
การเรียนรู้เชิงโครงสร้างประสาท (NSL) มุ่งเน้นไปที่การฝึกอบรมโครงข่ายประสาทเทียมเชิงลึกโดยใช้ประโยชน์จากสัญญาณที่มีโครงสร้าง (ถ้ามี) ควบคู่ไปกับอินพุตฟีเจอร์ ตามที่แนะนำโดย Bui และคณะ (WSDM'18) สัญญาณที่มีโครงสร้างเหล่านี้ใช้เพื่อทำให้การฝึกโครงข่ายประสาทเทียมเป็นปกติ โดยบังคับให้โมเดลเรียนรู้การคาดการณ์ที่แม่นยำ (โดยการลดการสูญเสียภายใต้การดูแล) ในขณะเดียวกันก็รักษาความคล้ายคลึงกันของโครงสร้างอินพุต (โดยการลดการสูญเสียเพื่อนบ้านให้เหลือน้อยที่สุด) ดูรูปด้านล่าง) เทคนิคนี้เป็นเทคนิคทั่วไปและสามารถนำไปใช้กับสถาปัตยกรรมประสาทที่กำหนดเองได้ (เช่น Feed-forward NNs, Convolutional NNs และ Recurrent NNs)
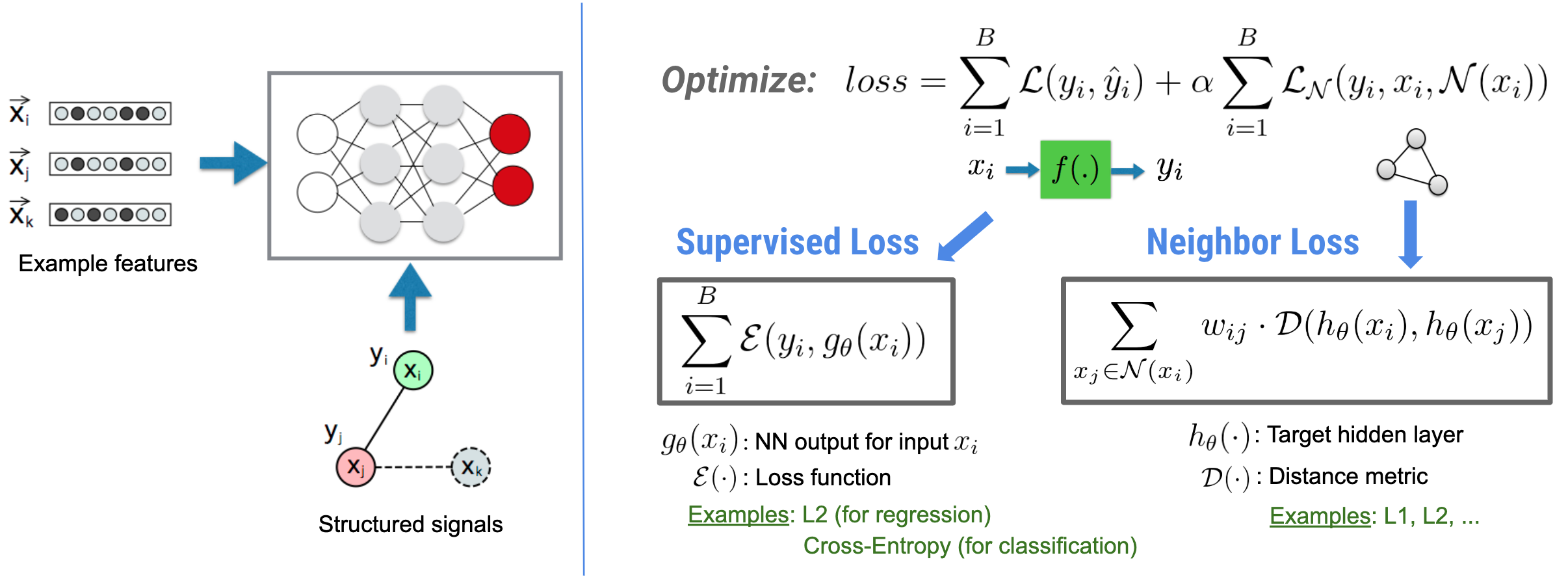
โปรดทราบว่าสมการการสูญเสียเพื่อนบ้านทั่วไปมีความยืดหยุ่นและสามารถมีรูปแบบอื่นนอกเหนือจากที่แสดงไว้ข้างต้น ตัวอย่างเช่น เรายังสามารถเลือกได้\(\sum_{x_j \in \mathcal{N}(x_i)}\mathcal{E}(y_i,g_\theta(x_j))\) ให้เป็นการสูญเสียเพื่อนบ้านซึ่งคำนวณระยะห่างระหว่างความจริงภาคพื้นดิน \(y_i\)และคำทำนายจากเพื่อนบ้าน \(g_\theta(x_j)\)- สิ่งนี้มักใช้ในการเรียนรู้แบบขัดแย้ง (Goodfellow et al., ICLR'15) ดังนั้น NSL จึงสรุปเป็นการ เรียนรู้กราฟประสาท ถ้าเพื่อนบ้านถูกแสดงด้วยกราฟอย่างชัดเจน และกับ การเรียนรู้แบบตรงข้าม หากเพื่อนบ้านถูกชักจูงโดยปริยายโดยการก่อกวนที่ขัดแย้งกัน
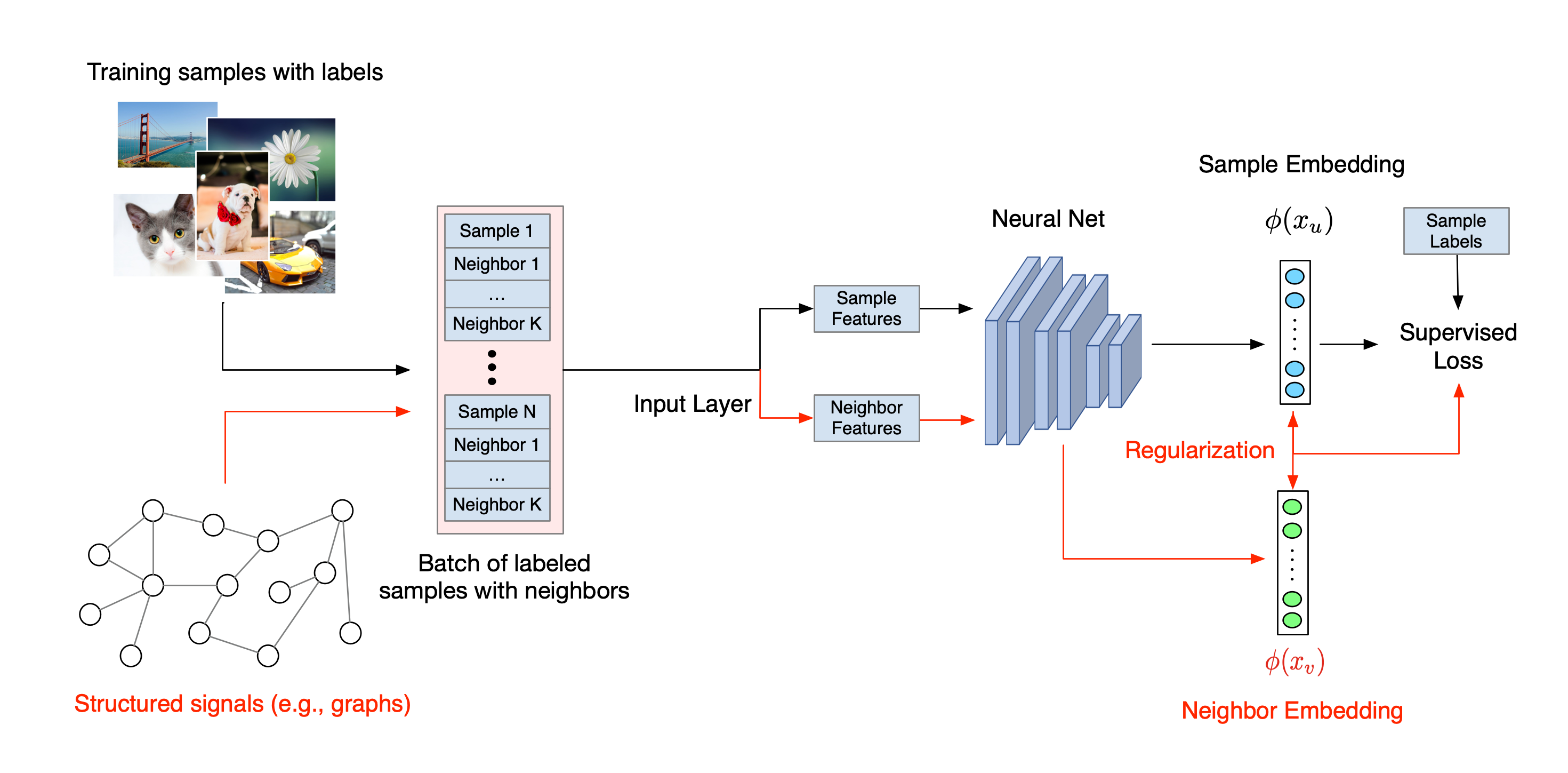
