
למכשירי Edge יש לרוב זיכרון מוגבל או כוח חישוב מוגבל. ניתן להחיל אופטימיזציות שונות על מודלים כך שניתן יהיה להפעילם במסגרת אילוצים אלו. בנוסף, אופטימיזציות מסוימות מאפשרות שימוש בחומרה מיוחדת להסקת הסקה מואצת.
TensorFlow Lite ו- TensorFlow Model Optimization Toolkit מספקים כלים למזער את המורכבות של אופטימיזציה של מסקנות.
מומלץ לשקול אופטימיזציה של מודלים במהלך תהליך פיתוח האפליקציה שלך. מסמך זה מתאר כמה שיטות עבודה מומלצות למיטוב דגמי TensorFlow לפריסה לחומרה קצה.
מדוע יש לבצע אופטימיזציה של דגמים
ישנן מספר דרכים עיקריות שבהן אופטימיזציה של מודלים יכולה לעזור בפיתוח אפליקציות.
הפחתת גודל
ניתן להשתמש בצורות מסוימות של אופטימיזציה כדי להקטין את גודל המודל. לדגמים קטנים יותר יש את היתרונות הבאים:
- גודל אחסון קטן יותר: דגמים קטנים יותר תופסים פחות שטח אחסון במכשירים של המשתמשים שלך. לדוגמה, אפליקציית אנדרואיד המשתמשת בדגם קטן יותר תתפוס פחות שטח אחסון במכשיר הנייד של המשתמש.
- גודל הורדה קטן יותר: דגמים קטנים יותר דורשים פחות זמן ורוחב פס כדי להוריד למכשירים של המשתמשים.
- פחות שימוש בזיכרון: דגמים קטנים יותר משתמשים בפחות זיכרון RAM כשהם מופעלים, מה שמפנה זיכרון לשימוש בחלקים אחרים של היישום שלך, ויכול לתרגם לביצועים ויציבות טובים יותר.
קוונטיזציה יכולה להקטין את גודל המודל בכל המקרים הללו, אולי על חשבון דיוק מסוים. גיזום ואשכול יכולים להקטין את גודל הדגם להורדה על ידי הפיכתו לדחיסה בקלות רבה יותר.
הפחתת חביון
חביון הוא משך הזמן שלוקח להפעיל הסקה בודדת עם מודל נתון. צורות מסוימות של אופטימיזציה יכולות להפחית את כמות החישוב הנדרשת להפעלת הסקת מסקנות באמצעות מודל, וכתוצאה מכך זמן השהייה נמוך יותר. חביון יכול גם להשפיע על צריכת החשמל.
נכון לעכשיו, ניתן להשתמש בקוונטיזציה כדי להפחית את זמן ההשהיה על ידי פישוט החישובים המתרחשים במהלך ההסקה, אולי על חשבון דיוק מסוים.
תאימות מאיץ
מאיצי חומרה מסוימים, כגון Edge TPU , יכולים להסיק מהר מאוד עם דגמים שעברו אופטימיזציה נכונה.
בדרך כלל, מכשירים מסוג זה דורשים לכימות דגמים בצורה ספציפית. עיין בתיעוד של כל מאיץ חומרה כדי ללמוד עוד על הדרישות שלו.
פשרות
אופטימיזציות עלולות לגרום לשינויים בדיוק המודל, שיש לקחת בחשבון במהלך תהליך פיתוח האפליקציה.
שינויי הדיוק תלויים במודל הבודד שעובר אופטימיזציה, וקשה לחזות אותם מבעוד מועד. בדרך כלל, דגמים המותאמים לגודל או לאחזור יאבדו כמות קטנה של דיוק. בהתאם לאפליקציה שלך, זה עשוי להשפיע או לא להשפיע על חוויית המשתמשים שלך. במקרים נדירים, דגמים מסוימים עשויים לקבל דיוק מסוים כתוצאה מתהליך האופטימיזציה.
סוגי אופטימיזציה
TensorFlow Lite תומך כיום באופטימיזציה באמצעות כימות, גיזום ואשכולות.
אלה הם חלק מ- TensorFlow Model Optimization Toolkit , המספק משאבים לטכניקות אופטימיזציה של מודלים התואמים ל- TensorFlow Lite.
כימות
קוונטיזציה פועלת על ידי הפחתת הדיוק של המספרים המשמשים לייצוג פרמטרים של מודל, שהם כברירת מחדל הם מספרי נקודה צפה של 32 סיביות. זה מביא לגודל דגם קטן יותר וחישוב מהיר יותר.
