
| | |  Xem nguồn trên GitHub Xem nguồn trên GitHub |
Đề xuất được cá nhân hóa được sử dụng rộng rãi cho nhiều trường hợp sử dụng khác nhau trên thiết bị di động, chẳng hạn như truy xuất nội dung phương tiện, đề xuất sản phẩm mua sắm và đề xuất ứng dụng tiếp theo. Nếu bạn quan tâm đến việc cung cấp các đề xuất được cá nhân hóa trong ứng dụng của mình mà vẫn tôn trọng quyền riêng tư của người dùng, chúng tôi khuyên bạn nên khám phá ví dụ và bộ công cụ sau.
Bắt đầu
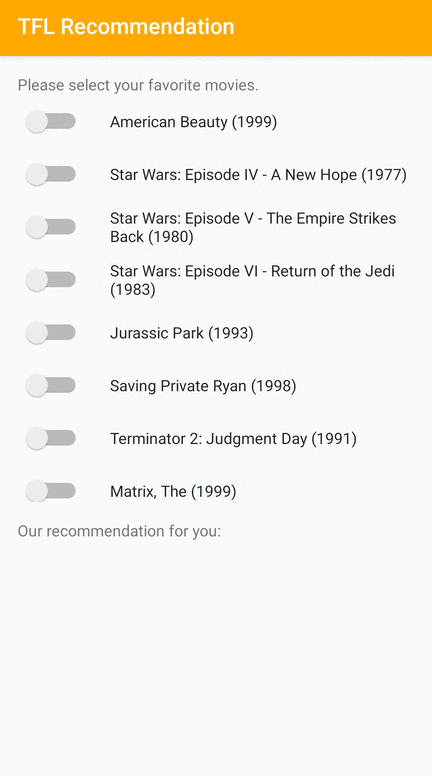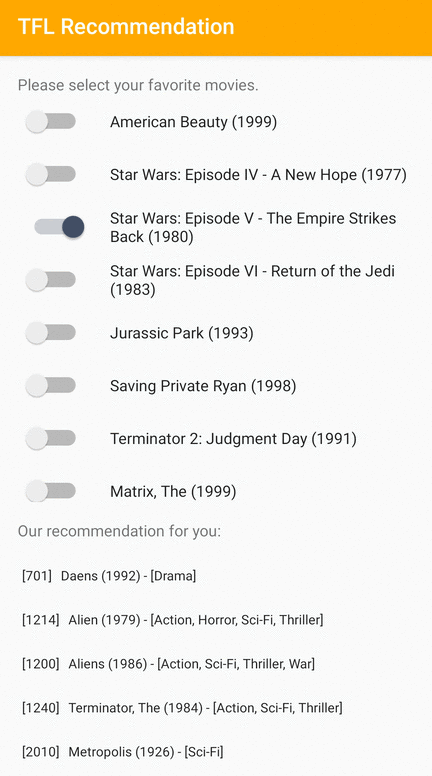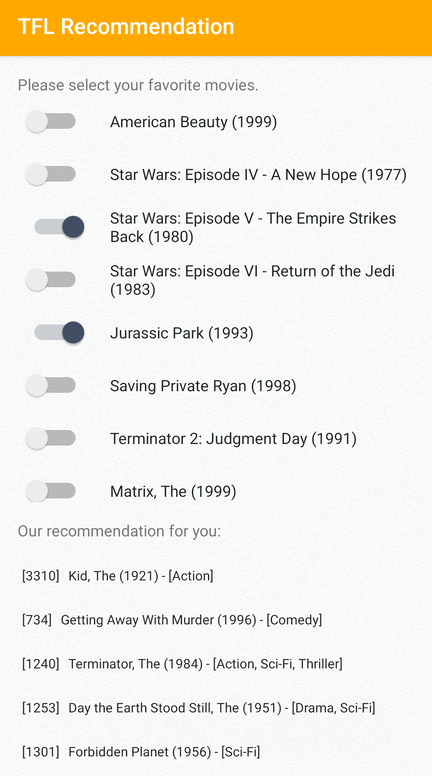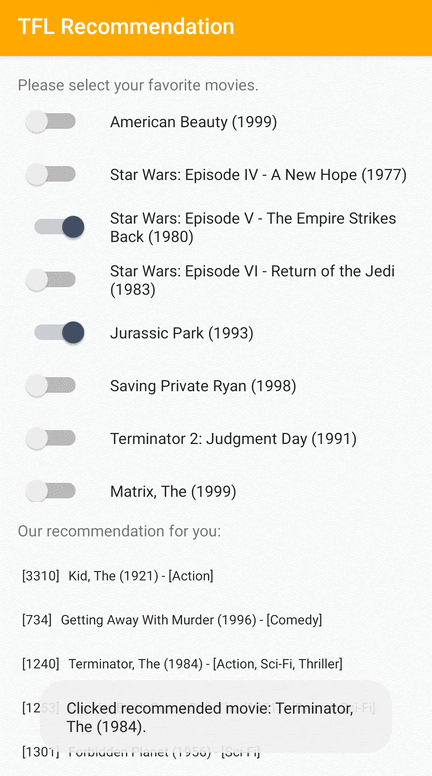
Chúng tôi cung cấp ứng dụng mẫu TensorFlow Lite trình bày cách đề xuất các mục có liên quan cho người dùng trên Android.
Nếu bạn đang sử dụng nền tảng không phải Android hoặc đã quen với API TensorFlow Lite, bạn có thể tải xuống mô hình đề xuất ban đầu của chúng tôi.
Chúng tôi cũng cung cấp tập lệnh đào tạo trong Github để đào tạo mô hình của riêng bạn theo cách có thể định cấu hình.
Tìm hiểu kiến trúc mô hình
Chúng tôi tận dụng kiến trúc mô hình bộ mã hóa kép, với bộ mã hóa ngữ cảnh để mã hóa lịch sử người dùng tuần tự và bộ mã hóa nhãn để mã hóa ứng cử viên đề xuất được dự đoán. Sự giống nhau giữa mã hóa ngữ cảnh và nhãn được sử dụng để thể hiện khả năng ứng viên được dự đoán đáp ứng nhu cầu của người dùng.
