
| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub |
Персонализированные рекомендации широко используются для различных случаев использования на мобильных устройствах, таких как поиск медиаконтента, предложение продуктов для покупок и рекомендации следующего приложения. Если вы заинтересованы в предоставлении персонализированных рекомендаций в своем приложении при соблюдении конфиденциальности пользователей, мы рекомендуем изучить следующий пример и набор инструментов.
Начать
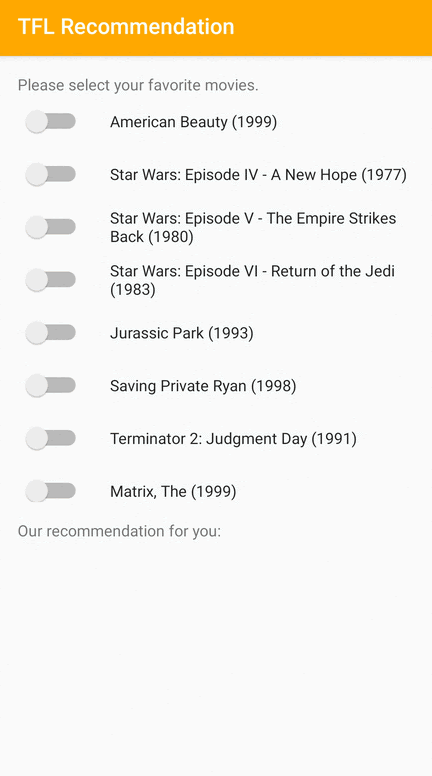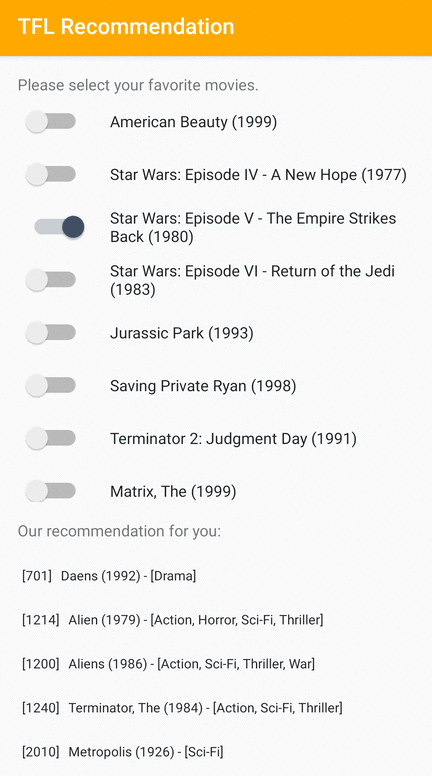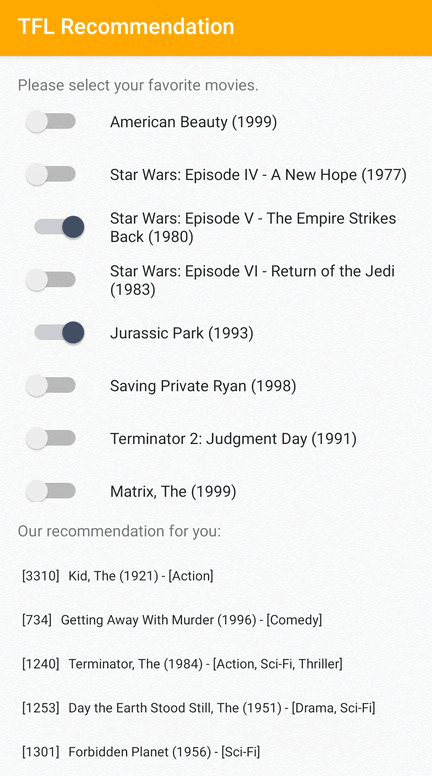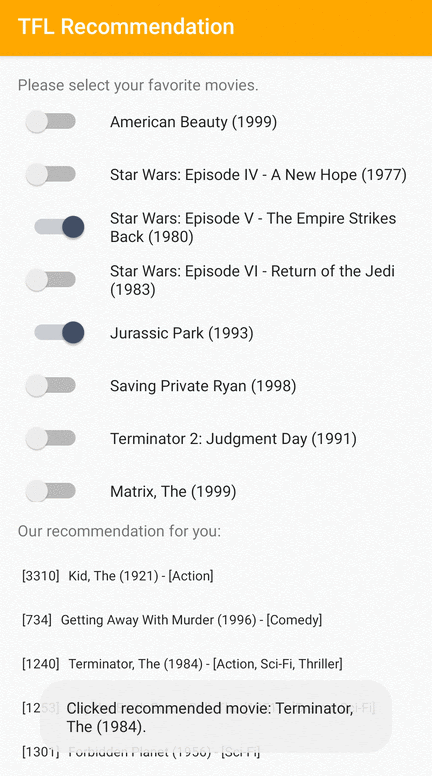
Мы предоставляем образец приложения TensorFlow Lite, который демонстрирует, как рекомендовать подходящие элементы пользователям Android.