הסוגים הבאים של קוונטיזציה זמינים ב-TensorFlow Lite:
| טֶכנִיקָה | דרישות נתונים | הפחתת גודל | דיוק | חומרה נתמכת |
|---|---|---|---|---|
| קוונטיזציה לצוף16 לאחר אימון | אין מידע | עד 50% | אובדן דיוק לא משמעותי | מעבד, GPU |
| קוונטיזציה של טווח דינמי לאחר אימון | אין מידע | עד 75% | אובדן הדיוק הקטן ביותר | CPU, GPU (אנדרואיד) |
| קוונטיזציה של מספרים שלמים לאחר אימון | מדגם מייצג ללא תווית | עד 75% | אובדן דיוק קטן | CPU, GPU (אנדרואיד), EdgeTPU, Hexagon DSP |
| הכשרה מודעת לקוונטיזציה | נתוני אימון מסומנים | עד 75% | אובדן הדיוק הקטן ביותר | CPU, GPU (אנדרואיד), EdgeTPU, Hexagon DSP |
עץ ההחלטות הבא עוזר לך לבחור את סכימות הקוונטיזציה שבהן תרצה להשתמש עבור המודל שלך, פשוט על סמך גודל המודל והדיוק הצפויים.
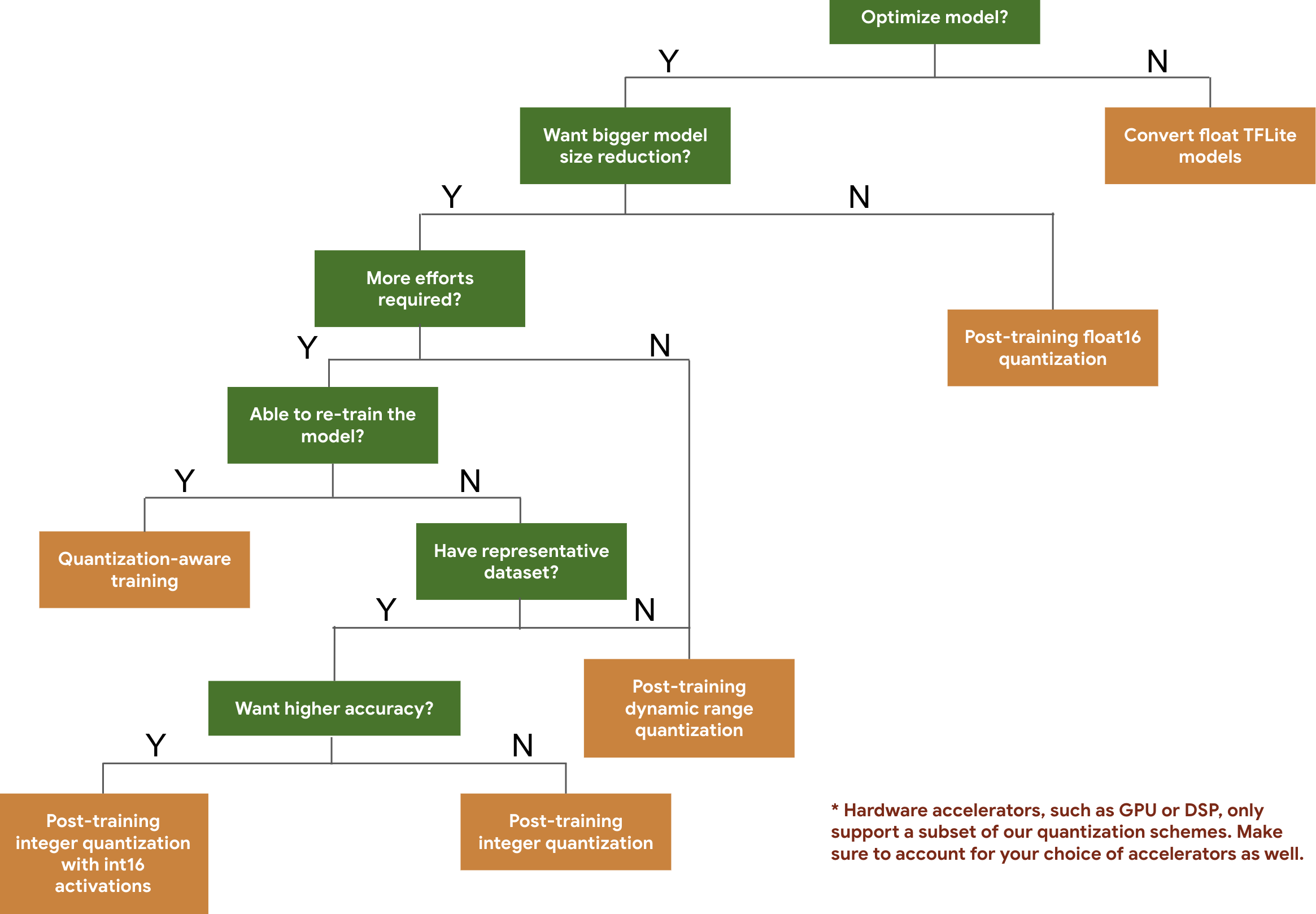
להלן תוצאות ההשהיה והדיוק עבור קוונטיזציה לאחר אימון ואימון מודע לכימות בכמה דגמים. כל מספרי ההשהיה נמדדים במכשירי Pixel 2 באמצעות מעבד ליבה אחד גדול. ככל שערכת הכלים משתפרת, כך גם המספרים כאן:
| דֶגֶם | דיוק מוביל (מקורי) | דיוק מוביל (לאחר הדרכה כמותית) | דיוק מוביל (הדרכה למודעות קוונטיזציה) | חביון (מקורי) (ms) | אחזור (לאחר אימון כמותי) (מיליות שניות) | חביון (הדרכה למודעות קוונטיזציה) (ms) | גודל (מקורי) (MB) | גודל (מוטב) (MB) |
|---|---|---|---|---|---|---|---|---|
| Mobilenet-v1-1-224 | 0.709 | 0.657 | 0.70 | 124 | 112 | 64 | 16.9 | 4.3 |
| Mobilenet-v2-1-224 | 0.719 | 0.637 | 0.709 | 89 | 98 | 54 | 14 | 3.6 |
| Inception_v3 | 0.78 | 0.772 | 0.775 | 1130 | 845 | 543 | 95.7 | 23.9 |
| Resnet_v2_101 | 0.770 | 0.768 | לא | 3973 | 2868 | לא | 178.3 | 44.9 |
קוונטיזציה מלאה של מספרים שלמים עם הפעלת int16 ומשקולות int8
קוונטיזציה עם הפעלת int16 היא סכימת כימות שלמים מלאה עם הפעלות ב-int16 ומשקולות ב-int8. מצב זה יכול לשפר את הדיוק של המודל המקוונטי בהשוואה לסכימת הכימות המלאה של מספרים שלמים עם הפעלה ומשקולות ב-int8 תוך שמירה על גודל מודל דומה. מומלץ כאשר הפעלות רגישות לכימות.