ขั้นตอนการทำงานโดยรวมสำหรับการเรียนรู้แบบมีโครงสร้างประสาทมีดังต่อไปนี้ ลูกศรสีดำแสดงถึงขั้นตอนการฝึกอบรมแบบเดิมๆ และลูกศรสีแดงแสดงถึงขั้นตอนการทำงานใหม่ตามที่ NSL นำมาใช้เพื่อใช้ประโยชน์จากสัญญาณที่มีโครงสร้าง ขั้นแรก เพิ่มตัวอย่างการฝึกอบรมเพื่อรวมสัญญาณที่มีโครงสร้างไว้ด้วย เมื่อสัญญาณที่มีโครงสร้างไม่ได้รับการจัดเตรียมไว้อย่างชัดเจน สัญญาณเหล่านั้นสามารถสร้างขึ้นหรือชักจูงได้ (อย่างหลังใช้กับการเรียนรู้แบบฝ่ายตรงข้าม) ถัดไป ตัวอย่างการฝึกอบรมเสริม (รวมทั้งตัวอย่างดั้งเดิมและเพื่อนบ้านที่เกี่ยวข้อง) จะถูกป้อนไปยังโครงข่ายประสาทเทียมเพื่อคำนวณการฝัง ระยะห่างระหว่างการฝังตัวอย่างและการฝังของเพื่อนบ้านจะถูกคำนวณและใช้เป็นการสูญเสียเพื่อนบ้าน ซึ่งถือเป็นเงื่อนไขการทำให้เป็นมาตรฐานและเพิ่มเข้ากับการสูญเสียขั้นสุดท้าย สำหรับการทำให้เป็นมาตรฐานโดยอิงเพื่อนบ้านอย่างชัดเจน โดยทั่วไปเราจะคำนวณการสูญเสียเพื่อนบ้านเป็นระยะห่างระหว่างการฝังตัวอย่างและการฝังของเพื่อนบ้าน อย่างไรก็ตาม อาจมีการใช้เลเยอร์ใดๆ ของโครงข่ายประสาทเทียมเพื่อคำนวณการสูญเสียเพื่อนบ้าน ในทางกลับกัน สำหรับการทำให้เป็นมาตรฐานตามเพื่อนบ้านที่ถูกชักนำ (ฝ่ายตรงข้าม) เราคำนวณการสูญเสียเพื่อนบ้านเป็นระยะห่างระหว่างการทำนายผลลัพธ์ของเพื่อนบ้านที่เป็นปฏิปักษ์ที่ถูกชักนำและป้ายกำกับความจริงภาคพื้นดิน
ทำไมต้องใช้ NSL?
NSL มีข้อดีดังต่อไปนี้:
- ความแม่นยำสูงกว่า : สัญญาณที่มีโครงสร้างระหว่างตัวอย่างสามารถให้ข้อมูลที่ไม่มีอยู่ในอินพุตคุณลักษณะเสมอไป ดังนั้นแนวทางการฝึกอบรมร่วม (ที่มีทั้งสัญญาณที่มีโครงสร้างและคุณลักษณะ) จึงแสดงให้เห็นว่ามีประสิทธิภาพเหนือกว่าวิธีการที่มีอยู่หลายวิธี (ที่ต้องอาศัยการฝึกอบรมด้วยคุณลักษณะเท่านั้น) ในงานที่หลากหลาย เช่น การจำแนกประเภทเอกสาร และการจำแนกเจตนาเชิงความหมาย ( Bui et al ., WSDM'18 & Kipf และคณะ, ICLR'17 )