Ba kỹ thuật mã hóa lịch sử người dùng tuần tự khác nhau được cung cấp cùng với cơ sở mã này:
- Bộ mã hóa túi từ (BOW): tính trung bình các phần nhúng của hoạt động của người dùng mà không xem xét thứ tự ngữ cảnh.
- Bộ mã hóa mạng thần kinh tích chập (CNN): áp dụng nhiều lớp mạng thần kinh tích chập để tạo mã hóa ngữ cảnh.
- Bộ mã hóa mạng thần kinh tái phát (RNN): ứng dụng mạng thần kinh tái phát để mã hóa chuỗi ngữ cảnh.
Để mô hình hóa từng hoạt động của người dùng, chúng tôi có thể sử dụng ID của mục hoạt động (dựa trên ID) hoặc nhiều tính năng của mục đó (dựa trên tính năng) hoặc kết hợp cả hai. Mô hình dựa trên tính năng sử dụng nhiều tính năng để mã hóa chung hành vi của người dùng. Với cơ sở mã này, bạn có thể tạo các mô hình dựa trên ID hoặc dựa trên tính năng theo cách có thể định cấu hình.
Sau khi đào tạo, một mô hình TensorFlow Lite sẽ được xuất ra để có thể trực tiếp đưa ra dự đoán top-K trong số các ứng cử viên được đề xuất.
Sử dụng dữ liệu đào tạo của bạn
Ngoài mô hình được đào tạo, chúng tôi còn cung cấp bộ công cụ nguồn mở trong GitHub để đào tạo các mô hình bằng dữ liệu của riêng bạn. Bạn có thể làm theo hướng dẫn này để tìm hiểu cách sử dụng bộ công cụ và triển khai các mô hình đã đào tạo trong ứng dụng di động của riêng bạn.
Vui lòng làm theo hướng dẫn này để áp dụng kỹ thuật tương tự được sử dụng ở đây để đào tạo mô hình đề xuất bằng cách sử dụng bộ dữ liệu của riêng bạn.
