
Às vezes, eventos catastróficos envolvendo NaN s podem ocorrer durante um programa TensorFlow, prejudicando os processos de treinamento do modelo. A causa raiz de tais eventos é muitas vezes obscura, especialmente para modelos de tamanho e complexidade não triviais. Para facilitar a depuração desse tipo de bug de modelo, o TensorBoard 2.3+ (junto com o TensorFlow 2.3+) fornece um painel especializado chamado Debugger V2. Aqui demonstramos como usar essa ferramenta resolvendo um bug real envolvendo NaNs em uma rede neural escrita em TensorFlow.
As técnicas ilustradas neste tutorial são aplicáveis a outros tipos de atividades de depuração, como a inspeção de formas de tensores de tempo de execução em programas complexos. Este tutorial se concentra em NaNs devido à sua frequência de ocorrência relativamente alta.
Observando o bug
O código-fonte do programa TF2 que depuraremos está disponível no GitHub . O programa de exemplo também está empacotado no pacote tensorflow pip (versão 2.3+) e pode ser invocado por:
python -m tensorflow.python.debug.examples.v2.debug_mnist_v2
Este programa TF2 cria uma percepção multicamada (MLP) e a treina para reconhecer imagens MNIST . Este exemplo usa propositalmente a API de baixo nível do TF2 para definir construções de camadas personalizadas, função de perda e loop de treinamento, porque a probabilidade de bugs NaN é maior quando usamos esta API mais flexível, mas mais propensa a erros, do que quando usamos a API mais fácil APIs de alto nível -to-use, mas um pouco menos flexíveis, como tf.keras .
O programa imprime uma precisão de teste após cada etapa de treinamento. Podemos ver no console que a precisão do teste fica presa em um nível próximo ao acaso (~0,1) após a primeira etapa. Certamente não é assim que se espera que o treinamento do modelo se comporte: esperamos que a precisão se aproxime gradualmente de 1,0 (100%) à medida que o passo aumenta.
Accuracy at step 0: 0.216
Accuracy at step 1: 0.098
Accuracy at step 2: 0.098
Accuracy at step 3: 0.098
...
Uma suposição fundamentada é que esse problema é causado por uma instabilidade numérica, como NaN ou infinito. Porém, como podemos confirmar que este é realmente o caso e como encontramos a operação (op) do TensorFlow responsável por gerar a instabilidade numérica? Para responder a essas perguntas, vamos instrumentar o programa com bugs com o Debugger V2.
Instrumentação de código do TensorFlow com o Debugger V2
tf.debugging.experimental.enable_dump_debug_info() é o ponto de entrada da API do Debugger V2. Ele instrumenta um programa TF2 com uma única linha de código. Por exemplo, adicionar a seguinte linha perto do início do programa fará com que as informações de depuração sejam gravadas no diretório de log (logdir) em /tmp/tfdbg2_logdir. As informações de depuração abrangem vários aspectos do tempo de execução do TensorFlow. No TF2, inclui o histórico completo de execução antecipada, construção de gráfico realizada por @tf.function , a execução dos gráficos, os valores de tensor gerados pelos eventos de execução, bem como a localização do código (rastreamentos de pilha Python) desses eventos . A riqueza das informações de depuração permite que os usuários se concentrem em bugs obscuros.
tf.debugging.experimental.enable_dump_debug_info(
"/tmp/tfdbg2_logdir",
tensor_debug_mode="FULL_HEALTH",
circular_buffer_size=-1)
O argumento tensor_debug_mode controla quais informações o Debugger V2 extrai de cada tensor ansioso ou no gráfico. “FULL_HEALTH” é um modo que captura as seguintes informações sobre cada tensor do tipo flutuante (por exemplo, o comumente visto float32 e o menos comum bfloat16 dtype):
- DTipo
- Classificação
- Número total de elementos
- Uma divisão dos elementos do tipo flutuante nas seguintes categorias: finito negativo (
-), zero (0), finito positivo (+), infinito negativo (-∞), infinito positivo (+∞) eNaN.
