
| | |  GitHub पर स्रोत देखें GitHub पर स्रोत देखें |
वैयक्तिकृत अनुशंसाओं का व्यापक रूप से मोबाइल उपकरणों पर विभिन्न उपयोग के मामलों के लिए उपयोग किया जाता है, जैसे मीडिया सामग्री पुनर्प्राप्ति, खरीदारी उत्पाद सुझाव और अगले ऐप अनुशंसा। यदि आप उपयोगकर्ता की गोपनीयता का सम्मान करते हुए अपने एप्लिकेशन में वैयक्तिकृत अनुशंसाएँ प्रदान करने में रुचि रखते हैं, तो हम निम्नलिखित उदाहरण और टूलकिट की खोज करने की सलाह देते हैं।
शुरू हो जाओ
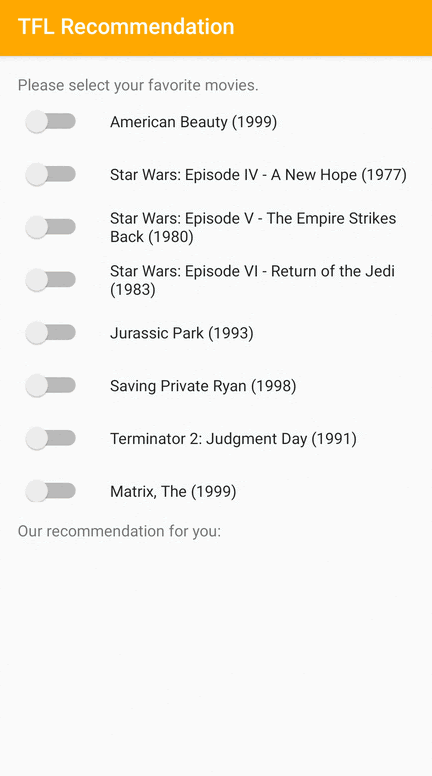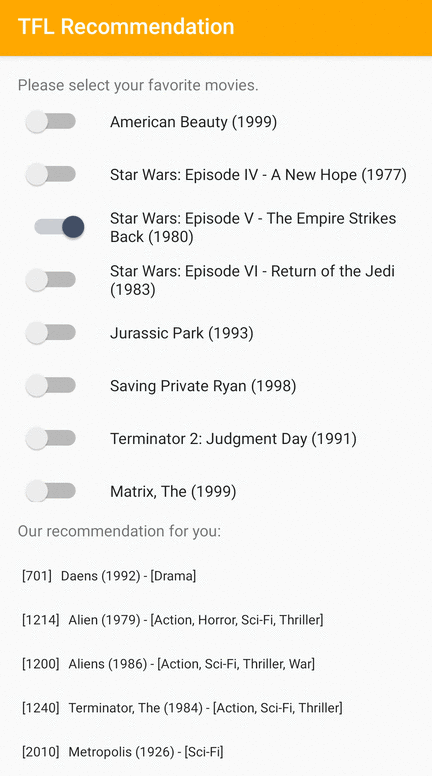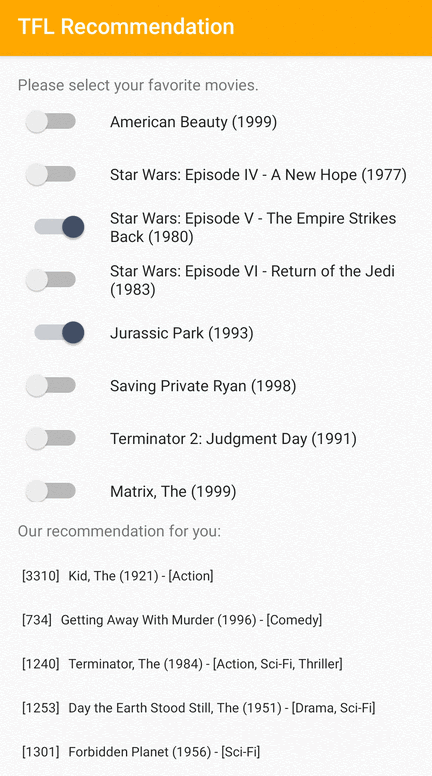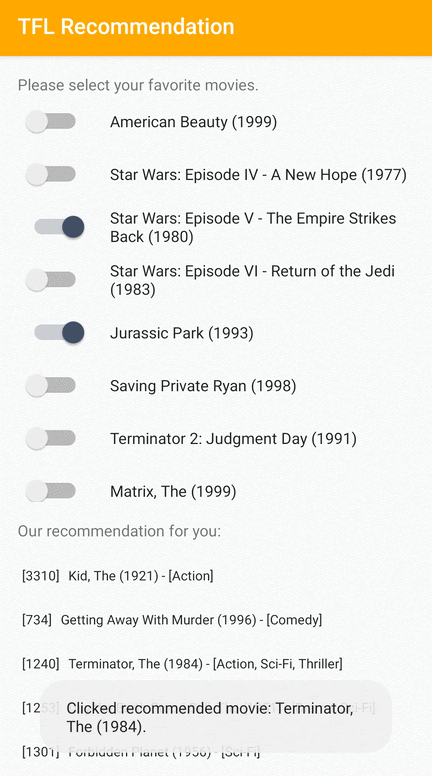
हम एक TensorFlow Lite नमूना एप्लिकेशन प्रदान करते हैं जो दर्शाता है कि Android पर उपयोगकर्ताओं को प्रासंगिक आइटम की अनुशंसा कैसे की जाए।
यदि आप Android के अलावा किसी अन्य प्लेटफ़ॉर्म का उपयोग कर रहे हैं, या आप पहले से ही TensorFlow Lite API से परिचित हैं, तो आप हमारे स्टार्टर अनुशंसा मॉडल को डाउनलोड कर सकते हैं।
हम आपके स्वयं के मॉडल को कॉन्फ़िगर करने योग्य तरीके से प्रशिक्षित करने के लिए जीथब में प्रशिक्षण स्क्रिप्ट भी प्रदान करते हैं।
मॉडल आर्किटेक्चर को समझें
हम दोहरे-एनकोडर मॉडल आर्किटेक्चर का लाभ उठाते हैं, अनुक्रमिक उपयोगकर्ता इतिहास को एनकोड करने के लिए संदर्भ-एनकोडर और अनुमानित अनुशंसा उम्मीदवार को एनकोड करने के लिए लेबल-एनकोडर का उपयोग करते हैं। संदर्भ और लेबल एन्कोडिंग के बीच समानता का उपयोग इस संभावना को दर्शाने के लिए किया जाता है कि अनुमानित उम्मीदवार उपयोगकर्ता की आवश्यकताओं को पूरा करता है।
इस कोड आधार के साथ तीन अलग-अलग अनुक्रमिक उपयोगकर्ता इतिहास एन्कोडिंग तकनीकें प्रदान की जाती हैं:
- बैग-ऑफ-वर्ड्स एनकोडर (बीओडब्ल्यू): संदर्भ क्रम पर विचार किए बिना उपयोगकर्ता गतिविधियों की एम्बेडिंग का औसत।
- कन्वेन्शनल न्यूरल नेटवर्क एनकोडर (सीएनएन): संदर्भ एन्कोडिंग उत्पन्न करने के लिए कन्वेन्शनल न्यूरल नेटवर्क की कई परतों को लागू करना।
- आवर्तक तंत्रिका नेटवर्क एनकोडर (आरएनएन): संदर्भ अनुक्रम को एन्कोड करने के लिए आवर्तक तंत्रिका नेटवर्क को लागू करना।