- ความทนทาน : โมเดลที่ได้รับการฝึกด้วยตัวอย่างที่เป็นปฏิปักษ์ได้แสดงให้เห็นว่ามีความทนทานต่อการก่อกวนที่เป็นปฏิปักษ์ ซึ่งออกแบบมาเพื่อทำให้การคาดการณ์หรือการจำแนกประเภทของแบบจำลองเข้าใจผิด ( Goodfellow et al., ICLR'15 & Miyato et al., ICLR'16 ) เมื่อจำนวนตัวอย่างการฝึกอบรมมีน้อย การฝึกอบรมกับตัวอย่างที่ขัดแย้งกันยังช่วยปรับปรุงความแม่นยำของแบบจำลอง ( Tsipras et al., ICLR'19 )
- ต้องการข้อมูลที่มีป้ายกำกับน้อยลง : NSL ช่วยให้โครงข่ายประสาทเทียมสามารถควบคุมข้อมูลทั้งที่มีป้ายกำกับและไม่มีป้ายกำกับ ซึ่งขยายกระบวนทัศน์การเรียนรู้ไปสู่ การเรียนรู้แบบกึ่งกำกับดูแล โดยเฉพาะอย่างยิ่ง NSL อนุญาตให้เครือข่ายฝึกการใช้ข้อมูลที่ติดป้ายกำกับเช่นเดียวกับในการตั้งค่าภายใต้การดูแล และในขณะเดียวกันก็ขับเคลื่อนเครือข่ายเพื่อเรียนรู้การนำเสนอที่ซ่อนอยู่ที่คล้ายกันสำหรับ "ตัวอย่างใกล้เคียง" ที่อาจมีหรือไม่มีป้ายกำกับก็ได้ เทคนิคนี้แสดงให้เห็นถึงคำมั่นสัญญาที่ดีในการปรับปรุงความแม่นยำของแบบจำลองเมื่อปริมาณข้อมูลที่ติดป้ายกำกับค่อนข้างน้อย ( Bui et al., WSDM'18 & Miyato et al., ICLR'16 )
บทช่วยสอนทีละขั้นตอน
เพื่อให้ได้ประสบการณ์ตรงกับการเรียนรู้ที่มีโครงสร้างทางประสาท เรามีบทช่วยสอนที่ครอบคลุมสถานการณ์ต่างๆ ที่อาจได้รับ สร้าง หรือชักจูงสัญญาณที่มีโครงสร้างอย่างชัดเจน นี่คือบางส่วน:
การทำให้กราฟเป็นมาตรฐานสำหรับการจำแนกประเภทเอกสารโดยใช้กราฟธรรมชาติ ในบทช่วยสอนนี้ เราจะสำรวจการใช้การทำให้กราฟเป็นมาตรฐานเพื่อจัดประเภทเอกสารที่สร้างกราฟธรรมชาติ (ทั่วไป)
