
| | |  Ver fonte no GitHub Ver fonte no GitHub |
As recomendações personalizadas são amplamente utilizadas para uma variedade de casos de uso em dispositivos móveis, como recuperação de conteúdo de mídia, sugestão de produtos de compras e recomendação do próximo aplicativo. Se você estiver interessado em fornecer recomendações personalizadas em seu aplicativo, respeitando a privacidade do usuário, recomendamos explorar o exemplo e o kit de ferramentas a seguir.
iniciar
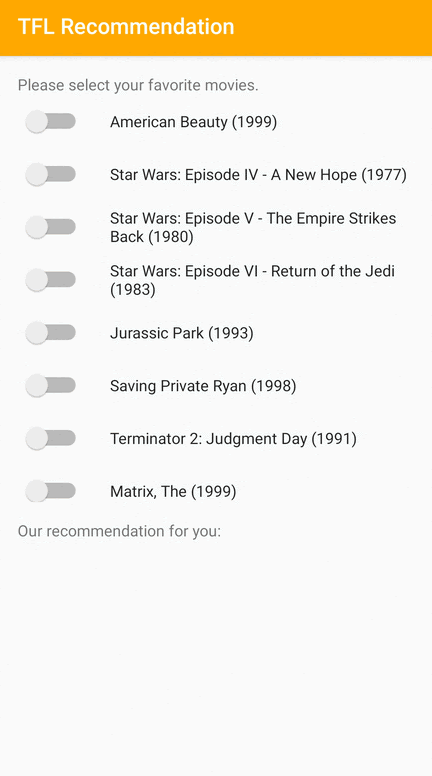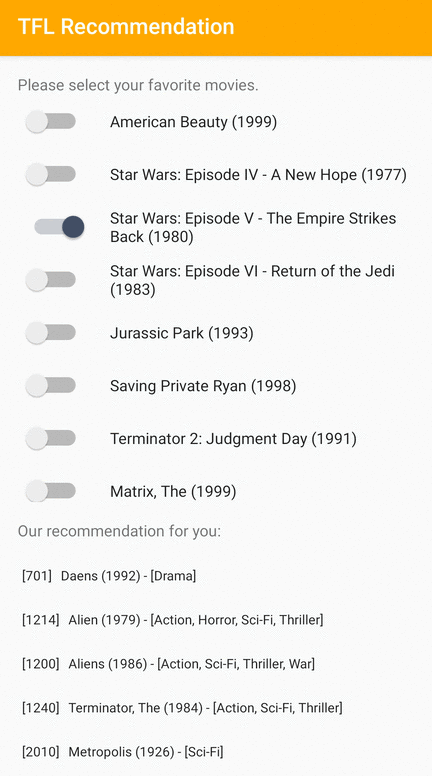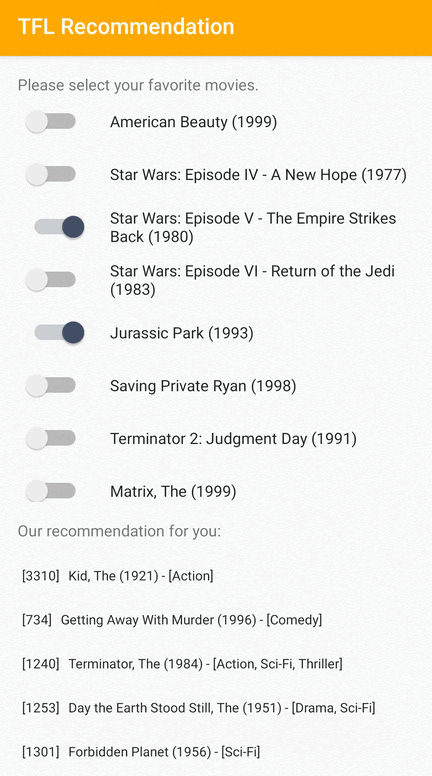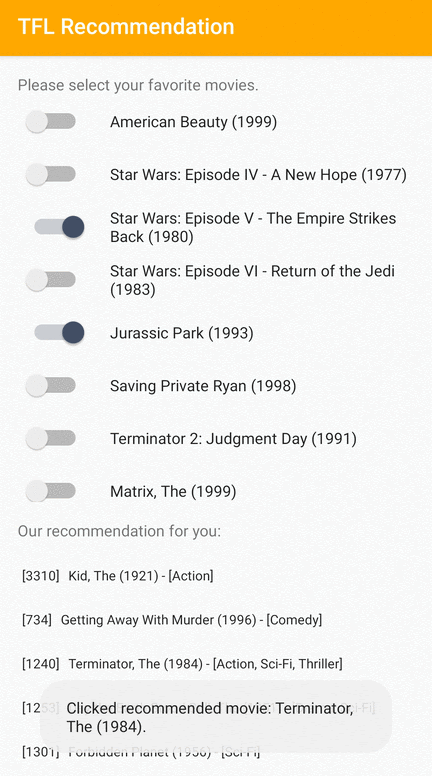
Fornecemos um aplicativo de amostra do TensorFlow Lite que demonstra como recomendar itens relevantes aos usuários do Android.
