
إن التكميم بعد التدريب هو أسلوب تحويل يمكنه تقليل حجم النموذج مع تحسين زمن استجابة وحدة المعالجة المركزية والأجهزة، مع انخفاض طفيف في دقة النموذج. يمكنك تحديد حجم نموذج TensorFlow العائم الذي تم تدريبه بالفعل عند تحويله إلى تنسيق TensorFlow Lite باستخدام محول TensorFlow Lite .
طرق التحسين
هناك العديد من خيارات التكميم بعد التدريب للاختيار من بينها. فيما يلي جدول ملخص بالاختيارات والفوائد التي توفرها:
| تقنية | فوائد | المعدات |
|---|---|---|
| تكميم النطاق الديناميكي | 4x أصغر، 2x-3x تسريع | وحدة المعالجة المركزية |
| تكميم عدد صحيح كامل | 4x أصغر، 3x+ تسريع | وحدة المعالجة المركزية، حافة TPU، وحدات التحكم الدقيقة |
| Float16 التكميم | 2x أصغر، وتسريع GPU | وحدة المعالجة المركزية، وحدة معالجة الرسومات |
يمكن أن تساعد شجرة القرار التالية في تحديد طريقة القياس الكمي بعد التدريب الأفضل لحالة الاستخدام الخاصة بك:
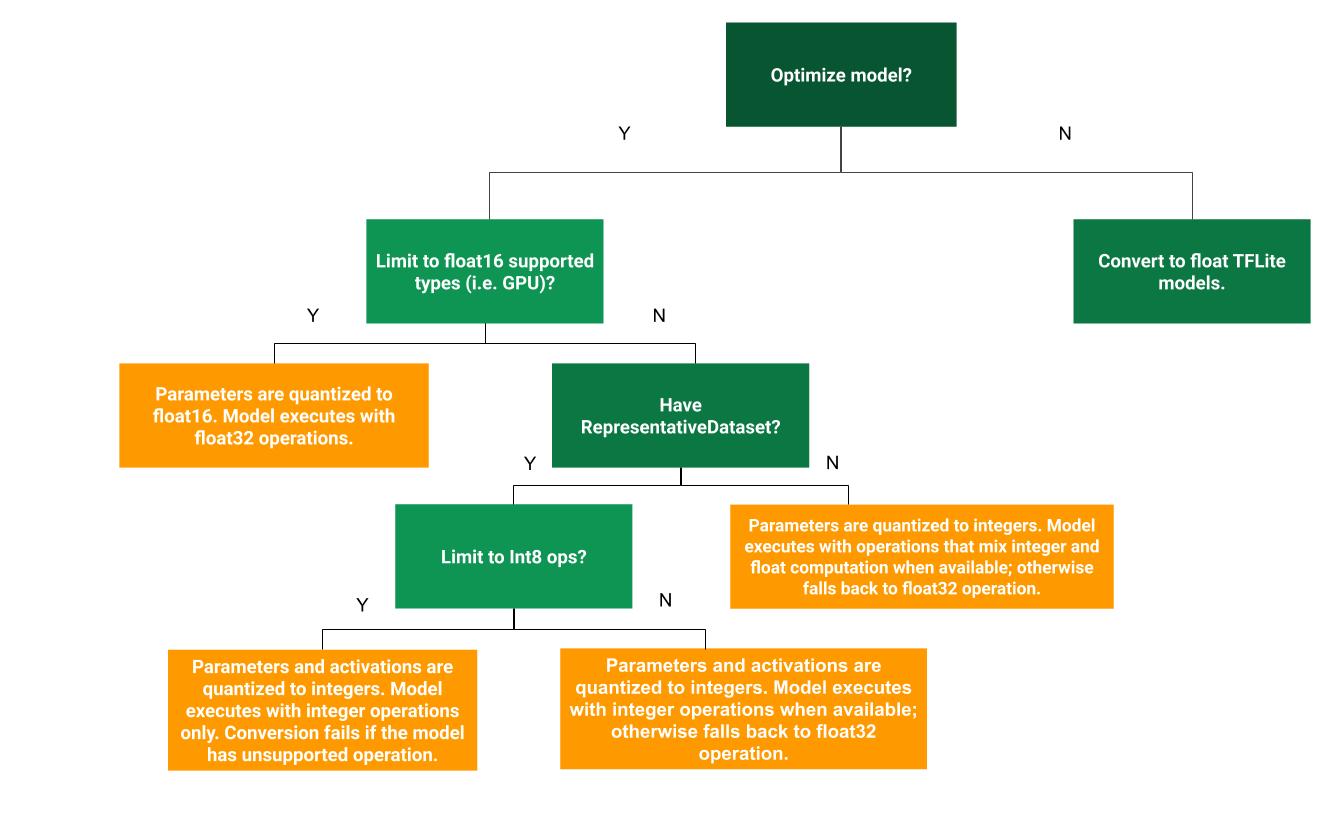
تكميم النطاق الديناميكي
يعد تكميم النطاق الديناميكي نقطة بداية موصى بها لأنه يوفر استخدامًا أقل للذاكرة وحسابًا أسرع دون الحاجة إلى توفير مجموعة بيانات تمثيلية للمعايرة. هذا النوع من التكميم، يكمم بشكل ثابت فقط الأوزان من النقطة العائمة إلى عدد صحيح في وقت التحويل، مما يوفر 8 بت من الدقة:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] tflite_quant_model = converter.convert()
