
| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub |
توصیههای شخصیشده بهطور گسترده برای موارد مختلف در دستگاههای تلفن همراه، مانند بازیابی محتوای رسانه، پیشنهاد محصول خرید و توصیه برنامه بعدی، استفاده میشوند. اگر علاقه مند به ارائه توصیه های شخصی در برنامه خود با رعایت حریم خصوصی کاربر هستید، توصیه می کنیم نمونه و جعبه ابزار زیر را بررسی کنید.
شروع کنید
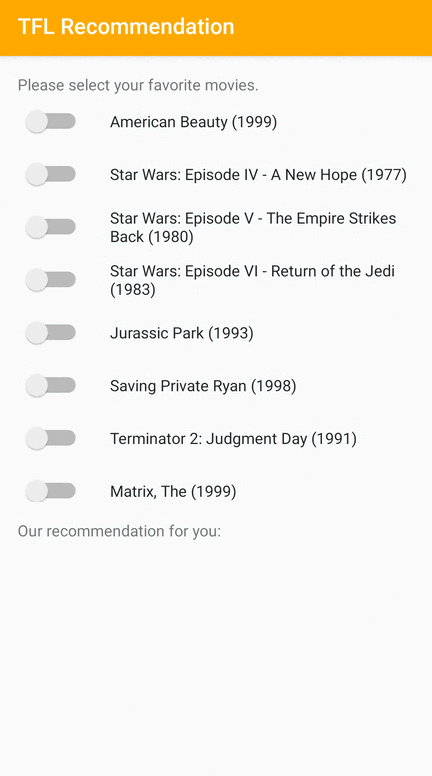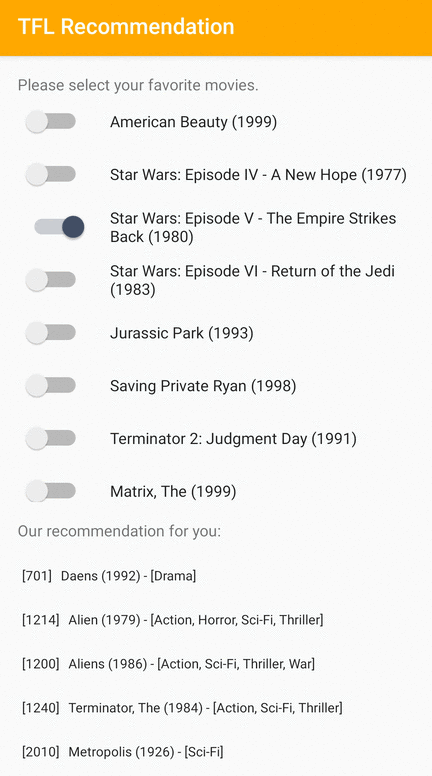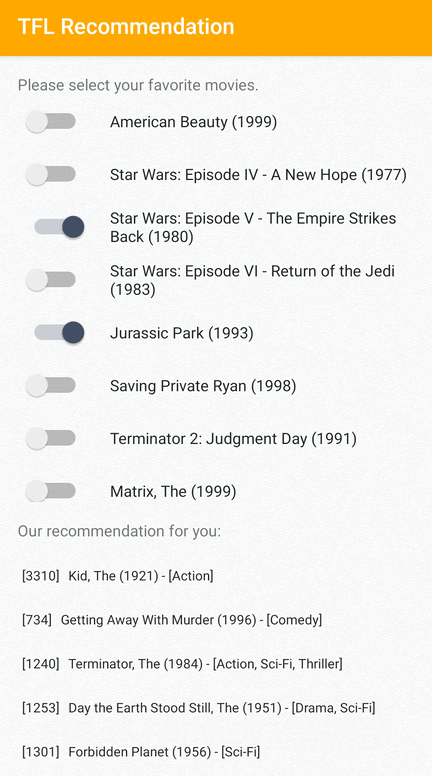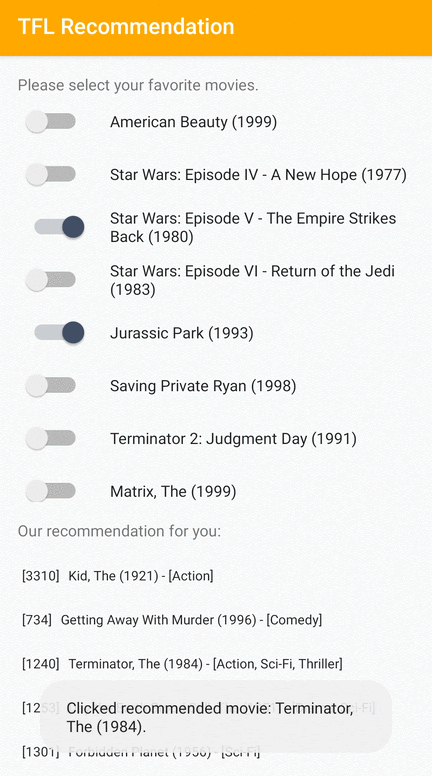
ما یک نمونه برنامه TensorFlow Lite ارائه می دهیم که نشان می دهد چگونه موارد مرتبط را در Android به کاربران توصیه کنیم.
اگر از پلتفرمی غیر از اندروید استفاده میکنید، یا از قبل با APIهای TensorFlow Lite آشنا هستید، میتوانید مدل پیشنهادی استارت ما را دانلود کنید.
ما همچنین اسکریپت آموزشی را در Github ارائه می دهیم تا مدل خود را به روشی قابل تنظیم آموزش دهید.
معماری مدل را درک کنید
ما از معماری مدل رمزگذار دوگانه استفاده میکنیم، با متن-رمز برای رمزگذاری تاریخچه کاربر متوالی و رمزگذار برچسب برای رمزگذاری نامزد پیشنهادی پیشبینیشده. شباهت بین متن و رمزگذاری برچسب برای نشان دادن احتمال برآورده شدن نیازهای کاربر توسط نامزد پیش بینی شده استفاده می شود.