प्रत्येक उपयोगकर्ता गतिविधि को मॉडल करने के लिए, हम गतिविधि आइटम की आईडी (आईडी-आधारित), या आइटम की कई विशेषताओं (सुविधा-आधारित), या दोनों के संयोजन का उपयोग कर सकते हैं। फीचर-आधारित मॉडल उपयोगकर्ताओं के व्यवहार को सामूहिक रूप से एन्कोड करने के लिए कई सुविधाओं का उपयोग करता है। इस कोड आधार के साथ, आप कॉन्फ़िगर करने योग्य तरीके से आईडी-आधारित या फीचर-आधारित मॉडल बना सकते हैं।
प्रशिक्षण के बाद, एक TensorFlow Lite मॉडल निर्यात किया जाएगा जो अनुशंसित उम्मीदवारों के बीच सीधे शीर्ष-K पूर्वानुमान प्रदान कर सकता है।
अपने प्रशिक्षण डेटा का उपयोग करें
प्रशिक्षित मॉडल के अलावा, हम आपके अपने डेटा के साथ मॉडल को प्रशिक्षित करने के लिए GitHub में एक ओपन-सोर्स टूलकिट प्रदान करते हैं। टूलकिट का उपयोग कैसे करें और अपने मोबाइल एप्लिकेशन में प्रशिक्षित मॉडल कैसे तैनात करें, यह जानने के लिए आप इस ट्यूटोरियल का अनुसरण कर सकते हैं।
अपने स्वयं के डेटासेट का उपयोग करके अनुशंसा मॉडल को प्रशिक्षित करने के लिए यहां उपयोग की जाने वाली उसी तकनीक को लागू करने के लिए कृपया इस ट्यूटोरियल का पालन करें।
उदाहरण
उदाहरण के तौर पर, हमने आईडी-आधारित और फीचर-आधारित दोनों दृष्टिकोणों के साथ अनुशंसा मॉडल को प्रशिक्षित किया। आईडी-आधारित मॉडल केवल मूवी आईडी को इनपुट के रूप में लेता है, और फीचर-आधारित मॉडल मूवी आईडी और मूवी शैली आईडी दोनों को इनपुट के रूप में लेता है। कृपया निम्नलिखित इनपुट और आउटपुट उदाहरण ढूंढें।
इनपुट
प्रसंग मूवी आईडी:
- द लायन किंग (आईडी: 362)
- टॉय स्टोरी (आईडी: 1)
- (और अधिक)
प्रसंग मूवी शैली आईडी:
- एनिमेशन (आईडी: 15)
- बच्चे (आईडी: 9)
- संगीतमय (आईडी: 13)
- एनिमेशन (आईडी: 15)
- बच्चे (आईडी: 9)
- कॉमेडी (आईडी: 2)
- (और अधिक)
आउटपुट:
- अनुशंसित मूवी आईडी:
- टॉय स्टोरी 2 (आईडी: 3114)
- (और अधिक)
प्रदर्शन मानदंड
प्रदर्शन बेंचमार्क नंबर यहां वर्णित टूल से तैयार किए जाते हैं।
| मॉडल नाम | मॉडल का आकार | उपकरण | CPU |
|---|---|---|---|