لتقليل زمن الوصول بشكل أكبر أثناء الاستدلال، يقوم مشغلو "النطاق الديناميكي" بتكميم عمليات التنشيط ديناميكيًا استنادًا إلى نطاقها إلى 8 بت وإجراء عمليات حسابية بأوزان وعمليات تنشيط 8 بت. يوفر هذا التحسين أزمنة استجابة قريبة من استنتاجات النقاط الثابتة بالكامل. ومع ذلك، لا يزال يتم تخزين المخرجات باستخدام النقطة العائمة، وبالتالي فإن السرعة المتزايدة لعمليات النطاق الديناميكي تكون أقل من حساب كامل للنقطة الثابتة.
تكميم عدد صحيح كامل
يمكنك الحصول على مزيد من التحسينات في زمن الاستجابة، وتخفيضات في ذروة استخدام الذاكرة، والتوافق مع الأجهزة أو المسرعات ذات الأعداد الصحيحة فقط من خلال التأكد من أن جميع نماذج الرياضيات مُكممة بشكل صحيح.
للحصول على تكميم كامل للأعداد الصحيحة، تحتاج إلى معايرة أو تقدير النطاق، أي (min، max) لجميع موترات الفاصلة العائمة في النموذج. على عكس الموترات الثابتة مثل الأوزان والتحيزات، لا يمكن معايرة الموترات المتغيرة مثل مدخلات النموذج والتنشيط (مخرجات الطبقات المتوسطة) ومخرجات النموذج إلا إذا قمنا بتشغيل بضع دورات استدلالية. ونتيجة لذلك، يتطلب المحول مجموعة بيانات تمثيلية لمعايرتها. يمكن أن تكون مجموعة البيانات هذه مجموعة فرعية صغيرة (حوالي 100-500 عينة) من بيانات التدريب أو التحقق من الصحة. ارجع إلى الدالة representative_dataset() أدناه.