การทำให้กราฟเป็นปกติสำหรับการจำแนกความรู้สึกโดยใช้กราฟสังเคราะห์ ในบทช่วยสอนนี้ เราสาธิตการใช้การทำให้กราฟเป็นมาตรฐานเพื่อจำแนกความรู้สึกในการวิจารณ์ภาพยนตร์โดยการสร้าง (สังเคราะห์) สัญญาณที่มีโครงสร้าง
การเรียนรู้แบบปฏิปักษ์เพื่อการจำแนกภาพ ในบทช่วยสอนนี้ เราจะสำรวจการใช้การเรียนรู้แบบขัดแย้ง (เมื่อมีการชักนำสัญญาณที่มีโครงสร้าง) เพื่อจัดประเภทรูปภาพที่มีตัวเลข
สามารถดูตัวอย่างและบทช่วยสอนเพิ่มเติมได้ในไดเรกทอรี ตัวอย่าง ของพื้นที่เก็บข้อมูล GitHub ของเรา
-การเรียนรู้เชิงโครงสร้างประสาท (NSL) มุ่งเน้นไปที่การฝึกอบรมโครงข่ายประสาทเทียมเชิงลึกโดยใช้ประโยชน์จากสัญญาณที่มีโครงสร้าง (ถ้ามี) ควบคู่ไปกับอินพุตฟีเจอร์ ตามที่แนะนำโดย Bui และคณะ (WSDM'18) สัญญาณที่มีโครงสร้างเหล่านี้ใช้เพื่อทำให้การฝึกโครงข่ายประสาทเทียมเป็นปกติ โดยบังคับให้โมเดลเรียนรู้การคาดการณ์ที่แม่นยำ (โดยการลดการสูญเสียภายใต้การดูแล) ในขณะเดียวกันก็รักษาความคล้ายคลึงกันของโครงสร้างอินพุต (โดยการลดการสูญเสียเพื่อนบ้านให้เหลือน้อยที่สุด) ดูรูปด้านล่าง) เทคนิคนี้เป็นเทคนิคทั่วไปและสามารถนำไปใช้กับสถาปัตยกรรมประสาทที่กำหนดเองได้ (เช่น Feed-forward NNs, Convolutional NNs และ Recurrent NNs)
โปรดทราบว่าสมการการสูญเสียเพื่อนบ้านทั่วไปมีความยืดหยุ่นและสามารถมีรูปแบบอื่นนอกเหนือจากที่แสดงไว้ข้างต้น ตัวอย่างเช่น เรายังสามารถเลือกได้\(\sum_{x_j \in \mathcal{N}(x_i)}\mathcal{E}(y_i,g_\theta(x_j))\) ให้เป็นการสูญเสียเพื่อนบ้านซึ่งคำนวณระยะห่างระหว่างความจริงภาคพื้นดิน \(y_i\)และคำทำนายจากเพื่อนบ้าน \(g_\theta(x_j)\)- สิ่งนี้มักใช้ในการเรียนรู้แบบขัดแย้ง (Goodfellow et al., ICLR'15) ดังนั้น NSL จึงสรุปเป็นการ เรียนรู้กราฟประสาท ถ้าเพื่อนบ้านถูกแสดงด้วยกราฟอย่างชัดเจน และกับ การเรียนรู้แบบตรงข้าม หากเพื่อนบ้านถูกชักจูงโดยปริยายโดยการก่อกวนที่ขัดแย้งกัน
ขั้นตอนการทำงานโดยรวมสำหรับการเรียนรู้แบบมีโครงสร้างประสาทมีดังต่อไปนี้ ลูกศรสีดำแสดงถึงขั้นตอนการฝึกอบรมแบบเดิมๆ และลูกศรสีแดงแสดงถึงขั้นตอนการทำงานใหม่ตามที่ NSL นำมาใช้เพื่อใช้ประโยชน์จากสัญญาณที่มีโครงสร้าง ขั้นแรก เพิ่มตัวอย่างการฝึกอบรมเพื่อรวมสัญญาณที่มีโครงสร้างไว้ด้วย เมื่อสัญญาณที่มีโครงสร้างไม่ได้รับการจัดเตรียมไว้อย่างชัดเจน สัญญาณเหล่านั้นสามารถสร้างขึ้นหรือชักจูงได้ (อย่างหลังใช้กับการเรียนรู้แบบฝ่ายตรงข้าม) ถัดไป ตัวอย่างการฝึกอบรมเสริม (รวมทั้งตัวอย่างดั้งเดิมและเพื่อนบ้านที่เกี่ยวข้อง) จะถูกป้อนไปยังโครงข่ายประสาทเทียมเพื่อคำนวณการฝัง ระยะห่างระหว่างการฝังตัวอย่างและการฝังของเพื่อนบ้านจะถูกคำนวณและใช้เป็นการสูญเสียเพื่อนบ้าน ซึ่งถือเป็นเงื่อนไขการทำให้เป็นมาตรฐานและเพิ่มเข้ากับการสูญเสียขั้นสุดท้าย สำหรับการทำให้เป็นมาตรฐานโดยอิงเพื่อนบ้านอย่างชัดเจน โดยทั่วไปเราจะคำนวณการสูญเสียเพื่อนบ้านเป็นระยะห่างระหว่างการฝังตัวอย่างและการฝังของเพื่อนบ้าน อย่างไรก็ตาม อาจมีการใช้เลเยอร์ใดๆ ของโครงข่ายประสาทเทียมเพื่อคำนวณการสูญเสียเพื่อนบ้าน ในทางกลับกัน สำหรับการทำให้เป็นมาตรฐานตามเพื่อนบ้านที่ถูกชักนำ (ฝ่ายตรงข้าม) เราคำนวณการสูญเสียเพื่อนบ้านเป็นระยะห่างระหว่างการทำนายผลลัพธ์ของเพื่อนบ้านที่เป็นปฏิปักษ์ที่ถูกชักนำและป้ายกำกับความจริงภาคพื้นดิน
ทำไมต้องใช้ NSL?