سه تکنیک مختلف رمزگذاری تاریخچه کاربری متوالی با این پایه کد ارائه شده است:
- رمزگذار بسته کلمات (BOW): میانگینگیری تعبیههای فعالیتهای کاربر بدون در نظر گرفتن ترتیب بافت.
- رمزگذار شبکه عصبی کانولوشن (CNN): استفاده از چندین لایه از شبکه های عصبی کانولوشن برای تولید رمزگذاری زمینه.
- رمزگذار شبکه عصبی بازگشتی (RNN): استفاده از شبکه عصبی بازگشتی برای رمزگذاری توالی زمینه.
برای مدلسازی هر فعالیت کاربر، میتوانیم از شناسه مورد فعالیت (مبتنی بر شناسه)، یا چندین ویژگی مورد (مبتنی بر ویژگی)، یا ترکیبی از هر دو استفاده کنیم. مدل مبتنی بر ویژگی با استفاده از ویژگیهای متعدد برای رمزگذاری رفتار کاربران. با این پایه کد، می توانید مدل های مبتنی بر شناسه یا مبتنی بر ویژگی را به روشی قابل تنظیم ایجاد کنید.
پس از آموزش، یک مدل TensorFlow Lite صادر میشود که میتواند مستقیماً پیشبینیهای K بالا را در میان نامزدهای پیشنهادی ارائه دهد.
از داده های آموزشی خود استفاده کنید
علاوه بر مدل آموزشدیده، ما یک جعبه ابزار منبع باز در GitHub برای آموزش مدلها با دادههای خودتان ارائه میکنیم. می توانید این آموزش را دنبال کنید تا نحوه استفاده از جعبه ابزار و استقرار مدل های آموزش دیده را در برنامه های تلفن همراه خود بیاموزید.
لطفاً این آموزش را دنبال کنید تا از همان تکنیک استفاده شده در اینجا برای آموزش یک مدل توصیه با استفاده از مجموعه داده های خود استفاده کنید.