הערה: נכון לעכשיו, רק יישומי ליבת התייחסות לא מותאמים זמינים ב-TFLite עבור ערכת כימות זו, כך שכברירת מחדל הביצועים יהיו איטיים בהשוואה לגרעיני int8. כעת ניתן לגשת ליתרונות המלאים של מצב זה באמצעות חומרה מיוחדת, או תוכנה מותאמת אישית.
להלן תוצאות הדיוק עבור דגמים מסוימים הנהנים ממצב זה. דֶגֶם סוג מדדי דיוק דיוק (הפעלת float32) דיוק (הפעלת אינט8) דיוק (הפעלת אינט16) Wav2letter WER 6.7% 7.7% 7.2% DeepSpeech 0.5.1 (פרוש) CER 6.13% 43.67% 6.52% YoloV3 mAP(IOU=0.5) 0.577 0.563 0.574 MobileNetV1 דיוק מוביל 0.7062 0.694 0.6936 MobileNetV2 דיוק מוביל 0.718 0.7126 0.7137 MobileBert F1 (התאמה מדויקת) 88.81(81.23) 2.08(0) 88.73(81.15)
קִצוּץ
גיזום עובד על ידי הסרת פרמטרים בתוך מודל שיש להם השפעה מינורית בלבד על התחזיות שלו. דגמים גזומים הם באותו גודל בדיסק, ובעלי אותו זמן השהייה, אך ניתן לדחוס אותם בצורה יעילה יותר. זה הופך את הגיזום לטכניקה שימושית להפחתת גודל הורדת הדגם.
בעתיד, TensorFlow Lite תספק הפחתת זמן השהייה עבור דגמים גזומים.
מקבץ
Clustering פועל על ידי קיבוץ המשקלים של כל שכבה במודל למספר מוגדר מראש של אשכולות, ולאחר מכן שיתוף ערכי המרכז עבור המשקולות השייכות לכל אשכול בודד. זה מפחית את מספר ערכי המשקל הייחודיים במודל, ובכך מפחית את המורכבות שלו.
כתוצאה מכך, ניתן לדחוס מודלים מקובצים ביעילות רבה יותר, ולספק הטבות פריסה דומות לגיזום.
זרימת עבודה לפיתוח
כנקודת התחלה, בדוק אם הדגמים בדגמים מתארחים יכולים לעבוד עבור היישום שלך. אם לא, אנו ממליצים למשתמשים להתחיל עם כלי הקוונטיזציה שלאחר האימון מכיוון שזה ישים באופן נרחב ואינו דורש נתוני הדרכה.
במקרים שבהם יעדי הדיוק והשהייה אינם עומדים, או שתמיכה במאיצי חומרה חשובה, אימון מודע לכימות הוא האפשרות הטובה יותר. ראה טכניקות אופטימיזציה נוספות תחת ערכת הכלים לאופטימיזציה של מודל TensorFlow .
אם ברצונך להקטין עוד יותר את גודל הדגם שלך, אתה יכול לנסות לגזום ו/או לקבץ קבצים לפני כימות הדגמים שלך.