Ví dụ
Ví dụ: chúng tôi đã đào tạo các mô hình đề xuất bằng cả cách tiếp cận dựa trên ID và dựa trên tính năng. Mô hình dựa trên ID chỉ lấy ID phim làm đầu vào và mô hình dựa trên tính năng lấy cả ID phim và ID thể loại phim làm đầu vào. Vui lòng tìm các ví dụ đầu vào và đầu ra sau đây.
Đầu vào
ID phim ngữ cảnh:
- Vua Sư Tử (ID: 362)
- Câu chuyện đồ chơi (ID: 1)
- (và hơn thế nữa)
ID thể loại phim theo ngữ cảnh:
- Hoạt hình (ID: 15)
- Trẻ em (ID: 9)
- Âm nhạc (ID: 13)
- Hoạt hình (ID: 15)
- Trẻ em (ID: 9)
- Hài kịch (ID: 2)
- (và hơn thế nữa)
Đầu ra:
- ID phim được đề xuất:
- Câu Chuyện Đồ Chơi 2 (ID: 3114)
- (và hơn thế nữa)
Điểm chuẩn hiệu suất
Số điểm chuẩn hiệu suất được tạo bằng công cụ được mô tả ở đây .
| Tên mẫu | Kích thước mô hình | Thiết bị | CPU |
|---|---|---|---|
| đề xuất (ID phim làm đầu vào) | 0,52 Mb | Pixel 3 | 0,09 mili giây* |
| Pixel 4 | 0,05 mili giây* | ||
| đề xuất (ID phim và thể loại phim làm đầu vào) | 1,3 Mb | Pixel 3 | 0,13 mili giây* |
| Pixel 4 | 0,06 mili giây* |
* 4 chủ đề được sử dụng.
Sử dụng dữ liệu đào tạo của bạn
Ngoài mô hình được đào tạo, chúng tôi còn cung cấp bộ công cụ nguồn mở trong GitHub để đào tạo các mô hình bằng dữ liệu của riêng bạn. Bạn có thể làm theo hướng dẫn này để tìm hiểu cách sử dụng bộ công cụ và triển khai các mô hình đã đào tạo trong ứng dụng di động của riêng bạn.
Vui lòng làm theo hướng dẫn này để áp dụng kỹ thuật tương tự được sử dụng ở đây để đào tạo mô hình đề xuất bằng cách sử dụng bộ dữ liệu của riêng bạn.
Mẹo để tùy chỉnh mô hình với dữ liệu của bạn
Mô hình được đào tạo trước được tích hợp trong ứng dụng demo này được đào tạo bằng tập dữ liệu MovieLens , bạn có thể muốn sửa đổi cấu hình mô hình dựa trên dữ liệu của riêng mình, chẳng hạn như kích thước từ vựng, độ mờ nhúng và độ dài ngữ cảnh đầu vào. Dưới đây là một vài lời khuyên:
Độ dài ngữ cảnh đầu vào: Độ dài ngữ cảnh đầu vào tốt nhất thay đổi tùy theo tập dữ liệu. Chúng tôi khuyên bạn nên chọn độ dài ngữ cảnh đầu vào dựa trên mức độ tương quan giữa các sự kiện nhãn với sở thích dài hạn và bối cảnh ngắn hạn.
Lựa chọn loại bộ mã hóa: chúng tôi khuyên bạn nên chọn loại bộ mã hóa dựa trên độ dài ngữ cảnh đầu vào. Bộ mã hóa túi từ hoạt động tốt với độ dài ngữ cảnh đầu vào ngắn (ví dụ <10), bộ mã hóa CNN và RNN mang lại khả năng tóm tắt nhiều hơn cho độ dài ngữ cảnh đầu vào dài.
Việc sử dụng các tính năng cơ bản để thể hiện các mục hoặc hoạt động của người dùng có thể cải thiện hiệu suất mô hình, phù hợp hơn với các mục mới, có thể giảm không gian nhúng quy mô, do đó giảm mức tiêu thụ bộ nhớ và thân thiện hơn trên thiết bị.