O modo “FULL_HEALTH” é adequado para depuração de bugs envolvendo NaN e infinito. Veja abaixo outros tensor_debug_mode s suportados.
O argumento circular_buffer_size controla quantos eventos de tensor são salvos no logdir. O padrão é 1000, o que faz com que apenas os últimos 1000 tensores antes do final do programa TF2 instrumentado sejam salvos no disco. Esse comportamento padrão reduz a sobrecarga do depurador sacrificando a integridade dos dados de depuração. Se a completude for preferida, como neste caso, podemos desabilitar o buffer circular definindo o argumento com um valor negativo (por exemplo, -1 aqui).
O exemplo debug_mnist_v2 invoca enable_dump_debug_info() passando sinalizadores de linha de comando para ele. Para executar nosso programa TF2 problemático novamente com esta instrumentação de depuração habilitada, faça:
python -m tensorflow.python.debug.examples.v2.debug_mnist_v2 \
--dump_dir /tmp/tfdbg2_logdir --dump_tensor_debug_mode FULL_HEALTH
Iniciando a GUI do Debugger V2 no TensorBoard
A execução do programa com a instrumentação do depurador cria um logdir em /tmp/tfdbg2_logdir. Podemos iniciar o TensorBoard e apontá-lo para o logdir com:
tensorboard --logdir /tmp/tfdbg2_logdir
No navegador da web, navegue até a página do TensorBoard em http://localhost:6006. O plugin “Debugger V2” estará inativo por padrão, então selecione-o no menu “Plugins inativos” no canto superior direito. Depois de selecionado, deverá ficar parecido com o seguinte:
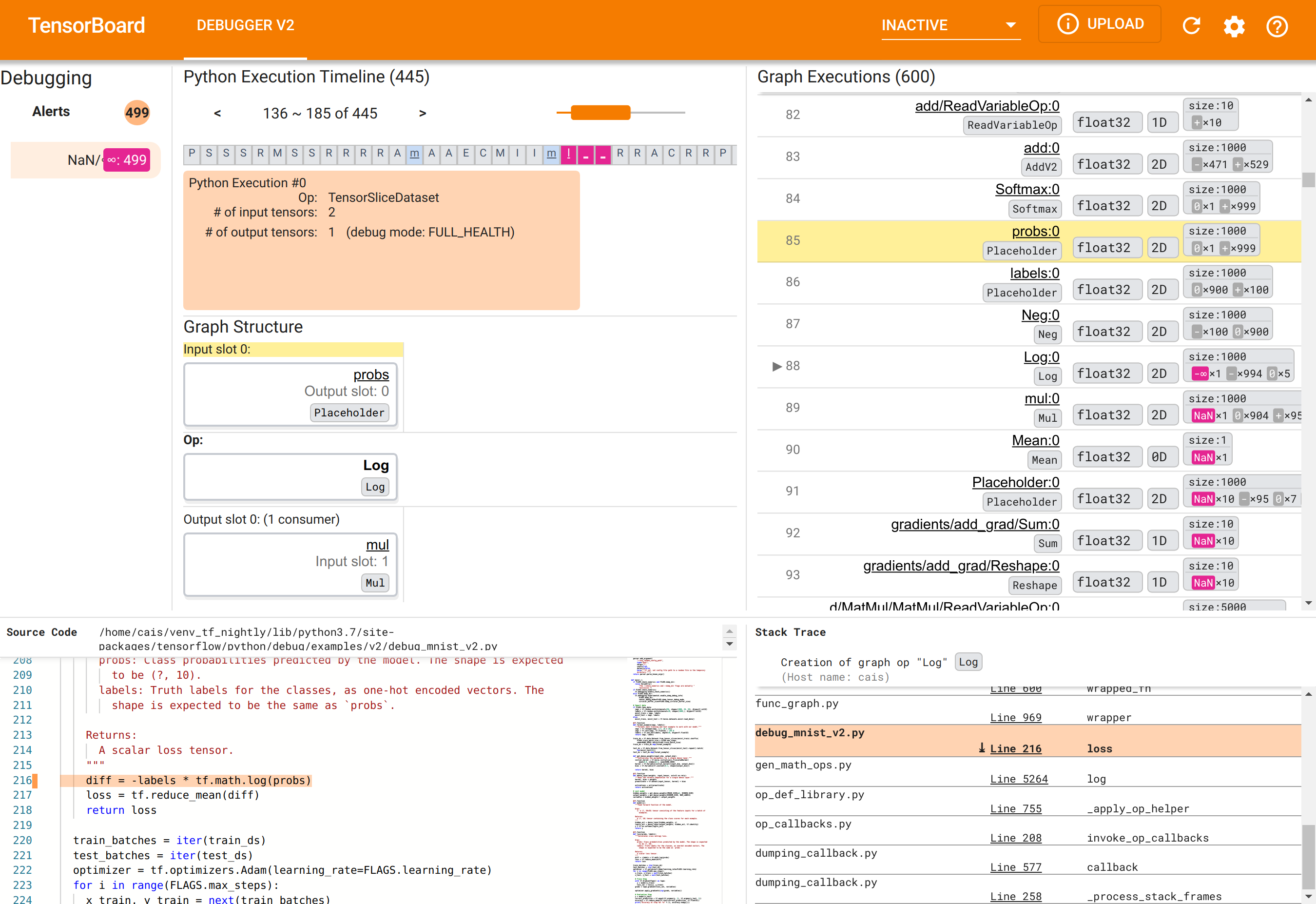
Usando a GUI do Debugger V2 para encontrar a causa raiz dos NaNs
A GUI do Debugger V2 no TensorBoard é organizada em seis seções:
- Alertas : esta seção superior esquerda contém uma lista de eventos de “alerta” detectados pelo depurador nos dados de depuração do programa TensorFlow instrumentado. Cada alerta indica uma determinada anomalia que merece atenção. No nosso caso, esta seção destaca eventos 499 NaN/∞ com uma cor rosa-avermelhada saliente. Isso confirma nossa suspeita de que o modelo falha em aprender devido à presença de NaNs e/ou infinitos em seus valores de tensor interno. Iremos nos aprofundar nesses alertas em breve.