NSL มีข้อดีดังต่อไปนี้:
- ความแม่นยำสูงกว่า : สัญญาณที่มีโครงสร้างระหว่างตัวอย่างสามารถให้ข้อมูลที่ไม่มีอยู่ในอินพุตคุณลักษณะเสมอไป ดังนั้นแนวทางการฝึกอบรมร่วม (ที่มีทั้งสัญญาณที่มีโครงสร้างและคุณลักษณะ) จึงแสดงให้เห็นว่ามีประสิทธิภาพเหนือกว่าวิธีการที่มีอยู่หลายวิธี (ที่ต้องอาศัยการฝึกอบรมด้วยคุณลักษณะเท่านั้น) ในงานที่หลากหลาย เช่น การจำแนกประเภทเอกสาร และการจำแนกเจตนาเชิงความหมาย ( Bui et al ., WSDM'18 & Kipf และคณะ, ICLR'17 )
- ความทนทาน : โมเดลที่ได้รับการฝึกด้วยตัวอย่างที่เป็นปฏิปักษ์ได้แสดงให้เห็นว่ามีความทนทานต่อการก่อกวนที่เป็นปฏิปักษ์ ซึ่งออกแบบมาเพื่อทำให้การคาดการณ์หรือการจำแนกประเภทของแบบจำลองเข้าใจผิด ( Goodfellow et al., ICLR'15 & Miyato et al., ICLR'16 ) เมื่อจำนวนตัวอย่างการฝึกอบรมมีน้อย การฝึกอบรมกับตัวอย่างที่ขัดแย้งกันยังช่วยปรับปรุงความแม่นยำของแบบจำลอง ( Tsipras et al., ICLR'19 )
- ต้องการข้อมูลที่มีป้ายกำกับน้อยลง : NSL ช่วยให้โครงข่ายประสาทเทียมสามารถควบคุมข้อมูลทั้งที่มีป้ายกำกับและไม่มีป้ายกำกับ ซึ่งขยายกระบวนทัศน์การเรียนรู้ไปสู่ การเรียนรู้แบบกึ่งกำกับดูแล โดยเฉพาะอย่างยิ่ง NSL อนุญาตให้เครือข่ายฝึกการใช้ข้อมูลที่ติดป้ายกำกับเช่นเดียวกับในการตั้งค่าภายใต้การดูแล และในขณะเดียวกันก็ขับเคลื่อนเครือข่ายเพื่อเรียนรู้การนำเสนอที่ซ่อนอยู่ที่คล้ายกันสำหรับ "ตัวอย่างใกล้เคียง" ที่อาจมีหรือไม่มีป้ายกำกับก็ได้ เทคนิคนี้แสดงให้เห็นถึงคำมั่นสัญญาที่ดีในการปรับปรุงความแม่นยำของแบบจำลองเมื่อปริมาณข้อมูลที่ติดป้ายกำกับค่อนข้างน้อย ( Bui et al., WSDM'18 & Miyato et al., ICLR'16 )
บทช่วยสอนทีละขั้นตอน
เพื่อให้ได้ประสบการณ์ตรงกับการเรียนรู้ที่มีโครงสร้างทางประสาท เรามีบทช่วยสอนที่ครอบคลุมสถานการณ์ต่างๆ ที่อาจได้รับ สร้าง หรือชักจูงสัญญาณที่มีโครงสร้างอย่างชัดเจน นี่คือบางส่วน:
การทำให้กราฟเป็นมาตรฐานสำหรับการจำแนกประเภทเอกสารโดยใช้กราฟธรรมชาติ ในบทช่วยสอนนี้ เราจะสำรวจการใช้การทำให้กราฟเป็นมาตรฐานเพื่อจัดประเภทเอกสารที่สร้างกราฟธรรมชาติ (ทั่วไป)
การทำให้กราฟเป็นปกติสำหรับการจำแนกความรู้สึกโดยใช้กราฟสังเคราะห์ ในบทช่วยสอนนี้ เราสาธิตการใช้การทำให้กราฟเป็นมาตรฐานเพื่อจำแนกความรู้สึกในการวิจารณ์ภาพยนตร์โดยการสร้าง (สังเคราะห์) สัญญาณที่มีโครงสร้าง
การเรียนรู้แบบปฏิปักษ์เพื่อการจำแนกภาพ ในบทช่วยสอนนี้ เราจะสำรวจการใช้การเรียนรู้แบบขัดแย้ง (เมื่อมีการชักนำสัญญาณที่มีโครงสร้าง) เพื่อจัดประเภทรูปภาพที่มีตัวเลข
สามารถดูตัวอย่างและบทช่วยสอนเพิ่มเติมได้ในไดเรกทอรี ตัวอย่าง ของพื้นที่เก็บข้อมูล GitHub ของเรา