من الإصدار 2.7 من TensorFlow، يمكنك تحديد مجموعة البيانات التمثيلية من خلال التوقيع كالمثال التالي:
def representative_dataset():
for data in dataset:
yield {
"image": data.image,
"bias": data.bias,
}
إذا كان هناك أكثر من توقيع في نموذج TensorFlow المحدد، فيمكنك تحديد مجموعة البيانات المتعددة عن طريق تحديد مفاتيح التوقيع:
def representative_dataset():
# Feed data set for the "encode" signature.
for data in encode_signature_dataset:
yield (
"encode", {
"image": data.image,
"bias": data.bias,
}
)
# Feed data set for the "decode" signature.
for data in decode_signature_dataset:
yield (
"decode", {
"image": data.image,
"hint": data.hint,
},
)
يمكنك إنشاء مجموعة البيانات التمثيلية من خلال توفير قائمة موتر الإدخال:
def representative_dataset():
for data in tf.data.Dataset.from_tensor_slices((images)).batch(1).take(100):
yield [tf.dtypes.cast(data, tf.float32)]
منذ الإصدار 2.7 من TensorFlow، نوصي باستخدام النهج القائم على التوقيع بدلاً من النهج القائم على قائمة موتر الإدخال لأنه يمكن قلب ترتيب موتر الإدخال بسهولة.
لأغراض الاختبار، يمكنك استخدام مجموعة بيانات وهمية على النحو التالي:
def representative_dataset():
for _ in range(100):
data = np.random.rand(1, 244, 244, 3)
yield [data.astype(np.float32)]
عدد صحيح مع احتياطي عائم (باستخدام الإدخال/الإخراج الافتراضي)
من أجل تحديد عدد صحيح بالكامل لنموذج، ولكن استخدم عوامل التشغيل العائمة عندما لا يكون لديهم تطبيق عدد صحيح (لضمان حدوث التحويل بسلاسة)، استخدم الخطوات التالية:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset tflite_quant_model = converter.convert()
عدد صحيح فقط
يعد إنشاء النماذج ذات الأعداد الصحيحة فقط حالة استخدام شائعة لـ TensorFlow Lite لوحدات التحكم الدقيقة ووحدات Coral Edge TPU .
بالإضافة إلى ذلك، لضمان التوافق مع الأجهزة التي تحتوي على أعداد صحيحة فقط (مثل وحدات التحكم الدقيقة 8 بت) والمسرعات (مثل Coral Edge TPU)، يمكنك فرض تكميم كامل للأعداد الصحيحة لجميع العمليات بما في ذلك الإدخال والإخراج، باستخدام الخطوات التالية:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.representative_dataset = representative_dataset converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8] converter.inference_input_type = tf.int8 # or tf.uint8 converter.inference_output_type = tf.int8 # or tf.uint8 tflite_quant_model = converter.convert()
Float16 التكميم
يمكنك تقليل حجم نموذج النقطة العائمة عن طريق قياس الأوزان إلى float16، وهو معيار IEEE لأرقام الفاصلة العائمة ذات 16 بت. لتمكين float16 تكميم الأوزان، استخدم الخطوات التالية:
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_types = [tf.float16] tflite_quant_model = converter.convert()
مزايا float16 التكميم هي كما يلي:
- إنه يقلل من حجم النموذج بما يصل إلى النصف (نظرًا لأن جميع الأوزان تصبح نصف حجمها الأصلي).
- إنه يسبب الحد الأدنى من الخسارة في الدقة.
- وهو يدعم بعض المندوبين (مثل مندوب GPU) الذين يمكنهم العمل مباشرة على بيانات float16، مما يؤدي إلى تنفيذ أسرع من حسابات float32.
عيوب float16 التكميم هي كما يلي:
- إنه لا يقلل من زمن الوصول بقدر ما يقلل من التكميم في رياضيات النقطة الثابتة.
- افتراضيًا، سوف يقوم النموذج الكمي float16 "بإلغاء تربيع" قيم الأوزان إلى float32 عند تشغيله على وحدة المعالجة المركزية. (لاحظ أن مندوب GPU لن يقوم بإجراء عملية الاستخلاص هذه، لأنه يمكنه العمل على بيانات float16.)
