
| | |
introduzione
I modelli linguistici di grandi dimensioni (LLM) sono una classe di modelli di machine learning addestrati a generare testo basato su set di dati di grandi dimensioni. Possono essere utilizzati per attività di elaborazione del linguaggio naturale (NLP), tra cui la generazione di testo, la risposta a domande e la traduzione automatica. Si basano sull'architettura Transformer e vengono addestrati su enormi quantità di dati di testo, che spesso coinvolgono miliardi di parole. Anche i LLM su scala più piccola, come GPT-2, possono ottenere prestazioni impressionanti. La conversione dei modelli TensorFlow in un modello più leggero, più veloce e a basso consumo ci consente di eseguire modelli di intelligenza artificiale generativa sul dispositivo, con vantaggi in termini di migliore sicurezza dell'utente perché i dati non lasceranno mai il tuo dispositivo.
Questo runbook illustra come creare un'app Android con TensorFlow Lite per eseguire un Keras LLM e fornisce suggerimenti per l'ottimizzazione del modello utilizzando tecniche di quantizzazione, che altrimenti richiederebbero una quantità di memoria molto maggiore e una maggiore potenza di calcolo per l'esecuzione.
Abbiamo reso open source il nostro framework di app Android a cui qualsiasi LLM TFLite compatibile può collegarsi. Ecco due demo:
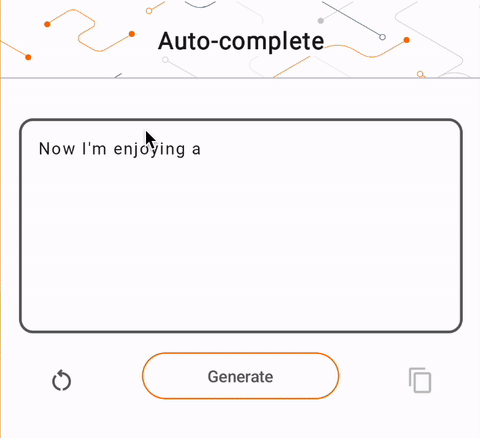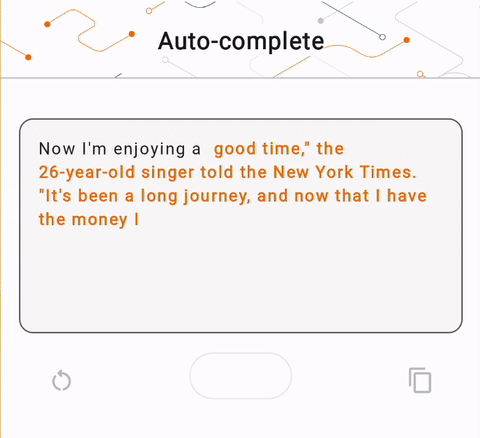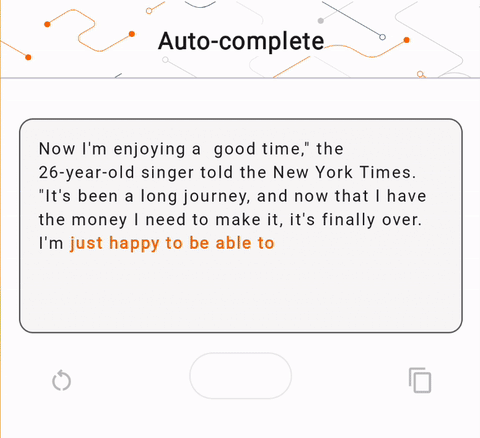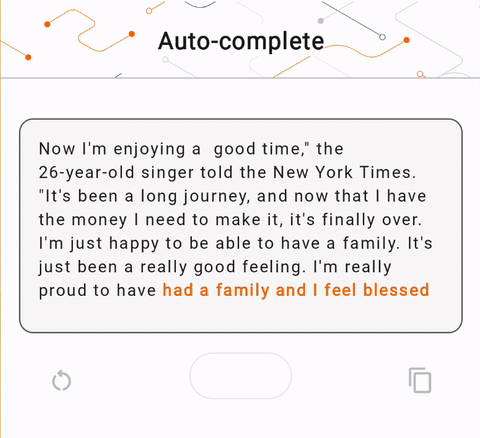
- Nella Figura 1, abbiamo utilizzato un modello Keras GPT-2 per eseguire attività di completamento del testo sul dispositivo.