- Linha do tempo de execução do Python : esta é a metade superior da seção intermediária superior. Apresenta o histórico completo da execução ávida de operações e gráficos. Cada caixa da linha do tempo é marcada pela letra inicial da operação ou nome do gráfico (por exemplo, “T” para a operação “TensorSliceDataset”, “m” para o “modelo”
tf.function). Podemos navegar nesta linha do tempo usando os botões de navegação e a barra de rolagem acima da linha do tempo. - Execução do Gráfico : Localizada no canto superior direito da GUI, esta seção será central para nossa tarefa de depuração. Ele contém um histórico de todos os tensores do tipo flutuante calculados dentro dos gráficos (ou seja, compilados por
@tf-functions). - Estrutura do gráfico (metade inferior da seção central superior), Código-fonte (seção inferior esquerda) e Stack Trace (seção inferior direita) estão inicialmente vazios. Seu conteúdo será preenchido quando interagirmos com a GUI. Essas três seções também desempenharão papéis importantes em nossa tarefa de depuração.
Tendo nos orientado para a organização da UI, vamos seguir os seguintes passos para descobrir por que os NaNs apareceram. Primeiro, clique no alerta NaN/∞ na seção Alertas. Isso rola automaticamente a lista de 600 tensores de gráfico na seção Execução de gráfico e se concentra no #88, que é um tensor chamado Log:0 gerado por uma Log (logaritmo natural). Uma cor rosa-avermelhada saliente destaca um elemento -∞ entre os 1000 elementos do tensor float32 2D. Este é o primeiro tensor no histórico de tempo de execução do programa TF2 que continha qualquer NaN ou infinito: tensores calculados antes dele não contêm NaN ou ∞; muitos (na verdade, a maioria) tensores calculados posteriormente contêm NaNs. Podemos confirmar isso rolando para cima e para baixo na lista de Execução do Gráfico. Esta observação fornece uma forte indicação de que o Log op é a fonte da instabilidade numérica neste programa TF2.