-การเรียนรู้เชิงโครงสร้างประสาท (NSL) มุ่งเน้นไปที่การฝึกอบรมโครงข่ายประสาทเทียมเชิงลึกโดยใช้ประโยชน์จากสัญญาณที่มีโครงสร้าง (ถ้ามี) ควบคู่ไปกับอินพุตฟีเจอร์ ตามที่แนะนำโดย Bui และคณะ (WSDM'18) สัญญาณที่มีโครงสร้างเหล่านี้ใช้เพื่อทำให้การฝึกโครงข่ายประสาทเทียมเป็นปกติ โดยบังคับให้โมเดลเรียนรู้การคาดการณ์ที่แม่นยำ (โดยการลดการสูญเสียภายใต้การดูแล) ในขณะเดียวกันก็รักษาความคล้ายคลึงกันของโครงสร้างอินพุต (โดยการลดการสูญเสียเพื่อนบ้านให้เหลือน้อยที่สุด) ดูรูปด้านล่าง) เทคนิคนี้เป็นเทคนิคทั่วไปและสามารถนำไปใช้กับสถาปัตยกรรมประสาทที่กำหนดเองได้ (เช่น Feed-forward NNs, Convolutional NNs และ Recurrent NNs)
โปรดทราบว่าสมการการสูญเสียเพื่อนบ้านทั่วไปมีความยืดหยุ่นและสามารถมีรูปแบบอื่นนอกเหนือจากที่แสดงไว้ข้างต้น ตัวอย่างเช่น เรายังสามารถเลือกได้\(\sum_{x_j \in \mathcal{N}(x_i)}\mathcal{E}(y_i,g_\theta(x_j))\) ให้เป็นการสูญเสียเพื่อนบ้านซึ่งคำนวณระยะห่างระหว่างความจริงภาคพื้นดิน \(y_i\)และคำทำนายจากเพื่อนบ้าน \(g_\theta(x_j)\)- สิ่งนี้มักใช้ในการเรียนรู้แบบขัดแย้ง (Goodfellow et al., ICLR'15) ดังนั้น NSL จึงสรุปเป็นการ เรียนรู้กราฟประสาท ถ้าเพื่อนบ้านถูกแสดงด้วยกราฟอย่างชัดเจน และกับ การเรียนรู้แบบตรงข้าม หากเพื่อนบ้านถูกชักจูงโดยปริยายโดยการก่อกวนที่ขัดแย้งกัน
ขั้นตอนการทำงานโดยรวมสำหรับการเรียนรู้แบบมีโครงสร้างประสาทมีดังต่อไปนี้ ลูกศรสีดำแสดงถึงขั้นตอนการฝึกอบรมแบบเดิมๆ และลูกศรสีแดงแสดงถึงขั้นตอนการทำงานใหม่ตามที่ NSL นำมาใช้เพื่อใช้ประโยชน์จากสัญญาณที่มีโครงสร้าง ขั้นแรก เพิ่มตัวอย่างการฝึกอบรมเพื่อรวมสัญญาณที่มีโครงสร้างไว้ด้วย เมื่อสัญญาณที่มีโครงสร้างไม่ได้รับการจัดเตรียมไว้อย่างชัดเจน สัญญาณเหล่านั้นสามารถสร้างขึ้นหรือชักจูงได้ (อย่างหลังใช้กับการเรียนรู้แบบฝ่ายตรงข้าม) ถัดไป ตัวอย่างการฝึกอบรมเสริม (รวมทั้งตัวอย่างดั้งเดิมและเพื่อนบ้านที่เกี่ยวข้อง) จะถูกป้อนไปยังโครงข่ายประสาทเทียมเพื่อคำนวณการฝัง ระยะห่างระหว่างการฝังตัวอย่างและการฝังของเพื่อนบ้านจะถูกคำนวณและใช้เป็นการสูญเสียเพื่อนบ้าน ซึ่งถือเป็นเงื่อนไขการทำให้เป็นมาตรฐานและเพิ่มเข้ากับการสูญเสียขั้นสุดท้าย สำหรับการทำให้เป็นมาตรฐานโดยอิงเพื่อนบ้านอย่างชัดเจน โดยทั่วไปเราจะคำนวณการสูญเสียเพื่อนบ้านเป็นระยะห่างระหว่างการฝังตัวอย่างและการฝังของเพื่อนบ้าน อย่างไรก็ตาม ชั้นใดๆ ของโครงข่ายประสาทเทียมอาจถูกนำมาใช้เพื่อคำนวณการสูญเสียเพื่อนบ้าน ในทางกลับกัน สำหรับการทำให้เป็นมาตรฐานตามเพื่อนบ้านที่ถูกชักนำ (ฝ่ายตรงข้าม) เราคำนวณการสูญเสียเพื่อนบ้านเป็นระยะห่างระหว่างการทำนายผลลัพธ์ของเพื่อนบ้านที่เป็นปฏิปักษ์ที่ถูกชักนำและป้ายกำกับความจริงภาคพื้นดิน
ทำไมต้องใช้ NSL?