- Nella Figura 2, abbiamo convertito una versione del modello PaLM ottimizzato per le istruzioni (1,5 miliardi di parametri) in TFLite ed eseguito tramite il runtime TFLite.
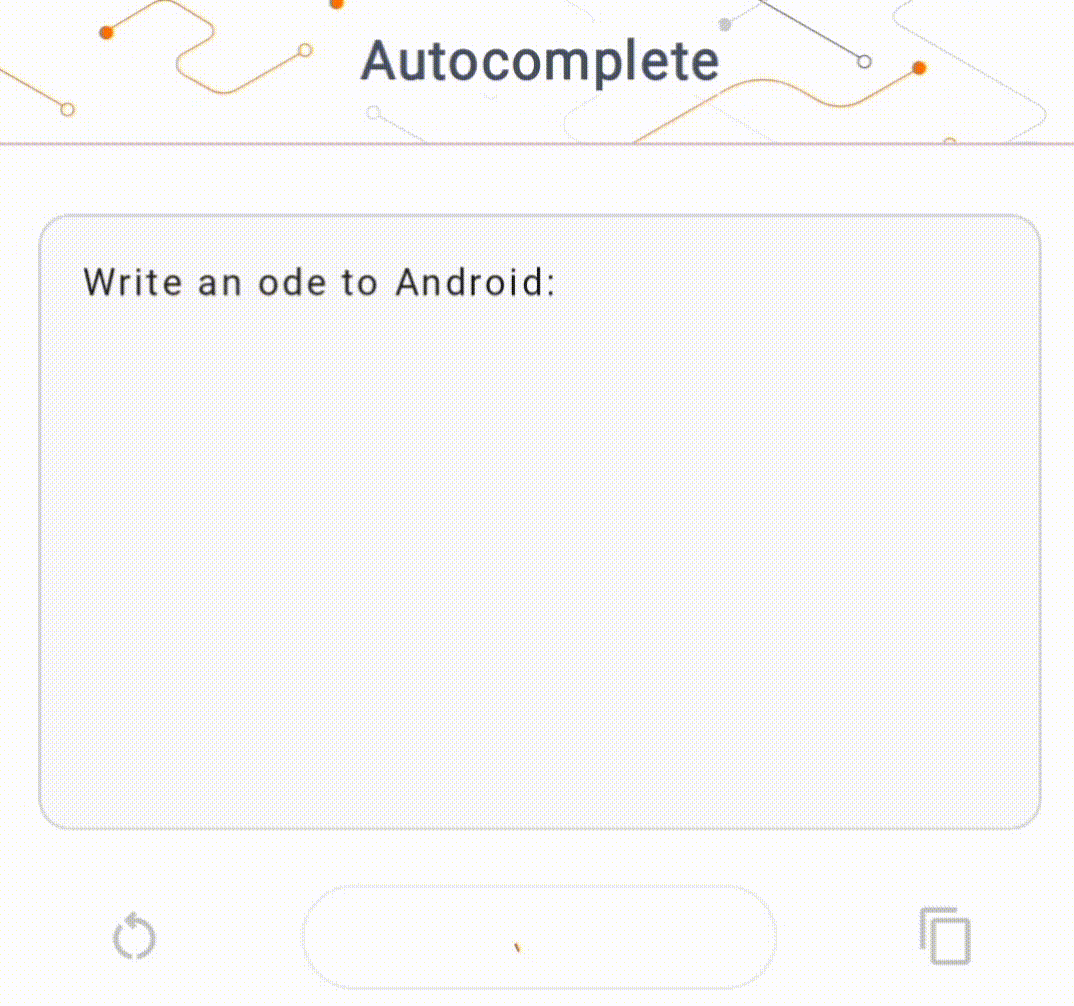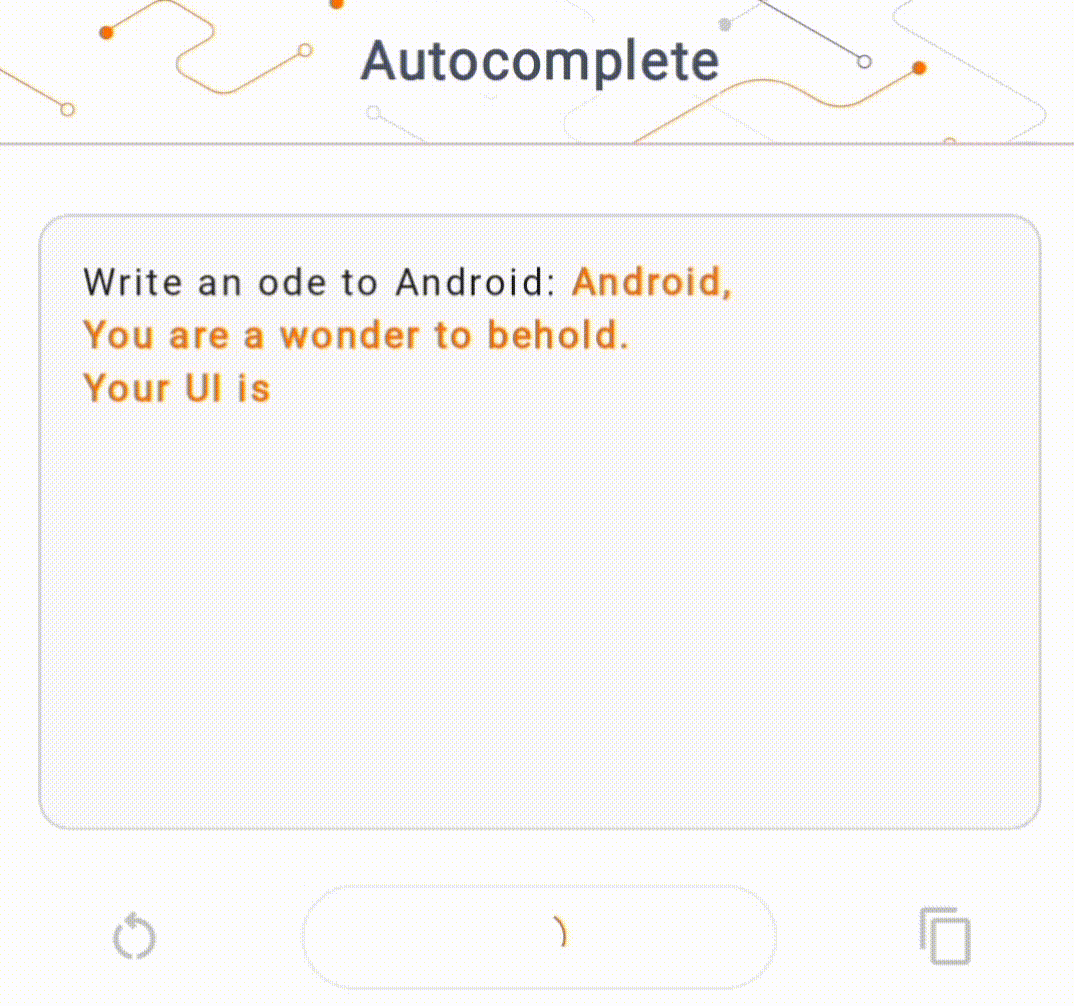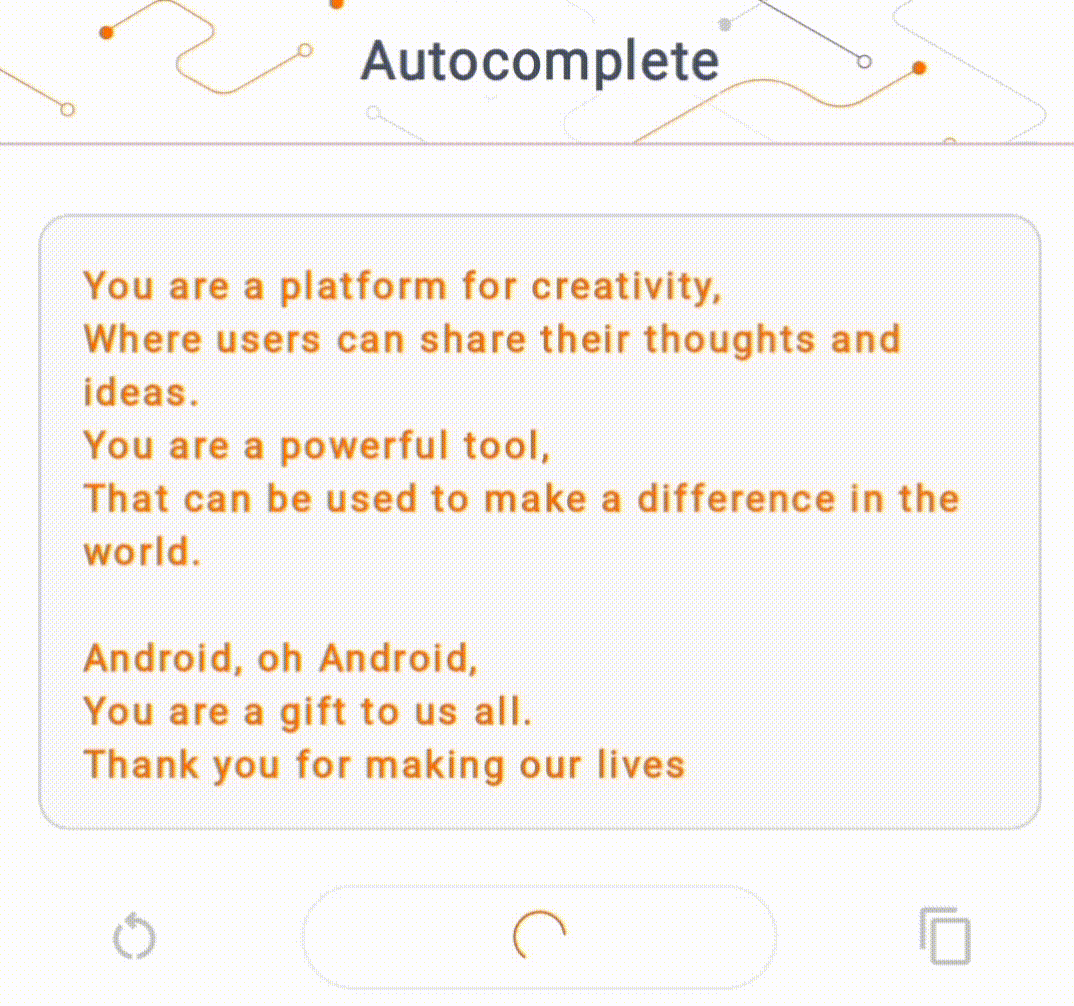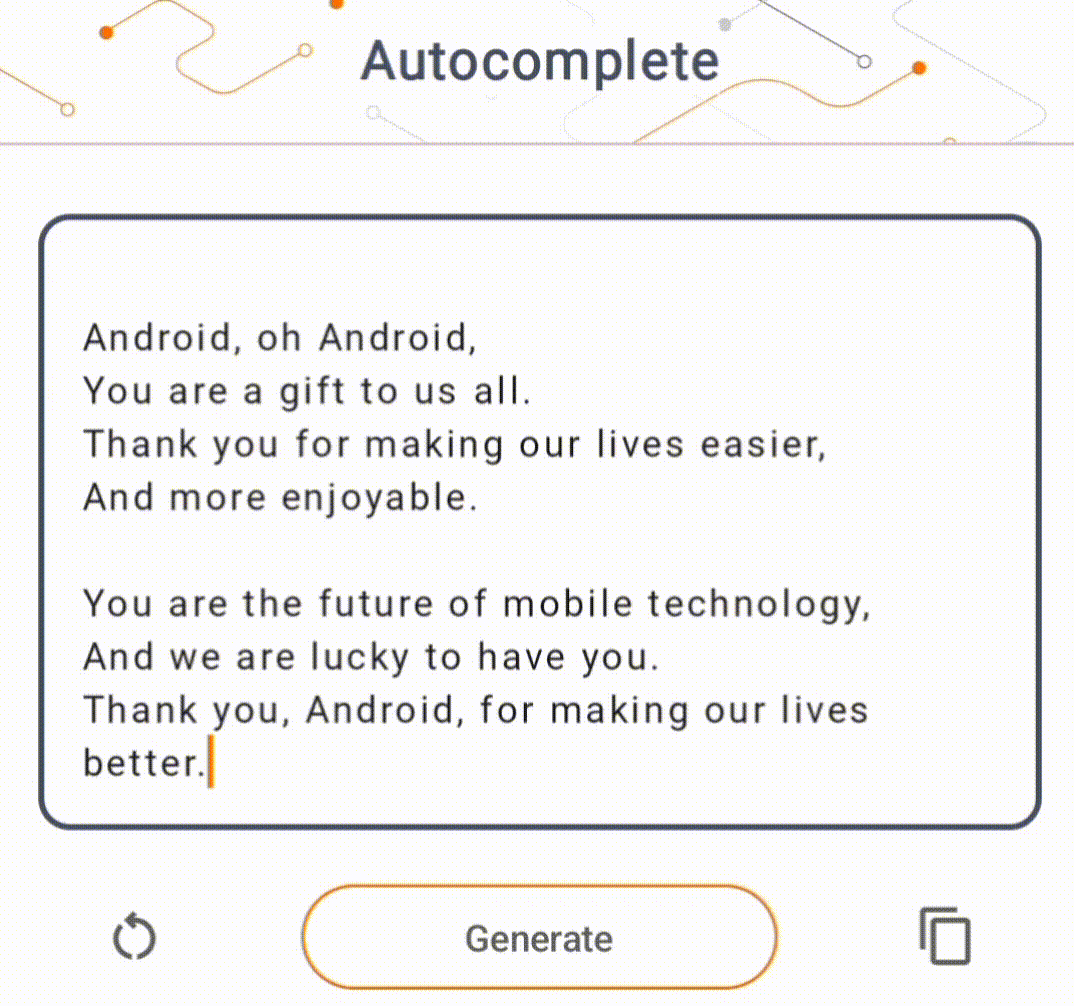
Guide
Creazione di modelli
Per questa dimostrazione utilizzeremo KerasNLP per ottenere il modello GPT-2. KerasNLP è una libreria che contiene modelli preaddestrati all'avanguardia per attività di elaborazione del linguaggio naturale e può supportare gli utenti durante l'intero ciclo di sviluppo. Puoi vedere l'elenco dei