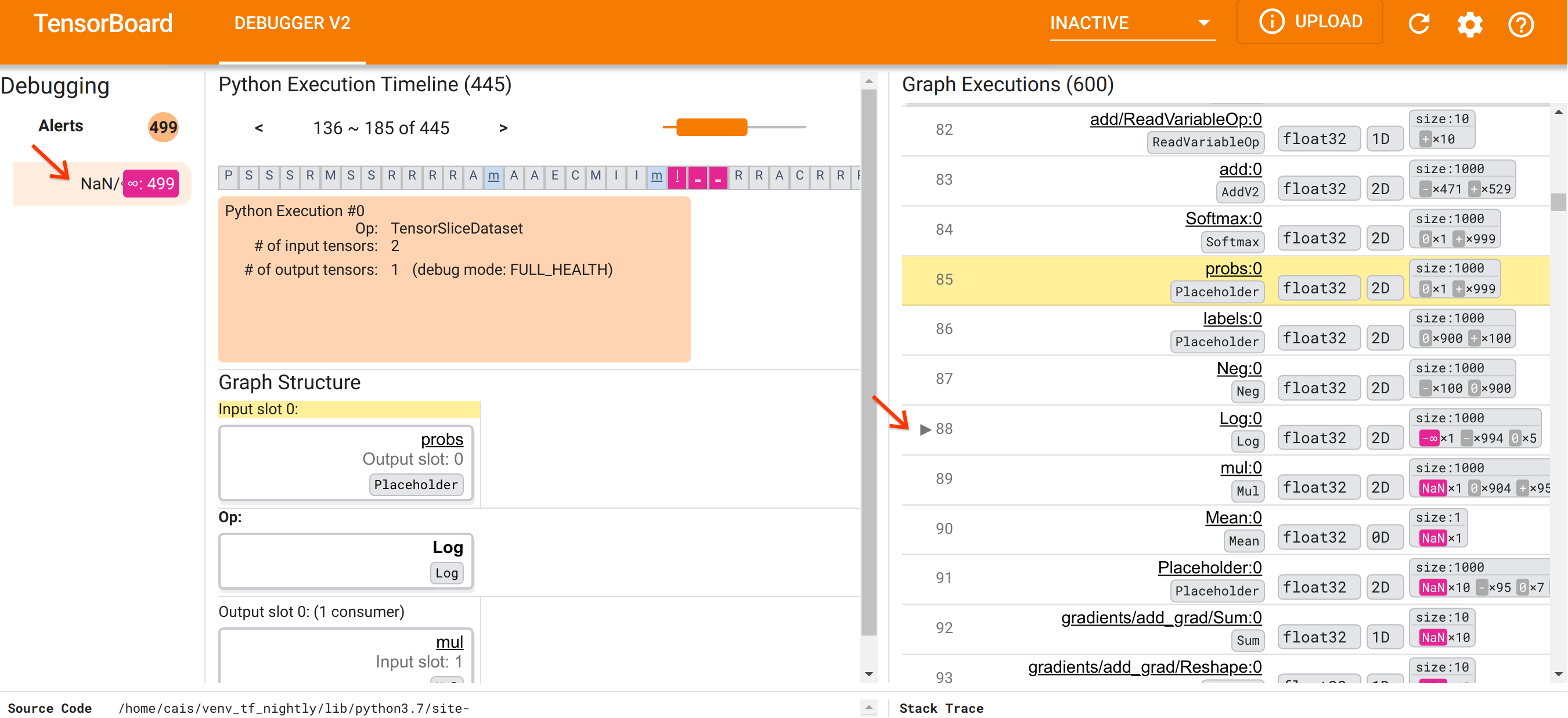
Por que esta operação Log exibe um -∞? Responder a essa pergunta requer examinar a entrada da operação. Clicar no nome do tensor ( Log:0 ) traz uma visualização simples, mas informativa, da vizinhança do Log op em seu gráfico TensorFlow na seção Estrutura do gráfico. Observe a direção de cima para baixo do fluxo de informações. A operação em si é mostrada em negrito no meio. Imediatamente acima dele, podemos ver que uma operação de espaço reservado fornece a única entrada para a operação Log . Onde está o tensor gerado por este espaço reservado probs na lista de execução do gráfico? Usando a cor de fundo amarela como auxílio visual, podemos ver que o tensor probs:0 está três linhas acima do tensor Log:0 , ou seja, na linha 85.
