan seperti halusinasi, keadilan, dan bias; Hal ini karena model ini dilatih berdasarkan data dunia nyata, sehingga model tersebut mencerminkan permasalahan di dunia nyata.
Codelab ini dibuat hanya untuk menunjukkan cara membuat aplikasi yang didukung oleh LLM dengan alat TensorFlow. Model yang dihasilkan dalam codelab ini hanya untuk tujuan pendidikan dan tidak dimaksudkan untuk penggunaan produksi.
Penggunaan produksi LLM memerlukan pemilihan kumpulan data pelatihan yang cermat dan mitigasi keselamatan yang komprehensif. Salah satu fungsi yang ditawarkan dalam aplikasi Android ini adalah filter kata-kata kotor, yang menolak masukan pengguna atau keluaran model yang buruk. Jika ada bahasa yang tidak pantas terdeteksi, aplikasi akan menolak tindakan tersebut. Untuk mempelajari lebih lanjut tentang AI yang Bertanggung Jawab dalam konteks LLM, pastikan untuk menonton sesi teknis Pengembangan yang Aman dan Bertanggung Jawab dengan Model Bahasa Generatif di Google I/O 2023 dan lihat Perangkat AI yang Bertanggung Jawab .