NSL มีข้อดีดังต่อไปนี้:
- ความแม่นยำสูงกว่า : สัญญาณที่มีโครงสร้างระหว่างตัวอย่างสามารถให้ข้อมูลที่ไม่มีอยู่ในอินพุตคุณลักษณะเสมอไป ดังนั้นแนวทางการฝึกอบรมร่วม (ที่มีทั้งสัญญาณที่มีโครงสร้างและคุณลักษณะ) จึงแสดงให้เห็นว่ามีประสิทธิภาพเหนือกว่าวิธีการที่มีอยู่หลายวิธี (ที่ต้องอาศัยการฝึกอบรมด้วยคุณลักษณะเท่านั้น) ในงานที่หลากหลาย เช่น การจำแนกประเภทเอกสาร และการจำแนกเจตนาเชิงความหมาย ( Bui et al ., WSDM'18 & Kipf และคณะ, ICLR'17 )
- ความทนทาน : โมเดลที่ได้รับการฝึกด้วยตัวอย่างที่เป็นปฏิปักษ์ได้แสดงให้เห็นว่ามีความทนทานต่อการก่อกวนที่เป็นปฏิปักษ์ ซึ่งออกแบบมาเพื่อทำให้การคาดการณ์หรือการจำแนกประเภทของแบบจำลองเข้าใจผิด ( Goodfellow et al., ICLR'15 & Miyato et al., ICLR'16 ) เมื่อจำนวนตัวอย่างการฝึกอบรมมีน้อย การฝึกอบรมกับตัวอย่างที่ขัดแย้งกันยังช่วยปรับปรุงความแม่นยำของแบบจำลอง ( Tsipras et al., ICLR'19 )
- ต้องการข้อมูลที่มีป้ายกำกับน้อยลง : NSL ช่วยให้โครงข่ายประสาทเทียมสามารถควบคุมข้อมูลทั้งที่มีป้ายกำกับและไม่มีป้ายกำกับ ซึ่งขยายกระบวนทัศน์การเรียนรู้ไปสู่ การเรียนรู้แบบกึ่งกำกับดูแล โดยเฉพาะอย่างยิ่ง NSL อนุญาตให้เครือข่ายฝึกการใช้ข้อมูลที่ติดป้ายกำกับเช่นเดียวกับในการตั้งค่าภายใต้การดูแล และในขณะเดียวกันก็ขับเคลื่อนเครือข่ายเพื่อเรียนรู้การนำเสนอที่ซ่อนอยู่ที่คล้ายกันสำหรับ "ตัวอย่างใกล้เคียง" ที่อาจมีหรือไม่มีป้ายกำกับก็ได้ เทคนิคนี้แสดงให้เห็นถึงคำมั่นสัญญาที่ดีในการปรับปรุงความแม่นยำของแบบจำลองเมื่อปริมาณข้อมูลที่ติดป้ายกำกับค่อนข้างน้อย ( Bui et al., WSDM'18 & Miyato et al., ICLR'16 )
บทช่วยสอนทีละขั้นตอน
เพื่อให้ได้ประสบการณ์ตรงกับการเรียนรู้ที่มีโครงสร้างทางประสาท เรามีบทช่วยสอนที่ครอบคลุมสถานการณ์ต่างๆ ที่อาจได้รับ สร้าง หรือชักจูงสัญญาณที่มีโครงสร้างอย่างชัดเจน นี่คือบางส่วน:
การทำให้กราฟเป็นมาตรฐานสำหรับการจำแนกประเภทเอกสารโดยใช้กราฟธรรมชาติ ในบทช่วยสอนนี้ เราจะสำรวจการใช้การทำให้กราฟเป็นมาตรฐานเพื่อจัดประเภทเอกสารที่สร้างกราฟธรรมชาติ (ทั่วไป)
การทำให้กราฟเป็นปกติสำหรับการจำแนกความรู้สึกโดยใช้กราฟสังเคราะห์ ในบทช่วยสอนนี้ เราสาธิตการใช้การทำให้กราฟเป็นมาตรฐานเพื่อจำแนกความรู้สึกในการวิจารณ์ภาพยนตร์โดยการสร้าง (สังเคราะห์) สัญญาณที่มีโครงสร้าง
การเรียนรู้แบบปฏิปักษ์เพื่อการจำแนกภาพ ในบทช่วยสอนนี้ เราจะสำรวจการใช้การเรียนรู้แบบขัดแย้ง (เมื่อมีการชักนำสัญญาณที่มีโครงสร้าง) เพื่อจัดประเภทรูปภาพที่มีตัวเลข
สามารถดูตัวอย่างและบทช่วยสอนเพิ่มเติมได้ในไดเรกทอรี ตัวอย่าง ของพื้นที่เก็บข้อมูล GitHub ของเรา