Если вы используете платформу, отличную от Android, или уже знакомы с API-интерфейсами TensorFlow Lite, вы можете загрузить нашу модель рекомендаций для начинающих.
Мы также предоставляем сценарий обучения на Github для обучения вашей собственной модели настраиваемым способом.
Понимание архитектуры модели
Мы используем архитектуру модели с двойным кодировщиком: кодировщик контекста для кодирования последовательной истории пользователей и кодировщик меток для кодирования прогнозируемого кандидата на рекомендации. Сходство между кодировками контекста и метки используется для представления вероятности того, что прогнозируемый кандидат соответствует потребностям пользователя.
В этой базе кода предусмотрены три различных метода последовательного кодирования истории пользователя:
- Кодер пакетов слов (BOW): усреднение вложений действий пользователя без учета порядка контекста.
- Кодер сверточной нейронной сети (CNN): применение нескольких слоев сверточных нейронных сетей для генерации кодирования контекста.
- Кодер рекуррентной нейронной сети (RNN): применение рекуррентной нейронной сети для кодирования контекстной последовательности.
Чтобы смоделировать каждое действие пользователя, мы могли бы использовать идентификатор элемента действия (на основе идентификатора), или несколько функций элемента (на основе функций), или комбинацию того и другого. Модель, основанная на функциях, использующая несколько функций для коллективного кодирования поведения пользователей. С помощью этой базы кода вы можете создавать модели на основе идентификаторов или функций с возможностью настройки.
После обучения будет экспортирована модель TensorFlow Lite, которая может напрямую предоставлять прогнозы Top-K среди кандидатов на рекомендации.
Используйте свои тренировочные данные
В дополнение к обученной модели мы предоставляем набор инструментов с открытым исходным кодом на GitHub для обучения моделей с использованием ваших собственных данных. Вы можете следовать этому руководству, чтобы узнать, как использовать набор инструментов и развертывать обученные модели в своих собственных мобильных приложениях.
Следуйте этому руководству , чтобы применить ту же технику, что и здесь, для обучения модели рекомендаций с использованием ваших собственных наборов данных.
Примеры
В качестве примера мы обучили модели рекомендаций с использованием подходов, основанных как на идентификаторах, так и на основе функций. Модель на основе идентификаторов принимает в качестве входных данных только идентификаторы фильмов, а модель на основе функций принимает в качестве входных данных как идентификаторы фильмов, так и идентификаторы жанров фильмов. Ниже приведены примеры входных и выходных данных.
Входы
Идентификаторы контекстных фильмов:
- Король Лев (ID: 362)
- История игрушек (ID: 1)
- (и более)
Контекстные идентификаторы жанров фильмов:
- Анимация (ID: 15)
- Детский (ID: 9)
- Мюзикл (ID: 13)
- Анимация (ID: 15)
- Детский (ID: 9)
- Комедия (ID: 2)
- (и более)
Выходы:
- Рекомендуемые идентификаторы фильмов:
- История игрушек 2 (ID: 3114)
- (и более)
Тесты производительности
Показатели производительности генерируются с помощью инструмента, описанного здесь .
| Название модели | Размер модели | Устройство | Процессор |
|---|---|---|---|
| рекомендация (идентификатор фильма в качестве входных данных) | 0,52 Мб | Пиксель 3 | 0,09 мс* |
| Пиксель 4 | 0,05 мс* | ||
| рекомендация (идентификатор фильма и жанр фильма в качестве входных данных) | 1,3 Мб | Пиксель 3 | 0,13 мс* |
| Пиксель 4 | 0,06 мс* |
* Использовано 4 нити.
Используйте свои тренировочные данные
В дополнение к обученной модели мы предоставляем набор инструментов с открытым исходным кодом на GitHub для обучения моделей с использованием ваших собственных данных. Вы можете следовать этому руководству, чтобы узнать, как использовать набор инструментов и развертывать обученные модели в своих собственных мобильных приложениях.
Следуйте этому руководству , чтобы применить ту же технику, что и здесь, для обучения модели рекомендаций с использованием ваших собственных наборов данных.
Советы по настройке модели с использованием ваших данных
Предварительно обученная модель, интегрированная в это демонстрационное приложение, обучена с помощью набора данных MovieLens . Возможно, вы захотите изменить конфигурацию модели на основе ваших собственных данных, таких как размер словарного запаса, встроенные затемнения и длина входного контекста. Вот несколько советов:
Длина входного контекста: оптимальная длина входного контекста зависит от наборов данных. Мы предлагаем выбирать длину входного контекста на основе того, насколько события метки коррелируют с долгосрочными интересами по сравнению с краткосрочным контекстом.
Выбор типа кодировщика: мы предлагаем выбирать тип кодировщика на основе длины входного контекста. Кодер пакета слов хорошо работает для короткой длины входного контекста (например, <10), кодеры CNN и RNN обеспечивают больше возможностей суммирования для большой длины входного контекста.
Использование базовых функций для представления элементов или действий пользователя может улучшить производительность модели, лучше разместить новые элементы, возможно, уменьшить масштаб пространства для встраивания, следовательно, уменьшить потребление памяти и сделать ее более удобной для использования на устройстве.