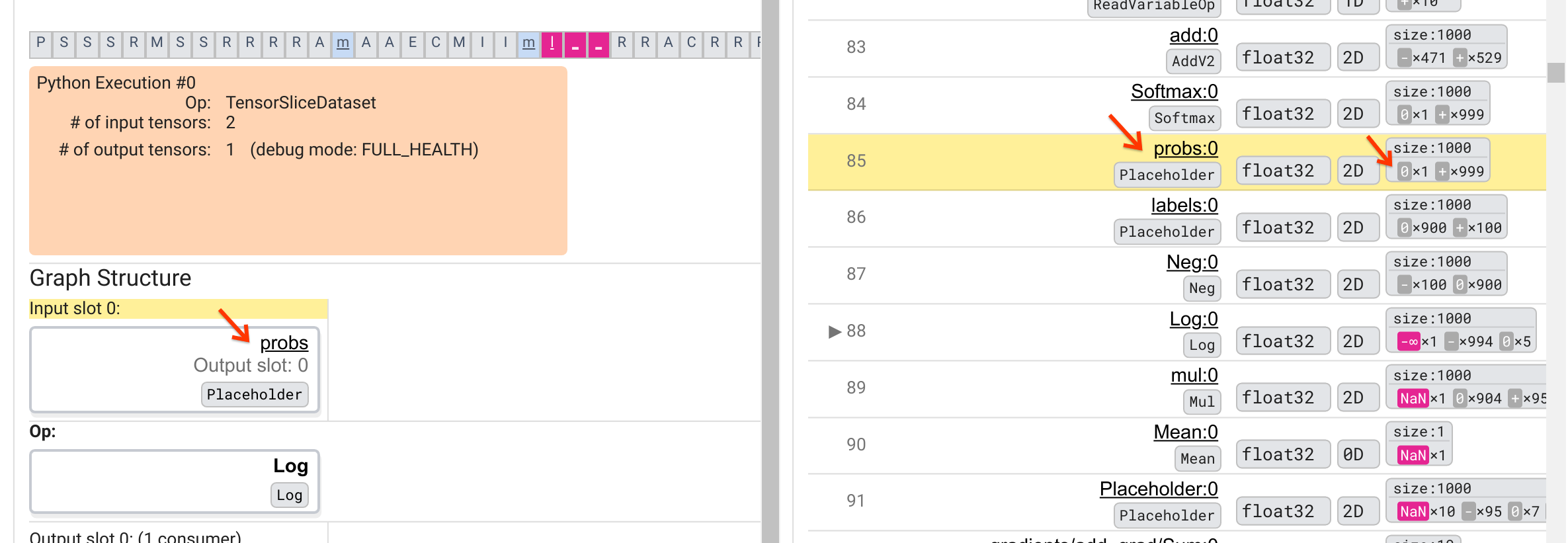
Uma análise mais cuidadosa da divisão numérica do tensor probs:0 na linha 85 revela por que seu consumidor Log:0 produz um -∞: Entre os 1000 elementos de probs:0 , um elemento tem o valor 0. O -∞ é resultado do cálculo do logaritmo natural de 0! Se pudermos de alguma forma garantir que a operação Log seja exposta apenas a entradas positivas, seremos capazes de evitar que NaN/∞ aconteça. Isso pode ser conseguido aplicando recorte (por exemplo, usando tf.clip_by_value() ) no tensor Placeholder probs .