modelli disponibili nel repository KerasNLP . I flussi di lavoro sono costruiti da componenti modulari che hanno pesi e architetture preimpostate all'avanguardia quando utilizzati fuori dagli schemi e sono facilmente personalizzabili quando è necessario un maggiore controllo. La creazione del modello GPT-2 può essere eseguita con i seguenti passaggi:
gpt2_tokenizer = keras_nlp.models.GPT2Tokenizer.from_preset("gpt2_base_en")
gpt2_preprocessor = keras_nlp.models.GPT2CausalLMPreprocessor.from_preset(
"gpt2_base_en",
sequence_length=256,
add_end_token=True,
)
gpt2_lm =
keras_nlp.models.GPT2CausalLM.from_preset(
"gpt2_base_en",
preprocessor=gpt2_preprocessor
)
Un punto in comune tra queste tre righe di codice è il metodo from_preset() , che istanzia la parte dell'API Keras da un'architettura e/o pesi preimpostati, caricando quindi il modello pre-addestrato. Da questo frammento di codice noterai anche tre componenti modulari:
Tokenizer : converte un input di stringa grezza in ID token interi adatti per un livello di incorporamento Keras. GPT-2 utilizza specificamente il tokenizzatore di codifica byte-pair (BPE).
Preprocessore : livello per la tokenizzazione e l'imballaggio degli input da inserire in un modello Keras. Qui, il preprocessore riempirà il tensore degli ID token fino a una lunghezza specificata (256) dopo la tokenizzazione.
Backbone : modello Keras che segue l'architettura del backbone del trasformatore SoTA e ha i pesi preimpostati.
Inoltre, puoi controllare l'implementazione completa del modello GPT-2 su GitHub .
Conversione del modello
TensorFlow Lite è una libreria mobile per la distribuzione di metodi su dispositivi mobili, microcontrollori e altri dispositivi edge. Il primo passaggio consiste nel convertire un modello Keras in un formato TensorFlow Lite più compatto utilizzando il convertitore TensorFlow Lite, quindi utilizzare l' interprete TensorFlow Lite, altamente ottimizzato per i dispositivi mobili, per eseguire il modello convertito.