مثال ها
به عنوان نمونه، ما مدلهای توصیه را با رویکردهای مبتنی بر ID و مبتنی بر ویژگی آموزش دادیم. مدل مبتنی بر ID فقط شناسه های فیلم را به عنوان ورودی می گیرد و مدل مبتنی بر ویژگی هم شناسه فیلم و هم شناسه ژانر فیلم را به عنوان ورودی می گیرد. لطفاً نمونه های ورودی و خروجی زیر را بیابید.
ورودی ها
شناسه های فیلم زمینه:
- شیر شاه (ID: 362)
- داستان اسباب بازی (ID: 1)
- (و بیشتر)
شناسه های ژانر فیلم زمینه:
- انیمیشن (ID: 15)
- کودکان (ID: 9)
- موزیکال (ID: 13)
- انیمیشن (ID: 15)
- کودکان (ID: 9)
- کمدی (ID: 2)
- (و بیشتر)
خروجی ها:
- شناسه های پیشنهادی فیلم:
- داستان اسباب بازی 2 (ID: 3114)
- (و بیشتر)
معیارهای عملکرد
اعداد معیار عملکرد با ابزار توضیح داده شده در اینجا تولید می شوند.
| نام مدل | سایز مدل | دستگاه | CPU |
|---|---|---|---|
| توصیه (شناسه فیلم به عنوان ورودی) | 0.52 مگابایت | پیکسل 3 | 0.09 میلیثانیه* |
| پیکسل 4 | 0.05 میلیثانیه* | ||
| توصیه (شناسه فیلم و ژانر فیلم به عنوان ورودی) | 1.3 مگابایت | پیکسل 3 | 0.13 میلیثانیه* |
| پیکسل 4 | 0.06 میلیثانیه* |
* 4 نخ استفاده شده است.
از داده های آموزشی خود استفاده کنید
علاوه بر مدل آموزشدیده، ما یک جعبه ابزار منبع باز در GitHub برای آموزش مدلها با دادههای خودتان ارائه میکنیم. می توانید این آموزش را دنبال کنید تا نحوه استفاده از جعبه ابزار و استقرار مدل های آموزش دیده را در برنامه های تلفن همراه خود بیاموزید.
لطفاً این آموزش را دنبال کنید تا از همان تکنیک استفاده شده در اینجا برای آموزش یک مدل توصیه با استفاده از مجموعه داده های خود استفاده کنید.
نکاتی برای سفارشی سازی مدل با داده های شما
مدل از پیش آموزش دیده ادغام شده در این برنامه آزمایشی با مجموعه داده MovieLens آموزش داده شده است، ممکن است بخواهید پیکربندی مدل را بر اساس داده های خود، مانند اندازه vocab، تعبیه کم نور و طول متن ورودی تغییر دهید. اینجا نکاتی وجود دارد:
طول متن ورودی: بهترین طول زمینه ورودی با مجموعه داده ها متفاوت است. پیشنهاد میکنیم طول بافت ورودی را بر اساس میزان ارتباط رویدادهای برچسب با علایق بلندمدت در مقابل زمینه کوتاهمدت انتخاب کنید.
انتخاب نوع رمزگذار: پیشنهاد می کنیم نوع رمزگذار را بر اساس طول زمینه ورودی انتخاب کنید. رمزگذار کیسه کلمات برای طول متن ورودی کوتاه (به عنوان مثال <10) به خوبی کار می کند، رمزگذارهای CNN و RNN توانایی خلاصه سازی بیشتری را برای طول متن ورودی طولانی به ارمغان می آورند.
استفاده از ویژگیهای زیربنایی برای نمایش اقلام یا فعالیتهای کاربر میتواند عملکرد مدل را بهبود بخشد، آیتمهای تازه را بهتر در خود جای دهد، احتمالاً فضاهای تعبیهشده را کاهش دهد، بنابراین مصرف حافظه را کاهش میدهد و سازگاری بیشتری با دستگاه دارد.