Se você estiver usando uma plataforma diferente do Android ou já estiver familiarizado com as APIs do TensorFlow Lite, poderá fazer download do nosso modelo de recomendação inicial.
Também fornecemos script de treinamento no Github para treinar seu próprio modelo de forma configurável.
Entenda a arquitetura do modelo
Aproveitamos uma arquitetura de modelo de codificador duplo, com codificador de contexto para codificar o histórico do usuário sequencial e codificador de rótulo para codificar o candidato de recomendação previsto. A similaridade entre as codificações de contexto e de rótulo é usada para representar a probabilidade de o candidato previsto atender às necessidades do usuário.
Três técnicas diferentes de codificação sequencial do histórico do usuário são fornecidas com esta base de código:
- Codificador bag-of-words (BOW): calcula a média das incorporações das atividades do usuário sem considerar a ordem do contexto.
- Codificador de rede neural convolucional (CNN): aplicação de múltiplas camadas de redes neurais convolucionais para gerar codificação de contexto.
- Codificador de rede neural recorrente (RNN): aplicação de rede neural recorrente para codificar a sequência de contexto.
Para modelar a atividade de cada usuário, poderíamos usar o ID do item de atividade (com base em ID) ou vários recursos do item (com base em recursos) ou uma combinação de ambos. O modelo baseado em recursos que utiliza vários recursos para codificar coletivamente o comportamento dos usuários. Com essa base de código, você pode criar modelos baseados em ID ou em recursos de maneira configurável.
Após o treinamento, um modelo TensorFlow Lite será exportado, que pode fornecer diretamente as principais previsões entre os candidatos à recomendação.
Use seus dados de treinamento
Além do modelo treinado, fornecemos um kit de ferramentas de código aberto no GitHub para treinar modelos com seus próprios dados. Você pode seguir este tutorial para aprender como usar o kit de ferramentas e implementar modelos treinados em seus próprios aplicativos móveis.
Siga este tutorial para aplicar a mesma técnica usada aqui para treinar um modelo de recomendação usando seus próprios conjuntos de dados.
Exemplos
Como exemplos, treinamos modelos de recomendação com abordagens baseadas em ID e em recursos. O modelo baseado em ID usa apenas os IDs dos filmes como entrada, e o modelo baseado em recursos usa os IDs dos filmes e os IDs do gênero do filme como entradas. Encontre os seguintes exemplos de entradas e saídas.
Entradas
IDs de filmes de contexto:
- O Rei Leão (ID: 362)
- História de brinquedos (ID: 1)
- (e mais)
IDs de gênero de filme de contexto:
- Animação (ID: 15)
- Infantil (ID: 9)
- Musical (ID: 13)
- Animação (ID: 15)
- Infantil (ID: 9)
- Comédia (ID: 2)
- (e mais)
Saídas:
- IDs de filmes recomendados:
- Toy Story 2 (ID: 3114)
- (e mais)
Referências de desempenho
Os números de benchmark de desempenho são gerados com a ferramenta descrita aqui .
| Nome do modelo | Tamanho do modelo | Dispositivo | CPU |
|---|---|---|---|
| recomendação (ID do filme como entrada) | 0,52 MB | Pixel 3 | 0,09ms* |
| Pixel 4 | 0,05ms* | ||
| recomendação (ID do filme e gênero do filme como entradas) | 1,3 MB | Pixel 3 | 0,13ms* |
| Pixel 4 | 0,06ms* |
* 4 fios usados.
Use seus dados de treinamento
Além do modelo treinado, fornecemos um kit de ferramentas de código aberto no GitHub para treinar modelos com seus próprios dados. Você pode seguir este tutorial para aprender como usar o kit de ferramentas e implementar modelos treinados em seus próprios aplicativos móveis.
Siga este tutorial para aplicar a mesma técnica usada aqui para treinar um modelo de recomendação usando seus próprios conjuntos de dados.
Dicas para customização de modelo com seus dados
O modelo pré-treinado integrado neste aplicativo de demonstração é treinado com o conjunto de dados MovieLens . Você pode querer modificar a configuração do modelo com base em seus próprios dados, como tamanho do vocabulário, incorporação de dims e comprimento do contexto de entrada. Aqui estão algumas dicas:
Comprimento do contexto de entrada: o melhor comprimento do contexto de entrada varia de acordo com os conjuntos de dados. Sugerimos selecionar a duração do contexto de entrada com base em quanto os eventos do rótulo estão correlacionados com interesses de longo prazo versus contexto de curto prazo.
Seleção do tipo de codificador: sugerimos selecionar o tipo de codificador com base no comprimento do contexto de entrada. O codificador bag-of-words funciona bem para comprimentos de contexto de entrada curtos (por exemplo, <10), os codificadores CNN e RNN trazem mais capacidade de resumo para comprimentos de contexto de entrada longos.
O uso de recursos subjacentes para representar itens ou atividades do usuário pode melhorar o desempenho do modelo, acomodar melhor itens novos, possivelmente reduzir a escala de espaços de incorporação, reduzindo assim o consumo de memória e tornando-o mais amigável no dispositivo.