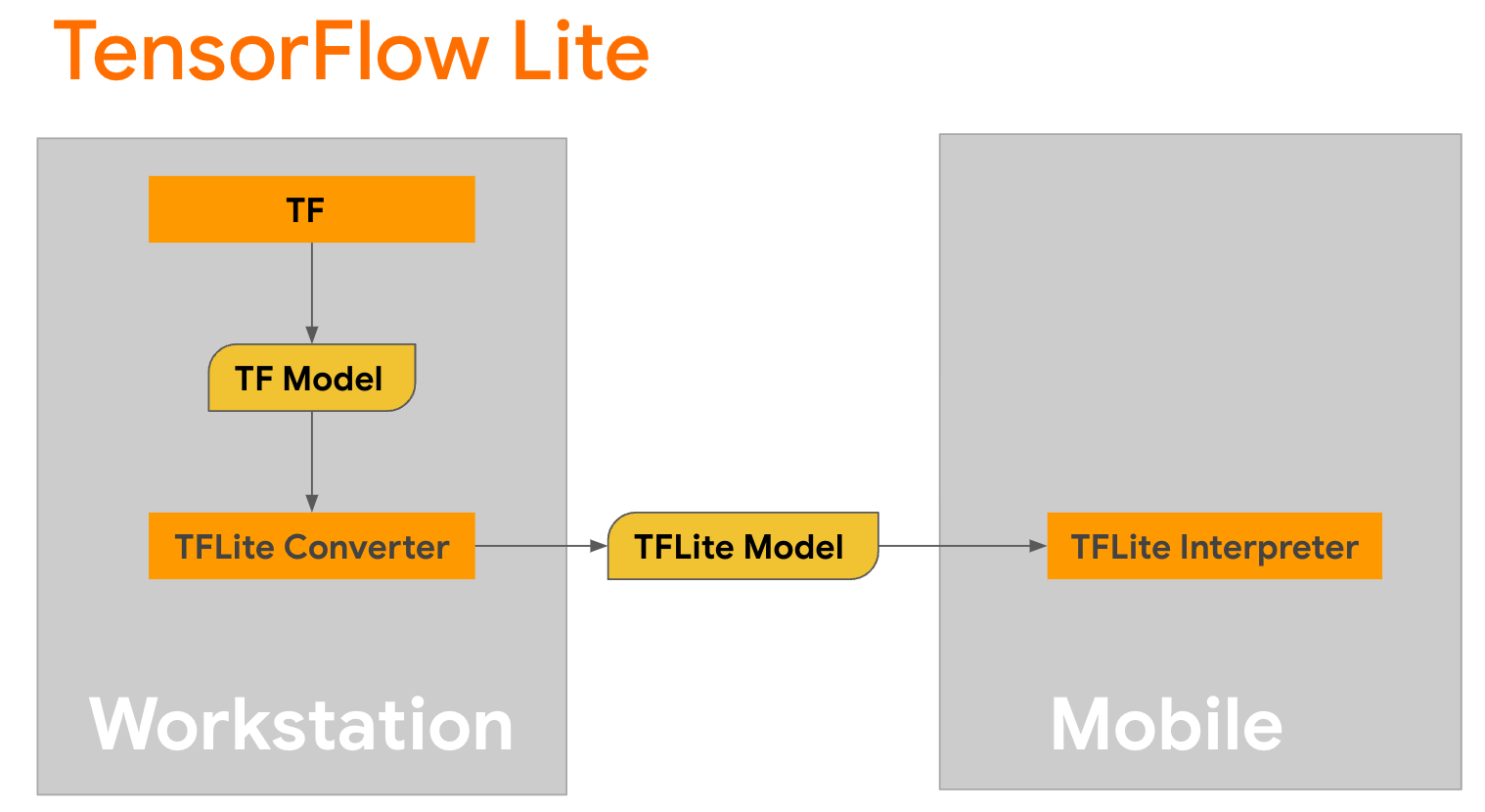 Inizia con la funzione
Inizia con la funzione generate() di GPT2CausalLM che esegue la conversione. Avvolgi la funzione generate() per creare una funzione TensorFlow concreta:
@tf.function
def generate(prompt, max_length):
"""
Args:
prompt: input prompt to the LLM in string format
max_length: the max length of the generated tokens
"""
return gpt2_lm.generate(prompt, max_length)
concrete_func = generate.get_concrete_function(tf.TensorSpec([], tf.string), 100)
Tieni presente che puoi anche utilizzare from_keras_model() da TFLiteConverter per eseguire la conversione.