Estamos cada vez mais perto de resolver o bug, mas ainda não terminamos. Para aplicar a correção, precisamos saber onde no código-fonte Python a operação Log e sua entrada Placeholder se originaram. O Debugger V2 fornece suporte de primeira classe para rastrear operações gráficas e eventos de execução até sua origem. Quando clicamos no tensor Log:0 em Graph Executions, a seção Stack Trace foi preenchida com o stack trace original da criação da operação Log . O rastreamento de pilha é um tanto grande porque inclui muitos quadros do código interno do TensorFlow (por exemplo, gen_math_ops.py e dumping_callback.py), que podemos ignorar com segurança para a maioria das tarefas de depuração. O quadro de interesse é a linha 216 de debug_mnist_v2.py (ou seja, o arquivo Python que estamos tentando depurar). Clicar em “Linha 216” abre uma visualização da linha de código correspondente na seção Código-fonte.
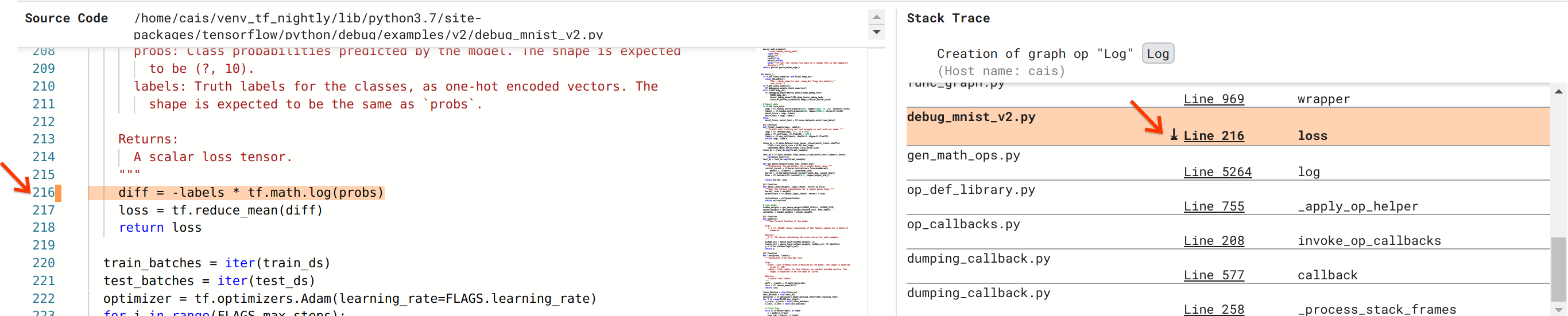
Isso finalmente nos leva ao código-fonte que criou a operação Log problemática a partir de sua entrada probs . Esta é nossa função categórica personalizada de perda de entropia cruzada decorada com @tf.function e, portanto, convertida em um gráfico TensorFlow. O Placeholder op probs corresponde ao primeiro argumento de entrada da função de perda. A operação Log é criada com a chamada de API tf.math.log().
A correção de recorte de valor para esse bug será semelhante a:
diff = -(labels *
tf.math.log(tf.clip_by_value(probs), 1e-6, 1.))
Isso resolverá a instabilidade numérica neste programa TF2 e fará com que o MLP seja treinado com sucesso. Outra abordagem possível para corrigir a instabilidade numérica é usar tf.keras.losses.CategoricalCrossentropy .
Isso conclui nossa jornada desde a observação de um bug do modelo TF2 até a criação de uma alteração de código que corrige o bug, auxiliada pela ferramenta Debugger V2, que fornece visibilidade total do histórico de execução antecipada e gráfica do programa TF2 instrumentado, incluindo os resumos numéricos de valores de tensores e associação entre operações, tensores e seu código-fonte original.