عدد صحيح فقط: عمليات تنشيط 16 بت بأوزان 8 بت (تجريبية)
هذا هو مخطط الكمي التجريبي. إنه مشابه لمخطط "العدد الصحيح فقط"، ولكن يتم تحديد كمية التنشيط بناءً على نطاقها إلى 16 بت، ويتم تحديد كمية الأوزان في عدد صحيح 8 بت ويتم قياس التحيز إلى عدد صحيح 64 بت. ويشار إلى هذا باسم التكميم 16x8 كذلك.
والميزة الرئيسية لهذا التكميم هو أنه يمكن أن يحسن الدقة بشكل كبير، ولكن يزيد حجم النموذج بشكل طفيف فقط.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8] tflite_quant_model = converter.convert()
إذا لم يكن التكميم 16x8 مدعومًا لبعض المشغلين في النموذج، فلا يزال من الممكن تكميم النموذج، ولكن يتم الاحتفاظ بالمشغلين غير المدعومين في حالة تعويم. يجب إضافة الخيار التالي إلى target_spec للسماح بذلك.
import tensorflow as tf converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir) converter.representative_dataset = representative_dataset converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8, tf.lite.OpsSet.TFLITE_BUILTINS] tflite_quant_model = converter.convert()
تتضمن أمثلة حالات الاستخدام التي تتضمن تحسينات الدقة التي يوفرها نظام التكميم هذا ما يلي:
- فائقة الدقة,
- معالجة الإشارات الصوتية مثل إلغاء الضوضاء وتكوين الشعاع،
- إزالة ضوضاء الصورة,
- إعادة بناء HDR من صورة واحدة.
عيب هذا التكمية هو:
- الاستدلال حاليًا أبطأ بشكل ملحوظ من العدد الصحيح الكامل 8 بت بسبب عدم وجود تنفيذ محسّن للنواة.
- وهو حاليًا غير متوافق مع مندوبي TFLite المعجلين للأجهزة الموجودة.
يمكن العثور على برنامج تعليمي لوضع التكميم هنا .
دقة النموذج
وبما أن الأوزان يتم قياسها بعد التدريب، فقد يكون هناك فقدان للدقة، خاصة بالنسبة للشبكات الأصغر. يتم توفير نماذج كمية كاملة مدربة مسبقًا لشبكات محددة على TensorFlow Hub . ومن المهم التحقق من دقة النموذج الكمي للتحقق من أن أي تدهور في الدقة يقع ضمن الحدود المقبولة. هناك أدوات لتقييم دقة نموذج TensorFlow Lite .
وبدلاً من ذلك، إذا كان انخفاض الدقة مرتفعًا جدًا، ففكر في استخدام التدريب المدرك للتكميم . ومع ذلك، فإن القيام بذلك يتطلب تعديلات أثناء التدريب على النموذج لإضافة عقد تكميم وهمية، في حين تستخدم تقنيات التكميم بعد التدريب في هذه الصفحة نموذجًا موجودًا تم تدريبه مسبقًا.
تمثيل الموترات الكمية
تقريب 8 بتات قيم الفاصلة العائمة باستخدام الصيغة التالية.
\[real\_value = (int8\_value - zero\_point) \times scale\]
يتكون التمثيل من جزأين رئيسيين:
أوزان لكل محور (ويعرف أيضًا باسم لكل قناة) أو أوزان لكل موتر ممثلة بالقيم التكميلية int8 two في النطاق [-127، 127] مع نقطة صفر تساوي 0.
عمليات التنشيط/المدخلات لكل موتر ممثلة بالقيم التكميلية لـ int8 two في النطاق [-128، 127]، مع نقطة صفر في النطاق [-128، 127].
للحصول على عرض تفصيلي لخطة التكميم لدينا، يرجى الاطلاع على مواصفات التكميم لدينا. يتم تشجيع بائعي الأجهزة الذين يرغبون في الاتصال بواجهة تفويض TensorFlow Lite على تنفيذ مخطط القياس الموضح هناك.