Ora definisci una funzione helper che eseguirà l'inferenza con un input e un modello TFLite. Le operazioni di testo di TensorFlow non sono operazioni integrate nel runtime TFLite, quindi dovrai aggiungere queste operazioni personalizzate affinché l'interprete possa fare inferenze su questo modello. Questa funzione di supporto accetta un input e una funzione che esegue la conversione, vale a dire la funzione generator() definita sopra.
def run_inference(input, generate_tflite):
interp = interpreter.InterpreterWithCustomOps(
model_content=generate_tflite,
custom_op_registerers=
tf_text.tflite_registrar.SELECT_TFTEXT_OPS
)
interp.get_signature_list()
generator = interp.get_signature_runner('serving_default')
output = generator(prompt=np.array([input]))
Puoi convertire il modello ora:
gpt2_lm.jit_compile = False
converter = tf.lite.TFLiteConverter.from_concrete_functions(
[concrete_func],
gpt2_lm)
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # enable TFLite ops
tf.lite.OpsSet.SELECT_TF_OPS, # enable TF ops
]
converter.allow_custom_ops = True
converter.target_spec.experimental_select_user_tf_ops = [
"UnsortedSegmentJoin",
"UpperBound"
]
converter._experimental_guarantee_all_funcs_one_use = True
generate_tflite = converter.convert()
run_inference("I'm enjoying a", generate_tflite)
Quantizzazione
TensorFlow Lite ha implementato una tecnica di ottimizzazione chiamata quantizzazione che può ridurre le dimensioni del modello e accelerare l'inferenza. Attraverso il processo di quantizzazione, i numeri in virgola mobile a 32 bit vengono mappati su interi più piccoli a 8 bit, riducendo quindi le dimensioni del modello di un fattore 4 per un'esecuzione più efficiente sugli hardware moderni. Esistono diversi modi per eseguire la quantizzazione in TensorFlow. Per ulteriori informazioni, puoi visitare le pagine Ottimizzazione del modello TFLite e Kit di strumenti per l'ottimizzazione del modello TensorFlow . I tipi di quantizzazione sono spiegati brevemente di seguito.
Qui utilizzerai la quantizzazione della gamma dinamica post-allenamento sul modello GPT-2 impostando il flag di ottimizzazione del convertitore su tf.lite.Optimize.DEFAULT e il resto del processo di conversione è lo stesso descritto in precedenza. Abbiamo testato che con questa tecnica di quantizzazione la latenza è di circa 6,7 secondi su Pixel 7 con la lunghezza massima dell'output impostata su 100.
gpt2_lm.jit_compile = False
converter = tf.lite.TFLiteConverter.from_concrete_functions(
[concrete_func],
gpt2_lm)
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # enable TFLite ops
tf.lite.OpsSet.SELECT_TF_OPS, # enable TF ops
]
converter.allow_custom_ops = True
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.experimental_select_user_tf_ops = [
"UnsortedSegmentJoin",
"UpperBound"
]
converter._experimental_guarantee_all_funcs_one_use = True
quant_generate_tflite = converter.convert()
run_inference("I'm enjoying a", quant_generate_tflite)
Gamma dinamica
La quantizzazione della gamma dinamica è il punto di partenza consigliato per ottimizzare i modelli sul dispositivo. Può ottenere una riduzione di circa 4 volte nelle dimensioni del modello ed è un punto di partenza consigliato in quanto fornisce un utilizzo ridotto della memoria e calcoli più rapidi senza dover fornire un set di dati rappresentativo per la calibrazione. Questo tipo di quantizzazione quantizza staticamente solo i pesi da virgola mobile a intero a 8 bit al momento della conversione.
FP16
I modelli a virgola mobile possono anche essere ottimizzati quantizzando i pesi nel tipo float16. I vantaggi della quantizzazione float16 stanno riducendo le dimensioni del modello fino alla metà (poiché tutti i pesi diventano la metà delle loro dimensioni), causando una perdita minima di precisione e supportando i delegati GPU che possono operare direttamente sui dati float16 (il che si traduce in un calcolo più veloce rispetto a float32 dati). Un modello convertito in pesi float16 può comunque essere eseguito sulla CPU senza ulteriori modifiche. I pesi float16 vengono sovracampionati a float32 prima della prima inferenza, il che consente una riduzione delle dimensioni del modello in cambio di un impatto minimo su latenza e precisione.