Compatibilidade de hardware do Debugger V2
O Debugger V2 oferece suporte a hardware de treinamento convencional, incluindo CPU e GPU. O treinamento multi-GPU com tf.distributed.MirroredStrategy também é compatível. O suporte para TPU ainda está em estágio inicial e requer ligação
tf.config.set_soft_device_placement(True)
antes de chamar enable_dump_debug_info() . Também pode ter outras limitações nas TPUs. Se você tiver problemas ao usar o Debugger V2, relate os bugs em nossa página de problemas do GitHub .
Compatibilidade de API do Debugger V2
O Debugger V2 é implementado em um nível relativamente baixo da pilha de software do TensorFlow e, portanto, é compatível com tf.keras , tf.data e outras APIs criadas com base nos níveis mais baixos do TensorFlow. O Debugger V2 também é compatível com versões anteriores do TF1, embora o Eager Execution Timeline esteja vazio para os logdirs de depuração gerados pelos programas TF1.
Dicas de uso de API
Uma pergunta frequente sobre esta API de depuração é onde no código do TensorFlow se deve inserir a chamada para enable_dump_debug_info() . Normalmente, a API deve ser chamada o mais cedo possível em seu programa TF2, de preferência após as linhas de importação do Python e antes do início da construção e execução do gráfico. Isso garantirá cobertura completa de todas as operações e gráficos que alimentam seu modelo e seu treinamento.
Os tensor_debug_modes atualmente suportados são: NO_TENSOR , CURT_HEALTH , CONCISE_HEALTH , FULL_HEALTH e SHAPE . Eles variam na quantidade de informações extraídas de cada tensor e na sobrecarga de desempenho do programa depurado. Consulte a seção args da documentação de enable_dump_debug_info() .
Sobrecarga de desempenho
A API de depuração introduz sobrecarga de desempenho no programa TensorFlow instrumentado. A sobrecarga varia de acordo com tensor_debug_mode , tipo de hardware e natureza do programa TensorFlow instrumentado. Como ponto de referência, em uma GPU, o modo NO_TENSOR adiciona uma sobrecarga de 15% durante o treinamento de um modelo Transformer no tamanho de lote 64. A sobrecarga percentual para outros tensor_debug_modes é maior: aproximadamente 50% para CURT_HEALTH , CONCISE_HEALTH , FULL_HEALTH e SHAPE modos. Nas CPUs, a sobrecarga é um pouco menor. Nas TPUs, a sobrecarga é atualmente maior.
Relação com outras APIs de depuração do TensorFlow
Observe que o TensorFlow oferece outras ferramentas e APIs para depuração. Você pode navegar por essas APIs no tf.debugging.* na página de documentos da API. Entre essas APIs, a mais utilizada é tf.print() . Quando se deve usar o Debugger V2 e quando deve ser usado tf.print() ? tf.print() é conveniente no caso em que
- sabemos exatamente quais tensores imprimir,
- sabemos exatamente onde inserir essas instruções
tf.print()no código-fonte, - o número de tais tensores não é muito grande.
Para outros casos (por exemplo, examinar muitos valores de tensor, examinar valores de tensor gerados pelo código interno do TensorFlow e procurar a origem da instabilidade numérica como mostramos acima), o Debugger V2 fornece uma maneira mais rápida de depuração. Além disso, o Debugger V2 fornece uma abordagem unificada para inspecionar tensores ansiosos e gráficos. Além disso, fornece informações sobre a estrutura do gráfico e localizações de código, que estão além da capacidade de tf.print() .
Outra API que pode ser usada para depurar problemas envolvendo ∞ e NaN é tf.debugging.enable_check_numerics() . Ao contrário de enable_dump_debug_info() , enable_check_numerics() não salva informações de depuração no disco. Em vez disso, ele apenas monitora ∞ e NaN durante o tempo de execução do TensorFlow e gera erros na localização do código de origem assim que qualquer operação gera valores numéricos ruins. Ele tem uma sobrecarga de desempenho menor em comparação com enable_dump_debug_info() , mas não oferece um rastreamento completo do histórico de execução do programa e não vem com uma interface gráfica de usuário como o Debugger V2.