| अनुशंसा (इनपुट के रूप में मूवी आईडी) | 0.52 एमबी | पिक्सेल 3 | 0.09ms* |
| पिक्सेल 4 | 0.05ms* | ||
| अनुशंसा (इनपुट के रूप में मूवी आईडी और मूवी शैली) | 1.3 एमबी | पिक्सेल 3 | 0.13ms* |
| पिक्सेल 4 | 0.06ms* |
* 4 धागों का प्रयोग किया गया।
अपने प्रशिक्षण डेटा का उपयोग करें
प्रशिक्षित मॉडल के अलावा, हम आपके अपने डेटा के साथ मॉडल को प्रशिक्षित करने के लिए GitHub में एक ओपन-सोर्स टूलकिट प्रदान करते हैं। टूलकिट का उपयोग कैसे करें और अपने मोबाइल एप्लिकेशन में प्रशिक्षित मॉडल कैसे तैनात करें, यह जानने के लिए आप इस ट्यूटोरियल का अनुसरण कर सकते हैं।
अपने स्वयं के डेटासेट का उपयोग करके अनुशंसा मॉडल को प्रशिक्षित करने के लिए यहां उपयोग की जाने वाली उसी तकनीक को लागू करने के लिए कृपया इस ट्यूटोरियल का पालन करें।
आपके डेटा के साथ मॉडल अनुकूलन के लिए युक्तियाँ
इस डेमो एप्लिकेशन में एकीकृत पूर्व-प्रशिक्षित मॉडल को मूवीलेंस डेटासेट के साथ प्रशिक्षित किया गया है, आप अपने स्वयं के डेटा, जैसे वोकैब आकार, एम्बेडिंग डिम्स और इनपुट संदर्भ लंबाई के आधार पर मॉडल कॉन्फ़िगरेशन को संशोधित करना चाह सकते हैं। यहां कुछ सलाह हैं:
इनपुट संदर्भ लंबाई: सर्वोत्तम इनपुट संदर्भ लंबाई डेटासेट के साथ भिन्न होती है। हम इनपुट संदर्भ लंबाई का चयन इस आधार पर करने का सुझाव देते हैं कि कितने लेबल इवेंट दीर्घकालिक हितों बनाम अल्पकालिक संदर्भ से संबंधित हैं।
एनकोडर प्रकार का चयन: हम इनपुट संदर्भ लंबाई के आधार पर एनकोडर प्रकार का चयन करने का सुझाव देते हैं। बैग-ऑफ-वर्ड्स एनकोडर छोटी इनपुट संदर्भ लंबाई (उदाहरण के लिए <10) के लिए अच्छा काम करता है, सीएनएन और आरएनएन एनकोडर लंबी इनपुट संदर्भ लंबाई के लिए अधिक सारांशीकरण क्षमता लाते हैं।
वस्तुओं या उपयोगकर्ता गतिविधियों का प्रतिनिधित्व करने के लिए अंतर्निहित सुविधाओं का उपयोग करने से मॉडल के प्रदर्शन में सुधार हो सकता है, ताजा वस्तुओं को बेहतर ढंग से समायोजित किया जा सकता है, संभवतः स्केल एम्बेडिंग रिक्त स्थान को कम किया जा सकता है जिससे मेमोरी की खपत कम हो सकती है और डिवाइस पर अधिक अनुकूल हो सकता है।