Quantizzazione intera intera
La quantizzazione intera completa converte i numeri in virgola mobile a 32 bit, inclusi pesi e attivazioni, negli interi a 8 bit più vicini. Questo tipo di quantizzazione si traduce in un modello più piccolo con una maggiore velocità di inferenza, il che è incredibilmente prezioso quando si utilizzano microcontrollori. Questa modalità è consigliata quando le attivazioni sono sensibili alla quantizzazione.
Integrazione dell'app Android
Puoi seguire questo esempio Android per integrare il tuo modello TFLite in un'app Android.
Prerequisiti
Se non l'hai già fatto, installa Android Studio , seguendo le istruzioni sul sito.
- Android Studio 2022.2.1 o versione successiva.
- Un dispositivo Android o un emulatore Android con più di 4G di memoria
Creazione ed esecuzione con Android Studio
- Apri Android Studio e, nella schermata di benvenuto, seleziona Apri un progetto Android Studio esistente .
- Dalla finestra Apri file o progetto visualizzata, individua e seleziona la directory
lite/examples/generative_ai/androiddal punto in cui hai clonato il repository GitHub di esempio TensorFlow Lite. - Potrebbe anche essere necessario installare varie piattaforme e strumenti in base ai messaggi di errore.
- Rinominare il modello .tflite convertito in
autocomplete.tflitee copiarlo nella cartellaapp/src/main/assets/. - Selezionare il menu Compila -> Crea progetto per creare l'app. (Ctrl+F9, a seconda della versione).
- Fare clic sul menu Esegui -> Esegui 'app' . (Maiusc+F10, a seconda della versione)
In alternativa, puoi anche utilizzare il wrapper gradle per crearlo nella riga di comando. Per ulteriori informazioni fare riferimento alla documentazione di Gradle .
(Facoltativo) Creazione del file .aar
Per impostazione predefinita, l'app scarica automaticamente i file .aar necessari. Ma se vuoi crearne uno tuo, passa alla cartella app/libs/build_aar/ run ./build_aar.sh . Questo script inserirà le operazioni necessarie da TensorFlow Text e creerà l'aar per gli operatori Select TF.
Dopo la compilazione, viene generato un nuovo file tftext_tflite_flex.aar . Sostituisci il file .aar nella cartella app/libs/ e ricostruisci l'app.
Tieni presente che devi comunque includere l'aar tensorflow-lite standard nel tuo file Gradle.
Dimensioni della finestra di contesto

L'app ha un parametro modificabile "dimensione della finestra di contesto", necessario perché oggi gli LLM hanno generalmente una dimensione di contesto fissa che limita il numero di parole/token che possono essere inseriti nel modello come "prompt" (si noti che "parola" non è necessariamente equivalente a "token" in questo caso, a causa dei diversi metodi di tokenizzazione). Questo numero è importante perché:
- Impostandolo su un valore troppo piccolo, il modello non avrà contesto sufficiente per generare output significativi
- Impostandolo troppo grande, il modello non avrà abbastanza spazio su cui lavorare (poiché la sequenza di output include il prompt)
Puoi sperimentarlo, ma impostarlo su circa il 50% della lunghezza della sequenza di output è un buon inizio.
Sicurezza e IA responsabile
Come notato nell'annuncio originale di OpenAI GPT-2 , ci sono notevoli avvertenze e limitazioni con il modello GPT-2. In effetti, gli LLM oggi presentano generalmente alcune sfide ben note come allucinazioni, equità e pregiudizi; questo perché questi modelli sono addestrati su dati del mondo reale, che li fanno riflettere le questioni del mondo reale.
Questo codelab viene creato solo per dimostrare come creare un'app basata su LLM con gli strumenti TensorFlow. Il modello prodotto in questo codelab è solo a scopo didattico e non è destinato all'uso in produzione.
L'utilizzo della produzione LLM richiede un'attenta selezione dei set di dati di addestramento e misure di sicurezza complete. Una di queste funzionalità offerte in questa app Android è il filtro volgarità, che rifiuta input errati dell'utente o output del modello. Se viene rilevato un linguaggio inappropriato, l'app in cambio rifiuterà tale azione. Per saperne di più sull'intelligenza artificiale responsabile nel contesto dei LLM, assicurati di guardare la sessione tecnica Sviluppo sicuro e responsabile con modelli linguistici generativi al Google I/O 2023 e dai un'occhiata al Responsible AI Toolkit .